
年轻代频繁ParNew GC,导致http服务rt飙高原创
背景介绍
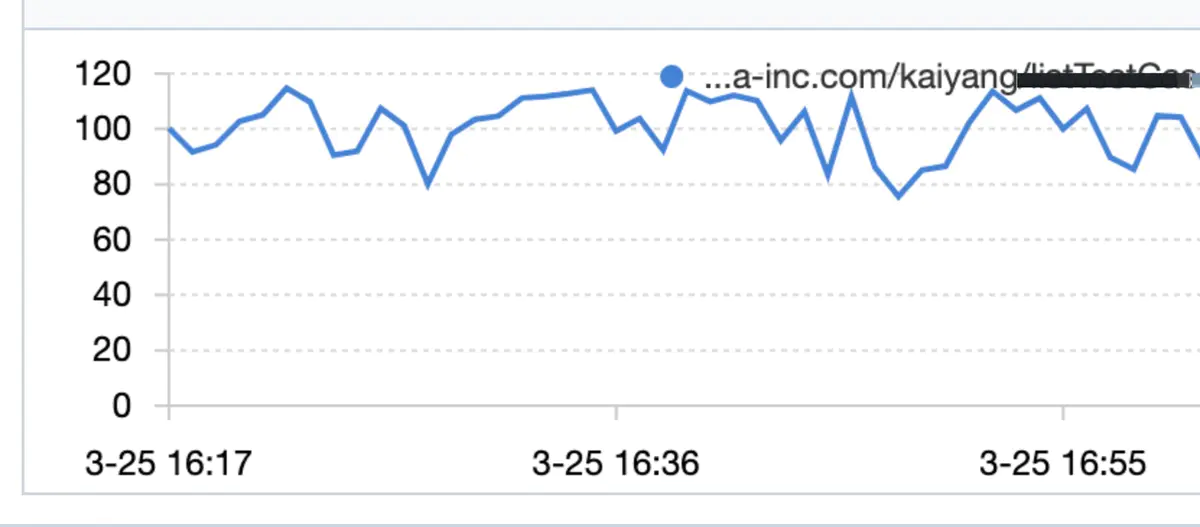
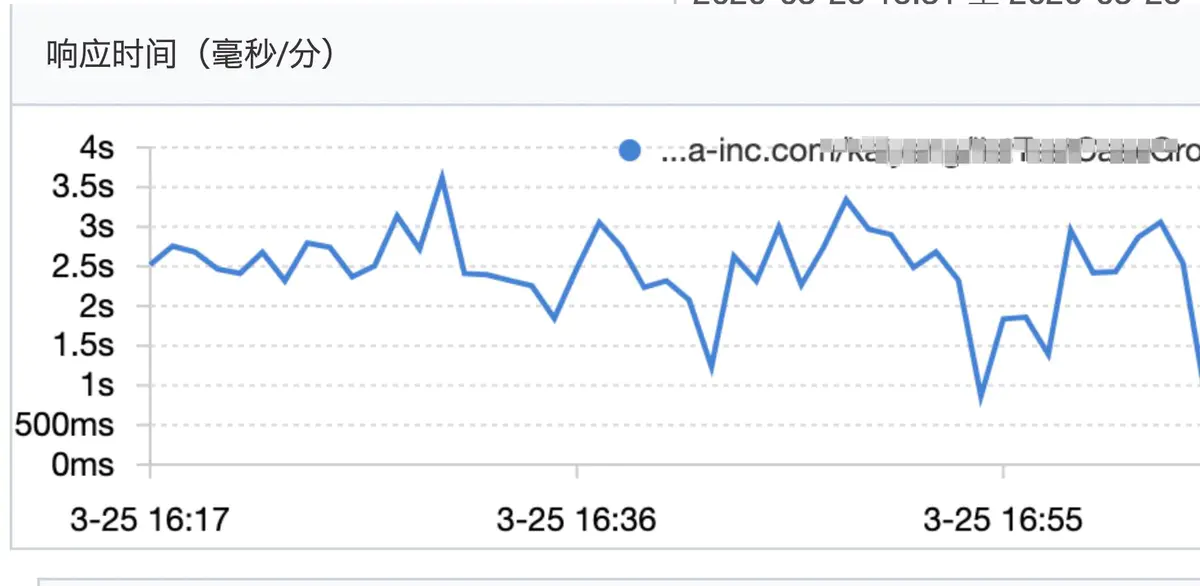
某日下午大约四点多,接到合作方消息,线上环境,我这边维护的某http服务突然大量超时(对方超时时间设置为300ms),我迅速到鹰眼平台开启采样,发现该服务平均QPS到了120左右,平均RT在2秒多到3秒,部分毛刺高达5到6秒(正常时候在60ms左右)。
qps情况:
rt情况
问题解决
该服务是一个对内的运营平台服务(只部署了两台docker)预期qps个位数,近期没做过任何的线上发布,核心操作是整合查询数据库,一次请求最多涉及40次左右的DB查询,最终查询结果为一个多层树形结构,一个响应体大约50K。之前口头跟调用方约定要做缓存,现在看到QPS在120左右,(QPS证明没有做缓存),遂要求对方做缓存,降低QPS。后QPS降到80以内,rt恢复正常(平均60ms),最终QPS一直降到40(后续需要推动调用方上缓存,保证QPS在个位数)。
问题定位
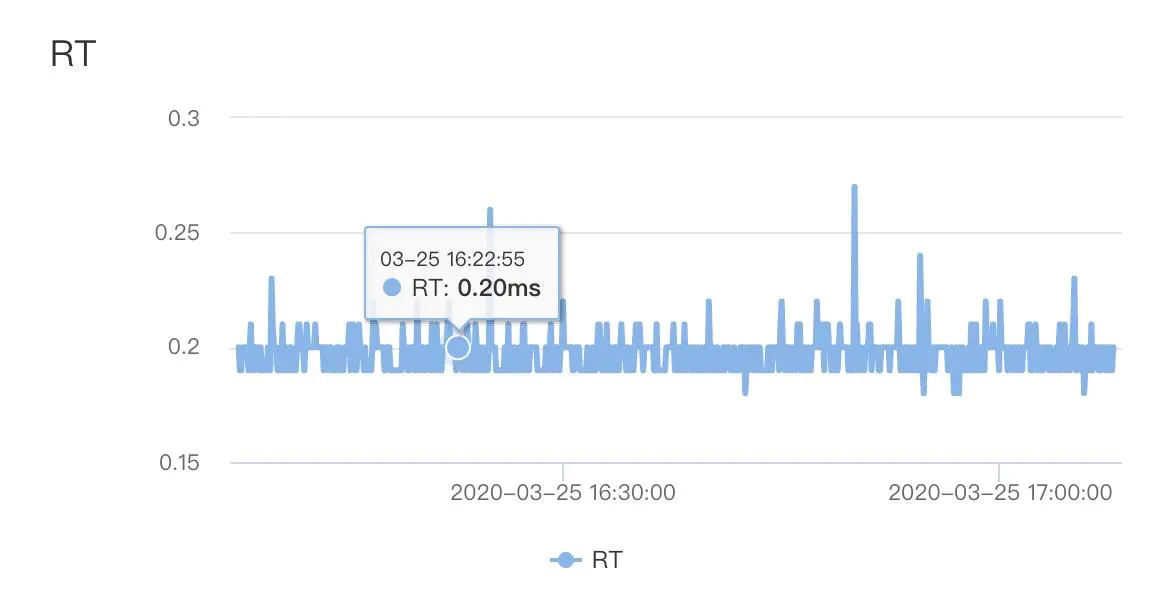
