
从源码出发看ZGC黑科技——栈水位(Stack Watermark)技术内幕原创
jdk17已经出来半年了,作为一个长期支持的版本,笔者还是挺期待它的表现的。但是奈何最近比较忙,还有其他博客系列要收尾,就没有过多关注。最近看了下openjdk的官方wiki,惊奇的发现zgc的最大停顿时间从10ms降低到了1ms(实际上是jdk16已经实现的功能)。看到这里笔者不得不感叹,zgc的开发团队是一个非常有野心的团队,并不满足10ms的最大停顿时间的现状,又进一步将停顿时间打下来,实现了最大停顿时间小于1ms的优化。
经过笔者对官方资料的查阅与分析,这一功能得以实现依赖于一项黑科技——栈水位/水印(Stack Watermark),官方文档也将栈水位称之为在代码中加了魔法。目前全网对于这个特性的中文文档非常少,而且大多都是机翻的文档,关于其原理的文档更是连英文文档也很少见。笔者出于对技术的执着与好奇,下载了openjdk17的源码,直接从源码开始揭开栈水位的神秘面纱。由于关于栈水位的文档比较少,笔者这篇博客应该算是第一篇可以将栈水位讲述的相对清楚的资料,所以在看源码之前,笔者先简单概括下栈水位解决的问题和功能:
一.栈水位的产生的背景和实现的功能
以往的并发垃圾回收器包括jdk16之前的ZGC在标记GCROOT集合的时候都需要在初次标记和初始迁移阶段扫描并标记根集合(GCROOT),这个过程是需要进入全局安全点完成的并且是STW的。因为GCROOT主要是在线程栈中,如果在进行标记的时候线程还在执行,那么在标记过程中就不能保证所有对象处于同一时刻的状态。
而实现将扫描和标记根集合的任务变成并发的技术就是今天要讲的主角——栈水位。其实现是依赖于在全局安全点设置或修改一个统一的栈水位线,通过水位线来达到记录当前所有栈帧的快照的效果,这样在扫描和标记根集合的工作就可以并发执行。因为不论线程在执行过程中栈如何出栈和入栈,只要保证扫描水位线以上(假设栈是向下增长的)安全的栈帧即可保证扫描的对象处于同一时刻。当然有时候栈帧出栈的时候会高于水位线,那么此时jvm会对水位线进行修复,保证水位线的正确性。
二.栈水位与安全点
光是看文字可能还是不能完全理解水位线的技术内幕,想要真正的理解还得靠源码,既然刚刚提到了zgc是在安全点插入的水位线,那么我们就先从安全点的源码切入看下(一下源码源自jdk17):
//全局安全点
void SafepointSynchronize::begin() {
//省略一些代码
......
// 安全点进行清理工作
do_cleanup_tasks();
post_safepoint_cleanup_event(cleanup_event, _safepoint_id);
post_safepoint_begin_event(begin_event, _safepoint_id, nof_threads, _current_jni_active_count);
SafepointTracing::cleanup();
}
void SafepointSynchronize::do_cleanup_tasks() {
TraceTime timer("safepoint cleanup tasks", TRACETIME_LOG(Info, safepoint, cleanup));
CollectedHeap* heap = Universe::heap();
WorkGang* cleanup_workers = heap->safepoint_workers();
//并行或串行执行清理任务
if (cleanup_workers != NULL) {
// Parallel cleanup using GC provided thread pool.
uint num_cleanup_workers = cleanup_workers->active_workers();
ParallelSPCleanupTask cleanup(num_cleanup_workers);
cleanup_workers->run_task(&cleanup);
} else {
// Serial cleanup using VMThread.
ParallelSPCleanupTask cleanup(1);
cleanup.work(0);
}
......
