
深入理解 G1 的 GC 日志原创
本文基于1.8.0_201-b09对G1的GC日志进行分析。
G1 模式下总计有 3 中日志级别,分别被称为:fine,finer,finest。
- fine:fine模式打开方式是-verbose:gc,等价于-XX:+PrintGC。
- finer:推荐,finer模式的打开方式是-XX:+PrintGCDetails。
- finest:finest模式打开方式是-XX:+UnlockExperimentalVMOptions -XX:G1LogLevel=finest。
G1模拟下主要有四种回收方式:
- Young GC:所有Eden区域满了后触发,并行收集,且完全STW。
- 并发标记周期:它的第一个阶段初始化标记和YGC一起发生,这个周期的目的就是找到回收价值最大的Region集合(垃圾很多,存活对象很少),为接下来的Mixed GC服务。
- Mixed GC:回收所有年轻代的Region和部分老年代的Region,Mixed GC可能连续发生多次。
- Full GC:非常慢,对OLTP系统来说简直就是灾难,会STW且回收所有类型的Region。
本文以我们最常用的finer模式来分析G1的GC日志,我们只需要增加JVM参数-XX:+PrintGCDetails就能看到相关GC日志,
YGC
我们首先分析YGC日志,是G1模式下遇到的频率最高的GC,GC日志如下所示:
3.378: [GC pause (G1 Evacuation Pause) (young), 0.0015185 secs]
[Parallel Time: 0.7 ms, GC Workers: 4]
[GC Worker Start (ms): Min: 3378.1, Avg: 3378.3, Max: 3378.6, Diff: 0.5]
[Ext Root Scanning (ms): Min: 0.0, Avg: 0.1, Max: 0.2, Diff: 0.2, Sum: 0.6]
[Update RS (ms): Min: 0.0, Avg: 0.0, Max: 0.0, Diff: 0.0, Sum: 0.0]
[Processed Buffers: Min: 0, Avg: 0.2, Max: 1, Diff: 1, Sum: 1]
[Scan RS (ms): Min: 0.0, Avg: 0.1, Max: 0.1, Diff: 0.1, Sum: 0.3]
[Code Root Scanning (ms): Min: 0.0, Avg: 0.0, Max: 0.0, Diff: 0.0, Sum: 0.0]
[Object Copy (ms): Min: 0.0, Avg: 0.0, Max: 0.0, Diff: 0.0, Sum: 0.1]
[Termination (ms): Min: 0.0, Avg: 0.2, Max: 0.3, Diff: 0.3, Sum: 0.7]
[Termination Attempts: Min: 1, Avg: 1.0, Max: 1, Diff: 0, Sum: 4]
[GC Worker Other (ms): Min: 0.0, Avg: 0.0, Max: 0.0, Diff: 0.0, Sum: 0.1]
[GC Worker Total (ms): Min: 0.1, Avg: 0.4, Max: 0.6, Diff: 0.6, Sum: 1.8]