由于该服务核心操作是查询数据库,且一次请求有40次DB query,遂首先排查是否慢sql导致,查看db性能监控,发现db 平均rt在0.3ms以内,可以算出来DB整体耗时在12ms左右,排除慢sql导致RT变高。
开始怀疑,是否DB连接池在高并发下出现排队,tddl默认的连接池大小是10.一查监控,整个占用的连接数从来没有超过7个,排除连接池不足的问题。
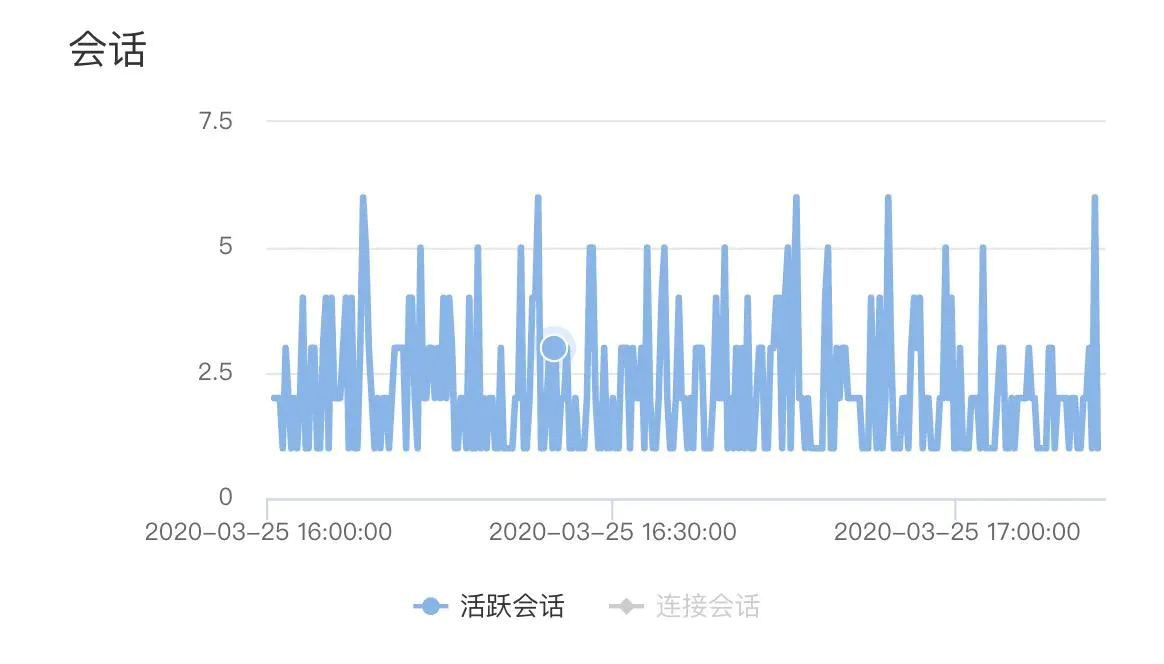
至此,造成RT高的原因,在数据库层面被排除。
接着开始查采样到的服务调用链上的每一个执行点,看看到底是调用链上的那部分耗时最多。发现里面很多执行点都有一个特点,就是本地调用耗时特别长(几百毫秒),但是真正的服务调用(比如db查询动作)时间却很短,(0ms代表执行时间小于1ms,也间接印证之前db的平均RT在0.3ms以内)
本地调用耗时: 267ms
客户端发送请求: 0ms
服务端处理请求: 0ms
客户端收到响应: 1ms
总耗时: 1ms
这时候问题逐渐清晰,问题出现在本地方法执行的耗时过长,可是再次检查该服务所有代码,并没有需要长耗时的本地执行逻辑,那么继续看CPU的load情况。
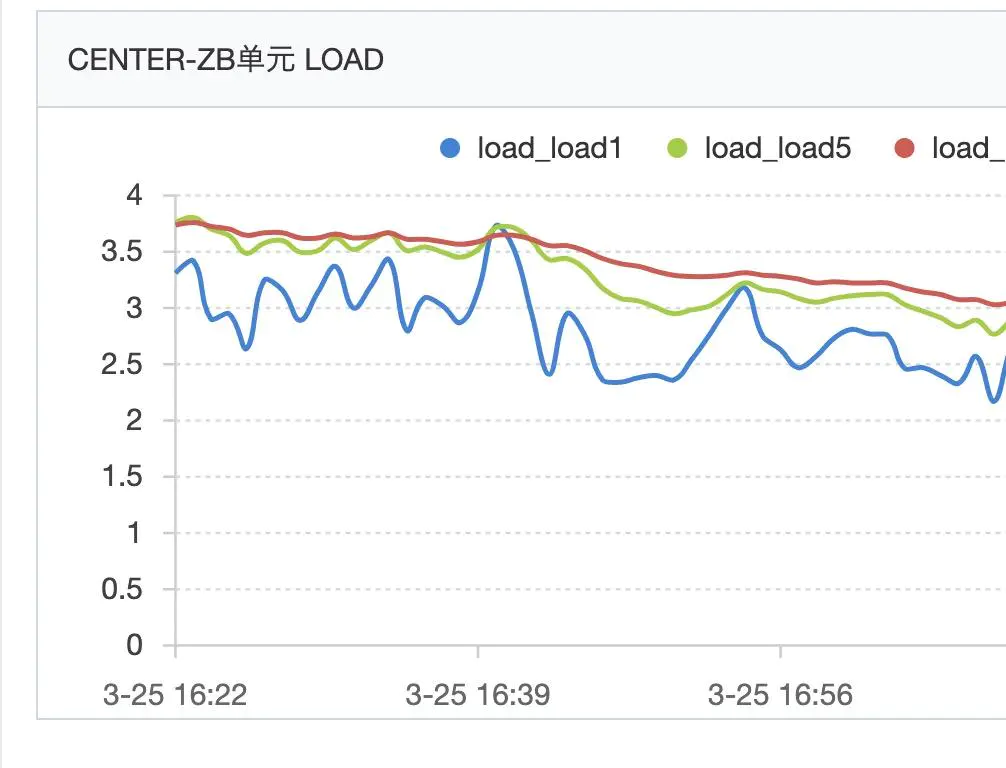
