
jstat显示的full GC次数与CMS周期的关系原创
使用Oracle/Sun JDK来运行Java程序的时候,大家或许有用过jstat工具来观察GC的统计数据,例如上一篇日志里的
Command prompt代码
$ jstat -gcutil `pgrep -u admin java`
S0 S1 E O P YGC YGCT FGC FGCT GCT
37.21 0.00 99.81 12.87 76.82 1767 196.843 3085 2998.088 3194.931
以前写过一帖说明jstat工具显示的读数与jvmstat计数器之前的关系:用Java获取full GC的次数?(2)
可以知道,FGC列表示的是full GC次数,对应的jvmstat计数器是sun.gc.collector.1.invocations:
Text代码
column {
header "^FGC^" /* Full Collections */
data sun.gc.collector.1.invocations
align right
width 5
scale raw
format "0"
}
但是这个计数器在CMS GC里到底是指什么的次数呢?
在JDK 6的HotSpot VM中,Oracle/Sun有官方支持的GC只有CMS比较特殊(Garbage-First在JDK6里还没正式支持,不算在内):其它几种GC的每个周期都是完全stop-the-world的;而CMS的每个并发GC周期则有两个stop-the-world阶段——initial mark与final re-mark,其它阶段是与应用程序一起并发执行的。
Memory Management in the Java HotSpot™ Virtual Machine 写道
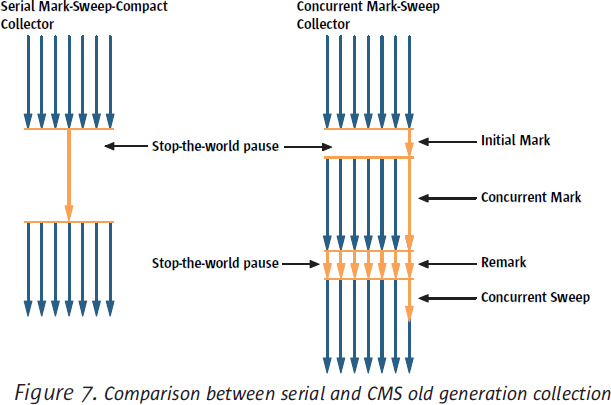
如果CMS并发GC过程中出现了concurrent mode failure的话那么接下来就会做一次mark-sweep-compact的full GC,这个是完全stop-the-world的。
正是这个特征,使得CMS的每个并发GC周期总共会更新full GC计数器两次,initial mark与final re-mark各一次;如果出现concurrent mode failure,则接下来的full GC自己算一次。
如果说大家关心“GC次数”主要关心的其实是应用暂停次数的话,这么做倒也合理。但要注意的是在CMS里“暂停次数”并不等同于“GC次数”,CMS并发GC的一个周期叫“一次GC”但暂停了两次。
只不过有些人在从其它GC改为用CMS的时候会对“full GC次数”的显著增加感到不满,觉得是不是应该想办法调优来让“full GC次数”降下来。这里有几点:
1、CMS GC的设计初衷就是以降低GC latency为目标。如果一个应用产生垃圾的速度非常高的话,原本清除那些垃圾需要的时间并不会消失,CMS只是把它从一个大暂停分散到了多个阶段上,其中部分是暂停的,部分是并发的。所以暂停的次数本来就应该会增加,而每次停顿的时间则应该比较短——这是设计取舍的倾向性导致的。
2、为了更有效的实现并发,CMS GC进行的过程中必须保证堆里还有足够剩余空间来留给应用去分配对象,所以比起ParallelScavenge等别的实现CMS必须要提早一些触发并发GC的启动。如果从ParallelScavange迁移到CMS的时候不同事增大GC堆的大小,那么可以看到同样的应用在GC堆的占用率更低的时候就会触发GC了,所以GC次数增加了。
3、CMS GC中,“full GC次数”的计数器在每个并发GC周期里是增加2而不是增加1的。这也就是这篇日志最想说明的点:这个计数器说明了GC造成的应用暂停的次数,但并不代表CMS的并发GC周期的个数。由于full GC的计数器也会在完全stop-the-world的full GC中增加1,所以这个计数器也不准确代表并发GC周期个数的正好两倍。
4、一个CMS并发GC周期的触发原因只有一个;其中的两次暂停都是同一个原因引致的,例如说最初CMS old gen或者perm gen的使用率已经超过了某个阈值之类。
实现细节感兴趣的同学们,看代码~
CMSCollector里有_gc_counters用于记录jvmstat(或者说PerfData)需要的统计数据。这是个CollectorCounters类型的对象,里面有_invocations成员是用来记录GC次数的。
C++代码
CollectorCounters::CollectorCounters(const char* name, int ordinal) {
if (UsePerfData) {
EXCEPTION_MARK;
ResourceMark rm;
const char* cns = PerfDataManager::name_space("collector", ordinal);
_name_space = NEW_C_HEAP_ARRAY(char, strlen(cns)+1);
strcpy(_name_space, cns);
// ...
cname = PerfDataManager::counter_name(_name_space, "invocations");
_invocations = PerfDataManager::create_counter(SUN_GC, cname,
PerfData::U_Events, CHECK);
// ...
