记一次线上内存过高的问题解决原创
本文正在参加「Java应用线上问题排查经验/工具分享」活动
背景
线上**-product-center服务器发现有报警,
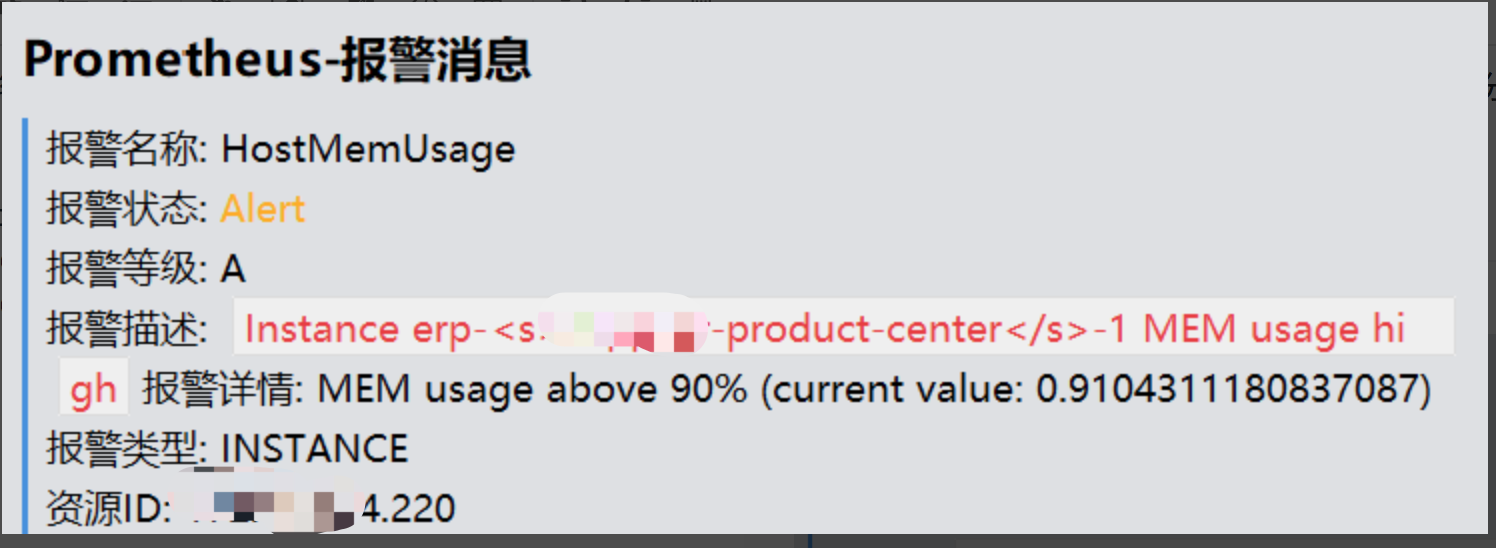
从报警看出内存占用过高,开始定位问题
解决
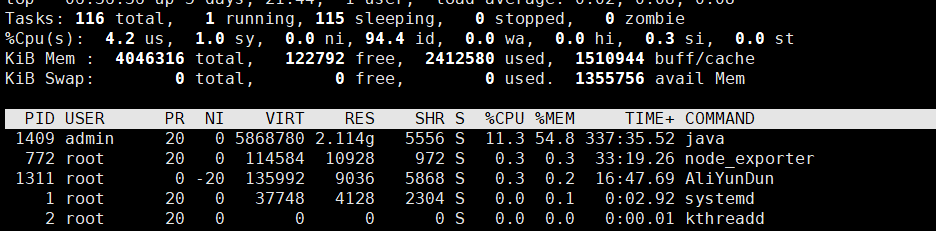
去有问题的服务器看cpu负载,通过top命令
一开始打算看log找问题,但是不好定位,只是看到log日志有大的对象输出,其实这里大概能看出有程序大对象的问题,但是优化过一版本之后还是偶尔会有报警出来。
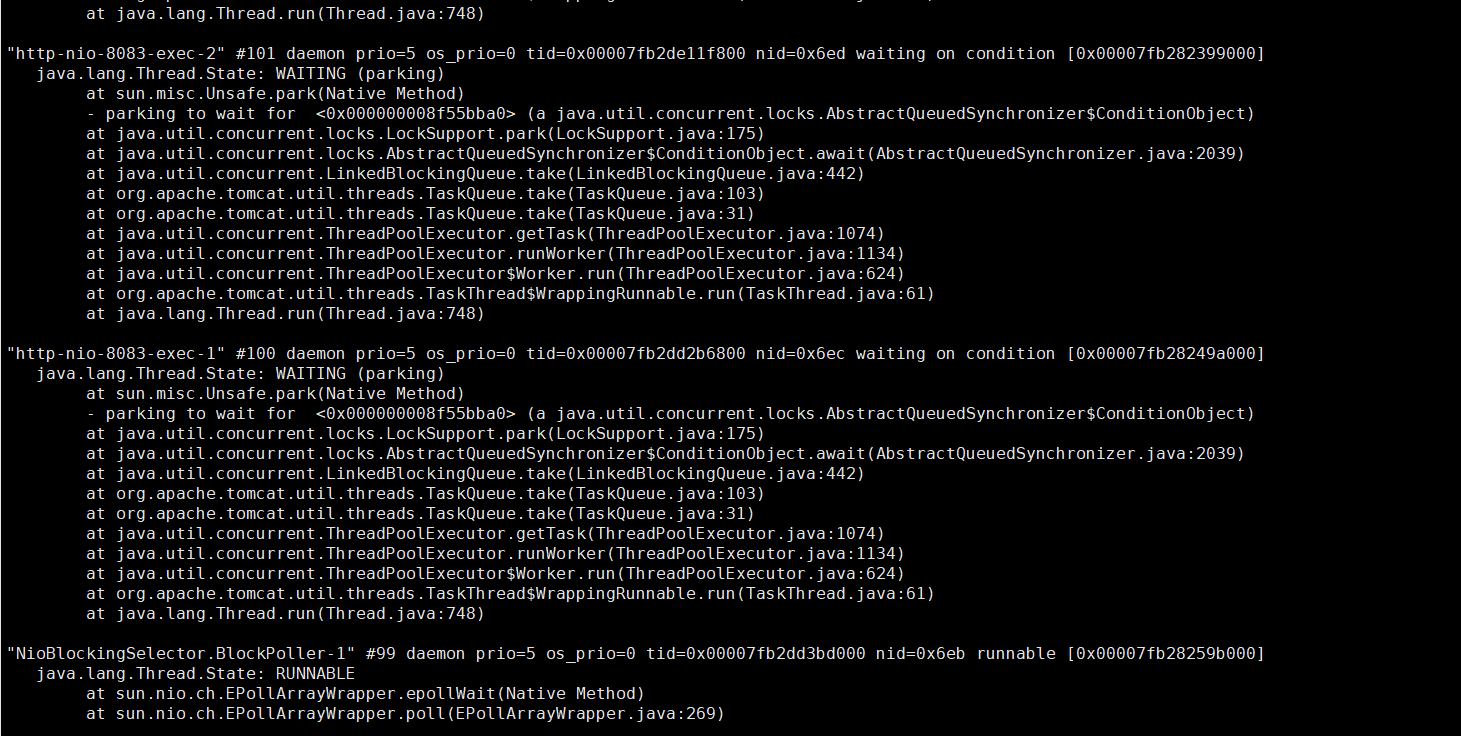