load长时间在4左右徘徊,我们的docker部署在4c8G的宿主机上,但是我们不能独占这个4C的,持续这么高的load已经不正常了。
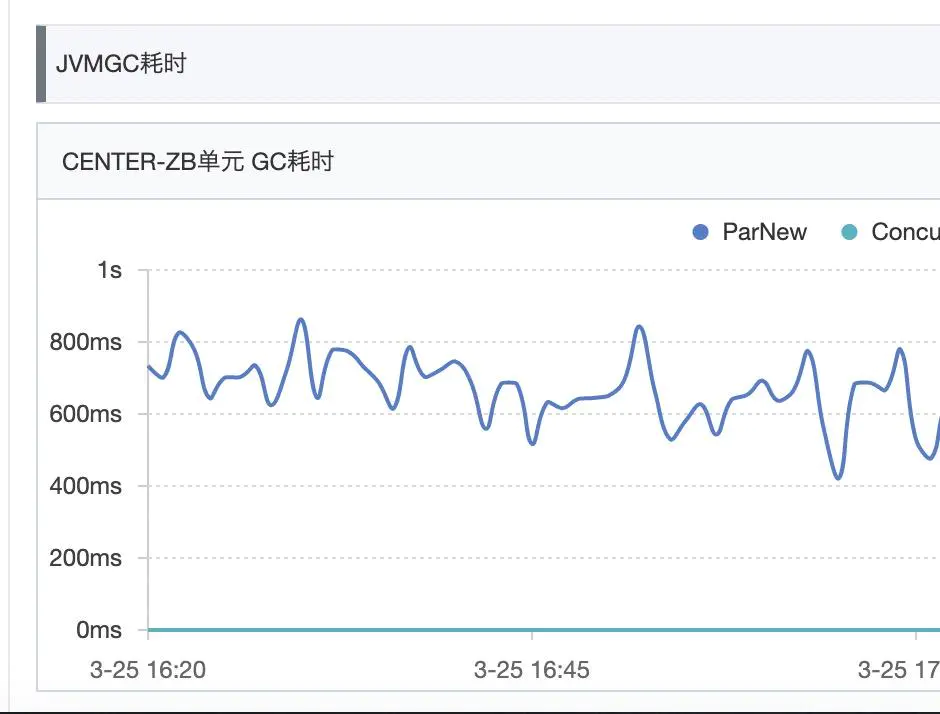
继续追查cpu load飙高的原因,接着去看GC日志,发现大量的Allocation Failure,然后ParNew次数在每分钟100次以上,明显异常,见下GC日志例子
2020-03-25T16:16:18.390+0800: 1294233.934: [GC (Allocation Failure) 2020-03-25T16:16:18.391+0800: 1294233.935: [ParNew: 1770060K->25950K(1922432K), 0.0317141 secs] 2105763K->361653K(4019584K), 0.0323010 secs] [Times: user=0.12 sys=0.00, real=0.04 secs]
每次占用cpu的时间在0.04s左右,但是由于ParNew GC太过频繁,每分钟最高100次以上,整体占用cpu时间还是很可观。
看了下jvm内存参数
Heap Configuration:
MinHeapFreeRatio = 40
