一个fullgc引发的流血事件原创
本文正在参加「Java应用线上问题排查经验/工具分享」活动
先点赞再看,养成好习惯
背景
全国最大的短信平台,大家都用过我们的产品。数据量比较大,最多时候一天近7亿条短信。由于我们技术不很扎实,生产问题就非常的多,都是摸着石头过河,每一次故障一个血泪史,目前已经出了一本血泪史的书了。

吐糟开言:
full gc这东西折腾了我一个国庆假期。之前从来不在意这东西,后来发现他是一旦出问题就是致命的。
事件原由:
回归正题吧,9月28号项目开始出现大量RocketMQ消费重复的情况。然后就开始着手排查,不过慢慢排查分析已经赶不上事态的升级了,5分钟已经由小故障变成大故障了,然而这5分钟过得很快,还没分析出头绪呢,投诉已经铺天盖地了。大故障已经演变成了事故了。没办法就开始采取应急手段,因为有些客户手机开始出现间断性短信轰炸,于是开始关停客户等等手段来扼制这种事情,但是出现同样问题的客户越来越多已经来不及一个一个关停了,就赶紧停掉应用来应 对这个事。
分析步骤:
1.先直观分析问题产生原因
因为是消息重发,肯定想到是 RcoketMQ 消费重复的情况。RocketMQ 重复消费 那就是在消费者增加或者剔除的时候会造成重复消费(具体怎么重复消费我就不 在这说了)。然后就去查应用的 RocketMQ 日志,看到很多消息出现 request timeout 的情况。猜测可能是网络情况,导致应用跟 RocketMQ 已经断链了,然 后消费者出现不稳定导致消费重复。但是查了 netstat 链接正常呀,为何出现超 时呢,然后就怀疑是网络问题火急火燎的找网络人员分析是不是有问题,然后找 网络人员看了网络也是正常的(后续一直在找网络人员扯皮,其实我们也有责任, 在这给人家道个歉)。
2.排查网络情况
网络正常……!!!然后开始通过命令查这个消费者有多少个链接,查出来是 41 个,然后有点疑问不是 42 个吗?因为我们每一组机器是 2 台(当时架构设计 保障双活单台机器宕机不影响业务)。然后我去查其他问题的时候,同事说这个 消费者链接变成 42 个了,这时候终于找到罪魁祸首了(如释重负)。过一会儿 又查又成 41 了(这个时候消息重复现象还是非常严重)。然后通过命令查到 42 个连接的 ip,然后又查了 41 个连接的 ip。然后找到有一个突出的 IP,为了进 一步确认是他,查了两次结果还是他。然后开干找到这台机器果断把他上面的应 用停机了(毫不犹豫)。迅速把该机器上的客户迁移到其他机器上。慢慢的投诉 也少了。然后总觉得这件事不是那么简单的。接下来就开始仔细的分析。
3.查看连接数状态
开始再次查了 netstat(和 rocketmq 链接)监控,如果消费者频繁剔除和新 增的话,那连接也可能会断,但是连接监控好像没发现什么问题,都很正常。不 经意间发现 Recv_Q 出现了堆积,而且堆积的数据还很多基本都是在 5 位数或者 6 位数。然后这个时候就可以解释说明为啥出现 request timeout 了,响应的数 据都在 Recv_Q 未处理导致认为消息请求超时。Recv_Q 堆积那就是应用的处理能 力不足。为啥会处理能力不足呢?这又开启了新的问题探究,这时候觉得前面有 无数个坑在等着我,我怕越抛越深,但是甲方爸爸在催促出故障报告和后期平账 方案。就草草给提供了一个故障报告。
4.日常甩锅
也许是责任心也有可能是好奇心驱使,然后继续深究,上面看到 Recv_Q 很多 数据未处理,那咱们就差 jsatck 看看系统当时都在干嘛?然后查到很多线程都在一个代码块上执行着(这是第三方提供的一个算法),这个时候就猜测他们代码有问题,要么是效率太差。这时候自信满满的觉得这个锅我要甩出去了。但是这个时候一个大师说了一嘴真的没有 full gc 吗?我总以为此刻的 full gc会输出到 error或者 log日志里面,就信誓旦旦的说没有(其实为了掩饰自己的无知),说完后我就去查了一 下,才发现生产真有gc日志文件。
5.接下来就开始深究 gc 日志了。
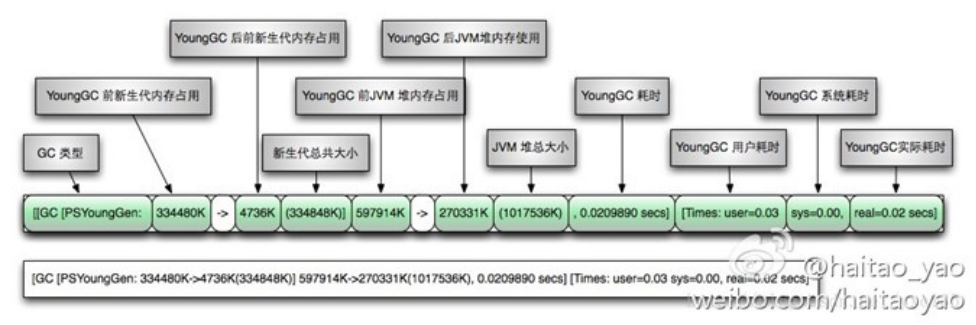
通过 gc 日志还真发现了 full gc。先展示现象逐步分析:通过这个图(这个图 有点老或许是 jdk1.7 的凑合看)分析吧,jdk 版本是 1.8 的,因此只有新生代 和老年代。新老默认分是 1:2,我们配置的是 8G。那就是新生代 8/3G=2.6G,老 年代就是 16/3G=5.3G。此处都是约等。
