
1 介绍
在分布式系统中,由于涉及到多个不同业务module的交互,以及高并发的场景。我们需要系统能够生成一个跨业务module的全网唯一序列号,来保证我们业务操作的独立性和唯一性。
在常见的业务场景中,比如全局订单Id,唯一标识的支付编号等,都需要这个来保证。
那生成ID都有哪些解决方案呢?特别是在复杂的分布式系统业务场景中,我们应该采用哪种解决方案来实现这个唯一序列呢?
一般来说,这个唯一序号有如下几种特征:
-
全局唯一性:确保生成的序列是全局唯一的,不可重复。
-
有序性:确保生成的ID值对于某个用户或者业务是按一定的数字有序递增的。
-
高可用性:确保生成ID功能的高可用,能够承接较大峰值,能够保证序列生成的有效性(不重复且有序)。
-
带时间标记:ID中有时间片段组成,可是清晰识别出操作的时间。
下面是业内几种常见的分布式唯一序列生成方案,我们一一来介绍下。
2 数据库自增
数据库主键设置自增序号 auto_increment,可以按照一定的趋势自增,保证主键ID的唯一性。
这个方案简单易操作,优点是明显、可控。
但由于它是在数据库的单表上进行操作,对数据库性能依赖比较明显,高并发下的压力也很大。所以不是唯一ID生成的最佳方法。
1 create table `t_generator_id` 2 ( 3 `id` bigint(20) not null auto_increment, -- 表示自增列 4 -- 其他字段信息 5 )
3 系统时间毫秒数
我们可以使用当前系统时间精确到毫秒数(或者时间戳)+业务属性+用户属性+随机数+...等参数组合形式来确保ID的唯一性,缺点是ID的有序性难以保证,如果对有序性由强需求的业务不建议使用。
类似京东淘宝等电商的订单号生成。因为订单号和用户id在业务上的区别,订单号尽可能要多些冗余的业务信息,比如
滴滴:时间+起点编号+车牌号 ; 淘宝订单:时间戳+用户ID,类似滴滴订单的唯一序号如下:
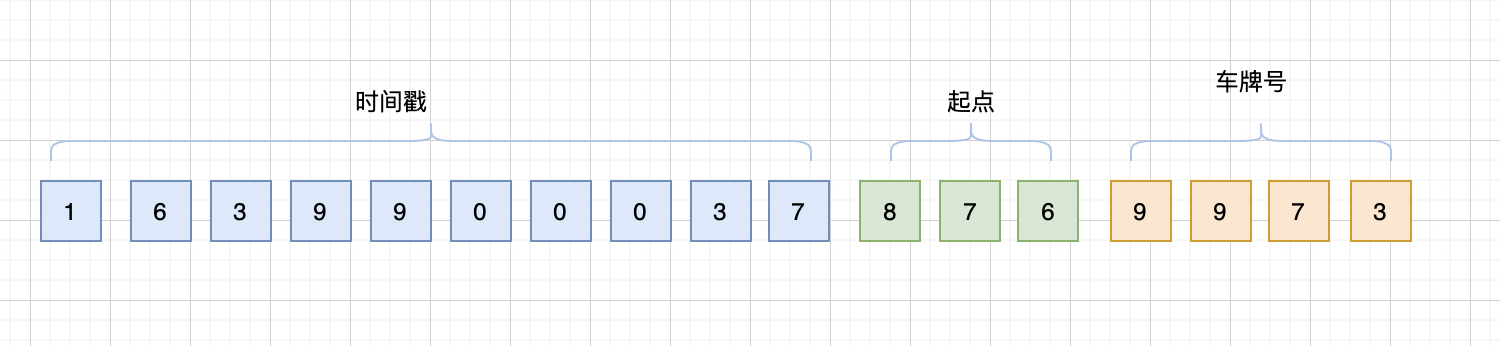
4 UUID(GUID)
