
记一次堆外内存泄漏排查过程原创
本文涉及以下内容
- 开启NMT查看JVM内存使用情况
- 通过pmap命令查看进程物理内存使用情况
- smaps查看进程内存地址
- gdb命令dump内存块
背景
最近收到运维反馈,说有项目的一个节点的RSS已经是Xmx的两倍多了,因为是ECS机器所以项目可以一直运行,幸亏机器内存充足,不然就可能影响到其他应用了。
排查问题
通过跳板机登录到目标机器,执行top命令,再按c,看到对应的进程所占用的RES有8个多G(这里当时忘记截图了),但是实际上我们配置的Xmx只有3G,而且程序还是正常运行的,所以不会是堆占用了这么多,于是就把问题方向指向了非堆的内存。
首先想到通过Arthas查看内存分布情况,执行dashboard命令,查看内存分布情况
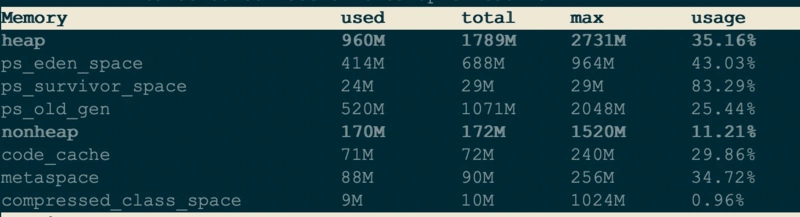
发现堆和非堆的内存加起来也就2个G不到,但是这里看到的非堆只包含了code_cache和metaspace的部分,那有没有可能是其他非堆的部分有问题呢?
NMT
NMT是Native Memory Tracking的缩写,是Java7U40引入的HotSpot新特性,开启后可以通过jcmd命令来对JVM内存使用情况进行跟踪。注意,根据Java官方文档,开启NMT会有5%-10%的性能损耗。
-XX:NativeMemoryTracking=[off | summary | detail]
# off: 默认关闭
# summary: 只统计各个分类的内存使用情况.
# detail: Collect memory usage by individual call sites.
添加-XX:NativeMemoryTracking=detail命令到启动参数中,然后重启项目。
跑了一段时间后top看了下进程的RES,发现已经5个多G了
执行jcmd <pid> VM.native_memory summary scale=MB
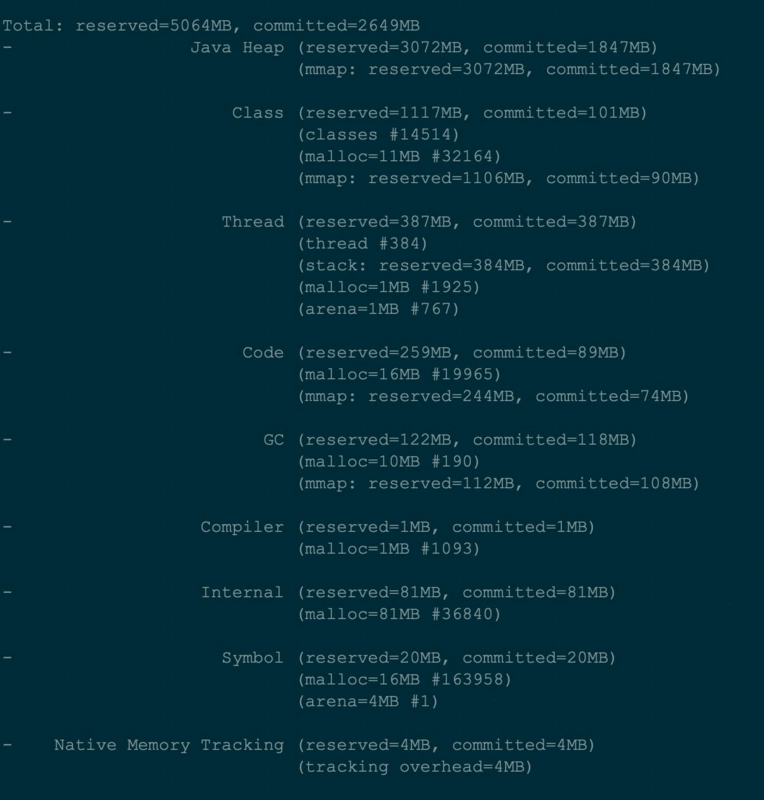
从图中可以看到堆和非堆的总使用内存(committed)也就2G多,那还有3个G的内存去哪里了呢。
pmap
pmap命令是Linux上用来开进程地址空间的