2020-09-30T01:57:27.016+0800: 123505.544: [GC (Allocation Failure) 2020-09-30T01:57:27.018+0800: 123505.546: [ParNew: 2110950K->15960K(2621440K), 0.4462201 secs] 5822618K->3727804K(7864320K), 0.4493196 secs] [Times: user=5.65 sys=0.00, real=0.45 secs]
可以看得出来1点57分27秒的时候触发了一次gc回收,虽然出现了GC (Allocation Failure) 但是回收也算OK吧。
GC (Allocation Failure):表明本引起GC的原因是因为在年轻代中没有足够的空间能够存储新的数据了。
ParNew:就是新生代或者叫年轻代。 表明本次GC发生在年轻代并且使用的是ParNew垃圾收集器。ParNew是一个Serial收集器的多线程版本,会使用多个CPU和线程完成垃圾收集工作(默认使用的线程数和CPU数相同,可以使用-XX:ParallelGCThreads参数限制)。该收集器采用复制算法回收内存,期间会停止其他工作线程,即Stop The World。
会出现下面一行话,具体我就不翻译了看一眼就能明白:Total time for which application threads were stopped: 0.2991738 seconds, Stopping threads took: 0.0005475 seconds
ParNew: 2110950K->15960K(2621440K), 0.4462201 secs:新生代回收前堆大小2110950K,回收后堆大小15960K,总堆大小2621440K。新生代此刻回收了多少,我就不在计算了自己减一下就是了。这个时候2621440K正好能对的上上面新生代分了2.6个G内存。此次回收耗时0.4462201 secs(秒,总有些人不知道哈哈);
5822618K->3727804K(7864320K), 0.4493196 secs:堆区垃圾回收前的大小,堆区垃圾回收后的大小,堆区总大小。
2020-09-30T02:02:53.336+0800: 123831.864: Total time for which application threads were stopped: 0.2050041 seconds, Stopping threads took: 0.0006543 seconds。
注1
GC (CMS Initial Mark):
收集阶段,这个阶段会标记老年代全部的存活对象,包括那些在并发标记阶段更改的或者新创建的引用对象;
YG occupancy: 1900186 K (2621440 K):年轻代当前占用情况和容量;说明够用了。
Rescan (parallel) , 0.1469902 secs:这个阶段在应用停止的阶段完成存活对象的标记工作;执行了这么长时间。
weak refs processing, 0.0081846 secs:第一个子阶段,随着这个阶段的进行处理弱引用;这玩意是啥我真的不清楚哈哈,感觉不很重要,最主要就是看个时间,时间大了肯定就不正常了。
class unloading, 0.0273789 secs:第二个子阶段。
scrub symbol table, 0.0081663 secs:最后一个子阶段。
CMS-remark: 4203311K(5242880K)] 6103497K(7864320K):在这个阶段之后老年代占有的内存大小和老年代的容量,后面追加的一般都是总量,堆内存大小和总堆内存大小。
2020-09-30T02:02:56.051+0800: 123834.579: [CMS-concurrent-reset: 0.012/0.012 secs] [Times: user=0.04 sys=0.00, real=0.01 secs]
CMS-concurrent-reset-start:开始并发标记(concurrent-mark-start) 阶段注2,在第一个阶段被暂停的线程重新开始运行,由前阶段标记过的对象出发,所有可到达的对象都在本阶段中标记。就是在垃圾回收的时候所有线程都被停止了。看注1
CMS-concurrent-sweep: 2.473/2.702 secs:并发标记阶段结束,占用 2.473秒CPU时间, 2.702秒墙钟时间(也包含线程让出CPU给其他线程执行的时间)
