
关键词:k8s、jvm、高可用
1.背景
最近有运维反馈某个微服务频繁重启,客户映像特别不好,需要我们尽快看一下。
听他说完我立马到监控平台去看这个服务的运行情况,确实重启了很多次。对于技术人员来说,这既是压力也是动力,大多数时候我们都是沉浸在单调的业务开发中,对自我的提升有限,久而久之可能会陷入一种舒适区,遇到这种救火案例一时间会有点无所适从,但是没关系,毕竟......
“我只是收了火,但没有熄炉”,借用电影中的一句话表达一下此时的心情。
2.初看日志
我当即就看这个服务的运行日志,里面有大量的oom异常,如下:
org.springframework.web.util.NestedServletException: Handler dispatch failed; nested exception is java.lang.OutOfMemoryError: GC overhead limit exceeded
整个服务基本可以说处于不可用状态,任何请求过来几乎都会报oom,但是这跟重启有什么关系呢?是谁触发了重启呢?这里我暂时卖个关子,后面进行解答。
3.k8s健康检查介绍
我们的服务部署在k8s中,k8s可以对容器执行定期的诊断,要执行诊断,kubelet 调用由容器实现的 Handler (处理程序)。有三种类型的处理程序:
-
ExecAction:在容器内执行指定命令。如果命令退出时返回码为 0 则认为诊断成功。
-
TCPSocketAction:对容器的 IP 地址上的指定端口执行 TCP 检查。如果端口打开,则诊断被认为是成功的。
-
HTTPGetAction:对容器的 IP 地址上指定端口和路径执行 HTTP Get 请求。如果响应的状态码大于等于 200 且小于 400,则诊断被认为是成功的。
每次探测都将获得以下三种结果之一:
-
Success(成功):容器通过了诊断。
-
Failure(失败):容器未通过诊断。
-
Unknown(未知):诊断失败,因此不会采取任何行动。
针对运行中的容器,kubelet 可以选择是否执行以下三种探针,以及如何针对探测结果作出反应:
-
livenessProbe:指示容器是否正在运行。如果存活态探测失败,则 kubelet 会杀死容器, 并且容器将根据其重启策略决定未来。如果容器不提供存活探针, 则默认状态为 Success。
-
readinessProbe:指示容器是否准备好为请求提供服务。如果就绪态探测失败, 端点控制器将从与 Pod 匹配的所有服务的端点列表中删除该 Pod 的 IP 地址。初始延迟之前的就绪态的状态值默认为 Failure。如果容器不提供就绪态探针,则默认状态为 Success。
-
startupProbe: 指示容器中的应用是否已经启动。如果提供了启动探针,则所有其他探针都会被 禁用,直到此探针成功为止。如果启动探测失败,kubelet 将杀死容器,而容器依其 重启策略进行重启。如果容器没有提供启动探测,则默认状态为 Success。
以上探针介绍内容来源于https://kubernetes.io/zh/docs/concepts/workloads/pods/pod-lifecycle/#container-probes
看完探针的相关介绍,可以基本回答上面的疑点“oom和重启有什么关系?”,是livenessProbe的锅,简单描述一下为什么:
-
服务启动;
-
k8s通过livenessProbe中配置的健康检查Handler做定期诊断(我们配置的是HttpGetAction);
-
由于oom所以HttpGetAction返回的http status code是500,被k8s认定为Failure(失败)-容器未通过诊断;
-
k8s认为pod不健康,决定“杀死”它然后重新启动。
这是服务的Deployment.yml中关于livenessProbe和restartPolicy的配置
livenessProbe:
failureThreshold: 5
httpGet:
path: /health
port: 8080
scheme: HTTP
initialDelaySeconds: 180
periodSeconds: 20
successThreshold: 1
timeoutSeconds: 10
restartPolicy: Always
4.第一次优化
内存溢出无外乎内存不够用了,而这种不够用又粗略分两种情况:
-
存在内存泄漏情况,本来应该清理的对象但是并没有被清理,比如HashMap以自定义对象作为Key时对hashCode和equals方法处理不当时可能会发生;
-
内存确实不够用了,比如访问量突然上来了;
由于我们这个是一个老服务,而且在多个客户私有化环境都部署过,都没出过这个问题,所以我直接排除了内存泄漏的情况,那就将目光投向第二种“内存确实不够用”,通过对比访问日志和询问业务人员后得知最近客户在大力推广系统,所以访问量确实是上来了。
“不要一开始就陷入技术人员的固化思维,认为是程序存在问题”
知道了原因那解决手段也就很粗暴了,加内存呗,分分钟改完重新发布。

终于发布完成,我打开监控平台查看服务的运行情况,这次日志里确实没有oom的字样,本次优化以迅雷不及掩耳之势这么快就完了?果然是我想多了,一阵过后我眼睁睁看着pod再次重启,但诡异的是程序日志里没有oom,这一次是什么造成了它重启呢?
