
深入剖析JVM堆外内存的监控与回收原创
引子
记得那是一个风和日丽的周末,太阳红彤彤,花儿五颜六色,96 年的普哥微信找到我,描述了一个诡异的线上问题:线上程序使用了 NIO FileChannel 的 堆内内存作为缓冲区,读写文件,逻辑可以说相当简单,但根据监控却发现堆外内存飙升,导致了 OutOfMemeory 的异常。
由这个线上问题,引出了这篇文章的主题,主要包括:FileChannel 源码分析,堆外内存监控,堆外内存回收。
问题分析&源码分析
根据异常日志的定位,发现的确使用的是 HeapByteBuffer 来进行读写,但却导致堆外内存飙升,随即翻了 FileChannel 的源码,来一探究竟:
FileChannel 使用的是 IOUtil 来进行读写(只分析读的逻辑,写的逻辑行为和读其实一致,不进行重复分析)
//sun.nio.ch.IOUtil#read
static int read(FileDescriptor var0, ByteBuffer var1, long var2, NativeDispatcher var4) throws IOException {
if (var1.isReadOnly()) {
throw new IllegalArgumentException("Read-only buffer");
} else if (var1 instanceof DirectBuffer) {
return readIntoNativeBuffer(var0, var1, var2, var4);
} else {
ByteBuffer var5 = Util.getTemporaryDirectBuffer(var1.remaining());
int var7;
try {
int var6 = readIntoNativeBuffer(var0, var5, var2, var4);
var5.flip();
if (var6 > 0) {
var1.put(var5);
}
var7 = var6;
} finally {
Util.offerFirstTemporaryDirectBuffer(var5);
}
return var7;
}
}
可以发现当使用 HeapByteBuffer 时,会走到下面这行比较奇怪的代码分支:
Util.getTemporaryDirectBuffer(var1.remaining());
这个 Util 封装了更为底层的一些 IO 逻辑
package sun.nio.ch;
public class Util {
private static ThreadLocal<Util.BufferCache> bufferCache;
public static ByteBuffer getTemporaryDirectBuffer(int var0) {
if (isBufferTooLarge(var0)) {
return ByteBuffer.allocateDirect(var0);
