FullGC实战:业务小姐姐查看图片时一直在转圈圈原创
业务小姐姐说图片访问不了,我开始慌了:
看到业务小姐姐发的这个图片,你说能不慌嘛?但是再慌也要排查问题呀!对于这种前端响应不过来的问题,首先就用浏览器的F12看看接口响应速度(获取图片地址的接口)从而确认是接口响应慢还是网络等其他问题。我勒个去,耗时10多秒呀!这时候我的心里更慌了。

问题排查
既然能确认问题在服务端,那么就查看服务端日志,准备寻找蛛丝马迹。由于服务端日志都有通过AOP记录耗时情况的,实时观察一下就能发现问题所在(说明:这个服务还没有对接APM,否则这种问题更好定位)。不看不知道,一看吓一跳,接口耗时都是10多秒,甚至20多秒,你说这客户端能不转圈圈嘛:
2019-04-19 10:11:18.533 http-nio-8007-exec-14 INFO com.xxx.image.advice.LogRequestBodyAdvice:40
2019-04-19 10:11:38.543 http-nio-8007-exec-14 INFO com.xxx.image.advice.LogResponseBodyAdvice:35 elapsed time: 20s
... ...
2019-04-19 10:31:10.111 http-nio-8007-exec-11 INFO com.xxx.image.advice.LogRequestBodyAdvice:40
2019-04-19 10:31:22.121 http-nio-8007-exec-11 INFO com.xxx.image.advice.LogResponseBodyAdvice:35 elapsed time: 12s
... ...
2019-04-19 10:45:16.244 http-nio-8007-exec-13 INFO com.xxx.image.advice.LogRequestBodyAdvice:40
2019-04-19 10:45:29.678 http-nio-8007-exec-13 INFO com.xxx.image.advice.LogResponseBodyAdvice:35 elapsed time: 13s
而且出问题的不是某一个接口,而是所有接口。那么,接下来准备从我怀疑的地方开始排查:
- 数据库问题(数据库服务器一切指标正常,也没有慢日志);
- 同步日志阻塞问题(此问题也不存在);
- 系统问题,如SWAP等(sar命令以及zabbix查看一切OK);
- GC问题;
- … …
说明:我们这个服务的特点是,只会访问数据库,没有任何其他HTPP和RPC调用,也没有缓存。
接下来就是怀疑的GC问题了,因为以前也碰到过频繁FGC导致系统无法响应,jstat命令用起来,输出结果如下:
bash-4.4$ /app/jdk1.8.0_192/bin/jstat -gc 1 2s
S0C S1C S0U S1U EC EU OC OU MC MU CCSC CCSU YGC YGCT FGC FGCT GCT
170496.0 170496.0 0.0 0.0 171008.0 130368.9 1024000.0 590052.8 70016.0 68510.8 8064.0 7669.0 983 13.961 1400 275.606 289.567
170496.0 170496.0 0.0 0.0 171008.0 41717.2 1024000.0 758914.9 70016.0 68510.8 8064.0 7669.0 987 14.011 1401 275.722 289.733
170496.0 170496.0 0.0 0.0 171008.0 126547.2 1024000.0 770587.2 70016.0 68510.8 8064.0 7669.0 990 14.091 1403 275.986 290.077
170496.0 170496.0 0.0 0.0 171008.0 45488.7 1024000.0 650767.0 70016.0 68531.9 8064.0 7669.0 994 14.148 1405 276.222 290.371
170496.0 170496.0 0.0 0.0 171008.0 146029.1 1024000.0 714857.2 70016.0 68531.9 8064.0 7669.0 995 14.166 1406 276.366 290.531
170496.0 170496.0 0.0 0.0 171008.0 118073.5 1024000.0 669163.2 70016.0 68531.9 8064.0 7669.0 998 14.226 1408 276.736 290.962
170496.0 170496.0 0.0 0.0 171008.0 3636.1 1024000.0 687630.0 70016.0 68535.6 8064.0 7669.6 1001 14.342 1409 276.871 291.213
170496.0 170496.0 0.0 0.0 171008.0 87247.2 1024000.0 704977.5 70016.0 68535.6 8064.0 7669.6 1005 14.463 1411 277.099 291.562
如果你以前没有排查太多的GC问题,那么可能你看到这段日子有点头晕。笔者以前的文章说过很多次怎么排查GC问题,有兴趣的同学可以翻看笔者公众号的JVM专栏。首先,我们要把注意力放在最后几列(YGC、YGCT、FGC、FGCT、GCT),对应的结果如下:
bash-4.4$ /log/plms/jdk1.8.0_192/bin/jstat -gc 1 2s
... ... YGC YGCT FGC FGCT GCT
... ... 983 13.961 1400 275.606 289.567
... ... 987 14.011 1401 275.722 289.733
... ... 990 14.091 1403 275.986 290.077
... ... 994 14.148 1405 276.222 290.371
... ... 995 14.166 1406 276.366 290.531
... ... 998 14.226 1408 276.736 290.962
... ... 1001 14.342 1409 276.871 291.213
... ... 1005 14.463 1411 277.099 291.562
这样就容易理解多了,看看FGC那一列:几乎每1秒都有一次FGC(说明,笔者这个服务用的是默认的PS垃圾回收器,所以FGC这一列的值一定是FullGC的次数)。而且,再看FGCT这一列,停顿时间那是相当恐怖。那么会是什么原因呢?
