
GC 实战—浮动内存导致的 CPU 过高调优原创
由于接入的应用越来越多,对系统性能要求越来越高,提高系统的吞吐率,以及提升性能,是我们春节战役期间必须要做的事情。
系统的性能优化不单单是对 JVM 的参数调优,也不是某一段代码的改造,而是一个系统的工程,往往会出现牵一发而动全身,简单的解决,很容易治标不治本从而掩盖问题的本质,而这些深藏的问题才是我们解决问题关键。
本次的浮动内存发现就是一次扑朔迷离的查找过程,CPU 利用率过高,常见的问题都是线程使用不当造成的。但从这个方向去解决,你会发现很难解决本次的 CPU 过高问题,甚至效果不明显,若是从整个系统的各个指标协同分析验证,才会找到解决的最佳方案。
一、现象
高峰期报警频繁
服务一般的高峰期都是晚上的 19 点—22 点左右,期间的访问 QPS 可达到日间的 2 倍左右,访问量过大,机房的机器报警就接踵而至:
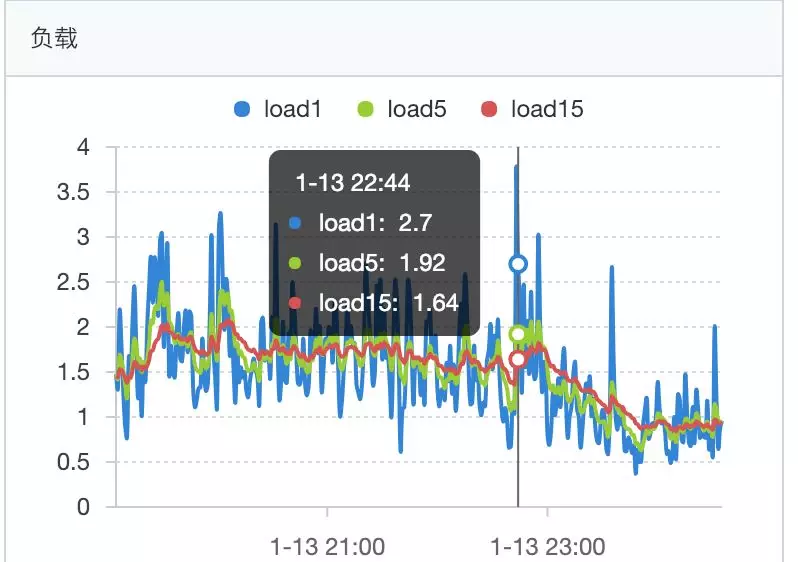
load1 过高 4 以上,CPU 利用率达到 40% 以上。
一般的尽快解决方案都是扩容,加更多的机器来分流,但这只是一个临时的方案,浪费资源不说,还会掩盖真实问题。
监控信息
JVM 内存
load
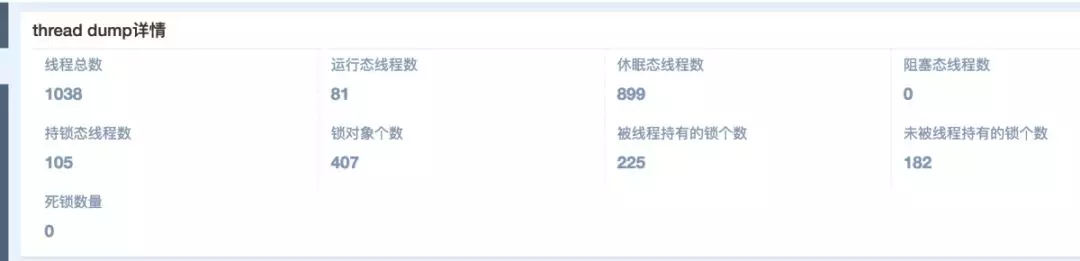
线程:
基于监控信息,我们发现以下问题:
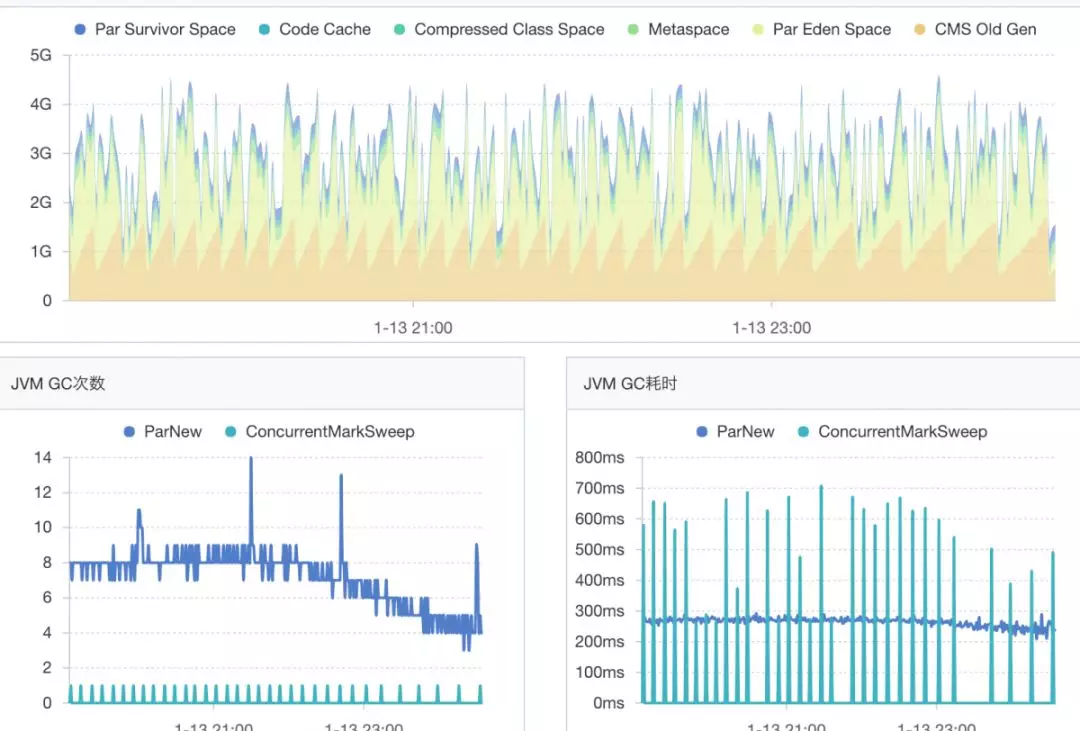
-
10 分钟 oldGC 一次,每个波峰间隔时间 8-10 分钟左右。
-
CPU load 过高,高峰期常在 load1 在 2-6 之间浮动(4核),cpu 利用率在 14%—46% 之间浮动。
-
JVM 的内存的波峰波谷过于频繁,不是长方体或椭圆形,呈锯齿状线程过多,单个系统线程达到 1000 以上。
二、分析
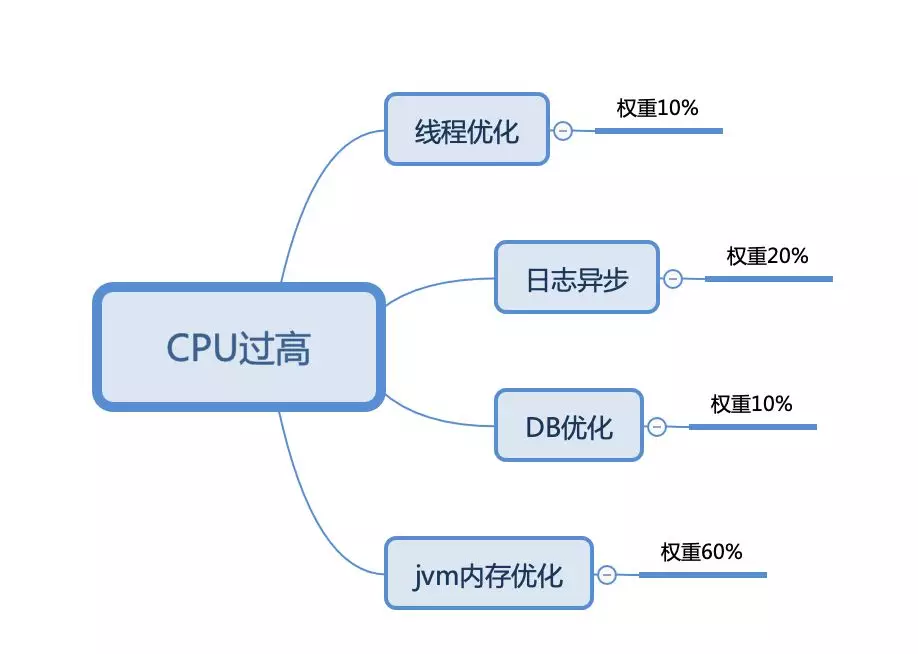
基于监控反馈的信息我们可以从以下几个点着手:
按道理来说 CPU 过高我们最应该从线程优化这个点入手,但通过监控信息的对比,我们发现,最严重的问题还是来之 JVM 内存管理。
从上图我们可以看出 oldGC 过于频繁:
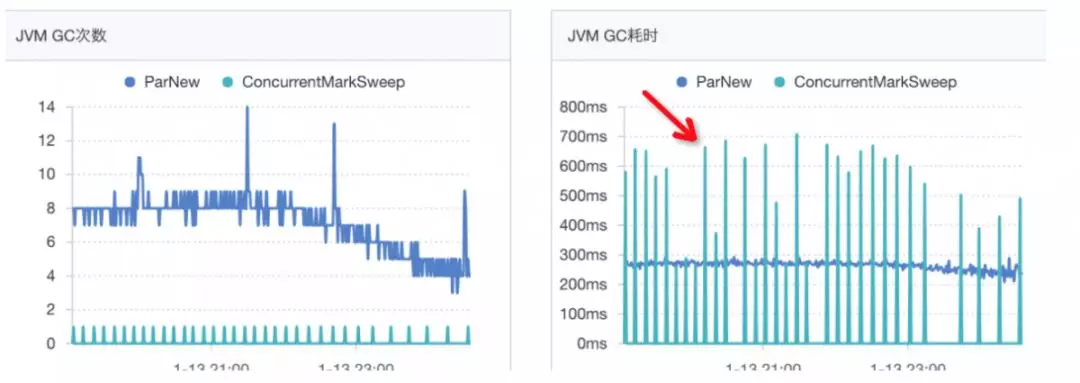
10 分钟 oldGC 一次,每个波峰间隔时间 8-10 分钟左右。
这是一个重要的信息,我们可以理解为由于频繁 GC 导致 CPU 利用率上升,因此降低 GC 的频率是我们的首要任务。
三、第一次尝试-GC 调优
GC调优我们很容易想到的方案,是调整新生代和老生代的比率,提升新生代看空间,降低 SurvivorRatio,从而延缓新生代的晋升。由于第一版的了解过于肤浅和紧急,我们的方案简单粗暴:
-
Total Head 提升 1g
-
ParNew head 提升 1g
-
SurvivorRatio 10->7
上面的结果可想而知,效果很勉强。
-
oldGC 从 8-10 分钟,改变问 10—12 分钟,提升 10% 左右
-
CPU 利用率 高峰期最高 46%,load1 (2-6)没变化
四、第二次尝试-浮动内存调优
鉴于第一次分析不仔细,我们在需要对 JVM 内存进行 Dump 分析,看下具体是什么原因导致 old 不断 GC。
我们借助以下工具:
-
Eagleeye
-
Zprofiler
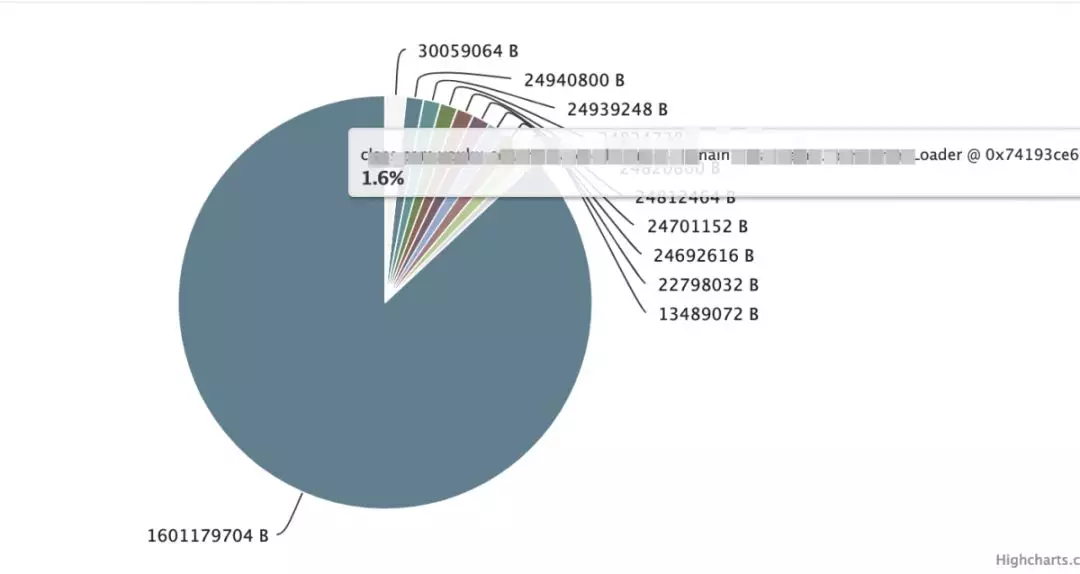
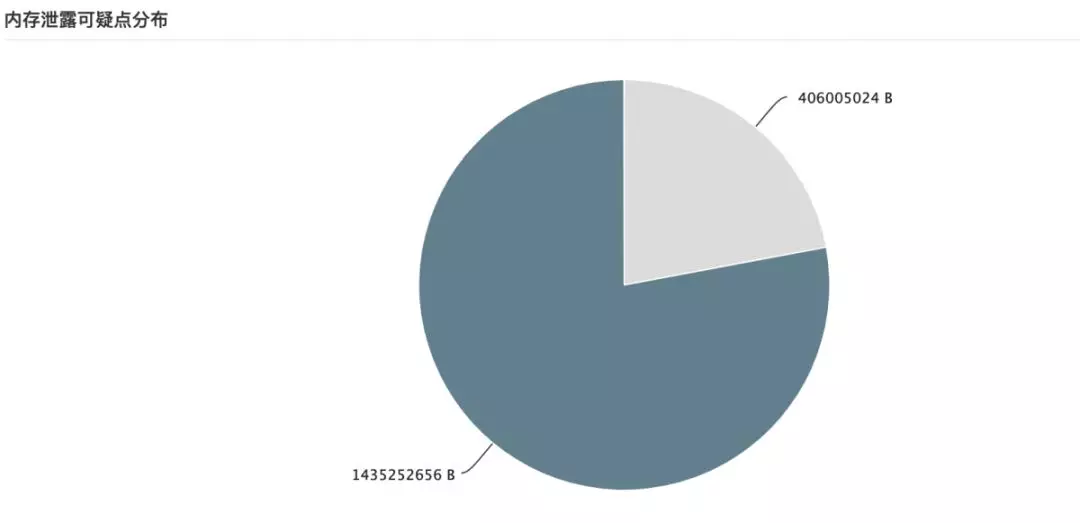
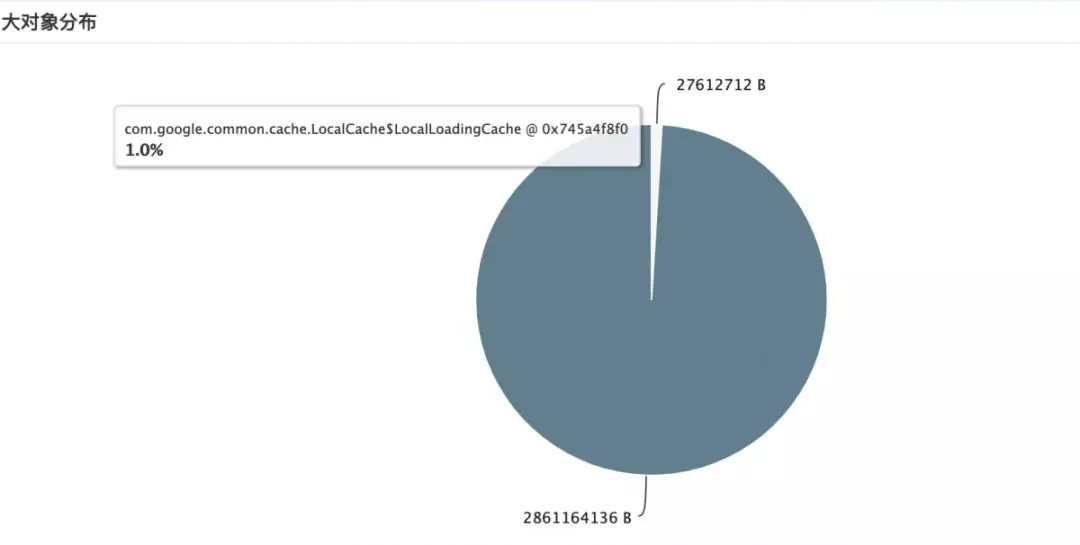
从 Dump 下的 head 信息,我们看到,有两部分占用内存过高。
内存泄漏可疑点分析:
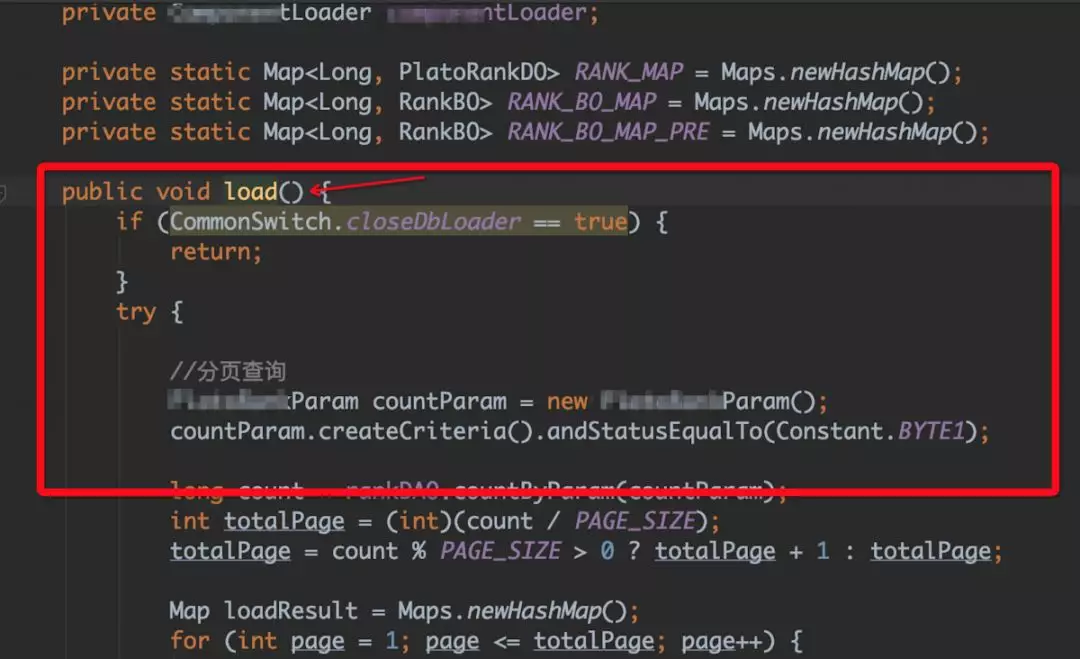
通过 head 占比分析,我们发现一些数据库 load 对象很可疑,使用了大量的 hashMap 缓存数据。通过追踪代码,我们发现以下问题:
以上代码是从数据库定时 load 数据到内存中,每次 load 之后,之前的 map 对象被遗弃。造成的现象:
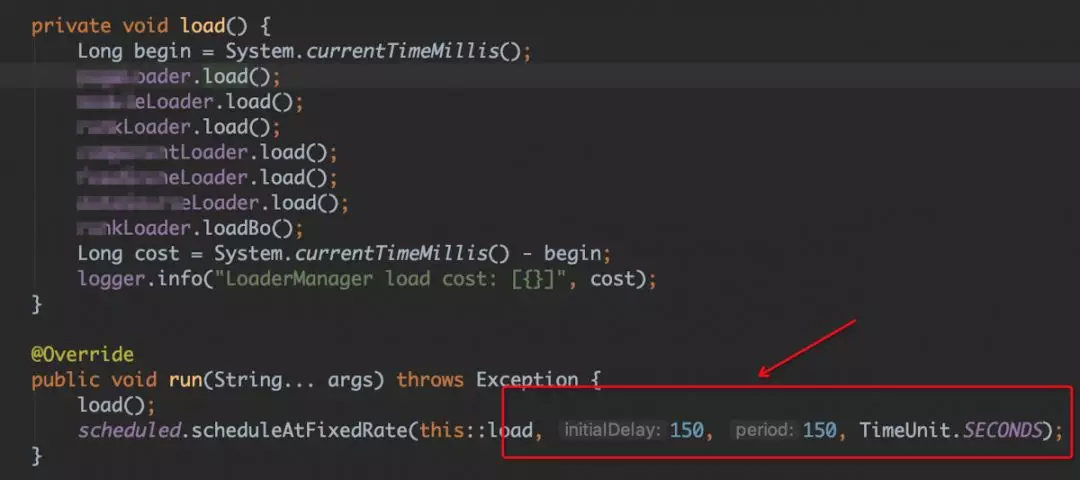
-
每隔一段时间(5 分钟以内)会有一批大对象被释放
-
大对象会随着系统的运营时长以及新应用的加入,越来越大
-
浮动对象是用来解决缓存被动更新的问题
-
浮动大对象对GC造成很大的压力,大量的浮动对象在新生代没有被释放就晋升到老年代,造成老年代频繁 GC
通过以上分析,我们可以定位频繁 GC 的主要问题就是 load 里面的map,由于不断的废弃,造成了大量的浮动大对象造成的。
通过扫描,我们发现系统中由于没有引入统一的缓存架构,大量需要缓存的代码,都采用这种 定时废弃的方式来进行。
如此多的代码,改动工作量还是很大的,这也促进我们对 YKCache 框架的推出,YKCache 主要用来改善缓存的统一管理接入工作,热点缓存的维护,以及多级缓存(local+tair+db)的支持。
YKCache 特点:
-
多级缓存(local+tair+db),
-
热点数据支持自动维护。
-
低侵入接入,不改造代码
-
缓存支持主动更新和被动更新
在引入 YKCache 之后,我们对内存占比最大的两个 load 进行改造,同时移除某个二方包里面的 loadMap,对此我们队 head 进行观察。
我们可以看到,load 的 map 内存占用比降低了,因为缓存框架的引入,内存中不必缓存全部数据,只维护热点数据,内存占比降低了 60% 以上。同时热点缓存直接接入老年代,减少了老年代的 GC 频率。
但是这并不是终点,GC 依然没有达到我们想要的目标。
五、第三次尝试-浮动内存+GC调优
以上我虽然解决的浮动内存的问题,但是我们还有一个问题忽略了,就是:
对象晋升的问题
对象晋升
我们知道对象晋升达到以下两个条件之一就可以发生:
-
minor gc 之后,存活于 survivor 区域的对象的 age 会+1,当超过(默认)15 的时候,转移到老年代。
-
动态对象,如果 survivor 空间中相同年龄所有的对象大小的综合和大于 survivor 空间的一半,年级大于或等于该年级的对象就可以直接进入老年代。
我们通过加入 PrintTenuringDistribution 参数,观察对象的晋升情况。
Desired survivor size 178946048 bytes, new threshold 15 (max 15)
- age 1: 88665064 bytes, 88665064 total
- age 2: 40523456 bytes, 129188520 total
- age 3: 40853440 bytes, 170041960 total
: 2722627K->253593K(2796224K), 0.2869541 secs] 3523830K->1114986K(4893376K), 0.2876559 secs] [Times: user=0.68 sys=0.02, real=0.29 secs]
2019-01-23T14:49:48.763+0800: 72770.431: [GC (Allocation Failure) 2019-01-23T14:49:48.763+0800: 72770.431: [ParNew
Desired survivor size 178946048 bytes, new threshold 4 (max 15)
- age 1: 93440696 bytes, 93440696 total
- age 2: 16810912 bytes, 110251608 total
- age 3: 35219480 bytes, 145471088 total
- age 4: 40484456 bytes, 185955544 total
: 2700313K->280078K(2796224K), 0.1973428 secs] 3561706K->1141471K(4893376K), 0.1982309 secs] [Times: user=0.46 sys=0.01, real=0.20 secs]
2019-01-23T14:49:59.610+0800: 72781.278: [GC (Allocation Failure) 2019-01-23T14:49:59.611+0800: 72781.279: [ParNew
Desired survivor size 178946048 bytes, new threshold 15 (max 15)
- age 1: 88155400 bytes, 88155400 total
- age 2: 14958464 bytes, 103113864 total
- age 3: 10194096 bytes, 113307960 total
- age 4: 35023952 bytes, 148331912 total
: 2726798K->188190K(2796224K), 0.2553227 secs] 3588191K->1089172K(4893376K), 0.2560257 secs] [Times: user=0.54 sys=0.00, real=0.25 secs]
通过以上日志我们可以发现,大量的对象在 age 很小的时候就晋升了,这说明两个问题:
-
新生代空间不足
-
survivor 空间不足
但问题 1 和 2 已经扩大了,我们不可能无限扩大,由于我们是互联网应用,大量请求到来的时候,会产生大量的临时对象,我们需要考虑的是让这些临时对象尽可能的留在新生代,而不是晋升。
我们可以提高 from 区的利用率。
TargetSurvivorRatio
我们可以尝试加上-XX:TargetSurvivorRatio=90,提高 from 区的利用率,使 from 区使用到 90% 时,再讲对象送入到老年代。
加上-XX:TargetSurvivorRatio=90,之后我们观察gc日志:
Desired survivor size 414115424 bytes, new threshold 15 (max 15)
age 1: 53927288 bytes, 53927288 total
age 2: 20714864 bytes, 74642152 total
age 3: 7596264 bytes, 82238416 total
age 4: 3017336 bytes, 85255752 total
age 5: 3873704 bytes, 89129456 total
age 6: 6201984 bytes, 95331440 total
age 7: 5167776 bytes, 100499216 total
age 8: 5968880 bytes, 106468096 total
age 9: 13705944 bytes, 120174040 total
age 10: 2725960 bytes, 122900000 total
age 11: 5891312 bytes, 128791312 total
age 12: 15099224 bytes, 143890536 total
age 13: 3007408 bytes, 146897944 total
age 14: 1947336 bytes, 148845280 total
age 15: 879432 bytes, 149724712 total: 2425961K->195062K(2696384K), 0.1951935 secs] 3259218K->1028912K(4793536K), 0.1957401 secs] [Times: user=0.42 sys=0.06, real=0.20 secs]2019-02-17T21:07:53.115+0800: 205984.589: [GC (Allocation Failure) 2019-02-17T21:07:53.115+0800: 205984.590: [ParNewDesired survivor size 414115424 bytes, new threshold 15 (max 15)
age 1: 61925600 bytes, 61925600 total
age 2: 22640624 bytes, 84566224 total
age 3: 6638528 bytes, 91204752 total
age 4: 5696944 bytes, 96901696 total
age 5: 2959920 bytes, 99861616 total
age 6: 3602640 bytes, 103464256 total
age 7: 6189360 bytes, 109653616 total
age 8: 5161344 bytes, 114814960 total
age 9: 5949672 bytes, 120764632 total
age 10: 13695168 bytes, 134459800 total
age 11: 2725096 bytes, 137184896 total
age 12: 4659184 bytes, 141844080 total- age 13: 14082208 bytes, 155926288 total- age 14: 2899928 bytes, 158826216 total
age 15: 1929920 bytes, 160756136 total: 2442102K->196395K(2696384K), 0.1910995 secs] 3275952K->1031074K(4793536K), 0.1916514 secs] [Times: user=0.45 sys=0.00, real=0.20 secs]
