
一文读懂直播卡顿优化那些事儿原创
4年前
873848
希望本文可以带给大家一个相对全局的视角看待卡顿问题,认识到卡顿是什么、卡顿的成因、卡顿的分类、卡顿的优化和一些经验积累,有的放矢地解决 App 流畅性问题。接下来会从以下五个方面进行讲述:✦什么是卡顿✦为什么会发生卡顿✦如何评价卡顿✦如何优化卡顿✦加入我们
1. 什么是卡顿
卡顿,顾名思义就是用户体感界面不流畅。我们知道手机的屏幕画面是按照一定频率来刷新的,理论上讲,24 帧的画面更新就能让人眼感觉是连贯的。但是实际上,这个只是针对普通的视频而言。对于一些强交互或者较为敏感的场景来说,比如游戏,起码需要 60 帧,30 帧的游戏会让人感觉不适;位移或者大幅度动画 30 帧会有明显顿挫感;跟手动画如果能到 90 帧甚至 120 帧,会让人感觉十分细腻,这也是近来厂商主打高刷牌的原因。
对于用户来说,从体感角度大致可以将卡顿分为以下几类:
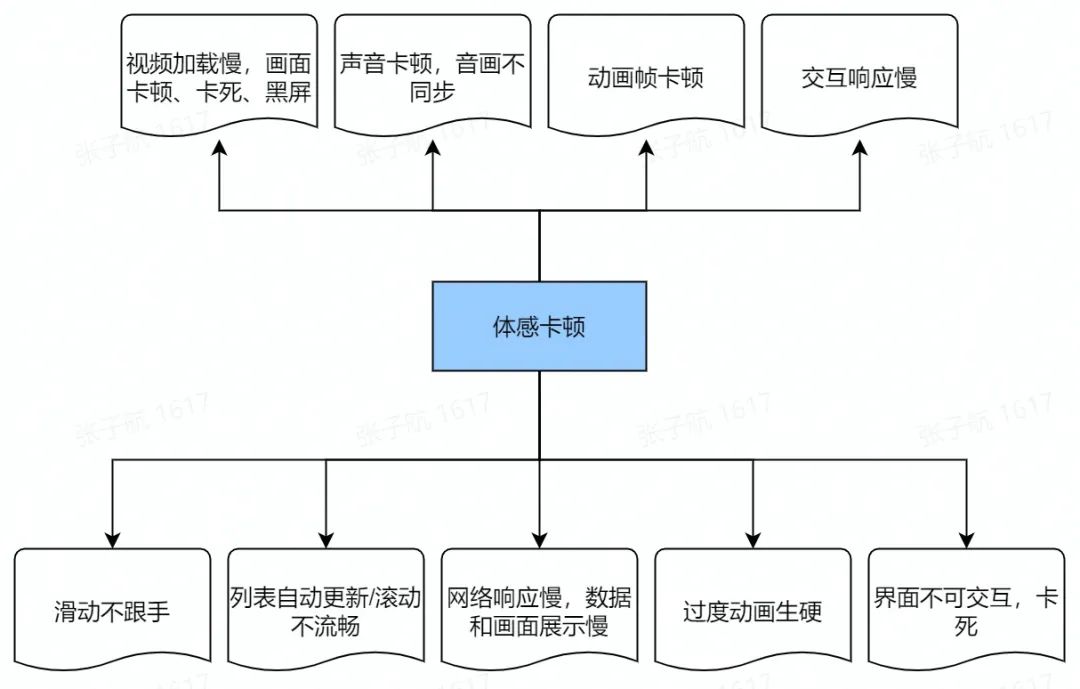
这些体验对于用户可以说是非常糟糕的,甚至会引起感官的烦躁,进而导致用户不愿意继续停留在我们的 App。可以说,流畅的体验对于用户来说至关重要。
2. 为什么会发生卡顿
用户体感的卡顿问题原因很多,且常常是一个复合型的问题,为了聚焦,这里暂只考虑真正意义上的掉帧卡顿。
2.1 绕不开的 VSYNC
我们通常会说,屏幕的刷新率是 60 帧,需要在 16ms 内做完所有的操作才不会造成卡顿。但是这里需要明确几个基本问题:
为什么是 16ms?16ms 内都需要完成什么?系统如何尽力保证任务在 16ms 内完成?16ms 内没有完成,一定会造成卡顿吗?