MaxHeapFreeRatio = 70
MaxHeapSize = 4294967296 (4096.0MB)
NewSize = 2147483648 (2048.0MB)
MaxNewSize = 2147483648 (2048.0MB)
OldSize = 2147483648 (2048.0MB)
NewRatio = 2
SurvivorRatio = 10
MetaspaceSize = 268435456 (256.0MB)
CompressedClassSpaceSize = 1073741824 (1024.0MB)
MaxMetaspaceSize = 536870912 (512.0MB)
G1HeapRegionSize = 0 (0.0MB)
年轻代分配了2G内存,其中eden区约1.7G
使用jmap查看年轻代对象占用空间情况,排名靠前的有多个org.apache.tomcat.util.buf包下的对象,比如ByteChunk、CharChunk、MessageBytes等,以及响应涉及的一些临时对象列表。其中ByteChunk等即tomcat响应输出相关类
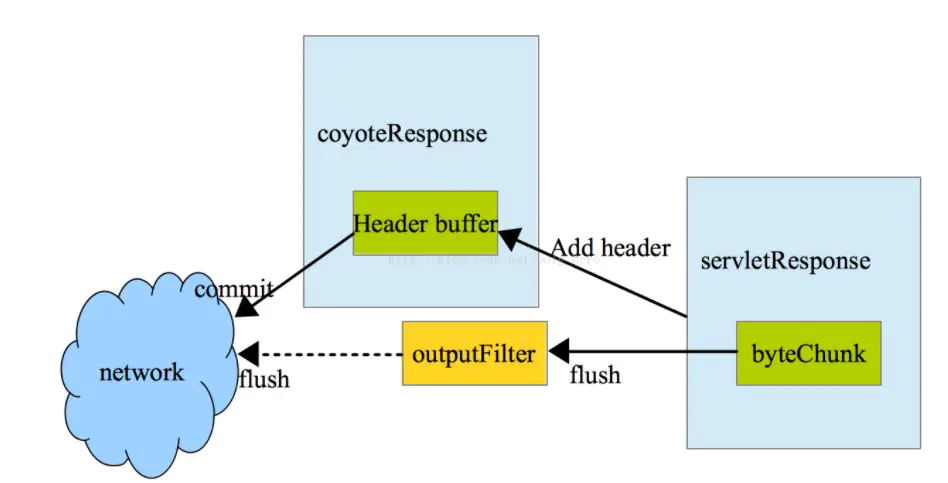
