
全网最硬核 JVM TLAB 分析(上)原创
1. 观前提醒
本期内容比较硬核,非常全面,涉及到了设计思想到实现原理以及源码,并且还给出了相应的日志以及监控方式,如果有不清楚或者有疑问的地方,欢迎留言。
其中涉及到的设计思想主要为个人理解,实现原理以及源码解析也是个人整理,如果有不准确的地方,非常欢迎指正!提前感谢~~
2. 分配内存实现思路
我们经常会 new 一个对象,这个对象是需要占用空间的,第一次 new 一个对象占用的空间如 图00 所示,
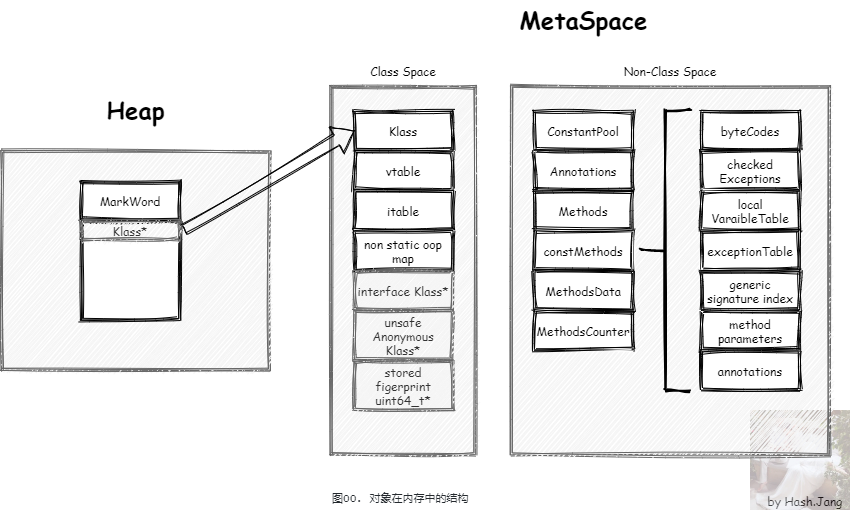
我们这里先只关心堆内部的存储,元空间中的存储,我们会在另一个系列详细讨论。堆内部的存储包括对象头,对象体以及内存对齐填充,那么这块空间是如何分配的呢?
首先,对象所需的内存,在对象的类被解析加载进入元空间之后,就可以在分配内存创建前计算出来。假设现在我们自己来设计堆内存分配,一种最简单的实现方式就是线性分配,也被称为撞针分配(bump-the-pointer)。
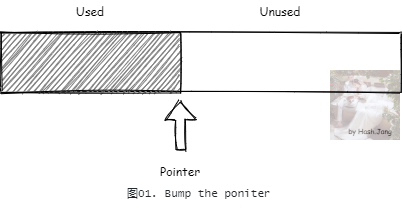
每次需要分配内存时,先计算出需要的内存大小,然后 CAS 更新如 图01 中所示的内存分配指针,标记分配的内存。但是内存一般不是这么整齐的,可能有些内存在分配有些内存就被释放回收了。所以一般不会只靠撞针分配。一种思路是在撞针分配的基础上,加上一个 FreeList。
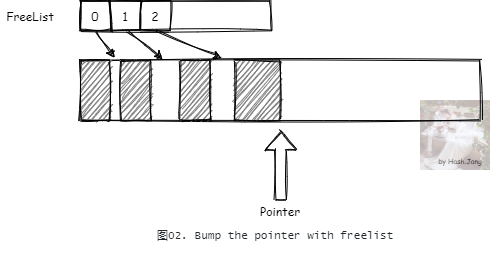
简单的实现是将释放的对象内存加入 FreeList,下次分配对象的时候,优先从 FreeList 中寻找合适的内存大小进行分配,之后再在主内存中撞针分配。
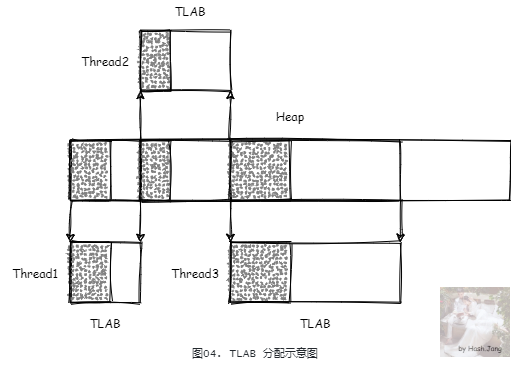
这样虽然一定程度上解决了问题,但是目前大多数应用是多线程的,所以内存分配是多线程的,都从主内存中分配,CAS 更新重试过于频繁导致效率低下。目前的应用,一般根据不同业务区分了不同的线程池,在这种情况下**,一般每个线程分配内存的特性是比较稳定的**。这里的比较稳定指的是,每次分配对象的大小,每轮 GC 分配区间内的分配对象的个数以及总大小。所以,我们可以考虑每个线程分配内存后,就将这块内存保留起来,用于下次分配,这样就不用每次从主内存中分配了。如果能估算每轮 GC 内每个线程使用的内存大小,则可以提前分配好内存给线程,这样就更能提高分配效率。这种内存分配的实现方式,在 JVM 中就是 TLAB (Thread Local Allocate Buffer)。
3. JVM 对象堆内存分配流程简述
我们这里不考虑栈上分配,这些会在 JIT 的章节详细分析,我们这里考虑的是无法栈上分配需要共享的对象。
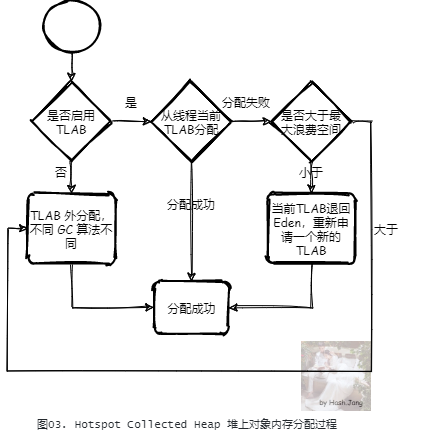
对于 HotSpot JVM 实现,所有的 GC 算法的实现都是一种对于堆内存的管理,也就是都实现了一种堆的抽象,它们都实现了接口 CollectedHeap。当分配一个对象堆内存空间时,在 CollectedHeap 上首先都会检查是否启用了 TLAB,如果启用了,则会尝试 TLAB 分配;如果当前线程的 TLAB 大小足够,那么从线程当前的 TLAB 中分配;如果不够,但是当前 TLAB 剩余空间小于最大浪费空间限制(这是一个动态的值,我们后面会详细分析),则从堆上(一般是 Eden 区) 重新申请一个新的 TLAB 进行分配。否则,直接在 TLAB 外进行分配。TLAB 外的分配策略,不同的 GC 算法不同。例如G1:
- 如果是 Humongous 对象(对象在超过 Region 一半大小的时候),直接在 Humongous 区域分配(老年代的连续区域)。
- 根据 Mutator 状况在当前分配下标的 Region 内分配
4. TLAB 的生命周期
TLAB 是线程私有的,线程初始化的时候,会创建并初始化 TLAB。同时,在 GC 扫描对象发生之后,线程第一次尝试分配对象的时候,也会创建并初始化 TLAB。
TLAB 生命周期停止(TLAB 声明周期停止不代表内存被回收,只是代表这个 TLAB 不再被这个线程私有管理)在:
-
当前 TLAB 不够分配,并且剩余空间小于最大浪费空间限制,那么这个 TLAB 会被退回 Eden,重新申请一个新的
-
发生 GC 的时候,TLAB 被回收。
5. TLAB 要解决的问题以及带来的问题与解决方案的思考
TLAB 要解决的问题很明显,尽量避免从堆上直接分配内存从而避免频繁的锁争用。
引入 TLAB 之后,TLAB 的设计上,也有很多值得考虑的问题。
5.1. 引入 TLAB 后,会有内存孔隙问题,还可能影响 GC 扫描性能
出现孔隙的情况:
-
当前 TLAB 不够分配时,如果剩余空间小于最大浪费空间限制,那么这个 TLAB 会被退回 Eden,重新申请一个新的。这个剩余空间就会成为孔隙。
-
当发生 GC 的时候,TLAB 没有用完,没有分配的内存也会成为孔隙。
