
Java最前沿技术——ZGC原创
ZGC介绍
ZGC(The Z Garbage Collector)是JDK 11中推出的一款追求极致低延迟的实验性质的垃圾收集器,它曾经设计目标包括:
- 停顿时间不超过10ms;
- 停顿时间不会随着堆的大小,或者活跃对象的大小而增加;
- 支持8MB~4TB级别的堆(未来支持16TB)。
当初,提出这个目标的时候,有很多人都觉得设计者在吹牛逼。
但今天看来,这些“吹下的牛逼”都在一个个被实现。
基于最新的JDK15来看,“停顿时间不超过10ms”和“支持16TB的堆”这两个目标已经实现,并且官方明确指出JDK15中的ZGC不再是实验性质的垃圾收集器,且建议投入生产了。
ZGC已经熟了,面试题还会远吗?
本文会从ZGC的设计思路出发,讲清楚为何ZGC能在低延时场景中的应用中有着如此卓越的表现。
核心技术
多重映射
为了能更好的理解ZGC的内存管理,我们先看一下这个例子:
你在你爸爸妈妈眼中是儿子,在你女朋友眼中是男朋友。在全世界人面前就是最帅的人。你还有一个名字,但名字也只是你的一个代号,并不是你本人。将这个关系画一张映射图表示:
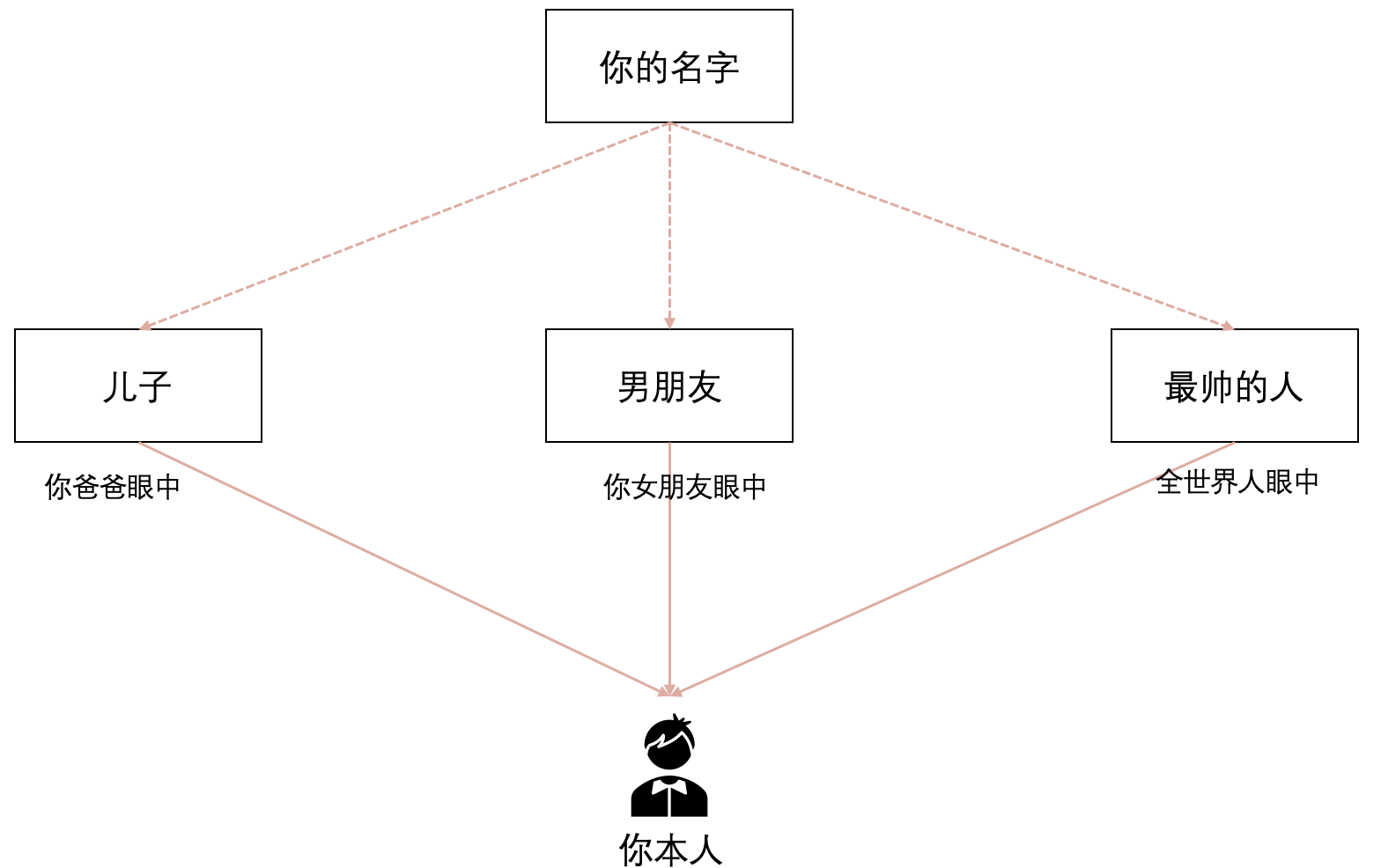
- 在你爸爸的眼中,你就是儿子;
- 在你女朋友的眼中,你就说男朋友;
- 站在全世界角度来看,你就说世界上最帅的人;
假如你的名字是全世界唯一的,通过“你的名字”、“你爸爸的儿子”、“你女朋友的男朋友”,“世界上最帅的人”最后定位到的都是你本人。
现在我们再来看看ZGC的内存管理。
ZGC为了能高效、灵活地管理内存,实现了两级内存管理:虚拟内存和物理内存,并且实现了物理内存和虚拟内存的映射关系。这和操作系统中虚拟地址和物理地址设计思路基本一致。
当应用程序创建对象时,首先在堆空间申请一个虚拟地址,ZGC同时会为该对象在Marked0、Marked1和Remapped三个视图空间分别申请一个虚拟地址,且这三个虚拟地址对应同一个物理地址。
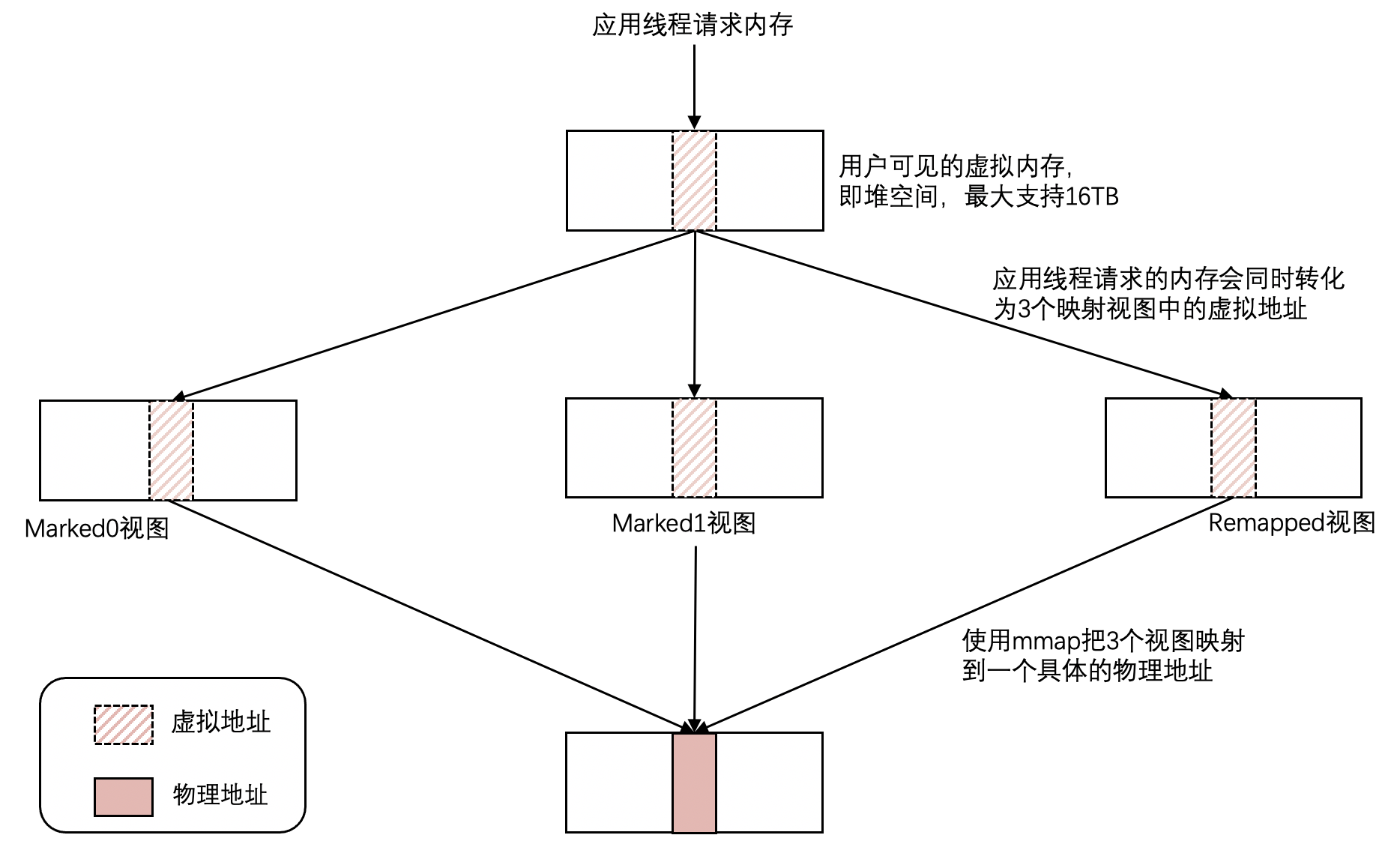
图中的Marked0、Marked1和Remapped三个视图是什么意思呢?
对照上面的例子,这三个视图分别对应的就是"你爸爸眼中",“你女朋友的眼中”,“全世界人眼中”。
而三个视图里面的地址,都是虚拟地址,对应的是“你爸爸眼中的儿子”,“你女朋友眼中的男朋友”…
最后,这些虚地址都能映射到同一个物理地址,这个物理地址对应上面例子中的“你本人”。
用一段简单的Java代码表示这种关系:
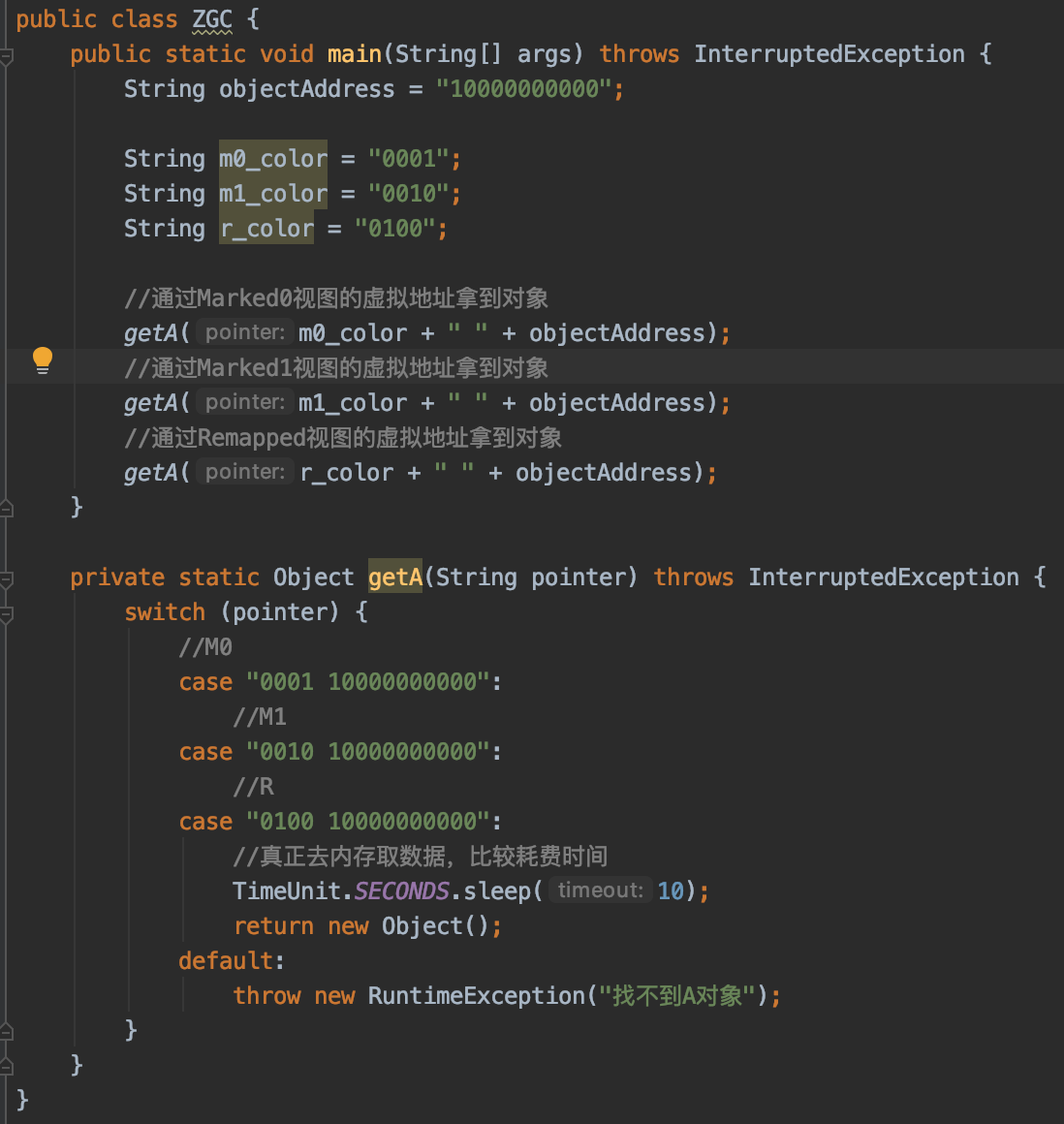
在ZGC中这三个空间在同一时间点有且仅有一个空间有效。
为什么这么设计呢?这就是ZGC的高明之处,利用虚拟空间换时间,这三个空间的切换是由垃圾回收的不同阶段触发的,通过限定三个空间在同一时间点有且仅有一个空间有效高效的完成GC过程的并发操作,具体实现会在后面讲ZGC并发处理算法的部分再详细描述。
染色指针
在讲ZGC并发处理算法之前,还需要补充一个知识点——染色指针。
我们都知道,之前的垃圾收集器都是把GC信息(标记信息、GC分代年龄…)存在对象头的Mark Word里。举个例子:
如果某个人是个垃圾人,就在这个人的头上盖一个“垃圾”的章;如果这个人不是垃圾了,就把这个人头上的“垃圾”印章洗掉。
而ZGC是这样做的:
如果某个人是垃圾人。就在这个人的身份证信息里面标注这个人是个垃圾,以后不管这个人在哪刷身份证,别人都知道他是个垃圾人了。也许哪一天,这个人醒悟了不再是垃圾人了,就把这个人身份证里面的“垃圾”标志去掉。
在这例子中,“这个人”就是一个对象,而“身份证”就是指向这个对象的指针。
ZGC将信息存储在指针中,这种技术有一个高大上的名字——染色指针(Colored Pointer)。
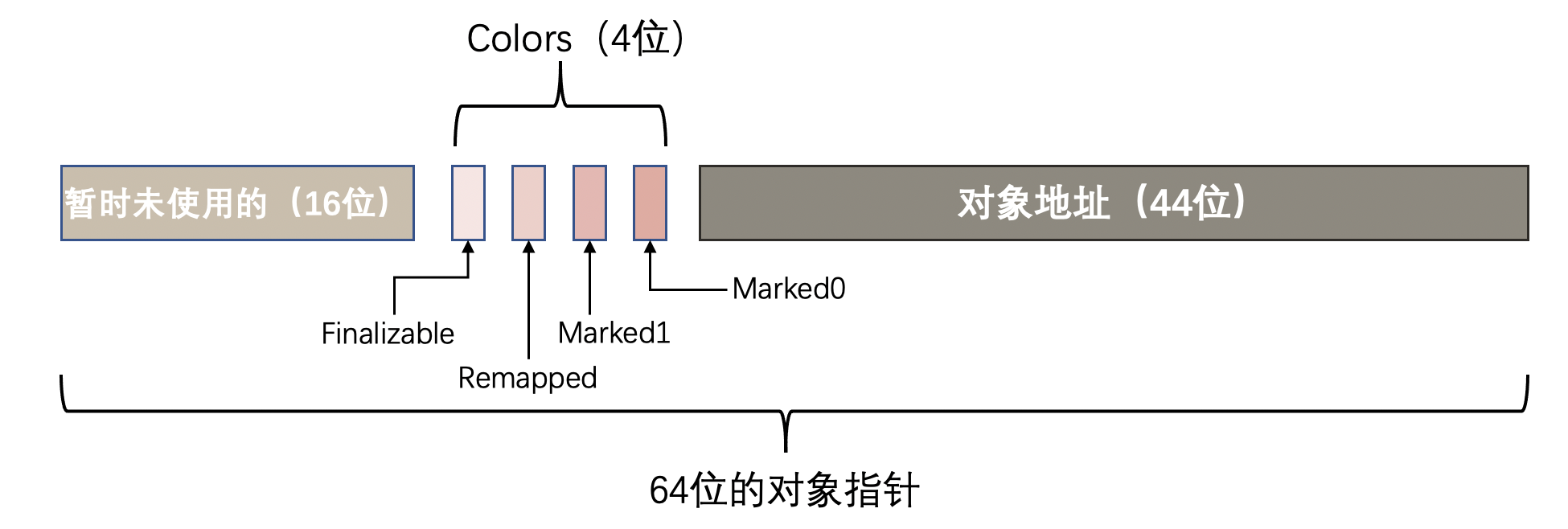
在64位的机器中,对象指针是64位的。
- ZGC使用64位地址空间的第0~43位存储对象地址,2^44 = 16TB,所以ZGC最大支持16TB的堆。
- 而第44~47位作为颜色标志位,Marked0、Marked1和Remapped代表三个视图标志位,Finalizable表示这个对象只能通过finalizer才能访问。
- 第48~63位固定为0没有利用。
读屏障
读屏障是JVM向应用代码插入一小段代码的技术。当应用线程从堆中读取对象引用时,就会执行这段代码。千万不要把这个读屏障和Java内存模型里面的读屏障搞混了,两者根本不是同一个东西,ZGC中的读屏障更像是一种AOP技术,在字节码层面或者编译代码层面给读操作增加一个额外的处理。
读屏障实例:

Object o = obj.FieldA // 从堆中读取对象引用,需要加入读屏障
<load barrier needed here>
Object p = o // 无需加入读屏障,因为不是从堆中读取引用
o.dosomething() // 无需加入读屏障,因为不是从堆中读取引用
int i = obj.FieldB // 无需加入读屏障,因为不是对象引用
ZGC中读屏障的代码作用:
GC线程和应用线程是并发执行的,所以存在应用线程去A对象内部的引用所指向的对象B的时候,这个对象B正在被GC线程移动或者其他操作,加上读屏障之后,应用线程会去探测对象B是否被GC线程操作,然后等待操作完成再读取对象,确保数据的准确性。具体的探测和操作步骤如下:
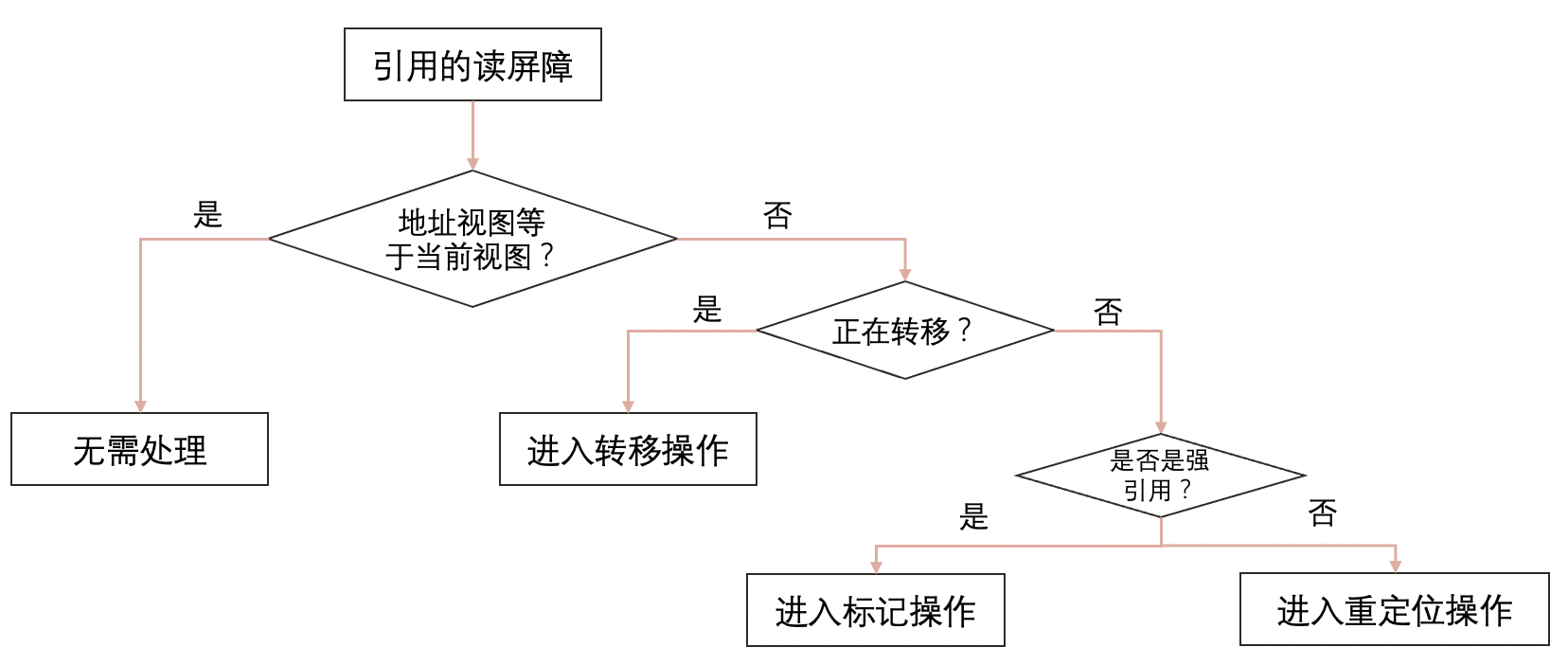
这样会影响程序的性能吗?
会。据测试,最多百分之4的性能损耗。但这是ZGC并发转移的基础,为了降低STW,设计者认为这点牺牲是可接受的。
ZGC并发处理算法
ZGC并发处理算法利用全局空间视图的切换和对象地址视图的切换,结合SATB算法实现了高效的并发。
以上所有的铺垫,都是为了讲清楚ZGC的并发处理算法,在一些博文上,都说染色指针和读屏障是ZGC的核心,但都没有讲清楚两者是如何在算法里面被利用的,我认为,ZGC的并发处理算法才是ZGC的核心,染色指针和读屏障只不过是为算法服务而已。
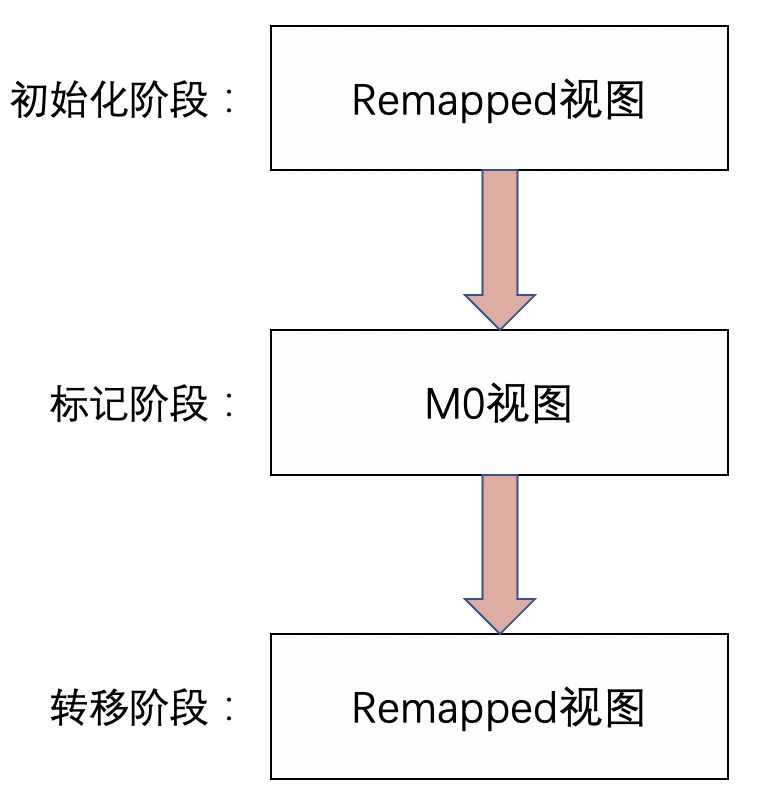
ZGC的并发处理算法三个阶段的全局视图切换如下:
- 初始化阶段:ZGC初始化之后,整个内存空间的地址视图被设置为Remapped
- 标记阶段:当进入标记阶段时的视图转变为Marked0(以下皆简称M0)或者Marked1(以下皆简称M1)
- 转移阶段:从标记阶段结束进入转移阶段时的视图再次设置为Remapped
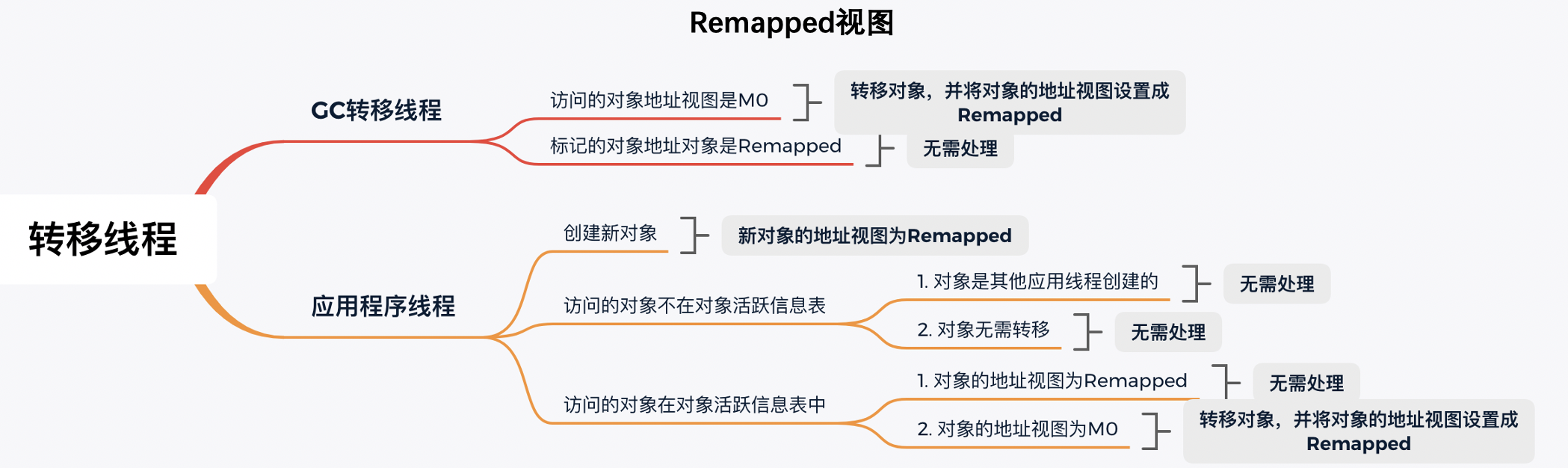
标记阶段
标记阶段全局视图切换到M0视图。因为应用程序和标记线程并发执行,那么对象的访问可能来自标记线程和应用程序线程。
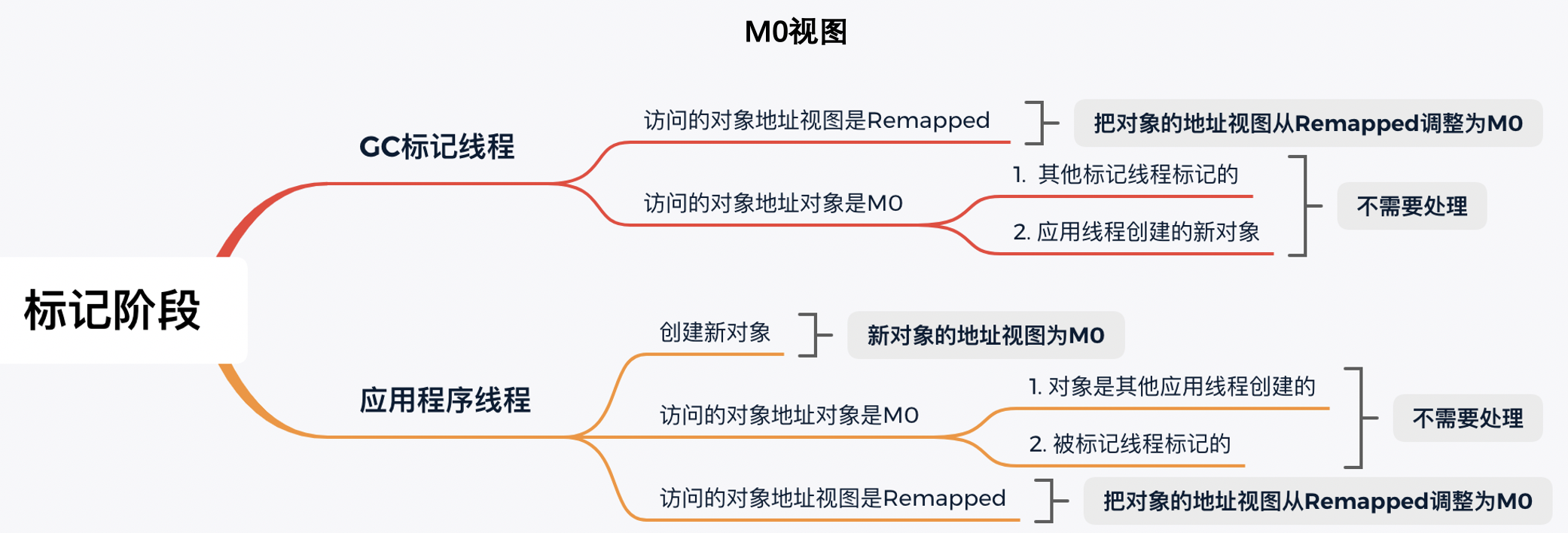
在标记阶段结束之后,对象的地址视图要么是M0,要么是Remapped。
- 如果对象的地址视图是M0,说明对象是活跃的;
- 如果对象的地址视图是Remapped,说明对象是不活跃的,即对象所使用的内存可以被回收。
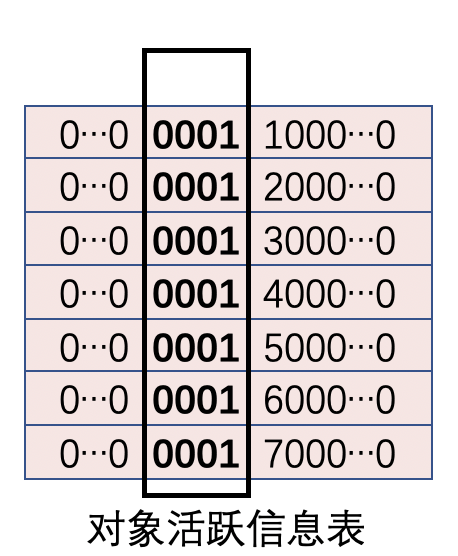
当标记阶段结束后,ZGC会把所有活跃对象的地址存到对象活跃信息表,活跃对象的地址视图都是M0。
转移阶段
转移阶段切换到Remapped视图。因为应用程序和转移线程也是并发执行,那么对象的访问可能来自转移线程和应用程序线程。
至此,ZGC的一个垃圾回收周期中,并发标记和并发转移就结束了。
为何要设计M0和M1
我们提到在标记阶段存在两个地址视图M0和M1,上面的算法过程显示只用到了一个地址视图,为什么设计成两个?简单地说是为了区别前一次标记和当前标记。
ZGC是按照页面进行部分内存垃圾回收的,也就是说当对象所在的页面需要回收时,页面里面的对象需要被转移,如果页面不需要转移,页面里面的对象也就不需要转移。
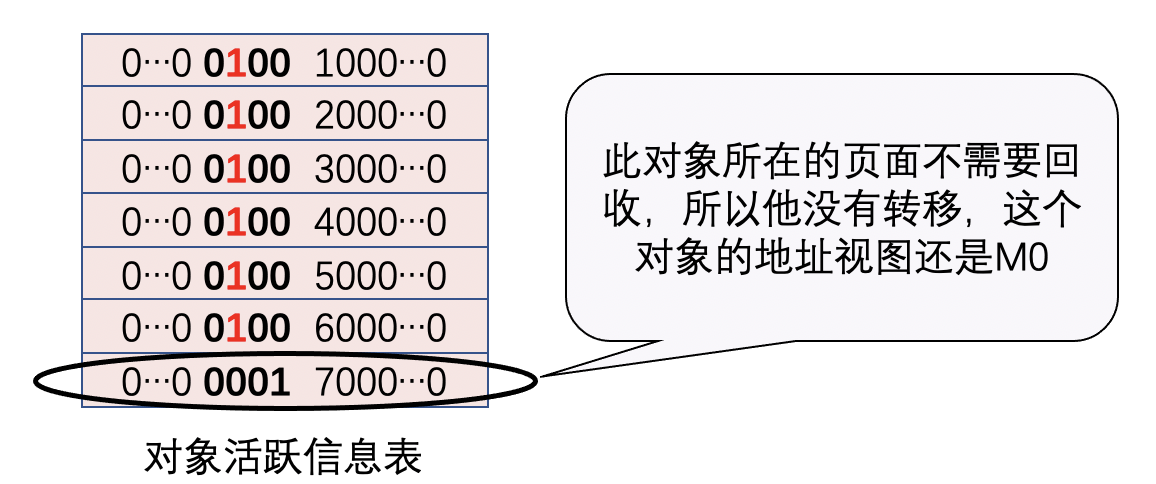
如图,这个对象在第二次GC周期开始的时候,地址视图还是M0。如果第二次GC的标记阶段还切到M0视图的话,就不能区分出对象是活跃的,还是上一次垃圾回收标记过的。这个时候,第二次GC周期的标记阶段切到M1视图的话就可以区分了,此时这3个地址视图代表的含义是:
-
M1:本次垃圾回收中识别的活跃对象。
-
M0:前一次垃圾回收的标记阶段被标记过的活跃对象,对象在转移阶段未被转移,但是在本次垃圾回收中被识别为不活跃对象。
-
Remapped:前一次垃圾回收的转移阶段发生转移的对象或者是被应用程序线程访问的对象,但是在本次垃圾回收中被识别为不活跃对象。
现在,我们可以回答“使用地址视图和染色指针有什么好处”这个问题了
使用地址视图和染色指针可以加快标记和转移的速度。以前的垃圾回收器通过修改对象头的标记位来标记GC信息,这是有内存存取访问的,而ZGC通过地址视图和染色指针技术,无需任何对象访问,只需要设置地址中对应的标志位即可。这就是ZGC在标记和转移阶段速度更快的原因。
当GC信息不再存储在对象头上时而存在引用指针上时,当确定一个对象已经无用的时候,可以立即重用对应的内存空间,这是把GC信息放到对象头所做不到的。
ZGC步骤
ZGC采用的是标记-复制算法,标记、转移和重定位阶段几乎都是并发的,ZGC垃圾回收周期如下图所示:

ZGC只有三个STW阶段:初始标记,再标记,初始转移。
其中,初始标记和初始转移分别都只需要扫描所有GC Roots,其处理时间和GC Roots的数量成正比,一般情况耗时非常短;
再标记阶段STW时间很短,最多1ms,超过1ms则再次进入并发标记阶段。即,ZGC几乎所有暂停都只依赖于GC Roots集合大小,停顿时间不会随着堆的大小或者活跃对象的大小而增加。与ZGC对比,G1的转移阶段完全STW的,且停顿时间随存活对象的大小增加而增加。
ZGC的发展
ZGC诞生于JDK11,经过不断的完善,JDK15中的ZGC已经不再是实验性质的了。
从只支持Linux/x64,到现在支持多平台;从不支持指针压缩,到支持压缩类指针…
在JDK16,ZGC将支持并发线程栈扫描(Concurrent Thread Stack Scanning),根据SPECjbb2015测试结果,实现并发线程栈扫描之后,ZGC的STW时间又能降低一个数量级,停顿时间将进入毫秒时代。

ZGC已然是一款优秀的垃圾收集器了,它借鉴了Pauseless GC,也似乎在朝着C4 GC的方向发展——引入分代思想。
Oracle的努力,让我们开发者看到了商用级别的GC“飞入寻常百姓家”的希望,随着JDK的发展,我相信在未来的某一天,JVM调优这种反人类的操作将不复存在,底层的GC会自适应各种情况自动优化。
ZGC确实是Java的最前沿的技术,但在G1都没有普及的今天,谈论ZGC似乎为时过早。但也许我们探讨的不是ZGC,而是ZGC背后的设计思路。
希望你能有所收获!
写在最后
为了对每一篇发出去的文章负责,力求准确,我一般是参考官方文档和业界权威的书籍,有些时候,还需要看一些论文,看一部分源代码。而官方文档和论文一般都是英文,对于一个英语四级只考了456分的人来说,非常艰难,整个过程都是谷歌翻译和有道词典陪伴着我的。因为一些专业术语翻译的不够准确,还需要英文和翻译对照慢慢理解。
但即使这样,也难免会有纰漏,如果你发现了,欢迎提出,我会对其修正。
你的正反馈对我来说非常重要,点个赞,点个再看,点个关注都是对我最大的支持!
谢谢您的阅读,我们下期再见!