继续分析问题前,笔者先介绍3个JVM参数:MaxRAMPercentage、InitialRAMPercentage、MinRAMPercentage。这三个参数是JDK8U191为适配Docker容器新增的几个参数,类比Xmx、Xms,至于-XX:InitialRAMFraction、-XX:MaxRAMFraction、-XX:MinRAMFraction已经被标记为deprecated 。这几个参数的好处是什么呢?Docker容器模式下,我们可以给每个JVM实例所属的POD分配任意大小的内存上限。比如,给每个账户服务分配4G,给每个支付服务分配8G。如此一来,启动脚本就不好写成通用的了,指定3G也不是,指定6G也不是。但是,有了这三个新增参数,我们就可以在通用的启动脚本中指定75%(-XX:MaxRAMPercentage=75 -XX:InitialRAMPercentage=75 -XX:MinRAMPercentage=75)。那么,账户服务就相当于设置了-Xmx3g -Xms3g。而支付服务相当于设置了-Xmx6g -Xms6g,是不是很赞。
再给出我们的JVM参数配置(说明:POD内存限制是6G):
-XX:MaxRAMPercentage=75 -XX:InitialRAMPercentage=75 -XX:MinRAMPercentage=75
-XX:MetaspaceSize=256m -XX:MaxMetaspaceSize=256m
等价于:
-Xmx4608m -Xms4608m -XX:MetaspaceSize=256m -XX:MaxMetaspaceSize=256m
原因分析
再回到前面那一段完整的GC日志(jstat的输出结果),我们分析命令结果输出时这个JVM的一些情况:
- S0/S1区容量为170496K(对应S0C/S1C两列);
- Eden区容量为171008K(对应EC列);
- Old区容量为1024000K(对应OC列);
- Metaspace容量为70M;
根据各个区的容量大小,发现和JVM参数配置的4.5G内存出入非常大。整个堆的大小缩容了很多,从4.5G缩小到现在的大概1.5G(170496K*2+171008K+1024000K+70M ≈ 1.5G),WHY ?
如果对默认的PS垃圾回收器有一定了解的同学,可能大概知道问题所在了。没错,就是参数-XX:+UseAdaptiveSizePolicy的锅。这个参数在PS前提下默认是开启的,其作用是自动调整堆的大小,以及对象从S区晋升到Old区的年龄阈值(threshold),调节threshold逻辑为:判断Young GC和Full GC消耗的时间差:
- 如果Young gc > 1.1 * Full GC,threshold就会一直减少。
- 如果1.1* Young GC < Full GC,threshold就会一直增加。
也就是说,如果Young GC比较频繁,那么threshold可能会一直减小,直到最小值1,这时候S区的对象很容易晋升到Old区,导致Old区空间涨幅过快而触发Full GC的频率也加快。另外,这个参数是如何调整堆的大小就不在这里介绍了,因为很复杂,我也不知道,哈哈哈:
问题验证
默认PS垃圾回收器调整堆大小的这个问题很好验证,笔者写了一段简短的代码,如下所示:
/**
* @author afei, 公众号:阿飞的博客
*/
public class ParallelGcTest {
private static final int _1M = 1024 * 1024;
public static void main(String[] args) {
allocate();
}
private static void allocate(){
// 强引用分配的对象, 为了触发FGC
List<byte[]> holder = new ArrayList<>();
for (int i = 0; i < Integer.MAX_VALUE; i++) {
byte[] tmp = new byte[_1M];
// 不要让FGC来的太快
if (i%10==0) {
holder.add(tmp);
}
}
}
}
配置JVM参数(-Xmx256m -Xms256m -Xmn128m -XX:+PrintGCDetails)运行的GC日志如下,默认情况下,即-XX:+UseAdaptiveSizePolicy时,初始第一次YGC时堆大小为245760K,OOM之前最后一次FGC时堆大小为224768K,从而验证了堆缩小的现象:
[GC (Allocation Failure) [PSYoungGen: 97896K->10497K(114688K)] 97896K->10505K(245760K), 0.0030860 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
[GC (Allocation Failure) [PSYoungGen: 108661K->16312K(114688K)] 108669K->20424K(245760K), 0.0057851 secs] [Times: user=0.00 sys=0.00, real=0.01 secs]
... ...