这里先回答第一个问题:为什么是 16ms。早期的 Android 是没有 vsync 机制的,CPU 和 GPU 的配合也比较混乱,这也造成著名的 tearing 问题,即 CPU/GPU 直接更新正在显示的屏幕 buffer 造成画面撕裂。后续 Android 引入了双缓冲机制,但是 buffer 的切换也需要一个比较合适的时机,也就是屏幕扫描完上一帧后的时机,这也就是引入 vsync 的原因。
早先一般的屏幕刷新率是 60fps,所以每个 vsync 信号的间隔也是 16ms,不过随着技术的更迭以及厂商对于流畅性的追求,越来越多 90fps 和 120fps 的手机面世,相对应的间隔也就变成了 11ms 和 8ms。
那既然有了 VSYNC,谁在消费 VSYNC?其实 Android 的 VSYNC 消费者有两个,也就对应两类 VSYNC 信号,分别是 VSYNC-app 和 VSYNC-sf,所对应的也是上层 view 绘制和 surfaceFlinger 的合成,具体的我们接下来详细说。

这里还有一些比较有意思的点,有些厂商会有 vsync offset 的设计,App 和 sf 的 vsync 信号之间是有偏移量的,这也在一定程度上使得 App 和 sf 的协同效应更好。
2.2 View 颠沛流离的一生
在讲下一 part 之前先引入一个话题:
一个 view 究竟是如何显示在屏幕上的?
我们一般都比较了解 view 渲染的三大流程,但是 view 的渲染远不止于此:
此处以一个通用的硬件加速流程来表征
Vsync 调度:很多同学的一个认知误区在于认为 vsync 是每 16ms 都会有的,但是其实 vsync 是需要调度的,没有调度就不会有回调;消息调度:主要是 doframe 的消息调度,如果消息被阻塞,会直接造成卡顿;input 处理:触摸事件的处理;动画处理:animator 动画执行和渲染;view 处理:主要是 view 相关的遍历和三大流程;measure、layout、draw:view 三大流程的执行;DisplayList 更新:view 硬件加速后的 draw op;OpenGL 指令转换:绘制指令转换为 OpenGL 指令;指令 buffer 交换:OpenGL 的指令交换到 GPU 内部执行;GPU 处理:GPU 对数据的处理过程;layer 合成:surface buffer 合成屏幕显示 buffer 的流程;光栅化:将矢量图转换为位图;Display:显示控制;buffer 切换:切换屏幕显示的帧 buffer;
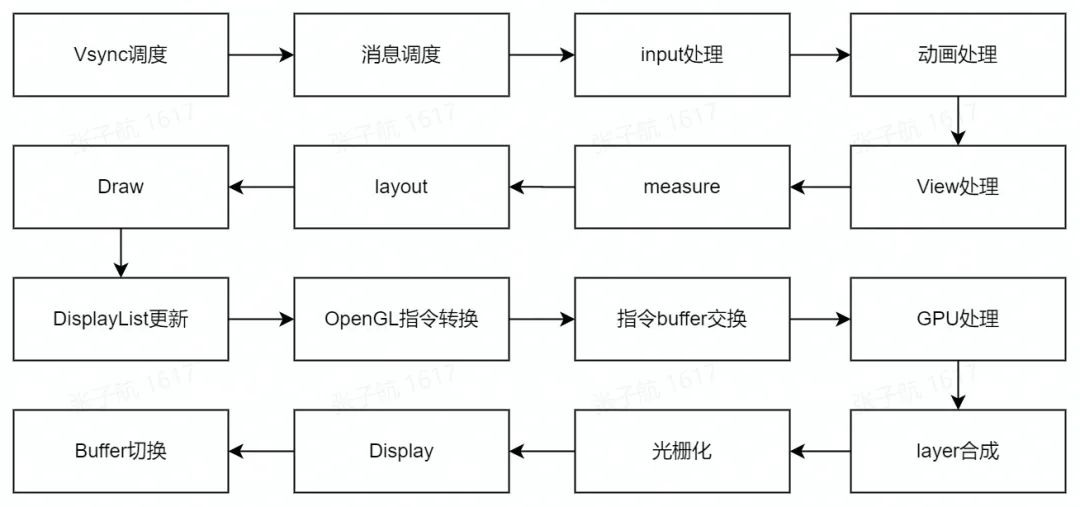
Google 将这个过程划分为:其他时间/VSync 延迟、输入处理、动画、测量/布局、绘制、同步和上传、命令问题、交换缓冲区。也就是我们常用的 GPU 严格模式,其实道理是一样的。到这里,我们也就回答出来了第二个问题:16ms 内都需要完成什么?
