
一次 Young GC 的优化实践(FinalReference 相关)原创
前言
博客已经好久没有更新了,主要原因是 18 年下半年工作比较忙,另外也没有比较有意思的题材,所以迟迟没有更新。
此篇是 18 年底的微信上的某同学提供的一个 Young GC 问题案例,找我帮忙解决。这个 GC 案例比较有意思,虽然过去有一段时间了,但是想想觉得还是有必要写出来,应该对大家很有帮助。
排查问题有点像侦探断案,先分析各种可能性,再按照获得的一个个证据,去排除各种可能性、然后定位原因,最终解决问题。
问题
某同学在微信上问我,有没有办法排查 YoungGC 效率低的问题?听到这话,我也是不知从何说起,就让他说下具体情况。
具体情况是:
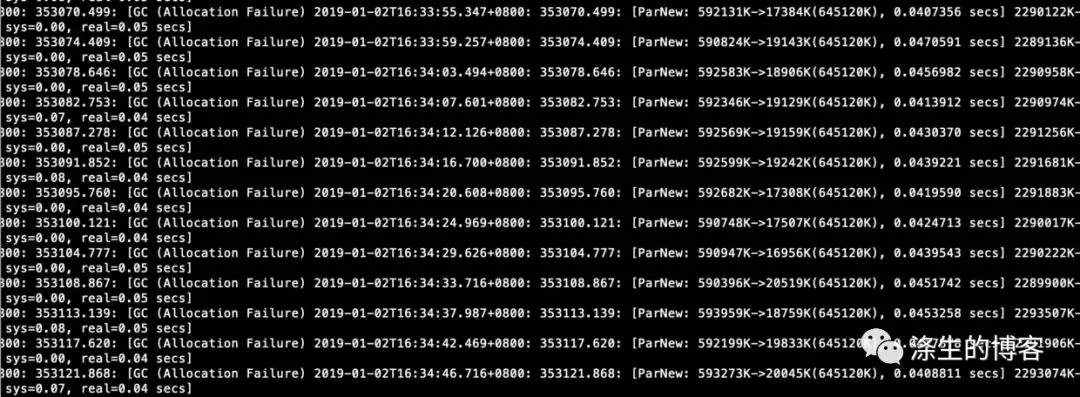
有个服务在没有 RPC 调用时,YoungGC 时间大约在 4-5ms,但是有 RPC 调用时,YoungGC 的耗时在 40ms 以上,几乎没有什么对象晋升,频率 4-5 秒一次。GC 日志截图如下。
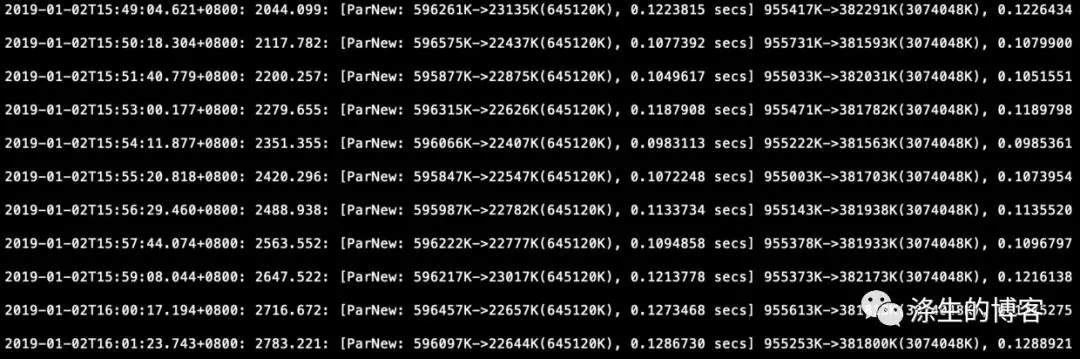
后来他为了排查问题,把服务只留一个 RPC 调用,结果 YoungGC 更严重,变成 100ms 以上,几乎没有什么对象晋升,另外 RPC 调用耗时在 4-5ms,压测的 QPS 也比较低,只有几个线程在压。GC 日志截图如下。
另外还有一个奇葩的现象,如果测试时,只留一个调用耗时更长的 RPC 进行测试,发现 Young GC 耗时会小一点。
这里也提供下提供了下 GC 参数如下:
- //GC 参数
- -Xmn700m -Xms3072m -Xmx3072m -XX:SurvivorRatio=8
- -XX:MetaspaceSize=384m -XX:MaxMetaspaceSize=384m -XX:+UseConcMarkSweepGC
- -XX:+CMSScavengeBeforeRemark -XX:CMSInitiatingOccupancyFraction=80
- -XX:+UseCMSInitiatingOccupancyOnly -XX:+PrintGC -XX:+PrintGCDateStamps
- -XX:+PrintGCDetails
可以看到,整个堆 3072M,Young Gen只有 700M,都不大。
疑惑
从上述问题来看可以判断出:RPC 调用影响了 YoungGC 的时间。
但是你一定有很多疑惑:
-
为什么进行 RPC 调用和不进行 RPC 调用相比 YoungGC 耗时增加那么多?(Young Gen 的空间一直那么大,而且每次 GC 几乎没有对象晋升到 Old Gen,)
-
为什么 RPC 调用耗时长短也会影响 YoungGC 的耗时?