执行pmap -x <pid> | sort -n -k3 > pmap-sorted.txt命令可以根据实际内存排序
查看pmap-sorted.txt文件,发现有大量的64M内存块
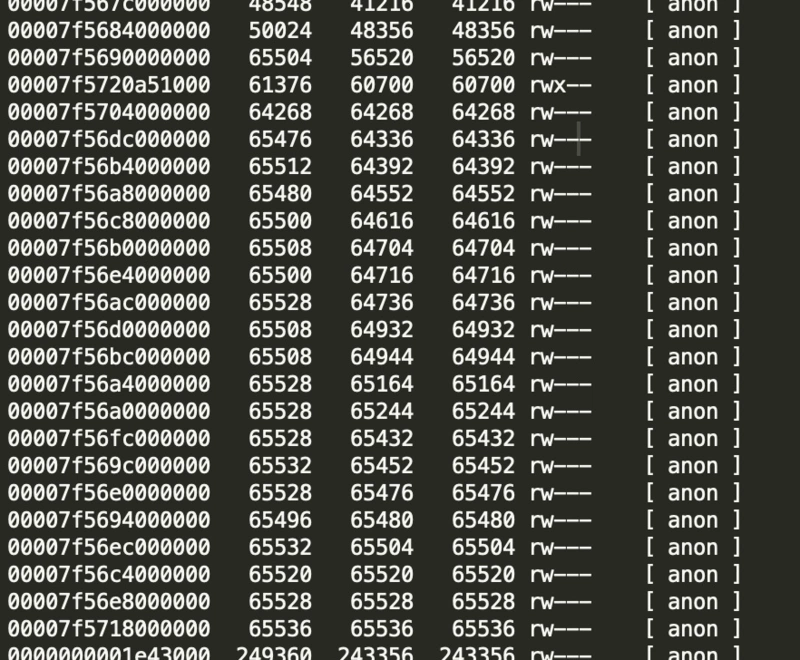
难道是linux glibc 中经典的 64M 内存问题?之前看挖坑的张师傅写过一篇文章(一次 Java 进程 OOM 的排查分析(glibc 篇))讲过这个问题,于是准备参考一下排查思路
尝试设置环境变量MALLOC_ARENA_MAX=1,重启项目,跑了一段时间以后,再次执行pmap命令查看内存情况,发现并没有什么变化,看来并不是这个原因,文章后面的步骤就没有什么参考意义了。
smaps + gdb
既然可以看到有这么多异常的内存块,那有没有办法知道里面存的是什么内容呢,答案是肯定的。经过一番资料查阅,发现可以通过gdb的命令把指定地址范围的内存块dump出来。
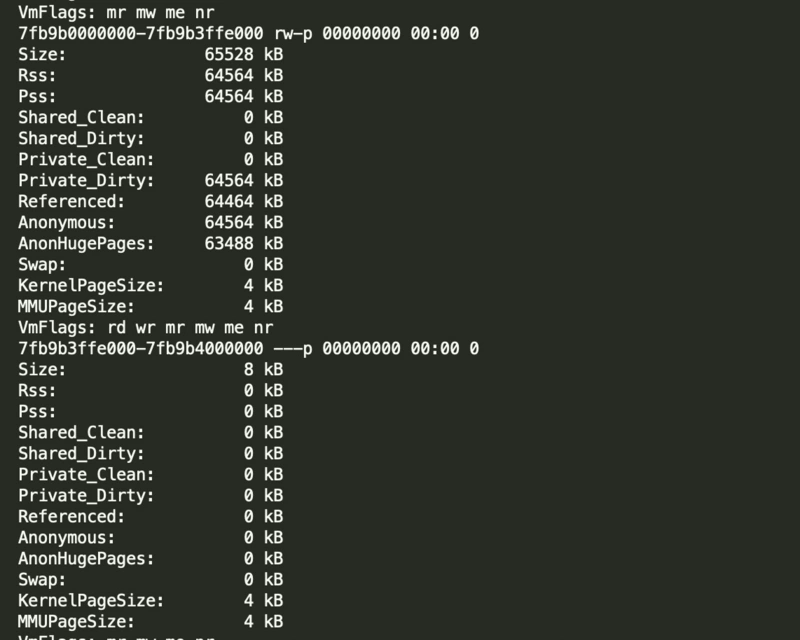
要执行gdb的dump需要先知道一个地址范围,通过smaps可以输出进程使用的内存块详细信息,包括地址范围和来源
cat /proc/<pid>/smaps > smaps.txt
查看smaps.txt,找到有问题的内存块地址,比如下图中的 7fb9b0000000-7fb9b3ffe000
启动gdb
gdb attach <pid>
dump指定内存地址到指定的目录下,参数的地址需要在smaps拿到地址前加上0x
dump memory /tmp/0x7fb9b0000000-0x7fb9b3ffe000.dump 0x7fb9b0000000 0x7fb9b3ffe000
显示长度超过10字符的字符串
strings -10 /tmp/0x7fb9b0000000-0x7fb9b3ffe000.dump
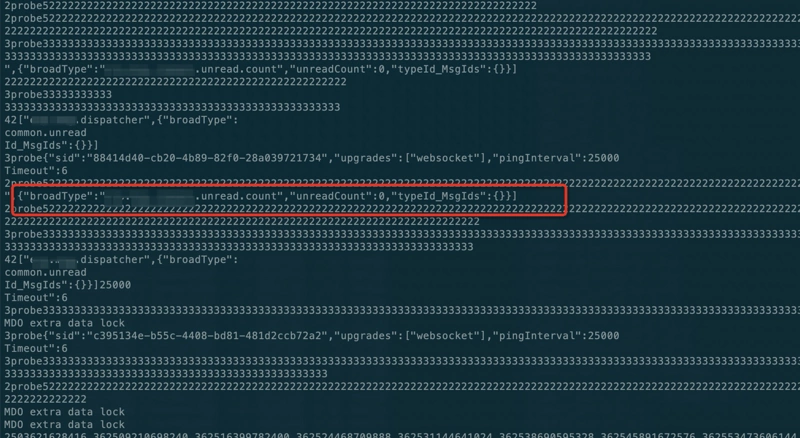
发现里面有大量的图中红框中的内容,这个内容是后端给前端websocket推送的内容,怎么会驻留在堆外内存里面呢?检查了项目代码发现,后端的websocket是使用的netty-socketio实现的,maven依赖为