}
//ParallelSPCleanupTask任务类的work方法
//可以看到这里在全局安全点会执行重新调整字符串常量表和符号引用表等操作,这里就不展开讲了
void work(uint worker_id) {
//如果开启栈水位会执行这个分支————懒处理GCROOT
if (_subtasks.try_claim_task(SafepointSynchronize::SAFEPOINT_CLEANUP_LAZY_ROOT_PROCESSING)) {
if (_do_lazy_roots) {
Tracer t("lazy partial thread root processing");
//主要逻辑在这个闭包里
ParallelSPCleanupThreadClosure cl;
//这个方法会在每个线程(java线程和非java线程)中执行闭包
Threads::threads_do(&cl);
}
}
if (_subtasks.try_claim_task(SafepointSynchronize::SAFEPOINT_CLEANUP_UPDATE_INLINE_CACHES)) {
Tracer t("updating inline caches");
InlineCacheBuffer::update_inline_caches();
}
if (_subtasks.try_claim_task(SafepointSynchronize::SAFEPOINT_CLEANUP_COMPILATION_POLICY)) {
Tracer t("compilation policy safepoint handler");
CompilationPolicy::do_safepoint_work();
}
if (_subtasks.try_claim_task(SafepointSynchronize::SAFEPOINT_CLEANUP_SYMBOL_TABLE_REHASH)) {
if (SymbolTable::needs_rehashing()) {
Tracer t("rehashing symbol table");
SymbolTable::rehash_table();
}
}
if (_subtasks.try_claim_task(SafepointSynchronize::SAFEPOINT_CLEANUP_STRING_TABLE_REHASH)) {
if (StringTable::needs_rehashing()) {
Tracer t("rehashing string table");
StringTable::rehash_table();
}
}
if (_subtasks.try_claim_task(SafepointSynchronize::SAFEPOINT_CLEANUP_SYSTEM_DICTIONARY_RESIZE)) {
if (Dictionary::does_any_dictionary_needs_resizing()) {
Tracer t("resizing system dictionaries");
ClassLoaderDataGraph::resize_dictionaries();
}
}
if (_subtasks.try_claim_task(SafepointSynchronize::SAFEPOINT_CLEANUP_REQUEST_OOPSTORAGE_CLEANUP)) {
OopStorage::trigger_cleanup_if_needed();
}
_subtasks.all_tasks_claimed();
}
//Threads::threads_do会分别遍历java线程和非java线程
void Threads::threads_do(ThreadClosure* tc) {
java_threads_do(tc);
non_java_threads_do(tc);
}
让我们把视线聚焦到这个ParallelSPCleanupThreadClosure闭包:
//ParallelSPCleanupThreadClosure的do_thread方法
void do_thread(Thread* thread) {
//如果是java线程
if (thread->is_Java_thread()) {
//到此引出了我们的栈水位集合类我们一起看下这个方法
//第一个参数是java线程,第二个参数是一个枚举值
StackWatermarkSet::start_processing(thread->as_Java_thread(), StackWatermarkKind::gc);
}
}
void StackWatermarkSet::start_processing(JavaThread* jt, StackWatermarkKind kind) {
verify_processing_context();
//这里会根据线程和栈水位类型(一个枚举值)获取线程的栈水位
//这里我们先看下这个方法,探究下栈水位是从哪里获取的
StackWatermark* watermark = get(jt, kind);
if (watermark != NULL) {
//后面我们在讲这个方法
watermark->start_processing();
}
}先看下get()方法:
inline StackWatermark* StackWatermarkSet::get(JavaThread* jt, StackWatermarkKind kind) {
//可以看到获取一个栈水位链表然后进行遍历,我们看下head()方法
for (StackWatermark* stack_watermark = head(jt); stack_watermark != NULL; stack_watermark = stack_watermark->next()) {
if (stack_watermark->kind() == kind) {
return stack_watermark;
}
}
return NULL;
}
//这里可以清楚的看到整个链表是保存在java线程中的
StackWatermark* StackWatermarkSet::head(JavaThread* jt) {
return jt->stack_watermarks()->_head;
}搞清楚了栈水位对象保存在哪里,我们继续看刚刚提到的方法watermark->start_processing() :
//这个方法是开始执行栈水位
void StackWatermark::start_processing() {
//先判断是否已经执行过
if (!processing_started_acquire()) {
MutexLocker ml(&_lock, Mutex::_no_safepoint_check_flag);
//如果没有执行过则开始执行
if (!processing_started()) {
start_processing_impl(NULL /* context */);
}
}
}
//真正的执行方法在ZGC中调用的是ZStackWatermark这个子类的方法
void ZStackWatermark::start_processing_impl(void* context) {
//这是验证方法,我们忽略
ZVerify::verify_thread_head_bad(_jt);
//执行线程栈中非帧的部分
//第一个参数是遍历对象的闭包类型是ZLoadBarrierOopClosure
//第二个参数是遍历代码块的闭包类型是ZOnStackCodeBlobClosure
//非帧部分包括异常信息,逆优化的MonitorChunk等部分,我们这里就先不展开了
_jt->oops_do_no_frames(closure_from_context(context), &_cb_cl);