基于以上日志我们可以看出,对象的年龄多数晋升到MaxTenuringThreshold(默认值15)设置的值才完成晋升。另外我们还可以把大对象直接送入到老年代,通过设置-XX:PetenureSizeThreshold,设置大对象直接进入年老代的阈值。当对象的大小超过这个值时,将直接在年老代分配。
优化结果
基于上述优化之后的结果。
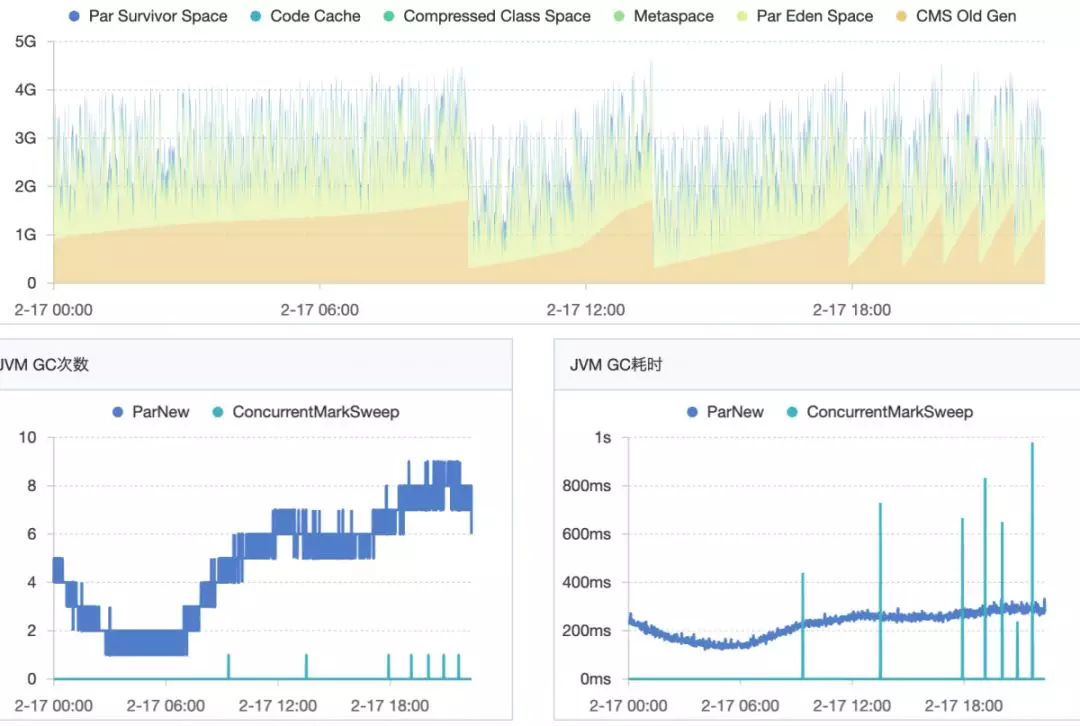
可以看到上图中:
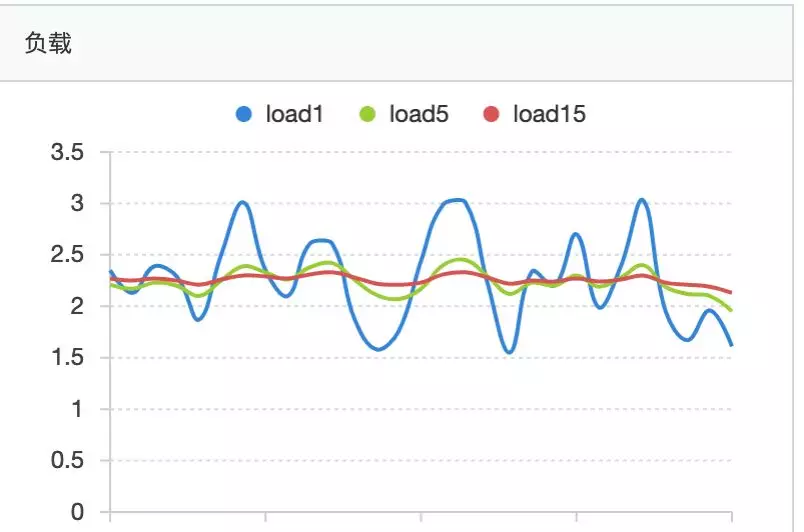
-
高峰期,oldGC 从10分钟提升到50分钟一次
-
低峰期,oldGc 6小时1次
-
cpu利用率 高峰期 从46% 降低到26%
-
load从2-6区间,降低到1.4-3区间
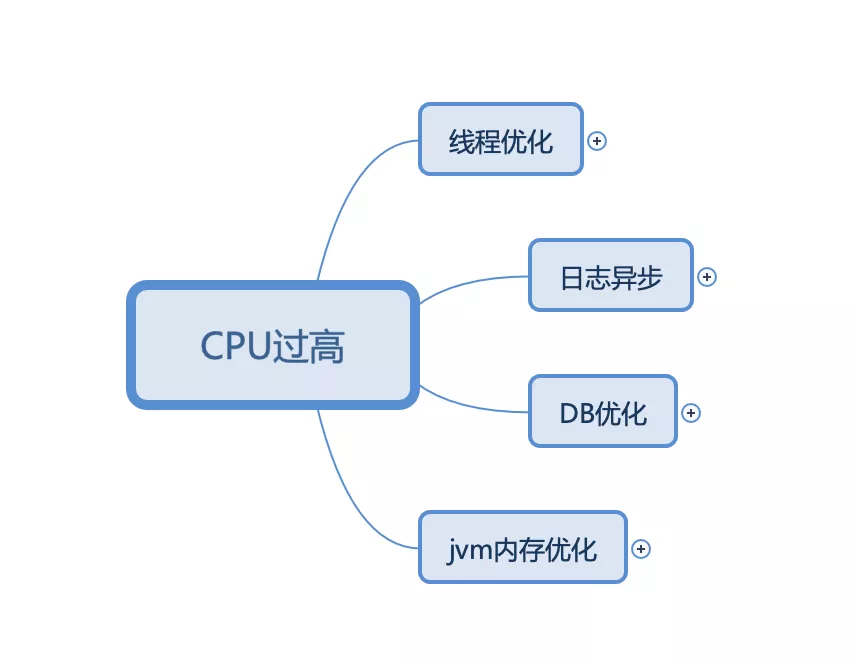
六、其他优化
线程优化
线程优化主要着重于线程池的优化,系统大量使用线程池,但对线程池的滥用也会造成资源的浪费,基于此有以下建议:
CPU 密集型任务配置尽可能小的线程,建议Ncpu+1 个。
IO 密集型任务,线程多数在等待,配置尽可能多的线程,建议 2*Ncpu。
不建议maxPoolSize设置的过大,多开线程解决不了问题,加大CPU管理负担。
超时时间不必太长,加大下游负担
日志异步
线上由于用户基数大,产生的日志量也大,如果没对日志进行异步写处理,会导致这一块会耗费大量的资源在IO上,所以日志异步队列化,也是提升系统性能的必不可少的。
DB优化
DB的优化主要主要体现在慢查询的优化,这一块集团提供的iDB工具已经很好的支持,定期的去查看下DB性能,针对慢查询的sql语句优化也是必不可少的优化缓解。
性能调优层次
为了提升系统性能,我们需要对系统的各个角度和层次来进行优化,针对系统的调优不是只有jvm调优一项,而是需要针对系统来整体调优,才能提升系统的性能。我们不能指望一个系统架构有缺陷或者代码层次优化没有穷尽的应用,通过jvm调优令其达到一个质的飞跃,这是不可能的。
本文作者:大码侯
关注个人成长和游戏研发,致力于推进国内游戏技术社区的进步。


