
深入分析G1垃圾收集器实现原理原创
1 与垃圾收集器有关的算法
在分析G1前先简单回顾一下与垃圾收集器相关的算法。通常所谓的垃圾收集器更多地是指跟踪垃圾收集器(Tracing Garbage Collection),而不是引用计数(Reference Counting )垃圾收集器。跟踪垃圾收集器采用可达性分析方法确定哪些对象要被回收,通常会选取一些对象作为GC Roots,如果对象能直接或间接地被GC Roots中的对象引用,则认为该对象可达(存活对象)不能被回收,否则该对象不可达(垃圾对象)要被回收。
1.1 三色标记算法
在确定内存中哪些对象是垃圾对象时,可以采用最简单的标记算法,即给内存中每个对象一个专门的标记位,被标记则认为是存活对象,否则是垃圾对象,然从GC Roots的对象集合开始递归遍历对象图,如果对象图中的对象能被GC Roots中的对象直接或简接引用则进行标记。理论上该算法可以确定内存中哪些对象是存活的,哪些对象是垃圾,但整个过程应用程序必须暂停,并且要处理所有的内存区域。
为了解决上面的问题,Dijkstra等人在On-the-Fly Garbage Collection: An Exercise in Cooperation 一文中提出了三色标记(Tri-color Marking)算法。像Go、JavaScript 、Java等语言在内存回收上都采用了三色标记算法的变种。
三色标记算法会创建白色、灰色、黑色三个集合,三个集合内分别只存储白色对象、灰色对象、黑色对象。白色对象,代表尚未开始标记的对象或已完成标记并确认为垃圾的对象;灰色集合,代表还在标记中的对象,即遍历对象图时已遍历到自己,但还未完成自己引用 对象的遍历;黑色对象,代表已完成标记并确认为存活的对象(正常情况下,对象标记的颜色变化只能白色变成灰色,灰色变成黑色)。起初黑色集合通常为空,灰色集合内为GC Roots直接引用的对象,其他对象均在白色集合内。一个对象任一时刻只能在白色、灰色、黑色三个集合中的某一个。通常三色标记算法的处理流程如下:
1、起初除GC Roots 外的其他对象全白色集合,将GC Roots直接引用的对象从白色集合内移到灰色集合。
2、从灰色集合取出一个灰色对象,依次处理该对象引用的对象。若其未引用任何对象,则直接将其移入黑色集合中;若其引用的对象在白色集合中则将其移入灰色集合,否则直接不处理,当该灰色对象引用的对象全处理完后,再将其移入黑色集合中。
3、重复第2步的流程直到灰色集合为空。
4、上面的步骤处理完后,GC Roots与黑色集合内的对象为存活对象,而白色集合内的对象为垃圾对象,最后要做的就是将白色集合内的垃圾对象清理。
下图展示了除GC Roots 另外有8个对象时,三色标记算法的处理流程。
-
起初除了GC Roots内的对象外,其他对象全在右则的白色集合中。
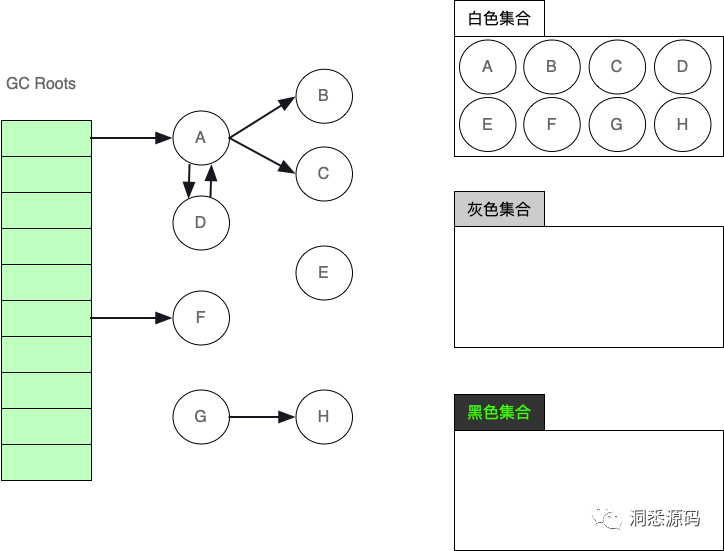
-
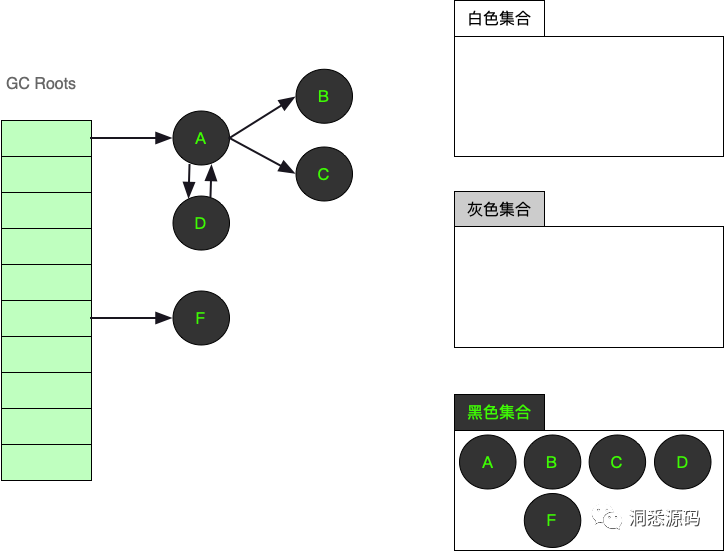
将GC Roots直接引用的对象从白色集合内移到灰色集合后,此时A对象与F对象已从白色集移到灰色集合。
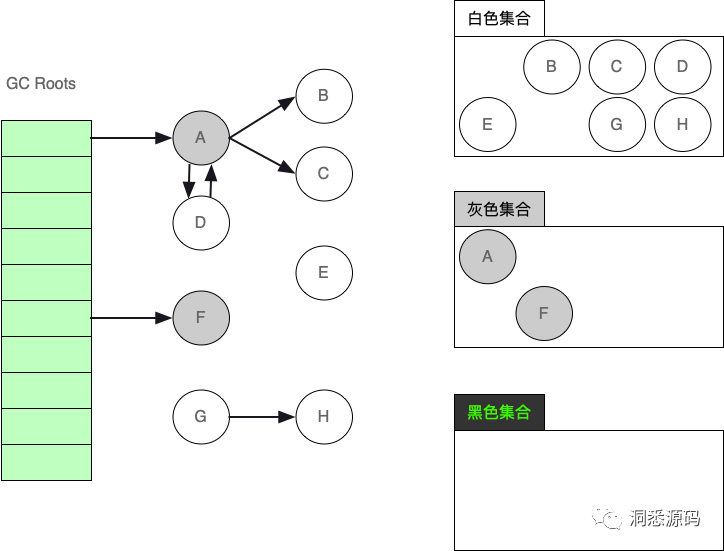
-
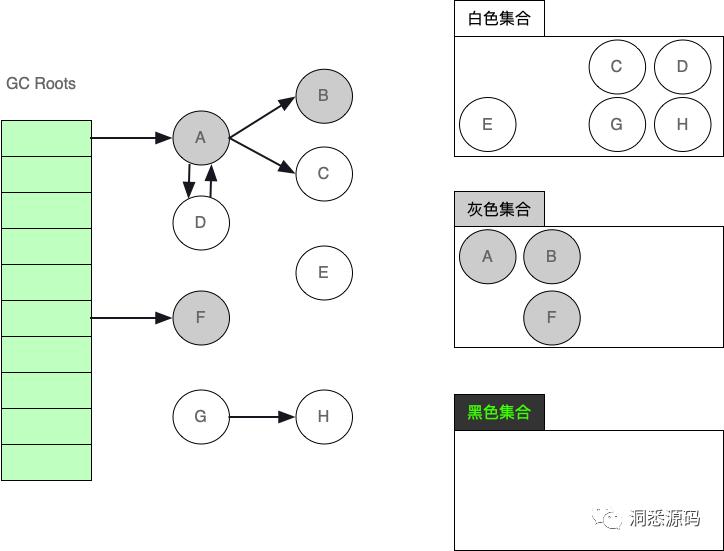
处理完灰色集合中的A对象引用的B对象后,此时B对象已从白色集移到灰色集合。
-
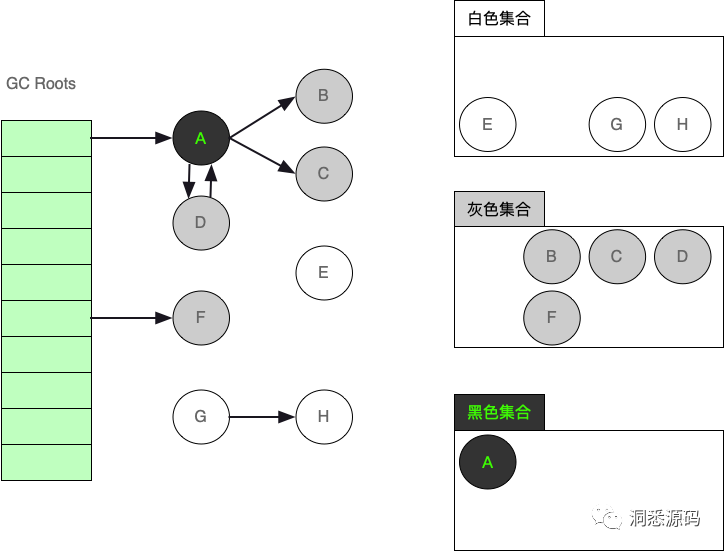
处理完灰色集合中的A对象引用的C对象与D对象后。此时A对象已从灰色集合移到黑色集合,C对象与D对象已从白色集移到灰色集合。
-
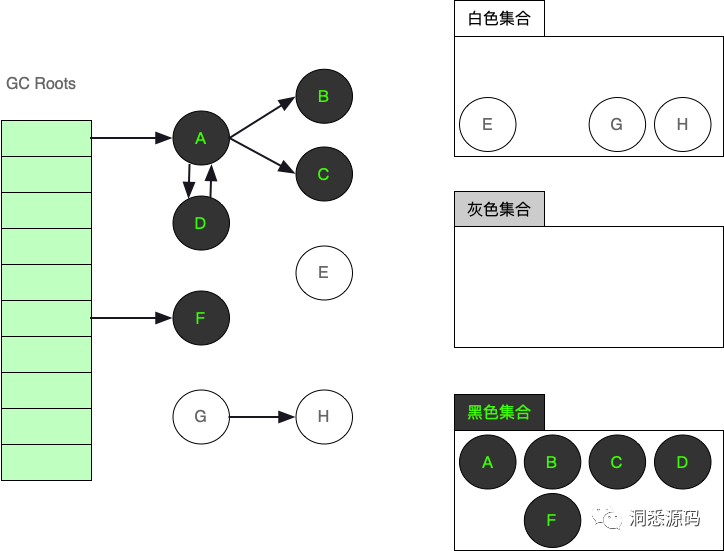
处理灰色集合中剩余的B对象、C对象、D对象与F对象后,B对象、C对象、D对象与F对象象已从灰色集移到黑色集合。
-
经历过上面的处理后灰色集合已为空,三色标记法标记阶段结束到达清理阶段,白色集合中的E对象、G对象与H对象被清理,最后结果如下图。
1.2 三色标记算法的不足
如果应用程序线程与三色标记算法的GC线程一起运行,则可能出现对象错标与漏标。所谓的对象错标是指原为是垃圾的对象被标记为黑色认为是存活的,这种情况的出现并不会引起应用程序的错误,只是会将垃圾收集的时间拖延到下一次垃圾回收。而对象漏标,则是原本要标记为黑色的对象,被遗漏了,没有被标记,最终导致该对象在白色集合中被垃圾回收集给回收掉;这种情况的一旦发生应用程序将出现未知的异常,这个异常可能是无关紧要的也可能是致命的。
以上面的例子来看看漏标是怎么发生的。
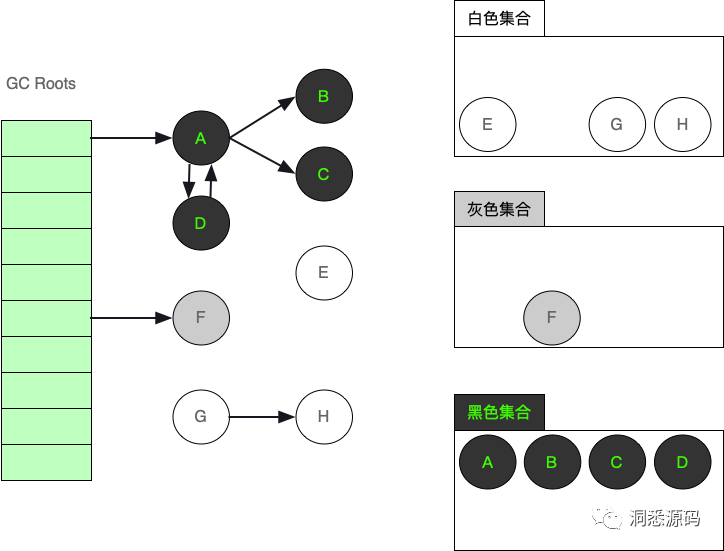
假设GC线程准备下一步标记工作前,对象的标记状态如上图。此时GC线程下一步将处理灰色集合中的F对象,由于F对象未引用任何对象其将直接移动到黑色集合中,整体个灰色集合为空标记结束。可是如果在GC线程还未完成F对象从灰色集合转移到黑色集合的操作时,应用线程正好增加了F对象对G对象的引用呢?
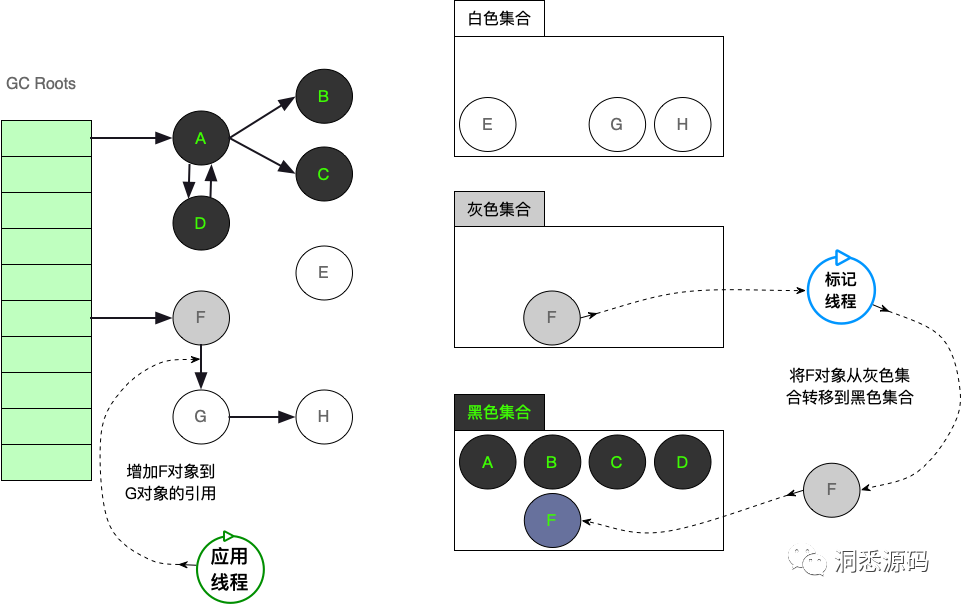
由于F对象已结束标记工作(实际GC线程已认为F对象是黑色的),F对象最终还是会从灰色集合成功地转移到黑色集合。而GC线程将无法感知应用程序新增加的F对象到G对象的引用,最终导致G对象的漏标。实际上产生漏标一定会满足下面两种情况的一种。
1、GC线程标记的过程中,应用线程增加黑色对象到白色对象的引用
2、GC线程标记的过程中,应用线程删除了灰色对象到白色对象的引用
上面的漏标示例实际是第一种情况,论文Uniprocessor Garbage Collection Techniques 的 3.2.1 Incremental approache小节将处理漏标时关注的点不同将GC分为 Snapshot-at-beginning collectors 与 Incremental update collectors。Snapshot-at-beginning collectors 关注于处理第一种情况,而Incremental update collectors关注于处理第二种情况,G1属于Snapshot-at-beginning collectors,而CMS属于Incremental update collectors。G1并发标记过程关注处理应用线程增加黑色对象到白色对象的引用,即当黑色对象新引用了白色对象时,便将这个黑色对象重新设置为灰(技术实现上采用pre-write barrier) ;而CMS发标记过程关注处理线程删除了灰色对象到白色对象的引用,即当灰色对象删除了白色对象的引用时,便将这个白色对象直接置灰(技术实现上采用post-write barrier)。