分析
首先,大家都知道 Young GC 是全程 stop the world 的,时间可能有多方面原因决定:
-
各个线程到达安全点的等待时间;
-
从 GC Root 扫描对象,进行标记的时间;
-
存活对象 copy 到 Survivor 以及晋升 Old Gen 到的时间;
-
GC 日志的时间。
原因比较多,从表象上很难看出 YoungGC 耗时的原因,因此,我们需要收集更多的证据,来排除干扰选项,定位原因
- 对于是否线程到达安全点时间引起的原因, 我们加上显示 Stop 时间与 Safepoint 的相关参数
- //Stop时间与Safepoint的相关参数
- -XX:+PrintGCApplicationStoppedTime -XX:+PrintSafepointStatistics -XX:PrintSafepointStatisticsCount=1
结论也很明显,stopping threads took 的时间都很短,可以排除此项因素。

- 对于从 GC Root 扫描对象,进行标记的时间引起的原因 我们加上显示 GC 处理 Reference 耗时的相关参数
- // 打印参数
- -XX:+PrintReferenceGC
结论也很明显,YoungGC 总耗时 110ms, 而 reference 处理耗时较长,主要是 FinalReference,耗时有 86 ms。
- //YoungGC 日志
- 2019-01-02T17:42:53.926+0800: 409.638: [GC (Allocation Failure)
- 2019-01-02T17:42:53.927+0800: 409.638: [ParNew2019-01-02T17:42:53.950+0800: 409.662: [SoftReference, 0 refs, 0.0000893 secs]
- 2019-01-02T17:42:53.951+0800: 409.662: [WeakReference, 185 refs, 0.0000499 secs]
- 2019-01-02T17:42:53.951+0800: 409.662: [FinalReference, 38820 refs, 0.0865010 secs]
- 2019-01-02T17:42:54.037+0800: 409.749: [PhantomReference, 0 refs, 1 refs, 0.0000447 secs]
- 2019-01-02T17:42:54.037+0800: 409.749: [JNI Weak Reference, 0.0000220 secs]: 645120K->37540K(645120K), 0.1126527 secs]
- 1005305K->397726K(3074048K), 0.1128549 secs]
- [Times: user=0.40 sys=0.00, real=0.11 secs]
-
对于存活对象 Copy 到 Survivor 以及晋升 Old Gen 到的时间引起的原因
由于 Survivor 较小,每次 YoungGC 又几乎没有晋升到 Old Gen 的对象,因此很明显,可以排除此项因素。 -
对 GC 日志的时间;
大部分 GC 日志是不耗时的,除非机器使用了大量的 swap 空间,或者其他原因导致的 iowait 较高,此项可以通过 top 或者 dstat 等命令看看 swap 使用情况以及 iowait 指标。
分析到这里,其实问题基本已经定位了,主要是 FinalReference 的处理时间比较长,导致 Young GC 时间比较长。
原理
FinalReference 是什么?
FinalReference 的具体细节,又需要一篇文章来讲解。
这里简单描述下:
对于重载了 Object 类的 finalize 方法的类实例化的对象(这里称为 f 对象),JVM 为了能在 GC 对象时触发 f 对象的 finalize 方法的调用,将每个 f 对象包装生成一个对应的 FinalReference 对象,方便 GC 时进行处理。
- //finalize方法
- protected void finalize() throws Throwable {
- ....
- }
FinalReference 详细解读,可以看下你假笨大神的这篇博客JVM源码分析之FinalReference完全解读(增强版)
FinalReference 来源何处?
FinalReference 对于没有实现 finalize 的程序,一般是不会出现的,到底是来源何处呢?
