
不起眼,但是足以让你收获的JVM内存案例原创
今天的这个案例我觉得应该会让你涨姿势吧,不管你对JVM有多熟悉,看到这篇文章,应该还是会有点小惊讶的,不过我觉得这个案例我分享出来,是想表达不管多么奇怪的现象请一定要追究下去,会让你慢慢变得强大起来,我对奇怪现象一直充满好奇,所以你碰到些奇怪的问题也可以发给我,当然最好是JVM相关的
问题
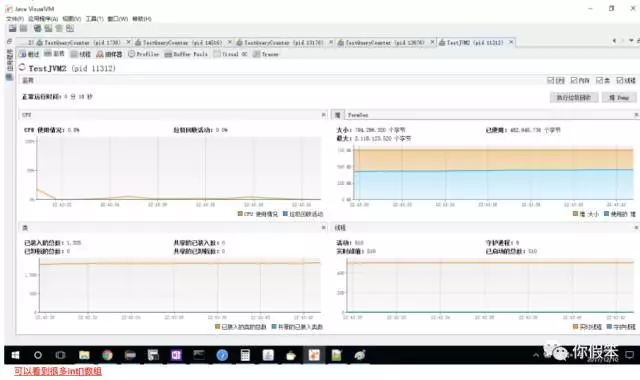
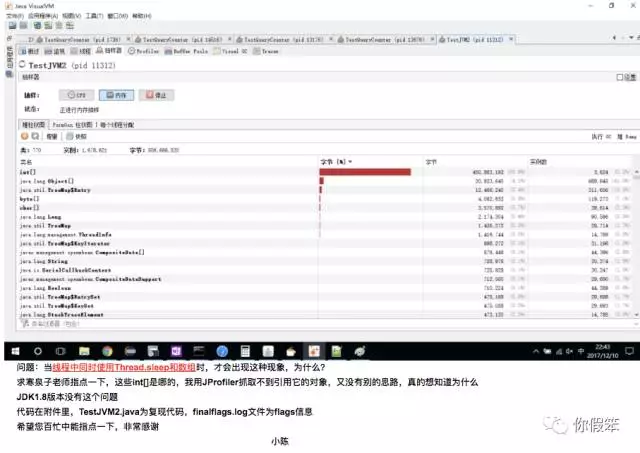
因为编辑比较麻烦,直接以截图的方式发出来吧
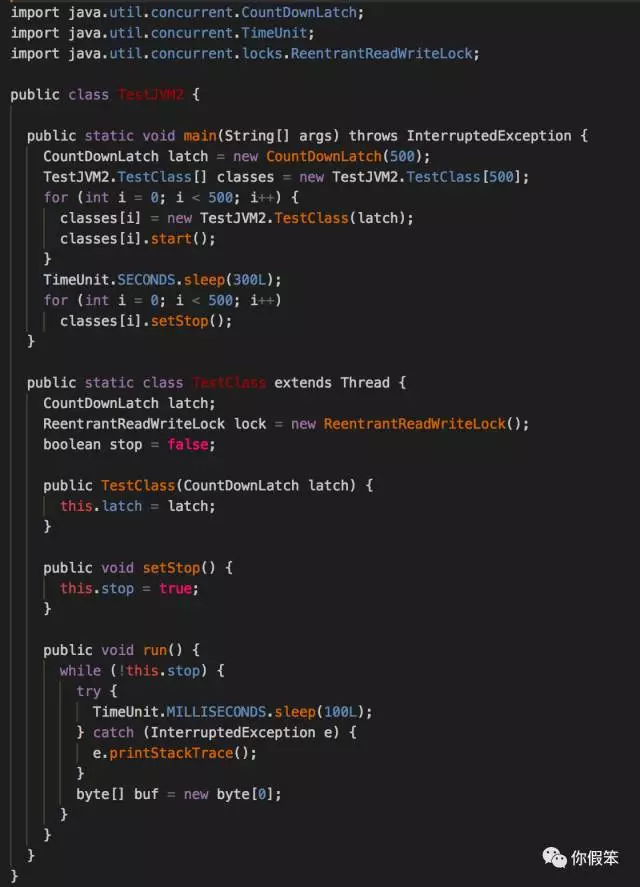
另外附上测试源码:
这个问题描述其实还挺详细的,另外还附上了测试代码,我比较喜欢这种提问题的方式,可以简单模拟出问题来,这样也比较好分析,问题简化是很重要的一步,这样能节省很多时间,有些现象甚至都不用描述太多,很快就能抓住点

分析
简化程序
这个问题说白了,就是说有些int[]对象不知道是哪里来的,于是我拿他的例子跑了跑,好像还真有这么回事,于是我不断简化他的代码,最终发现int[]对象的多少和线程run方法里的最后一个byte数组的创建有一定关系。
初步疑点
我觉得不应该啊,byte数组在内存里明明就是byte数组,和int数组也没半毛钱关系呀,当时突然灵光一闪,这估计是因为jmx通信导致的吧,因为jvisualvm和目标进程通信,传递一些数据也挺正常,因为当时比较忙,于是就回复他了,也许是jmx导致的,要它不要使用visualvm看了,jmx端口也关了,可以通过jmap -histo来确认下。
再次怀疑
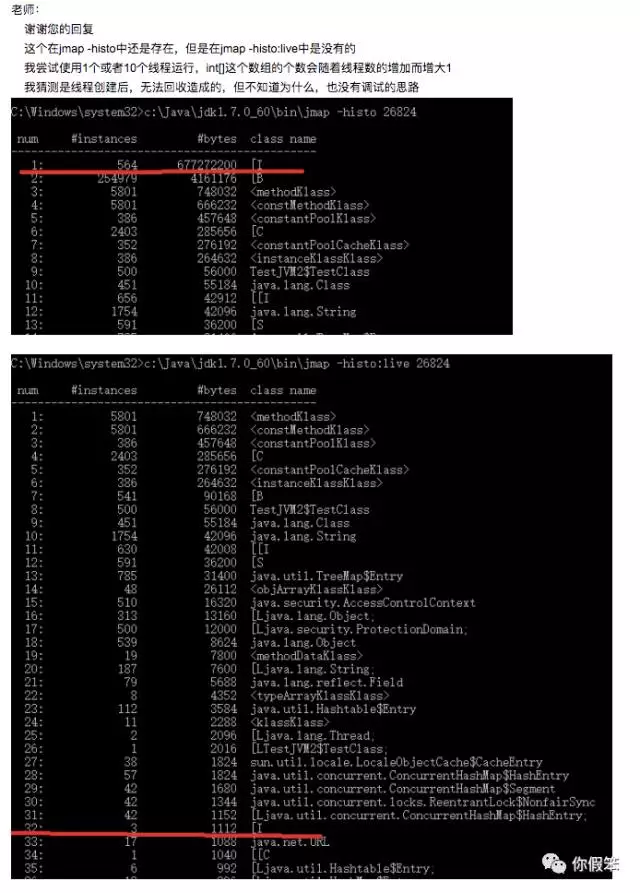
今天突然又收到了该同学的邮件了,他也注意到了和那个byte数组有一定关系
