
译:谁是 JDK8 中最快的 GC原创
我们都知道 OpenJDK8 有好几个垃圾回收算法,比如 ParallelGC,CMS,还有 G1,那么哪个才是最快的?如果 GC 算法从 Java8 中默认的 ParallelGC 切换到 G1 会发生什么(JDK9 就是把默认 GC 从 ParallelGC 切到了 G1)?废话不多说,做一个基准测试就知道了,Let’s benchmark it.
基准测试方法
-
分别用不同的 JVM 参数运行 6 次同样的代码。这些VM参数为:-XX:+UseSerialGC, -XX:+UseParallelGC, -XX:+UseConcMarkSweepGC, -XX:ParallelCMSThreads=2, -XX:ParallelCMSThreads=4, -XX:+UseG1GC。
-
每次运行大概花 55 分钟。
-
除了指定 GC 的 JVM 参数,其他的 JVM 参数为:
- -Xmx2048M -server
- OpenJDK version: 1.8.0_51
- Software: Linux version 4.0.4-301.fc22.x86_64
- Hardware: Intel® Core™ i7-4790 CPU @ 3.60GHz
-
每次通过 optaplanner 解决 13 个问题,每个问题大概 5 分钟,并且前 30 秒的 JVM 预热时间不计算在内。
-
解决问题时不会发生IO,运行过程中,单个CPU完全饱和,并且会一直创建很多生命周期很短的对象,然后GC负责收集它们。
-
基准测试测量每毫秒能被计算的分数,越高表示越好。需要说明的是,计算一个分数可不是一件容易的事情,它涉及很多计算,有兴趣的话,可以去 optaplanner 查看它们的源码。
如果想要在你的本地复制演示这个基准测试,只需要基于源码构建 optaplanner,然后运行 main 类GeneralOptaPlannerBenchmarkApp即可。
OptaPlanner: https://www.optaplanner.org。
基准测试结果
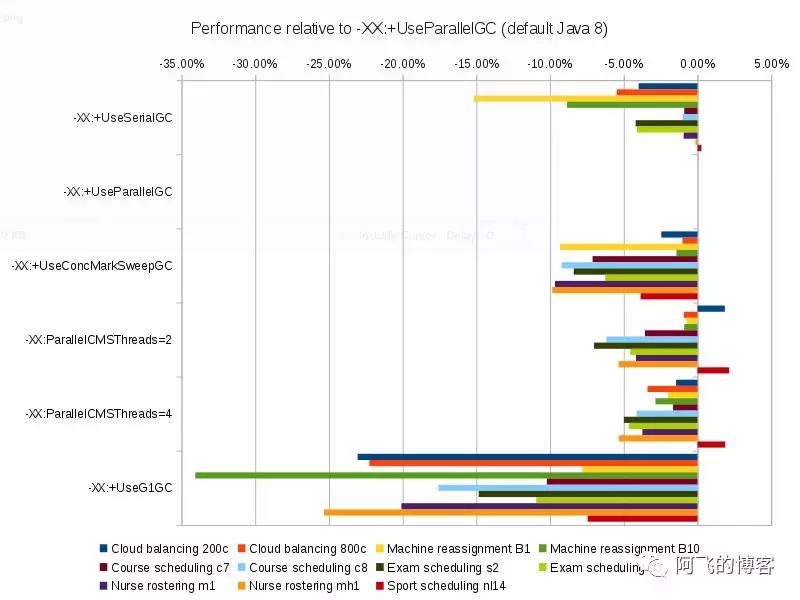
每个垃圾回收器和 Java8 默认的 ParallelGC 的对比如下图所示:
结果非常清晰,JDK8 默认的 ParallelGC 是最快的,其他垃圾回收器相比默认的 ParallelGC 都会有不同程度的衰减,并且 G1 表现最差,是最慢的。
Java9 应该将 G1 设置为默认吗?
JDK 有一个提案建议将 G1 作为服务端默认的垃圾收集器,详情请戳链接:JEP 248: Make G1 the Default Garbage Collector: http://openjdk.java.net/jeps/248 ,我的第一反应是拒绝这个提案,并且上面的压测结果给了我充足的理由:
- G1 相比平均水平慢了 17.60%.
- 对于每一种数据集来说,G1在每个用例上一直是更慢的。
- 在最大的数据集 (Machine Reassignment B10)中,G1慢了34.07%。
其他方面,也有一些需要注意的地方:
- G1重点是限制GC停顿时间,而不是吞吐量。对于那些侧重于计算的用例,GC停顿时间长短都不是很重要。
- 本次基准测试几乎是单线程的,将来,并行或者多线程求解的基准测试.可能会影响结果。
- G1 更推荐在至少 6G 的堆上使用,而基准测试只使用 2G 的堆。
- 侧重计算只是 OpenJDK 众多使用场景之一,一些其他的场景如 Web 服务,也许就会值得更改默认 GC。
Java9 更改默认 GC
自 G1 完全支持以来,它一直被吹捧为 CMS 的替代者。但是,社区关心的这个JEP248 却是要用 G1 取代 ParallelGC,而不是 CMS。人们普遍认为,由于业务从 CMS 迁移到 G1,因此有数据对比 CMS 和 G1,但是却没有足够的数据对比 ParallelGC(现在默认的 GC)和 G1(准备默认的 GC)。同时,数据表明,许多业务还在使用默认的 GC,即 ParallelGC。因此,当 G1 变成默认的 GC 后,肯定能观察到一些 GC 行为的变化。
Java9 将 G1 设置为默认 GC 的最主要动机是 G1 能减少 FullGC 的次数,这是 G1 相比 JDK8 默认的 ParallelGC 一个很大的改进。G1 的目标是在不受到堆大小或存活对象数量限制的情况下最小化暂停时间。这是通过并发进行大部分 GC 工作,只对部分堆的压缩来实现的,这个 GC 过程被称为 mixed gc。尽可能避免做 FullGC 是 G1 的主要优点之一。
通常来说,限制 GC 停顿时间比追求大吞吐量更重要。对许多用户来说,切换到 G1 这种低延迟的垃圾收集器相比 JDK8 以前默认的吞吐量优先的垃圾收集器 ParallelGC,应该能提供更好的整体体验。
为什么是 G1
G1 GC 被当做是 CMS 的长期替代品,现在的 CMS 有一个很大的问题,将导致并发模式失败,最终导致收集并压缩整个堆(FullGC)。当然,你也可以调优 CMS,延迟这种单线程压缩整个堆的 FullGC,但是,随着使用 CMS 的 JVM 运行的时间越来越长,最终一定不能避免(发生 FullGC),注意措词,是一定。
将来,这种 FullGC 会被优化成多线程并行(JDK10),但是,还是不能避免FullGC(只不过,现在是单线程 FullGC,以后是多线程 FullGC)感兴趣的话,请戳链接 JEP 307: Parallel Full GC for G1: https://openjdk.java.net/jeps/307。
另外一个重要的点是,即使是经验丰富的 GC 工程师,维护好 CMS 也被证明是非常具有挑战性和不确定性的。
还有,CMS,ParallelGC 以及 G1 都是基于不同的 GC 框架来实现的,如此以来,导致维护代价非常大。而 G1 是基于 Region 设计的堆框架,这是未来发展的方向。IBM 的 Balanced GC,Azul 的C4,以及 OpenJDK 的 Shenandoah GC,都是同类的基于 Region 设计实现。
放弃 ParallelGC
ParallelGC 不能做递增式的收集。因此,它为了吞吐量就会牺牲延迟性。随着负载加大,以及更大的堆,GC 的停顿时间也会增加。这样的话,可能会影响与延迟相关的系统级协议(SLA)。
G1 能帮助你满足 SLA,而且 G1 的 Mixed GC 停顿时间远比 ParallelGC 的 FullGC 要短的多(当然,G1 也有 FullGC,但是其发生的次数可比 ParallelGC 的 FullGC 次数少很多)。
放弃 CMS
当前情况下,CMS 由于碎片化问题和并发模式失败问题而很可能无法满足 SLA,而调优后的 G1 却能够满足 SLA。G1 的mixed gc 最糟糕情况的停顿时间,也要比 CMS 遭遇的最糟糕的整个堆压缩停堆时间要更好。还有前面提到的,CMS 堆的碎片化问题,导致单线程的 FullGC 只能推迟,不可能完全阻止。
因此,CMS 已经被放弃,并且在 JDK9 中被标记为 deprecated,未来的版本会被移除,参考 JEP 291: Deprecate the Concurrent Mark Sweep (CMS) Garbage Collector,相关连接:http://openjdk.java.net/jeps/291
另外,像谷歌这样的公司,基于 OpenJDK 源码构建和运行它们自己私有的 JDK,其特定的源码根据它们的需求而有所改变。例如,谷歌工程师提到:为了减少碎片化,他们为他们的 CMS 的重新标记阶段,增加了一种增量压缩,使它们的 CMS 更可靠。
(参考链接: http://mail.openjdk.java.net/pipermail/hotspot-dev/2015-July/019534.html).
注意:增量压缩也有自己的成本,谷歌可能在权衡其特定使用场景的好处后,才会增加增量压缩。
结论
没有最好的垃圾回收器,只有更适合业务的垃圾回收器。如果对 GC 的停顿时间很敏感,那么请使用 G1,比如 WEB 服务器;如果对吞吐量有很大的要求,建议使用 ParallelGC,比如 OptaPlanner 这种测试用例。