准确地说,这里仍可以进一步细化:16ms 内完成 APP 侧数据的生产;16ms 内完成 sf layer 的合成

View 的视觉效果正是通过这一整条复杂的链路一步步展示出来的,有了这个前提,那就可以得出一个结论:上述任意链路发生卡顿,均会造成卡顿。
2.3 生产者和消费者
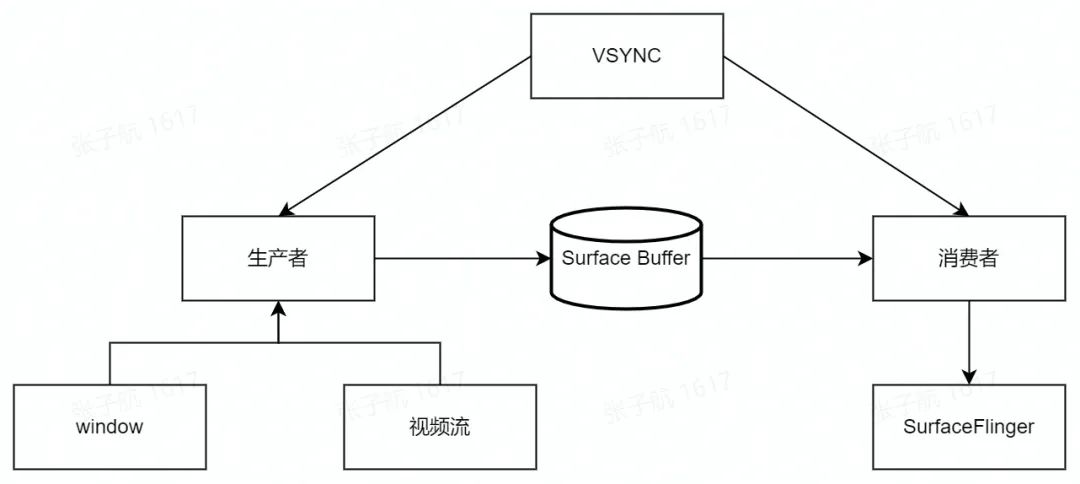
我们再回到 Vsync 的话题,消费 Vsync 的双方分别是 App 和 sf,其中 App 代表的是生产者,sf 代表的是消费者,两者交付的中间产物则是 surface buffer。
再具体一点,生产者大致可以分为两类,一类是以 window 为代表的页面,也就是我们平时所看到的 view 树这一套;另一类是以视频流为代表的可以直接和 surface 完成数据交换的来源,比如相机预览等。
对于一般的生产者和消费者模式,我们知道会存在相互阻塞的问题。比如生产者速度快但是消费者速度慢,亦或是生产者速度慢消费者速度快,都会导致整体速度慢且造成资源浪费。所以 Vsync 的协同以及双缓冲甚至三缓冲的作用就体现出来了。
思考一个问题:是否缓冲的个数越多越好?过多的缓冲会造成什么问题?