Java自带的生成UUID的方式(.Net体系下也有GUID可以对应),生成的是Length=32的16进制格式的字符串,如果回退为byte数组共16个byte元素,即UUID是一个128bit长的数字,一般用16进制表示。
可以保证唯一性,但缺点是它不包含时间标识、业务数据可读性太差了,而且也不能ID的有序递增。优点生成方式,简单,高效,一般业务系统中比较少用。
5 批量预生成ID
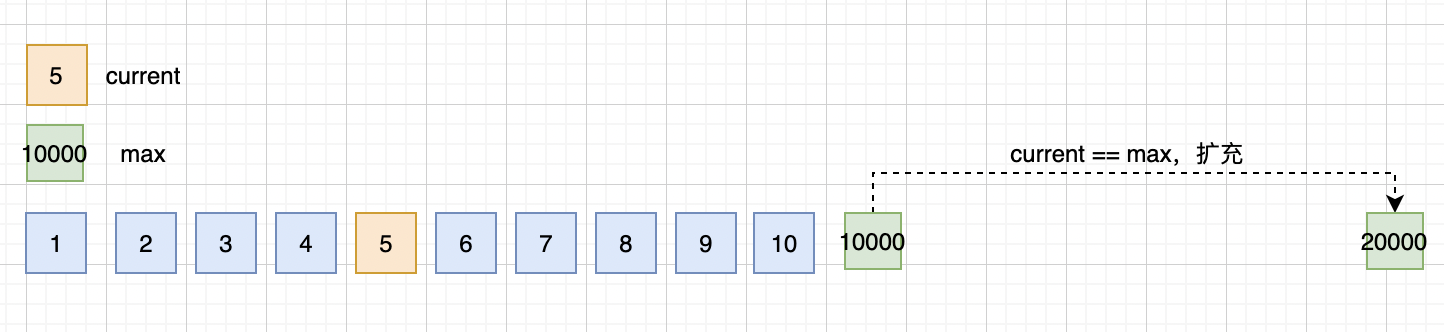
1、在内存(缓存)中,按需批量生成N个ID,并将最大ID值记录到数据库中。比如生成 1~10000,把max=10000持久化到数据库中,内存中记录的是current=1和max=10000。
2、所有的使用都在内存中进行,每消耗一次序号,current + 1。
3、当current==max的时候,重复第一个步骤,再次批量生成 10001~20000的值,并将数据库中的max改成20000。
优点是避免了每次生成ID都要访问数据库并带来压力。
缺点是只能是单点服务,如果服务重启势必会造成ID丢失不连续的情况,而且这种方式也不利于水平扩展。
6 Redis生成唯一序列
Redis可以使用简易的String类型,它的 incr/decr key 语法,支持高效快速的增减值,能够保证生成的ID肯定是唯一有序的。
这种方式不依赖数据库持久化,速度快,算是比较好的办法了。但系统中引入Redis这一中间件,无形中增加维护成本。在超大流量、超高并发的情况下,单实例Redis还是无法满足的,需要横向扩展Redis集群来进行支撑。
1 incr/decr key // 自增减 1 2 incrby/decrby key increment // 自增减指定数值 3 incrbyfloat/decrbyfloat key increment // 自增减浮点数
还可以利用像Zookeeper中的znode数据版本来生成序列号,及MongoDB的ObjectId等,但是性能不如Redis,不是很推荐。
7 snowflake算法
Twitter在把存储系统从MySQL迁移到Cassandra的过程中由于Cassandra没有顺序ID生成机制,于是自己开发了一套全局唯一ID生成服务:Snowflake。