后来通过jstack命令看能不能发现一些端倪,结果发现并无卵用,可能自家内功修炼还不够并未发现问题~
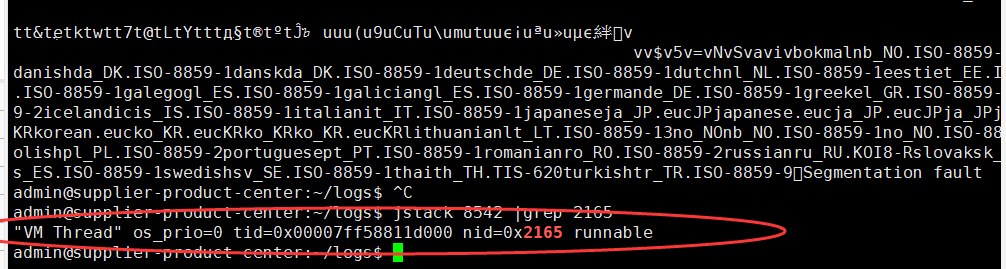
通过 top -Hp pid找到cpu过高的进程,转换16进制,可以使用linux自带命令printf "%x\n" pid,通过jstack pid |grep tid看打印结果
这里的VM Thread一行显示nid=0x2165,这里nid的意思就是操作系统线程id的意思。而VM Thread指的就是垃圾回收的线程,而此线程刚刚cpu负载比较高,这里我们基本上可以确定,当前系统缓慢的原因主要是垃圾回收过于频繁,导致GC停顿时间较长。
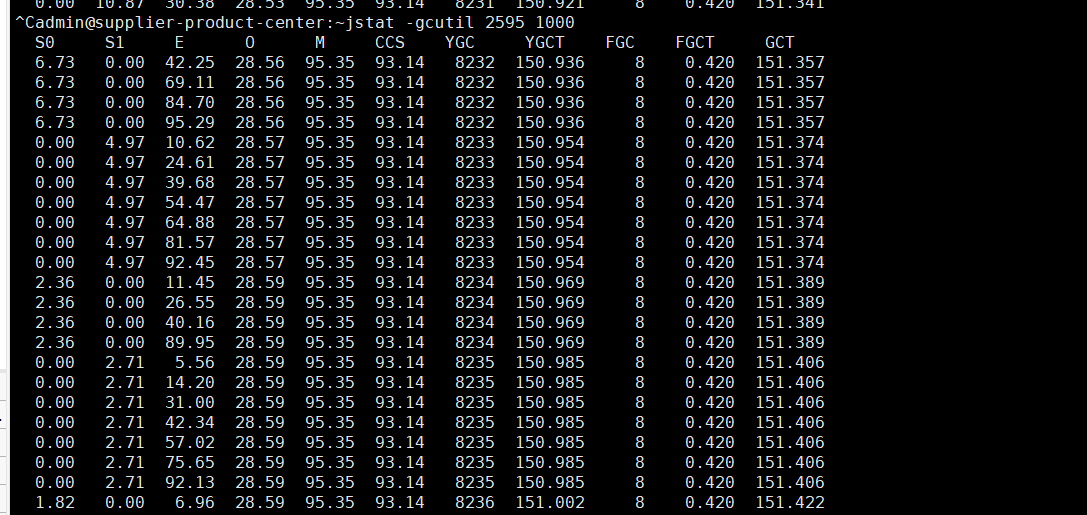
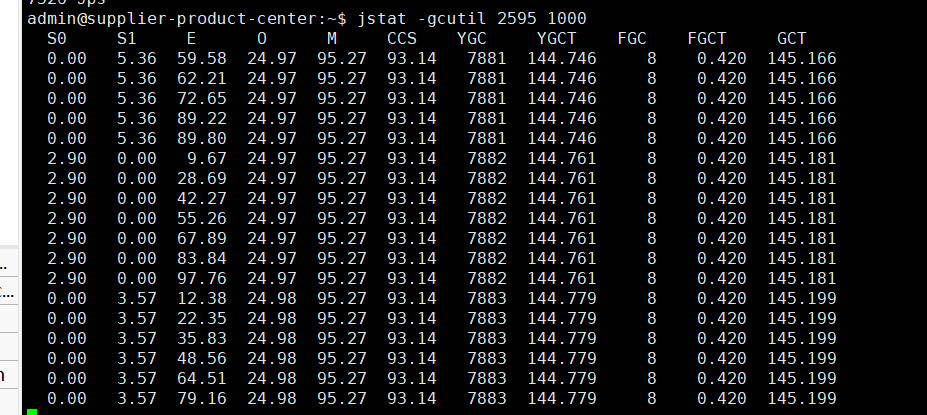
下图FGC次数为8,比较正常。
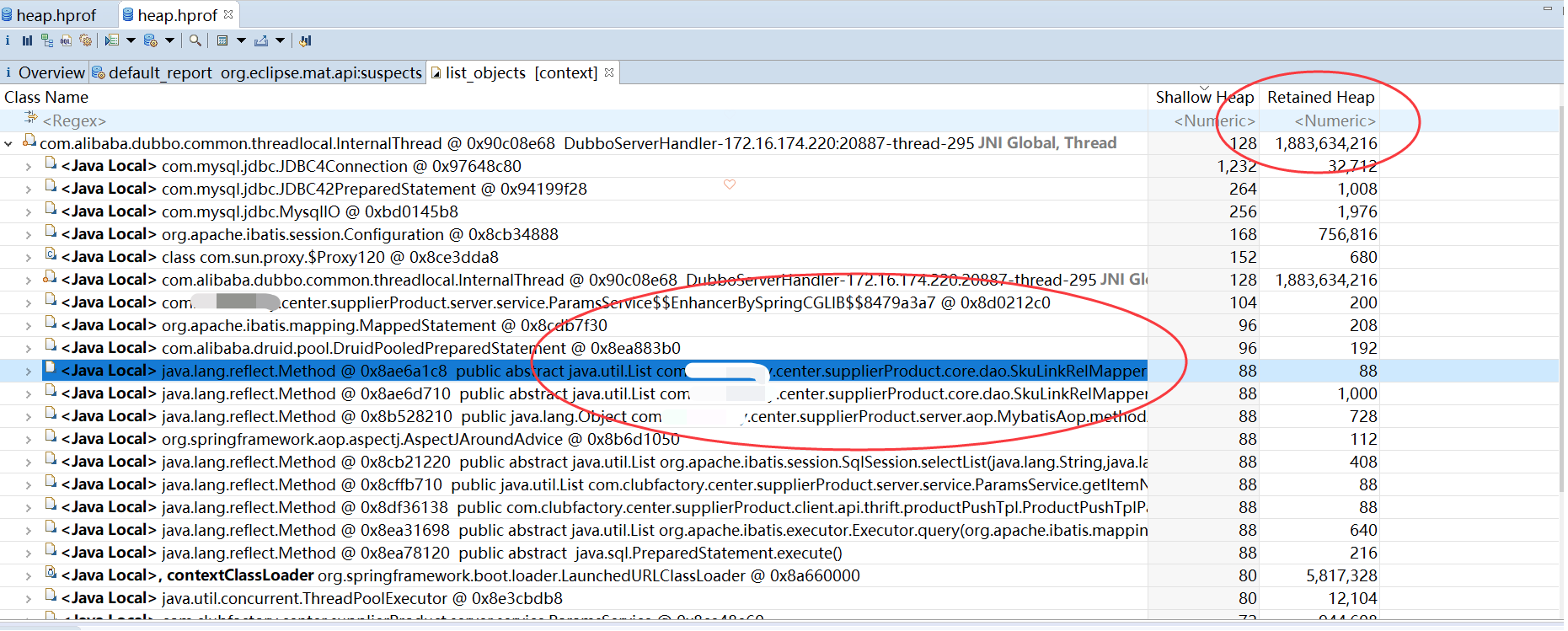
当时没有截图记得当时的FGC值是六百多次,而且每次一旦cpu过高FGC次数就会增长较快,可进一步确认是内存溢出或者程序有大对象导致。当时jmap -dump:format=b,file=/home/admin/logs/heap.hprof pid dump出内存日志。但是线上服务器下载大文件容易影响线上IO,然后在线上安装了rclone上传到文件服务器,然后在本地pc安装rclone下载文件。通过MAT工具打开,下面直接贴图,看图就可察觉到问题了。
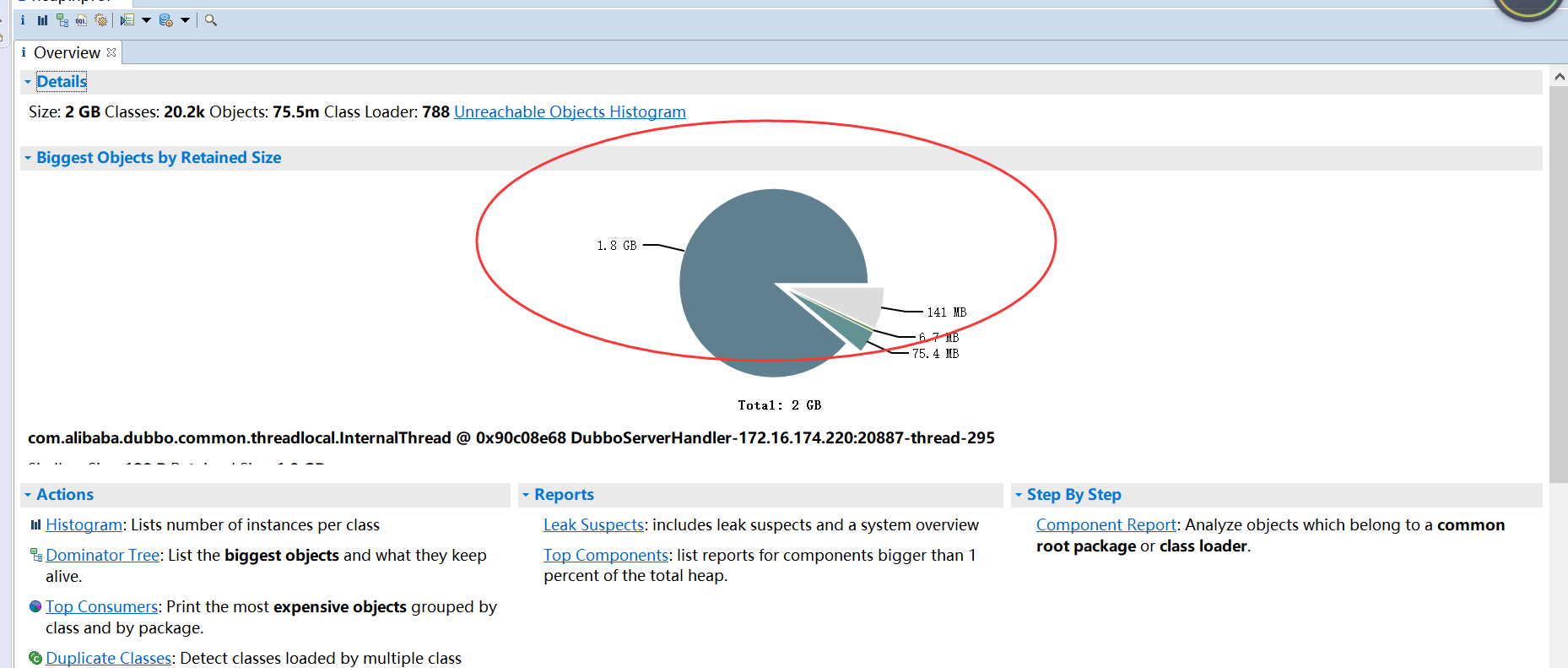
用MAT打开一个hprof文件后一般会进入如下的overview界面,或者和这个界面类似的leak suspect界面,overview界面会以饼图的方式显示当前消耗内存最多的几类对象,可以使我们对当前内存消耗有一个直观的印象
以直方图的方式来显示当前内存使用情况可能更加适合较为复杂的内存泄漏分析
shallow heap:指的是某一个对象所占内存大小。
retained heap:指的是一个对象的retained set所包含对象所占内存的总大小。
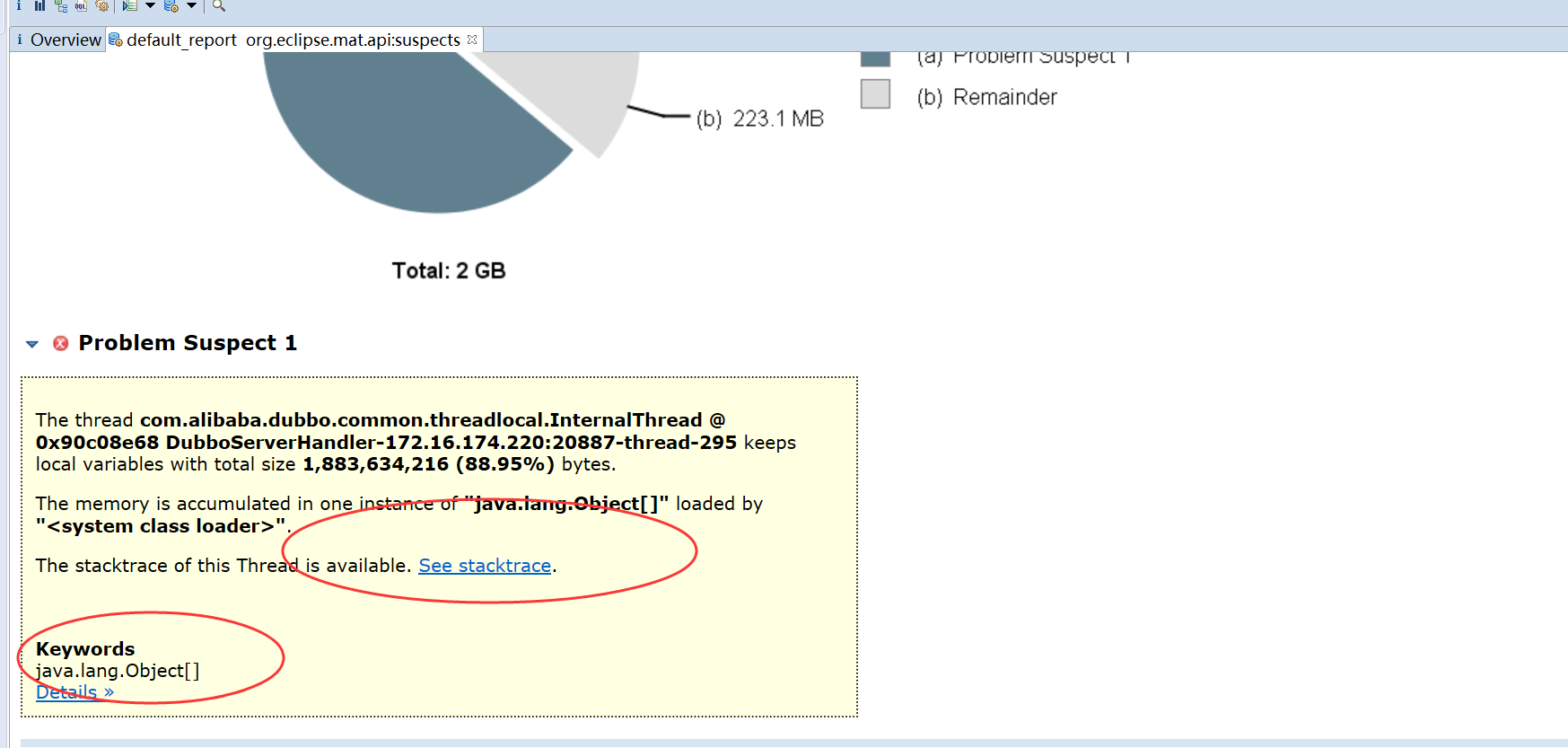
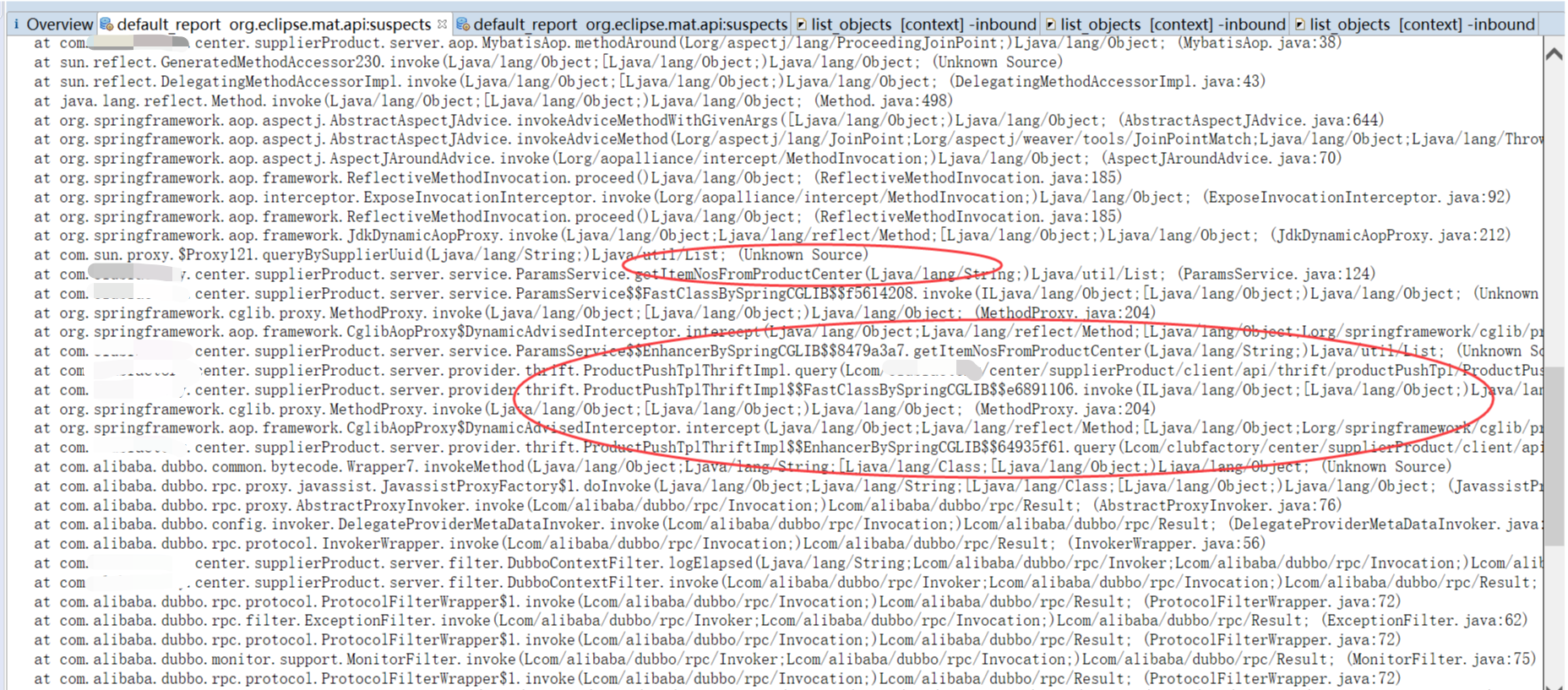
经过mat工具分析之后,我们基本上就能确定内存中主要是哪个对象比较消耗内存,然后找到该对象的创建位置,进行处理即可,这里主要是ArrayList最对,关键词也是java.lang.Object[],可以看出大对象导致大量Full GC。
到此已定位到问题,更改代码发版解决。
小结
此次问题第一天没有找出来,没来得及dump出堆栈信息,第二天才解决。
对于线上的系统突然产生的问题,如果问题导致服务不可用,首先要做的导出jstack和内存信息,查看当时问题记录,然后重启系统,尽快保证服务可用性。
一般线上服务cpu较高以及full gc过多不外乎几种情况:大对象过多或者数据量过大导致Full GC频繁从而系统缓慢,另外的或者有比较耗CPU的计算工作;另外有些有可能有死循环或者锁使用不当导致死锁等。
稍微总结下步骤:
通过`jps`或者`ps -ef|grep java`找到java进程pid;
通过`top` 查看cpu情况,如果cpu过高,通过`top -Hp pid`查看当前进程的各个线程情况,找到cpu过高的线程;
通过`printf "%x\n" pid` 命令转换16进制;
通过`jstack pid |grep tid`查看线程工作:如果是正常的用户线程,则通过该线程的堆栈信息查看其具体是在哪处用户代码处运行比较消耗CPU;如果该线程是`VM Thread`,则通过`jstat -gcutil pid time `命令监控当前系统的GC状况,然后通过`jmap dump:format=b,file= `导出系统当前的内存数据。导出之后将内存情况放到MAT工具中进行分析即可得出内存中主要是什么对象比较消耗内存,进而可以处理相关代码;
另外我们也可以多用jstat -gcutil pid time多关注下ygc以及fgc次数
当然问题出来了,我们平时可以怎么避免尽量减少这种情况的发生呢?个人认为代码的严谨性是第一位。