答案是会造成另一个严重的问题:lag,响应延迟
这里结合 view 的一生,我们可以把两个流程合在一起,让我们的视角再高一层:
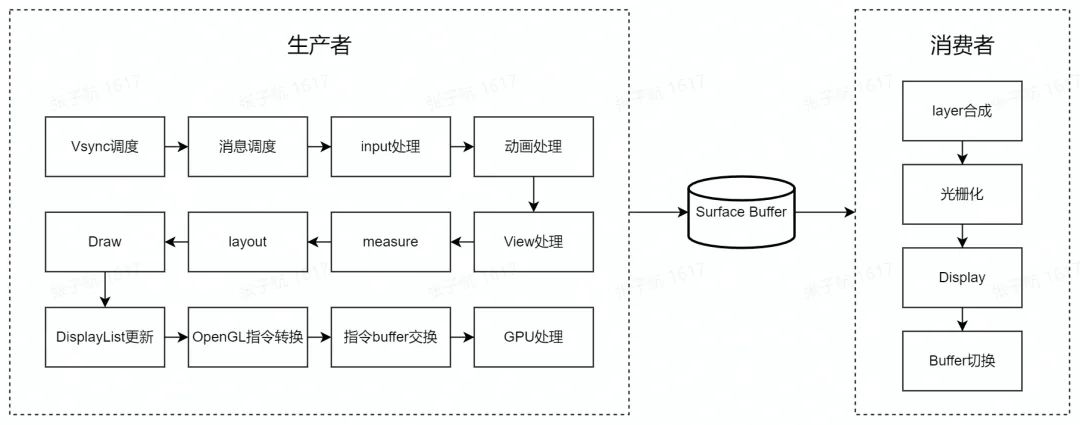
2.4 机制上的保护
这里我们来回答第三个问题,从系统的渲染架构上来说,机制上的保护主要有几方面:
Vsync 机制的协同;多缓冲设计;surface 的提供;同步屏障的保护;硬件绘制的支持;渲染线程的支持;GPU 合成加速;
这些机制上的保护在系统层面最大程度地保障了 App 体验的流畅性,但是并不能帮我们彻底解决卡顿。为了提供更加流畅的体验,一方面,我们可以加强系统的机制保护,比如 FWatchDog;另一方面,需要我们从 App 的角度入手,治理应用内的卡顿问题。
2.5 再看卡顿的成因
经过上面的讨论,我们得出一个卡顿分析的核心理论支撑:渲染机制中的任何流转过程发生异常,均会造成卡顿。
那么接下来,我们逐个分析,看看都会有哪些原因可能造成卡顿。
2.5.1 渲染流程
Vsync 调度:这个是起始点,但是调度的过程会经过线程切换以及一些委派的逻辑,有可能造成卡顿,但是一般可能性比较小,我们也基本无法介入;消息调度:主要是 doframe Message 的调度,这就是一个普通的 Handler 调度,如果这个调度被其他的 Message 阻塞产生了时延,会直接导致后续的所有流程不会被触发。这里直播建立了一个 FWtachDog 机制,可以通过优化消息调度达到插帧的效果,使得界面更加流畅;input 处理:input 是一次 Vsync 调度最先执行的逻辑,主要处理 input 事件。如果有大量的事件堆积或者在事件分发逻辑中加入大量耗时业务逻辑,会造成当前帧的时长被拉大,造成卡顿。