那具体采用何种技术手段处理上面的两种情况呢?其实也很简单,就是想办法让GC线程感知对象引用的变化,即所谓的写屏障(write barrier)。这里的所说的写屏障并不是硬件层面的写屏障,而是软件层的写屏障,其实质可理解为在引用赋值这个写操作前加一个切面,根据切点加入时机不同又可分为 pre-write barrier 与post-write barrier,下面是G1中采用的写屏障的伪代码实现(来源于[HotSpot VM] 请教G1算法的原理 )。
void oop_field_store(oop* field, oop new_value) {
pre_write_barrier(field); // pre-write barrier: for maintaining SATB invariant
*field = new_value; // the actual store
post_write_barrier(field, new_value); // post-write barrier: for tracking cross-region reference
}1.3 对象的清除实现方式
当对象标记结束后,便可以清除对象。而在具体实现时可以采用三种方式标记清除、标记复制、标记压缩算法。标记清除最为简单与高效,其直接将那些垃圾对象清除,但这也带来了内存碎片的问题,同时对象分配时也不得不采用空闲空间列表算法而不能采用高效的指针碰撞算法。标记复制算法通常要额外占用50%的空间,其实现是一直用一半内存存储对象,而另一半内存置空,当回收垃圾时,将已使用空间中仍存活的对象直接复制到置空的那段内存中,然后直接置空之前使用的那半内存。标记压缩算法,兼顾标记清除与标记复制算法的优点,在回收垃圾后会对存活对象进行相应的移动,尽量将碎片化的内存空间进行压缩。
2 分代垃圾收集器
在分析G1垃圾收集器之前有必要先简单回顾一下HotSpot VM中的其他垃圾收集器。在G1出现之前HotSpot VM中的其他垃圾收集器都是基于新生代与年老代进行垃圾回收的,这些垃圾回收集器统称为分代垃圾。而G1则是兼顾分代与分区的垃圾收集器。
2.1 分代垃圾收集器垃圾收集过程
分代垃圾收集器将Heap划分为新生代(Young Generation)与年老代 (Old Generation),在JDK1.8 之前还有永久代(Permanent Generation)的概念。新生代又被进一步划分为Eden、From Space 、To Space,其中 From Space 与 To Space 大小相等又称作Survivor Spaces。
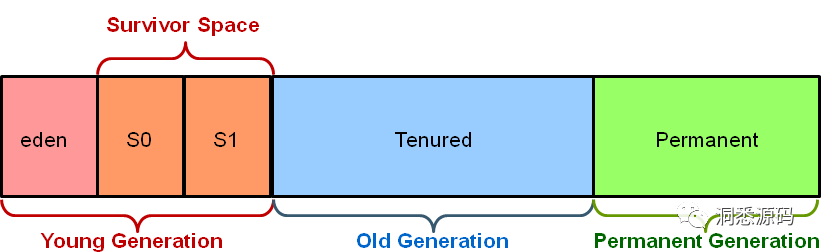
Heap被划分为新生代与年老代是基于弱分代假设的,在java应用程序与其他应用程序中都可以观测到弱分代假设的现象。
1、大多数分配的对象不会被长期引用(被认为是存活的)即他们很年轻就死去。
2、老对象很少持有来自新对象的引用。
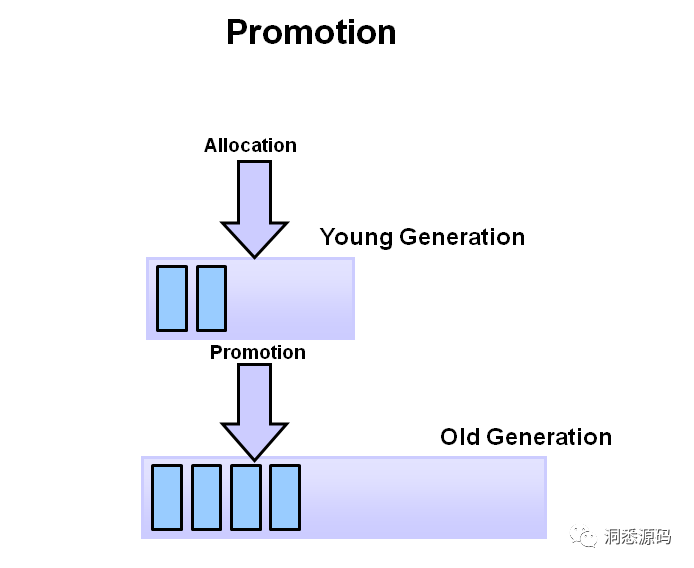
新生代垃圾回收相对频繁,且利用的算法高效快速,因为年轻代空间通常很小并且可能包含许多不再被引用的对象。而年老代垃圾回收频率则相对较低,但由于年老代占用内存相对更多,通常老代垃圾回收将更加耗时。新生代与年老代分别存储不同年龄的对象,通常刚分配内存的对象被存储在新生代,每经过一次垃圾回收如果对象还存活其年龄将加1,当经过多轮垃圾回收后如果对象的年龄超过了MaxTenuringThreshold值,该对象将晋升到年老代。
由于新生代垃圾回收相对更加频繁,新生代垃圾回收更加关注垃圾回收的时效性,通常会采用复制算法或标记清除算法处理垃圾回收。年老代占用内存相对更大,而垃圾回收频繁较低,年老代垃圾回收更加关注垃圾回收的空间性,即垃圾回收后能否释放更多连续的内存,通常会采用压缩算法处理垃圾回收。
现在来简单看看对象如何在Eden、Survivor与Old Generation之间进行分配与转移的。
-
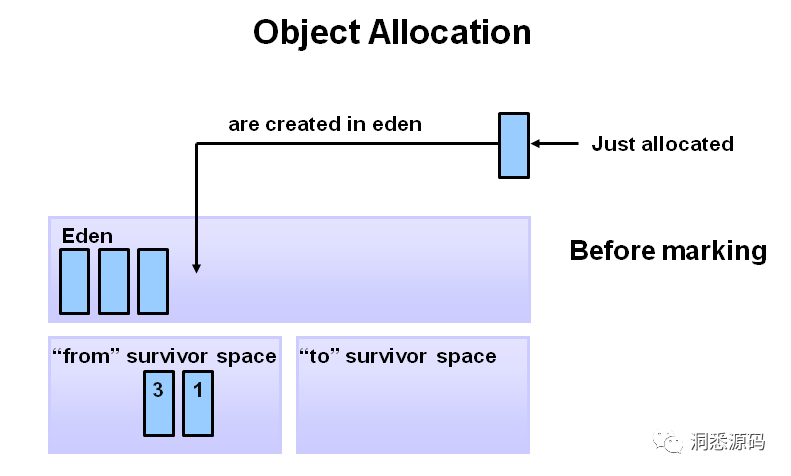
任何新对象都被分配到新生代的Eden空间,当Eden区域无法容纳新对象时,会触发一次Young GC。最开始时两个Survivor空间都是空(下图是已经过若干次GC的情况)。
-
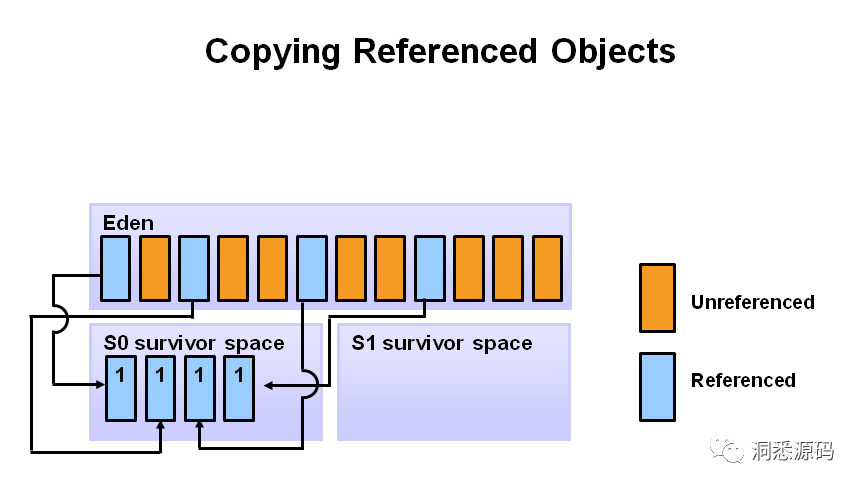
Young GC 过程中Eden空间仍被引用的对象(存活对象)会被复制到第一个Survivor空间(S0 Survivor Space)。而Eden 空间未被引用的对象将被直接删除。经历过一次Young GC后仍存活的对象,其年龄都会增加1,下图S0 Survivor Space中的对象都只经历一次Young GC,全被标记为1。
-
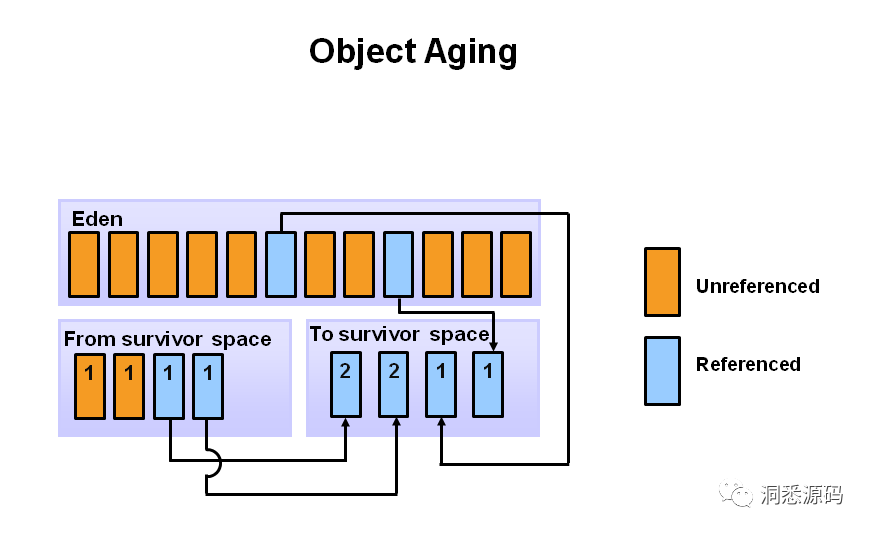
下一次Young GC 中仍被引用的对象(存活对象)会被复制到之前是空的Survivor空间(To survivor space ,实际是之前的S1 survivor space),Eden 空间未被引用的对象将被直接删除。之前的S0 suvivor space现在称为Form survivor space,其中依赖被引用的对象,被复现到了之前是空的Survivor空间(To survivor space ),Form survivor space 未被引用的对象将被直接删除。仍被引用的对象从Form survivor space复制到To survivor space后,其对象年龄将加1,表明该对象又经历了一次Young GC。
-
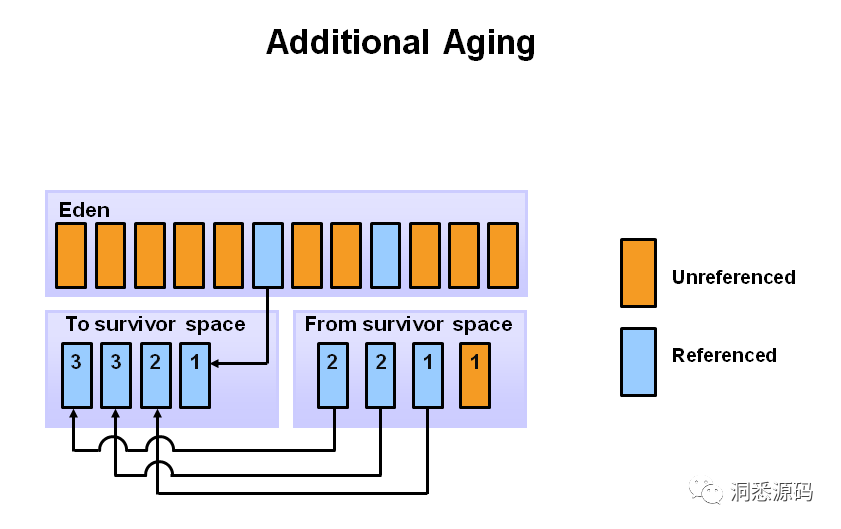
再下一次Young GC 中,会重复上面相同的过程。 但这时Survivor space 角色将进行交换,即From survivor space 变成 To survivor space,To survivor space 变成 From survivor space。这个交换的目的实际就是为了将已使用的Survivor space中仍存活的对象复制到被清空的Survivor space中。
-
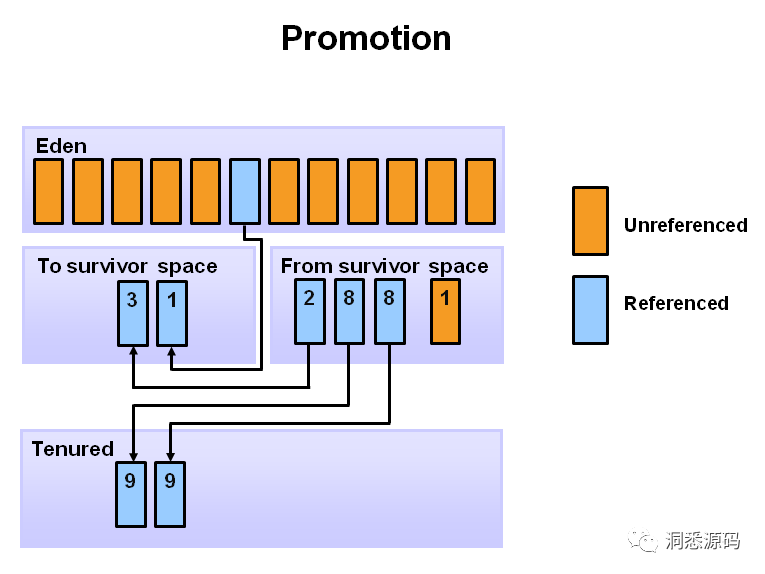
当经历很多次Young GC后新生代中仍存活的对象将会晋升(Promotion)到老年代。下图展示了当MaxTenuringThreshold参数为8 时,仍存活的对象从新生代的From survivor space晋升到老年代。
-
随着Young GC 的不断发生,新生代中仍存活的对象将不断地晋升到年老代。最终老年代将没有更多的空间容纳新晋升的对象,此时引发Major GC。
对象分配与晋升时何时会触发GC的详细流程图可以参考下图(参考了《码出高效:Java开发手册》第四章走进JVM中的图):
