
记一次Jvm参数调优实战原创
案例一
public class test1 {
private static final int _1MB = 1024 * 1024;
public static void main(String[] args) throws IOException, InterruptedException {
System.out.println("My Process Id is:"+getProcessID());
Thread.sleep(10000);
byte[] all1 = new byte[ 2 * _1MB];
byte[] all2 = new byte[ 2 * _1MB];
Thread.sleep(2000);
byte[] all3 = new byte[ 2 * _1MB];
byte[] all4 = new byte[ 7 * _1MB];
System.in.read();
}
public static int getProcessID() {
RuntimeMXBean runtimeMXBean = ManagementFactory.getRuntimeMXBean();
return Integer.valueOf(runtimeMXBean.getName().split("@")[0])
.intValue();
}
}
注:这里getProcessId的作用是拿到进程号
jvm参数
-Xmx20m // 设置最大堆大小
-Xms20m // 设置最小堆大小,一般和-Xmx一致
-Xmn10m // 设置新生代大小
-XX:+UseParNewGC //表示新生代使用ParNewGc
-XX:+UseConcMarkSweepGC // 表示老年代使用CMS
-XX:+UseCMSInitiatingOccupancyOnly //表示CMS不基于运行时收集数据来进行GC控制
-XX:CMSInitiatingOccupancyFraction=75 //而表示当老年代使用率到达阈值75%时触发
我们这么设置JVM参数,就可以看出一些基本设置:
-
年轻代 10M
-
老年代 10M
-
eden:s0:s1 = 8:1:1
-
新生代使用ParNewGc
-
老年代使用CMS,并只有当老年代使用率超过75的时候触发FullGC
我们先简单看一下这么设置有什么问题:
代码里先创建了 2M的对象,直接放入eden区,再创建了2M的对象,同样也放入eden区,此时eden 有4M的对象,再创建了2M的对象,eden有4M,可以放更多,这2M也放进了eden,最后创建了7M对象,eden区存不下,所以会触发一次young gc,但是剩下的s0,s1已经放不下,所以放入老年代,此时 eden有7M对象,老年代有6M对象,此时年轻代和老年代都有剩下的空间,不会触发GC,但,真的是这样吗?
我们实战看看:,在程序开始时,记录下输出的pid,然后 在程序运行的饿时候在cmd使用 jstat -gcutil pid 1000 ,每一秒输出一次gc信息,看看结果是什么,先在代码上每一处加上sleep为了方便观察
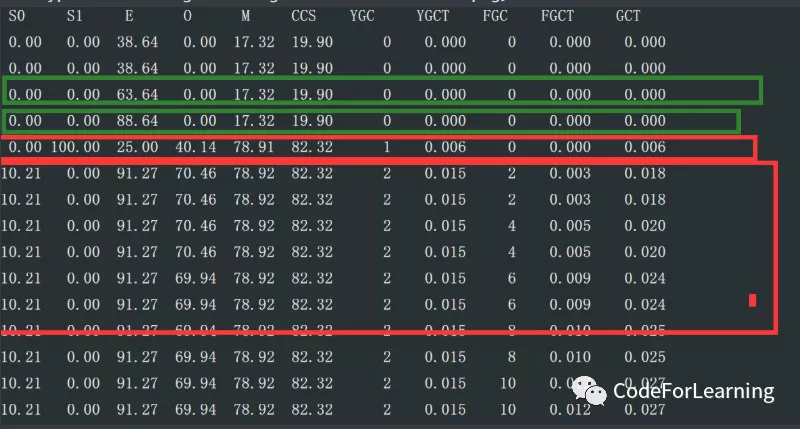
第一个绿线,是第一个2M对象生成,此时eden区使用了63%,6.3M的空间
第二个绿线,是第二个2M对象生成,此时eden区使用了88%,8.8M空间
第三个绿线,是第三个2M对象生成,此时eden区并不足够承载这个2M对象,
此时进行young GC,如图YGC被触发一次,但是现存的4MB对象均不能被回收,且大于S0、S1的空间,所以直接进入老年代,此时老年代有4M的空间,正好是那两个2M的对象,此时Eden区已经可以存放2M,此时eden去和s0一起young gc 可以放入s1的对象即1M左右的零碎对象放入了S1,然后s1、s0名称互换 。
而且,第一次young gc后,消失了部分空间,这即是 “垃圾"", 被回收掉了,但是为什么Metespace区容量暴增呢?