} else {
// FOUCS ON THIS LINE
Util.BufferCache var1 = (Util.BufferCache)bufferCache.get();
ByteBuffer var2 = var1.get(var0);
if (var2 != null) {
return var2;
} else {
if (!var1.isEmpty()) {
var2 = var1.removeFirst();
free(var2);
}
return ByteBuffer.allocateDirect(var0);
}
}
}
}
isBufferTooLarge 这个方法会根据传入 Buffer 的大小决定如何分配堆外内存,如果过大,直接分布大缓冲区;如果不是太大,会使用 bufferCache 这个 ThreadLocal 变量来进行缓存,从而复用(实际上这个数值非常大,几乎不会走进直接分配堆外内存这个分支)。这么看来似乎发现了两个不得了的结论:
-
使用 HeapByteBuffer 读写都会经过 DirectByteBuffer,写入数据的流转方式其实是:HeapByteBuffer -> DirectByteBuffer -> PageCache -> Disk,读取数据的流转方式正好相反。
-
大多数情况下,会申请一块跟线程绑定的堆外缓存,这意味着,线程越多,这块临时的堆外缓存就越大。
看到这儿,似乎线上的问题有了一点眉目:很有可能是多线程使用堆内内存写入文件,而额外分配这块堆外缓存导致了内存溢出。在验证这个猜测之前,我们最好能直观地监控到堆外内存的使用量,这才能增加我们定位问题的信心。
实现堆外内存的监控
JDK 提供了一个非常好用的监控工具 —— Java VisualVM。我们只需要为他安装 2 个插件,即可很方便地实现堆外内存的监控。
进入本地 JDK 的可执行目录(在我本地是:/Library/Java/JavaVirtualMachines/jdk1.8.0_181.jdk/Contents/Home/bin),找到 jvisualvm 命令,双击即可打开一个可视化的界面
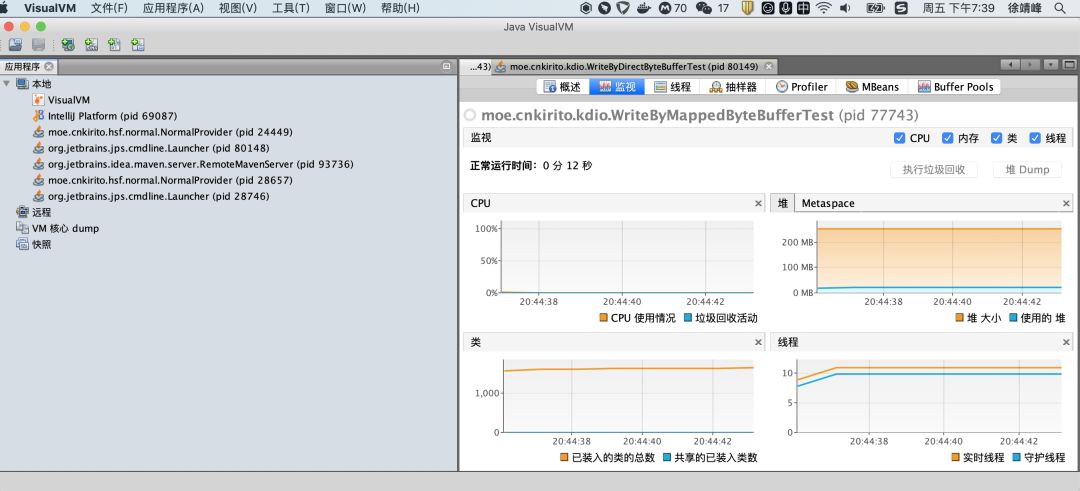
左侧树状目录可以选择需要监控的 Java 进程,右侧是监控的维度信息,除了 CPU、线程、堆、类等信息,还可以通过上方的【工具(T)】 安装插件,增加 MBeans、Buffer Pools 等维度的监控。
Buffer Pools 插件可以监控堆外内存(包含 DirectByteBuffer 和 MappedByteBuffer),如下图所示:
左侧对应 DirectByteBuffer,右侧对应 MappedByteBuffer。
复现问题
为了复现线上的问题,我们使用一个程序,不断开启线程使用堆内内存作为缓冲区进行文件的读取操作,并监控该进程的堆外内存使用情况。
public class ReadByHeapByteBufferTest {