抖音基础技术同学也有尝试过事件采样的方案,减少 event 的处理,取得了不错的效果;动画处理:主要是 animator 动画的更新,同理,动画数量过多,或者动画的更新中有比较耗时的逻辑,也会造成当前帧的渲染卡顿。对动画的降帧和降复杂度其实解决的就是这个问题;view 处理:主要是接下来的三大流程,过度绘制、频繁刷新、复杂的视图效果都是此处造成卡顿的主要原因。比如我们平时所说的降低页面层级,主要解决的就是这个问题;measure/layout/draw:view 渲染的三大流程,因为涉及到遍历和高频执行,所以这里涉及到的耗时问题均会被放大,比如我们会降不能在 draw 里面调用耗时函数,不能 new 对象等等;DisplayList 的更新:这里主要是 canvas 和 displaylist 的映射,一般不会存在卡顿问题,反而可能存在映射失败导致的显示问题;OpenGL 指令转换:这里主要是将 canvas 的命令转换为 OpenGL 的指令,一般不存在问题。不过这里倒是有一个可以探索的点,会不会存在一类特殊的 canvas 指令,转换后的 OpenGL 指令消耗比较大,进而导致 GPU 的损耗?有了解的同学可以探讨一下;buffer 交换:这里主要指 OpenGL 指令集交换给 GPU,这个一般和指令的复杂度有关。一个有意思的事儿是这里一度被我们作为线上采集 GPU 指标的数据源,但是由于多缓冲的因素数据准确度不够被放弃了;GPU 处理:顾名思义,这里是 GPU 对数据的处理,耗时主要和任务量和纹理复杂度有关。这也就是我们降低 GPU 负载有助于降低卡顿的原因;layer 合成:这里主要是 layer 的 compose 的工作,一般接触不到。偶尔发现 sf 的 vsync 信号被 delay 的情况,造成 buffer 供应不及时,暂时还不清楚原因;光栅化/Display:这里暂时忽略,底层系统行为;Buffer 切换:主要是屏幕的显示,这里 buffer 的数量也会影响帧的整体延迟,不过是系统行为,不能干预。
