
一次超诡异的FGC,这个原因找了好久!原创
正撸着代码,公司内的聊天工具弹出一条信息:
“狼哥,我这个机器总是频繁FGC…”
我赶紧打开对话框,机智的回复一个表情
然后继续默默撸码。
随后,小伙伴砸了一段GC日志过来
2019-09-17T20:33:57.889+0800: 4753520.554: [Full GC (Metadata GC Threshold) 4753520.554: [CMS[YG occupancy: 723220 K (1887488 K)]4753520.988: [weak refs process ing, 0.0042134 secs]4753520.992: [class unloading, 0.0987343 secs]4753521.091: [scrub symbol table, 0.0237609 secs]4753521.115: [scrub string table, 0.0025983 s ecs]: 145423K->141376K(3354624K), 0.6260023 secs] 868644K->864597K(5242112K), [Metaspace: 128179K->128179K(1234944K)], 0.6264315 secs] [Times: user=1.24 sys=0.0 0, real=0.63 secs]
4159962 Heap after GC invocations=8029 (full 50):
4159963 par new generation total 1887488K, used 723220K [0x0000000673400000, 0x00000006f3400000, 0x00000006f3400000)
4159964 eden space 1677824K, 42% used [0x0000000673400000, 0x000000069ed59090, 0x00000006d9a80000)
4159965 from space 209664K, 4% used [0x00000006d9a80000, 0x00000006da36c210, 0x00000006e6740000)
4159966 to space 209664K, 0% used [0x00000006e6740000, 0x00000006e6740000, 0x00000006f3400000)
4159967 concurrent mark-sweep generation total 3354624K, used 141376K [0x00000006f3400000, 0x00000007c0000000, 0x00000007c0000000)
4159968 Metaspace used 128145K, capacity 136860K, committed 262144K, reserved 1234944K
4159969 class space used 14443K, capacity 16168K, committed 77312K, reserved 1048576K
4159970 }
4159971 {Heap before GC invocations=8029 (full 50):
4159972 par new generation total 1887488K, used 723220K [0x0000000673400000, 0x00000006f3400000, 0x00000006f3400000)
4159973 eden space 1677824K, 42% used [0x0000000673400000, 0x000000069ed59090, 0x00000006d9a80000)
4159974 from space 209664K, 4% used [0x00000006d9a80000, 0x00000006da36c210, 0x00000006e6740000)
4159975 to space 209664K, 0% used [0x00000006e6740000, 0x00000006e6740000, 0x00000006f3400000)
4159976 concurrent mark-sweep generation total 3354624K, used 141376K [0x00000006f3400000, 0x00000007c0000000, 0x00000007c0000000)
4159977 Metaspace used 128145K, capacity 136860K, committed 262144K, reserved 1234944K