//处理ThreadLocal中看不见的root,第二个参数是处理的闭包方法,这里我们先不展开
ZThreadLocalData::do_invisible_root(_jt, ZBarrier::load_barrier_on_invisible_root_oop_field);
//这是验证方法,我们忽略
ZVerify::verify_thread_frames_bad(_jt);
//更新localData的坏标记
ZThreadLocalData::set_address_bad_mask(_jt, ZAddressBadMask);
//这里是tlab处理逻辑
if (ZGlobalPhase == ZPhaseMark) {
ZThreadLocalAllocBuffer::retire(_jt, &_stats);
} else {
ZThreadLocalAllocBuffer::remap(_jt);
}
//开始在并发线程中处理
StackWatermark::start_processing_impl(context);
}
void StackWatermark::start_processing_impl(void* context) {
delete _iterator;
//判断java线程是否有帧
if (_jt->has_last_Java_frame()) {
//封装迭代器,处理三帧分别是:
//1.被调用者帧
//2.调用者帧
//3.额外一帧
_iterator = new StackWatermarkFramesIterator(*this);
_iterator->process_one(context);
_iterator->process_one(context);
_iterator->process_one(context);
} else {
_iterator = NULL;
}
//更新水位线
update_watermark();
}这里的我们先看下更新水位线方法的逻辑,后面再重点看执行帧的方法。
//可以看到这个方法主要是修改了两个变量
//1._watermark 水位线
//2._state epoch_id 可以理解为当前水位线的版本号
void StackWatermark::update_watermark() {
//判断是否还有帧
if (_iterator != NULL && _iterator->has_next()) {
//这里可以看到迭代器被调整到了被调用者帧的位置,即实际的水位线是在被调用者帧这里
Atomic::release_store(&_watermark, _iterator->callee());
//若还有帧则更新水位线到被调用者位置和版本号
Atomic::release_store(&_state, StackWatermarkState::create(epoch_id(), false /* is_done */));
} else {
//如果没有则水位线更新成0
Atomic::release_store(&_watermark, uintptr_t(0));
Atomic::release_store(&_state, StackWatermarkState::create(epoch_id(), true /* is_done */));
}
}可以看到zgc在安全点设置的全局水位线由两个变量构成——分别是watermark和state。watermark则是我们的水位线,可以看到其被设置到了被调用者帧这里,这里我们先留意一下,后面笔者会讲到。
然后我们重点看下刚刚提到的执行帧的方法:
//刚刚提到的_iterator->process_one(context)方法调用
void StackWatermarkFramesIterator::process_one(void* context) {
StackWatermarkProcessingMark swpm(Thread::current());
//判断是否有帧
while (has_next()) {
frame f = current();
uintptr_t sp = reinterpret_cast<uintptr_t>(f.sp());
//判断是否存在栈水位屏障,其实就是判断是解释帧或者编译帧
bool frame_has_barrier = StackWatermark::has_barrier(f);
//真正的执行方法
_owner.process(f, register_map(), context);
next();
if (frame_has_barrier) {
//如果存在屏障则更新调用者和被调用者
set_watermark(sp);
break;
}
}
}这里先解释下解释帧和编译帧:
1.解释帧:表示帧是通过jvm模板解释器创建的帧
2.编译帧:表示帧是通过即时编译器编译热点代码后生成的帧
我们先看下更新调用者和被调用者的方法,之后再看下执行帧的方法_owner.process():
//这个方法比较简单,主要是更新调用者和被调用者属性
void StackWatermarkFramesIterator::set_watermark(uintptr_t sp) {
if (!has_next()) {
return;
}
//如果不存在被调用者则当前帧为被调用者
if (_callee == 0) {
_callee = sp;
//如果不存在调用者则当前帧为调用者
} else if (_caller == 0) {
_caller = sp;
//否则调用者成为被调用者,调用者为当前帧
} else {
_callee = _caller;
_caller = sp;
}
}这里稍微解释下主要是表现对栈帧进行执行的时候,因为假设栈是向上增长,那么曾经的被调用者后入栈,所以再执行帧的时候,曾经的调用者会变成被调用者,当前帧则变成调用者,如图:

我们继续看下执行帧的方法_owner.process(),这里owner是StackWatermark类型:
//ZStackWatermark是StackWatermark的实现类
void ZStackWatermark::process(const frame& fr, RegisterMap& register_map, void* context) {
ZVerify::verify_frame_bad(fr, register_map);
//这个方法是对栈帧中的对象进行遍历,这里两个闭包和刚刚ZStackWatermark::start_processing_impl方法中的一样
//第一个参数是遍历对象的闭包方法,由于context是null所以类型是ZLoadBarrierOopClosure
//第二个参数是遍历代码块的闭包方法,类型是ZOnStackCodeBlobClosure
fr.oops_do(closure_from_context(context), &_cb_cl, ®ister_map, DerivedPointerIterationMode::_directly);
}
//先看下遍历对象的方法
void frame::oops_do(OopClosure* f, CodeBlobClosure* cf, const RegisterMap* map,
DerivedPointerIterationMode derived_mode) const {
oops_do_internal(f, cf, map, true, derived_mode);
}
void frame::oops_do_internal(OopClosure* f, CodeBlobClosure* cf, const RegisterMap* map,
bool use_interpreter_oop_map_cache, DerivedPointerIterationMode derived_mode) const {
......