2.5.2 视频流
除了上述的渲染流程引起的卡顿,还有一些其他的因素,典型的就是视频流。
渲染卡顿:主要是 TextureView 渲染,textureview 跟随 window 共用一个 surface,每一帧均需要一起协同渲染并相互影响,UI 卡顿会造成视频流卡顿,视频流的卡顿有时候也会造成 UI 的卡顿;解码:解码主要是将数据流解码为 surface 可消费的 buffer 数据,是除了网络外最重要的耗时点。现在我们一般都会采用硬解,比软解的性能高很多。但是帧的复杂度、编码算法的复杂度、分辨率等也会直接导致解码耗时被拉长;OpenGL 处理:有时会对解码完成的数据做二次处理,这个如果比较耗时会直接导致渲染卡顿;网络:这个就不再赘述了,包括 DNS 节点优选、cdn 服务、GOP 配置等;推流异常:这个属于数据源出了问题,这里暂时以用户侧的视角为主,暂不讨论。
2.5.3 系统负载
内存:内存的吃紧会直接导致 GC 的增加甚至 ANR,是造成卡顿的一个不可忽视的因素;CPU:CPU 对卡顿的影响主要在于线程调度慢、任务执行的慢和资源竞争,比如降频会直接导致应用卡顿;GPU:GPU 的影响见渲染流程,但是其实还会间接影响到功耗和发热;功耗/发热:功耗和发热一般是不分家的,高功耗会引起高发热,进而会引起系统保护,比如降频、热缓解等,间接的导致卡顿。
2.6 卡顿的分类
我们此处再整体整理并归类,为了更完备一些,这里将推流也放了上来。在一定程度上,我们遇到的所有卡顿问题,均能在这里找到理论依据,这也是指导我们优化卡顿问题的理论支撑。
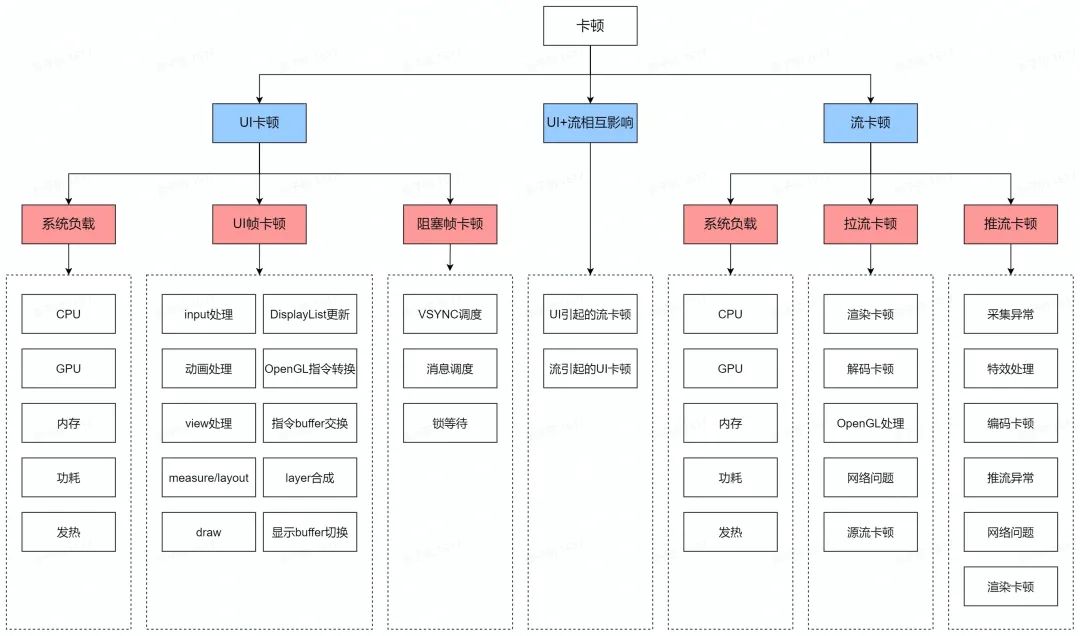
3. 如何评价卡顿
3.1 线上指标

3.2 线下指标