<dependency>
<groupId>com.corundumstudio.socketio</groupId>
<artifactId>netty-socketio</artifactId>
<version>1.7.12</version>
</dependency>
这是一个开源的socket.io的一个java实现框架,具体可以看
https://github.com/mrniko/netty-socketio
看了下最近的版本发布日志,发现这个框架的最新版本已经是1.7.18,而且中间发布的几个版本多次修复了内存泄漏相关的问题

于是把依赖版本升级到最新版,重新发布后,第二天在看,发现RES还是变得很高
中间又仔细看了使用框架的相关代码,发现断开连接的时候没有调用leaveRoom方法,而是调用了joinRoom,导致群发信息的时候还会往断开的连接里面发送数据(理论上会报错,但是没有看到过相关日志),修复代码后又重新发布了一版,跑了一天在看,依然没有效果。
结论
到这一步可以确认的是内存泄漏的问题肯定跟这个websocket及相关功能有关的(因为中间升级到1.7.18发现websocket连不上了,后来降到了1.7.17,期间有较长的时间是没有暴露websocket服务的,而正好这段时间的RES是非常稳定的,完全没有上涨的趋势,因为这个功能点比较小,用户没有什么感知),最后,经过跟产品方面沟通,决定把这里的websocet去掉,改为前端直接请求接口获取数据,因为这里的功能就是为了实时推送一个未读信息数量,而这个信息其实很少有用户关心,所以,就改成刷新页面的时候查询一下就行了,就这样,问题算是变相解决了😁。至于这个问题的具体原因还是没有找到,可能是框架BUG,也可能是代码使用问题,后面需要重度依赖websocket的时候或许会基于netty自己写一套,这样比较可控一点。
总结
虽然经过这么多的努力,最终只是证明了【没有需求就没有BUG】这句话,但是中间还是有挺多的收获的,很多命令也是第一次使用,中间还有一些曲折,就没有一一写出来了,挑选了一些比较有价值的过程写了这篇文章总结,希望可以分享给有需要的人,以后遇到类似问题,可以做个经验参考。
感谢
这次排查问题从网上查找学习了很多资料,非常感谢以下文章作者分享的经验