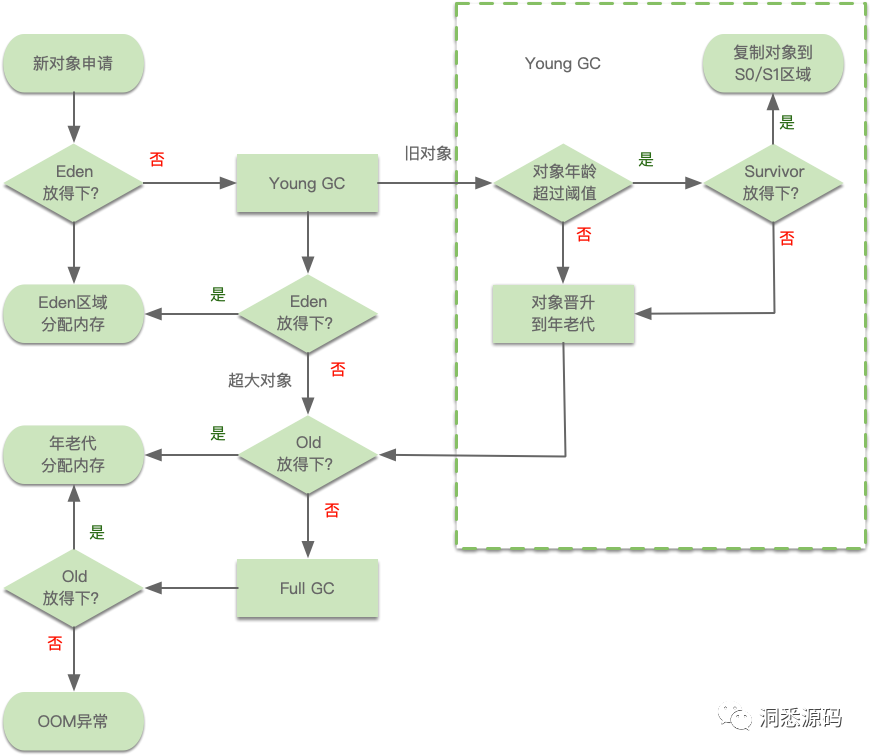
上图中没有描绘出 Thread Local Allocation Buffer (TLAB)与 Promotion Local Allocation Buffer (PLAB)的细节。此外上图中的Full GC可能让大家引起歧义,因为和Major GC太容易混淆了。实际JVM规范与垃圾收回相关的文献并没有给Full GC 与 Major GC作定义。一般Full GC认为是对新生代与老年代都进行垃圾回收,而Major GC则是专门针对年老代垃圾进行回收。那问题来了由Young GC 引发了老年代的垃圾回收,是叫Full GC好呢,还是Major GC好呢?个人认为可能Full GC更合适,这个大家可以不用过多纠结这个。实现纠结可以看看这两篇文章Minor GC vs Major GC vs Full GC 与 Major GC和Full GC的区别是什么?触发条件呢?。
上面只简单的描述了分代垃圾收集器垃圾收集的过程,实际垃圾收集器不仅负责了内存的回收工作,同样负责了对象的分配工作。更多的入门内容可以参考Memory Management in the Java HotSpot™ Virtual Machine 、Plumbr Handbook Java Garbage Collection。如果想再进一步了解垃圾回收相关的东西,还可以看看 《垃圾回收算法手册 自动内存管理的艺术》。
2.2 串行垃圾收集器
串行垃圾收集器(Serial GC)在进行垃圾回收时只有单个GC线程在进行垃圾回收。通常实现串行垃圾回收器更加简单,串行垃圾回收器内部不用维护复杂的数据结构,内存开销也更加小。但由于在STW(Stop The World)时只有单个GC线程在进行垃圾回收工作,垃圾回收的时间通常都会比较长,并且与应用程序占用的内存呈线性增长。该垃圾回收器比较适合Client端与嵌入设备等占用内存较小的场景。
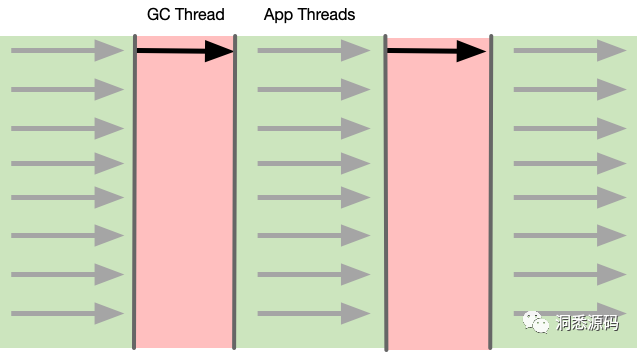
上图灰色箭头为应用线程,而黑色箭头为GC线程,应用线程在工作时通常都是多线程,而到过安全点后应用线程停止工作也叫SWT(Stop The World),串行垃圾回收器将开始一个GC线程完成垃圾回收工作。根据回收分代的不同串行垃圾回收器通常又分为Serial New 与 Serial Old,他们分别负责回收新生代(Young Generation)与年老代(Old Generation)。Serial New采用复制算法完成垃圾清理工作,Serial Old采用压缩算法完成垃圾清理工作。
2.3 并行垃圾收集器
很显然在多核CPU架构下面垃圾回收时,串行垃圾回收器不能利用多核CPU的优势。因此出行了并行垃圾收集器(Parallel GC),其与串行垃圾回收器最大的差别在于STW时,进行垃圾回收的线程由单个变成了多个。相对于串行垃圾回收器而言,由于垃圾回收的工作被分配给了多个线程,每次进行GC时整体时间将大大下降。并行垃圾回收器工作时,新生代与年老代都会采用线程并行处理垃圾回收工作。与串行垃圾回收器一样,并行垃圾回收器,根据回收分代的不同通常又分为ParNew 与 Parallel Old,他们分别负责回收新生代(Young Generation)与年老代(Old Generation)。同样新生代垃圾回收采用复制算法完成垃圾清理工作,年老代采用压缩算法完成垃圾清理工作。
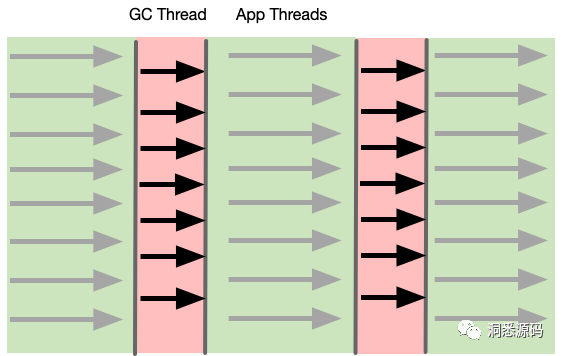
上图灰色箭头为应用线程,而黑色箭头为GC线程,并行垃圾回收器在STW时进行垃圾回收的线程相对于串行垃圾回收器而言变成了多个线程,并且这些线程同时进行垃圾回收工作。
2.4 并发标记清除垃圾收集器
并发标记清除垃圾收集器 (Concurrent Mark Sweep,CMS )是Hotspot VM上真正意义上的并发垃圾回收器。所谓并发(Concurrent)是指GC线程与应用线程一起工作,GC线程工作时不用STW,应用线程也在工作,而通常说的并行(Parallel)是指多个GC线程同时工作,清理垃圾。很多文献中将应用线程叫作Mutator Thread。
CMS 主要负责回收年老代垃圾,使用CMS时新生代垃圾收集工作通常由Serial New 或 ParNew 完成,默认新生代垃圾回收器为ParNew。CMS回收年老代垃圾时,将整体垃圾回收的过程拆分为多个阶段,并且大部分阶段与应用线程都是并发不会发生STW。CMS整体垃圾回收过程可分为初始化标记( Initial-mark)、并发标记(Concurrent Marking)、并发预清除(Concurrent Pre-cleaning)、重新标记(Remark)、并发清除(Concurrent Sweeping),初始化标记与重新标记都会发生STW,但通常时间都比较短。CMS早其版本中初始化标记与重新标记都是由单线程完成的,后期版本可以通过 -XX:+CMSParallelInitialMark 与 -XX:CMSParallelRemarkEnabled 分别将初始化标记与重新标记阶段指定为多线程。在CMS对年老代进行并发回收时很多可能新生代发生了Young GC,此时年老代垃圾回收将立刻中断,直到Young GC结束后又重新恢复。
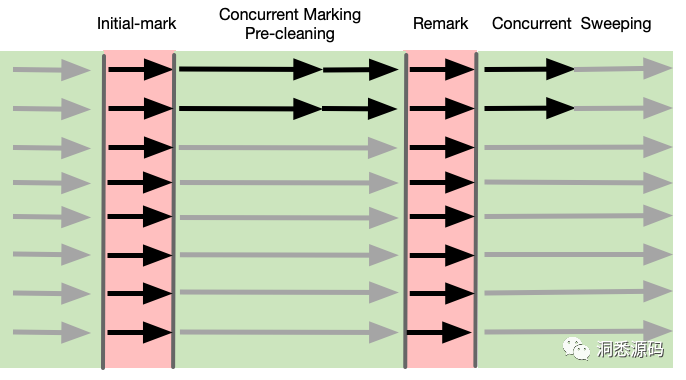
上图灰色箭头为应用线程,而黑色箭头为GC线程,CMS在Initial-mark阶段开启多个GC线程对GC Root进行标记,该阶段通常时间会比较短。CMS在并发标记与并发预清除阶段同会开启多线程工作,该阶段GC线程与应用线程并发工作。上图中Concurrent Making Pre-cleaning 阶段中长的黑色箭头代表处理Concurrent Making工作的GC线程,短的黑色箭头代表处理Pre-cleaning工作的线程。CMS在重新标记同样开启多个GC线程并且与Initial-mark阶段一样会SWT。CMS在并发清除阶段GC线程与应用线程并发工作。
CMS调优的一个关键问题是如何找出合适的时间让CMS开始并发工作,以便在应用程序耗尽可用的堆空间之前CMS完成所有的并发工作。通常会某次Young GC后开始CMS的并发工作,因为Young GC过后 CMS Initail-mark 要标记的对象通常会更少。CMS另外的一个问题是年老代内存碎片问题,由于CMS在回收年老代时采用了标记清除算法,标记清除算法相对于压缩算法而言执行效率更高,但由于清理垃圾时没有对内存的压缩整理,其不可避免地会出现内存碎片问题。下面二种情况会由于内存碎片问题最终导致concurrent mode failure。