同时他还发现个现象,也就是我要他确认的方式,发现jmap -histo执行的时候,int数组还是比较多,但是加了live参数之后,降下去了,降下去这个比较好解释,因为live参数会做一次fgc的动作,把某些死对象给回收掉了

再次分析
我于是拿它的demo又跑了跑,按照下面的步骤进行操作
- 执行jmap -histo,发现int数组比较多
- 再执行jmap -histo:live,发现int数组降下去了
- 继续执行jmap -histo,int数组又多了点
执行到这里,我就开始怀疑jmap了,难道是因为jmap导致的?于是我开始check jmap的实现,包括JDK和JVM里的逻辑,我要找到哪里可能会创建int数组,JDK层面基本可以忽略,因为实在想不到会有啥逻辑可能会有int数组产生,只是发了个命令给JVM进程而已,于是我重点分析JVM层面的实现,当我们使用jmap做了一次dump的时候或者gc发生的时候都会走到下面的逻辑
因为GC或者内存dump,都必须对内存做一个遍历,因此必须先暂停这些Java线程,防止在遍历内存里的对象的时候进行内存分配,但是每个线程分配内存其实都是优先走tlab(每个线程独有的一块在eden里的小内存块)的,为了能快速遍历对象,而不存在不连续的内存,于是JVM会对tlab做一个填充,填充的正好是int数组对象(从上面代码得知),将剩下的没被分配的tlab内存给填满了,因此在系统运行过程中其实可能伴随着很多无用的对象产生,哈哈,看到这里你是不是豁然开朗?
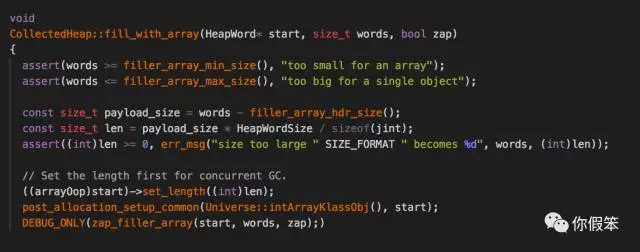
你是否可以解释如下问题了?
- 线程越多,int数组增长越快
- 没有分配byte数组,int数组增长很慢,甚至不增长?
- jmap其实也不是唯一的因素
这个案例还是非常有意思的,上述问题我抛出来给大家,大家可以到下面留言回答上面的问题,如果没人回答或者没有正确的答案,我到时到下面留言补充,看大家的热情度?欢迎大家转发给更多的人。