[GC Worker End (ms): Min: 3378.7, Avg: 3378.7, Max: 3378.8, Diff: 0.1]
[Code Root Fixup: 0.0 ms]
[Code Root Purge: 0.0 ms]
[Clear CT: 0.1 ms]
[Other: 0.7 ms]
[Choose CSet: 0.0 ms]
[Ref Proc: 0.5 ms]
[Ref Enq: 0.0 ms]
[Redirty Cards: 0.1 ms]
[Humongous Register: 0.0 ms]
[Humongous Reclaim: 0.1 ms]
[Free CSet: 0.1 ms]
[Eden: 304.0M(304.0M)->0.0B(304.0M) Survivors: 2048.0K->2048.0K Heap: 304.5M(512.0M)->529.0K(512.0M)]
[Times: user=0.01 sys=0.00, real=0.00 secs]
这段日志是典型的Evacuation阶段日志(GC pause (G1 Evacuation Pause) (young))。Evacution这个词在G1中出现的频率非常高,中文意思是疏散,在G1中可以理解为拷贝&清理,就是把存活的对象拷贝到1个或者多个Region中,目标Region可能只是Young区,也可能是Young区+Old区,取决于这次YGC是否有符合晋升到Old区的对象。
另外,我们可以看到这段GC日志有层级关系,笔者现在将其抽取成如下样式:
GC pause (G1 Evacuation Pause) (young)
├── Parallel Time
├── GC Worker Start
├── Ext Root Scanning
├── Update RS
├── Scan RS
├── Code Root Scanning
├── Object Copy
├── Code Root Fixup
├── Code Root Purge
├── Clear CT
├── Other
├── Choose CSet
├── Ref Proc
├── Ref Enq
├── Redirty Cards
├── Humongous Register
├── Humongous Reclaim
├── Free CSet
由这段GC日志我们可知,整个YGC由多个子任务以及嵌套子任务组成,且一些核心任务为:Root Scanning,Update/Scan RS,Object Copy,CleanCT,Choose CSet,Ref Proc,Humongous Reclaim,Free CSet。
YGC第一行日志如下所示,这行日志告诉我们,这次YGC是在JVM启动后3.378秒的时候发生的,并且整个过程耗时0.0015185秒:
3.378: [GC pause (G1 Evacuation Pause) (young), 0.0015185 secs]
接下来,深入解读YGC所有的子任务,即YGC都经历过的阶段。
- Parallel Time
GC日志如下所示,这段日志告诉我们,本次YGC总计由4个GC线程并行收集,并总计消耗时间0.7毫秒:
[Parallel Time: 0.7 ms, GC Workers: 4]
接下来就是下面这段日志,这段日志告诉我们几个GC线程开始的最小时间、平均时间和最大时间(这个时间是相对于JVM启动后到现在的毫秒数),最后的Diff:0.5表示几个GC线程最大启动时间差有0.5毫秒:
[GC Worker Start (ms): Min: 3378.1, Avg: 3378.3, Max: 3378.6, Diff: 0.5]
再然后就是下面这段GC日志,这段日志表示几个GC线程ROOT扫描阶段消耗的时间统计信息,从这行日志可知,ROOT扫描平均耗时0.1毫秒:
[Ext Root Scanning (ms): Min: 0.0, Avg: 0.1, Max: 0.2, Diff: 0.2, Sum: 0.6]
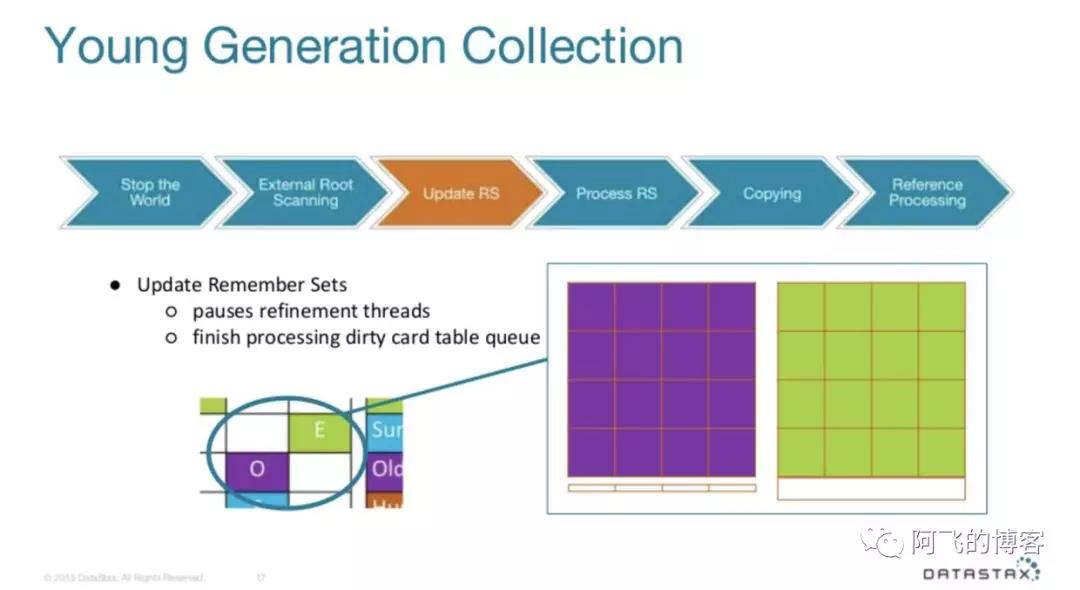
接下来就是下面这段GC日志,即更新RSet消耗的时间统计信息,RSet即Remember Sets,它是用来记录引用指向一个Region的跟踪信息的数据结构。我们看到后面还有一段Processed Buffers的日志,Mutator线程会记录对象图的变化,JVM将这些变化的track信息记录在被称为Update Buffers中。这个Update RS的子任务Processed Buffers就是负责处理这个Update Buffers的,从而将所有Region的RSets更新到一致的状态:
[Update RS (ms): Min: 0.0, Avg: 0.0, Max: 0.0, Diff: 0.0, Sum: 0.0]
[Processed Buffers: Min: 0, Avg: 0.2, Max: 1, Diff: 1, Sum: 1]
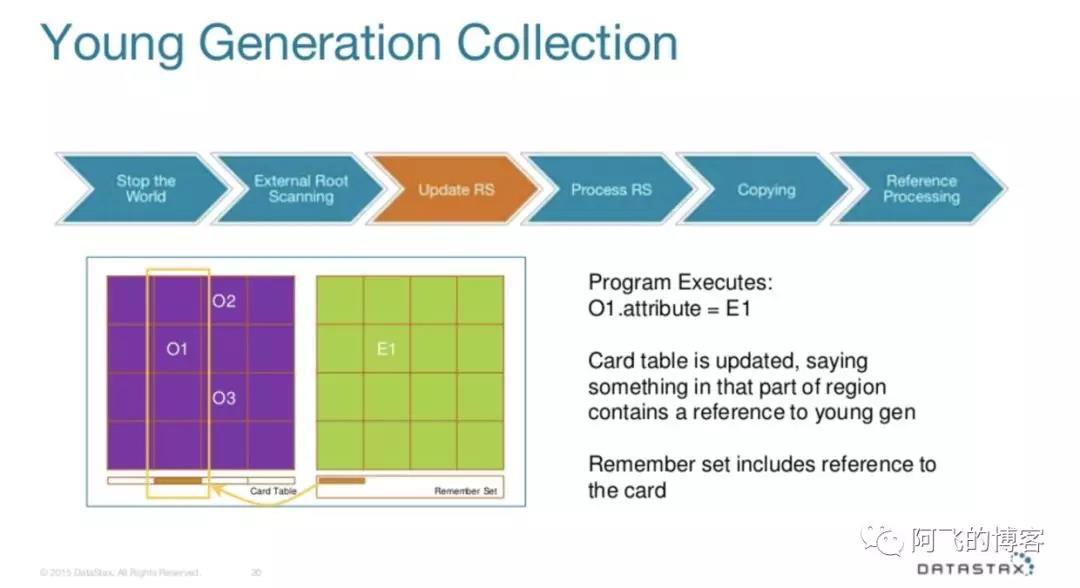
如下图所示,我们假设O1,即紫色块就是某一个Old类型的Region,而绿色块就是某一个Eden类型的Region:
如果程序中执行了O1.attr=E1,即O1有对E1的引用,那么Card Table就会记录下来。而Remember Sets包含了对Card Table中这个Card的引用:
接下来就是Scan RS阶段,这个阶段会扫描遍历Remember Sets。由上图可知,一个Region的RSet包含了指向这个Region的引用的Cards,这个阶段就是扫描RSet中这些Cards,从而找出任何有指向CSet中所有Region的引用。通过这一步就能知道,Eden区哪些对象被老年代引用,从而不会在GC时回收掉:
[Scan RS (ms): Min: 0.0, Avg: 0.1, Max: 0.1, Diff: 0.1, Sum: 0.3]
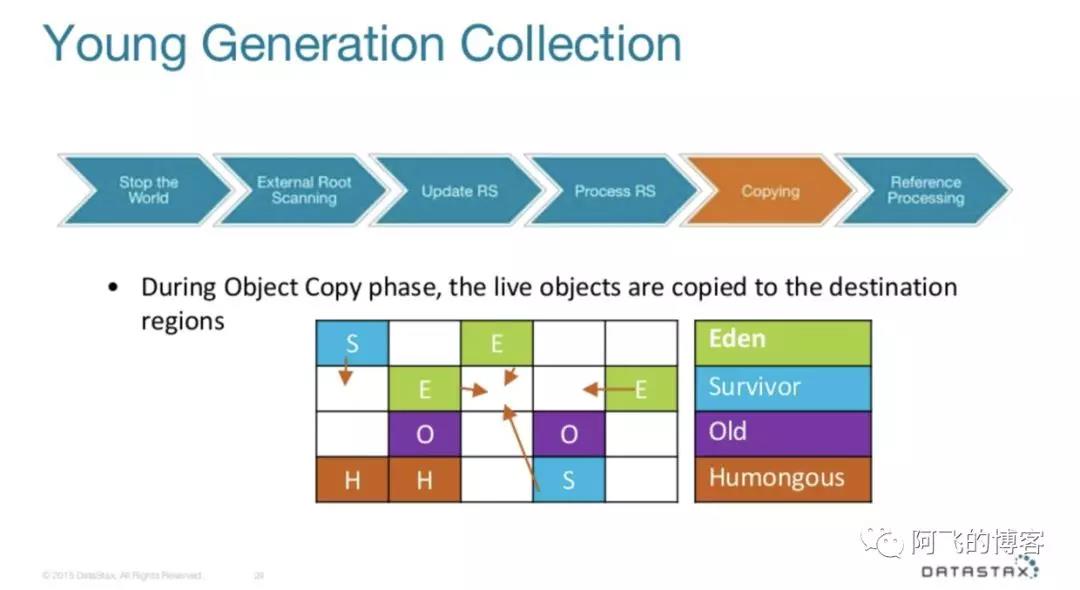
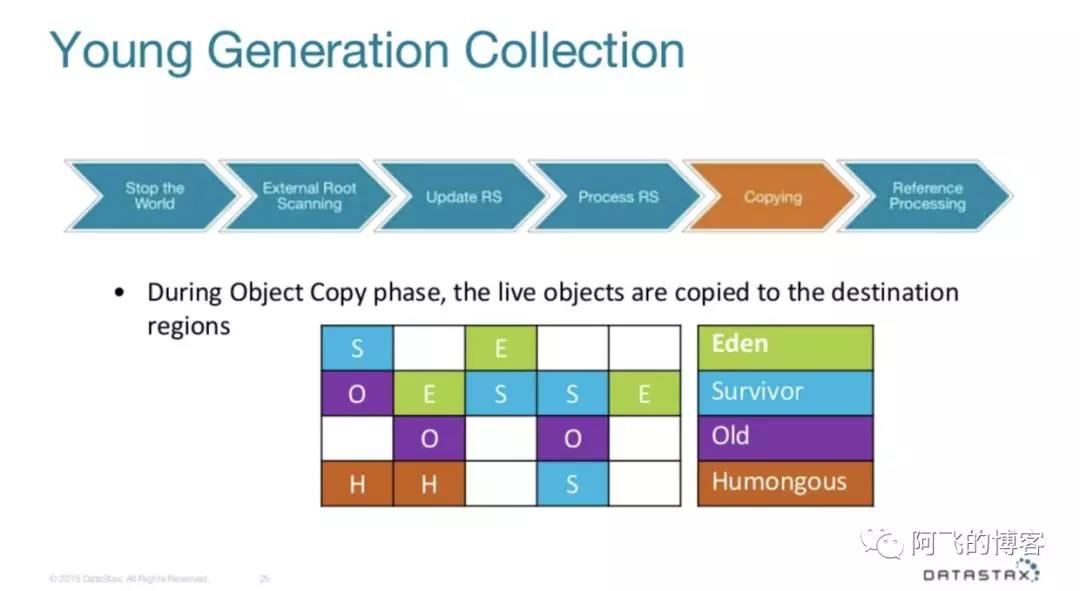
再然后就是对象拷贝阶段。这个阶段会将前面扫描到的存活的对象拷贝到目标Region中,可能是Survivor类型Region,也可能是Old类型Region(如果达到晋升条件的话),并记录拷贝过程消耗的时间统计信息:
[Object Copy (ms): Min: 0.0, Avg: 0.0, Max: 0.0, Diff: 0.0, Sum: 0.1]
如下图所示,就是对象拷贝前后对比图:
接下来就是Parallel阶段最后几个子任务,GC Worker Total表示GC线程整个生命周期总计消耗的时间,而GC Worker End表示GC线程完成任务停止的时间(这个时间是相对于JVM进程启动后的毫秒数):
[GC Worker Other (ms): Min: 0.0, Avg: 0.0, Max: 0.0, Diff: 0.0, Sum: 0.1]
[GC Worker Total (ms): Min: 0.1, Avg: 0.4, Max: 0.6, Diff: 0.6, Sum: 1.8]
[GC Worker End (ms): Min: 3378.7, Avg: 3378.7, Max: 3378.8, Diff: 0.1]
- Clear CT
CT就是Card Table,即清理Card Table消耗的时间。这个阶段对应的GC日志如下所示:
[Clear CT: 0.1 ms]
- Other
最后一个阶段Other,这个阶段也包含了比较多的子任务,接下来一个一个进行剖析。
第一个就是Choose Cset,很好理解,就是选择哪些Region作为CSet一部分需要的时间,G1会根据用户设置的停顿时间来决定Region的数量:
[Choose CSet: 0.0 ms]
再然后就是Ref Proc,即处理引用对象消耗的时间,可能是Weak、Soft、Phantom引用,强烈建议配置参数:-XX:+ParallelRefProcEnabled(这个参数默认是关闭的),即让这个阶段并行处理:
[Ref Proc: 0.5 ms]
下一步就是超大(humongous)对象的处理,YGC阶段如果发现某些H区域的对象都不是存活对象,就会回收掉这些对象占用的空间:
[Humongous Register: 0.0 ms]
[Humongous Reclaim: 0.1 ms]
Other阶段最后一个子任务就是Free CSet,即释放掉CSet中Region占用的内存空间所消耗的时间(前面的Object Copy已经将CSet中存活的对象拷贝到了目标Region中,所以这里需要回收Region占用的内存空间):
[Free CSet: 0.1 ms]
- Eden
这一行GC日志非常容易理解,和以前的ParNew+CMS或者默认的PS垃圾回收几乎一样的,Eden: 304.0M(304.0M)->0.0B(304.0M)表示整个Eden区从占用304.0M到回收后的0.0B,并且GC前后 整个Eden区大小没有变化,还是304.0M,最后的Heap: 304.5M(512.0M)->529.0K(512.0M)表示整个堆回收前占用304.5M,回收后占用529.0K,并且整个堆大小是512.0M:
[Eden: 304.0M(304.0M)->0.0B(304.0M) Survivors: 2048.0K->2048.0K Heap: 304.5M(512.0M)->529.0K(512.0M)]
并发标记周期
上面提分析的日志全部是YGC阶段的日志,G1模式下还有一个重要的周期,即全局并发标记周期,其GC日志如下所示:
# 这一行日志是全局并发标记的第一个阶段,即初始化标记,是伴随YGC一起发生的,后面的857M->617M表示YGC发生前后堆内存变化,0.0112237表示YGC的耗时
[GC pause (G1 Evacuation Pause) (young) (initial-mark) 857M->617M(1024M), 0.0112237 secs]
# 开始并发ROOT区域扫描
[GC concurrent-root-region-scan-start]
# 结束并发ROOT区域扫描,并统计这个阶段的耗时
[GC concurrent-root-region-scan-end, 0.0000525 secs]
[GC concurrent-mark-start]
[GC concurrent-mark-end, 0.0083864 secs]
# 最终标记阶段完成并发标记阶段后遗留的工作,即SATB buffer处理,并统计这个阶段耗时
[GC remark, 0.0038066 secs]
# 清理阶段会根据所有Region标记信息,计算出每个Region存活对象信息,并且把Region根据GC回收效率排序
[GC cleanup 680M->680M(1024M), 0.0006165 secs]
Mixed GC
Evacuation Pause除了是YGC触发之外,还可能是Mixed GC([GC pause (G1 Evacuation Pause) (mixed)),日志如下所示,Mixed GC的整个子任务和YGC完全一样,只是回收的范围(CSet)不一样而已,YGC只回收Young区,而Mixed GC回收Young区+部分Old区:
29.268: [GC pause (G1 Evacuation Pause) (mixed), 0.0059011 secs]
[Parallel Time: 5.6 ms, GC Workers: 4]
... ...
[Code Root Fixup: 0.0 ms]
[Code Root Purge: 0.0 ms]
[Clear CT: 0.1 ms]
[Other: 0.3 ms]
... ...
[Eden: 14.0M(14.0M)->0.0B(156.0M) Survivors: 10.0M->4096.0K Heap: 165.9M(512.0M)->148.7M(512.0M)]
[Times: user=0.02 sys=0.01, real=0.00 secs]
Full GC
最后一种垃圾收集方式即FullGC,事实上,在G1的正常工作流程中没有Full GC的概念,只有在G1搞不定的情况下(或者主动触发),才会发生的GC方式。日志如下,也非常容易理解,由第一行日志可知,这次的FullGC是由System.gc()触发的:
4.358: [Full GC (System.gc()) 298M->509K(512M), 0.0101774 secs]
[Eden: 122.0M(154.0M)->0.0B(230.0M) Survivors: 4096.0K->0.0B Heap: 298.8M(512.0M)->509.4K(512.0M)], [Metaspace: 3308K->3308K(1056768K)]
[Times: user=0.01 sys=0.00, real=0.01 secs]
下面这段日志是G1搞不定的情况下发触发的FullGC,从第二行日志可以看出,Mixed GC前后,堆大小都是99G,说明没有任何回收效果,而堆由已经满了,所以触发了Full GC:
805.815: [GC pause (G1 Evacuation Pause) (young) 96G->74G(100G), 2.4778659 secs] 813.964: [GC pause (G1 Evacuation Pause) (mixed)-- 97G->99G(100G), 23.7970094 secs]
837.762: [GC pause (G1 Evacuation Pause) (mixed)-- 99G->99G(100G), 32.0781615 secs]
869.842: [Full GC (Allocation Failure) 99G->62G(100G), 169.3897706 secs]