1、Young GC 时,Eden区域存活的对象过大Survivor区域无法存放导致promotion failed,此时对象只能放入年老代,但由于内存碎片问题年老代同样放不下该对象,最后将发生concurrent mode failure,这时会引发Full GC,Full GC会回收整个Heap 空间导致STW时长骤增。
2、Young GC 时,Survivor 区域存活对象年龄超过了MaxTenuringThreshold,晋升到年老代,但由于内存碎片问题年老代放不下该对象,将发生concurrent mode failure,这时会引发Full GC。
更多关于CMS调优方面的实践可以参考这两篇文章 Java中9种常见的CMS GC问题分析与解决 与 Understanding GC pauses in JVM, HotSpot's CMS collector
下面是一张关于HotSpot VM 中垃圾回收器如何组合分别处理年轻代与年老代的经典图。上面部分的Serial New、ParNew、Parallel Scavenge 都是专门用于处理新生代垃圾收集器,下面部分的CMS、Serial Old、Parallel Old是专门用于处理年老代的垃圾收集器,而处于中间的G1即能处理新生代也能处理年老代。图中的黑色实线代表哪些新生代垃圾收集器能与哪些年老代垃圾收集器组合工作。CMS与Serial Old之间的黑色虚线代表CMS发生concurrent mode failure时fail safe成Full GC采用Serial Old回收年老代垃圾。
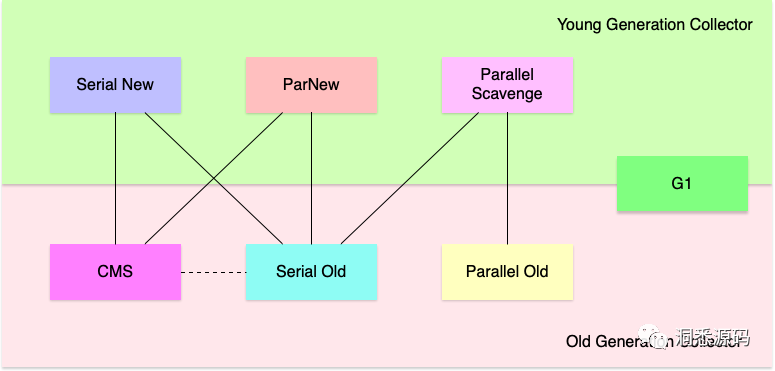
上面提到的Serial GC(Serial New 与 Serial Old)、Parallel GC(ParNew、Parallel Scavenge、Parallel Old)、CMS,由于新生代与年老代其内存布局是连续的(虚似内存是连续的)这些垃圾收集器在回收垃圾时要么只能处理具体某一个分区要么只能处理整个Heap。这必然会导致垃圾回收的STW时间或多或少与应用程序占用内存线性正相关,即应用程序占用的内存越大在执行垃圾回收时STW时间将越久。前面的垃圾收集器都是分代的垃圾收集器,G1开启了分区垃圾收集器的先河(虽然G1在逻辑上也有新生代与年老代的概念)。G1利用分治的思想将整体Heap划分为一块块大小相等的Region,在内存管理时可以针对这些Region进行管理,而不是笼统地对某个Generation进行管理。由于Region的大小通常远小于Generation,垃圾回收时处理多个Region效率通常高于处理某个Generation。
3 G1垃圾收集器概述
G1(Garbage First)垃圾收集器是续CMS收集器后的另一款跨时代的垃圾收集器,其开启了分区垃圾收集器的先河。G1通过时间预测模型尽可能地满足用户对暂停时间的要求(用户可以通过-XX:MaxGCPauseMillis=XXX,来指定垃圾收回时最大的暂停时间),G1 利用压缩算法优化回收垃圾更多的分区,所以他被称作垃圾优先(Garbage First)垃圾收集器。
3.1 G1 垃圾收集中的内存布局
G1与上面介绍的传统分代垃圾收集器一样同样存在Eden Generation、Survivor Generation、Old Generation的概念,但与他们最大的区别在于这些Generation的关系是逻辑上的关系,其各Generation内存布局不会存在连续性。G1 将Heap划分为一个个Region,每个Region的大小为2的N次方,其值在1M到32M之间。每一个Region属于某个Generation,于是有了Eden Region、Survivor Region、Old Region/Tenured Region的概念(不像传统分代垃圾收集器,G1中没有From Survivor 与 To Survivor的概念, 因为G1不管是Young GC、Mix GC、Full GC 对象都是从一个Region转移到另外一个Region或是直接清除)。除此之外G1还有一个专门用于存放大对象的Region(默认对象占用内存超过Region大小二分之一的对象),称为Humongous Region,Humongous Region 可能由多个Region构成,但一个Region最多存放一个大对象,当多个Region用于存放一个特别大的对象这些Region内在布局上是连续的。当经过多次Young GC、Mix GC、Full GC与对象分配后(G1中Young GC、Mix GC、Full GC 相关的东西后面会涉及),Eden Region、Survivor Region、Old Region、Humongous Region之间的角色会转变,即原来存有具体某种Generation对象的Region被清空后可以用来存放Eden对象、Survivor对象、Old 对象或是Humongous对象中的某一种。
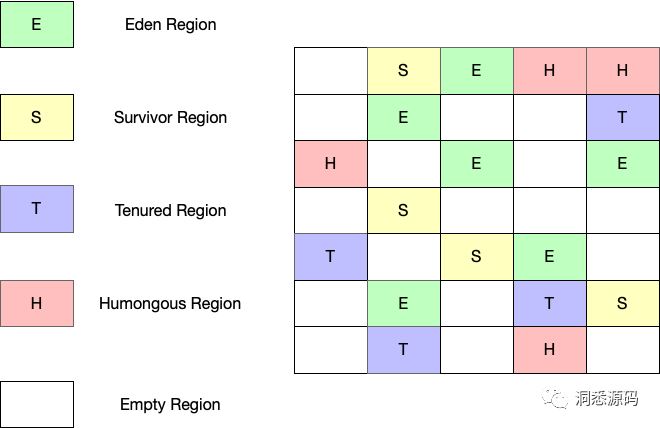
这种将内存分为一个个Region的内存布局更加有利于内存的回收,垃圾回收集可以采用分治的思想去管理一小块的内存(处理内存的分配与回收),避免了之前版本垃圾回收集在处理Old Generation时只能处理整个Old Generation困局(整个Old Generation一起处理通常非常耗时的,而且这个过程中避免不了STW)。
3.2 G1 垃圾收集的周期
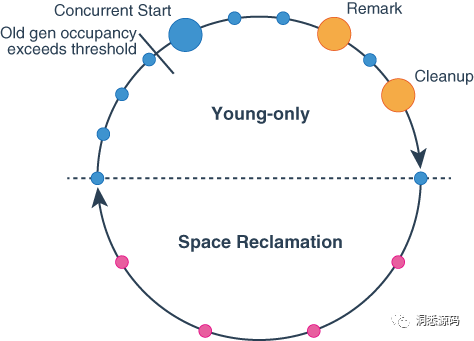
从全局视角来看,G1收集器回收垃圾的过程是在Young-only 阶段与Space Reclamation阶段之间进行交替的,下图来源于Oracle官网HotSpot Virtual Machine Garbage Collection Tuning Guide 一文中。
-
Young-only 阶段
Young-only阶段实际包括了多次Young GC 与整个并发标记过程。其从一些普通的Young GC(上图中小的蓝色点代表普通的Young GC)开始,并将满足条件的对象提升到老年代。当年老代占用内存超过阈值时,会触发并发标记阶段,该阈值由参数-XX:InitiatingHeapOccupancyPercent=65%,指定默认值为65%。与此同时G1会开启并发的Young GC(上图中大的蓝色大代表并发的Young GC) ,而不是普通的Young GC。整个并发标记阶段是与普通的Young GC交替的。并发标记阶段又可细分为初始化标记(Initial Marking)、重新标记(Remark)与清理(Cleanup)阶段。初始化标记阶段实际是在并发的Young GC中完成的(文献中通常用piggybacking一词表述)。当初始化标记完成后可能会发生若干的普通Yong GC,才进入Remark阶段(上图中靠上方的**小点)。接着并发标记可能被Young GC打断,Young GC结束后再进入Cleanup阶段(上图中靠下方的**小点)。
