Young GC 突刺排查又让我涨知识了!原创
现象
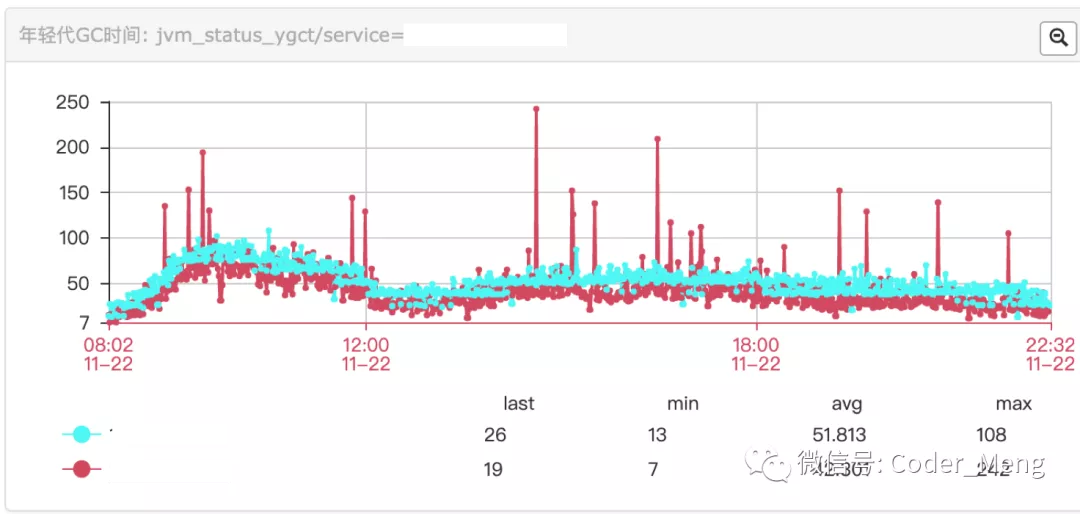
下图是每分钟young gc 所消耗的时间,没有规律的突刺。
年轻代gc 使用的是 ParNew 并发收集。
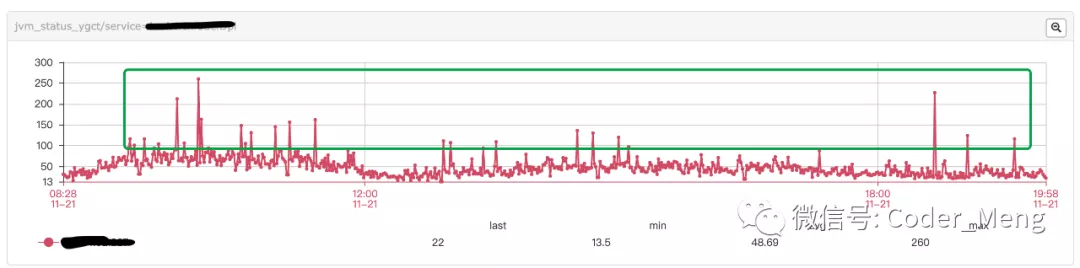
下图是每分钟young gc 的次数,可以看出每分钟gc的频率比较稳定。
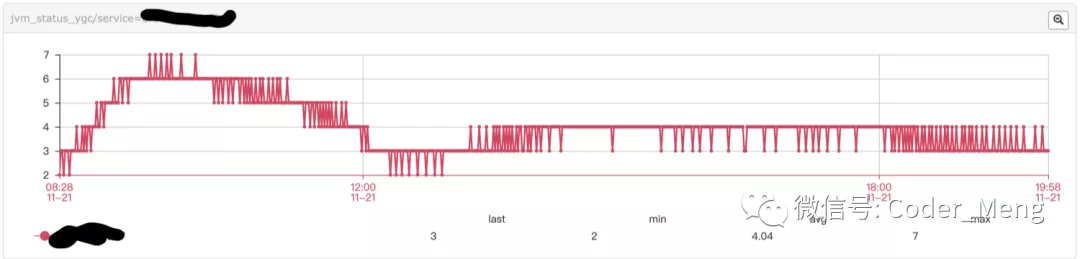
每分钟gc次数没有变化,gc时间增加了,说明某次gc时间变长了。
首先去机器上查看 GC 日志,可以看出年轻代都回收掉了,最后堆大小600多M主要是老年代,但是这里却用了 100ms。
[ParNew: 842033K->2719K(943744K), 0.1051401 secs]
GC后年轻代 822M -> 2.6M
1516408K->677103K(1992320K), 0.1052194 secs]
堆大小 1.4G -> 661M
[Times: user=0.26 sys=0.04, real=0.10 secs]
时间用了 100ms
一般程序有问题,可能是每次GC耗时都比较久,但是这种只是偶尔出现,并且没有规律,检查了代码排除了由于代码写的有问题造成的。