2020-09-30T02:13:38.524+0800: 124477.052: [GC (CMS Initial Mark) [1 CMS-initial-mark: 4319020K(5242880K)] 4843833K(7864320K), 0.1291383 secs] [Times: user=0.51 sys=0.00, real=0.12 secs]
上面描述的是:开始使用CMS回收器进行老年代回收。初始标记(CMS-initial-mark)阶段,这个阶段标记由根可以直接到达的对象,标记期间整个应用线程会暂停。老年代容量为5242880K,CMS 回收器在空间占用达到 4319020K时被触发
2020-09-30T02:13:38.654+0800: 124477.182: Total time for which application threads were stopped: 0.1321627 seconds, Stopping threads took: 0.0002331 seconds
这就不在说了吧,上面描述的很清楚这是干嘛的。
2020-09-30T02:13:38.654+0800: 124477.182: [CMS-concurrent-mark-start]
开始并发标记(concurrent-mark-start) 阶段,在第一个阶段被暂停的线程重新开始运行,由前阶段标记过的对象出发,所有可到达的对象都在本阶段中标记。看注2
2020-09-30T02:13:42.760+0800: 124481.289: [CMS-concurrent-mark: 4.107/4.107 secs] [Times: user=16.97 sys=0.00, real=4.10 secs]
并发标记阶段结束,占用 4.107秒CPU时间, 4.107秒墙钟时间(也包含线程让出CPU给其他线程执行的时间)
2020-09-30T02:13:42.761+0800: 124481.289: [CMS-concurrent-preclean-start]
开始预清理阶段,预清理也是一个并发执行的阶段。在本阶段,会查找前一阶段执行过程中,从新生代晋升或新分配或被更新的对象。通过并发地重新扫描这些对象,预清理阶段可以减少下一个stop-the-world 重新标记阶段的工作量。
2020-09-30T02:13:42.798+0800: 124481.326: [CMS-concurrent-preclean: 0.036/0.037 secs] [Times: user=0.04 sys=0.00, real=0.04 secs]
预清理阶段费时 0.036秒CPU时间,0.037秒墙钟时间。这块说实话我也不太懂,我个人认为是CPU执行了0.036,真正执行到结束的时间是0.037.
2020-09-30T02:13:42.798+0800: 124481.327: [CMS-concurrent-abortable-preclean-start] CMS: abort preclean due to time 2020-09-30T02:13:52.273+0800: 124490.801: [CMS-concurrent-abortable-preclean: 9.471/9.475 secs] [Times: user=11.14 sys=0.00, real=9.47 secs]
可终止的并发预清理开始运行, 9.471/9.475 secs展示该阶段持续的时间和时钟时间。同上解释。
6.接下来开始分析full gc了,上面都是铺垫。
提前打个埋伏,我们平台凌晨2点会定时同步一些数据,如携号转网(目测1000万左右),还有等等一些数据,目的是为了对比前一天和总量差异的数据防止漏网之鱼,总体占用约2个G左右。但是这个时候会翻倍,因为同步之前是2个G,再加上这个时候加载数据库进来的全量数据2个G那就翻倍了。
2020-10-01T06:40:55.515+0800: 226914.043: [Full GC (Allocation Failure) 2020-10-01T06:40:55.515+0800: 226914.043: [CMS2020-10-01T06:40:59.411+0800: 226917.939: [CMS-concurrent-mark: 5.357/5.365 secs] [Times: user=27.02 sys=0.20, real=5.36 secs] (concurrent mode failure): 5242880K->5242879K(5242880K), 28.6013685 secs] 7864319K->6907149K(7864320K), [Metaspace: 65339K->65339K(1107968K)], 28.6018758 secs] [Times: user=40.18 sys=0.00, real=28.60 secs]