-
Space Reclamation 阶段
当Cleanup结束后,G1会进入Space Reclamation 阶段,该阶段由若干次的MixGC组成。每次MixGC都会从之前并发标记阶段标记的对象中选择一部分进行清理,MixGC过程中同时伴随着部分的Young GC(上图中红色的小点代表一次MixGC)。当G1发现清除对象所获取的空间不够多时将停止MixGC,与此同时Space Reclamation 阶段结束。
当Space Reclamation 阶段结束后,G1收集周期又重一个Young-only阶段重新开始。Young-only中的普通Young GC的触发条件与前分的分代垃圾收集器Young GC触发条件一致,只不过G1是针对Region处理的,即G1会根据Eden Region中是否有Region能够容纳新对象来决定是否要开启Young GC。作为兜底策略,当G1垃圾回收过程释放的内存不足于满足应用程序中新对象对内存要求时,G1会采用Full GC处理所有Region。
3.3 记忆集(RSet)
前面已了解到Young GC时只会处理新生代对应的Region即 Eden Region与Survivor Region,这有利于降低每次Young GC的时间。但如果 Eden Region与Survivor Region持有老年代的引用呢,难道在Young GC时,要把Heap中所有的Region都遍历一次才能确定Eden Region与Survivor Region有哪些对象才是垃圾吗?这种方式显然是不可取的,这样一来就会拉长Young GC的时间。
有种有效地方法是新生代的每一个Region都维护一个集合记录一下老年代指进来的(point-in)的跨代引用,这样在Young GC时只要看一下这个point-in的集合就行,这个集合便是所谓的记忆集(Remember Set,RSet)。那年老代里面需要这个RSet吗?前面提到每次Mix GC时会回收部分年老代的Region,如果没有这个记忆集的话和Young GC一样同样避免不了要扫描整个年老代的Region,所以年老代的Region也要维护一个point-in的集合,不过个集合记录是Old Region point-in 过来的集合,至于Young Region point-in 过来的则可以不用管。
那RSet具体实现上又是怎么样的呢?在这之前必须先知道卡表(CardTable),在G1之前CMS中也有CardTable。CardTable本质上是一种point-out数据结构,表示某一区域自己有指向别的区域的引用。在G1中CardTable由byte数组构成,数组的每个元素称之为卡片/卡页(CardPage)。CardTale会映射到整个堆的空间,每个CardPage会对应堆中的512B空间。如下图所示,在一个大小为8GB的堆中,那么CardTable的长度为16777215 (8GB / 512B);假设-XX:G1HeapRegionSize参数为2MB,即每个Region 大小为2 MB,则每个Region都会对应4096个CardPage。CardTable将占用16MB额外内存空间。
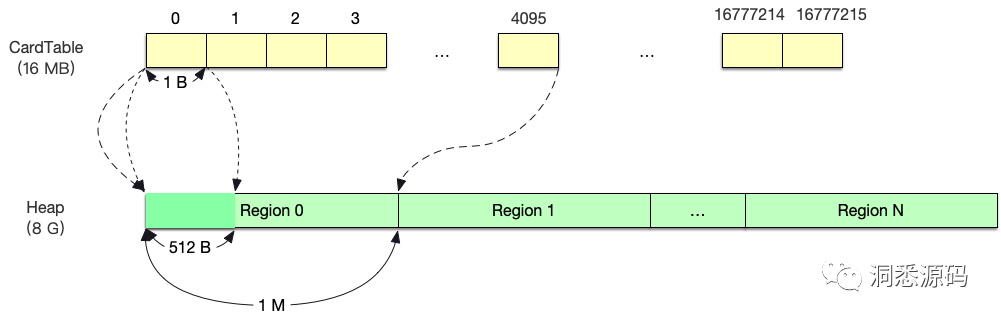
查找一个对象所在的CardPage只需要应用如下公式便可得出。
CardPageIndex = (对象的地址 – 堆开始地址) ÷ 512说完CardTable再来看看RSet的具体实现,RSet实际是通过HashMap实现的,该HashMap其key引用了本Region的其他Regionr的地址,value是一个数组,数组的元素是引用方的对象所对应的CardPage在CardTable中的下标。
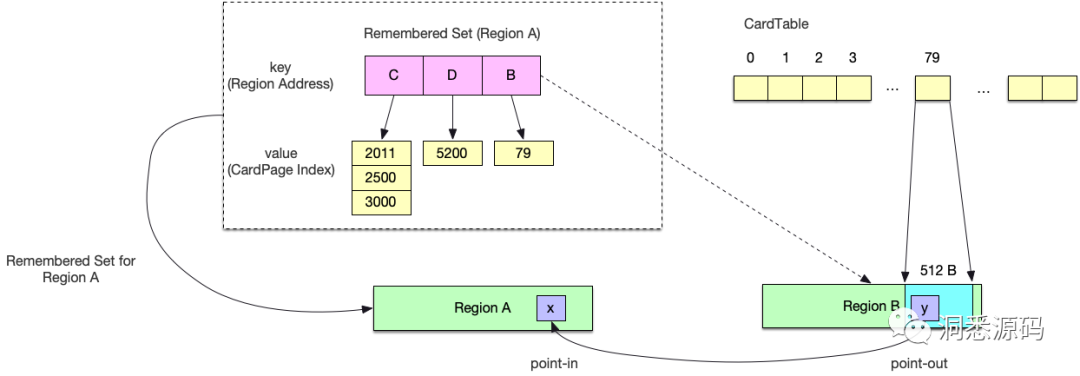
如上图所示,区域B中的对象y引用了区域A中的对象x,这个引用关系跨了两个区域。y对象所在的CardPage为179,在区域A的RSet中,以区域B的地址作为key,b对象所在CardPage下标79为value记录了这个引用关系,这样就完成了这个跨区域引用的记录。不过这个CardTable的粒度有点粗,毕竟一个CardPage有512B,在一个CardPage内可能会存在多个对象。所以在扫描标记时,需要扫描RSet中关联的整个CardPage,上图的例子是要把CardTable下标为79的CardPage都扫描一遍。
实际上HotSpot VM 中 G1的RSet具体实现要比上面说的更加复杂(上面说的只是其中的一种情况,Sparse粒度的情况 )。应用程序中可能存在频繁的更新引用情况,这会使得某些区域的RSet变成popular Region。G1 采用不同粒度的方式来处理RSet Popularity,RSet可分为Sparse、Fine、Coarse三种粒度。不同粒度时RSet内部采用不同的数据结构记录其他Region point-in 进来的引用 ,上面介绍的便是Sparse粒度时的情况。下面是 Evaluating and improving remembered sets in the HotSpot G1 garbage collector论文中给出的G1中 RSet 数据结构的简化定义。

1、Sparse Grained (上面g1_rset数据结构中的 saprse)
稀疏粒度情况时,采用HashMap实现,该HashMap其key引用了本Region的其他Regionr的地址,value是一个数组,数组的元素是引用方的对象所对应的CardPage在CardTable中的下标。
2、Fine Grained (上面g1_rset数据结构中的 fine_grained)
细粒度情况时,同样采用HashMap实现,该HashMap其key引用了本Region的其他Regionr的地址,value是一个位图,位图的最大位数代表一个Region最多能被拆分为多少CardPage,位图上值为1则代表Region上CardPage内有对象引用了RSet 所属Region的对象。
3、Coarse Grained (上面g1_rset数据结构中的 coarse)
粗粒度情况时,采用位图实现,位图的最大位数代表整个Heap能被拆分为多少个Region。位图上值为1则代表其他Region内有对象引用了RSet 所属Region的对象。因为Region的大小是一样的,可以通过Heap的起始地址,计算出位图中每个Region的起始地址。