第四个红线,是第四个7M对象生成,eden区并不能存放这个7M的大对象,则需要进行一次younggc,s1中的100%的1M的对象被垃圾回收部分垃圾并放到了s0区,同样此时eden区的2.5M有一个2M的对象,此时没有办法进入s0 s1,所以只能进入老年代,此时老年代占用70%,而eden占用90%,并不具备full gc触发条件,当时full GC被触发,
且每隔两秒被触发一次?这是为什么?
我们再这个jstat上已经无法得出更重要的信息,我们打印GC日志看看,
在启动参数上加上
-XX:+PrintGCDetails // 打印详细日志
-XX:+PrintHeapAtGC // 在GC前后打印堆信息
-XX:+PrintGCDateStamps // 打印时间
我们启动后,看看日志输出:
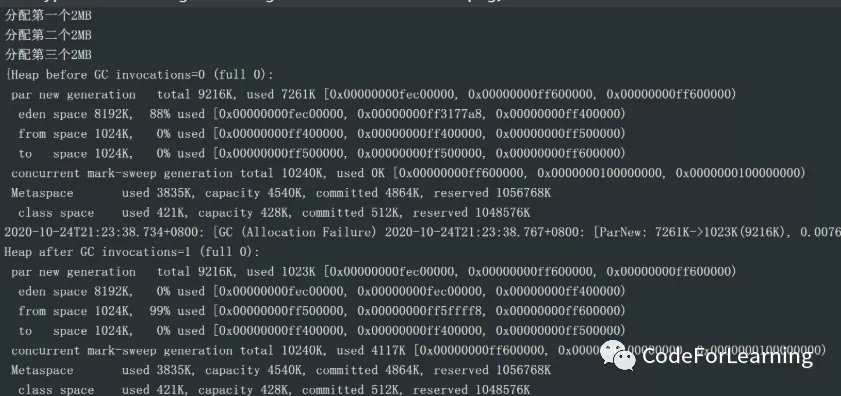
很容易发现,在第三个2MB分配时,进行了一次GC,在GC前堆的信息为:
eden:88%, s0 0%,s1 0% CMS 区0%,元空间区0%,类空间 0%
此时日志里写到 Allocation Failure ,即空间分配失败,然后后面PerNew的空间由 7261k-》1023K,即进行一次young GC,此时年轻代空间总大小为9216K,为啥不是10240k?因为这里算得空间是eden+s1
然后看gc后的堆的空间信息:eden为0,即所有的对象都被移走了,移到哪了?4M的大对象移到了堆,剩下的进行垃圾回收只剩下1023k移入到了from也就是s1区
此时老年代有4117k,即4M的大对象
然后GC后就是分配刚刚的2MB的对象到eden,如下图刚开始就有26%的used,就是这个2MB的对象
然后后面就是分配一个7M的大对象
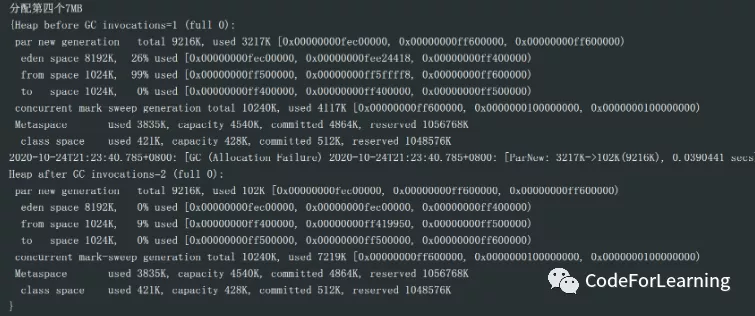
在分配7MB大对象时,进行了一次young GC,同样看GC日志 ,perNew由3217K-》102K 然后看GC后的堆空间情况:eden:0,s1:9%,CMS区 7219k,72%
- 到这里就和上面的jstat的信息保持一致,那么主要关键点在下面
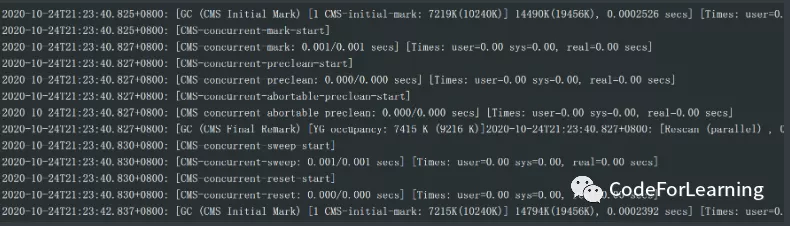
剩下的未截出的都是完全重复的信息
这些记录里记录了什么?
