
g1源码之YoungGC技术细节探究原创
笔者经过上次研究ZGC的代码之后,感受到了ZGC性能的提升和设计的巧妙,由此知道了ZGC的各种优势。但是现在日常生产中许多应用还是用的JAVA8和G1,作为一个对技术有追求的程序员,不由得产生了看一看G1源码的想法。笔者一直本着比较学习才能收获更多的原则,所以打开了java8的源码,开始学习G1,再学习过程中发现,G1的代码相较于zgc阅读起来稍微有些困难,花的时间更长一些。网上许多关于G1源码的文章并不是很全面,有些问题也没有讲清楚,笔者会尽量将源码的细节阐述清楚。
首先G1的GC过程分为4个阶段或者说策略:
1.youngGC
2.老年代并发GC(又叫并发模式gc,本文都先称之为老年代并发gc)
3.混合GC
4.FullGC
每个阶段GC的内容都比较多,在这里由于篇幅原因,我们先讲解下g1中youngGc(源码中也叫增量gc) 的源码,话不多说,直接来看:
一、youngGC触发的时机
关于GC笔者不建议直接去看GC的方法,最好时从GC触发的时机去看,从入口去看,这样才能更全面的学习GC的源码,更深层次的学习GC的相关流程。
youngGC的触发时机是在创建对象时若申请不到内存,则会触发一次youngGC,说起来很简单,我们看下源码,其实还是有很多细节:
//熟悉jvm源码的朋友都知道IRT_ENTRY是运行解释器的宏,其实是定义了一个_new方法
//这里我们可以理解成是解释java new关键字的方法,本质上在java使用new关键字时会调用这个方法
IRT_ENTRY(void, InterpreterRuntime::_new(JavaThread* thread, ConstantPool* pool, int index))
//先会去常量池(这里的常量池其实运行时常量池)中查找Klass的信息
Klass* k_oop = pool->klass_at(index, CHECK);
//然后将其包装成instanceKlassHandle句柄,其实就是klass包装类
instanceKlassHandle klass (THREAD, k_oop);
//做一些验证和初始化操作
klass->check_valid_for_instantiation(true, CHECK);
klass->initialize(CHECK);
//调用申请对象的方法
oop obj = klass->allocate_instance(CHECK);
//将申请的结果返回
thread->set_vm_result(obj);
IRT_END
之后会跳到这个方法InstanceKlass::allocate_instance:
//这个方法返回的instanceOop是instanceOopDesc指针的别名(不开启预编译),instanceOopDesc是oopDesc
//的子类,表示java class的实例
//InstanceKlass是Klass的子类,表示类的元数据
instanceOop InstanceKlass::allocate_instance(TRAPS) {
//判断是否定义finalizer方法
bool has_finalizer_flag = has_finalizer();
//返回实例大小
int size = size_helper();
//封装成KlassHandle句柄,可以简单理解为是Klass的封装类
KlassHandle h_k(THREAD, this);
instanceOop i;
//创建对象实例
i = (instanceOop)CollectedHeap::obj_allocate(h_k, size, CHECK_NULL);
//注册finalizer方法
if (has_finalizer_flag && !RegisterFinalizersAtInit) {
i = register_finalizer(i, CHECK_NULL);
}
return i;
}
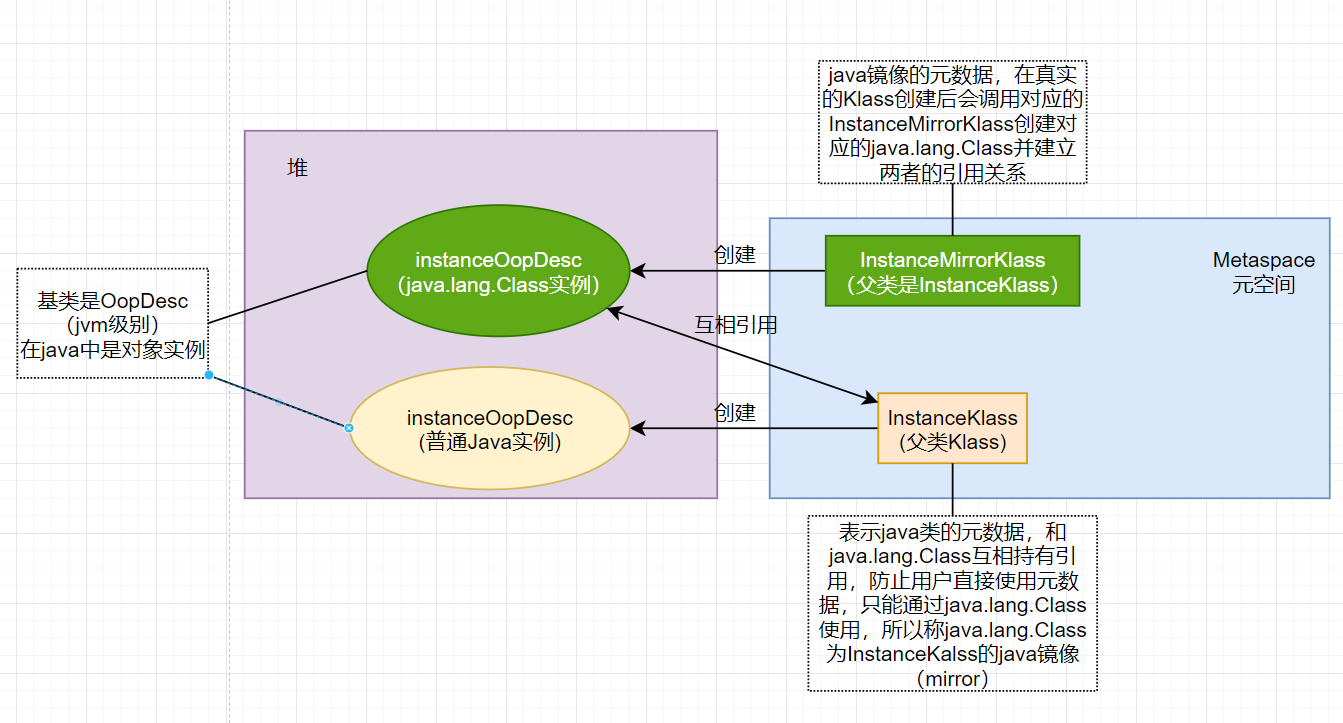
看到这里,小伙伴们可能会有点迷惑,搞不懂instanceOopDesc和InstanceKlass,这个地方涉及到jvm的oop-klass模型,我们来画张图简单说明下,通过这张图,我们就可以理解这两句话的原因:
1.加载.class到元空间时,会在堆中实例化出一个class对象
实际上是通过instanceMirrorKlass实例化出的
2.在java中利用反射传入的是java.lang.Class对象,创建出的是普通的java实例
因为java.lang.Class对象实际上是InstanceKlass的java镜像类,可以通过java.lang.Class对象获取InstanceKlass的信息,进而获取普通java实例的信息,从而创建普通实例
关于oop-klass模型也非常有意思,有兴趣的读者可以自行查看下源码,本篇还是着重讲述youngGC
言归正传,我们继续往下看:
oop CollectedHeap::obj_allocate(KlassHandle klass, int size, TRAPS) {
//申请内存并初始化对象
HeapWord* obj = common_mem_allocate_init(klass, size, CHECK_NULL);
post_allocation_setup_obj(klass, obj);
return (oop)obj;
}
HeapWord* CollectedHeap::common_mem_allocate_init(KlassHandle klass, size_t size, TRAPS) {
//先申请内存
HeapWord* obj = common_mem_allocate_noinit(klass, size, CHECK_NULL);
init_obj(obj, size);
return obj;
}
//最后进入这个方法
