
并发垃圾收集器(CMS)为什么没有采用标记-整理算法来实现?原创
并发垃圾收集器(CMS)为什么没有采用标记整理-算法来实现,而是采用的标记-清除算法?
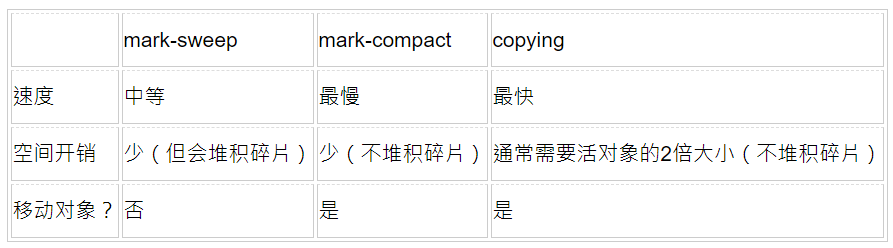
分代式GC里,年老代常用mark-sweep;或者是mark-sweep/mark-compact的混合方式,一般情况下用mark-sweep,统计估算碎片量达到一定程度时用mark-compact。这是因为传统上大家认为年老代的对象可能会长时间存活且存活率高,或者是比较大,这样拷贝起来不划算,还不如采用就地收集的方式。Mark-sweep、mark-compact、copying这三种基本算法里,只有mark-sweep是不移动对象(也就是不用拷贝)的,所以选用mark-sweep。
简要对比三种基本算法:
关于时间开销:
mark-sweep:mark阶段与活对象的数量成正比,sweep阶段与整堆大小成正比
mark-compact:mark阶段与活对象的数量成正比,compact阶段与活对象的大小成正比
copying:与活对象大小成正比
如果把mark、sweep、compact、copying这几种动作的耗时放在一起看,大致有这样的关系:
compaction >= copying > marking > sweeping
还有 marking + sweeping > copying
(虽然compactiont与copying都涉及移动对象,但取决于具体算法,compact可能要先计算一次对象的目标地址,然后修正指针,然后再移动对象;copying则可以把这几件事情合为一体来做,所以可以快一些。
另外还需要留意GC带来的开销不能只看collector的耗时,还得看allocator一侧的。如果能保证内存没碎片,分配就可以用pointer bumping方式,只有挪一个指针就完成了分配,非常快;而如果内存有碎片就得用freelist之类的方式管理,分配速度通常会慢一些。)
=====================================
在分代式假设中,年轻代中的对象在minor GC时的存活率应该很低,这样用copying算法就是最合算的,因为其时间开销与活对象的大小成正比,如果没多少活对象,它就非常快;而且young gen本身应该比较小,就算需要2倍空间也只会浪费不太多的空间。
而年老代被GC时对象存活率可能会很高,而且假定可用剩余空间不太多,这样copying算法就不太合适,于是更可能选用另两种算法,特别是不用移动对象的mark-sweep算法。
不过HotSpot VM中除了CMS之外的其它收集器都是会移动对象的,也就是要么是copying、要么是mark-compact的变种。
=====================================
HotSpot VM的serial GC(UseSerialGC)、parallel GC(UseParallelGC)中,只有full GC会收集年老代(实际上收集整个GC堆,包括年老代在内)。它用的算法是mark-compact("Mark-Compact Old Object Collector"那一节),具体来说是典型的单线程(串行)的LISP 2算法。虽然在HotSpot VM的源码里,这个full GC的实现类叫做MarkSweep,而许多资料上都把它称为mark-sweep-compact,但实际上它是典型的mark-compact而不是mark-sweep,请留意不要弄混了。出现这种情况是历史原因,十几二十年前GC的术语还没固定到几个公认的用法时mark-sweep-compact和mark-compact说的是一回事。
我不太清楚当初HotSpot VM为何选择先以mark-compact算法来实现full GC,而不像后来微软的CLR那样先选择使用mark-sweep为基本算法来实现Gen 2 GC。但其背后的真相未必很复杂:
HotSpot VM的前身是Strongtalk VM,它的full GC也是mark-compact算法的,虽说具体算法跟HotSpot VM的不同,是一种threaded compaction算法。这种算法比较省空间,但限制也挺多,实现起来比较绕弯,所以后来出现的HotSpot才改用了更简单直观的LISP 2算法吧,而这个决定又进一步在V8上得到体现。
而Strongtalk VM的前身是Self VM,同样使用mark-compact算法来实现full GC。可以看到mark-compact是这一系列VM一脉相承的,一直延续到更加新的Google V8也是如此。或许当初规划HotSpot VM时也没想那么多就先继承下了其前身的特点。
如果硬要猜为什么,那一个合理的推断是:如果不能整理碎片,长时间运行的程序终究会遭遇内存碎片化,导致内存空间的浪费和内存分配速度下降的问题;要解决这个问题就得要能整理内存。如果决定要根治碎片化问题,那么可以直接选用mark-compact,或者是主要用mark-sweep外加用mark-compact来备份。显然直接选用mark-compact实现起来更简单些。所以就选它了。
(而CLR就选择了不根治碎片化问题。所有可能出问题的地方都最终会出问题,于是现在就有很多.NET程序受碎片化的困扰)
后来HotSpot VM有了parallel old GC(UseParallelOldGC),这个用的是多线程并行版的mark-compact算法。这个算法具体应该叫什么名字我说不上来,因为并没有专门的论文去描述它,而大家有许多不同的办法去并行化LISP 2之类的经典mark-compact算法,各自取舍的细节都不同。无论如何,这里要关注的只是它用的也是mark-compact而不是mark-sweep算法。
=====================================
那CMS为啥选用mark-sweep为基本算法将其并发化,而不跟HotSpot VM的其它GC一样用会移动对象的算法呢?
一个不算原因的原因是:当时设计和实现CMS是在Sun的另外一款JVM,Exact VM(EVM)上做的。后来EVM项目跟HotSpot VM竞争落败,CMS才从EVM移植到HotSpot VM来。因此它没有HotSpot VM的初始血缘。 <- 真的算不上原因(逃
真正的原因请参考CMS的原始论文:A Generational Mostly-concurrent Garbage Collector(可恶,Oracle Labs的链接挂了。用CiteSeerX的链接吧)
把GC之外的代码(主要是应用程序的逻辑)叫做mutator,把GC的代码叫做collector。两者之间需要保持同步,这样才可以保证两者所观察到的对象图是一致的。
如果有一个串行、不并发、不分代、不增量式的collector,那么它在工作的时候总是能观察到整个对象图。因而它跟mutator之间的同步方式非常简单:mutator一侧不用做任何特殊的事情,只要在需要GC时同步调用collector即可,就跟普通函数调用一样。
如果有一个分代式的,或者增量式的collector,那它在工作的时候就只会观察到整个对象图的一部分;它观察不到的部分就有可能与mutator产生不一致,于是需要mutator配合:它与mutator之间需要额外的同步。Mutator在改变对象图中的引用关系时必须执行一些额外代码,让collector记录下这些变化。有两种做法,一种是write barrier,一种是read barrier。
Write barrier就是当改写一个引用时:
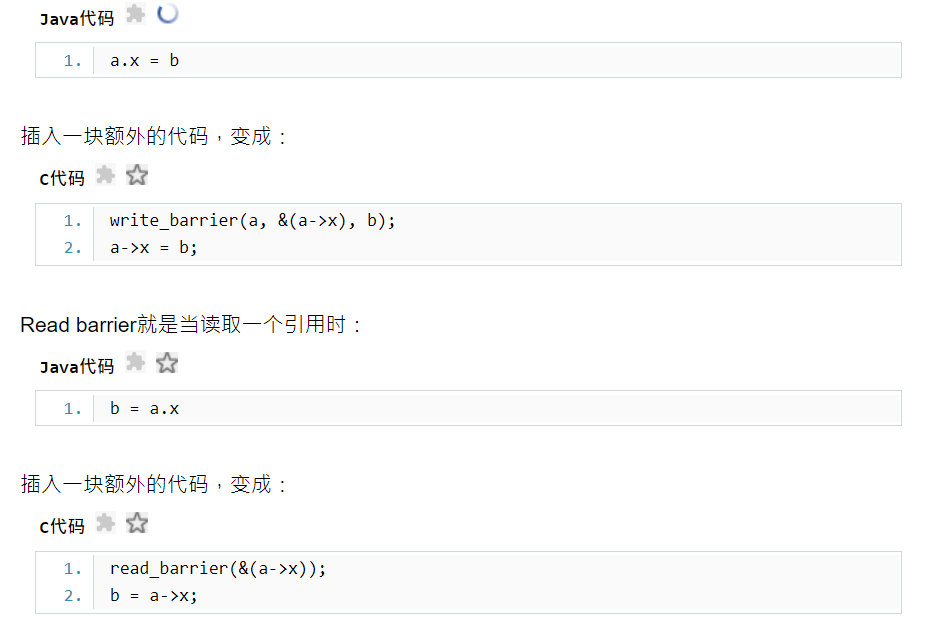
通常一个程序里对引用的读远比对引用的写要更频繁,所以通常认为read barrier的开销远大于write barrier,所以很少有GC使用read barrier。
如果只用write barrier,那么“移动对象”这个动作就必须要完全暂停mutator,让collector把对象都移动好,然后把指针都修正好,接下来才可以恢复mutator的执行。也就是说collector“移动对象”这个动作无法与mutator并发进行。
如果用到了read barrier(虽少见但不是不存在,例如Azul C4 Collector),那移动对象就可以单个单个的进行,而且不需要立即修正所有的指针,所以可以看作整个过程collector都与mutator是并发的。
CMS没有使用read barrier,只用了write barrier。这样,如果它要选用mark-compact为基本算法的话,就只有mark阶段可以并发执行(其中root scanning阶段仍然需要暂停mutator,这是initial marking;后面的concurrent marking才可以跟mutator并发执行),然后整个compact阶段都要暂停mutator。回想最初提到的:compact阶段的时间开销与活对象的大小成正比,这对年老代来说就不划算了。
于是选用mark-sweep为基本算法就是很合理的选择:mark与sweep阶段都可以与mutator并发执行。Sweep阶段由于不移动对象所以不用修正指针,所以不用暂停mutator。
(题外话:但现实中我们仍然可以看到以mark-compact为基础算法的增量式/并发式年老代GC。例如Google V8里的年老代GC就可以把marking阶段拆分为非并发的initial marking和增量式的incremental marking;但真正比较耗时的compact阶段仍然需要完全暂停mutator。它要降低暂停时间就只能想办法在年老代内进一步选择其中一部分来做compaction,而不是整个年老代一口气做compaction。这在V8里也已经有实现,叫做incremental compaction。再继续朝这方向发展的话最终会变成region-based collector,那就跟G1类似了。)
那碎片堆积起来了怎么办呢?
HotSpot VM里CMS只负责并发收集年老代(而不是整个GC堆)。如果并发收集所回收到的空间赶不上分配的需求,就会回退到使用serial GC的mark-compact算法做full GC。也就是mark-sweep为主,mark-compact为备份的经典配置。但这种配置方式也埋下了隐患:使用CMS时必须非常小心的调优,尽量推迟由碎片化引致的full GC的发生。一旦发生full GC,暂停时间可能又会很长,这样原本为低延迟而选择CMS的优势就没了。
所以新的Garbage-First(G1)GC就回到了以copying为基础的算法上,把整个GC堆划分为许多小区域(region),通过每次GC只选择收集很少量region来控制移动对象带来的暂停时间。这样既能实现低延迟也不会受碎片化的影响。
(注意:G1虽然有concurrent global marking,但那是可选的,真正带来暂停时间的工作仍然是基于copying算法而不是mark-compact的)