我使用kubectl describe pod命令查看一下pod的详细信息,重点关注Last State,里面包括上一次的退出原因和退回code。
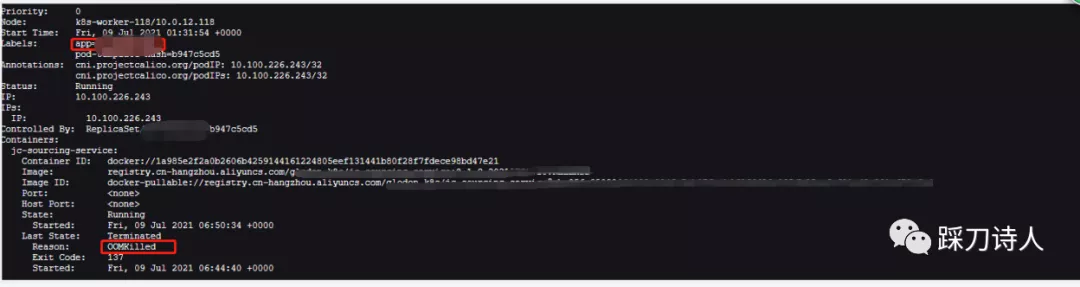
可以看到上一次退出是由于OOMKilled,字面意思就是pod由于内存溢出被kill,这里的OOMKilled和之前提到的程序日志中输出的oom异常可千万不要混为一谈,如果pod 中的limit 资源设置较小,会运行内存不足导致 OOMKilled,这个是k8s层面的oom,这里借助官网的文档顺便介绍一下pod和容器中的内存限制。
以下pod内存限制内容来源于https://kubernetes.io/zh/docs/tasks/configure-pod-container/assign-memory-resource/
要为容器指定内存请求,请在容器资源清单中包含 resources:requests 字段。同理,要指定内存限制,请包含 resources:limits。
以下deployment.yml将创建一个拥有一个容器的 Pod。容器将会请求 100 MiB 内存,并且内存会被限制在 200 MiB 以内:
apiVersion: v1
kind: Pod
metadata:
name: memory-demo
namespace: mem-example
spec:
containers:
- name: memory-demo-ctr
image: polinux/stress
resources:
limits:
memory: "200Mi"
requests:
memory: "100Mi"
command: ["stress"]
args: ["--vm", "1", "--vm-bytes", "150M", "--vm-hang", "1"]
当节点拥有足够的可用内存时,容器可以使用其请求的内存。但是,容器不允许使用超过其限制的内存。如果容器分配的内存超过其限制,该容器会成为被终止的候选容器。如果容器继续消耗超出其限制的内存,则终止容器。如果终止的容器可以被重启,则 kubelet 会重新启动它,就像其他任何类型的运行时失败一样。
回归到我们的场景中来讲,虽然把jvm内存提高了,但是其运行环境(pod、容器)的内存限制并没有提高,所以自然是达不到预期状态的,解决方式也是很简单了,提高deployment.yml中memory的限制,比如jvm中-Xmx为1G,那memory的limits至少应该大于1G。
至此,第一次优化算是真正告一段落。
5.第二次优化
第一次优化只给我们带来了短暂的平静,重启次数确实有所下降,但是离我们追求的目标还是相差甚远,所以亟需来一次更彻底的优化,来捍卫技术人员的尊严,毕竟我们都是头顶别墅的人。

头顶撑不住的时候,吃点好的补补
上一次频繁重启是因为内存不足导致大量的oom异常,最终k8s健康检查机制认为pod不健康触发了重启,优化手段就是加大jvm和pod的内存,这一次的重启是因为什么呢?