HeapWord* CollectedHeap::common_mem_allocate_noinit(KlassHandle klass, size_t size, TRAPS) {
HeapWord* result = NULL;
//是否使用TLAB处理,这里先不论述TLAB我们直接跳过
if (UseTLAB) {
result = allocate_from_tlab(klass, THREAD, size);
if (result != NULL) {
return result;
}
}
bool gc_overhead_limit_was_exceeded = false;
//堆中申请内存,直接进入这个方法
result = Universe::heap()->mem_allocate(size,
&gc_overhead_limit_was_exceeded);
......
}
Universe::heap()这个方法返回的是当前jvm使用的堆类,由于我们是G1的垃圾回收器,所以这里返回的是g1CollectedHeap.cpp:
HeapWord*
G1CollectedHeap::mem_allocate(size_t word_size,
bool* gc_overhead_limit_was_exceeded) {
//循环直到申请成功或者GC后申请失败
for (int try_count = 1, gclocker_retry_count = 0; /* we'll return */; try_count += 1) {
unsigned int gc_count_before;
HeapWord* result = NULL;
//判断是否是大对象
if (!isHumongous(word_size)) {
//申请大对象的情况相对来说比较复杂,我们这里先看下申请小对象的逻辑
result = attempt_allocation(word_size, &gc_count_before, &gclocker_retry_count);
} else {
result = attempt_allocation_humongous(word_size, &gc_count_before, &gclocker_retry_count);
}
if (result != NULL) {
return result;
}
// 这个是fullGC的操作任务类
VM_G1CollectForAllocation op(gc_count_before, word_size);
//这里申请失败则会执行fullGC(这里先不论述FullGC)
VMThread::execute(&op);
......
}
return NULL;
}
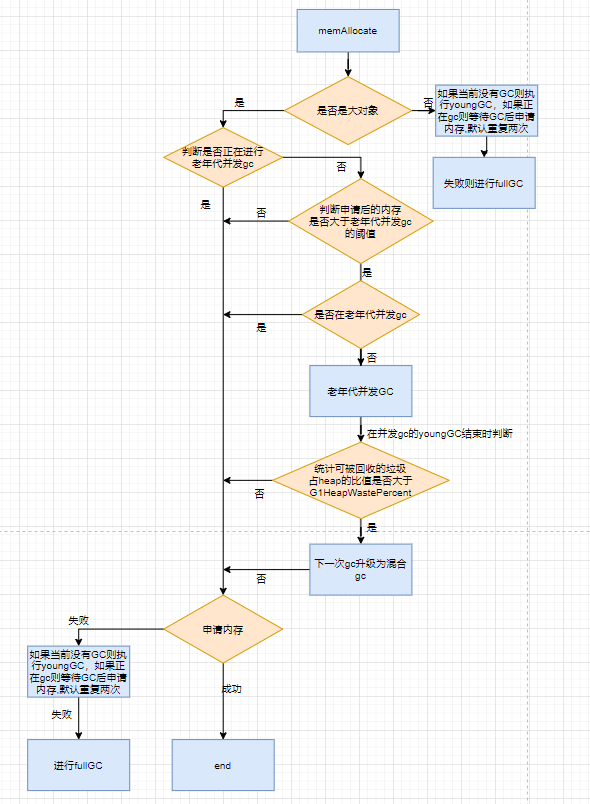
大对象的申请流程比较复杂,笔者这里简单画了张图表示下大对象申请的流程,小伙伴们可以参考了解下,当然其中具体的步骤肯定不止这么简单,有兴趣的小伙伴可以自行查看源码
从小对象方法申请入手我们继续看:
inline HeapWord*
G1CollectedHeap::attempt_allocation(size_t word_size,
unsigned int* gc_count_before_ret,
int* gclocker_retry_count_ret) {
//再去申请一次内存,_mutator_alloc_region内部有指向当前活跃的eden region,每次申请会从这里申请内存
//在每次gc之前会清空申请的内存
HeapWord* result = _mutator_alloc_region.attempt_allocation(word_size,
false /* bot_updates */);
if (result == NULL) {
//失败后进入这个方法
result = attempt_allocation_slow(word_size,
gc_count_before_ret,
gclocker_retry_count_ret);
}
if (result != NULL) {
dirty_young_block(result, word_size);
}
return result;
}
//进入这个方法
HeapWord* G1CollectedHeap::attempt_allocation_slow(size_t word_size,
unsigned int *gc_count_before_ret,
int* gclocker_retry_count_ret) {
//这里默认情况下会循环三次,根据这个参数GCLockerRetryAllocationCount
HeapWord* result = NULL;
for (int try_count = 1; /* we'll return */; try_count += 1) {
bool should_try_gc;
unsigned int gc_count_before;
{
MutexLockerEx x(Heap_lock);
//还是先去申请内存这个方法申请内存失败会将_mutator_alloc_region中的活跃区域进行retire并填充
//retire即将现在活跃的eden区region填充后加入到增量cset(即将要被回收的集合)中
//之后再去申请一块新的region代替当前活跃区域
//如果申请新的region失败才会继续下面操作进行GC
result = _mutator_alloc_region.attempt_allocation_locked(word_size,
false /* bot_updates */);
if (result != NULL) {
return result;
}
//GC_locker涉及到线程临界区的概念,这个方法会判断三个参数
//needs_gc && (_lock_count > 0 || _jni_lock_count > 0)
//这方法如果程序中使用jni开发可能会是true
