
一次jvm调优实战原创
参数对比
调优前
-Dfile.encoding=UTF-8 -J-server -Xms8000M -Xmx8000M -Xmn5000M -J-Xss256K -J-XX:ThreadStackSize=256 -J-XX:StackShadowPages=8 -J-verbosegc -J-XX:+PrintGCDetails -J-XX:+PrintGCTimeStamps -XX:PermSize=128m -XX:MaxPermSize=128m -XX:+UseParallelGC
调优后
-Dfile.encoding=UTF-8 -J-server -Xms10000M -Xmx10000M -Xmn5000M -XX:MaxTenuringThreshold=1 -XX:SurvivorRatio=30 -XX:TargetSurvivorRatio=50 -Xnoclassgc -Xss256K -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:PermSize=256m -XX:MaxPermSize=256m -XX:+UseParNewGC -XX:+UseConcMarkSweepGC -XX:CMSInitiatingOccupancyFraction=80 -XX:ParallelGCThreads=24 -XX:ConcGCThreads=24 -XX:+CMSParallelRemarkEnabled -XX:+CMSScavengeBeforeRemark -XX:+ExplicitGCInvokesConcurrent -XX:+UseTLAB -XX:TLABSize=64K
经验分享
在开始前,我们需要一些数据,因为jvm调优没有一个标准的答案,根据实际应用不同而不同,但也不是完全没有章法可言,从一个实际的应用,我们也可以找出一些规律来,找出一些比较公用的,比如下面三条:
1、应用平均和最大暂停时间(stop the world)
2、吞吐量,真正运行时间/(GC时间+真正运行时间),而相对的GC开销为:GC时间/(GC时间+真正运行时间);
3、URL的请求响应时间
查看可以设置的所有参数
使用-XX:+PrintFlagsFinal参数可以查看当前版本的虚拟机所能设置的所有参数,还可以看到其默认值。我使用6u26版本的java虚拟机,一共有663个参数,很多参数不必完全搞懂什么意思,而且很多优化项在JDK6版本中已经默认开启,所以我们只需要了解一些常用的即可。
最大堆的设置
在单机web server的情况下,最大堆的设置建议在物理内存的1/2到2/3之间,如果是16G的物理内存的话,最大堆的设置应该在8000M-10000M之间,Java进程消耗的总内存肯定大于最大堆设置的内存:堆内存(Xmx)+ 方法区内存(MaxPermSize)+ 栈内存(Xss,包括虚拟机栈和本地方法栈)*线程数 + NIO direct memory + socket缓存区(receive37KB,send25KB)+ JNI代码 + 虚拟机和GC本身 = java的内存。
我们经常碰到内存巨高的线上问题,留更多的内存给“意外情况”是一件好事也是一件坏事,好事是更多的内存可以给“错误”提供扩展空间,提升“容错性”,不至于马上宕机,但另一方面来说技术人员不会第一时间收到“吃swap”这个告警信息。
GC策略的选择
GC调优是JVM调优很重要的一步,当前比较成熟的GC基本上有三种选择,serial、Parallel和CMS,大型互联网应用基本上选择后两种,但Parallel的暂停时间实在太长,以-Xmx8000M -Xmn5000M为例,平均一次youngGC需要100ms-200ms,而FullGC最长需要6s,平均也要4s,虽然当前没有哪种GC策略能完全做到没有暂停时间,但太长的“stop the world”时间也让人无法忍受。
serial 和ParallelGC都是完全stop the world的GC,而CMS分为六步骤:
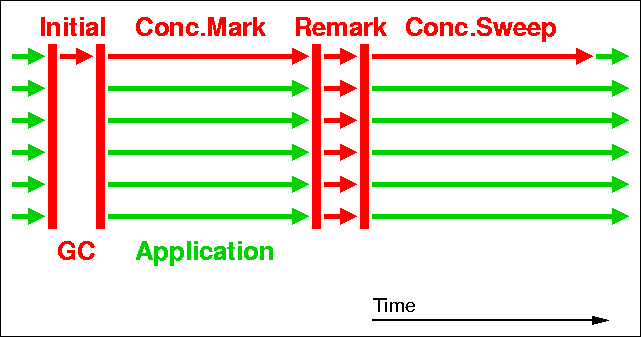
初始标记(stop the world)
1093.220: [GC [1 CMS-initial-mark: 4113308K(5120000K)] 4180786K(10080000K), 0.0732930 secs] [Times: user=0.07 sys=0.00, real=0.07 secs]
运行时标记(并发)
1094.275: [CMS-concurrent-mark: 0.980/0.980 secs] [Times: user=19.95 sys=0.51, real=0.98 secs]
运行时清理(并发)
1094.305: [CMS-concurrent-preclean: 0.028/0.029 secs] [Times: user=0.10 sys=0.02, real=0.03 secs]
CMS: abort preclean due to time 1099.643: [CMS-concurrent-abortable-preclean: 5.288/5.337 secs] [Times: user=12.64 sys=1.19, real=5.34 secs]
第二次标记(stop the world,这个例子remark前执行了一次youngGC)
1099.647: [GC[YG occupancy: 3308479 K (4960000 K)]1099.648: [GC 1099.649: [ParNew: 3308479K->42384K(4960000K), 0.1420310 secs] 7421787K->4180693K(10080000K), 0.1447160 secs] [Times: user=2.69 sys=0.03, real=0.15 secs]
