
一个 JVM 解释器bug在 AArch64 平台导致应用崩溃的问题分析原创
编者按:笔者遇到一个非常典型的问题,应用在 X86 正常运行,在 aarch64 上 JVM 就会崩溃。这个典型的 JVM 内部问题。笔者通过分析最终定位到是由于 JVM 中模板解释器代码存在 bug 导致在弱内存模型的平台上 Crash。在分析过程中,涉及到非常多的 JVM 内部知识,比如对象头、GC 复制算法操作、CAS 操作、字节码执行、内存序等,希望对读者有所帮助。本文介绍了一般分析 JVM crash 的方法,并且深入介绍了为什么在 aarch64 平台上引起这样的问题,最后还给出了修改方法并推送到上游社区中。对于使用非毕昇 JDK 的其他 JDK 只有在 jdk8u292、jdk11.0.9、jdk15以后的版本才得到修复,读者使用时需要注意版本选择避免这类问题发生。
背景知识
java 程序在发生 crash 时,会生成 hs_err_pid<XXX>.log 文件,以及 core 文件(需要操作系统开启相关设置),其中 hs_err 文件以文本格式记录了 crash 发生位置的小范围精确现场信息(调用栈、寄存器、线程栈、致命信号、指令上下文等)、jvm 各组件状态信息(java 堆、jit 事件、gc 事件)、系统层面信息(环境变量、入参、内存使用信息、系统版本)等,精简记录了关键信息。而 core 文件是程序崩溃时进程的二进制快照,完整记录了崩溃现场信息,可以使用 gdb 工具来打开 core 文件,恢复出一个崩溃现场,方便分析。
约束
文中描述的问题适用于 jdk8u292 之前的版本。
现象
某业务线隔十天半个月总会报过来 crash 问题,crash 位置比较统一,都是在某处执行 young gc 的上下文中,crash 的直接原因是 java 对象的头被写坏了,比如这样:
而正常的对象头由 markoop 和 metadata 两部分组成,前者存放该对象的 hash 值、年龄、锁信息等,后者存放该对象所属的 Klass 指针。这里关注的是 markoop,64 位机器上它的具体布局如下:
每种布局中每个字段的详细含义可以在 jdk 源码 jdk8u/hotspot/src/share/vm/oops/markOop.hpp 中找到,这里简单给出结论就是 gc 阶段一个正常对象头中的 markoop 不可能是全 0,而是比如这样:
此外,crash 时间上也有个特点:基本每次都发生在程序刚启动时的几秒内。



分析
发生 crash 的 java 对象有个一致的特点,就是总位于 eden 区,我们仔细分析了 crash 位置的 gc 过程逻辑,特别是会在 gc 期间修改对象头的相关源码更是重点关注对象,因为那块代码为了追求性能,使用了无锁编程:
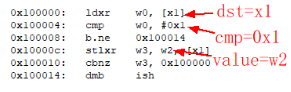
补充介绍一下 CAS(Compare And Swap),CAS 的完整意思是比较并替换,并且确保整个操作原子性。CAS 需要 3 个操作数:内存地址 dst,比较值 cmp,要更新的目标值 value。当且仅当内存地址 dst 上的值跟比较值 cmp 相等时,将内存地址 dst 上的值改写为 value,否则就什么都不做,其在 aarch64 上的汇编实现类似如下:
然而我们经过反复推敲,这块 gc 逻辑似乎无懈可击,而且位于 eden 区也意味着没有被 gc 搬移过的可能性,这个问题在很长时间里陷入了停滞……
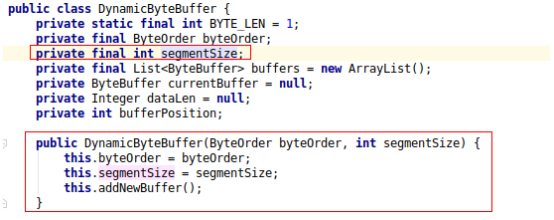