//判断是解释帧,(本次案例都会是解释帧,我们直接看这个分支的代码)
if (is_interpreted_frame()) {
//这里传入的是第一个遍历的闭包方法,类型是ZLoadBarrierOopClosure
oops_interpreted_do(f, map, use_interpreter_oop_map_cache);
} else if (is_entry_frame()) {
oops_entry_do(f, map);
} else if (is_optimized_entry_frame()) {
_cb->as_optimized_entry_blob()->oops_do(f, *this);
} else if (CodeCache::contains(pc())) {
oops_code_blob_do(f, cf, map, derived_mode);
} else {
ShouldNotReachHere();
}
}
//直接看处理解释帧方法
void frame::oops_interpreted_do(OopClosure* f, const RegisterMap* map, bool query_oop_map_cache) const {
Thread *thread = Thread::current();
methodHandle m (thread, interpreter_frame_method());
jint bci = interpreter_frame_bci();
//先对monitor进行处理(这里是处理解释帧的monitor),再之前我们看到有处理非帧的逻辑中也有处理monitor的部分
//那部分是逆优化的帧的monitor与这里不同
for (
BasicObjectLock* current = interpreter_frame_monitor_end();
current < interpreter_frame_monitor_begin();
current = next_monitor_in_interpreter_frame(current)
) {
current->oops_do(f);
}
//如果是native方法,则处理temp oop(temp oop是本地帧独有的一个结构,这里就不展开了)
if (m->is_native()) {
f->do_oop(interpreter_frame_temp_oop_addr());
}
//这里用mirror地址替代method指针作为一个GCROOT.处理mirror
//这里的f其实就是用提到ZLoadBarrierOopClosure闭包进行遍历
f->do_oop(interpreter_frame_mirror_addr());
int max_locals = m->is_native() ? m->size_of_parameters() : m->max_locals();
Symbol* signature = NULL;
bool has_receiver = false;
//如果是调用字节码处,我们要处理入参(由于篇幅,这里我们也不展开)
if (!m->is_native()) {
Bytecode_invoke call = Bytecode_invoke_check(m, bci);
if (call.is_valid()) {
signature = call.signature();
has_receiver = call.has_receiver();
if (map->include_argument_oops() &&
interpreter_frame_expression_stack_size() > 0) {
ResourceMark rm(thread); // is this right ???