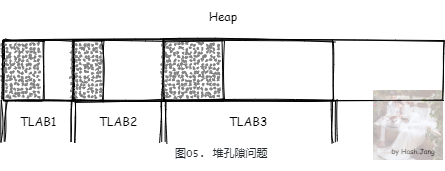
如果不管这些孔隙,由于 TLAB 仅线程内知道哪些被分配了,在 GC 扫描发生时返回 Eden 区,如果不填充的话,外部并不知道哪一部分被使用哪一部分没有,需要做额外的检查,那么会影响 GC 扫描效率。所以 TLAB 回归 Eden 的时候,会将剩余可用的空间用一个 dummy object 填充满。如果填充已经确认会被回收的对象,也就是 dummy object, GC 会直接标记之后跳过这块内存,增加扫描效率。但是同时,由于需要填充这个 dummy object,所以需要预留出这个对象的对象头的空间。
5.2. 某个线程在一轮 GC 内分配的内存并不稳定
如果我们能提前知道在这一轮内每个线程会分配多少内存,那么我们可以直接提前分配好。但是,这简直是痴人说梦。每个线程在每一轮 GC 的分配情况可能都是不一样的:
- 不同的线程业务场景不同导致分配对象大小不同。我们一般会按照业务区分不同的线程池,做好线程池隔离。对于用户请求,每次分配的对象可能比较小。对于后台分析请求,每次分配的对象相对大一些。
- 不同时间段内线程压力并不均匀。业务是有高峰有低谷的,高峰时间段内肯定分配对象更多。
- 同一时间段同一线程池内的线程的业务压力也不一定不能做到很均匀。很可能只有几个线程很忙,其他线程很闲。
所以,综合考虑以上情况,我们应该这么实现 TLAB:
- 不能一下子就给一个线程申请一个比较大的 TLAB,而是考虑这个线程 TLAB 分配满之后再申请新的,这样更加灵活。
- 每次申请 TLAB 的大小是变化的,并不是固定的。
- 每次申请 TLAB 的大小需要考虑当前 GC 轮次内会分配对象的线程的个数期望
- 每次申请 TLAB 的大小需要考虑所有线程期望 TLAB 分配满重新申请新的 TLAB 次数
6. JVM 中的期望计算 EMA
在上面提到的 TLAB 大小设计的时候,我们经常提到期望。这个期望是根据历史数据计算得出的,也就是每次输入采样值,根据历史采样值得出最新的期望值。不仅 TLAB 用到了这种期望计算,GC 和 JIT 等等 JVM 机制中都用到了。这里我们来看一种 TLAB 中经常用到的 EMA(Exponential Moving Average 指数平均数) 算法:
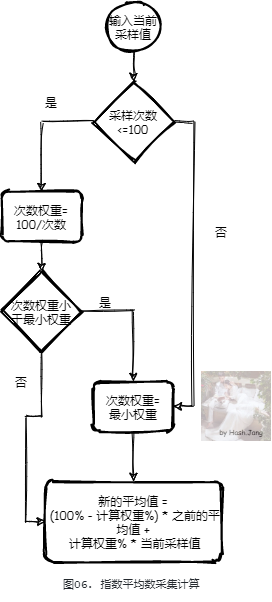
EMA 算法的核心在于设置合适的最小权重,我们假设一个场景:首先采样100个 100(算法中的前 100 个是为了排除不稳定的干扰,我们这里直接忽略前 100 个采样),之后采样 50 个 2,最后采样 50 个 200,对于不同的最小权重,来看一下变化曲线。
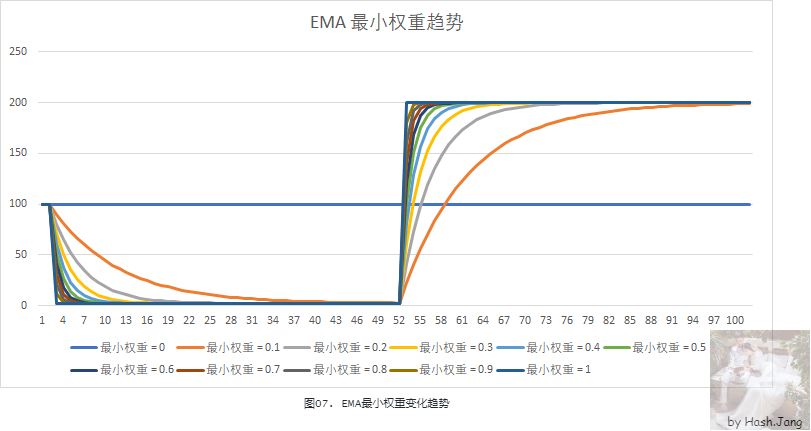
可以看出,最小权重越大,变化得越快,受历史数据影响越小。根据应用设置合适的最小权重,可以让你的期望更加理想。
这块对应的源代码:gcUtil.hpp 的 AdaptiveWeightedAverage 类。
7. TLAB 相关的 JVM 参数
这里仅仅是列出来,并附上简介,看不懂没关系,之后会有详细分析,帮助你理解每一个参数。等你理解后,这个小章节就是你的工具书啦~~
以下参数以及默认值基于 OpenJDK 17
7.1. TLABStats(已过期)
从 Java 12 开始已过期,目前已经没有相关的逻辑了。之前是用于 TLAB 统计数据从而更好地伸缩 TLAB 但是性能消耗相对较大,但是现在主要通过 EMA 计算了。
7.2. UseTLAB
说明:是否启用 TLAB,默认是启用的。
默认:true
举例:如果想关闭:-XX:-UseTLAB
7.3. ZeroTLAB
说明:是否将新创建的 TLAB 内的所有字节归零。我们创建一个类的时候,类的 field 是有默认值的,例如 boolean 是 false,int 是 0 等等,实现的方式就是对分配好的内存空间赋 0。设置 ZeroTLAB 为 true 代表在 TLAB 申请好的时候就赋 0,否则会在分配对象并初始化的时候赋 0.讲道理,由于 TLAB 分配的时候会涉及到 Allocation Prefetch 优化 CPU 缓存,在 TLAB 分配好之后立刻更新赋 0 对于 CPU 缓存应该是更友好的,并且,如果 TLAB 没有用满,填充的 dummy object 其实依然是 0 数组,相当于大部分不用改。这么看来,开启应该更好。但是ZeroTLAB 默认还是不开启的。
默认:false
举例:-XX:+ZeroTLAB
7.4. ResizeTLAB
说明:TLAB 是否是可变的,默认为是,也就是会根据线程历史分配数据相关 EMA 计算出每次期望 TLAB 大小并以这个大小为准申请 TLAB。
默认:true
举例:如果想关闭:-XX:-ResizeTLAB
7.5. TLABSize
说明:初始 TLAB 大小。单位是字节
默认:0, 0 就是不主动设置 TLAB 初始大小,而是通过 JVM 自己计算每一个线程的初始大小
举例:-XX:TLABSize=65536
7.6. MinTLABSize
说明:最小 TLAB 大小。单位是字节
默认:2048
举例:-XX:TLABSize=4096
7.7. TLABAllocationWeight
说明: TLAB 初始大小计算和线程数量有关,但是线程是动态创建销毁的。所以需要基于历史线程个数推测接下来的线程个数来计算 TLAB 大小。一般 JVM 内像这种预测函数都采用了 EMA 。这个参数就是 图06 中的最小权重,权重越高,最近的数据占比影响越大。TLAB 重新计算大小是根据分配比例,分配比例也是采用了 EMA 算法,最小权重也是 TLABAllocationWeight
默认:35
举例:-XX:TLABAllocationWeight=70
7.8. TLABWasteTargetPercent
说明:TLAB 的大小计算涉及到了 Eden 区的大小以及可以浪费的比率。TLAB 浪费指的是上面提到的重新申请新的 TLAB 的时候老的 TLAB 没有分配的空间。这个参数其实就是 TLAB 浪费占用 Eden 的百分比,这个参数的作用会在接下来的原理说明内详细说明
默认:1
举例:-XX:TLABWasteTargetPercent=10
7.9. TLABRefillWasteFraction
说明: 初始最大浪费空间限制计算参数,初始最大浪费空间限制 = 当前期望 TLAB 大小 / TLABRefillWasteFraction
默认:64
举例:-XX:TLABRefillWasteFraction=32
7.10. TLABWasteIncrement
说明: 最大浪费空间限制并不是不变的,在发生 TLAB 缓慢分配的时候(也就是当前 TLAB 空间不足以分配的时候),会增加最大浪费空间限制。这个参数就是 TLAB 缓慢分配时允许的 TLAB 浪费增量。单位不是字节,而是 MarkWord 个数,也就是 Java 堆的内存最小单元,64 位虚拟机的情况下,MarkWord 大小为 3 字节。
默认:4
举例:-XX:TLABWasteIncrement=4
8.TLAB 基本流程
8.0. 如何设计每个线程的 TLAB 大小
之前我们提到了引入 TLAB 要面临的问题以及解决方式,根据这些我们可以这么设计 TLAB。
首先,TLAB 的初始大小,应该和每个 GC 内需要对象分配的线程个数相关。但是,要分配的线程个数并不一定是稳定的,可能这个时间段线程数多,下个阶段线程数就不那么多了,所以,需要用 EMA 的算法采集每个 GC 内需要对象分配的线程个数来计算这个个数期望。
接着,我们最理想的情况下,是每个 GC 内,所有用来分配对象的内存都处于对应线程的 TLAB 中。每个 GC 内用来分配对象的内存从 JVM 设计上来讲,其实就是 Eden 区大小。在 最理想的情况下,最好只有Eden 区满了的时候才会 GC,不会有其他原因导致的 GC,这样是最高效的情况。Eden 区被用光,如果全都是 TLAB 内分配,也就是 Eden 区被所有线程的 TLAB 占满了,这样分配是最快的。
然后,每轮 GC 分配内存的线程个数以及大小是不一定的,如果一下子分配一大块会造成浪费,如果太小则会频繁从 Eden 申请 TLAB,降低效率。这个大小比较难以控制,但是我们可以限制每个线程究竟在一轮 GC 内,最多从 Eden 申请多少次 TLAB,这样对于用户来说更好控制。
最后,每个线程分配的内存大小,在每轮 GC 并不一定稳定,只用初始大小来指导之后的 TLAB 大小,显然不够。我们换个思路,每个线程分配的内存和历史有一定关系因此我们可以从历史分配中推测,所以每个线程也需要采用 EMA 的算法采集这个线程每次 GC 分配的内存,用于指导下次期望的 TLAB 的大小。
综上所述,我们可以得出这样一个近似的 TLAB 计算公式:
每个线程 TLAB 初始大小 = Eden区大小 / (线程单个 GC 轮次内最多从 Eden 申请多少次 TLAB * 当前 GC 分配线程个数 EMA)
GC 后,重新计算 TLAB 大小 = Eden区大小 / (线程单个 GC 轮次内最多从 Eden 申请多少次 TLAB * 当前 GC 分配线程个数 EMA)
接下来,我们来详细分析 TLAB 的整个生命周期的每个流程。
8.1. TLAB 初始化
线程初始化的时候,如果 JVM 启用了 TLAB(默认是启用的, 可以通过 -XX:-UseTLAB 关闭),则会初始化 TLAB,在发生对象分配时,会根据期望大小申请 TLAB 内存。同时,在 GC 扫描对象发生之后,线程第一次尝试分配对象的时候,也会重新申请 TLAB 内存。我们先只关心初始化,初始化的流程图如 图08 所示:
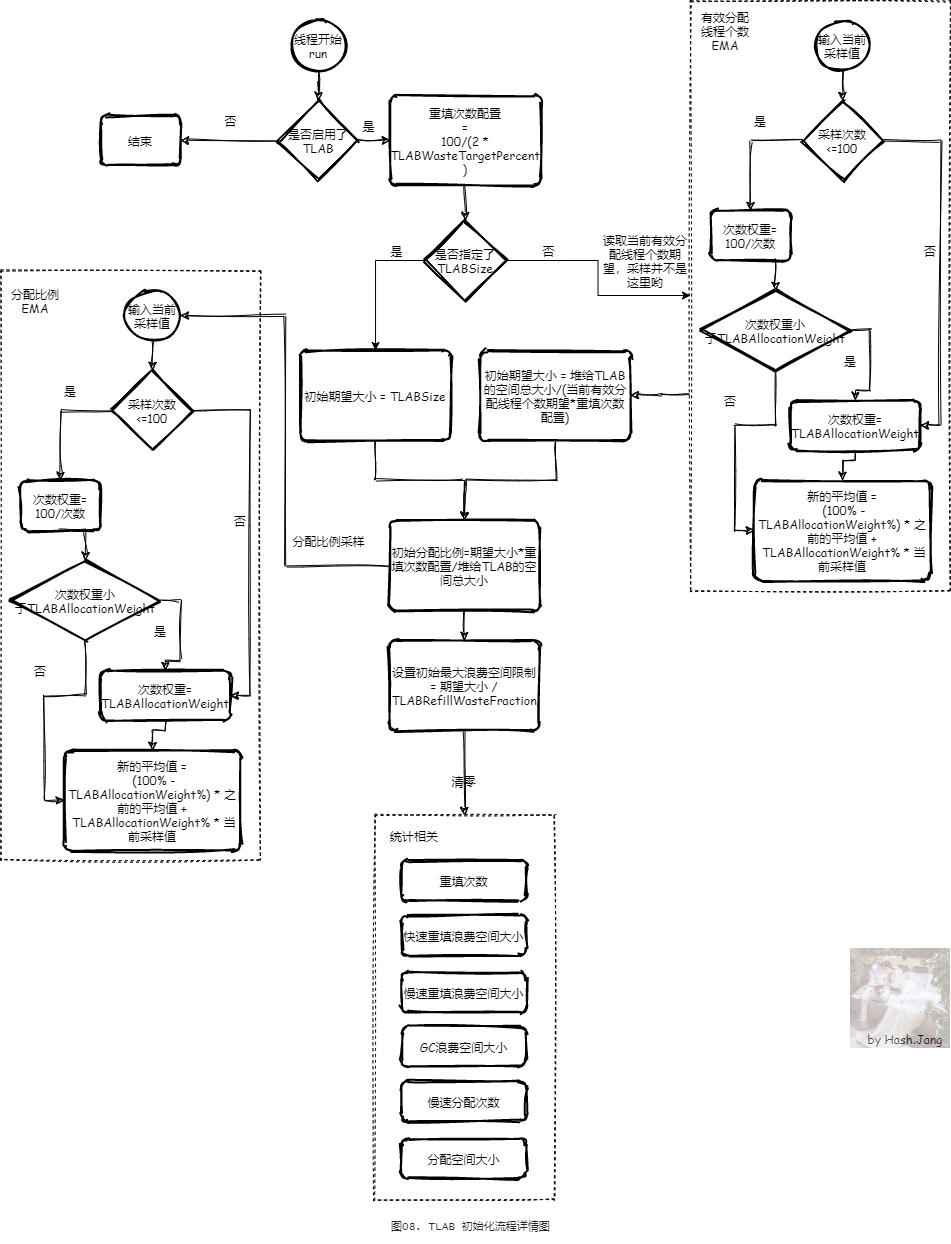
初始化时候会计算 TLAB 初始期望大小。这涉及到了 TLAB 大小的限制:
- TLAB 的最小大小:通过MinTLABSize指定
- TLAB 的最大大小:不同的 GC 中不同,G1 GC 中为大对象(humongous object)大小,也就是 G1 region 大小的一半。因为开头提到过,在 G1 GC 中,大对象不能在 TLAB 分配,而是老年代。ZGC 中为页大小的 8 分之一,类似的在大部分情况下 Shenandoah GC 也是每个 Region 大小的 8 分之一。他们都是期望至少有 8 分之 7 的区域是不用退回的减少选择 Cset 的时候的扫描复杂度。对于其他的 GC,则是 int 数组的最大大小,这个和之前提到的填充 dummy object 有关,后面会提到详细流程。
之后的流程里面,无论何时,TLAB 的大小都会在这个 TLAB 的最小大小 到 TLAB 的最大大小 的范围内,为了避免啰嗦,我们不会再强调这个限制~~~!!! 之后的流程里面,无论何时,TLAB 的大小都会在这个 TLAB 的最小大小 到 TLAB 的最大大小 的范围内,为了避免啰嗦,我们不会再强调这个限制~~~!!! 之后的流程里面,无论何时,TLAB 的大小都会在这个 TLAB 的最小大小 到 TLAB 的最大大小 的范围内,为了避免啰嗦,我们不会再强调这个限制~~~!!! 重要的事情说三遍~
TLAB 期望大小(desired size) 在初始化的时候会计算 TLAB 期望大小,之后再 GC 等操作回收掉 TLAB 需要重计算这个期望大小。根据这个期望大小,TLAB 在申请空间的时候每次申请都会以这个期望大小作为基准的空间作为 TLAB 分配空间。
8.1.1. TLAB 初始期望大小计算
如 图08 所示,如果指定了 TLABSize,就用这个大小作为初始期望大小。如果没有指定,则按照如下的公式进行计算:
堆给TLAB的空间总大小/(当前有效分配线程个数期望*重填次数配置)
- 堆给 TLAB 的空间总大小:堆上能有多少空间分配给 TLAB,不同的 GC 算法不一样,但是大多数 GC 算法的实现都是 Eden 区大小,例如:
- 传统的已经弃用的 Parallel Scanvage 中,就是 Eden 区大小。参考:parallelScavengeHeap.cpp
- 默认的G1 GC 中是 (YoungList 区域个数减去 Survivor 区域个数) * 区域大小,其实就是 Eden 区大小。参考:g1CollectedHeap.cpp
- ZGC 中是 Page 剩余空间大小,Page 类似于 Eden 区,是大部分对象分配的区域。参考:zHeap.cpp
- Shenandoah GC 中是 FreeSet 的大小,也是类似于 Eden 的概念。参考:shenandoahHeap.cpp
-
当前有效分配线程个数期望:这是一个全局 EMA,EMA 是什么之前已经说明了,是一种计算期望的方式。有效分配线程个数 EMA 的最小权重是 TLABAllocationWeight。有效分配线程个数 EMA 在有线程进行第一次有效对象分配的时候进行采集,在 TLAB 初始化的时候读取这个值计算 TLAB 期望大小。
-
TLAB 重填次数配置(refills time):根据 TLABWasteTargetPercent 计算的次数,公式为。TLABWasteTargetPercent 的意义其实是限制最大浪费空间限制,为何重填次数与之相关后面会详细分析。
8.1.2. TLAB 初始分配比例计算
如 图08 所示,接下来会计算TLAB 初始分配比例。
线程私有分配比例 EMA:与有效分配线程个数 EMA对应,有效分配线程个数 EMA是对于全局来说,每个线程应该占用多大的 TLAB 的描述,而分配比例 EMA 相当于对于当前线程应该占用的总 TLAB 空间的大小的一种动态控制。
初始化的时候,分配比例其实就是等于 1/当前有效分配线程个数。图08 的公式,代入之前的计算 TLAB 期望大小的公式,消参简化之后就是1/当前有效分配线程个数。这个值作为初始值,采集如线程私有的分配比例 EMA。
8.1.3. 清零线程私有统计数据
这些采集数据会用于之后的当前线程的分配比例的计算与采集,从而影响之后的当前线程 TLAB 期望大小。
8.2. TLAB 分配
TLAB 分配流程如 图09 所示。
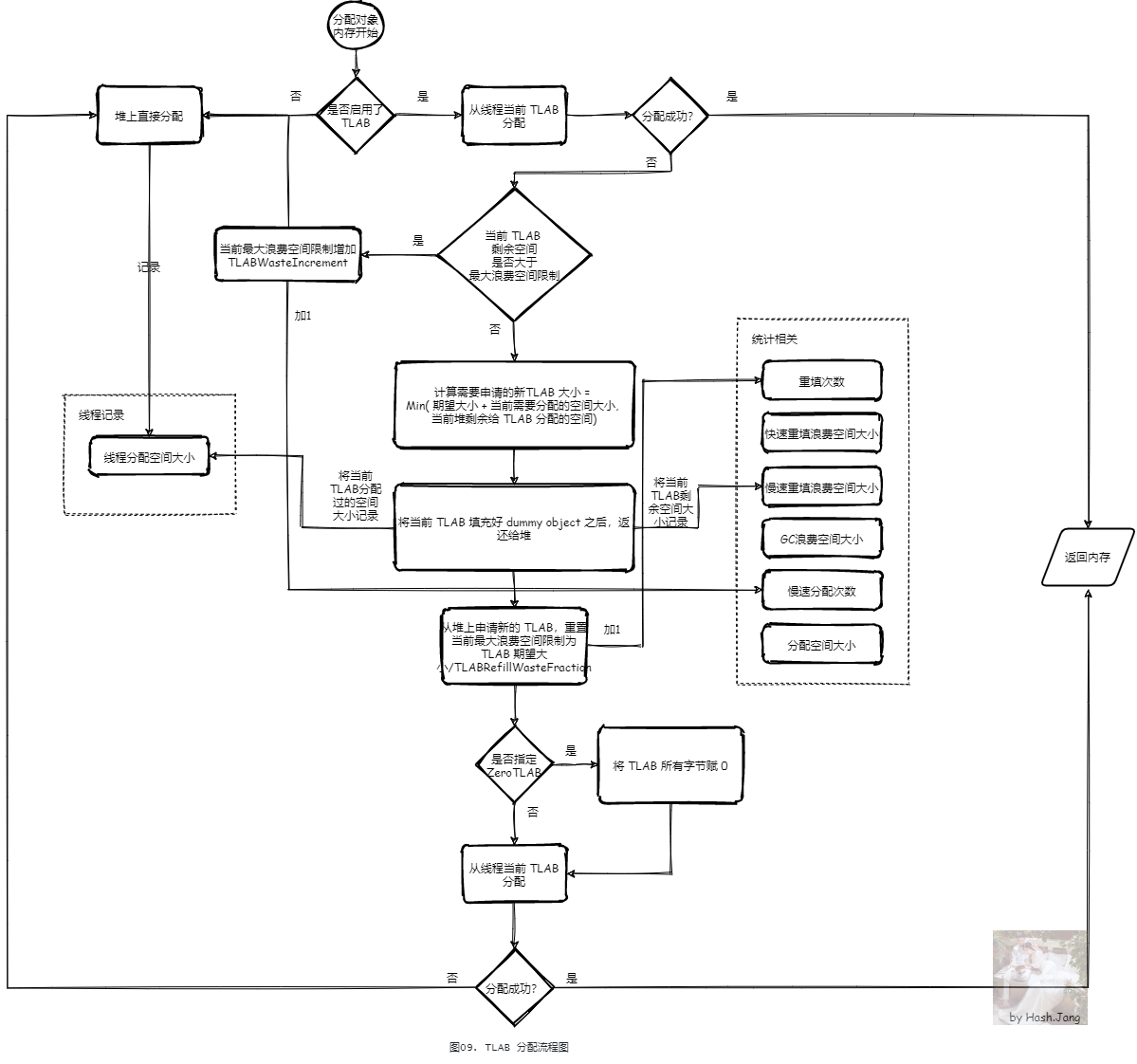
8.2.1. 从线程当前 TLAB 分配
如果启用了 TLAB(默认是启用的, 可以通过 -XX:-UseTLAB 关闭),则首先从线程当前 TLAB 分配内存,如果分配成功则返回,否则根据当前 TLAB 剩余空间与当前最大浪费空间限制大小进行不同的分配策略。在下一个流程,就会提到这个限制究竟是什么。
8.2.2. 重新申请 TLAB 分配
如果当前 TLAB 剩余空间大于当前最大浪费空间限制(根据 图08 的流程,我们知道这个初始值为 期望大小/TLABRefillWasteFraction),直接在堆上分配。否则,重新申请一个 TLAB 分配。
为什么需要最大浪费空间呢?
当重新分配一个 TLAB 的时候,原有的 TLAB 可能还有空间剩余。原有的 TLAB 被退回堆之前,需要填充好 dummy object。由于 TLAB 仅线程内知道哪些被分配了,在 GC 扫描发生时返回 Eden 区,如果不填充的话,外部并不知道哪一部分被使用哪一部分没有,需要做额外的检查,如果填充已经确认会被回收的对象,也就是 dummy object, GC 会直接标记之后跳过这块内存,增加扫描效率。反正这块内存已经属于 TLAB,其他线程在下次扫描结束前是无法使用的。这个 dummy object 就是 int 数组。为了一定能有填充 dummy object 的空间,一般 TLAB 大小都会预留一个 dummy object 的 header 的空间,也是一个 int[] 的 header,所以 TLAB 的大小不能超过int 数组的最大大小,否则无法用 dummy object 填满未使用的空间。
但是,填充 dummy 也造成了空间的浪费,这种浪费不能太多,所以通过最大浪费空间限制来限制这种浪费。
新的 TLAB 大小,取如下两个值中较小的那个:
- 当前堆剩余给 TLAB 可分配的空间,大部分 GC 的实现其实就是对应的 Eden 区剩余大小:
- 传统的已经弃用的 Parallel Scanvage 中,就是 Eden 区剩余大小。参考:parallelScavengeHeap.cpp
- 默认的G1 GC 中是当前 Region 中剩余大小,其实就是将 Eden 分区了。参考:g1CollectedHeap.cpp
- ZGC 中是 Page 剩余空间大小,Page 类似于 Eden 区,是大部分对象分配的区域。参考:zHeap.cpp
- Shenandoah GC 中是 FreeSet 的剩余大小,也是类似于 Eden 的概念。参考:shenandoahHeap.cpp
- TLAB 期望大小 + 当前需要分配的空间大小
当分配出来 TLAB 之后,根据 ZeroTLAB 配置,决定是否将每个字节赋 0。在创建对象的时候,本来也要对每个字段赋初始值,大部分字段初始值都是 0,并且,在 TLAB 返还到堆时,剩余空间填充的也是 int[] 数组,里面都是 0。所以其实可以提前填充好。并且,TLAB 刚分配出来的时候,赋 0 也能利用好 Allocation prefetch 的机制适应 CPU 缓存行(Allocation prefetch 的机制会在另一个系列说明),所以可以通过打开 ZeroTLAB 来在分配 TLAB 空间之后立刻赋 0。
8.2.3. 直接从堆上分配
直接从堆上分配是最慢的分配方式。一种情况就是,如果当前 TLAB 剩余空间大于当前最大浪费空间限制,直接在堆上分配。并且,还会增加当前最大浪费空间限制,每次有这样的分配就会增加 TLABWasteIncrement 的大小,这样在一定次数的直接堆上分配之后,当前最大浪费空间限制一直增大会导致当前 TLAB 剩余空间小于当前最大浪费空间限制,从而申请新的 TLAB 进行分配。
8.3. GC 时 TLAB 回收与重计算期望大小
相关流程如 图10 所示,在 GC 前与 GC 后,都会对 TLAB 做一些操作。
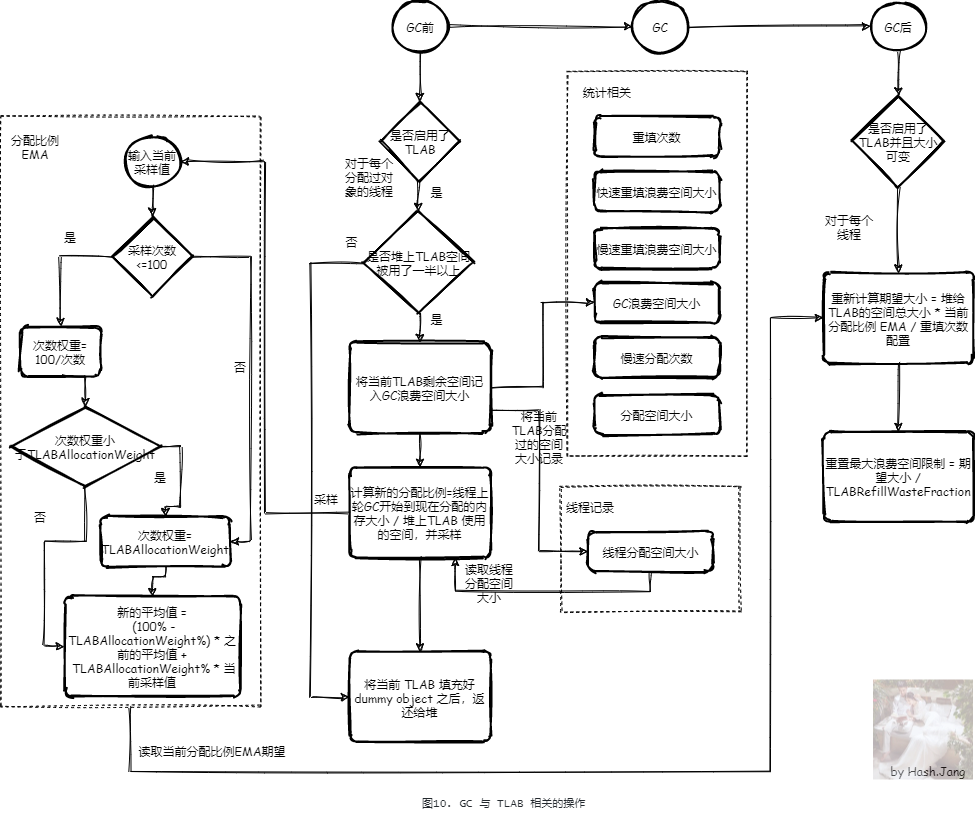
8.3.1. GC 前的操作
在 GC 前,如果启用了 TLAB(默认是启用的, 可以通过 -XX:-UseTLAB 关闭),则需要将所有线程的 TLAB 填充 dummy Object 退还给堆,并计算并采样一些东西用于以后的 TLAB 大小计算。
首先为了保证本次计算具有参考意义,需要先判断是否堆上 TLAB 空间被用了一半以上,假设不足,那么认为本轮 GC 的数据没有参考意义。如果被用了一半以上,那么计算新的分配比例,新的分配比例 = 线程本轮 GC 分配空间的大小 / 堆上所有线程 TLAB 使用的空间,这么计算主要因为分配比例描述的是当前线程占用堆上所有给 TLAB 的空间的比例,每个线程不一样,通过这个比例动态控制不同业务线程的 TLAB 大小。
线程本轮 GC 分配空间的大小包含 TLAB 中分配的和 TLAB 外分配的,从 图8、图9、图10 流程图中对于线程记录中的线程分配空间大小的记录就能看出,读取出线程分配空间大小减去上一轮 GC 结束时线程分配空间大小就是线程本轮 GC 分配空间的大小。
最后,将当前 TLAB 填充好 dummy object 之后,返还给堆。
8.3.2. GC 后的操作
如果启用了 TLAB(默认是启用的, 可以通过 -XX:-UseTLAB 关闭),以及 TLAB 大小可变(默认是启用的, 可以通过 -XX:-ResizeTLAB 关闭),那么在 GC 后会重新计算每个线程 TLAB 的期望大小,新的期望大小 = 堆给TLAB的空间总大小 * 当前分配比例 EMA / 重填次数配置。然后会重置最大浪费空间限制,为当前 期望大小 / TLABRefillWasteFraction。
9. OpenJDK HotSpot TLAB 相关源代码分析
如果这里看的比较吃力,可以直接看第 10 章,热门 Q&A,里面有很多大家常问的问题
9.1. TLAB 类构成
线程初始化的时候,如果 JVM 启用了 TLAB(默认是启用的, 可以通过 -XX:-UseTLAB 关闭),则会初始化 TLAB。
TLAB 包括如下几个 field (HeapWord* 可以理解为堆中的内存地址):
src/hotspot/share/gc/shared/threadLocalAllocBuffer.cpp
//静态全局变量
static size_t _max_size; // 所有 TLAB 的最大大小
static int _reserve_for_allocation_prefetch; // CPU 缓存优化 Allocation Prefetch 的保留空间,这里先不用关心
static unsigned _target_refills; //每个 GC 周期内期望的重填次数
//以下是 TLAB 的主要构成 field
HeapWord* _start; // TLAB 起始地址,表示堆内存地址都用 HeapWord*
HeapWord* _top; // 上次分配的内存地址
HeapWord* _end; // TLAB 结束地址
size_t _desired_size; // TLAB 大小 包括保留空间,表示内存大小都需要通过 size_t 类型,也就是实际字节数除以 HeapWordSize 的值
size_t _refill_waste_limit; // TLAB最大浪费空间,剩余空间不足分配浪费空间限制。在TLAB剩余空间不足的时候,根据这个值决定分配策略,如果浪费空间大于这个值则直接在 Eden 区分配,如果小于这个值则将当前 TLAB 放回 Eden 区管理并从 Eden 申请新的 TLAB 进行分配。
AdaptiveWeightedAverage _allocation_fraction; // 当前 TLAB 分配比例 EMA
//以下是我们这里不用太关心的 field
HeapWord* _allocation_end; // TLAB 真正可以用来分配内存的结束地址,这个是 _end 结束地址排除保留空间(预留给 dummy object 的对象头空间)
HeapWord* _pf_top; // Allocation Prefetch CPU 缓存优化机制相关需要的参数,这里先不用考虑
size_t _allocated_before_last_gc; // 这个用于计算 图10 中的线程本轮 GC 分配空间的大小,记录上次 GC 时,线程分配的空间大小
unsigned _number_of_refills; // 线程分配内存数据采集相关,TLAB 剩余空间不足分配次数
unsigned _fast_refill_waste; // 线程分配内存数据采集相关,TLAB 快速分配浪费,快速分配就是直接在 TLAB 分配,这个在现在 JVM 中已经用不到了
unsigned _slow_refill_waste; // 线程分配内存数据采集相关,TLAB 慢速分配浪费,慢速分配就是重填一个 TLAB 分配
unsigned _gc_waste; // 线程分配内存数据采集相关,gc浪费
unsigned _slow_allocations; // 线程分配内存数据采集相关,TLAB 慢速分配计数
size_t _allocated_size; // 分配的内存大小
size_t _bytes_since_last_sample_point; // JVM TI 采集指标相关 field,这里不用关心
9.2. TLAB 初始化
首先是 JVM 启动的时候,全局 TLAB 需要初始化:
src/hotspot/share/gc/shared/threadLocalAllocBuffer.cpp
void ThreadLocalAllocBuffer::startup_initialization() {
//初始化,也就是归零统计数据
ThreadLocalAllocStats::initialize();
// 假设平均下来,GC 扫描的时候,每个线程当前的 TLAB 都有一半的内存被浪费,这个每个线程使用内存的浪费的百分比率(也就是 TLABWasteTargetPercent),也就是等于(注意,仅最新的那个 TLAB 有浪费,之前 refill 退回的假设是没有浪费的):1/2 * (每个 epoch 内每个线程期望 refill 次数) * 100
//那么每个 epoch 内每个线程 refill 次数配置就等于 50 / TLABWasteTargetPercent, 默认也就是 50 次。
_target_refills = 100 / (2 * TLABWasteTargetPercent);
// 但是初始的 _target_refills 需要设置最多不超过 2 次来减少 VM 初始化时候 GC 的可能性
_target_refills = MAX2(_target_refills, 2U);
//如果 C2 JIT 编译存在并启用,则保留 CPU 缓存优化 Allocation Prefetch 空间,这个这里先不用关心,会在别的章节讲述
#ifdef COMPILER2
if (is_server_compilation_mode_vm()) {
int lines = MAX2(AllocatePrefetchLines, AllocateInstancePrefetchLines) + 2;
_reserve_for_allocation_prefetch = (AllocatePrefetchDistance + AllocatePrefetchStepSize * lines) /
(int)HeapWordSize;
}
#endif
// 初始化 main 线程的 TLAB
guarantee(Thread::current()->is_Java_thread(), "tlab initialization thread not Java thread");
Thread::current()->tlab().initialize();
log_develop_trace(gc, tlab)("TLAB min: " SIZE_FORMAT " initial: " SIZE_FORMAT " max: " SIZE_FORMAT,
min_size(), Thread::current()->tlab().initial_desired_size(), max_size());
}
每个线程维护自己的 TLAB,同时每个线程的 TLAB 大小不一。TLAB 的大小主要由 Eden 的大小,线程数量,还有线程的对象分配速率决定。
在 Java 线程开始运行时,会先分配 TLAB:
src/hotspot/share/runtime/thread.cpp
void JavaThread::run() {
// initialize thread-local alloc buffer related fields
this->initialize_tlab();
//剩余代码忽略
}
分配 TLAB 其实就是调用 ThreadLocalAllocBuffer 的 initialize 方法。
src/hotspot/share/runtime/thread.cpp
void initialize_tlab() {
//如果没有通过 -XX:-UseTLAB 禁用 TLAB,则初始化TLAB
if (UseTLAB) {
tlab().initialize();
}
}
// Thread-Local Allocation Buffer (TLAB) support
ThreadLocalAllocBuffer& tlab() {
return _tlab;
}
ThreadLocalAllocBuffer _tlab;
ThreadLocalAllocBuffer 的 initialize 方法初始化 TLAB 的上面提到的我们要关心的各种 field:
src/hotspot/share/gc/shared/threadLocalAllocBuffer.cpp
void ThreadLocalAllocBuffer::initialize() {
//设置初始指针,由于还没有从 Eden 分配内存,所以这里都设置为 NULL
initialize(NULL, // start
NULL, // top
NULL); // end
//计算初始期望大小,并设置
set_desired_size(initial_desired_size());
//所有 TLAB 总大小,不同的 GC 实现有不同的 TLAB 容量, 一般是 Eden 区大小
//例如 G1 GC,就是等于 (_policy->young_list_target_length() - _survivor.length()) * HeapRegion::GrainBytes,可以理解为年轻代减去Survivor区,也就是Eden区
size_t capacity = Universe::heap()->tlab_capacity(thread()) / HeapWordSize;
//计算这个线程的 TLAB 期望占用所有 TLAB 总体大小比例
//TLAB 期望占用大小也就是这个 TLAB 大小乘以期望 refill 的次数
float alloc_frac = desired_size() * target_refills() / (float) capacity;
//记录下来,用于计算 EMA
_allocation_fraction.sample(alloc_frac);
//计算初始 refill 最大浪费空间,并设置
//如前面原理部分所述,初始大小就是 TLAB 的大小(_desired_size) / TLABRefillWasteFraction
set_refill_waste_limit(initial_refill_waste_limit());
//重置统计
reset_statistics();
}
9.2.1. 初始期望大小是如何计算的呢?
src/hotspot/share/gc/shared/threadLocalAllocBuffer.cpp
//计算初始大小
size_t ThreadLocalAllocBuffer::initial_desired_size() {
size_t init_sz = 0;
//如果通过 -XX:TLABSize 设置了 TLAB 大小,则用这个值作为初始期望大小
//表示堆内存占用大小都需要用占用几个 HeapWord 表示,所以用TLABSize / HeapWordSize
if (TLABSize > 0) {
init_sz = TLABSize / HeapWordSize;
} else {
//获取当前epoch内线程数量期望,这个如之前所述通过 EMA 预测
unsigned int nof_threads = ThreadLocalAllocStats::allocating_threads_avg();
//不同的 GC 实现有不同的 TLAB 容量,Universe::heap()->tlab_capacity(thread()) 一般是 Eden 区大小
//例如 G1 GC,就是等于 (_policy->young_list_target_length() - _survivor.length()) * HeapRegion::GrainBytes,可以理解为年轻代减去Survivor区,也就是Eden区
//整体大小等于 Eden区大小/(当前 epcoh 内会分配对象期望线程个数 * 每个 epoch 内每个线程 refill 次数配置)
//target_refills已经在 JVM 初始化所有 TLAB 全局配置的时候初始化好了
init_sz = (Universe::heap()->tlab_capacity(thread()) / HeapWordSize) /
(nof_threads * target_refills());
//考虑对象对齐,得出最后的大小
init_sz = align_object_size(init_sz);
}
//保持大小在 min_size() 还有 max_size() 之间
//min_size主要由 MinTLABSize 决定
init_sz = MIN2(MAX2(init_sz, min_size()), max_size());
return init_sz;
}
//最小大小由 MinTLABSize 决定,需要表示为 HeapWordSize,并且考虑对象对齐,最后的 alignment_reserve 是 dummy object 填充的对象头大小(这里先不考虑 JVM 的 CPU 缓存 prematch,我们会在其他章节详细分析)。
static size_t min_size() {
return align_object_size(MinTLABSize / HeapWordSize) + alignment_reserve();
}
9.2.2. TLAB 最大大小是怎样决定的呢?
不同的 GC 方式,有不同的方式:
G1 GC 中为大对象(humongous object)大小,也就是 G1 region 大小的一半:
src/hotspot/share/gc/g1/g1CollectedHeap.cpp
// For G1 TLABs should not contain humongous objects, so the maximum TLAB size
// must be equal to the humongous object limit.
size_t G1CollectedHeap::max_tlab_size() const {
return align_down(_humongous_object_threshold_in_words, MinObjAlignment);
}
ZGC 中为页大小的 8 分之一,类似的在大部分情况下 Shenandoah GC 也是每个 Region 大小的 8 分之一。他们都是期望至少有 8 分之 7 的区域是不用退回的减少选择 Cset 的时候的扫描复杂度:
src/hotspot/share/gc/shenandoah/shenandoahHeap.cpp
MaxTLABSizeWords = MIN2(ShenandoahElasticTLAB ? RegionSizeWords : (RegionSizeWords / 8), HumongousThresholdWords);
src/hotspot/share/gc/z/zHeap.cpp
const size_t ZObjectSizeLimitSmall = ZPageSizeSmall / 8;
对于其他的 GC,则是 int 数组的最大大小,这个和为了填充 dummy object 表示 TLAB 的空区域有关。这个原因之前已经说明了。
9.3. TLAB 分配内存
当 new 一个对象时,需要调用instanceOop InstanceKlass::allocate_instance(TRAPS)
src/hotspot/share/oops/instanceKlass.cpp
instanceOop InstanceKlass::allocate_instance(TRAPS) {
bool has_finalizer_flag = has_finalizer(); // Query before possible GC
int size = size_helper(); // Query before forming handle.
instanceOop i;
i = (instanceOop)Universe::heap()->obj_allocate(this, size, CHECK_NULL);
if (has_finalizer_flag && !RegisterFinalizersAtInit) {
i = register_finalizer(i, CHECK_NULL);
}
return i;
}
其核心就是heap()->obj_allocate(this, size, CHECK_NULL)从堆上面分配内存:
src/hotspot/share/gc/shared/collectedHeap.inline.hpp
inline oop CollectedHeap::obj_allocate(Klass* klass, int size, TRAPS) {
ObjAllocator allocator(klass, size, THREAD);
return allocator.allocate();
}
使用全局的 ObjAllocator 实现进行对象内存分配:
src/hotspot/share/gc/shared/memAllocator.cpp
oop MemAllocator::allocate() const {
oop obj = NULL;
{
Allocation allocation(*this, &obj);
//分配堆内存,继续看下面一个方法
HeapWord* mem = mem_allocate(allocation);
if (mem != NULL) {
obj = initialize(mem);
} else {
// The unhandled oop detector will poison local variable obj,
// so reset it to NULL if mem is NULL.
obj = NULL;
}
}
return obj;
}
HeapWord* MemAllocator::mem_allocate(Allocation& allocation) const {
//如果使用了 TLAB,则从 TLAB 分配,分配代码继续看下面一个方法
if (UseTLAB) {
HeapWord* result = allocate_inside_tlab(allocation);
if (result != NULL) {
return result;
}
}
//否则直接从 tlab 外分配
return allocate_outside_tlab(allocation);
}
HeapWord* MemAllocator::allocate_inside_tlab(Allocation& allocation) const {
assert(UseTLAB, "should use UseTLAB");
//从当前线程的 TLAB 分配内存,TLAB 快分配
HeapWord* mem = _thread->tlab().allocate(_word_size);
//如果没有分配失败则返回
if (mem != NULL) {
return mem;
}
//如果分配失败则走 TLAB 慢分配,需要 refill 或者直接从 Eden 分配
return allocate_inside_tlab_slow(allocation);
}
9.3.1. TLAB 快分配
src/hotspot/share/gc/shared/threadLocalAllocBuffer.inline.hpp
inline HeapWord* ThreadLocalAllocBuffer::allocate(size_t size) {
//验证各个内存指针有效,也就是 _top 在 _start 和 _end 范围内
invariants();
HeapWord* obj = top();
//如果空间足够,则分配内存
if (pointer_delta(end(), obj) >= size) {
set_top(obj + size);
invariants();
return obj;
}
return NULL;
}
9.3.2. TLAB 慢分配
src/hotspot/share/gc/shared/memAllocator.cpp
HeapWord* MemAllocator::allocate_inside_tlab_slow(Allocation& allocation) const {
HeapWord* mem = NULL;
ThreadLocalAllocBuffer& tlab = _thread->tlab();
// 如果 TLAB 剩余空间大于 最大浪费空间,则记录并让最大浪费空间递增
if (tlab.free() > tlab.refill_waste_limit()) {
tlab.record_slow_allocation(_word_size);
return NULL;
}
//重新计算 TLAB 大小
size_t new_tlab_size = tlab.compute_size(_word_size);
//TLAB 放回 Eden 区
tlab.retire_before_allocation();
if (new_tlab_size == 0) {
return NULL;
}
// 计算最小大小
size_t min_tlab_size = ThreadLocalAllocBuffer::compute_min_size(_word_size);
//分配新的 TLAB 空间,并在里面分配对象
mem = Universe::heap()->allocate_new_tlab(min_tlab_size, new_tlab_size, &allocation._allocated_tlab_size);
if (mem == NULL) {
assert(allocation._allocated_tlab_size == 0,
"Allocation failed, but actual size was updated. min: " SIZE_FORMAT
", desired: " SIZE_FORMAT ", actual: " SIZE_FORMAT,
min_tlab_size, new_tlab_size, allocation._allocated_tlab_size);
return NULL;
}
assert(allocation._allocated_tlab_size != 0, "Allocation succeeded but actual size not updated. mem at: "
PTR_FORMAT " min: " SIZE_FORMAT ", desired: " SIZE_FORMAT,
p2i(mem), min_tlab_size, new_tlab_size);
//如果启用了 ZeroTLAB 这个 JVM 参数,则将对象所有字段置零值
if (ZeroTLAB) {
// ..and clear it.
Copy::zero_to_words(mem, allocation._allocated_tlab_size);
} else {
// ...and zap just allocated object.
}
//设置新的 TLAB 空间为当前线程的 TLAB
tlab.fill(mem, mem + _word_size, allocation._allocated_tlab_size);
//返回分配的对象内存地址
return mem;
}
9.3.2.1 TLAB最大浪费空间
TLAB最大浪费空间 _refill_waste_limit 初始值为 TLAB 大小除以 TLABRefillWasteFraction:
src/hotspot/share/gc/shared/threadLocalAllocBuffer.hpp
size_t initial_refill_waste_limit() { return desired_size() / TLABRefillWasteFraction; }
每次慢分配,调用record_slow_allocation(size_t obj_size)记录慢分配的同时,增加 TLAB 最大浪费空间的大小:
src/hotspot/share/gc/shared/threadLocalAllocBuffer.cpp
void ThreadLocalAllocBuffer::record_slow_allocation(size_t obj_size) {
//每次慢分配,_refill_waste_limit 增加 refill_waste_limit_increment,也就是 TLABWasteIncrement
set_refill_waste_limit(refill_waste_limit() + refill_waste_limit_increment());
_slow_allocations++;
log_develop_trace(gc, tlab)("TLAB: %s thread: " INTPTR_FORMAT " [id: %2d]"
" obj: " SIZE_FORMAT
" free: " SIZE_FORMAT
" waste: " SIZE_FORMAT,
"slow", p2i(thread()), thread()->osthread()->thread_id(),
obj_size, free(), refill_waste_limit());
}
//refill_waste_limit_increment 就是 JVM 参数 TLABWasteIncrement
static size_t refill_waste_limit_increment() { return TLABWasteIncrement; }
9.3.2.2. 重新计算 TLAB 大小
重新计算会取 当前堆剩余给 TLAB 可分配的空间 和 TLAB 期望大小 + 当前需要分配的空间大小 中的小的那个:
src/hotspot/share/gc/shared/threadLocalAllocBuffer.inline.hpp
inline size_t ThreadLocalAllocBuffer::compute_size(size_t obj_size) {
//获取当前堆剩余给 TLAB 可分配的空间
const size_t available_size = Universe::heap()->unsafe_max_tlab_alloc(thread()) / HeapWordSize;
//取 TLAB 可分配的空间 和 TLAB 期望大小 + 当前需要分配的空间大小 以及 TLAB 最大大小中的小的那个
size_t new_tlab_size = MIN3(available_size, desired_size() + align_object_size(obj_size), max_size());
// 确保大小大于 dummy obj 对象头
if (new_tlab_size < compute_min_size(obj_size)) {
log_trace(gc, tlab)("ThreadLocalAllocBuffer::compute_size(" SIZE_FORMAT ") returns failure",
obj_size);
return 0;
}
log_trace(gc, tlab)("ThreadLocalAllocBuffer::compute_size(" SIZE_FORMAT ") returns " SIZE_FORMAT,
obj_size, new_tlab_size);
return new_tlab_size;
}
9.3.2.3. 当前 TLAB 放回堆
src/hotspot/share/gc/shared/threadLocalAllocBuffer.cpp
//在TLAB慢分配被调用,当前 TLAB 放回堆
void ThreadLocalAllocBuffer::retire_before_allocation() {
//将当前 TLAB 剩余空间大小加入慢分配浪费空间大小
_slow_refill_waste += (unsigned int)remaining();
//执行 TLAB 退还给堆,这个在后面 GC 的时候还会被调用用于将所有的线程的 TLAB 退回堆
retire();
}
//对于 TLAB 慢分配,stats 为空
//对于 GC 的时候调用,stats 用于记录每个线程的数据
void ThreadLocalAllocBuffer::retire(ThreadLocalAllocStats* stats) {
if (stats != NULL) {
accumulate_and_reset_statistics(stats);
}
//如果当前 TLAB 有效
if (end() != NULL) {
invariants();
//将用了的空间记录如线程分配对象大小记录
thread()->incr_allocated_bytes(used_bytes());
//填充dummy object
insert_filler();
//清空当前 TLAB 指针
initialize(NULL, NULL, NULL);
}
}
9.4. GC 相关 TLAB 操作
9.4.1. GC 前
不同的 GC 可能实现不一样,但是 TLAB 操作的时机是基本一样的,这里以 G1 GC 为例,在真正 GC 前:
src/hotspot/share/gc/g1/g1CollectedHeap.cpp
void G1CollectedHeap::gc_prologue(bool full) {
//省略其他代码
// Fill TLAB's and such
{
Ticks start = Ticks::now();
//确保堆内存是可以解析的
ensure_parsability(true);
Tickspan dt = Ticks::now() - start;
phase_times()->record_prepare_tlab_time_ms(dt.seconds() * MILLIUNITS);
}
//省略其他代码
}
为何要确保堆内存是可以解析的呢?这样有利于更快速的扫描堆上对象。确保内存可以解析里面做了什么呢?其实主要就是退还每个线程的 TLAB 以及填充 dummy object。
src/hotspot/share/gc/g1/g1CollectedHeap.cpp
void CollectedHeap::ensure_parsability(bool retire_tlabs) {
//真正的 GC 肯定发生在安全点上,这个在后面安全点章节会详细说明
assert(SafepointSynchronize::is_at_safepoint() || !is_init_completed(),
"Should only be called at a safepoint or at start-up");
ThreadLocalAllocStats stats;
for (JavaThreadIteratorWithHandle jtiwh; JavaThread *thread = jtiwh.next();) {
BarrierSet::barrier_set()->make_parsable(thread);
//如果全局启用了 TLAB
if (UseTLAB) {
//如果指定要回收,则回收 TLAB
if (retire_tlabs) {
//回收 TLAB,调用 9.3.2.3. 当前 TLAB 放回堆 提到的 retire 方法
thread->tlab().retire(&stats);
} else {
//当前如果不回收,则将 TLAB 填充 Dummy Object 利于解析
thread->tlab().make_parsable();
}
}
}
stats.publish();
}
9.4.2. GC 后
不同的 GC 可能实现不一样,但是 TLAB 操作的时机是基本一样的,这里以 G1 GC 为例,在 GC 后:
src/hotspot/share/gc/g1/g1CollectedHeap.cpp
_desired_size是什么时候变得呢?怎么变得呢?
void G1CollectedHeap::gc_epilogue(bool full) {
//省略其他代码
resize_all_tlabs();
}
src/hotspot/share/gc/shared/collectedHeap.cpp
void CollectedHeap::resize_all_tlabs() {
//需要在安全点,GC 会处于安全点的
assert(SafepointSynchronize::is_at_safepoint() || !is_init_completed(),
"Should only resize tlabs at safepoint");
//如果 UseTLAB 和 ResizeTLAB 都是打开的(默认就是打开的)
if (UseTLAB && ResizeTLAB) {
for (JavaThreadIteratorWithHandle jtiwh; JavaThread *thread = jtiwh.next(); ) {
//重新计算每个线程 TLAB 期望大小
thread->tlab().resize();
}
}
}
重新计算每个线程 TLAB 期望大小:
src/hotspot/share/gc/shared/threadLocalAllocBuffer.cpp
void ThreadLocalAllocBuffer::resize() {
assert(ResizeTLAB, "Should not call this otherwise");
//根据 _allocation_fraction 这个 EMA 采集得出平均数乘以Eden区大小,得出 TLAB 当前预测占用内存比例
size_t alloc = (size_t)(_allocation_fraction.average() *
(Universe::heap()->tlab_capacity(thread()) / HeapWordSize));
//除以目标 refill 次数就是新的 TLAB 大小,和初始化时候的计算方法差不多
size_t new_size = alloc / _target_refills;
//保证在 min_size 还有 max_size 之间
new_size = clamp(new_size, min_size(), max_size());
size_t aligned_new_size = align_object_size(new_size);
log_trace(gc, tlab)("TLAB new size: thread: " INTPTR_FORMAT " [id: %2d]"
" refills %d alloc: %8.6f desired_size: " SIZE_FORMAT " -> " SIZE_FORMAT,
p2i(thread()), thread()->osthread()->thread_id(),
_target_refills, _allocation_fraction.average(), desired_size(), aligned_new_size);
//设置新的 TLAB 大小
set_desired_size(aligned_new_size);
//重置 TLAB 最大浪费空间
set_refill_waste_limit(initial_refill_waste_limit());
}
10. TLAB 流程常见问题 Q&A
这里我会持续更新的,解决大家的各种疑问
10.1. 为何 TLAB 在退还给堆的时候需要填充 dummy object
主要保证 GC 的时候扫描高效。由于 TLAB 仅线程内知道哪些被分配了,在 GC 扫描发生时返回 Eden 区,如果不填充的话,外部并不知道哪一部分被使用哪一部分没有,需要做额外的检查,如果填充已经确认会被回收的对象,也就是 dummy object, GC 会直接标记之后跳过这块内存,增加扫描效率。反正这块内存已经属于 TLAB,其他线程在下次扫描结束前是无法使用的。这个 dummy object 就是 int 数组。为了一定能有填充 dummy object 的空间,一般 TLAB 大小都会预留一个 dummy object 的 header 的空间,也是一个 int[] 的 header,所以 TLAB 的大小不能超过int 数组的最大大小,否则无法用 dummy object 填满未使用的空间。
10.2. 为何 TLAB 需要最大浪费空间限制
当重新分配一个 TLAB 的时候,原有的 TLAB 可能还有空间剩余。原有的 TLAB 被退回堆之前,需要填充好 dummy object。这样导致这块内存无法分配对象,所示被称为“浪费”。如果不限制,遇到 TLAB 剩余空间不足的情况就会重新申请,导致分配效率降低,大部分空间被 dummy object 占满了,导致 GC 更加频繁。
10.3. 为何 TLAB 重填次数配置 等于 100 / (2 * TLABWasteTargetPercent)
TLABWasteTargetPercent 描述了初始最大浪费空间配置占 TLAB 的比例
首先,最理想的情况就是尽量让所有对象在 TLAB 内分配,也就是 TLAB 可能要占满 Eden。
在下次 GC 扫描前,退回 Eden 的内存别的线程是不能用的,因为剩余空间已经填满了 dummy object。所以所有线程使用内存大小就是 下个 epcoh 内会分配对象期望线程个数 * 每个 epoch 内每个线程 refill 次数配置,对象一般都在 Eden 区由某个线程分配,也就所有线程使用内存大小就最好是整个 Eden。但是这种情况太过于理想,总会有内存被填充了 dummy object而造成了浪费,因为 GC 扫描随时可能发生。假设平均下来,GC 扫描的时候,每个线程当前的 TLAB 都有一半的内存被浪费,这个每个线程使用内存的浪费的百分比率(也就是 TLABWasteTargetPercent),也就是等于(注意,仅最新的那个 TLAB 有浪费,之前 refill 退回的假设是没有浪费的):
1/2 * (每个 epoch 内每个线程期望 refill 次数) * 100
那么每个 epoch 内每个线程 refill 次数配置就等于 50 / TLABWasteTargetPercent, 默认也就是 50 次。
10.4. 为何考虑 ZeroTLAB
当分配出来 TLAB 之后,根据 ZeroTLAB 配置,决定是否将每个字节赋 0。在 TLAB 申请时,由于申请 TLAB 都发生在对象分配的时候,也就是这块内存会立刻被使用,并修改赋值。操作内存,涉及到 CPU 缓存行,如果是多核环境,还会涉及到 CPU 缓存行 false sharing,为了优化,JVM 在这里做了 Allocation Prefetch,简单理解就是分配 TLAB 的时候,会尽量加载这块内存到 CPU 缓存,也就是在分配 TLAB 内存的时候,修改内存是最高效的。
在创建对象的时候,本来也要对每个字段赋初始值,大部分字段初始值都是 0,并且,在 TLAB 返还到堆时,剩余空间填充的也是 int[] 数组,里面都是 0。
所以,TLAB 刚分配出来的时候,赋 0 避免了后续再赋 0。也能利用好 Allocation prefetch 的机制适应 CPU 缓存行(Allocation prefetch 的机制详情会在另一个系列说明)
10.5. 为何 JVM 需要预热,为什么 Java 代码越执行越快(这里只提 TLAB 相关的,JIT,MetaSpace,GC等等其他系列会说)
根据之前的分析,每个线程的 TLAB 的大小,会根据线程分配的特性,不断变化并趋于稳定,大小主要是由分配比例 EMA 决定,但是这个采集是需要一定运行次数的。并且 EMA 的前 100 次采集默认是不够稳定的,所以 TLAB 大小也在程序一开始的时候变化频繁。当程序线程趋于稳定,运行一段时间后, 每个线程 TLAB 大小也会趋于稳定并且调整到最适合这个线程对象分配特性的大小。这样,就更接近最理想的只有 Eden 区满了才会 GC,所有 Eden 区的对象都是通过 TLAB 分配的高效分配情况。这就是 Java 代码越执行越快在 TLAB 方面的原因。