G1通常利用Refinement Threads 异步维护RSet,每个线程会利用前面介绍的post-write barrier 将跨代引用与Old Generation 到 Old Generation 的引用记录到各自的local log buffer中,当local log buffer满了之后会刷新到全局的 log buffer中,Refinement Threads 专门处理全局的 log buffer来维护RSet,当Refinement Threads 不能有效地处理全局的log buffer时,应用线程将一起处理 log buffer,但这对应用线程的性能有损耗。当垃圾回收过程中如果全局的log buffer还未处理完,GC线程将处这些log buffer。
void oop_field_store(oop* field, oop new_value) {
pre_write_barrier(field); // pre-write barrier: for maintaining SATB invariant
*field = new_value; // the actual store
post_write_barrier(field, new_value); // post-write barrier: for tracking cross-region reference
}3.4 回收集(CSet)
回收集(Collection Set,CSet),其代表每次GC暂停时回收的一系列目标分区。在任意一次收集暂停中,CSet所有分区都会被释放,内部存活的对象都会被转移到分配的空闲分区中。因此无论是年轻代收集,还是混合收集,工作的机制都是一致的。年轻代收集CSet只容纳年轻代分区,而混合收集会通过启发式算法,在老年代候选回收分区中,筛选出回收收益最高的分区添加到CSet中。
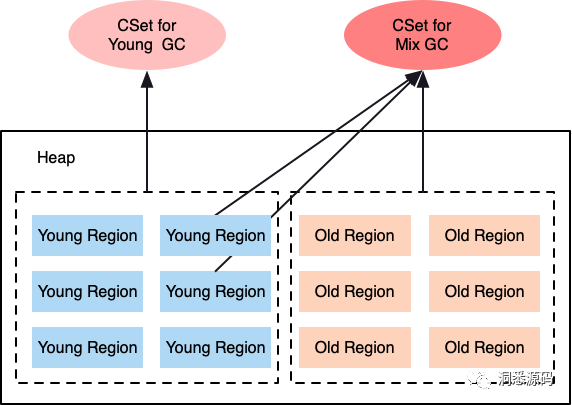
4 深入分析G1垃圾收集
前面已简要地介绍了,G1中Heap的内存布局、全局视角下G1的周期、RSet具体实现、CSet等内容,下再更细致地介绍一下G1中的Young GC 阶段、并发标记阶段、Mix GC 阶段。
4.1 Young GC阶段
同分代垃圾回收器一样,当G1中没有Eden Region能够容纳新要创建的对象时,G1中Young GC被触发;同时每个线程都有对应的TLAB,小的对象优先直接在TLAB中创建。前面已了解到G1的Young GC阶段只会回收全部的Young Region,Eden Region 与 Survivor Region;同时如果年老代内存占比超过了指定的阈值时,Young GC会一同完成并发标阶段的初始化标记工作。每次Young GC后,G1会根据当前新生代大小、新生代最小值、新生代最大值、目标暂停时间等重新调整新生代的大小。下面通常Young GC的 GC日志看一下Young GC具体包括那些阶段。JDK的采用的是HotSpot 1.8.0_241版本的JDK,JVM参数如下:
-XX:+UseG1GC -XX:G1HeapRegionSize=2m -Xms2g -Xmx2g -Xloggc:/Users/mac/Desktop/g1log -XX:+PrintGCDetails
-XX:+PrintGCDateStamps -XX:+PrintGCTimeStamps
2021-12-29T10:03:58.217-0800: 0.244: [GC pause (G1 Evacuation Pause) (young), 0.0914253 secs]
[Parallel Time: 90.3 ms, GC Workers: 8]
[GC Worker Start (ms): Min: 244.0, Avg: 244.1, Max: 244.1, Diff: 0.1]
[Ext Root Scanning (ms): Min: 0.1, Avg: 0.3, Max: 0.7, Diff: 0.7, Sum: 2.2]
[Update RS (ms): Min: 0.0, Avg: 0.0, Max: 0.0, Diff: 0.0, Sum: 0.0]
[Processed Buffers: Min: 0, Avg: 0.0, Max: 0, Diff: 0, Sum: 0]
[Scan RS (ms): Min: 0.0, Avg: 0.0, Max: 0.0, Diff: 0.0, Sum: 0.0]
[Code Root Scanning (ms): Min: 0.0, Avg: 0.0, Max: 0.2, Diff: 0.2, Sum: 0.2]
[Object Copy (ms): Min: 89.1, Avg: 89.6, Max: 89.8, Diff: 0.7, Sum: 716.5]
[Termination (ms): Min: 0.0, Avg: 0.1, Max: 0.2, Diff: 0.2, Sum: 0.8]
[Termination Attempts: Min: 1, Avg: 1.0, Max: 1, Diff: 0, Sum: 8]
[GC Worker Other (ms): Min: 0.1, Avg: 0.2, Max: 0.2, Diff: 0.1, Sum: 1.3]
[GC Worker Total (ms): Min: 90.1, Avg: 90.1, Max: 90.2, Diff: 0.1, Sum: 721.0]
[GC Worker End (ms): Min: 334.2, Avg: 334.2, Max: 334.2, Diff: 0.1]
[Code Root Fixup: 0.0 ms]
[Code Root Purge: 0.0 ms]
[Clear CT: 0.1 ms]
[Other: 1.1 ms]
[Choose CSet: 0.0 ms]
[Ref Proc: 0.7 ms]
[Ref Enq: 0.0 ms]
[Redirty Cards: 0.1 ms]
[Humongous Register: 0.1 ms]
[Humongous Reclaim: 0.0 ms]
[Free CSet: 0.0 ms]
[Eden: 102.0M(102.0M)->0.0B(88.0M) Survivors: 0.0B->14.0M Heap: 102.0M(2048.0M)->98.0M(2048.0M)]
[Times: user=0.12 sys=0.28, real=0.09 secs]
如上GC日志第一行所示 GC pause (G1 Evacuation Pause) (young) 代表本次GC 暂停为G1 的 Young GC。Young GC的工作分为并行工作与其他工作,为别为GC日志中的 [Parallel Time: 90.3 ms, GC Workers: 8] 与 [Other: 1.1 ms]。并行工作是Young GC的主要工作内容,并行工作被拆分为如下几部分。