oops_interpreted_arguments_do(signature, has_receiver, f);
}
}
}
//处理操作数栈和局部变量,我们重点看下这个部分和处理的闭包
//这个闭包后面还会提到,其第三个参数是刚刚提到的ZLoadBarrierOopClosure闭包
InterpreterFrameClosure blk(this, max_locals, m->max_stack(), f);
//创建一个临时oopMap
InterpreterOopMap mask;
//这里是true
if (query_oop_map_cache) {
//这个方法的主要逻辑是将局部变量放到oopMap中,我们先看下这个方法
m->mask_for(bci, &mask);
} else {
OopMapCache::compute_one_oop_map(m, bci, &mask);
}
//遍历并处理刚刚创建的oopMap
mask.iterate_oop(&blk);
}
//更新oopMap,第二个参数是需要保存局部变量的oopMap
//这个方法执行完mask(也就是刚刚创建oopMap)中将会有所有的局部变量信息
void Method::mask_for(int bci, InterpreterOopMap* mask) {
methodHandle h_this(Thread::current(), this);
//如果处于GC时,则创建并更新oopMap
if (Universe::heap()->is_gc_active()) {
method_holder()->mask_for(h_this, bci, mask);
} else {
//这个方法是,如果不是处于GC时,则将局部变量保存到传入的InterpreterOopMap mask中
OopMapCache::compute_one_oop_map(h_this, bci, mask);
}
return;
}注:看到这里可能会有对于oopMap不熟悉的读者,这里我们简单介绍下oopMap——在枚举根节点时,为了避免扫描整个栈,在GC发生时,jvm抵达全局安全点会将局部变量的引用关系保存到oopMap中,这样在枚举根节点时就可以遍历递归每个栈帧的oopMap进行快速标记。oopMap主要是由一个叫bit_mask的位图,这里我们就不继续展开了
到这里,我们已经可以看出在jdk17中的全局安全点会先执行三帧,然后创建栈水位,而这里的”执行“其实主要就是扫描并标记三帧的GCROOT(当然还包括一些其他正常GC时处理帧的逻辑),缕清了这个过程,我们继续看下mask.iterate_oop(&blk)方法,这个方法的参数时刚刚我们创建的闭包:
//这个方法主要是遍历oopMap
void InterpreterOopMap::iterate_oop(OffsetClosure* oop_closure) const {
int n = number_of_entries();
int word_index = 0;
uintptr_t value = 0;
uintptr_t mask = 0;
for (int i = 0; i < n; i++, mask <<= bits_per_entry) {
if (mask == 0) {
//获取位图
value = bit_mask()[word_index++];
mask = 1;
}
//这里判断位图的值,关于位图的具体结构这里就不展开了
//我们简单理解,这里根据value判断引用是否存活,如果存活就用传入的闭包去找i偏移量的变量
if ((value & (mask << oop_bit_number)) != 0) oop_closure->offset_do(i);
}
}
//接着来看下闭包(我们刚刚创建的InterpreterFrameClosure )的处理方法
void offset_do(int offset) {
oop* addr;
//max_locals是最大局部变量偏移量,这里判断如果偏移量小于max_locals即是局部变量
if (offset < _max_locals) {
//找到对应的对象
addr = (oop*) _fr->interpreter_frame_local_at(offset);
//用处理闭包进行处理,_f是之前的ZLoadBarrierOopClosure类型闭包
_f->do_oop(addr);
} else {
//处理操作数栈的逻辑
addr = (oop*) _fr->interpreter_frame_expression_stack_at((offset - _max_locals));
bool in_stack;
if (frame::interpreter_frame_expression_stack_direction() > 0) {
in_stack = (intptr_t*)addr <= _fr->interpreter_frame_tos_address();
} else {
in_stack = (intptr_t*)addr >= _fr->interpreter_frame_tos_address();
}
if (in_stack) {
_f->do_oop(addr);
}
}
