
架构与思维:一次缓存雪崩的灾难复盘原创
1 真实案例
云办公系统用户实时信息查询功能优化发布之后,系统发生宕机事件(系统挂起,页面无法加载)。
1.1 背景
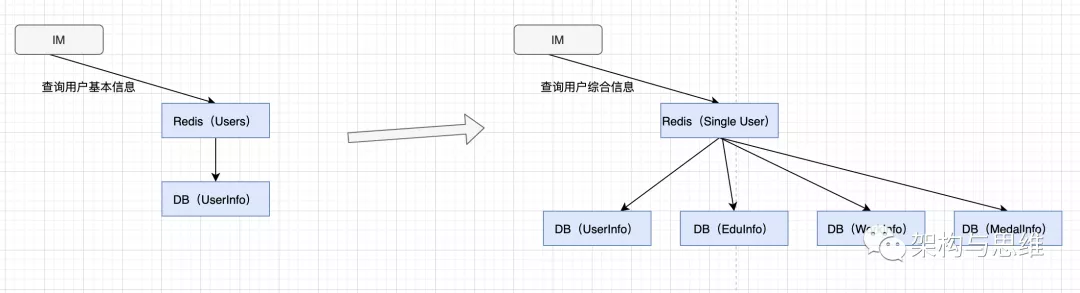
1.2 问题处理
2 缓存雪崩
2.1 概念
缓存雪崩是指大量的key设置了相同的过期时间,导致在缓存在同一时刻全部失效,造成瞬时DB请求量大、压力骤增,引起雪崩。
2.2 解决方案分析
2.2.1 缓存集群+数据库集群
在系统容量设计的时候,应该能够预见后期会有大量的请求,所以在发生雪崩前对缓存集群实现高可用,如果是使用 Redis,可以使用 主从+哨兵 ,Redis Cluster 来避免 Redis 全盘崩溃的情况。
同样的,也需要对数据库进行高可用保障,因为透过缓存之后,真正考验的是数据库的抗压能力。所以 1主N从 甚至 数据库集群 是我们需要重点去考虑的。
2.2.2 适当的限流、降级
可以使用 Hystrix进行限流 + 降级 ,比如像上面那种情况,一下子来了1W个请求,不是当前系统的吞吐能力能够承受的,假设单秒TPS的能力只能是 5000个,那么剩余的 5000 请求就可以走限流逻辑。
可以设置一些默认值,然后调用我们自己降级逻辑去FallBack,保护最后的 MySQL 不会被大量的请求挂起。 除了Hystrix之外,阿里的Sentinel 和 Google的RateLimiter 都是不错的选择。