Diggo 是字节自研的一个开放的开发调试工具平台,是一个集「评价、分析、调试」为一体的,一站式工具平台。内置性能测评、界面分析、卡顿分析、内存分析、崩溃分析、即时调试等基础分析能力,可为产品开发阶段提供强大助力。

4. 如何优化卡顿
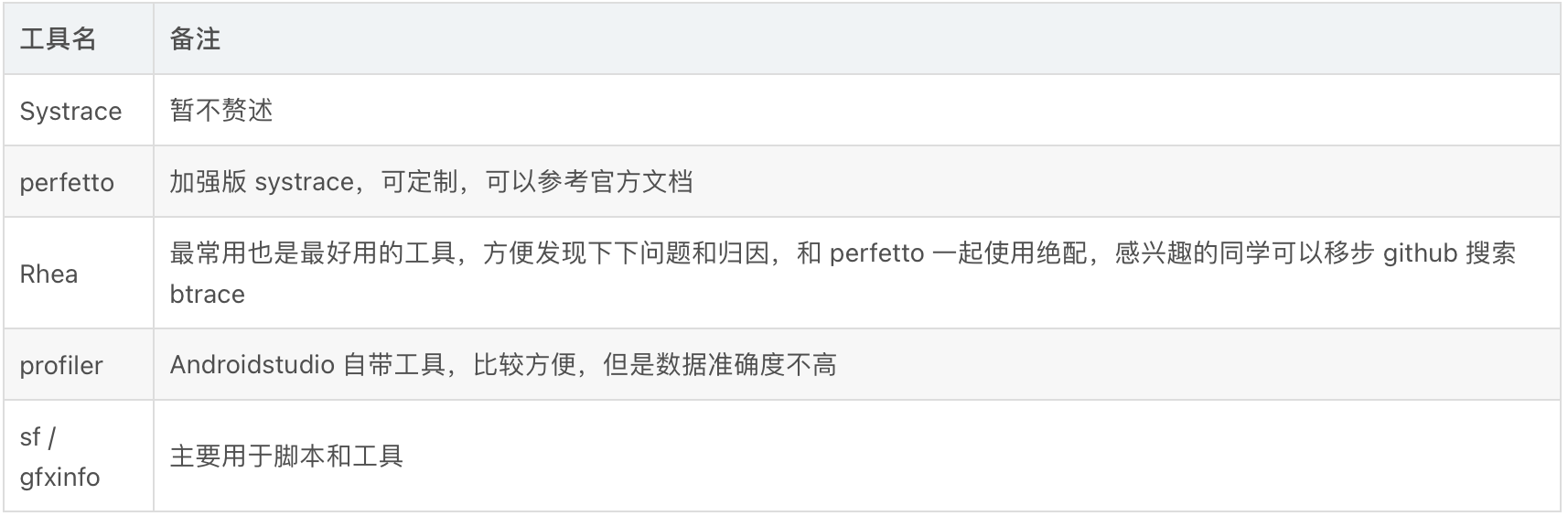
4.1 常用的工具
4.1.1 线上工具

4.1.2 线下工具
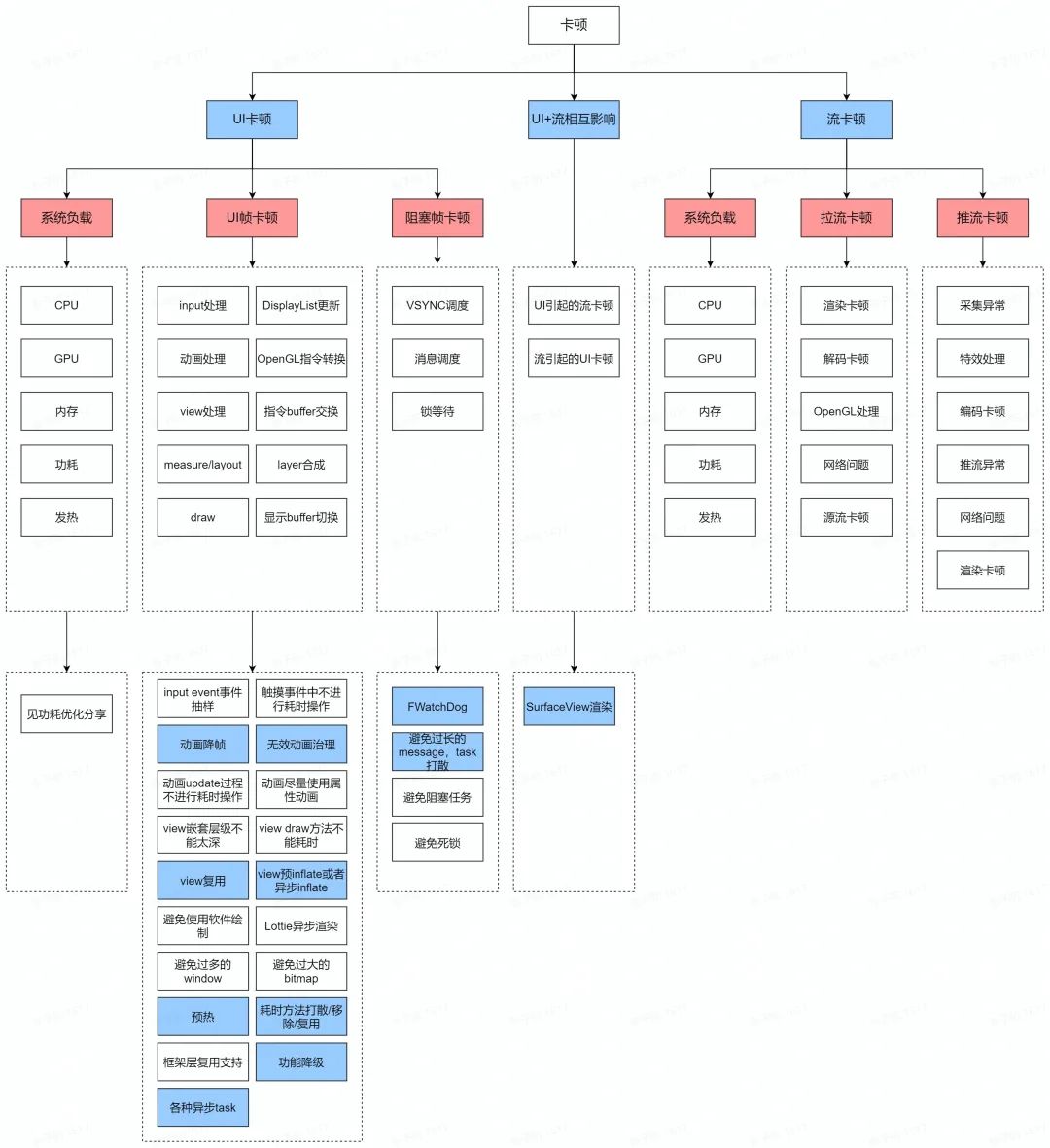
4.2 常用的思路
这里主要针对 UI 卡顿和 UI/流相互影响打来的卡顿。
对于 UI 卡顿来说,我们手握卡顿优化的 8 板大斧子,所向披靡:
下线代码;
减少执行次数;
异步;
打散;
预热;
复用;
方案优化;
硬件加速;
总体思路就是「能不干就不干、能少干就少干、能早点干就早点儿干、能晚点儿干就晚点儿干、能让别人干就让别人干、能干完一次当 10 次就只干一次,实在不行,再考虑自己大干一场」。
这里例举出一些常见的优化思路,注意这一定也不可能是全部,如果有其他好的优化思路,我们可以一起交流。
4.3 一些做过的事儿
4.3.1 解决 UI 卡顿引起的流卡顿
直播对于 SurfaceView 的切换是一个长期的专项,分为多期逐步将 SurfaceView 在直播全量落地,场景覆盖秀场直播、聊天室、游戏直播、电商直播、媒体直播等,业务上对于渗透率和停留时长有比较显著的收益,同时功耗的收益也很可观。
这里是一个权衡的问题,SurfaceView 的兼容性问题 pk 带来的收益是否能打平,一般来说,越是复杂的业务场景,收益约大。
4.3.2 解决 message 调度
FWatchDog 是基于对 MessageQueue 的调度策略和同步屏障原理,以均帧耗时为阈值判定丢帧后主动在 MessageQueue 中插入同步屏障,保证渲染异步 message 和 doframe 的优先执行,达到一种渲染插帧的效果,同时具备 ANR 自动恢复同步屏障的能力,保障打散的有效。
所以 FWatchDog 和打散是好的搭档,能产生 1+1 大于 2 的效果。
4.3.3 减少执行次数
一个典型的应用场景就是滑动场景的 GC 抑制,能够显著提高用户上下滑的使用体验。这个场景相信每个业务都会存在,特别是存在大量遍历的逻辑,优化效果明显。
4.3.4 代码下线
一些老的框架、无用的逻辑以及存在性不高的代码都可以下线,这里基本业务强相关,就不举具体的例子了。
4.3.5 解决耗时函数(打散/异步)
首先是打散,直播做了很多 task 的拆分以及打散,第一可以减轻当前渲染帧的耗时压力,第二可以和 FWatchDog 结合达到插帧的效果。这里其实还可以控制 task 的执行优先级,包括队列的插队等,总之 MessageQueue 的合理调度是很有必要的。
异步的使用也相对比较多,一个埋点日志的框架,以及一些 inflate 的加载等,都可以使用异步来解决卡顿问题。
4.3.6 预热
直播提供了一个预热框架,可以让直播内部的一次性成本逻辑得到在宿主侧执行的机会,同时提供完备的队列优先级管理、同步异步管理和 task 生命周期管理,降低直播内部首次加载的卡顿问题。
4.3.7 硬件加速
拉高硬件的运行性能,比如 CPU 频率、GPU 频率、线程绑大核以及网络相关的调优,从底层提高 App 的运行体验。
5. 加入我们
直播客户端技术团队是一个集体验优化、平台建设、跨端、端智能、稳定性为一体的综合性团队,团队氛围 nice,技术成长快,有充足的自由度发挥自己的特长,为亿级 DAU 产品保驾护航,也面临更加丰富多样的挑战,每一行代码都会让数亿的用户体验变得更好!现诚邀各位英才加入,对这些方向感兴趣的同学都可以来聊一聊。
点赞收藏
分类:


