
JVM故障分析及性能优化系列之五:常见的Thread Dump日志案例分析原创
我们在上篇文章中详细描述了Thread Dump中Native Thread和JVM Thread线程的各种状态及描述,今天总结分析的一些原则,并详细列举一些案例进行说明。
症状及解决方案
下面列出几种常见的症状即对应的解决方案:
CPU占用率很高,响应很慢
按照《Java内存泄漏分析系列之一:使用jstack定位线程堆栈信息》中所说的方法,先找到占用CPU的进程,然后再定位到对应的线程,最后分析出对应的堆栈信息。
在同一时间多次使用上述的方法,然后进行对比分析,从代码中找到问题所在的原因。如果线程指向的是"VM Thread"或者无法从代码中直接找到原因,就需要进行内存分析,具体的见下一篇文章。
CPU占用率不高,但响应很慢
在整个请求的过程中多次执行Thread Dump然后进行对比,取得 BLOCKED 状态的线程列表,通常是因为线程停在了I/O、数据库连接或网络连接的地方。
关注点概况
在Thread Dump文件中,线程的状态分成两种:Native Thread Status和JVM Thread Status,具体的含义可以参考上一篇文章。在分析日志的时候需要重点关注如下几种线程状态:
系统线程状态为 deadlock
线程处于死锁状态,将占用系统大量资源。
系统线程状态为 waiting for monitor entry 或 in Object.wait()
如上一篇文章中所说,系统线程处于这种状态说明它在等待进入一个临界区,此时JVM线程的状态通常都是 java.lang.Thread.State: BLOCKED。
如果大量线程处于这种状态的话,可能是一个全局锁阻塞了大量线程。如果短期内多次打印Thread Dump信息,发现 waiting for monitor entry 状态的线程越来越多,没有减少的趋势,可能意味着某些线程在临界区里呆得时间太长了,以至于越来越多新线程迟迟无法进入。
系统线程状态为 waiting on condition
系统线程处于此种状态说明它在等待另一个条件的发生来唤醒自己,或者自己调用了sleep()方法。此时JVM线程的状态通常是java.lang.Thread.State: WAITING (parking)(等待唤醒条件)或java.lang.Thread.State: TIMED_WAITING (parking或sleeping)(等待定时唤醒条件)。
如果大量线程处于此种状态,说明这些线程又去获取第三方资源了,比如第三方的网络资源或读取数据库的操作,长时间无法获得响应,导致大量线程进入等待状态。因此,这说明系统处于一个网络瓶颈或读取数据库操作时间太长。
系统线程状态为 blocked
线程处于阻塞状态,需要根据实际情况进行判断。
案例分析
下面通过几个案例进行分解来获得解决问题的方法。
waiting for monitor entry 和 java.lang.Thread.State: BLOCKED
- "DB-Processor-13" daemon prio=5 tid=0x003edf98 nid=0xca waiting for monitor entry [0x000000000825f000]
- java.lang.Thread.State: BLOCKED (on object monitor)
- at beans.ConnectionPool.getConnection(ConnectionPool.java:102)
- - waiting to lock <0xe0375410> (a beans.ConnectionPool)
- at beans.cus.ServiceCnt.getTodayCount(ServiceCnt.java:111)
- at beans.cus.ServiceCnt.insertCount(ServiceCnt.java:43)
- "DB-Processor-14" daemon prio=5 tid=0x003edf98 nid=0xca waiting for monitor entry [0x000000000825f020]
- java.lang.Thread.State: BLOCKED (on object monitor)
- at beans.ConnectionPool.getConnection(ConnectionPool.java:102)
- - waiting to lock <0xe0375410> (a beans.ConnectionPool)
- at beans.cus.ServiceCnt.getTodayCount(ServiceCnt.java:111)