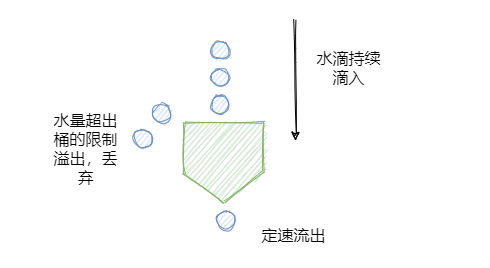
Sentinel 漏桶算法
RateLimiter 令牌桶算法
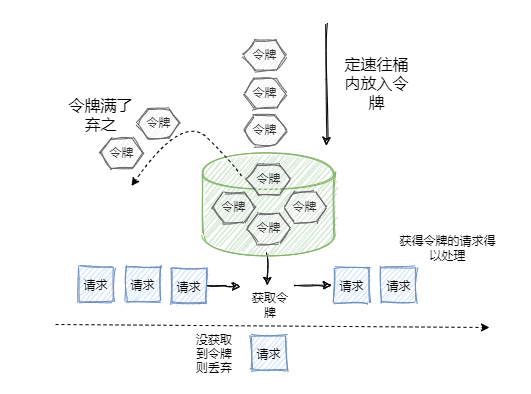
另外可以考虑使用用本地缓存来进行缓冲,在 Redis Cluster 不可用的时候,不至于全线崩溃。
2.2.3 随机过期时间
可以给缓存设置过期时间时加上一个随机值时间,使得每个key的过期时间分布开来,不会集中在同一时刻失效。
随机值我们团队的做法是:n * 3/4 + n * random() 。所以,比如你原本计划对一个缓存建立的过期时间为8小时,那就是6小时 + 0~2小时的随机值。

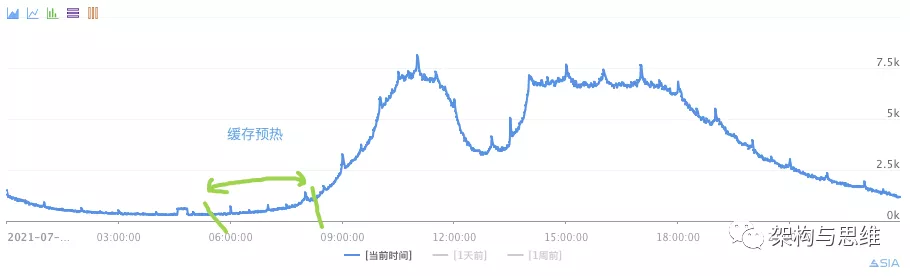
2.2.4 缓存预热
3 缓存穿透
3.1 概念
比如 我们查询用户的信息,程序会根据用户的编号去缓存中检索,如果找不到,再到数据库中搜索。如果你给了一个不存在的编号:XXXXXXXX,那么每次都比对不到,就透过缓存进入数据库。
这样风险很大,如果因为某些原因导致大量不存在的编号被查询,甚至被恶意伪造编号进行攻击,那将是灾难。
3.2 解决方案分析
3.2.1 缓存空值
发生穿透的原因是缓存中没有存储这些空数据的key,或者压根这个数据的key是不会存在的,从而导致每次查询都进入数据库中。