4159978 class space used 14443K, capacity 16168K, committed 77312K, reserved 1048576K
我这慧眼一瞧,看到了几个关键单词Full GC 、Metadata GC Threshold,然后很随意的回复了
是不是metaspace没有设置,或者设置太小,导致了FGC” 外加一个得意的表情
然后,又砸过来一段JVM参数配置
CATALINA_OPTS="$CATALINA_OPTS -server -Djava.awt.headless=true -Xms5324m -Xmx5324m -Xss512k -XX:PermSize=350m -XX:MaxPermSize=350m -XX:MetaspaceSize=256m -XX:MaxMet aspaceSize=256m -XX:NewSize=2048m -XX:MaxNewSize=2048m -XX:SurvivorRatio=8 -XX:MaxTenuringThreshold=9 -XX:+UseConcMarkSweepGC -XX:+UseCMSInitiatingOccupancyOnly -XX :+CMSScavengeBeforeRemark -XX:+ScavengeBeforeFullGC -XX:+UseCMSCompactAtFullCollection -XX:+CMSParallelRemarkEnabled -XX:CMSFullGCsBeforeCompaction=9 -XX:CMSInitiat ingOccupancyFraction=80 -XX:+CMSClassUnloadingEnabled -XX:SoftRefLRUPolicyMSPerMB=0 -XX:-ReduceInitialCardMarks -XX:+CMSPermGenSweepingEnabled -XX:CMSInitiatingPerm OccupancyFraction=80 -XX:+ExplicitGCInvokesConcurrent -Djava.nio.channels.spi.SelectorProvider=[sun.nio.ch](http://sun.nio.ch/).EPollSelectorProvider -Djava.util.logging.manager=org.apac he.juli.ClassLoaderLogManager -XX:+PrintGCDetails -XX:+PrintGCDateStamps -XX:+PrintGCApplicationConcurrentTime -XX:+PrintGCApplicationStoppedTime -XX:+PrintHeapAtGC -Xloggc:/data/applogs/heap_trace.txt -XX:+IgnoreUnrecognizedVMOptions -XX:-HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/data/applogs/HeapDumpOnOutOfMemoryError"
“应该不是,我们配置了-XX:MaxMetaspaceSize=256m -XX:MetaspaceSize=256m”
看到配置之后,有点懵逼,好像超出了我的认知范围,一下子没回复,又扔过来一堆数据。
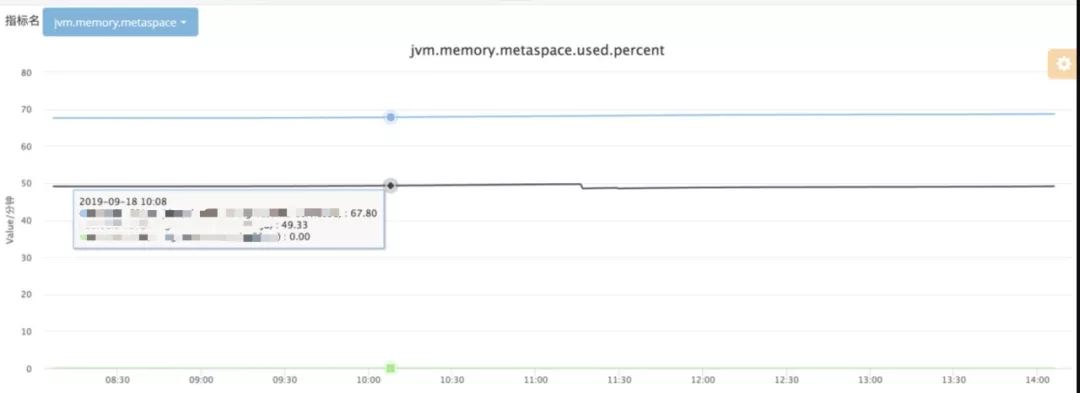
“看cat监控数据,Metaspace使用率在50%的时候就FGC了,GC 日志上的显示也只用了142M,可是我们明明设置了初始值是256M,最大值250M,这还没达到阈值”
机智如我,赶紧回复 “等等,我空的时候再看看”
等空闲下来,我又想起了这个问题,决定好好研究下。
既然是Metadata GC Threshold引起的FGC,那么只可能是MetadataSpace使用完了,我又反复的看了下GC日志片段,盯着下面看了会
[0x00000006f3400000, 0x00000007c0000000, 0x00000007c0000000)
4159977 Metaspace used 128145K, capacity 136860K, committed 262144K, reserved 1234944K
发生FGC之前,Metaspace的committed确实达到了256M,
我们需要知道一点:当目前的committed内存+当前需要分配的内存达到Metaspace阈值,就会发生Metadata GC Threshold的FGC。
看到这里,我们也能大概猜出了,这次FGC是合理的。
但是,为什么used指标只有125M,却还要申请其它内存?
看来只有一个原因可以解释了:内存碎片。
之前只听过老年代因为CMS的标记清理会产生内存碎片导致FGC,为什么Metaspace也会有这样的问题?