- at beans.cus.ServiceCnt.insertCount(ServiceCnt.java:43)
- "DB-Processor-3" daemon prio=5 tid=0x00928248 nid=0x8b waiting for monitor entry [0x000000000825d080]
- java.lang.Thread.State: RUNNABLE
- at oracle.jdbc.driver.OracleConnection.isClosed(OracleConnection.java:570)
- - waiting to lock <0xe03ba2e0> (a oracle.jdbc.driver.OracleConnection)
- at beans.ConnectionPool.getConnection(ConnectionPool.java:112)
- - locked <0xe0386580> (a java.util.Vector)
- - locked <0xe0375410> (a beans.ConnectionPool)
- at beans.cus.Cue_1700c.GetNationList(Cue_1700c.java:66)
- at org.apache.jsp.cue_1700c_jsp._jspService(cue_1700c_jsp.java:120)
上面系统线程的状态是 waiting for monitor entry,说明此线程通过 synchronized(obj) { } 申请进入临界区,但obj对应的 Monitor 被其他线程所拥有,所以 JVM线程的状态是 java.lang.Thread.State: BLOCKED (on object monitor),说明线程等待资源超时。
下面的 waiting to lock <0xe0375410> 说明线程在等待给 0xe0375410 这个地址上锁(trying to obtain 0xe0375410 lock),如果在日志中发现有大量的线程都在等待给 0xe0375410 上锁的话,这个时候需要在日志中查找那个线程获取了这个锁 locked <0xe0375410>,如上面的例子中是 “DB-Processor-14” 这个线程,这样就可以顺藤摸瓜了。上面的例子是因为获取数据库操作等待的时间太长所致的,这个时候就需要修改数据库连接的配置信息。
如果两个线程相互都被对方的线程锁锁住,这样就造成了 死锁 现象,如下面的例子所示:
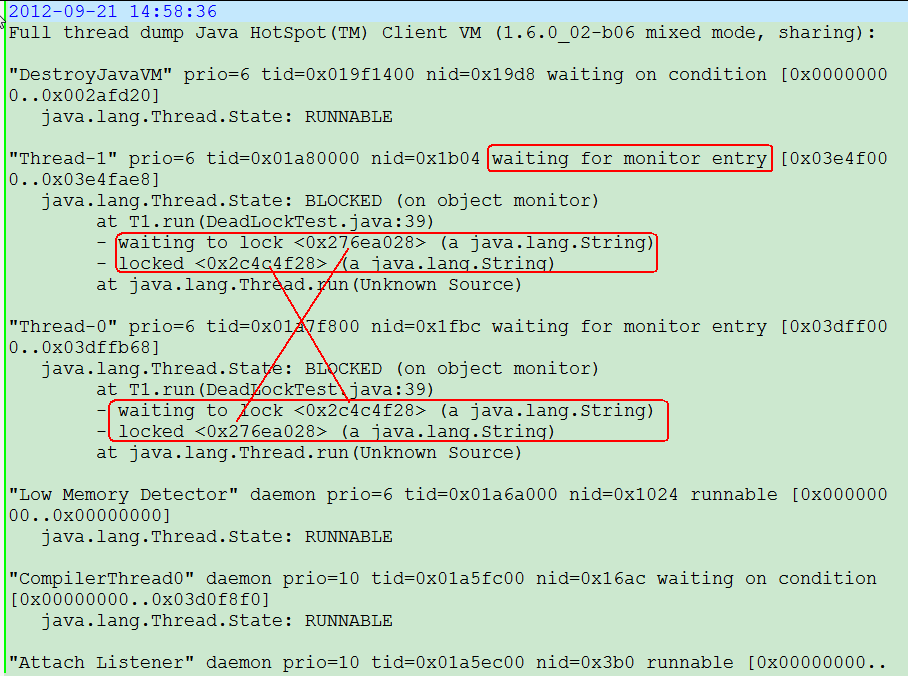
waiting on condition 和 java.lang.Thread.State: TIMED_WAITING
- "RMI TCP Connection(idle)" daemon prio=10 tid=0x00007fd50834e800 nid=0x56b2 waiting on condition [0x00007fd4f1a59000]
- java.lang.Thread.State: TIMED_WAITING (parking)
- at sun.misc.Unsafe.park(Native Method)
- - parking to wait for <0x00000000acd84de8> (a java.util.concurrent.SynchronousQueue$TransferStack)
- at java.util.concurrent.locks.LockSupport.parkNanos(LockSupport.java:198)
- at java.util.concurrent.SynchronousQueue$TransferStack.awaitFulfill(SynchronousQueue.java:424)
- at java.util.concurrent.SynchronousQueue$TransferStack.transfer(SynchronousQueue.java:323)
- at java.util.concurrent.SynchronousQueue.poll(SynchronousQueue.java:874)
- at java.util.concurrent.ThreadPoolExecutor.getTask(ThreadPoolExecutor.java:945)
- at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:907)
- at java.lang.Thread.run(Thread.java:662)