直到某一天又收到了一个类似的 crash,这个问题才迎来了转机。在这个 crash 里,也是 java 对象的头被写坏了,但特殊的地方在于,头上的错误值是 0x2000,凭着职业敏感,我们猜测这个特殊的错误值是否来自这个 java 对象本身呢?这个对象的 Java 名字叫 DynamicByteBuffer,来自某个基础组件。反编译得到了问题类 DynamicByteBuffer 的代码:
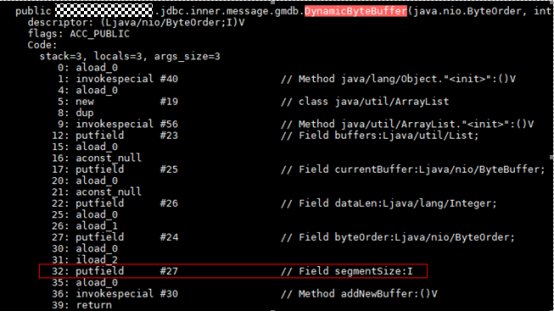
再结合 core 信息中其他正常 DynamicByteBuffer 对象的布局,确定了这个特殊的 0x2000 值原本应该位于 segmentSize 字段上,而且从代码中注意到这个 segmentSize 字段是 final 属性,意味着其值只可能在实例构造函数中被设置,使用 jdk 自带的命令 javap 进行反汇编,得到对应的字节码如下:
putfield 这条字节码的作用是给 java 对象的一个字段赋值,在红框中的语义就是给 DynamicByteBuffer 对象的 segmentSize 字段赋值。
分析到这里,我们做一下小结,crash 的第一现场并非在 gc 上下文中,而是得往前追溯,发生在这个 java 对象被初始化期间,这期间在初始化它的 segmentSize 字段时,因为某种原因,0x2000 被写到了对象头上。

接下来继续分析, JDK 在发生 crash 时会自动生成的 hs_err 日志,其中有记录最近发生的编译事件 “Compilation events (250 events)”,从中没有发现 DynamicByteBuffer 构造函数相关的编译事件,所以可以推断 crash 时 DynamicByteBuffer 这个类的构造函数尚未被编译过(由于 crash 发生在程序启动那几秒,JIT 往往需要预热后才会介入,所以可以假设记录的比较完整),这意味着,它的构造函数只会通过模板解释器去执行,更具体地说,是去执行模板解释器中的 putfield 指令来把 0x2000 写到 segmentSize 字段位置。
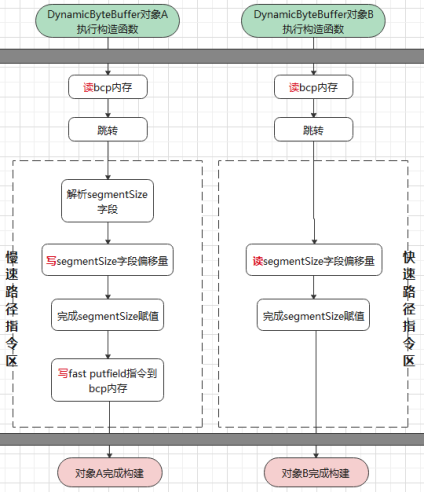
具体怎么写其实很简单,就是先拿到 segmentSize 字段的偏移量,根据偏移量定位到写的位置,然后写入。然而 JVM 的模板解释器在实现这个 putfield 指令时,额外增加了一条快速实现路径,在 runtime 期间会自动(具体的时间点是 “完整” 执行完第一次 putfield 指令后)从慢速路径切到快速路径上,这个切换操作的实现全程没有加锁,同步完全依赖 barrier,由于整个过程比较复杂,这里首先给一个比较容易理解的并行流程图:
注:图中 bcp 指的是 bytecode pointer,就是读字节码。
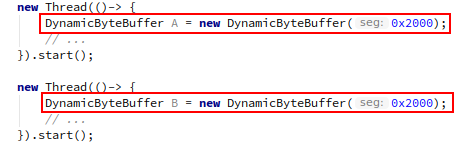
上图表示接近同一时间点前后,两条并行流分别构建一个 DynamicByteBuffer 类型的对象过程中,各自完成 segmentSize 字段赋值的过程,用 Java 代码简单示意如下:
其中第一条执行流走的慢速路径,第二条走的快速路径,可以留意到,红色标识的是几次公共内存的访存操作,barrier 就分布在这些位置前后(标在下图中)。
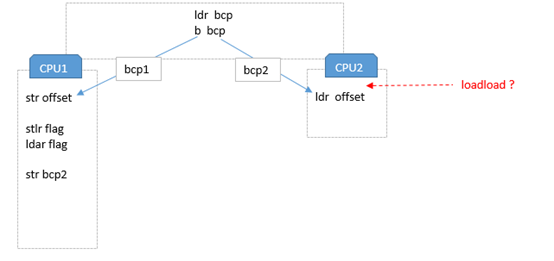
接下来再给一个更加精确一点的指令流模型:
简单介绍一下这个设计模型:
1.线程从记录了指令的内存地址 bcp(bytecode pointer) 上取出指令,然后跳转到该指令地址上执行,当取出的指令是 bcp1(比如 putfeild 指令的慢速路径)时就是图中左边的指令流;