首先是CMS初始标记CMS Initial Mark,此时STW
然后进入并发标记CMS-concurrent-mark-start
并在并发标记中执行并发预清理CMS-concurrent-preclean-start,由于此时并没有对象能被清理,所以此处无效,也没有消耗时间
并发预清理主要做两件事:
处理新生代已经发现的引用
如果老年代中有对象内部引用发生变化,会把所在的Card标记为Dirty
在执行预清理过程中,有个可中断的预清理CMS-concurrent-abortable-preclean-start,这里主要做两件事:
处理 From 和 To 区的对象,标记可达的老年代对象
扫描处理Dirty Card中的对象
最后执行 重新标记Final Remark,STW
然而后面就没有数据了,后面又是重复的进行CMS的扫描,没有执行清理,同样也没有执行Full GC
那么上面的Full GC又是怎么来的呢?
根据资料显示:这是CMS的一个并行收集阶段,只有到达阈值 (75)才进行清除
之前的标记信息都是并行收集阶段,走这一步在JVM监控中识别成了一次Full GC,实则并不是!
破案了,所以这并不是2秒一次Full GC,而是2秒一次CMS的并行搜集!
案例二
同样是上面的例子,例子来源上说当不用CMS时,不会触发,原因是什么?(88当然是没有并行收集这一阶段,直接没有Full gc信息**)
案例三
同样是上面例子,当接着再次生成一个8M的对象,会发生什么?
直接OOM,因为在生成之前,eden最大也8M,存不下这个8M,然后老年代也存不下,直接抛出错误
经测试,大于等于4M的大对象在此时创建,均会OOM
此时为:eden区已经被使用了89%,老年代也被使用了 6817k,完全不足以支撑下个对象,所以OOM
那么这个最大4M是怎么得来的?此时eden只有一个7M的大对象,此时这个7M的大对象并不能放入老年代,所以此时放入堆中的对象只有:小于eden区的剩余空间,1M,或者小于老年代的剩余空间,即4M,所以这个4,就是这么来的
还是看看GC日志把
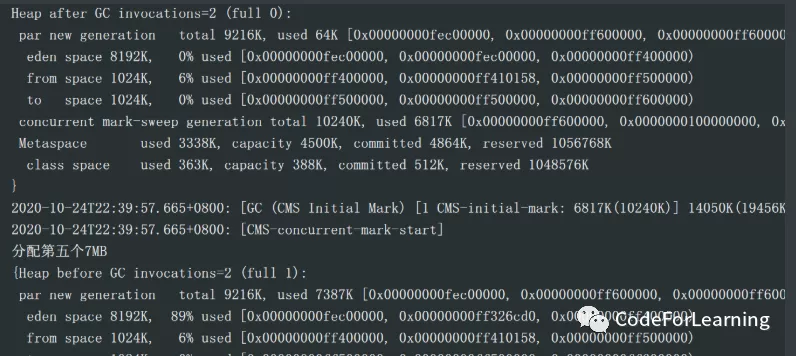
当分配第五个7M的前后,为什么eden区突然有了89%的占用率?其实这就是上一个GC后释放了空间,释放的空间就在GC后显示,然后才是这个第四个7M分配的空间,所以这个89%,就是第4个7M分配的空间
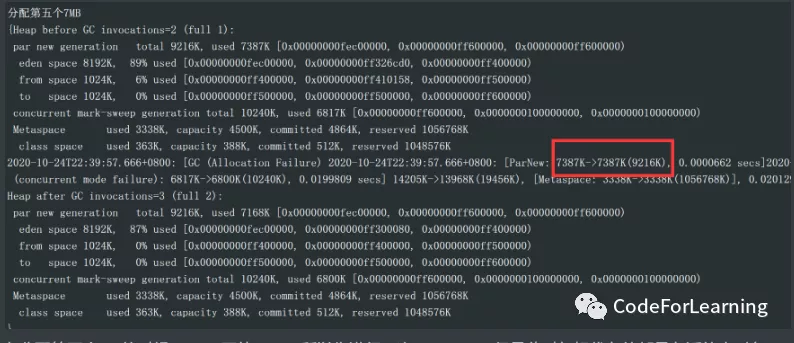
在分配第五个7M的时候,eden区放不下,所以先进行一次young gc,但是此时年轻代存的都是存活的大对象,无法被回收,所以这个年轻代GC并没有回收任何一点垃圾 然后后面再回进行一次GC,即FullGC
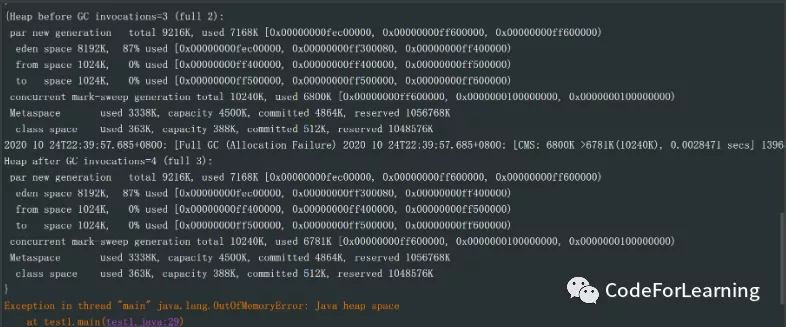
这个FullGC一共回收了俩地方,一个CMS,一个matespace(后面没截出来 此时CMS经过Full GC后仍然有6781K,而matespace就一点没小,所以此时老年代无法分配空间, 这里不youngGC是因为前面已经YoungGC过了, 此时年轻代老年代都不足以分配空间给新对象,所以OOM
案例四
还是上面的例子,如果有两种情况,一种是第4个7M接下来分配一个小于1M的对象,这个对象会被分配到哪?如果是大于2M小于4M呢?
先来分配一个1M的对象(小于当前eden区的剩余空间
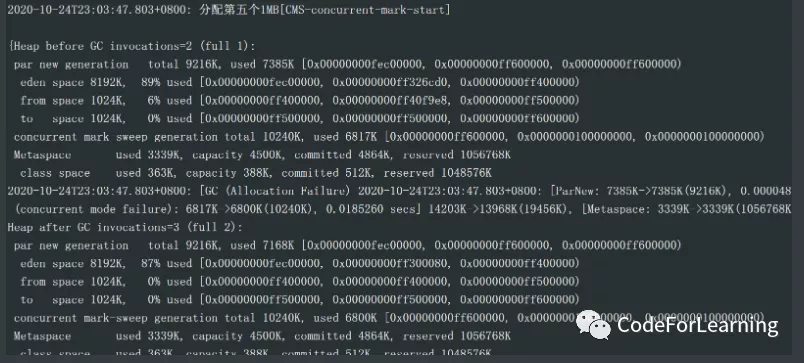
此时eden只有11%的剩余 1.1M,可以承载1M的对象,但是超过了阈值(95)触发young gc
young gc过后,将其放入eden,加上一些空间碎片,此时eden已经100%,再次歘young gc,
此时eden有俩对象,一个7M,一个1M,就只能将1M的对象放入老年代,此时eden占用了90%的空间
我们再来分配一个3M的对象,此时eden同样无法接受3M对象,先执行一次young gc,然后仍然无法存储,但是老年代空间够,所以直接移到老年代去,此时老年代有90%的占用率,但是后面为什么没有触发Ful gc?(这里省略了图)



