记录一次jvm调优过程原创
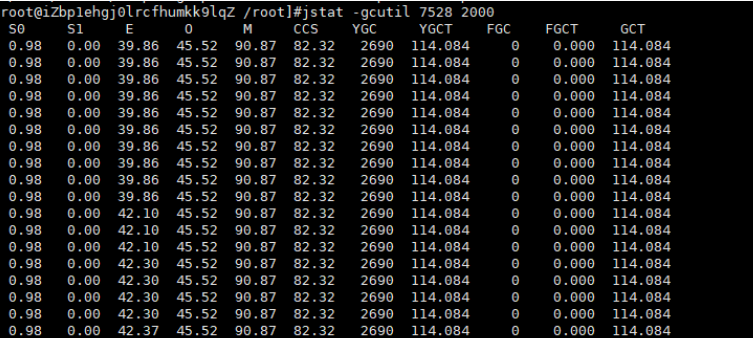
查看gc情况
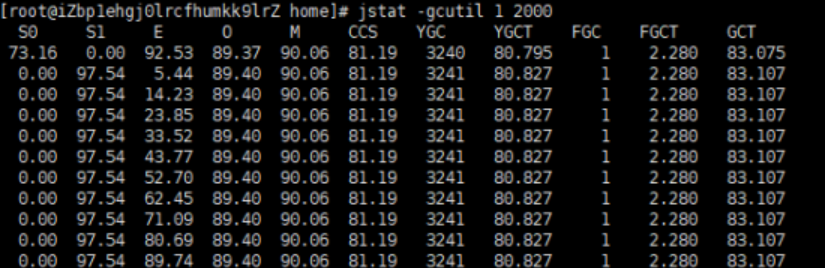

结果:服务启动时长是1天,进行了3240左右次minorGC,一共使用时间80s左右。也就是一次minirGC时间是0.02s,FGC是一次,时间是2.2s,fullGC时间过长,需要优化。
为什么需要优化:
FGC会不会导致请求失败?
查看GC方式是什么:
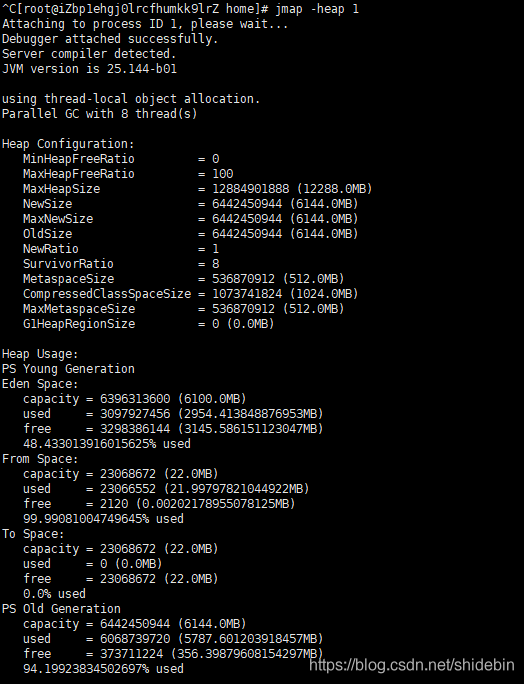
新生代使用的是PS Young Generation回收器,也就是Parallel Scavenge回收器,特点是使用复制算法的多线程serial回收器,跟perNew区别是更注重程序的吞吐量,吞吐量是要尽量保证系统运行时间,减少垃圾回收时间。在回收时会暂停所有的用户线程。老年代使用的是PS Old Generation回收器,也就是Parallel Scavenge的年老代版本,使用的是标记整理算法。其他特点见新生代。
几个名词的解释:
吞吐量与收集器关注点说明
(A)、吞吐量(Throughput)
CPU用于运行用户代码的时间与CPU总消耗时间的比值;
即吞吐量=运行用户代码时间/(运行用户代码时间+垃圾收集时间);
高吞吐量即减少垃圾收集时间,让用户代码获得更长的运行时间;
(B)、垃圾收集器期望的目标(关注点)
(1)、停顿时间
停顿时间越短就适合需要与用户交互的程序;
良好的响应速度能提升用户体验;
(2)、吞吐量
高吞吐量则可以高效率地利用CPU时间,尽快完成运算的任务;
主要适合在后台计算而不需要太多交互的任务;
(3)、覆盖区(Footprint)
在达到前面两个目标的情况下,尽量减少堆的内存空间;
可以获得更好的空间局部性;
通过分析GC回收器可以知道在GC回收时会暂停用户线程,可能会造成短暂的系统不可用。而且我们系统是更注重用户体验的系统,应该更加关注垃圾回收的时间而不是系统吞吐量,
优化思路:
- 新生代回收时间较短不需要优化
- 老年代使用cms回收器或G1回收器
-XX:+UseConcMarkSweepGC :启用cms
-XX:ParallelGCThreads=16 :设置垃圾回收时使用的线程数。默认是8,也可以用命令查询:
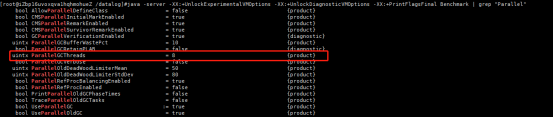
-XX:+CMSScavengeBeforeRemark :强制remark之前开始一次minor gc,减少remark的暂停时间
-XX:+CMSParallelRemarkEnabled :并行remark,减少标记时间
-XX:CMSInitiatingOccupancyFraction :老年代占据多少时进行cms,查看了下默认配置:
java -XX:+UnlockExperimentalVMOptions -XX:+UnlockDiagnosticVMOptions -XX:+PrintFlagsFinal Benchmark | grep "CMSInitiatingOccupancyFraction "

竟然是-1,也就是老年代满了的时候再进行cms,暂时不是很确定,但通过日志看像是的:
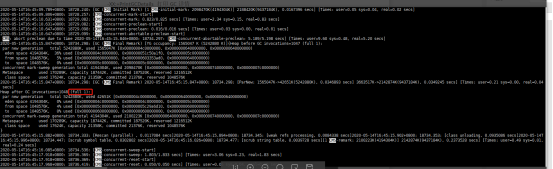