}
}
TraceCollectorStats用于辅助记录GC的次数。它在构造器里会将传入的CollectorCounters的invocation_counter()计数器自增1(自增1的具体逻辑在其基类的PerfTraceTimedEvent的构造器里)。
C++代码
class TraceCollectorStats: public PerfTraceTimedEvent {
protected:
CollectorCounters* _c;
public:
inline TraceCollectorStats(CollectorCounters* c) :
PerfTraceTimedEvent(c->time_counter(), c->invocation_counter()),
_c(c) {
if (UsePerfData) {
_c->last_entry_counter()->set_value(os::elapsed_counter());
}
}
inline ~TraceCollectorStats() {
if (UsePerfData) _c->last_exit_counter()->set_value(os::elapsed_counter());
}
};
C++代码
class PerfTraceTimedEvent : public PerfTraceTime {
protected:
PerfLongCounter* _eventp;
public:
inline PerfTraceTimedEvent(PerfLongCounter* timerp, PerfLongCounter* eventp): PerfTraceTime(timerp), _eventp(eventp) {
if (!UsePerfData) return;
_eventp->inc();
}
inline PerfTraceTimedEvent(PerfLongCounter* timerp, PerfLongCounter* eventp, int* recursion_counter): PerfTraceTime(timerp, recursion_counter), _eventp(eventp) {
if (!UsePerfData) return;
_eventp->inc();
}
};
计数器增加1就是这里的_eventp->inc();
HotSpot里每个stop-the-world行为都用一个VM_Operation包装起来。与CMS相关的两个VM_Operation就是VM_CMS_Initial_Mark与VM_CMS_Final_Mark。
C++代码
// The VM_CMS_Operation is slightly different from
// a VM_GC_Operation -- and would not have subclassed easily
// to VM_GC_Operation without several changes to VM_GC_Operation.
// To minimize the changes, we have replicated some of the VM_GC_Operation
// functionality here. We will consolidate that back by doing subclassing
// as appropriate in Dolphin.
//
// VM_Operation
// VM_CMS_Operation
// - implements the common portion of work done in support
// of CMS' stop-world phases (initial mark and remark).
//
// VM_CMS_Initial_Mark
// VM_CMS_Final_Mark
//
这两个VM_Operation的核心部分都调用了下面这个函数:
C++代码
void CMSCollector::do_CMS_operation(CMS_op_type op) {
gclog_or_tty->date_stamp(PrintGC && PrintGCDateStamps);
TraceCPUTime tcpu(PrintGCDetails, true, gclog_or_tty);
TraceTime t("GC", PrintGC, !PrintGCDetails, gclog_or_tty);
TraceCollectorStats tcs(counters());
switch (op) {
case CMS_op_checkpointRootsInitial: {
SvcGCMarker sgcm(SvcGCMarker::OTHER);
checkpointRootsInitial(true); // asynch
if (PrintGC) {
_cmsGen->printOccupancy("initial-mark");
}
break;
}
case CMS_op_checkpointRootsFinal: {
SvcGCMarker sgcm(SvcGCMarker::OTHER);
checkpointRootsFinal(true, // asynch
false, // !clear_all_soft_refs
false); // !init_mark_was_synchronous
if (PrintGC) {
_cmsGen->printOccupancy("remark");
}
break;
}
default:
fatal("No such CMS_op");
}
}
留意到其中的TraceCollectorStats tcs(counters());了么?这就让full GC的计数器增加了1。
也就是说CMS GC的两个暂停阶段各自会让full GC计数器增加1,于是整个CMS并发GC周期里该计数器就会增加2了。
追加:有人提醒我有这么一篇文章:
JDK6 Update 23 changes CMS Collection counters
所以顺便一提,我这篇blog用的是JDK 6 update 25对应的HotSpot 20来讲的。
如果大家关注JMX读出来CMS collections次数,请留意一下上面链接的文章。