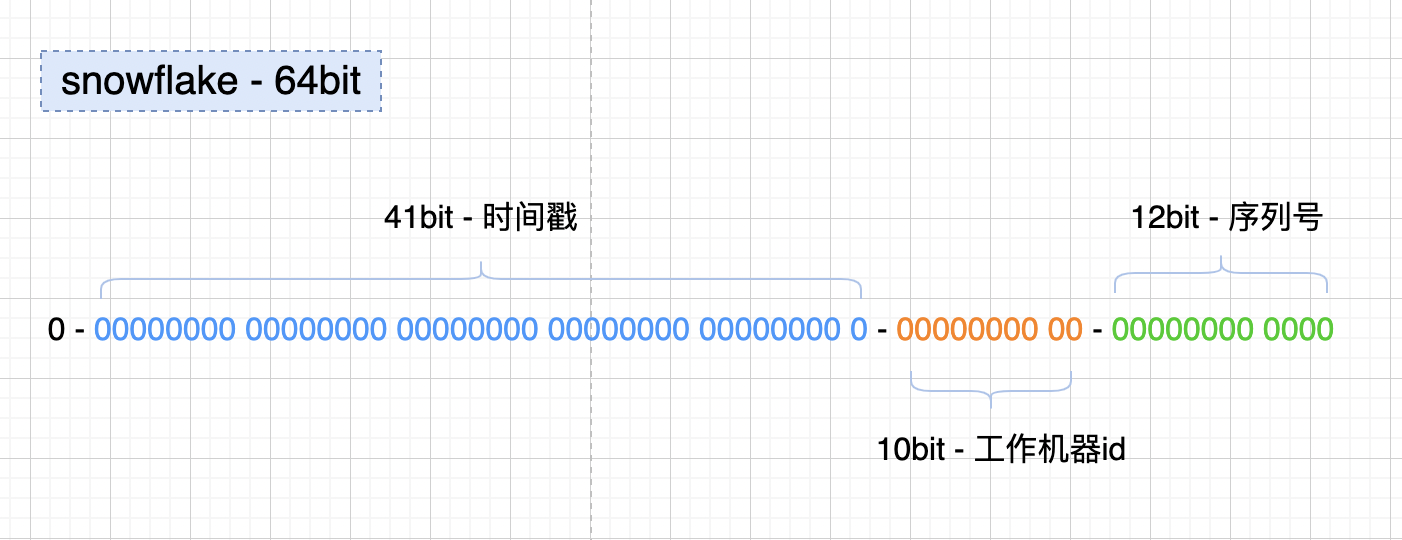
如上图的所示,Twitter的snowflake算法下面几部分组成:
-
41位的时间序列,精确到毫秒,可以使用69年
-
10位的机器标识,最多支持部署1024个节点
-
12位的序列号,支持每个节点每毫秒产生4096个ID序号,最高位是符号位始终为0。
这种方案性能好,在单机上是递增的,但是由于涉及到分布式环境,每台机器上的时钟不可能完全同步,也许有时候也会出现不是全局递增的情况。
而且这个项目在2010就停止维护了,但这个设计思路被很多厂家参考,应用于各个业务的ID生成器及变种。
8 UidGenerator
UidGenerator是百度开源的一款分布式高性能的唯一ID生成器,使用Java实现的, 基于Snowflake算法的唯一ID生成器。
在实现上, UidGenerator通过借用未来时间来解决sequence天然存在的并发限制; 采用RingBuffer来缓存已生成的UID, 并行化UID的生产和消费, 同时对CacheLine补齐,避免了由RingBuffer带来的硬件级「伪共享」问题. 最终单机QPS可达600万。
具体的GitHub地址如下:
https://github.com/baidu/uid-generator/blob/master/README.zh_cn.md
9 Leaf
Leaf是美团开源的分布式ID生成器,能保证全局唯一性、趋势递增、单调递增、信息安全,同时也需要依赖关系数据库、Zookeeper等中间件。
美团技术社区有详细的说明,同时也对分布式ID生成有一些比较好的分析和建议:
10 总结
个人觉得最好的是Redis方案和snowflake算法,无论是性能还是可用性程度上。另外各大厂也有自己的一些做法,比如百度的UidGenerator 和 美团的Leaf,
主要也是根据现有的方案进行优化和改造,达到比较契合他们自己业务的目标。

欢迎关注公众号【架构与思维】:撰稿者为bat、字节的几位高阶研发/架构。不做广告、不卖课、不要打赏,只分享优质技术。