1、External Root Scanning(GC日志中的 [Ext Root Scanning (ms): ...部分)
负责处理扫描指向CSet的外部根,例如寄存器、线程堆栈等。
2、Update Remembered Sets (RSets) (GC日志中的 [Update RS (ms): ...部分)
负责更新RSet,RSet之前详细介绍过主要是用来记录别的Region point-in 进来的引用。
3、Processed Buffers(GC日志中的[Processed Buffers: ...部分)
前面说过RSet的维护是通过先写log buffer然后再更新,Processed Buffers 便是处理那些在Young GC开始后还没有被Refinement Thread 处理完的 log buffer,这保证的RSet的完整性。
4、Scan RSets(GC日志中的[Scan RS (ms): ...部分)
负责扫描RSets中其他Region指向本Region的引用。这个扫描时间会因为RSet 的 Popularity 不同采用不同的粒度的数据结构存储而相差很多;前面介绍过的Coarse Grained时RSet的扫描时间将最耗时。
5、Code Root Scanning(GC日志中的[Code Root Scanning (ms): ...部分)
负责扫描CSet中已编译源代码的引用根。
6、Object Copy (GC日志中的[Object Copy (ms): ...部分)
负责将新生代Region,即Eden Region与 Survivor Region中依赖存活的对象复制到未使用的Survivor Region中或者将晋升的对象复制到Old Region中。
7、Termination (GC日志中的[Termination (ms): ...与 [Termination Attempts (ms): ...)部分
当每个GC Work线程完成其自身的工作后,会进行了结束阶段,这时已完成工作的Work 线程会与其他Work线程同步,同时尝试采用工作窃取算法获取还未完成工作的其他线程的工作。Termination Attempts 部分代表Work线程成功获取工作,处理完后再次尝试结束。这个过程其还会再次尝试获取其他未完成工作线程的任务。
其他工作,这部分主要是一些他们的任务包括选择Regino进入CSet、引用处理、引用入列队、重新标记卡页为脏页、释放CSet、处理Humongous对象等。关于G1 GC 日志更详细的解释可以参考Collecting and reading G1 garbage collector logs - part 2。
当年老代内存占比超过了-XX:InitiatingHeapOccupancyPercent指定的阈值,Young GC会顺便完成并发标记的初始化标记工作。这时在GC日志中将出现 GC pause (G1 Evacuation Pause) (young) (initial-mark) 的关键信息,其中的initial-mark 代表在进行Young GC时稍带完成的初始化标记工作。
4.2 G1中的SATB具体实现
文章的最开始已介绍过垃圾收集器通常会采用Tri-color Marking 算法来处理标记阶段对象引用的分析过程,在处理漏标问题上G1采用了Yuasa在Real-Time Garbage Collection on General Purpose Machines 提出的“snapshot-at-the-beginning” (SATB) 算法。
SATB 算法确保在并发标记开始后所有的垃圾对象都通过快照被识别出来。在并发标记过程中新分配的对象被认为是存活的对象,不用对他们进行追踪分析,这有利于减小标记的开销。G1维护二个用于并发标记的全局bitmap,分别被标记为previous与next。previous位图中保存了前一次并发标记的标记信息,next 位图保存了当前正在进行或刚完成并发标记的标记信息。previous bitmap中上次并发标记的标记信息,在本次本发标记中可以直接使用。同时每个Region都有几个重要的指针 PTAMS(上一次并发标记的起始位置)、NTAMS(下一次并发标记的起始位置)、Bottom(Region的起始地址)、Top(Region已使用地址)、End(Region的结束地址);TAMS实现是 top at mark start的缩写,也就是每次并发标记会把对应的指针放在Top针指同一位置,代表标志的结束位置 。每次并发标记开始时,NTAMS指针重新指Top指针的位置,当并发标记结束后,NTAMS指针与 PTAMS指针会交位置,next bitmap 与 previous bitmap 交换角色,新的next bitmap 被清空,即原来的 previous bitmap被清空。
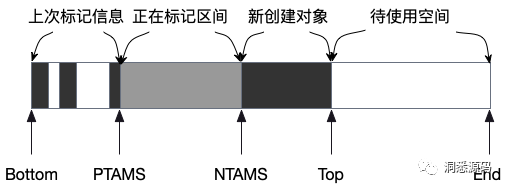
上图展示了某次并发标记过程中一个Region中 Bottom、PTAMS、NTAMS、Top、End指针位置,指针之间区域的含义。区间中的白色、灰色、黑色可以大致理解为三色标记法中的三种颜色。
[Bottom, PTAMS) 区间
该区间代表上次并发标记的区间,PTAMS为上次并发标记的结束位置,该区间上次并发标记的信息能直接被正在进行的并发标记利用,即正在进行的并发标记通过上次bitmap知道该区间哪些是垃圾哪些是存活对象。
[PTAMS, NTAMS) 区间
该区间代表本次正在进行的并发标记的区间,NTAMS为本次并发标记的结束位置,在并发标记开始时G1会为[PTAMS, NTAMS) 区间创建一个快照,实际就是next bitmap,然后处理bitmap映射的地址,标记这些地址上的对象是垃圾还是存活的。实际标记过程就是有一个指针从PTAMS指针位置一直移到NTAMS指针位置。
[NTAMS, Top) 区间
该区间代表并发标记过程中,应用线程新生成的对象,前面已说过在并发标记过程中新分配的对象被认为是存活的对象,所以上图中该区间全是黑色的。并发标记刚开始时Top指针与NTAMS指针处于同一位置,当应用线程每生成一个新对象时,Top指针就会相应的向End指针的方向右移。
[Top, End) 区间
该区间代表Region中还没有使用的空间。