}我们看到最终都是用ZLoadBarrierOopClosure闭包去处理GCROOT的引用,聪明的读者已经猜到,这个闭包应该是关于对象的标记逻辑,让我们继续看下这个闭包的处理方法:
void ZLoadBarrierOopClosure::do_oop(oop* p) {
ZBarrier::load_barrier_on_oop_field(p);
}
//看过笔者之前介绍zgc的博客的读者到这里应该会很熟悉了
inline oop ZBarrier::load_barrier_on_oop_field(volatile oop* p) {
const oop o = Atomic::load(p);
//这里是zgc标准的修复指针的方法
return load_barrier_on_oop_field_preloaded(p, o);
}
inline oop ZBarrier::load_barrier_on_oop_field_preloaded(volatile oop* p, oop o) {
//这里is_good_or_null_fast_path与load_barrier_on_oop_slow_path是两个闭包
//我们结合barrier方法来一起看下
return barrier<is_good_or_null_fast_path, load_barrier_on_oop_slow_path>(p, o);
}
template <ZBarrierFastPath fast_path, ZBarrierSlowPath slow_path>
inline oop ZBarrier::barrier(volatile oop* p, oop o) {
const uintptr_t addr = ZOop::to_address(o);
//判断是否可以快速处理
if (fast_path(addr)) {
return ZOop::from_address(addr);
}
//如果不能快速处理则进入慢速处理逻辑
const uintptr_t good_addr = slow_path(addr);
if (p != NULL) {
self_heal<fast_path>(p, addr, good_addr);
}
return ZOop::from_address(good_addr);
}
//快速处理闭包,逻辑比较简单,就是判断是否是好指针
inline bool ZBarrier::is_good_or_null_fast_path(uintptr_t addr) {
return ZAddress::is_good_or_null(addr);
}
//慢速处理闭包,这里会判断是否处于迁移阶段,如果处于迁移阶段则进行迁移,如果不是迁移阶段则标记即对指针进行染色
uintptr_t ZBarrier::load_barrier_on_oop_slow_path(uintptr_t addr) {
return relocate_or_mark(addr);
}
//笔者之前的博客中已经有这部分代码解析,这里就先不展开了
uintptr_t ZBarrier::relocate_or_mark(uintptr_t addr) {
return during_relocate() ? relocate(addr) : mark<AnyThread, Follow, Strong, Publish>(addr);
}
三.小结
到这里,我们回顾下之前看过的代码,我们又可以对栈水位进行更详细和准确的解释:栈水位本质上是一个用于标记栈帧是否安全的全局变量,再全局安全点jvm会首先对所有的java线程栈执行三个栈帧,执行的过程主要是对GCROOT指针的标记和修复,然后在第三帧后面插入我们的全局变量即栈水位。这样在后续GC阶段,我们就可以根据栈水位进行并发的GCROOT扫描和标记,因为水位线以上(假设栈是向下增长)的栈帧是可以安全扫描且线程还未执行的,当然在后续执行过程中线程若执行的过程中超过水位线,则会对水位线进行修复。
笔者当时得出这个结论后,又对两个问题有了兴趣,分别是:
1.为什么要先执行三帧 2.执行过程中水位线是怎么变化修复的
我们先来看下第一个问题,为什么要执行三帧?
要回答这个问题我们先来看看这三帧分别是什么,这三帧分别被jvm称做是 1.被调用者帧 2.调用者帧 3.额外帧
之前笔者提到过水位线其实是被记录在被调用者帧位置的,如图,我们可以看到至始至终水位线以上的两帧都是被处理过的,即调用者和被调用者帧,这样的好处是被调用者帧可以在执行的时候总是能直接从调用者帧读取状态而不需要额外的屏障去处理,这样可以简化由调用者传递,被调用者使用的参数使之可以自由访问。额外一帧的原因是GC可能与栈帧展开(异常发生时会进行栈帧展开)同时发生,这会发生在顶部帧展开前,所以需要我们提前额外执行一帧,保证展开的时候帧时安全的。
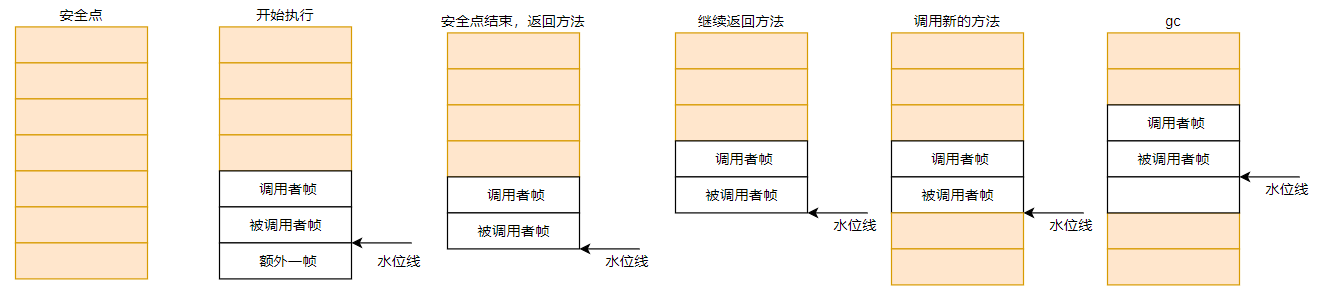
关于第二个问题,其实涉及到jvm的走栈逻辑了,通过上图我们也可以看出,线程在执行过程中如果超过水位线,则会对水位线进行修复,并执行一帧。这里还会涉及到jvm的模板帧和编译帧会不同的处理,这部分的代码比较多笔者虽然也已经整理完毕,但是由于篇幅有限,本篇博客就分析到这里。关于zgc对水位线的修复源码解析,笔者将会在后续的博客中放出。
最后感谢大家收看,本博客将持续分析zgc相关源码,欢迎大家持续关注。