至此问题明确,超大响应包(50K)在发送到网卡的过程中,需要经过从用户态user space拷贝到内核态 kernel space,然后在拷贝到网卡进行发送(像netty等的零拷贝针对的就是这种拷贝),加上响应体查询过程中,涉及的大量临时对象list,在高并发场景下,就导致年轻代内存占满,然后频繁gc(后续在合适的时间会压测该接口),这里还有一个点,很多人以为ParNewGC不会stop the world,其实是会的。频繁ParNewGC造成用户线程进入阻塞状态,让出CPU时间片,最终导致连接处理等待,接口的RT变高。整个排查过程,鹰眼,idb性能监控等可视化监控平台帮助真的很大,否则到处去查日志得查的晕头转向了。
经验总结
- 接口设计,需要避免超大响应体出现,分而治之,将一个大接口拆分为多个小接口。
- 缓存设计,像这个服务一样,一个请求带来将近40次DB查询的,需要考虑在服务端进行缓存(当时偷懒了,要求调用方去做缓存)。
- 性能设计,要对自己负责系统的性能了如指掌,可以通过压测等手段得到自己系统的天花板,否则,某一个接口hang住,会导致整个应用的可用性出现问题。
- 流量隔离,内部应用和外部流量之间,需要进行流量隔离,即使通过缓存,也有缓存击穿的问题。
- 口头说的东西都不靠谱,要落在文档上,还需要检查执行情况。