if (GC_locker::is_active_and_needs_gc()) {
//判断是否可以扩容年轻代,可以则再申请一次
if (g1_policy()->can_expand_young_list()) {
result = _mutator_alloc_region.attempt_allocation_force(word_size,
false /* bot_updates */);
if (result != NULL) {
return result;
}
}
should_try_gc = false;
} else {
//这里判断need_gc,默认是fasle
if (GC_locker::needs_gc()) {
should_try_gc = false;
} else {
gc_count_before = total_collections();
should_try_gc = true;
}
}
}
//有且只有_lock_count ==0 && _jni_lock_count == 0 && !need_gc 这里是should_try_gc=true
if (should_try_gc) {
bool succeeded;
//执行GC
result = do_collection_pause(word_size, gc_count_before, &succeeded,
GCCause::_g1_inc_collection_pause);
if (result != NULL) {
return result;
}
if (succeeded) {
MutexLockerEx x(Heap_lock);
*gc_count_before_ret = total_collections();
return NULL;
}
} else {
//其他情况的GC_locker会走这里
//先判断循环次数超出则返回
if (*gclocker_retry_count_ret > GCLockerRetryAllocationCount) {
MutexLockerEx x(Heap_lock);
*gc_count_before_ret = total_collections();
return NULL;
}
//这个方法会被JNICritical_lock锁住直到needs_gc == false
// while (needs_gc()) {
// JNICritical_lock->wait();
// }
GC_locker::stall_until_clear();
(*gclocker_retry_count_ret) += 1;
}
//再去申请一次内存
result = _mutator_alloc_region.attempt_allocation(word_size,
false /* bot_updates */);
if (result != NULL) {
return result;
}
}
return NULL;
}
这里简单介绍下GC_locker这个类,这个类中有三个主要参数
**int **_lock_count : 记录jvm启动时的锁,在jvm启动前会+1,在jvm成功启动后会-1
**int **_jni_lock_count : 记录当前处于jni线程临界区的锁的数量,表示有几个线程处于临界区
**bool **needs_gc : 是否需要gc, 默认为false ,当有线程处于临界区时,此时如果需要gc,则会先舍弃gc,并且将needs_gc变为true,当所有线程处理完临界区后,根据这个标记再进行gc,之后再将其设置为false
这里涉及到一个新的名词:线程的临界区(即 critical region)表示存在对共享资源的多线程读写操作的代码块。
如果程序中使用了jni开发这里可能会使得_jni_lock_count>0且当前gc暂时舍去,如果没有使用则正常情况会继续gc。
二、youngGC全局停顿
到这里youngGC的全局停顿就要开始了,我们直接来看代码
HeapWord* G1CollectedHeap::do_collection_pause(size_t word_size,
unsigned int gc_count_before,
bool* succeeded,
GCCause::Cause gc_cause) {
//记录gc停顿
//看到这里读者可能会比较疑惑,已经开始记录停顿开始了,但是怎么没有找到停顿的方法
//真正的停顿方法在VMThread::execute(&op);中
g1_policy()->record_stop_world_start();
// gc操作任务类,第三个参数表示本次gc是不是老年代并发gc
VM_G1IncCollectionPause op(gc_count_before,
word_size,
false, /* should_initiate_conc_mark */
g1_policy()->max_pause_time_ms(),
gc_cause);
VMThread::execute(&op);
HeapWord* result = op.result();
bool ret_succeeded = op.prologue_succeeded() && op.pause_succeeded();
*succeeded = ret_succeeded;
return result;
}
//简单介绍下VMThread,其实是原生的vm线程
void VMThread::execute(VM_Operation* op) {
Thread* t = Thread::current();
//判断当前线程是否是vm线程,这里t->is_VM_thread()返回true
if (!t->is_VM_thread()) {
//跳过这里,其实这里的逻辑是当前不是vm线程是java线程或者watcher线程
//会先将任务放到一个queue中,之后再执行
......
} else {
//如果是vm线程则会进入这里
......
HandleMark hm(t);
_cur_vm_operation = op;
//判断任务是否需要再安全点执行且当前是否在安全点
if (op->evaluate_at_safepoint() && !SafepointSynchronize::is_at_safepoint()) {
//如果不是安全点,则等待所有线程进入安全点,然后把线程暂时挂起
//这个类中有个状态 _state,所有java线程转换线程状态时会去判断这个状态然后
//决定是否block
SafepointSynchronize::begin();
//开始任务, op是刚刚传入的VM_G1IncCollectionPause操作任务类
//evaluate()方法最后会调用gc操作任务类的doit()方法
op->evaluate();
//安全点结束
SafepointSynchronize::end();
} else {
//是安全点则直接执行
op->evaluate();
}
if (op->is_cheap_allocated()) delete op;
_cur_vm_operation = prev_vm_operation;
}
}
SafepointSynchronize::begin()方法内包括了准备进入安全点到所有java线程Block的过程,此时youngGC的全局停顿开始了,之前和一些小伙伴沟通的时候发现有的小伙伴完全不知道G1的youngGC过程会发生全局停顿,导致程序出现不能提供服务的时候只盲目的区查fullGC日志,实际上通过源码我们可以直到G1的youngGC过程也会产生全局停顿,这是我们平时容易忽视的一点。
三、youngGC之前的准备工作
youngGC并不是直接就开始的,再着之前还会由很多准备工作,我们先来看看doit方法:
void VM_G1IncCollectionPause::doit() {
G1CollectedHeap* g1h = G1CollectedHeap::heap();
if (_word_size > 0) {
//会再去申请一次内存
_result = g1h->attempt_allocation_at_safepoint(_word_size,
false /* expect_null_cur_alloc_region */);
if (_result != NULL) {
_pause_succeeded = true;
return;
}
}
GCCauseSetter x(g1h, _gc_cause);
// youngGC这里是之前创建VM_G1IncCollectionPause的第三个参数:false
// 表示此次youngGC不属于老年代并发gc的周期
if (_should_initiate_conc_mark) {
_old_marking_cycles_completed_before = g1h->old_marking_cycles_completed();
bool res = g1h->g1_policy()->force_initial_mark_if_outside_cycle(_gc_cause);
if (!res) {
if (_gc_cause != GCCause::_g1_humongous_allocation) {
_should_retry_gc = true;
}
return;
}
}
//gc方法
_pause_succeeded =
g1h->do_collection_pause_at_safepoint(_target_pause_time_ms);
if (_pause_succeeded && _word_size > 0) {
// 再去申请内存
_result = g1h->attempt_allocation_at_safepoint(_word_size,
true /* expect_null_cur_alloc_region */);
} else {
if (!_pause_succeeded) {
_should_retry_gc = true;
}
}
}
继续往下看:
//这个方法是gc中最长的方法,我们忽略掉一些记日志和统计数据的方法,直接看关键的几个方法
bool
G1CollectedHeap::do_collection_pause_at_safepoint(double target_pause_time_ms) {
//判断是否有线程再临界区,如果有则舍弃本次gc,并把need_gc参数设置为true
//这里是我们刚刚提到的gc_locker
if (GC_locker::check_active_before_gc()) {
return false;
}
//打印一些heap日志和统计数据
......
//这个方法将会判断此次youngGC是不是一次初次标记
//(即老年代并发垃圾回收时,会伴随一次youngGC,此时会返回true)
//纯youngGC阶段这里会返回false
g1_policy()->decide_on_conc_mark_initiation();
//是否处于初始标记停顿阶段(youngGC这里返回的是false)
bool should_start_conc_mark = g1_policy()->during_initial_mark_pause();
{
EvacuationInfo evacuation_info;
//youngGC这里是false我们直接跳过
if (g1_policy()->during_initial_mark_pause()) {
increment_old_marking_cycles_started();
register_concurrent_cycle_start(_gc_timer_stw->gc_start());
}
//打印GC开始日志和活跃线程数
......
TraceCollectorStats tcs(g1mm()->incremental_collection_counters());
TraceMemoryManagerStats tms(false /* fullGC */, gc_cause());
//将二级空闲region列表合并到主空闲列表中
//二级空闲region列表包括之前释放的region
if (!G1StressConcRegionFreeing) {
append_secondary_free_list_if_not_empty_with_lock();
}
{
IsGCActiveMark x;
//填充tlab,扫描所有java线程的tlab并用空对象填充,之后再重置
gc_prologue(false);
......
//启动在全局停顿时期的软引用发现执行器
ref_processor_stw()->enable_discovery(true /*verify_disabled*/,
true /*verify_no_refs*/);
{
//关闭并发扫描阶段的软引用发现执行器
NoRefDiscovery no_cm_discovery(ref_processor_cm());
// 重置_mutator_alloc_region即主动将其中的活跃区域retire但是这次不会填充还没使用的区域
// 因为马上要gc了,之后将活跃的region并将其加入到_inc_cset_head中(增量cset)
// _mutator_alloc_region前面我们提到过是申请伊甸区内存的类
// 此时增量cset中将包含所有的eden区region
release_mutator_alloc_region();
.......
// 完成cset,这个方法会将增量cset设置成cset,并将youngRegion中的survivor区全部设置成单纯的young区
// 因为gc之后老的survivor区将变成新的eden区
// 此时cset中将包含所有的eden区
g1_policy()->finalize_cset(target_pause_time_ms, evacuation_info);
......
// 初始化GC要申请的region,包括要用的新的survivor区域和old区域
init_gc_alloc_regions(evacuation_info);
// 执行gc
evacuate_collection_set(evacuation_info);
//这个方法我们先看到这个里,后面是gc的收尾工作,我们之后再看
......
}
这里的代码比较复杂,其中cset就是我们需要回收的region集合,在youngGC中它包括所有eden区,这是youngGC中需要释放回收的区域
我们先看下执行gc的方法evacuate_collection_set(evacuation_info):
方法比较长,在看之前我们先简单介绍下几个即将涉及到的知识点:
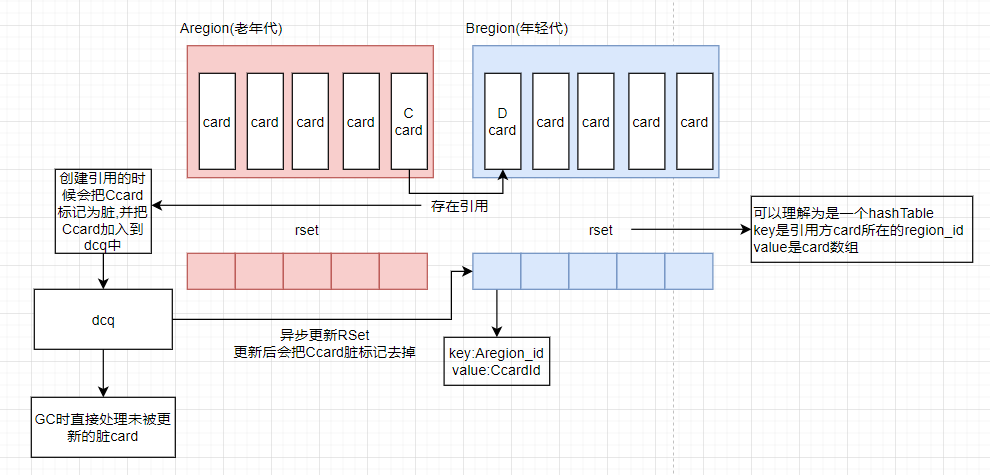
dirty card : 脏卡,在g1中每个region被分成若干个card,card用于映射一块内存块,其中不止有一个对象,当card有一个及以上对象的字段存在跨代引用时就被标记为脏
Rset : 记忆集合,在g1中用于解决跨region引用问题,在g1中只有老年代引用新生代的对象会被记录到Rset中,这样在youngGC中就可以避免扫描整个比较大的老年代减少开销,而只用处理记忆集合就好。在g1中rset只有脏卡会被加入到rset中
dirty card queue : 脏卡队列,再执行引用赋值语句时再写屏障中会将判断当前赋值是否跨代,如果跨代则将其对应的card标记为脏并加入dirty card queue中,后续会由其他线程异步处理更新到rset中。
dirty card queue set : 脏卡队列集合,其中由所有脏卡队列,当一个脏卡队列满时会再其中记录,youngGC时会将脏卡集合队列中满的脏卡队列更新到rset中。
这里涉及到的就是g1的写屏障和记忆集合,卡表等知识点,以后有机会笔者再专门介绍下相关知识,这里我们先简单了解下。
void G1CollectedHeap::evacuate_collection_set(EvacuationInfo& evacuation_info) {
//这个方法会把dcqs中没有满的dcq加入满的集合
//因为之后要更新脏卡到rset中,所以这里会把所有没满的集合标记成满的集合,之后只需要处理被标记为满的queue就可以了
g1_rem_set()->prepare_for_oops_into_collection_set_do();
// 先关闭热卡缓存
G1HotCardCache* hot_card_cache = _cg1r->hot_card_cache();
hot_card_cache->reset_hot_cache_claimed_index();
hot_card_cache->set_use_cache(false);
// 获取gc工作线程
uint n_workers;
if (G1CollectedHeap::use_parallel_gc_threads()) {
n_workers =
AdaptiveSizePolicy::calc_active_workers(workers()->total_workers(),
workers()->active_workers(),
Threads::number_of_non_daemon_threads());
workers()->set_active_workers(n_workers);
set_par_threads(n_workers);
} else {
n_workers = 1;
}
//youngGC任务类
G1ParTask g1_par_task(this, _task_queues);
init_for_evac_failure(NULL);
rem_set()->prepare_for_younger_refs_iterate(true);
......
{
StrongRootsScope srs(this);
//使用gc工作线程执行gc任务
if (G1CollectedHeap::use_parallel_gc_threads()) {
// The individual threads will set their evac-failure closures.
if (ParallelGCVerbose) G1ParScanThreadState::print_termination_stats_hdr();
// These tasks use ShareHeap::_process_strong_tasks
workers()->run_task(&g1_par_task);
} else {
g1_par_task.set_for_termination(n_workers);
g1_par_task.work(0);
}
end_par_time_sec = os::elapsedTime();
}
......
set_par_threads(0);
//在之前我们开启了软引用执行器,这里会处理软引用
process_discovered_references(n_workers);
//处理弱引用
{
G1STWIsAliveClosure is_alive(this);
G1KeepAliveClosure keep_alive(this);
JNIHandles::weak_oops_do(&is_alive, &keep_alive);
}
release_gc_alloc_regions(n_workers, evacuation_info);
g1_rem_set()->cleanup_after_oops_into_collection_set_do();
//重新启动热卡缓存
hot_card_cache->reset_hot_cache();
hot_card_cache->set_use_cache(true);
......
}
三、扫描根节点
下面我们终于可以看到我们所熟知的扫描根节点的方法,网上许多文章都是从这一步开始的,但其实youngGC在这之前做的准备还是很多的,而且这些准备都是包括在停顿范围内的,所以youngGC的停顿时间不止是从扫描根节点开始(虽然大部分时候准备时间可以忽略不计),这些只有亲自看了源码才能理解到。
//G1ParTask的work方法,youngGC入口
void work(uint worker_id) {
......
{
ResourceMark rm;
HandleMark hm;
//这边声明了许多闭包
ReferenceProcessor* rp = _g1h->ref_processor_stw();
//线程扫描状态闭包,里面有一个rset引用queue用于作为rset的缓冲
//这里我们先关注下这个pss后面更新rset时会用到
G1ParScanThreadState pss(_g1h, worker_id);
G1ParScanHeapEvacClosure scan_evac_cl(_g1h, &pss, rp);
G1ParScanHeapEvacFailureClosure evac_failure_cl(_g1h, &pss, rp);
G1ParScanPartialArrayClosure partial_scan_cl(_g1h, &pss, rp);
//这里会把扫描闭包放入pss
pss.set_evac_closure(&scan_evac_cl);
pss.set_evac_failure_closure(&evac_failure_cl);
pss.set_partial_scan_closure(&partial_scan_cl);
//这些都是别名实际上是 G1ParCopyClosure迭代器
//只扫描根
//扫描根的迭代器纯youngGC中使用的时这个
G1ParScanExtRootClosure only_scan_root_cl(_g1h, &pss, rp);
//只扫描元数据
G1ParScanMetadataClosure only_scan_metadata_cl(_g1h, &pss, rp);
......
//扫描根的迭代器
OopClosure* scan_root_cl = &only_scan_root_cl;
G1KlassScanClosure* scan_klasses_cl = &only_scan_klasses_cl_s;
......
//用来将rset中的card推入queue中后面统一copy对象的闭包
//pss中有处理rset中引用的queue
G1ParPushHeapRSClosure push_heap_rs_cl(_g1h, &pss);
int so = SharedHeap::SO_AllClasses | SharedHeap::SO_Strings;
//扫描根节点,第三个参数是G1ParScanExtRootClosure是主要的迭代器
//第四个参数是G1ParScanThreadState
_g1h->g1_process_strong_roots(/* is scavenging */ true,
SharedHeap::ScanningOption(so),
scan_root_cl,
&push_heap_rs_cl,
scan_klasses_cl,
worker_id);
{
double start = os::elapsedTime();
//pss中有处理rset中引用的queue
G1ParEvacuateFollowersClosure evac(_g1h, &pss, _queues, &_terminator);
//更新rset,这个方法我们注意下后面会讲到
evac.do_void();
......
}
......
}
......
}
};
void
G1CollectedHeap::
g1_process_strong_roots(bool is_scavenging,
ScanningOption so,
OopClosure* scan_non_heap_roots,
OopsInHeapRegionClosure* scan_rs,
G1KlassScanClosure* scan_klasses,
int worker_i) {
//根迭代器
//缓冲迭代器,传入的即上面提到G1ParScanExtRootClosure
//缓冲迭代器即是将迭代任务缓冲起来分批执行即将扫描gcRoot的任务缓冲到里面执行
BufferingOopClosure buf_scan_non_heap_roots(scan_non_heap_roots);
CodeBlobToOopClosure eager_scan_code_roots(scan_non_heap_roots, true /* do_marking */);
//扫描根的方法,这个方法会将gcRoot分别进行扫描,我们就不展开看了
//我们看下刚刚提到的迭代器G1ParScanExtRootClosure,这个是主要处理gcRoot的方法
process_strong_roots(false, // no scoping; this is parallel code
is_scavenging, so,
&buf_scan_non_heap_roots,
&eager_scan_code_roots,
scan_klasses
);
// 等待缓冲迭代器执行完毕,此时GCRoot已经扫描完毕
buf_scan_non_heap_roots.done();
//省略一些记录时间的代码
......
// 更新rset这个方法我们之后会讲
if (scan_rs != NULL) {
g1_rem_set()->oops_into_collection_set_do(scan_rs, &eager_scan_code_roots, worker_i);
}
_process_strong_tasks->all_tasks_completed();
}
看下刚刚我们提到的G1ParScanExtRootClosure,其实是一个别名:
typedef G1ParCopyClosure<false, G1BarrierNone, false> G1ParScanExtRootClosure
G1ParCopyClosure的迭代方法才是真正的遍历gcRoot引用的方法:
//真正的迭代方法
//三个泛型 <是否用屏障,屏障类型,是否标记>
//这里传入的是 false, G1BarrierNone, false
template <bool do_gen_barrier, G1Barrier barrier, bool do_mark_object>
template <class T>
void G1ParCopyClosure<do_gen_barrier, barrier, do_mark_object>
::do_oop_work(T* p) {
//根据oop指针获取对象值(本质是解引用)
//这里获取的是gcRoot引用的对象
oop obj = oopDesc::load_decode_heap_oop(p);
// 快速判断对象是否在cset回收集合中
if (_g1->in_cset_fast_test(obj)) {
oop forwardee;
// 判断对象是否被标记,根据对象头地址判断
// 这里会判断对象头中的标记信息
if (obj->is_forwarded()) {
//这里证明已经被扫描过且复制过,所以返回不带锁标记的对象地址
forwardee = obj->forwardee();
} else {
//没被标记则复制对象到survivor区,返回新对象的引用
//这个方法会判断对象的年龄,根据年龄去survivor区或者old区申请内存并复制对象
//具体我们就不进行展开了
forwardee = copy_to_survivor_space(obj);
}
//修改引用 p->fowardee
oopDesc::encode_store_heap_oop(p, forwardee);
.....
} else {
.....
}
......
}
我们可以看到对gcRoot扫描和复制对象的过程在youngGC中是一起进行的,并不是像一些其他文章一样是同时进行的。
这里我们简单解释下g1是如何如理标记对象的以便于我们和zgc比较学习,可以看到是先获取对象之后判断对象头的高位地址的最后两位来处理标记,而zgc则直接读取对象指针就可以判断:

四、处理dcq和Rset中的跨代引用card
接下来是该处理Rset了,这个步骤本质其实是将dcq和rset中的存在跨代引用的card全部加入到pss(G1ParScanThreadState)中的queue中,网上许多其他文章都是简单说这里是更新Rset,其实有很多细节还需要学习源码才能学到。
我们先回到我们刚刚提到的那个g1_rem_set()->oops_into_collection_set_do(scan_rs, &eager_scan_code_roots, worker_i)方法:
void G1RemSet::oops_into_collection_set_do(OopsInHeapRegionClosure* oc,
CodeBlobToOopClosure* code_root_cl,
int worker_i) {
//缓存闭包(更新rs迭代方法)
_cset_rs_update_cl[worker_i] = oc;
//这里的into_cset_dirty_card_queue_set()本质是属于JavaThread::dirty_card_queue_set()
//即dcqs,但其代表回收集合的dcqs再gc之后会进行处理,主要是保存引用了回收集合中对象的card
DirtyCardQueue into_cset_dcq(&_g1->into_cset_dirty_card_queue_set());
//更新rset
if (G1UseParallelRSetUpdating || (worker_i == 0)) {
updateRS(&into_cset_dcq, worker_i);
} else {
_g1p->phase_times()->record_update_rs_processed_buffers(worker_i, 0);
_g1p->phase_times()->record_update_rs_time(worker_i, 0.0);
}
//扫描并处理rset
if (G1UseParallelRSetScanning || (worker_i == 0)) {
scanRS(oc, code_root_cl, worker_i);
} else {
_g1p->phase_times()->record_scan_rs_time(worker_i, 0.0);
}
_cset_rs_update_cl[worker_i] = NULL;
}
//先看更新Rset
void G1RemSet::updateRS(DirtyCardQueue* into_cset_dcq, int worker_i) {
double start = os::elapsedTime();
// 处理card的闭包,这里我们留意下之后会碰到
RefineRecordRefsIntoCSCardTableEntryClosure into_cset_update_rs_cl(_g1, into_cset_dcq);
// 进行迭代
_g1->iterate_dirty_card_closure(&into_cset_update_rs_cl, into_cset_dcq, false, worker_i);
......
}
void G1CollectedHeap::iterate_dirty_card_closure(CardTableEntryClosure* cl,
DirtyCardQueue* into_cset_dcq,
bool concurrent,
int worker_i) {
G1HotCardCache* hot_card_cache = _cg1r->hot_card_cache();
// 这里会更新热卡,如果失败则将卡入列到刚刚创建的dcq中,此dcq属于dcqs集合
hot_card_cache->drain(worker_i, g1_rem_set(), into_cset_dcq);
//这里可能有点晕,我们简单理解之前创建的dcq用于处理回收集合,最后还是要归于dcqs来统一处理
DirtyCardQueueSet& dcqs = JavaThread::dirty_card_queue_set();
int n_completed_buffers = 0;
//处理dcqs中满的队列,在我们准备阶段已经把不满的队列标记为满的队列,所以这里相当于处理所有dcq
while (dcqs.apply_closure_to_completed_buffer(cl, worker_i, 0, true)) {
n_completed_buffers++;
}
dcqs.clear_n_completed_buffers();
}
bool DirtyCardQueueSet::apply_closure_to_completed_buffer(CardTableEntryClosure* cl,
int worker_i,
int stop_at,
bool during_pause) {
//从dcqs中获取一个满的队列,其实是一个bufferNode数组(是jvm自己封装的队列)
BufferNode* nd = get_completed_buffer(stop_at);
//遍历dcq中的card
bool res = apply_closure_to_completed_buffer_helper(cl, worker_i, nd);
if (res) Atomic::inc(&_processed_buffers_rs_thread);
return res;
}
经过几个方法的调用,最后会调用之前传入的闭包RefineRecordRefsIntoCSCardTableEntryClosure的方法:
//之前传入的闭包
RefineRecordRefsIntoCSCardTableEntryClosure
bool do_card_ptr(jbyte* card_ptr, int worker_i) {
//这个是更新rset的方法,注意这里第三个参数是true
//这里会检查引用是不是跨代且引用的对象是否在回收集合中,如果引用是old->young且引用的对象也在回收集合中
//则会用G1ParPushHeapRSClosure(之前提到过的pss)进行遍历
//G1ParPushHeapRSClosure其内部其实是一个queue先将card保存起来,之后统一处理
if (_g1rs->refine_card(card_ptr, worker_i, true)) {
//如果card中的引用引用的是回收集合的对象则会加入回收集合dcq中
_into_cset_dcq->enqueue(card_ptr);
}
return true;
}
refine_card是处理card的方法,这里由于篇幅原因,我们就不具体展开了,之后笔者在讲到写屏障的时候,我们可以再深入学习下。
至此,所有的dcq队列中所有处于回收集合的脏卡已经被加入到 G1ParPushHeapRSClosure 中的queue中。
接下来我们来看下扫描并处理Rset的方法 scanRS(oc, code_root_cl, worker_i):
void G1RemSet::scanRS(OopsInHeapRegionClosure* oc,
CodeBlobToOopClosure* code_root_cl,
int worker_i) {
double rs_time_start = os::elapsedTime();
//获取cset开始的region
HeapRegion *startRegion = _g1->start_cset_region_for_worker(worker_i);
//创建扫描rset的闭包
ScanRSClosure scanRScl(oc, code_root_cl, worker_i);
//遍历回收集合,这里是用上面创建的闭包进行扫描所有cset中的region
_g1->collection_set_iterate_from(startRegion, &scanRScl);
scanRScl.set_try_claimed();
_g1->collection_set_iterate_from(startRegion, &scanRScl);
_cards_scanned[worker_i] = scanRScl.cards_done();
}
//我们直接来看闭包的方法
//调用ScanRSClosure的这个方法
bool doHeapRegion(HeapRegion* r) {
//获取当前遍历的region的rset
HeapRegionRemSet* hrrs = r->rem_set();
....
//这里会把当前遍历的回收集合中的region加入脏卡region集合
//脏卡region集合仅用于GC之后清理卡表(Rset)
//因为被回收所以其Rset也需要清理
_g1h->push_dirty_cards_region(r);
......
//创建rset的迭代器
HeapRegionRemSetIterator iter(hrrs);
size_t card_index;
size_t jump_to_card = hrrs->iter_claimed_next(_block_size);
//这里会对rset集合中的card进行遍历
for (size_t current_card = 0; iter.has_next(card_index); current_card++) {
if (current_card >= jump_to_card + _block_size) {
jump_to_card = hrrs->iter_claimed_next(_block_size);
}
if (current_card < jump_to_card) continue;
HeapWord* card_start = _g1h->bot_shared()->address_for_index(card_index);
//获取card所属的region,即引用所在region
HeapRegion* card_region = _g1h->heap_region_containing(card_start);
_cards++;
//这里会把引用所在region也加入脏卡集合
if (!card_region->is_on_dirty_cards_region_list()) {
_g1h->push_dirty_cards_region(card_region);
}
//引用所在region不属于回收集合且非脏card会扫面,card中映射的对象
//Rset中的card本质都是脏card只不过进入Rset之后脏标记会被清除
//所以这里对非脏进行扫描,即这些card映射的对象引用的对象都是存活的,需要被迁移
if (!card_region->in_collection_set() &&
!_ct_bs->is_card_dirty(card_index)) {
//这个方法最后也会用之前提到的pss G1ParPushHeapRSClosure遍历并将card加入到其中的queue中
scanCard(card_index, card_region);
}
}
if (!_try_claimed) {
//这里会处理一些代码对象,我们就不继续看了
scan_strong_code_roots(r);
hrrs->set_iter_complete();
}
return false;
}
看到这里读者可能会有些迷惑,我们来简单画个图说明下脏卡标记和dcq的处理方式,这篇博客主要讲解youngGC,我们就不详细扩展:
五、处理pss中的queue中所有的存在跨代引用的card
根据源码我们可以看到,gc流程走到现在dcq中的脏card和Rset中本质上是脏但实际没有脏标记的card都已经进入到pss(G1ParScanThreadState)的queue中,
接下来就该看我们之前提到的这段代码 :
G1ParEvacuateFollowersClosure evac(_g1h, &pss, _queues, &_terminator);
evac.do_void();
//可以看出这里主要逻辑是处理queue,其中涉及到一些偷任务的逻辑我们先忽略
void G1ParEvacuateFollowersClosure::do_void() {
StarTask stolen_task;
//获取pss
G1ParScanThreadState* const pss = par_scan_state();
//这个方法会处理queue
pss->trim_queue();
.....
}
//进入几个方法会调这个方法处理引用
template <class T> void deal_with_reference(T* ref_to_scan) {
if (has_partial_array_mask(ref_to_scan)) {
_partial_scan_cl->do_oop_nv(ref_to_scan);
} else {
HeapRegion* r = _g1h->heap_region_containing_raw(ref_to_scan);
// _evac_cl是之前G1ParScanHeapEvacClosure
_evac_cl->set_region(r);
_evac_cl->do_oop_nv(ref_to_scan);
}
}
//G1ParScanHeapEvacClosure其实是一个别名,本质是G1ParCopyClosure只不过泛型和之前用
//到G1ParScanExtRootClosure的泛型不一样
//最终会调用这个熟悉的方法
//这里的三个泛型是<false, G1BarrierEvac, false>
void G1ParCopyClosure<do_gen_barrier, barrier, do_mark_object>
::do_oop_work(T* p) {
oop obj = oopDesc::load_decode_heap_oop(p);
//快速判断对象是否再本次gc的region中
if (_g1->in_cset_fast_test(obj)) {
oop forwardee;
//同样的先判断是否被标记
if (obj->is_forwarded()) {
forwardee = obj->forwardee();
} else {
//没有则进行对象复制
forwardee = copy_to_survivor_space(obj);
}
oopDesc::encode_store_heap_oop(p, forwardee);
if (do_mark_object && forwardee != obj) {
mark_forwarded_object(obj, forwardee);
}
......
} else {
......
}
//这里会进入这个方法重新更新rset,因为对象被copy到survivor区和old区,所以要重新更新Rset
if (barrier == G1BarrierEvac && obj != NULL) {
_par_scan_state->update_rs(_from, p, _worker_id);
}
......
}
六、处理引用
这个阶段会先处理一些Soft,Weak,Phantom,Final,JNI,Weak等引用,具体代码在 G1CollectedHeap.evacuate_collection_set后半段中,这里就不展开了。
七、收尾工作
至此youngGC的停顿还没有解除,还需要做一些收尾工作,我们看下之前跳过的 G1CollectedHeap::evacuate_collection_set这个方法的后半段:
//我们来看看后半段
void G1CollectedHeap::do_collection_pause_at_safepoint(EvacuationInfo& evacuation_info) {
......
//释放清理重建cset,surviving_young_words
free_collection_set(g1_policy()->collection_set(), evacuation_info);
g1_policy()->clear_collection_set();
cleanup_surviving_young_words();
g1_policy()->start_incremental_cset_building();
clear_cset_fast_test();
//重置youngLis
_young_list->reset_sampled_info();
_young_list->reset_auxilary_lists();
.....
//初始化Eden区申请region
init_mutator_alloc_region();
{
//扩容策略
size_t expand_bytes = g1_policy()->expansion_amount();
if (expand_bytes > 0) {
size_t bytes_before = capacity();
if (!expand(expand_bytes)) {
......
}
}
}
...
return true;
}
这里主要是对younggc中用到一些集合进行重置,计算扩容策略,记录统计和日志信息等等,具体就不进行展开。有兴趣的读者可以自行翻阅代码学习。
最后
1.与zgc的比较:
我们还可以看出,g1的youngGC整个都是再停顿中的,包括扫描根,处理Rset和dcq,复制对象,而对于Zgc来说,初次标记只经过对对象指针的判断进行染色标记,其效率应该是远高于g1的标记效率的。
2.网上很多文章把youngGC分为这5个阶段
1.扫描根节点 2.更新Rset 3.处理Rset 4.复制对象 5.处理引用
但是我们通过源码的学习发现,虽然这个分步大致上是一致的,但是很多细节并不是那么简单。比如根节点引用的对象是先复制,之后再处理跨代引用的对象赋值,再比如更新和处理Rset其实就是先将其加入一个queue中,之后再一起复制等等,就像笔者再看源码以前,一直以为进入Rset中的card都是脏card,其实进入Rset中的card本质是脏card但是其脏的标记已经被清除。
希望经过本篇博客可以帮助大家更好的认识g1的youngGC过程中的一些细节,最后因为笔者水平有限,如果文中说明有误,欢迎指出交流.