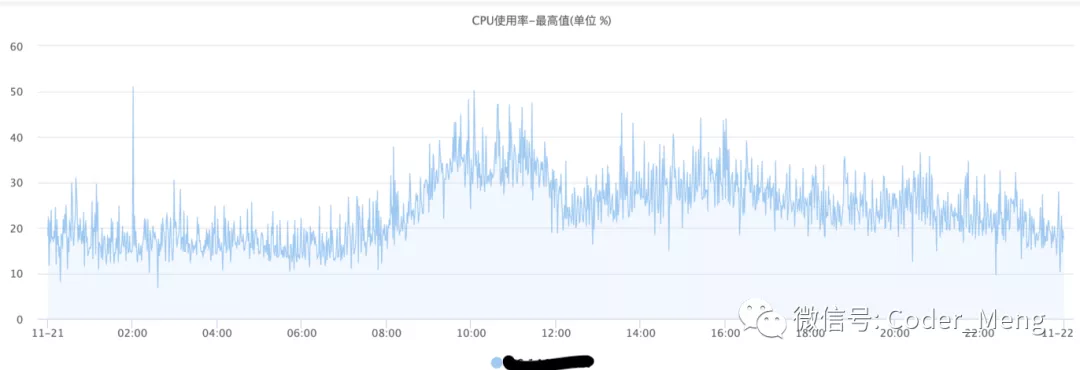
再看看系统的监控。下图是CPU使用率均值,压力不大。
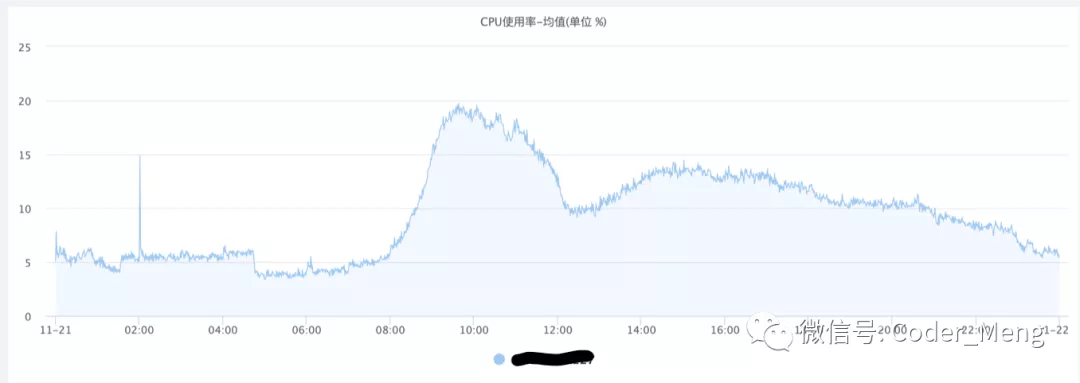
下图是峰值,感觉不太稳定。
排查问题
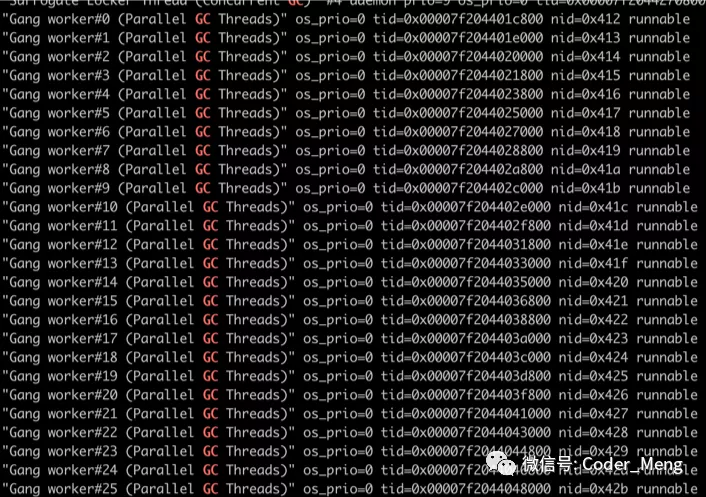
结合 CPU 峰值不太稳定和GC不稳定,我们再去机器上用 jstack 看下 GC 线程数。
$ grep Gang jstack.log | awk '{print $3,$4,$5}' |uniq -c
33 (Parallel GC Threads)"
9 (Parallel CMS Threads)"
这里介绍下背景,程序是在容器中运行的,容器是 4 核 CPU。这里年轻代GC的线程数远远超过了 CPU 的核数。
但是这个数字怎么算出来的呢?我们看下 GC 线程数据的计算规则
cpu 核数小于8 gc 线程数等于cpu核数,大于8的时候=8+(cpu数-8)*5/8
Parallel CMS Thread 并发的GC线程数(ParallelGCThreads+3)/4
这里我们宿主机是 48 核,带入上面的算法,刚好跟查询出来的数据一致。