我们就可以将这些key的值设置为null,并写到缓存池中。后面再出现查询这个key 的请求的时候,直接返回null,这样就在缓存池中就被判断返回了,压力在缓存层中,不会转移到数据库上。
3.2.2 BloomFilter
我们称作布隆过滤器,BloomFilter 类似于一个hbase set 用来判断某个元素(key)是否存在于某个集合中。
这种方式在大数据场景应用比较多,比如 Hbase 中使用它去判断数据是否在磁盘上。还有在爬虫场景判断url 是否已经被爬取过。
这种方案可以加在第一种方案中,在缓存之前在加一层 BloomFilter ,把存在的key记录在BloomFilter中,在查询的时候先去 BloomFilter 去查询 key 是否存在,如果不存在就直接返回,存在再走查缓存 ,投入数据库去查询,这样减轻了数据库的压力。
流程图如下:
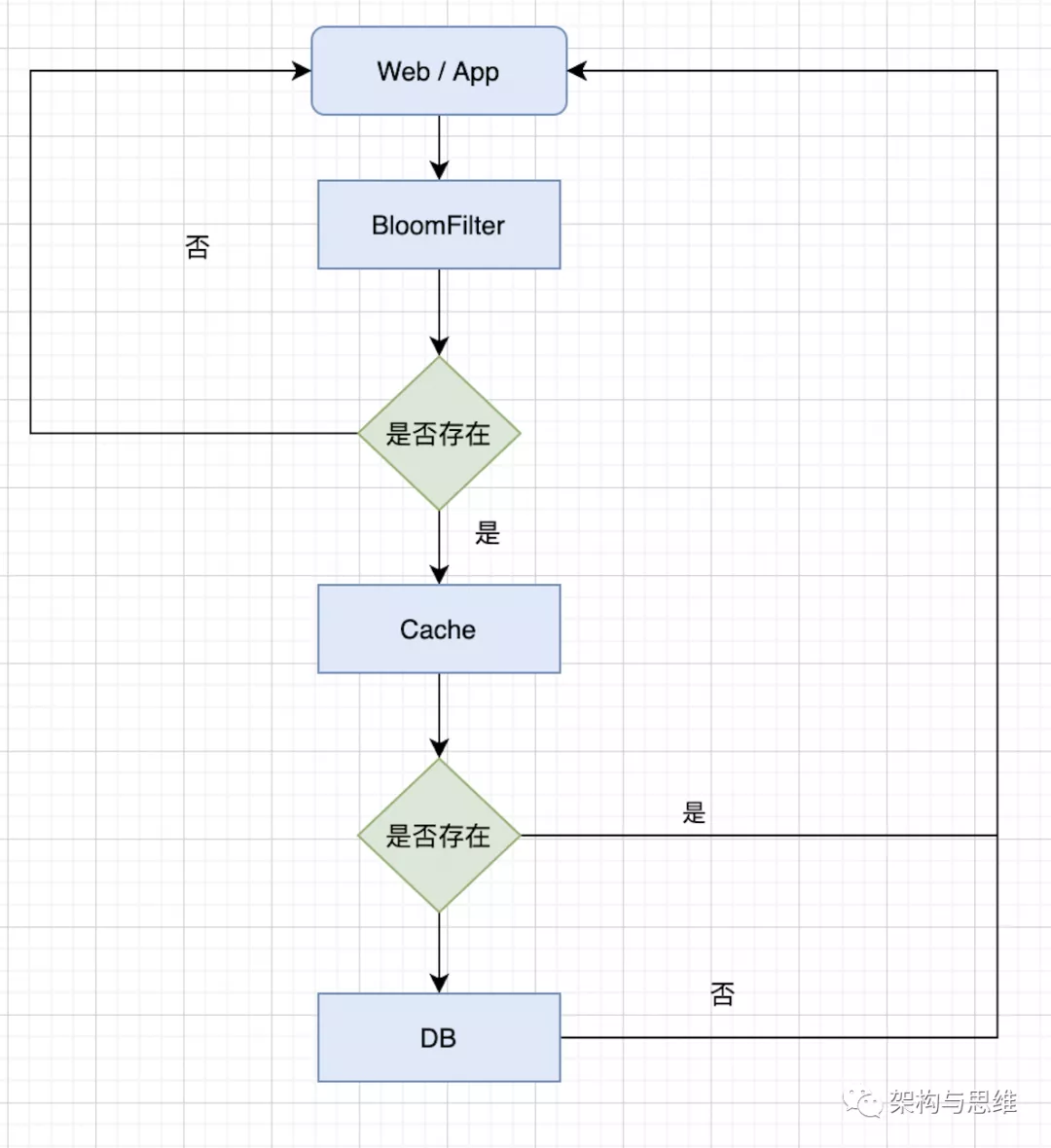
3.2.3 两种方案的选择判断
前面说过,可能会存在一些恶意攻击,伪造出大量不存在的key ,这种情况下如果我们如果采用缓存空值的办法,就会产生大量不存在key的null数据。显然是不合适的,这时我们完全可以使用第二种方案进行过滤掉这些key。
所以,判断的依据是:
针对key非常多、请求重复率比较低的数据,我们就没有必要进行缓存,使用 BloomFilter 直接过滤掉。
而对于空数据的key有限的,重复率比较高的,我们则可以采用 缓存空值的办法 进行处理。