JVM线程的状态是 java.lang.Thread.State: TIMED_WAITING (parking),说明线程处于定时等待的状态,parking指线程处于挂起中。
waiting on condition需要结合堆栈中的 parking to wait for <0x00000000acd84de8> (a java.util.concurrent.SynchronousQueue$TransferStack) 一起来分析。首先,本线程肯定是在等待某个条件的发生来把自己唤醒。其次,SynchronousQueue并不是一个队列,只是线程之间移交信息的机制,当我们把一个元素放入到 SynchronousQueue 中的时候必须有另一个线程正在等待接受移交的任务,因此这就是本线程在等待的条件。
in Object.wait() 和 java.lang.Thread.State: TIMED_WAITING
- "RMI RenewClean-[172.16.5.19:28475]" daemon prio=10 tid=0x0000000041428800 nid=0xb09 in Object.wait() [0x00007f34f4bd0000]
- java.lang.Thread.State: TIMED_WAITING (on object monitor)
- at java.lang.Object.wait(Native Method)
- - waiting on <0x00000000aa672478> (a java.lang.ref.ReferenceQueue$Lock)
- at java.lang.ref.ReferenceQueue.remove(ReferenceQueue.java:118)
- - locked <0x00000000aa672478> (a java.lang.ref.ReferenceQueue$Lock)
- at sun.rmi.transport.DGCClient$EndpointEntry$RenewCleanThread.run(DGCClient.java:516)
- at java.lang.Thread.run(Thread.java:662)
本例中JVM线程的状态是 java.lang.Thread.State: TIMED_WAITING (on object monitor),说明线程调用了 java.lang.Object.wait(long timeout) 方法而进入了等待状态。
"Wait Set"中等待的线程状态就是 in Object.wait(),当线程获得了 Monitor进入临界区之后,如果发现线程继续运行的条件没有满足,它就调用对象(通常是被 synchronized 的对象)的wait()方法,放弃了Monitor,进入 “Wait Set” 队列中。只有当别的线程在该对象上调用了 notify()或notifyAll()方法, “Wait Set” 队列中线程才得到机会去竞争,但是只有一个线程获得对象的 Monitor,恢复到的运行态。
另外需要注意的是,是先 locked <0x00000000aa672478> 然后再 waiting on <0x00000000aa672478>,之所以如此,可以通过下面的代码进行演示:
- static private class Lock { };
- private Lock lock = new Lock();
- public Reference<? extends T> remove(long timeout) {
- synchronized (lock) {
- Reference<? extends T> r = reallyPoll();
- if (r != null) return r;
- for (;;) {
- lock.wait(timeout);
- r = reallyPoll();
- // ……
- }
- }
线程在执行的过程中,先用 synchronized 获得了这个对象的 Monitor(对应 locked <0x00000000aa672478>),当执行到 lock.wait(timeout); 的时候,线程就放弃了Monitor的所有权,进入 “Wait Set” 队列(对应 waiting on <0x00000000aa672478>)。
前面几篇文章详细说明了如何分析Thread Dump文件,除此之外还可以通过分析JVM堆内存信息来进一步找到问题的原因。
原文链接:https://www.javatang.com/archives/2017/10/26/08572060.html
系列阅读