public static void main(String[] args) throws IOException, InterruptedException {
File data = new File("/tmp/data.txt");
FileChannel fileChannel = new RandomAccessFile(data, "rw").getChannel();
ByteBuffer buffer = ByteBuffer.allocate(4 * 1024 * 1024);
for (int i = 0; i < 1000; i++) {
Thread.sleep(1000);
new Thread(new Runnable() {
@Override
public void run() {
try {
fileChannel.read(buffer);
buffer.clear();
} catch (IOException e) {
e.printStackTrace();
}
}
}).start();
}
}
}
运行一段时间后,我们观察下堆外内存的使用情况
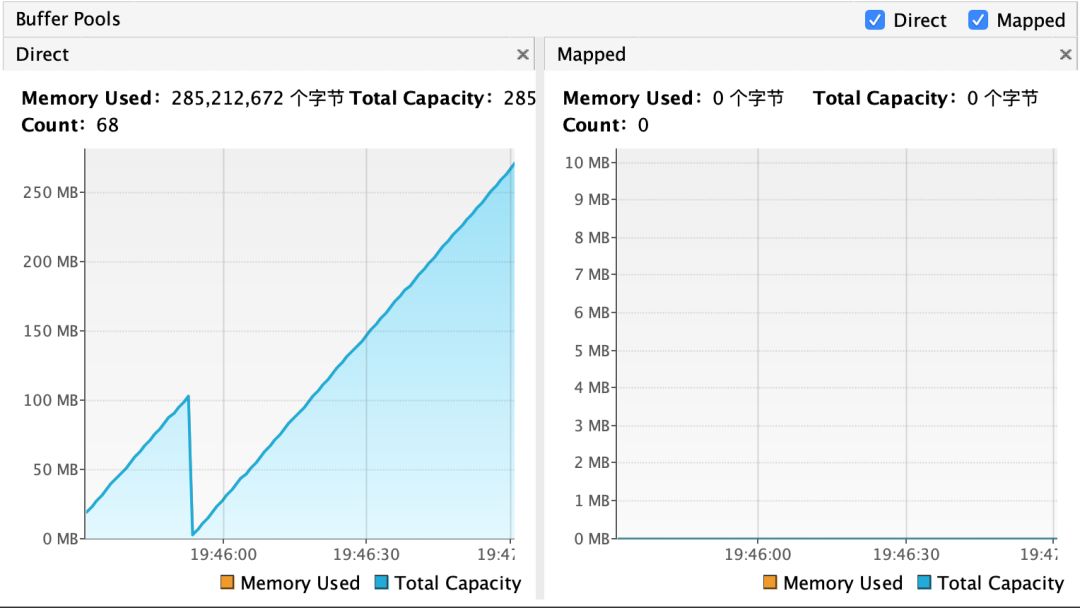
如上图左所示,堆外内存的确开始疯涨了,符合我们的预期,堆外缓存和线程绑定,当线程非常多时,即使只使用了 4M 的堆内内存,也可能会造成极大的堆外内存膨胀,在中间发生了一次断崖,推测是线程执行完毕 or GC,导致了内存的释放。
知晓了这一点,相信大家今后使用堆内内存时可能就会更加注意了,我总结了两个注意点:
-
使用 HeapByteBuffer 还需要经过一次 DirectByteBuffer 的拷贝,在追求极致性能的场景下是可以通过直接复用堆外内存来避免的。
-
多线程下使用 HeapByteBuffer 进行文件读写,要注意
ThreadLocal<Util.BufferCache>bufferCache导致的堆外内存膨胀的问题。
问题深究
那大家有没有想过,为什么 JDK 要如此设计?为什么不直接使用堆内内存写入 PageCache 进而落盘呢?为什么一定要经过 DirectByteBuffer 的拷贝呢?
在知乎的相关问题中,R 大和曾泽堂 两位同学进行了解答,是我比较认同的解释:
作者:RednaxelaFX
链接:https://www.zhihu.com/question/57374068/answer/152691891
来源:知乎
这里其实是在迁就OpenJDK里的HotSpot VM的一点实现细节。
HotSpot VM 里的 GC 除了 CMS 之外都是要移动对象的,是所谓“compacting GC”。
如果要把一个Java里的 byte[] 对象的引用传给native代码,让native代码直接访问数组的内容的话,就必须要保证native代码在访问的时候这个 byte[] 对象不能被移动,也就是要被“pin”(钉)住。