2020-10-01T06:41:56.714+0800: 226975.242: Total time for which application threads were stopped: 27.4420002 seconds, Stopping threads took: 0.0004846 seconds
concurrent mode failure: CMS垃圾收集器特有的错误,CMS的垃圾清理和引用线程是并行进行的,如果在并行清理的过程中老年代的空间不足以容纳应用产生的垃圾(也就是老年代正在清理,从年轻代晋升了新的对象,或者直接分配大对象年轻代放不下导致直接在老年代生成,这时候老年代也放不下)5242880K->5242879K(5242880K), 28.6013685 secs这个地方可以看得出来老年代已经没有空间了,执行前和执行后大小没啥变化,执行时间还贼长。 Total time for which application threads were stopped: 27.4420002 seconds, 28秒整个应用的所有线程都是stop状态。
Metaspace: 65339K->65339K(1107968K):这个就是之前说的永久代,1.8以后就成这个了叫元空间。他也满了。这玩意大小都是用的默认的20.xxxxxxxM,小数点后面很多位,具体我也不写了。
full gc后系统所有线程都停了27.4420002秒,相当于这么长时间都不干活了。但是时间还是正常的走的,譬如心跳时间,响应时间等这东西还是正常计算的,并不会因为你停了27秒,他们就不计算了。因此这块就导致了第三条Recv_Q堆积,因为大家都不干活了,接收缓冲区肯定堆积呀。还有就是应用和RocketMQ之间的心跳是30秒,你这27.4秒都不干活。这个时候老年代又开始回收了1.9秒
2020-10-01T06:41:58.717+0800: 226977.245: [GC (CMS Initial Mark) [1 CMS-initial-mark: 5242879K(5242880K)] 7644223K(7864320K), 1.9442440 secs] [Times: user=2.59 sys=0.00, real=1.94 secs] ,相当于29秒都没干活。30秒心跳一次然后RocketMQ认为你都没心跳了,那就把你剔除消费集群。然后这个时候开始2020-10-01T06:41:27.847+0800: 226946.375: [CMS-concurrent-mark-start]就是所有线程开始恢复了,这时应用和RocketMQ又开始创建了连接。又可以正常消费了。但是过了2秒又开始full gc了2020-10-01T06:41:29.276+0800: 226947.804: [Full GC (Allocation Failure)。其实项目就运行了2秒钟左右。然后反复的出现full gc,那就是跟RocketMQ断了连,连接再断。
7.针对full gc预防手段和解决方案
1.项目也迭代了N多个版本了,但是该应用的内存分配依旧不变一直配置的是8G,每次增加新功能都漏掉内存会增加多少这块考虑,就知道用内存处理数据速度快,但是从来不考虑占用多少?会引发什么问题等等。总觉得他不太重要但是一旦爆发就是致命的。
2.临时调高-Xms12288m -Xmx12288m -Xmn4096m 这几个参数的大小,来缓解full gc问题。这个是非常明显的。
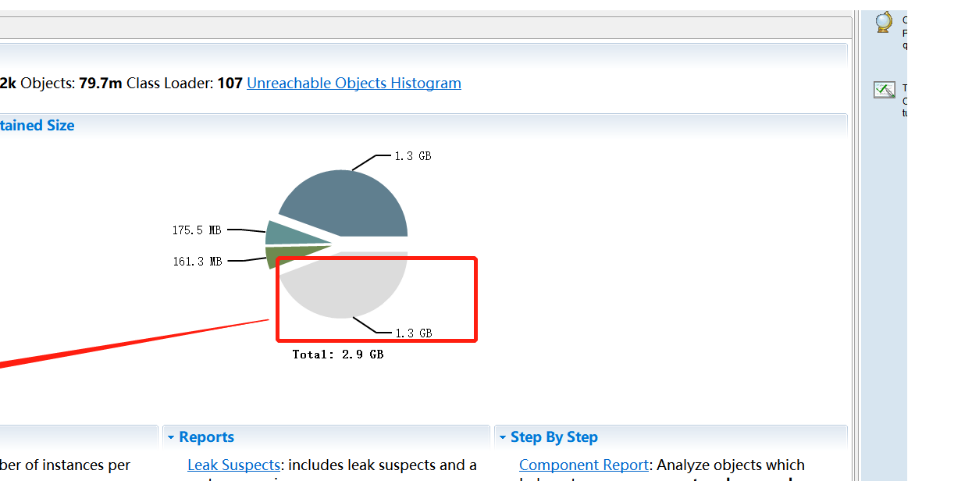
3.在临时解决的情况下,赶紧抓内存镜像,然后分析内存中占用的数据比。如下图:
怎么抓内存镜像命令我就不说了吧,太简单了。分析工具我用的是MemoryAnalyzer.exe。这东西很耗笔记本内存,不然打不开。这个就很明白的给你分析出来哪个类占用了多少内存,除了白色其他块他有表明是哪个类占用了多少内存,白色为其他数据占用内存这个暂时无法分析,大概就发普通数据流转内存使用。
注:上面各条描述中的数据都是由下图提取出来的,该图是我们平台出现问题的那台机器的gc日志。