1099.793: [Rescan (parallel) , 0.0121000 secs]1099.805: [weak refs processing, 0.0664790 secs] [1 CMS-remark: 4138308K(5120000K)] 4180693K(10080000K), 0.2254870 secs] [Times: user=3.00 sys=0.05, real=0.23 secs]
运行时清理(并发)
1104.895: [CMS-concurrent-sweep: 4.970/5.020 secs] [Times: user=12.43 sys=1.05, real=5.02 secs]
复原(并发)
1104.908: [CMS-concurrent-reset: 0.012/0.012 secs] [Times: user=0.03 sys=0.01, real=0.01 secs]
要想知道应用真正的停顿时间,可以使用PrintGCApplicationStoppedTime参数:
63043.344: [GC [PSYoungGen: 5009217K->34119K(5049600K)] 5985479K->1034614K(8121600K), 0.1721890 secs] [Times: user=2.62 sys=0.01, real=0.18 secs]
Total time for which application threads were stopped: 0.1806210 seconds
Total time for which application threads were stopped: 0.0074870 seconds
这样看来,真正应用暂停的时间要比stop the world时间还要稍长一点点。
本次调优我基本上放弃了ParallelGC而选择了CMS,CMS在old区很大的时候绝对是个利器,它不仅能大幅降低应用“stop the world”时间,而且还能增加应用的吞吐量。
CMS还有一种增量模式:iCMS,适用于单CPU模式,会将回收动作分作小块进行,但会增加回收时间,降低吞吐量,对于多CPU来说,可以不用考虑这种模式。
从PrintFlagsFinal参数可以得知CMS的UseCMSCompactAtFullCollection和CMSParallelRemarkEnabled参数在JDK6里一直都是默认为true的,所以我们不必显示设置它。从维护角度来看,在设置参数之前,我们应该首先看看这个参数是不是默认已经开启了,如果默认已经开启了我们就不必要再显示设置它。
年轻代(eden和Survivor)、年老代的设置
选择了GC策略之后,年轻代和年老代的设置就很重要了,如果一味的追求响应时间,可以尽量把年轻代调大一点,youngGC的回收频率减小了,但回收时间也增大了,5000M的年轻代,平均回收时间在150+ms,3000M的年轻代平均回收时间在90+ms。
如果一味的增大年轻代,CMS前提下的年老代的威力也发挥不出来,更容易出现promotion failed,导致一次FullGC。但如果一味的调小年轻代,虽然单次回收时间减小,但回收频率会陡增,应用世界暂停时间也会增加,总体年轻代回收的时间也可能会增大,所以调整年轻代和年老代的比例就是一个找平衡的过程。
我的经验是年轻代的比例在2/8到4/8之间,具体情况要看实际应用情况而定。
我们都知道年轻代采用的是“copy”算法,有两个survivor空间,每次回收总有一个是空的,另一个存放的是前几次youngGC存留下来而且还不够提升到old资格的对象,所以有三个参数很重要:
-
-XX:MaxTenuringThreshold=15:对象晋升到old的年龄,parallelGC默认是15,CMS默认是4,设置的越大,对象就越难进入到old区,youngGC反复copy的时间就会增大。
-
-XX:SurvivorRatio=8,eden和survivor的比例,默认是8,也就是说如果eden为2400M,那么两个survivor都为300M,如果MaxTenuringThreshold设置的很小,那么survivor区的使用率就会降低,反之,survivor的使用率就会增大。
-
-XX:TargetSurvivorRatio=80,survivor空间的利用率,默认是50。
如果设置SurvivorRatio为65536,MaxTenuringThreshold为0就表示禁止使用survivor空间,在这种模式下,对象直接进入old区,而且我发现在这种模式下,photo的resin启动时间大大减少,以前170s在这种模式下只需要90+s,足足降低了一半,因为这个,我顿时对这种模式产生的兴趣,但CMS的压力就增大了,威力根本发挥不出来了,GC的时间没有减少反而增加,remark的时间也增大到3s,最后不得不忍痛割爱放弃了这种模式。 -
-XX:+CMSScavengeBeforeRemark这个参数还蛮重要的,它的意思是在执行CMS remark之前进行一次youngGC,这样能有效降低remark的时间,之前我没有加这个参数,remark时间最大能达到3s,加上这个参数之后remark时间减少到1s之内。
另外,在13机器上(参照机器),我发现survivor空间并没有像预期的那样大(eden的1/8),通过跟踪JVM的启动过程中发现,JVM在一定的条件下(可能跟parallelGC和默认SurvivorRatio有关)会动态调整survivor的大小,避免内存浪费。
总结
内存多占1G左右,CPU利用率没有明显变化,但随着CMS收集抖动,最高达40%,CPU load平均高出1.0左右。
几乎0停顿,相比于之前每隔5分钟应用停顿3-4s,调优后的应用几乎没有停顿时间,每次”stop the world”由youngGC引起,最高也不过200+ms。
GC总时间开销显著减小20%多,吞吐量显著提升。
应用超过500ms的请求响应时间减少3%(一小时的观察,可能带有偶然性)