可惜 HotSpot VM 出于一些取舍而决定不实现单个对象层面的 object pinning,要 pin 的话就得暂时禁用 GC——也就等于把整个 Java 堆都给 pin 住。
所以 Oracle/Sun JDK / OpenJDK 的这个地方就用了点绕弯的做法。它假设把 HeapByteBuffer 背后的 byte[] 里的内容拷贝一次是一个时间开销可以接受的操作,同时假设真正的 I/O 可能是一个很慢的操作。
于是它就先把 HeapByteBuffer 背后的 byte[] 的内容拷贝到一个 DirectByteBuffer 背后的 native memory去,这个拷贝会涉及 sun.misc.Unsafe.copyMemory() 的调用,背后是类似 memcpy() 的实现。这个操作本质上是会在整个拷贝过程中暂时不允许发生 GC 的。
然后数据被拷贝到 native memory 之后就好办了,就去做真正的 I/O,把 DirectByteBuffer 背后的 native memory 地址传给真正做 I/O 的函数。这边就不需要再去访问 Java 对象去读写要做 I/O 的数据了。
总结一下就是:
-
为了方便 GC 的实现,DirectByteBuffer 指向的 native memory 是不受 GC 管辖的
-
HeapByteBuffer 背后使用的是 byte 数组,其占用的内存不一定是连续的,不太方便 JNI 方法的调用
-
数组实现在不同 JVM 中可能会不同
堆外内存的回收
继续深究一下一个话题,也是我的微信交流群中曾经有人提出过的一个疑问,到底该如何回收 DirectByteBuffer?既然可以监控堆外内存,那验证堆外内存的回收就变得很容易实现了。
CASE 1:分配 1G 的 DirectByteBuffer,等待用户输入后,赋值为 null,之后阻塞持续观察堆外内存变化
public class WriteByDirectByteBufferTest {
public static void main(String[] args) throws IOException, InterruptedException {
ByteBuffer buffer = ByteBuffer.allocateDirect(1024 * 1024 * 1024);
System.in.read();
buffer = null;
new CountDownLatch(1).await();
}
}
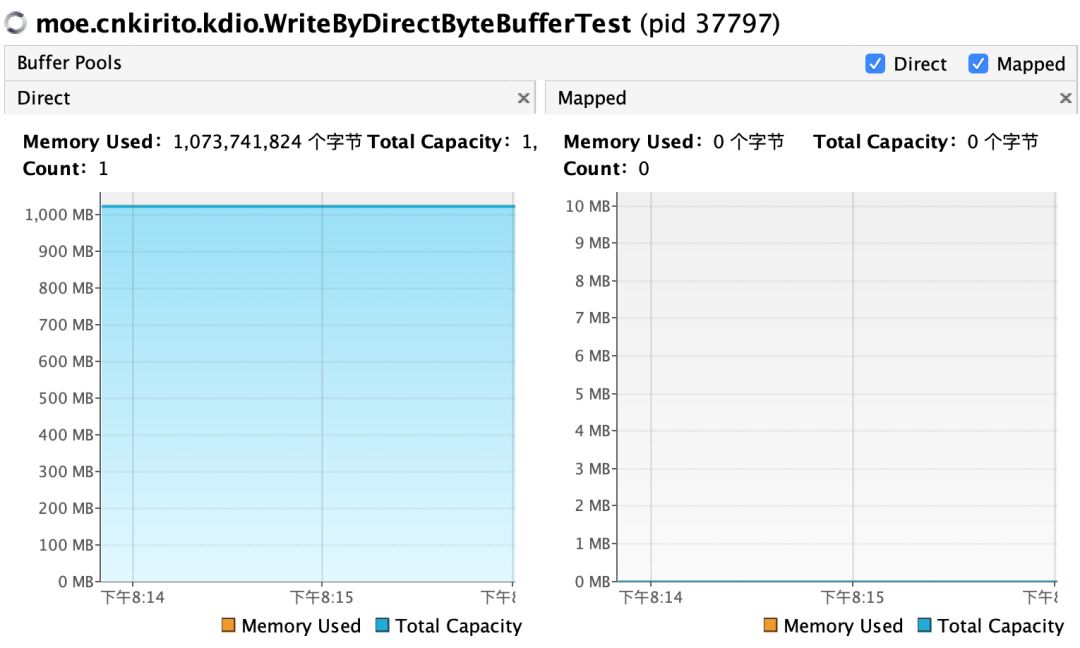
结论:变量虽然置为了 null,但内存依旧持续占用。
CASE 2:分配 1G DirectByteBuffer,等待用户输入后,赋值为 null,手动触发 GC,之后阻塞持续观察堆外内存变化
public class WriteByDirectByteBufferTest {
public static void main(String[] args) throws IOException, InterruptedException {
ByteBuffer buffer = ByteBuffer.allocateDirect(1024 * 1024 * 1024);
System.in.read();
buffer = null;
System.gc();
new CountDownLatch(1).await();
}
}
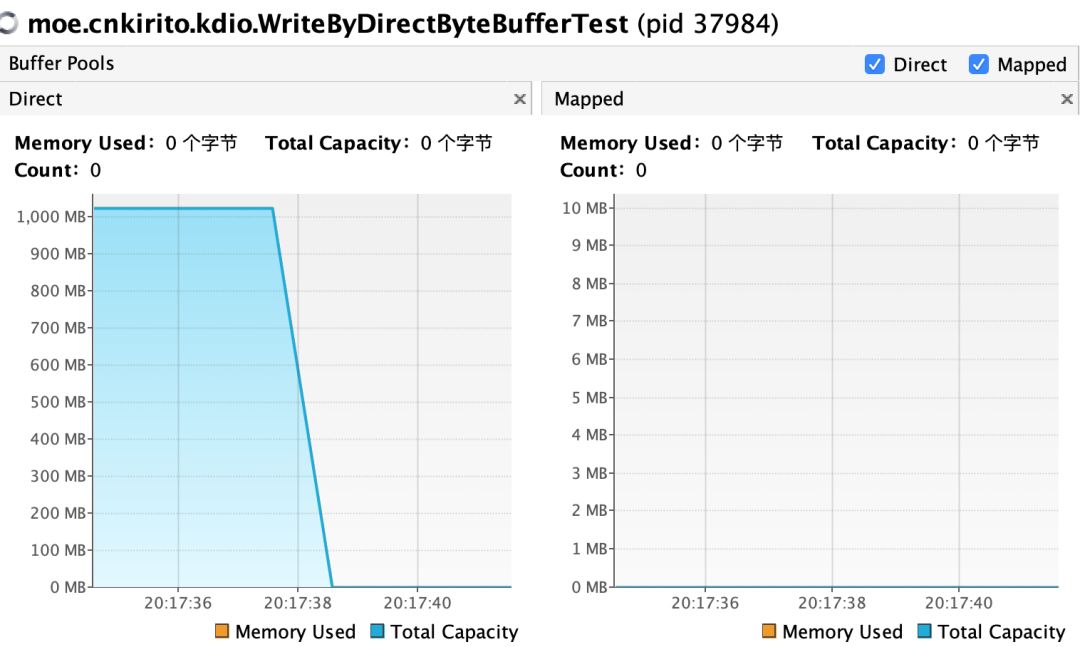
结论:GC 时会触发堆外空闲内存的回收。
CASE 3:分配 1G DirectByteBuffer,等待用户输入后,手动回收堆外内存,之后阻塞持续观察堆外内存变化
public class WriteByDirectByteBufferTest {
public static void main(String[] args) throws IOException, InterruptedException {
ByteBuffer buffer = ByteBuffer.allocateDirect(1024 * 1024 * 1024);
System.in.read();
((DirectBuffer) buffer).cleaner().clean();
new CountDownLatch(1).await();
}
}
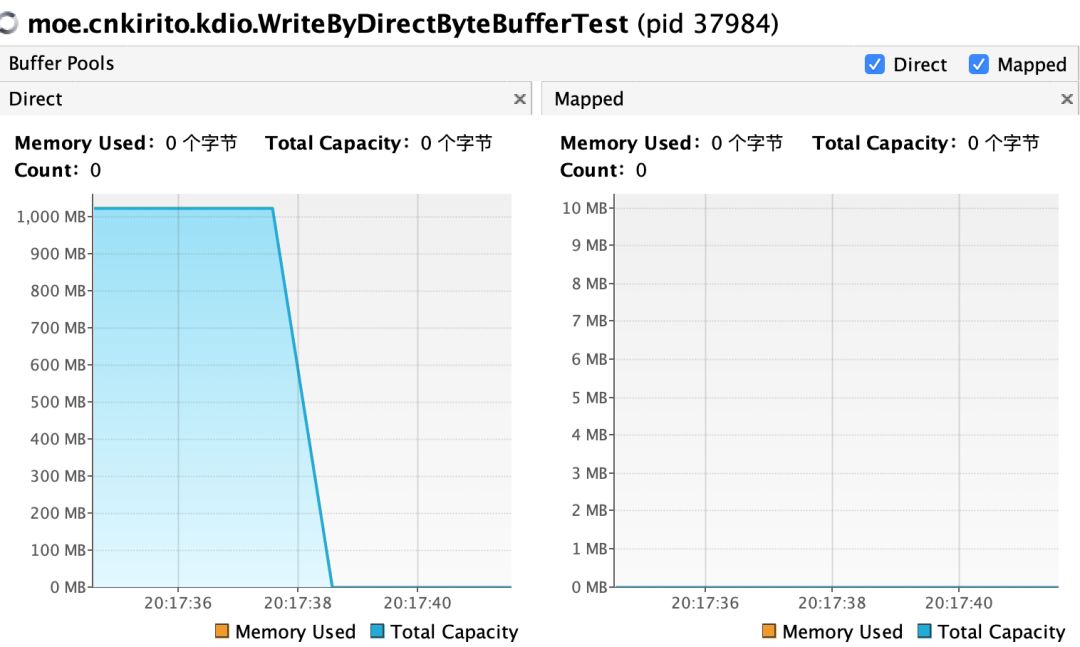
结论:手动回收可以立刻释放堆外内存,不需要等待到 GC 的发生。
对于 MappedByteBuffer 这个有点神秘的类,它的回收机制大概和 DirectByteBuffer 类似,体现在右边的 Mapped 之中,我们就不重复 CASE1 和 CASE2 的测试了,直接给出结论,在 GC 发生或者操作系统主动清理时 MappedByteBuffer 会被回收。但也不是不进行测试,我们会对 MappedByteBuffer 进行更有意思的研究。
CASE 4:手动回收 MappedByteBuffer。
public class MmapUtil {
public static void clean(MappedByteBuffer mappedByteBuffer) {
ByteBuffer buffer = mappedByteBuffer;
if (buffer == null || !buffer.isDirect() || buffer.capacity() == 0)
return;
invoke(invoke(viewed(buffer), "cleaner"), "clean");
}
private static Object invoke(final Object target, final String methodName, final Class<?>... args) {
return AccessController.doPrivileged(new PrivilegedAction<Object>() {
public Object run() {
try {
Method method = method(target, methodName, args);
method.setAccessible(true);
return method.invoke(target);
} catch (Exception e) {
throw new IllegalStateException(e);
}
}
});
}
private static Method method(Object target, String methodName, Class<?>[] args)
throws NoSuchMethodException {
try {
return target.getClass().getMethod(methodName, args);
} catch (NoSuchMethodException e) {
return target.getClass().getDeclaredMethod(methodName, args);
}
}
private static ByteBuffer viewed(ByteBuffer buffer) {
String methodName = "viewedBuffer";
Method[] methods = buffer.getClass().getMethods();
for (int i = 0; i < methods.length; i++) {
if (methods[i].getName().equals("attachment")) {
methodName = "attachment";
break;
}
}
ByteBuffer viewedBuffer = (ByteBuffer) invoke(buffer, methodName);
if (viewedBuffer == null)
return buffer;
else
return viewed(viewedBuffer);
}
}
这个类曾经在我的《文件 IO 的一些最佳实践》中有所介绍,在这里我们将验证它的作用。编写测试类:
public class WriteByMappedByteBufferTest {
public static void main(String[] args) throws IOException, InterruptedException {
File data = new File("/tmp/data.txt");
data.createNewFile();
FileChannel fileChannel = new RandomAccessFile(data, "rw").getChannel();
MappedByteBuffer map = fileChannel.map(FileChannel.MapMode.READ_WRITE, 0, 1024L * 1024 * 1024);
System.in.read();
MmapUtil.clean(map);
new CountDownLatch(1).await();
}
}
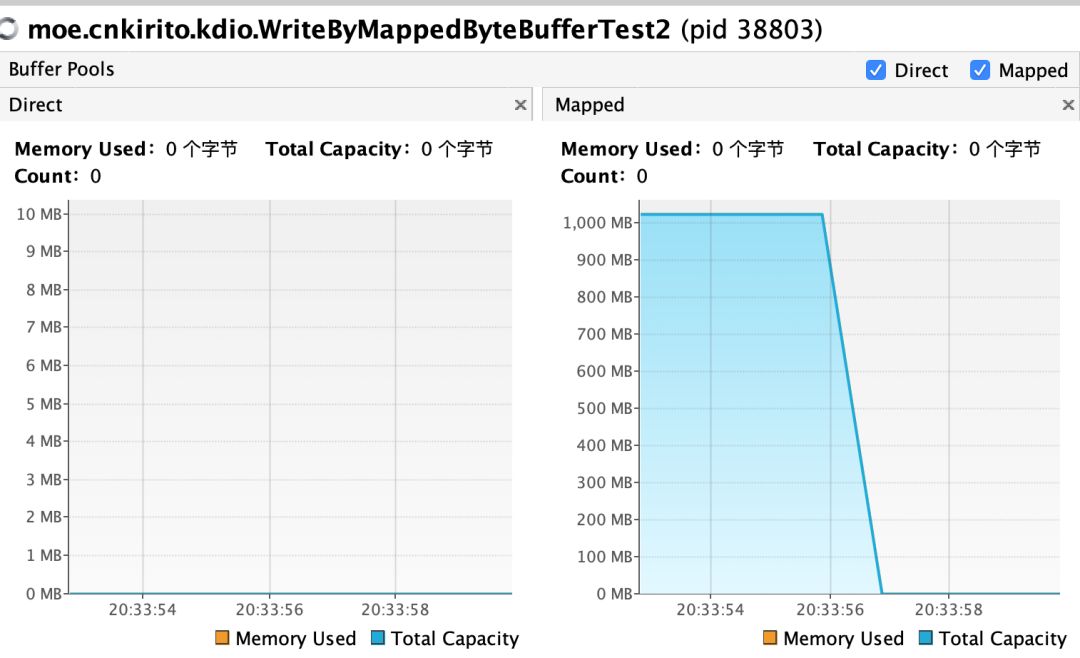
结论:通过一顿复杂的反射操作,成功地手动回收了 Mmap 的内存映射。
CASE 5:测试 Mmap 的内存占用
public class WriteByMappedByteBufferTest {
public static void main(String[] args) throws IOException, InterruptedException {
File data = new File("/tmp/data.txt");
data.createNewFile();
FileChannel fileChannel = new RandomAccessFile(data, "rw").getChannel();
for (int i = 0; i < 1000; i++) {
fileChannel.map(FileChannel.MapMode.READ_WRITE, 0, 1024L * 1024 * 1024);
}
System.out.println("map finish");
new CountDownLatch(1).await();
}
}
我尝试映射了 1000G 的内存,我的电脑显然没有 1000G 这么大内存,那么监控是如何反馈的呢?

几乎在瞬间,控制台打印出了 map finish 的日志,也意味着 1000G 的内存映射几乎是不耗费时间的,为什么要做这个测试?就是为了解释内存映射并不等于内存占用,很多文章认为内存映射这种方式可以大幅度提升文件的读写速度,并宣称“写 MappedByteBuffer 就等于写内存”,实际是非常错误的认知。通过控制面板可以查看到该 Java 进程(pid 39040)实际占用的内存,仅仅不到 100M。(关于 Mmap 的使用场景和方式可以参考我之前的文章)
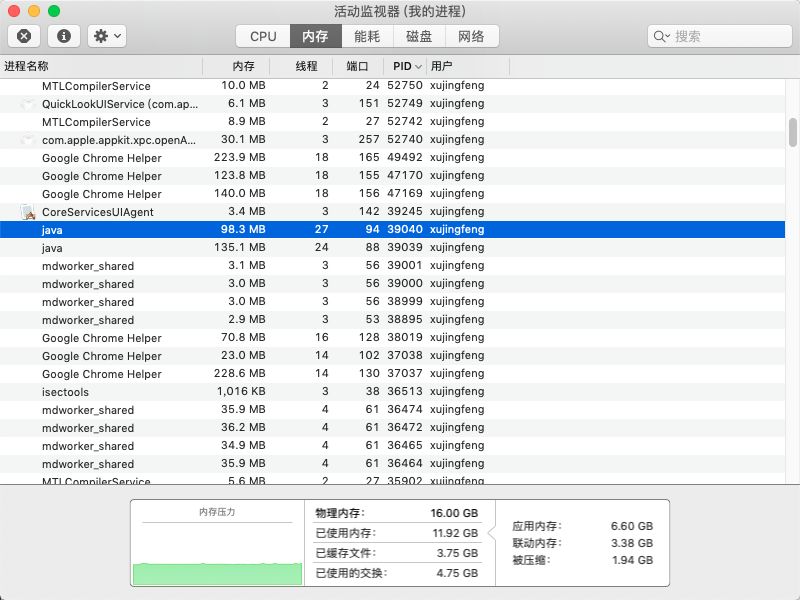
结论:MappedByteBuffer 映射出一片文件内容之后,不会全部加载到内存中,而是会进行一部分的预读(体现在占用的那 100M 上),MappedByteBuffer 不是文件读写的银弹,它仍然依赖于 PageCache 异步刷盘的机制。通过 Java VisualVM 可以监控到 mmap 总映射的大小,但并不是实际占用的内存量。
总结
本文借助一个线上问题,分析了使用堆内内存仍然会导致堆外内存分析的现象以及背后 JDK 如此设计的原因,并借助安装了插件之后的 Java VisualVM 工具进行了堆外内存的监控,进而讨论了如何正确的回收堆外内存,以及纠正了一个很多人对于 MappedByteBuffer 的错误认知。
文章来源:公众号【Kirito的技术分享】