这个时候我们猜测可能是线程数太多,在 GC 的时候进行了上下文切换,影响的 GC 的响应时间和 CPU 峰值。
验证猜测
根据上面的猜测,通过 jstack 查看线程id,nid线程id,0x412对应10进制1042,后面连续的几个线程 id 都是 GC 线程。
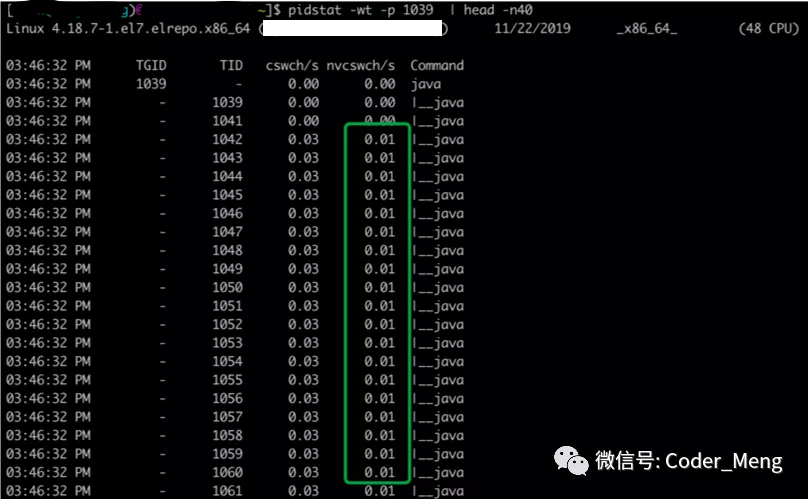
通过pidstat 查看进程下线程的上下文切换情况,自愿和非自愿切换都是非0。非自愿切换说明线程的时间片用完了,导致线程被迫进行了切换。
由于线程的非自愿切换导致 GC 时间受到了影响,然后每分钟 GC 耗时占比并不高所以均值没什么变化,但是对峰值造成了影响。
解决方案
在Docker中通过CGroup来限制内存和CPU,作为一种较新的技术,历史Java版本并不能自然的理解相应的资源限制。这个时候有2种解决方案:
方案一:
明确配置JIT和GC线程数
-XX:ParallelGCThreads
-XX:CICompilerCount
方案二:
JDK 8u191 后的版本可以识别容器的CPU限制,升级容器的JDK版本
升级后的cpu峰值效果对比,可以看到比较稳定。
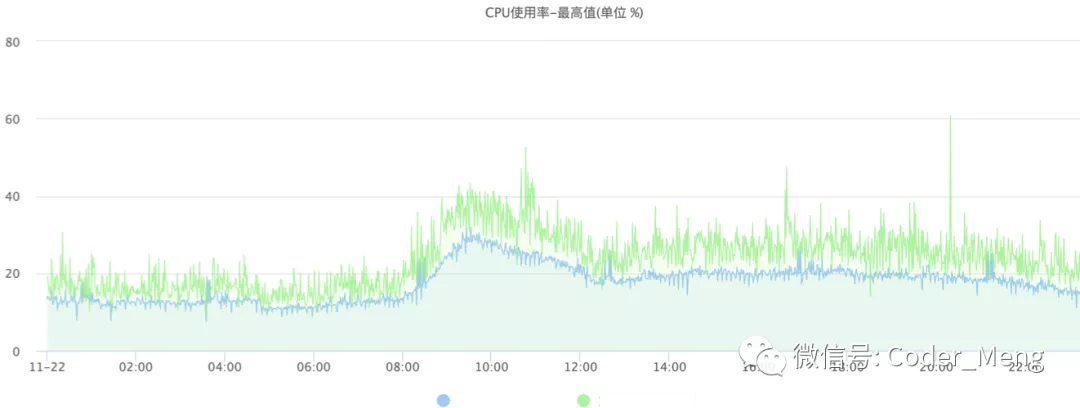
年轻代GC时间也比较稳定。