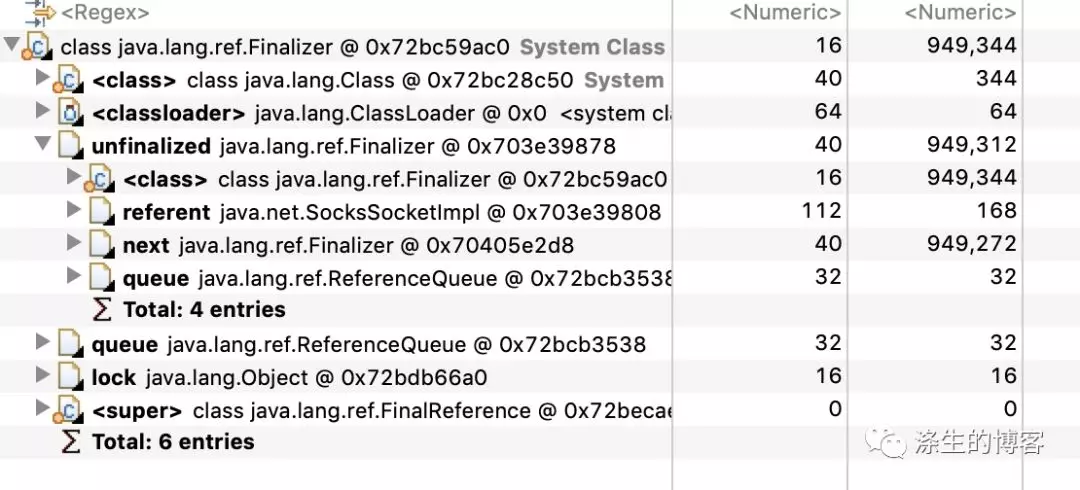
这里进行 JVM dump,然后通过 MAT 工具分析
很明显,是 SocksSocketImpl 对象,我们看下 SocksSocketImpl 类实现
- //SocksSocketImpl finalize 的实现
- /**
- * Cleans up if the user forgets to close it.
- */
- protected void finalize() throws IOException {
- close();
- }
这里是为了防止 Socket 连接忘记关闭导致资源泄漏而进行的保底措施。
为什么FinalReference GC 处理这么耗时?
为什么 JVM GC 处理 FinalReference 这么耗时呢,通过 GC 日志,可以看出有 38820 个 reference,耗时 86ms。
- 2019-01-02T17:42:53.951+0800: 409.662: [FinalReference, 38820 refs, 0.0865010 secs]
对于这个问题撸过 JVM 源码,但是一直没有搞清楚。
如何解释问题的想象?
看到上面的 FinalReference 主要是 Socket 引起的,当时就推想到为什么会有这么多 Socket 对象需要 GC,所以问某同学难道你使用的是短连接?得到的回答是肯定的,瞬间豁然开朗。
上文提到的两个疑惑就很容易解释了:
-
对于“为什么进行 RPC 调用和不进行 RPC 调用相比 YoungGC 耗时增加那么多?”问题
RPC 调用使用的是短连接,每调用一次就会创建一个 Socket 对象,致使 FinalReference 对象非常多, 因此,YoungGC 耗时增加。 -
对于“为什么 RPC 调用耗时长短也会影响 YoungGC 的耗时?”问题
由于 RPC 调用耗时长的,同样的线程数,调用的 QPS 就低,QPS 低自然创建的 Socket 对象就少,致使 FinalReference 对象少,因此,YoungGC 耗时相比就会小一些。
解决
理解了问题产生的原理,解决问题自然变得非常简单。
- 通用方法
加上 ParallelRefProcEnabled 参数可以使得 Reference 在 GC 的时候多线程并行处理过程,自然耗时就会降下来。
- //ParallelRefProcEnabled 参数
- -XX:+ParallelRefProcEnabled
- 减少 GC 的 Reference 数量
减少 GC 的 Reference 方法比较多,不同的案例不同的处理方法,能减少 GC 的 Reference 数量就好。 这里也很简单,RPC 调用短连接改用长链接,自然就能减少 GC 的 Reference 数量。 该案例就使用了这个方案,效果也很明显,YoungGC 时间直接降低到了 14ms。
总结
本案例总结原因就是 RPC 使用短连接调用,导致 Socket 的 FinalReference 引用较多,致使 YoungGC 耗时较长。因此,通过将短连接改成长连接,减少了 Socket 对象的创建,从而减少 FinalReference,来降低 YoungGC 耗时。
在看本篇文章之前,你一定不会想到 JVM GC 处理 FinalReference 耗时这么长;你也一定不会想到短连接还有影响 GC 耗时的坏处。
排查问题的过程,很享受,不仅可以证明所学,也可以锤炼技术。