很显然GC线程只会去处理[PTAMS, NTAMS) 区间完成标记工作,而应用线程运行则会对[Bottom, Top)区间有影响。应用线程对[Bottom, Top)区间中[NTAMS, Top)区间的影响并不会影响GC线程的并发标记工作,因为该部分应用线程新增的对象都认为是存活的对象。应用线程对[Bottom, Top)区间中[PTAMS, NTAMS)区间的影响可能会影响GC线程的并发标记工作,G1通过前面介绍的pre-write barrier来确保标记的正确性,即如果应用线程在[PTAMS, NTAMS)区间内增加了黑色对象对白色对象的引用,pre-write barrier内部处理时会将白色对象设置为灰色对象,使得该对象能再次被标记不会产生漏标。应用线程对[Bottom, Top)区间中[Bottom, PTAMS)区间的影响可能会影响GC线程的并发标记工作,具体G1是如何处理这个有待考证,猜测应该也是利用write barrier这里的技术。
有了上面介绍,再看一下 Sun公司 G1的论文Garbage-First Garbage Collection 中 Initial Marking Pause/Concurrent Marking 小节中的这个图应该会清晰点。

Initial Marking阶段,当Region首次被标记时,PrevBitmap为空,NextBitmap中有[PrevTAMS, NextTAMS)区间的块照,并发标记结束后将确定Bitmap中哪些是垃圾对象, PrevTAMS指针与Bottom指针位置相同,NextTAMS指针与Top指针位置相同。
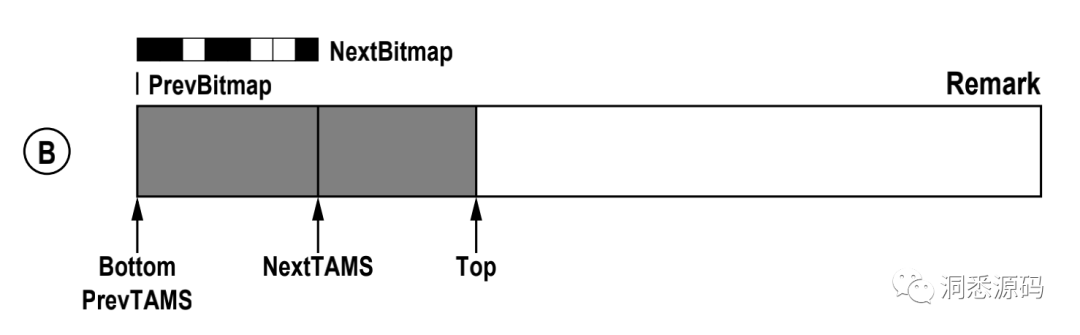
Remark 阶段,[PrevTAMS, NextTAMS)区间的存活对象与垃圾对象被标记出来,NextBitmap发生改变其中黑色部分表示标记出来的存活对象,白色部分为垃圾对象。同时由于应用程序生成了新的对象,Top指针的位置从NextTAMS指针处向右移动了。
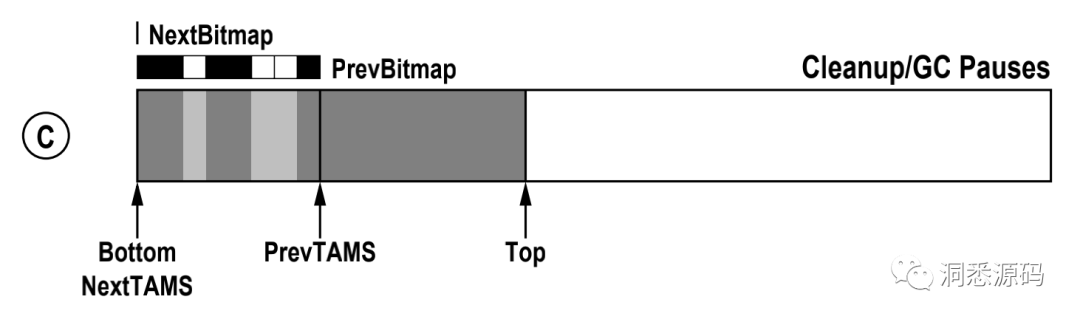
Cleanup/GC Pauses阶段,NextBitmap 与 PrevBitmap互换角色,同时NextTAMS指针与PrevTAMS指针互换位置。
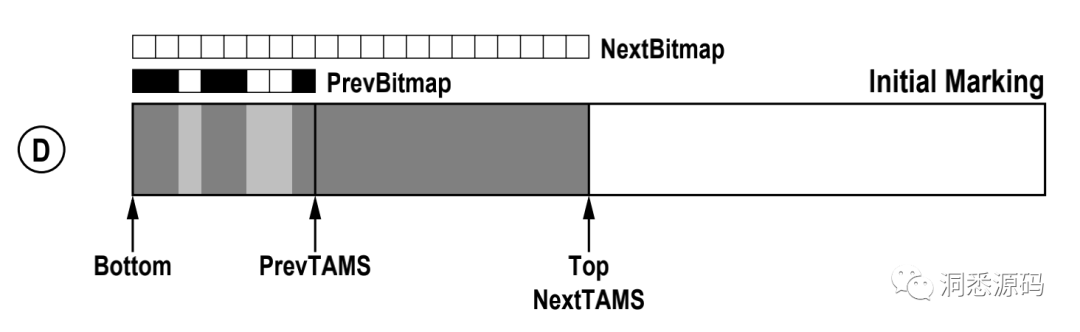
新一轮标记Initial Marking阶段,NextTAMS指针重新指向Top指针,PrevBitmap保证了上一次的标记信息,NextBitmap中有[PrevTAMS, NextTAMS)区间的块照。
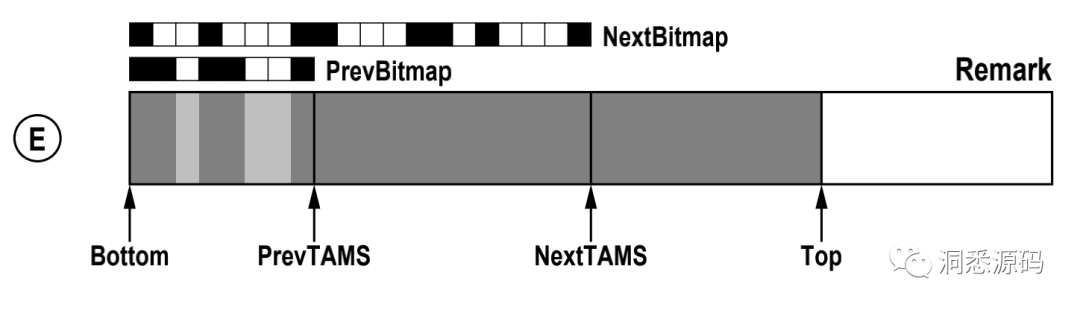
新一轮标记Remark阶段,再重复上面B的事情。
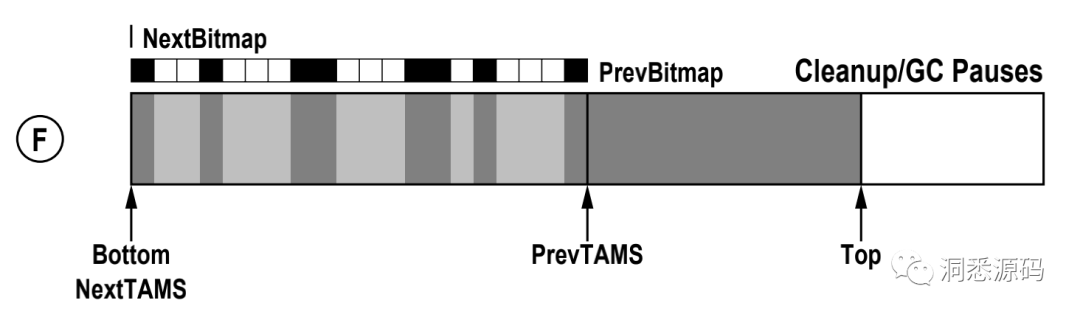
新一轮标记Remark阶段,Cleanup/GC Pauses阶段,再重复上面C的事情。
4.3 并发标记阶段
并发标记阶段主要是将Mix GC时要收集的垃圾对象先进行标记,然后根据Region能释放的内存空间做一下排序,同时其会在标记的最后阶段直接释放那些没有存活对象的Region,并将这些Region加入到可用Region列表中。并发标记阶段可细分为Initial Mark、Root Region Scanning、Concurrent Marking、Remark、Cleanup等等五个阶段。
Initial Mark 阶段
当年老代内存占比超过 -XX:InitiatingHeapOccupancyPercent指定的阈值时会触发并发标记,并发标记的第一个阶段为Initial Mark,该阶段会STW,其只扫描GCRoot直接引用的对象,由于Young GC时也要扫描GCRoot直接引用的对象,Young GC时会顺便完成Initial Mark的工作。GC日志通常会有GC pause (G1 Evacuation Pause) (young) (initial-mark) 的关键信息,其中的initial-mark 代表在进行Young GC时顺便完成的初始化标记工作。
Root Region Scanning 阶段
实际扫描的是新生代Survivor Region引用的对象,该阶段必须在下次GC暂停前完成,因为Heap要扫描存活对象的话,Survivor Region引用的对象必须先被识别。
Concurrent Marking 阶段
并发标记阶段GC线程与应用线程是并发的,同时可以通过-XX:ConcGCThreads指定并行GC线程数。前面已介绍过G1采用pre-write barrier 解决并发标记过种中因为应用线程更新了并发开始阶段创建的对象图的快照导致的漏标问题,每个线程。并发标记阶段会顺带完成每个Region对象的计数工作,方便后面统计哪些Region能回收更多的内存。
Remark 阶段
该阶段实际是标记的最后阶段,其会SWT,这个阶段就负责把剩下的引用处理完,该阶段会处理之前SATB write barrier记录的尚未处理引用。但其与与CMS的remark有本质的区别,即G1的Remark的暂停只需要扫描SATB buffer,而CMS的remark需要重新扫描里全部的dirty card 外加整个根集合,而此时整个新生代都会被当作根集合的一部分,因而CMS remark有可能会非常慢。
Cleanup 阶段
该阶段会阶段会STW,其主要工作是重置标记状态,如前面介绍的NextBitmap 与 PrevBitmap互换角色,同时NextTAMS指针与PrevTAMS指针互换位置。同时若发现有Region没有存活对象,则会直接将Region清空并将Region加入到空闲Region列表中。当然统计每个Region能回收多少垃圾的统计工作也在这个阶段完成,这样后Mix GC对象转移时便能快速地确定CSet。
4.4 Mix GC阶段
MixGC阶段主要负责回收部分年老代与全部新生代的Region,G1会根据设置的目标暂停时间-XX:MaxGCPauseMillis将并发标记阶段标记好的Region,按其可以释放内存空间大小,依次进行回收,即一个MixGC 阶段会包含多次的MixGC,当G1发现释放垃圾对象获取的内存空间过小时其将停止MixGC。MixGC时在GC日志中将出现GC pause (G1 Evacuation Pause) (mixed)的关键信息。作为兜底策略,当G1垃圾回收过程释放的内存不足于满足应用程序中新对象对内存要求时,G1会采用Full GC处理所有Region。
总结
本文详细深入地分析了G1垃圾收集器底层的实现原理,虽然没有涉及G1垃圾收集器的具体源码但基本把G1相关的知识都由浅及深地分析了一下。希望看完本文你会有所收获,限于本人能力有限文中不正确还望指正。最后欢迎关注个人公众号洞悉源码。
参考
Java Performance Companion
《垃圾回收算法手册自动内存管理的艺术》
结尾
原创不易,点赞、在看、转发是对我莫大的鼓励,关注公众号洞悉源码是对我最大的支持。同时相信我会分享更多干货,我同你一起成长,我同你一起进步。