4 缓存击穿
4.1 概念
4.2 解决方案
4.2.1 锁的方式
这种现象是多个线程同时去查询数据库的这条数据,那么我们可以在第一个查询数据的请求上使用一个 互斥锁来锁住它。
其他的线程走到这一步拿不到锁就等着,等第一个线程查询到了数据,然后做缓存。后面的线程进来发现已经有缓存了,就直接走缓存。
锁不好的地方就是在其他线程在拿不到锁的时候就等待,这个会造成系统整体吞吐量降低,用户体验度也不好。
4.2.2 空初始值
这是一种短暂降级的方式:
如果一个缓存失效的时候,有无数个请求狂奔而来,而第一个请求从进入缓存池,判空,再到数据库检索,再查询出结果并返回设置缓存的这个过程里,缓存是不存在的。
这个就很危险,超高并发下这个短暂的过程足已让千千万万请求投向数据库。更别提这可能是个慢查询,整个过程可能长达2s以上,那对数据库是一种非常大的伤害。
业内有一种做法叫做空初始值,短暂的局部降级来保证整个数据库系统不被击穿。大概流程如下:
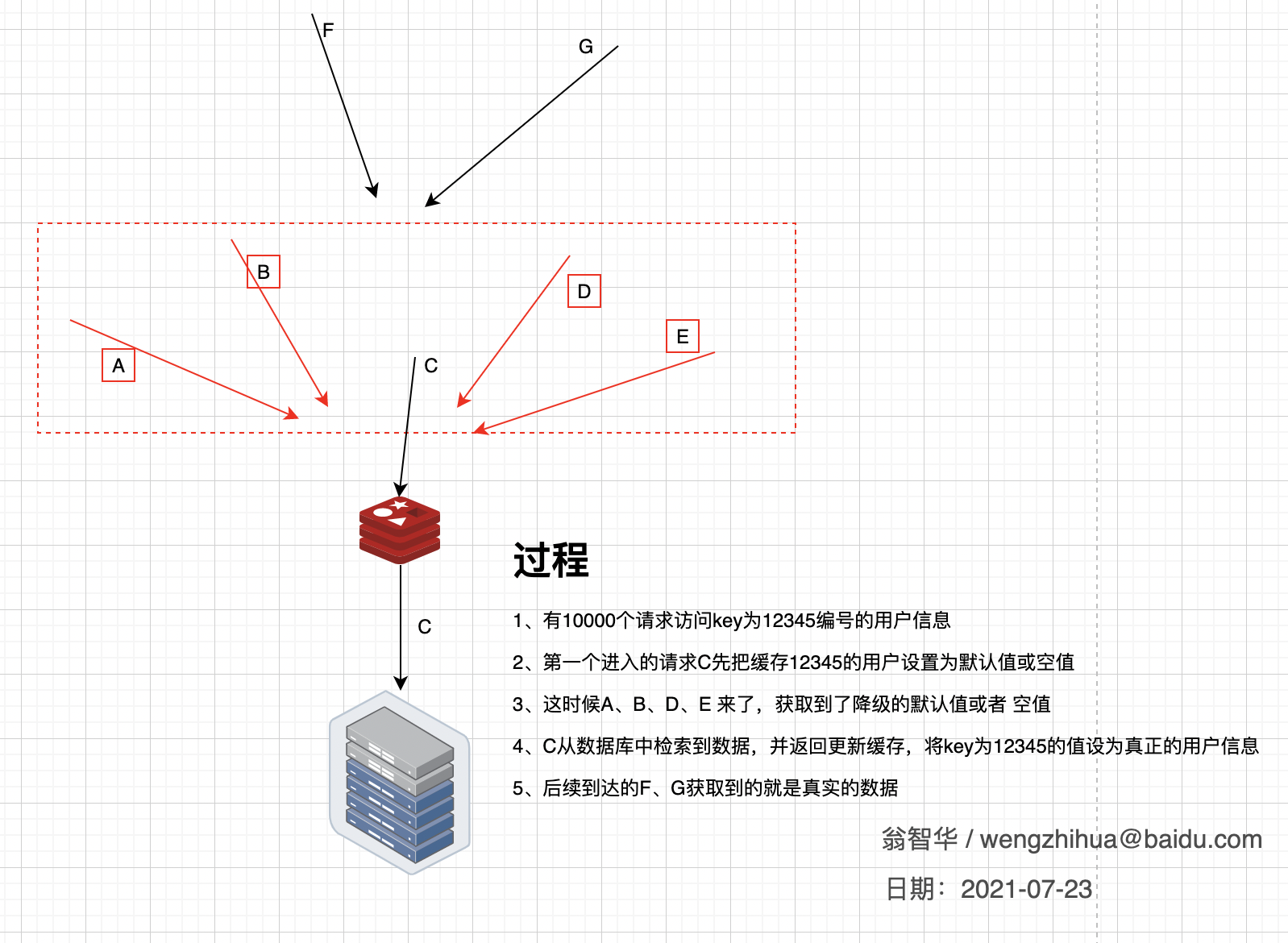
可以看出,整个过程中我们牺牲了A、B、C、D的请求,他们拿回了一个空值或者默认值,但是这局部的降级却保证整个数据库系统不被拥堵的请求击穿。
这也是我面试中最喜欢问候选人的缓存类问题。

欢迎关注公众号【架构与思维】:撰稿者为bat、字节的几位高阶研发/架构。不做广告、不卖课、不要打赏,只分享优质技术。