2.左边的指令流就是计算出字段的 offset 并 str 到指定内存地址,然后插入 barrier,最后将 bcp2 指令(比如 putfeild 指令的快速路径)覆写到步骤 1 中的内存地址 addr 上;
3.后续线程继续执行步骤 1 时,由于取出的指令变成了 bcp2,就改为跳转到图中右边的指令流;
4.右边的指令流就是直接取出步骤 2 中已经存到指定内存地址中的 offset。
回顾整个设计模型,左边的指令流通过一个等效于完整 dmb 的 barrier 来保证 str offset 和 str bcp2 这两条 str 指令的执行顺序并且全局可见;而右边的指令流中,ldr bcp 和 ldr offset 这两条 ldr 指令之间没有任何 barrier,设计者可能认为一个无条件跳转指令可以为两条 ldr 指令建立依赖,从而保证执行顺序,然而从实测结果来看是不成立的。
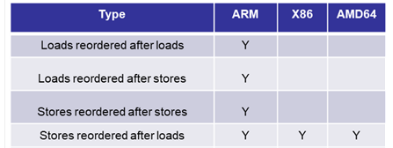
这里先来简单补充介绍一下内存顺序模型的概念,现代 CPU 为了提高执行效率,在指令的执行顺序上拥有很大的自主权,对每个独立的 CPU 来说,只要确保语义不变,实际如何执行都有可能,这种方式对于单个 CPU 来说没有问题,当放到多个 CPU 共享数据的时候,这种乱序执行的行为就会引发每个 CPU 看到数据的顺序不一致问题,导致跨 CPU 的程序逻辑乱套了。这就需要对读、写内存指令进行约束,来规范每个 CPU 看到的内存生效行为,由此提出了内存顺序模型的概念:
其中 ARM 采用的是一种弱内存模型,这种模型默认对读、写指令没有任何约束,需要由程序员自己通过插入 barrier 来手动保证。
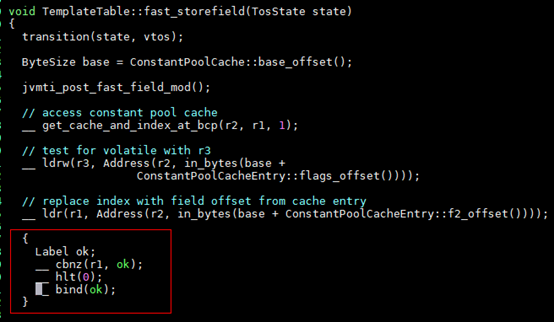
再回到这个问题上,测试方式是在 ldr offset 指令后额外加了检测指令:
就是检查 offset 值是否为 0,如果为 0 则直接强制 crash(设计上保证了 java 对象的任何实例字段的 offset 不可能是 0)。
经过长时间测试,程序果然在这个位置触发了 crash!这说明上面提到的两条 ldr 指令不存在依赖关系,或者说这种依赖关系类似 ARMv8 手册中描述的条件依赖,并不能保证执行顺序。ldr offset 指令先于 ldr bcp 执行,使得读到一个非法的 offset 值 0。更说明了,这才是这个案例的第一案发现场!
找到了问题的根因后,解决方法也就顺利出炉了,那就是在两条 ldr 指令之间插入 barrier 来确保这两条 ldr 指令不发生乱序。实测证明,这种修复方案非常有效,这类 crash 现象消失。
详细的修复 patch 见 https://hg.openjdk.java.net/jdk/jdk/rev/b9529fcbbd33 。目前已经 backport 到 jdk8u292、jdk11.0.9、jdk15。
总结
Java 虚拟机 (JVM) 为了追求性能,大量使用了无锁编程进行设计,而且这么多年以来 JDK(特别是 JDK8)主要都是面向 X86 平台开发的,如今才慢慢的开始支持 aarch64 平台,所以 aarch64 弱内存序问题是我们面临的一个比较严峻的挑战。
后记
如果遇到相关技术问题(包括不限于毕昇JDK),可以进入毕昇JDK社区查找相关资源(点击原文进入官网),包括二进制下载、代码仓库、使用教学、安装、学习资料等。毕昇JDK社区每双周周二举行技术例会,同时有一个技术交流群讨论GCC、LLVM、JDK和V8等相关编译技术,感兴趣的同学可以添加如下微信小助手,回复Compiler入群。