让同事对有问题的机器dump了下,用mat打开之后,发现了一个新大陆,包含了大量的类加载器。
** 难道这个碎片问题是大量类加载器引起的?**
本地验证
有了这个疑问,那就简单了,看看能不能在本地复现。
1、先定义一个自定义的类加载器,破坏双亲委派
public class MyClassLoader extends ClassLoader {
@Override
protected Class<?> findClass(String name) throws ClassNotFoundException {
try{
String filePath = "/Users/zhanjun/Desktop/" + name.replace('.', File.separatorChar) + ".class";
//指定读取磁盘上的某个文件夹下的.class文件:
File file = new File(filePath);
FileInputStream fis = new FileInputStream(file);
byte[] bytes = new byte[fis.available()];
fis.read(bytes);
//调用defineClass方法,将字节数组转换成Class对象
Class<?> clazz = this.defineClass(name, bytes, 0, bytes.length);
fis.close();
return clazz;
}catch (FileNotFoundException e){
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
}
return super.findClass(name);
}
}
2、然后在while循环中,不断的 load 已经编译好的class文件
public static void main(String[] args) throws Exception {
while (true) {
Class clazz0 = new MyClassLoader().loadClass("com.sankuai.discover.memory.OOM");
}
}
3、最后,配置一下jvm启动参数
-Xmx2688M -Xms2688M -Xmn960M -XX:MetaspaceSize=50M -XX:MaxMetaspaceSize=100M -XX:+PrintGCDetails -XX:+PrintGCDateStamps -XX:+PrintHeapAtGC -XX:+UseConcMarkSweepGC
启动之后,不一会儿在控制台果然出现了日志
{Heap before GC invocations=0 (full 0):
par new generation total 884736K, used 330302K [0x0000000752400000, 0x000000078e400000, 0x000000078e400000)
eden space 786432K, 42% used [0x0000000752400000, 0x000000076668fae0, 0x0000000782400000)
from space 98304K, 0% used [0x0000000782400000, 0x0000000782400000, 0x0000000788400000)
to space 98304K, 0% used [0x0000000788400000, 0x0000000788400000, 0x000000078e400000)
concurrent mark-sweep generation total 1769472K, used 0K [0x000000078e400000, 0x00000007fa400000, 0x00000007fa400000)
Metaspace used 22636K, capacity 102360K, committed 102400K, reserved 1118208K
class space used 8829K, capacity 33008K, committed 33008K, reserved 1048576K
2019-09-21T16:09:28.562-0800: [Full GC (Metadata GC Threshold) 2019-09-21T16:09:28.562-0800: [CMS: 0K->5029K(1769472K), 0.0987115 secs] 330302K->5029K(2654208K), [Metaspace: 22636K->22636K(1118208K)], 0.1340367 secs] [Times: user=0.11 sys=0.03, real=0.13 secs]
Heap after GC invocations=1 (full 1):
par new generation total 884736K, used 0K [0x0000000752400000, 0x000000078e400000, 0x000000078e400000)
eden space 786432K, 0% used [0x0000000752400000, 0x0000000752400000, 0x0000000782400000)
from space 98304K, 0% used [0x0000000782400000, 0x0000000782400000, 0x0000000788400000)
to space 98304K, 0% used [0x0000000788400000, 0x0000000788400000, 0x000000078e400000)
concurrent mark-sweep generation total 1769472K, used 5029K [0x000000078e400000, 0x00000007fa400000, 0x00000007fa400000)
Metaspace used 2885K, capacity 4500K, committed 43008K, reserved 1058816K
class space used 291K, capacity 388K, committed 33008K, reserved 1048576K
}
从日志可以看出来,发生FGC之前,used大概22M,committed已经达到100M,这时再加载class的时候,需要申请内存,就不够了,只能通过FGC对Metaspace的内存进行整理压缩。
到现在,我们已经验证了过多的类加载器确实可以引起FGC。
内存碎片是怎么产生的?
其实,JVM内部为了实现高效分配,在类加载器第一次加载类的时候,会在Metaspace分配一个独立的内存块,随后该类加载加载的类信息都保存在该内存块。但如果这个类加载器只加载了一个类或者少数类,那这块内存就被浪费了,如果类加载器又特别多,那内存碎片就产生了。