前面说过k8s对http形式的健康检查地址做探测时,如果响应的状态码大于等于 200 且小于 400,则诊断被认为是成功的,否则就认为失败,这里其实忽略了一种极其普遍的情况“超时”,如果超时了也一并会归为失败。
为什么这里才引出超时呢,因为之前日志中有大量的报错,很直观的可以联想到健康检查一定失败,反观这次并没有直接证据,逼迫着发挥想象力(其实后来知道通过kubectl describe pod是可以直接观测到超时这种情况的)。
现在我们就去反推有哪些情况会造成超时:
1.cpu 100%,这个之前确实遇到过一次,是因为宿主机cpu 100%,造成大量pod停止响应,最终大面积重启;
2.网络层面出了问题,比如tcp队列被打满,导致请求得不到处理。感兴趣的可以参考我之前的文章CLOSE_WAIT导致服务假死;
3.web容器比如tomcat、jetty的线程池饱和了,这时后来的任务会堆积在线程池的队列中;
4.jvm卡顿了,比如让开发闻风丧胆的fullgc+stw;
以上四种只是通过我的认知列举的,水平有限,更多情况欢迎大家补充。
现在我们一一排除,揪出元凶
1.看了监控宿主机负载正常,cpu正常,所以排除宿主机的问题;
2.ss -lnt查看tcp队列情况,并没有堆积、溢出情况,排除网络层面问题;
3.jstack查看线程情况,worker线程稍多但没有到最大值,排除线程池满的情况;
4.jstat gcutil查看gc情况,gc比较严重,老年代gc执行一次平均耗时1秒左右,持续时间50s到60s左右嫌疑非常大。
通过上面的排除法暂定是gc带来的stw导致jvm卡顿,最终导致健康检查超时,顺着这个思路我们先优化一把看看效果。
开始之前先补一张gc耗时的截图,为了查看的直观性,此图由arthas的dashboard产生。

说实话我对gc是没有什么调优经验的,虽然看过比较多的文章,但是连纸上谈兵都达不到,这次也是硬着头皮进行一次“调参”,调优这件事真是不敢当。
具体怎么调参呢,通过上面gc耗时的分布,很直观的拿到一个讯息,老年代的gc耗时有点长,而且次数比较频繁,虽然图里只有40次,但是相对于这个服务的启动时间来讲已经算频繁了,所以目标就是降低老年代gc频率。
从我了解的gc知识来看,老年代gc频繁是由于对象过早晋升导致,本来应该等到age达到晋升阈值才晋升到老年代的,但是由于年轻代内存不足,所以提前晋升到了老年代,晋升率过高是导致老年代gc频繁的主要原因,所以最终转化为如何降低晋升率,有两种办法:
1.增大年轻代大小,对象在年轻代得到回收,只有生命周期长的对象才进入老年代,这样老年代增速变慢,gc频率也就降下来了;
2.优化程序,降低对象的生存时间,尽量在young gc阶段回收对象。
由于我对这个服务并不是很熟悉,所以很自然的倾向于方法1“调整内存”,具体要怎么调整呢,这里借用一下美团技术博客中提到的一个公式来抛砖一下:

图片内容来源于https://tech.meituan.com/2017/12/29/jvm-optimize.html
结合之前的那张gc耗时图可以知道这个服务活跃数据大小为750m,进而得出jvm内存各区域的配比如下:
年轻代:750m*1.5 = 1125m
老年代:750m*2.5 = 1875m
接下来通过调整过的jvm内存配比重新发布验证效果,通过一段时间的观察,老年代gc频率很明显降下来了,大部分对象在新生代被回收,整体stw时间减少,运行一个多月再没有遇到自动重启的情况,由此也验证了我之前的猜测“因为持续的gc导致健康检查超时,进而触发重启”。
至此,第二次优化告一段落。
6.第三次优化
第二次优化确实给我们带来了一段时间的安宁,后续的一个多月宕机率的统计不至于啪啪打架构部的脸。

刚安生几天,这不又来活了
有运维反馈某服务在北京客户的私有化部署环境有重启现象,频率基本上在2天一次,接收到这个讯息以后我们立马重视起来,先确定两个事:
1.个例还是普遍现象-个例,只在这个客户环境出现;
2.会不会和前两次优化的问题一样,都是内存设置不合适导致的-不是,新服务,内存占用不高,gc也还好。
结合前面的两个推论“个例”+“新服务,各项指标暂时正常“,我怀疑会不会是给这个客户新做的某个功能存在bug,因为目前使用频率不高,所以积攒一段时间才把服务拖垮。带着这个疑惑我采取了守株待兔的方式,shell写一个定时任务,每5s输出一下关键指标数据,定时任务如下:
#!/bin/bash
while true ; do
/bin/sleep 5
netstat -n | awk '/^tcp/ {++S[$NF]} END {for(a in S) print a, S[a]}' >> netstat.log
ss -lnt >> ss.log
jstack 1 >> jstack.log
done
主要关注的指标有网络情况、tcp队列情况、线程栈情况。
就这样,一天以后这个服务终于重启了,我一一检查netstat.log,ss.log,jstack.log这几个文件,在jstack.log中问题原因剥茧抽丝般显现出来,贴一段stack信息让大家一睹为快:
"qtp1819038759-2508" #2508 prio=5 os_prio=0 tid=0x00005613a850c800 nid=0x4a39 waiting on condition [0x00007fe09ff25000]
java.lang.Thread.State: WAITING (parking)
at sun.misc.Unsafe.park(Native Method)
- parking to wait for <0x00000007221fc9e8> (a java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject)
at java.util.concurrent.locks.LockSupport.park(LockSupport.java:175)
at java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject.await(AbstractQueuedSynchronizer.java:2044)
at org.apache.http.pool.AbstractConnPool.getPoolEntryBlocking(AbstractConnPool.java:393)
at org.apache.http.pool.AbstractConnPool.access$300(AbstractConnPool.java:70)
at org.apache.http.pool.AbstractConnPool$2.get(AbstractConnPool.java:253)
- locked <0x00000007199cc158> (a org.apache.http.pool.AbstractConnPool$2)
at org.apache.http.pool.AbstractConnPool$2.get(AbstractConnPool.java:198)
at org.apache.http.impl.conn.PoolingHttpClientConnectionManager.leaseConnection(PoolingHttpClientConnectionManager.java:306)
at org.apache.http.impl.conn.PoolingHttpClientConnectionManager$1.get(PoolingHttpClientConnectionManager.java:282)
at org.apache.http.impl.execchain.MainClientExec.execute(MainClientExec.java:190)
at org.apache.http.impl.execchain.ProtocolExec.execute(ProtocolExec.java:186)
at org.apache.http.impl.execchain.RedirectExec.execute(RedirectExec.java:110)
at org.apache.http.impl.client.InternalHttpClient.doExecute(InternalHttpClient.java:185)
at org.apache.http.impl.client.CloseableHttpClient.execute(CloseableHttpClient.java:83)
at com.aliyun.oss.common.comm.DefaultServiceClient.sendRequestCore(DefaultServiceClient.java:125)
at com.aliyun.oss.common.comm.ServiceClient.sendRequestImpl(ServiceClient.java:123)
at com.aliyun.oss.common.comm.ServiceClient.sendRequest(ServiceClient.java:68)
at com.aliyun.oss.internal.OSSOperation.send(OSSOperation.java:94)
at com.aliyun.oss.internal.OSSOperation.doOperation(OSSOperation.java:149)
at com.aliyun.oss.internal.OSSOperation.doOperation(OSSOperation.java:113)
at com.aliyun.oss.internal.OSSObjectOperation.getObject(OSSObjectOperation.java:273)
at com.aliyun.oss.OSSClient.getObject(OSSClient.java:551)
at com.aliyun.oss.OSSClient.getObject(OSSClient.java:539)
at xxx.OssFileUtil.downFile(OssFileUtil.java:212)
大量的线程hang在了 org.apache.http.impl.conn.PoolingHttpClientConnectionManager$1.get(PoolingHttpClientConnectionManager.java:282
这个是做什么的呢?这个正是HttpClient中的连接池满了的迹象,线程在等待可用连接,最终导致jetty的线程被打满,造成服务假死,自然是不能及时响应健康检查,最终触发k8s的重启策略。
最终通过排查代码发现是由于使用阿里云oss sdk不规范导致连接没有按时归还,久而久之就造成了连接池、线程池被占满的情况,至于为什么只有北京客户有这个问题是因为只有这一家配置了oss存储,而且这个属于新支持的功能,目前尚处于试点阶段,所以短时间量不大,1到2天才出现一次重启事故。
解决办法很简单,就是及时关闭ossObject,防止连接泄漏。
7.总结
通过前前后后一个多月的持续优化,服务的可用性又提高了一个台阶,于我而言收获颇丰,对于jvm知识又回顾了一遍,也能结合以往知识进行简单的调参,对于k8s这一黑盒,也不再那么陌生,学习了基本的概念和一些简单的运维指令,最后还是要说一句“工程师对于自己写的每一行代码都要心生敬畏,否则可能就会给公司和客户带来资损”。
8.推荐阅读