[Full GC (Ergonomics) [PSYoungGen: 82946K->81922K(93696K)] [ParOldGen: 130906K->130906K(131072K)] 213852K->212828K(224768K), [Metaspace: 3308K->3308K(1056768K)], 0.0054117 secs] [Times: user=0.03 sys=0.00, real=0.00 secs]
[Full GC (Ergonomics) [PSYoungGen: 82946K->82946K(93696K)] [ParOldGen: 130906K->130906K(131072K)] 213852K->213852K(224768K), [Metaspace: 3308K->3308K(1056768K)], 0.0150534 secs] [Times: user=0.02 sys=0.00, real=0.02 secs]
配置JVM参数(-Xmx256m -Xms256m -Xmn128m -XX:+PrintGCDetails -XX:-UseAdaptiveSizePolicy)运行的GC日志如下,配置了-XX:-UseAdaptiveSizePolicy后,无论是初始第一次YGC时,还是OOM之前最后一次FGC时堆大小都是245760K:
[GC (Allocation Failure) [PSYoungGen: 97896K->10545K(114688K)] 97896K->10553K(245760K), 0.0030478 secs] [Times: user=0.03 sys=0.03, real=0.00 secs]
[GC (Allocation Failure) [PSYoungGen: 108709K->16264K(114688K)] 108717K->20376K(245760K), 0.0053165 secs] [Times: user=0.00 sys=0.00, real=0.01 secs]
... ...
[Full GC (Ergonomics) [PSYoungGen: 97282K->96258K(114688K)] [ParOldGen: 130906K->130906K(131072K)] 228189K->227164K(245760K), [Metaspace: 3308K->3308K(1056768K)], 0.0026970 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
[Full GC (Ergonomics) [PSYoungGen: 97282K->97282K(114688K)] [ParOldGen: 130906K->130906K(131072K)] 228189K->228189K(245760K), [Metaspace: 3308K->3308K(1056768K)], 0.0058994 secs] [Times: user=0.00 sys=0.00, real=0.01 secs]
解决方案
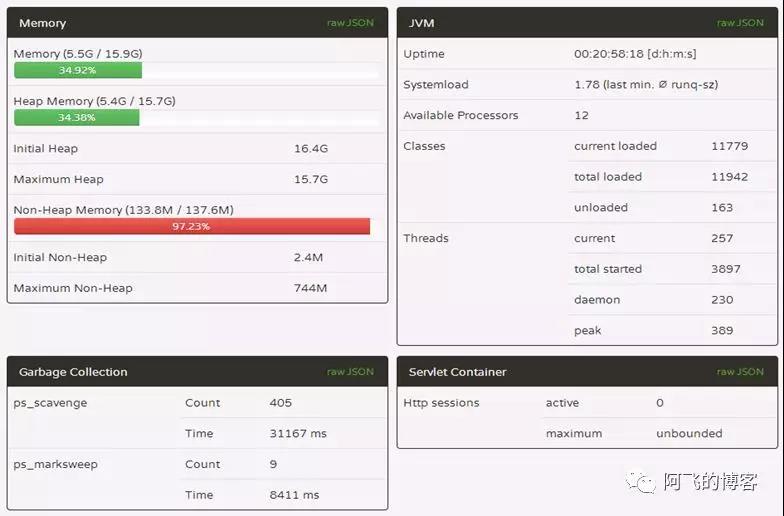
已经知道问题所在,那么就把这个参数关闭( -XX:-UseAdaptiveSizePolicy),优化后重启服务,运行一天的springboot-admin截图如下,业务小姐姐访问速度又飞起来了,图片看都看不过来,嘿嘿:
如图所示,每天还是有9次FGC,还能再优化么?后面分析业务发现,有个每分钟运行的JOB,其作用是将用户上传的PDF转成PNG图片,一个PDF有多少页就会转成多少张图片。并且,根据统计信息发现,一个有20页的PDF转成图片总计需要几十秒。那么就会导致YGC时,很可能这些正在压缩的图片任务还没有完成,从而导致这些对象(而且比较大的对象)晋升到S区,甚至晋升到Old区。所以,这个FGC不好再降低。当然,事实上也没必要再优化,因为,现在的FGC次数已经对业务基本上无感知了:每天9次FGC,每次FGC停顿时间才不到1秒(8411ms/9 ≈ 935ms),而且我们的系统并不是OLTP系统,而是给业务人员使用的。所以,有时候没必要过度优化,因为还要考虑付出的成本和获得的收益,判断是否值得我们去做这件事情。