后来得知计算得到_initiating_occupancy=(100-40+80*40/100)/100=92%。也就是说,如果不配置CMSInitiatingOccupancyFraction参数,默认情况下,initiating_occupancy的值就是92%。这种情况是很危险的。有可能导致cms失败:Prommotion failed 和 Concurrent mode failed。
Prommotion failed:这个问题的产生是由于救助空间不够,从而向年老代转移对象,年老代没有足够的空间来容纳这些对象,导致一次full gc的产生。解决这个问题的办法有两种完全相反的倾向:增大救助空间、增大年老代或者去掉救助空间。 增大救助空间就是调整-XX:SurvivorRatio参数,这个参数是Eden区和Survivor区的大小比值,默认是32,也就是说Eden区是 Survivor区的32倍大小,要注意Survivo是有两个区的,因此Surivivor其实占整个young genertation的1/34。调小这个参数将增大survivor区,让对象尽量在survitor区呆长一点,减少进入年老代的对象。去掉救助空 间的想法是让大部分不能马上回收的数据尽快进入年老代,加快年老代的回收频率,减少年老代暴涨的可能性,这个是通过将-XX:SurvivorRatio 设置成比较大的值(比如65536)来做到。在我们的应用中,将young generation设置成256M,这个值相对来说比较大了,而救助空间设置成默认大小(1/34),从压测情况来看,没有出现prommotion failed的现象,年轻代比较大,从GC日志来看,minor gc的时间也在5-20毫秒内,还可以接受,因此暂不调整。
Concurrent mode failed 的产生是由于CMS回收年老代的速度太慢,导致年老代在CMS完成前就被沾满,引起full gc,避免这个现象的产生就是调小-XX:CMSInitiatingOccupancyFraction参数的值,让CMS更早更频繁的触发,降低年老代被沾满的可能。我们的应用暂时负载比较低,在生产环境上年老代的增长非常缓慢,因此暂时设置此参数为80。在压测环境下,这个参数的表现还可以,没有出现过Concurrent mode failed。
G1回收器:
Eden区和survival区比例是否合理
-XX:+PrintTenuringDistribution让JVM在每次MinorGC后打印出Survivor空间中的对象的年龄分布
综上:jvm参数配置参考:
-server -Xms12288m
-Xmx12288m
-XX:NewRatio=2
-XX:SurvivorRatio=4
-XX:MetaspaceSize=1024m
-XX:MaxMetaspaceSize=1024m
-XX:+UseConcMarkSweepGC
-XX:+CMSScavengeBeforeRemark
-XX:+CMSParallelRemarkEnabled
-XX:CMSInitiatingOccupancyFraction=60
-XX:+UseCompressedClassPointers 压缩类指针
-XX:+UseCompressedOops 压缩对象指针
日志相关:
-XX:+PrintTenuringDistribution让JVM在每次MinorGC后打印出Survivor空间中的对象的年龄分布
-XX:+PrintGCDetails
-XX:+PrintGCDateStamps
-XX:+PrintHeapAtGC
-XX:+PrintFlagsFinal
-Xloggc:/datalog/tomcat-gc.log
运行半个月的情况: