
内存泄漏(增长)火焰图原创
正文
当你的应用程序占用的内存不断地提升时,你不得不立即修复它。造成这种情况的原因可能是因为错误配置而导致的内存增长,也可能是因为软件bug引起的内存泄露。无论哪一种,由于垃圾回收机制开始积极响应(消耗CPU),一些应用的性能便会开始下降。一旦某个应用增长得太过庞大,那么其性能会受调页机制(swapping)的影响出现断崖式下降,甚至可能直接被系统kill掉(Linux系统的OOM Killer)。无论是内存泄漏还是内存增长,如果你的应用在扩展,你肯定想先看看其内部发生了什么,说不定其实是个很容易修复的小问题。但关键是你怎样才能做到呢?
在调试增长问题时,不管你是使用应用程序还是系统工具,通常都要检查一下应用配置以及内存使用情况。内存泄漏问题往往更难处理,但好在有一些工具可以提供帮助。一些工具采用对应用程序的malloc调用进行程序插桩(instrumentation)的方式,比如Valgrind memcheck,它还能够模仿一颗CPU,以至于所有的内存访问都能被检测到。但使用该工具通常会导致某个应用程序变慢20-30倍,有时甚至会更慢;另外一个工具是libtcmalloc的堆分析器,使用它能快一点,但应用程序还是会慢5倍以上;还有一类工具(比如gdb工具)会引发core dump,并随后处理它来研究内存使用情况。通常在发生core dump时会要求程序暂停,或者是终止,那么free()例程就会被调用。所以尽管插桩型工具或者core dump技术都能够提供宝贵的细节,但别忘了你此时针对的是一个时刻增长的应用,这种情况下无论哪种工具都很难使用。
本文我会总结一下我在分析(运行时应用的)内存增长和内存泄漏问题时所用到的四种追踪方法。运用这些方法能够得到有关内存使用情况的代码路径,随后我会使用栈追踪技术对代码路径进行检查,并且会以火焰图的形式把它们可视化输出。我将在Linux上演示一下分析过程,随后概述一下其它系统的情况。
四种分析内存增长和内存泄漏问题的方法(已在下图中用绿色字标记):
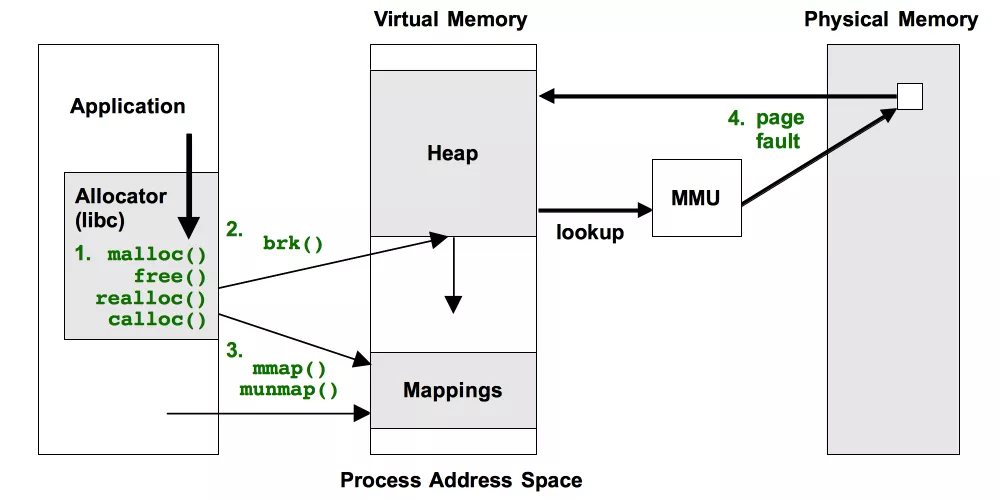
这些方法都有各自的缺陷,我将予以详细解释。
先决条件
下面所有方法都必须保证tracers能够正常地进行栈追踪,这可能需要你事先进行检查,因为栈追踪并不总是能够正常进行。比如现在有很多应用程序在编译的时候都使用了 -fomit-frame-pointer 这个GCC选项,这会使得基于帧指针的栈追踪技术无法使用;像java等一些基于虚拟机的runtime则会进行即时编译,这样tracers(如果不提供额外信息)很可能找不到程序的符号信息,就会导致栈追踪的结果仅仅是一些16进制的数值。还有其他一些陷阱,请参阅我以前基于perf写的栈追踪和JIT符号相关文章。
Linux: perf, eBPF
下面展示的方法是通用的,我将使用Linux作为目标示例,然后概括其他操作系统。
在Linux平台上有很多可以用于分析内存的tracers,这里我选择了perf以及bcc/eBPF这两个标准的Linux tracers,它们都是Linux内核源码的一部分。perf通常在较老的Linux版本上运行(也可在较新的Linux上运行),而eBPF则至少需要Linux 4.8才能进行栈追踪。使用eBPF可以更轻松地概括内核情况,使得栈追踪更加高效并且降低了开销。
1. 追踪分配器函数: malloc(), free(), …
我们开始追踪malloc(),free()等内存分配器函数。设想你用" -p PID"选项在某个进程上运行Valgrind memcheck工具,并收集60秒内其内存泄漏的信息。虽然不完整,但有这些信息已经有希望捕获严重的内存泄漏问题了。即使针对单个进程,运行Valgrind memcheck工具会带来同样的性能下降,甚至比预期下降更多,但是这种损失只有在你需要追踪的时候才会出现,并且只持续很短的一段时间。
分配器函数在虚拟内存上运行,而不是物理(常驻)内存,通常后者才是泄漏检测的目标。不过幸运的是,通常在虚拟内存这一层进行分析,已经离目标(找出问题代码)非常接近了。
我有时也会追踪分配器函数,但是开销很大。这使得追踪分配器函数更像是一种调试手段,而不是一种产品分析的方法。开销很大是因为像malloc()和free()这样的分配器函数在以很高的频率运行(每秒数百万次),哪怕每次只增加一点点开销,算下来整个开销也会增大非常多。但为了解决既存问题,这些都是值得的,它的开销至少比使用Valgrind memcheck或tcmalloc的堆分析工具都要小一些。内核工具eBPF在4.9或更高版本的Linux上更加好用,如果你想自己尝试一下,我想你可以先看看使用eBPF可以解决多少问题。
1.1. Perl的例子
这里有一个用eBPF追踪分配器函数的例子。需要用到stackcount,这是一个我开发的bcc工具,可以简单记录一个特定进程(这里是一个Perl程序)中malloc()库函数被调用的次数,这是通过用户态动态追踪机制uprobe来实现的。
# /usr/share/bcc/tools/stackcount -p 19183 -U c:malloc > out.stacks
^C
# more out.stacks
[...]
__GI___libc_malloc
Perl_sv_grow
Perl_sv_setpvn
Perl_newSVpvn_flags
Perl_pp_split
Perl_runops_standard
S_run_body
perl_run
main
__libc_start_main
[unknown]
23380
__GI___libc_malloc
Perl_sv_grow
Perl_sv_setpvn
Perl_newSVpvn_flags
Perl_pp_split
Perl_runops_standard
S_run_body
perl_run
main
__libc_start_main
[unknown]
65922输出结果显示了追踪的栈以及malloc()调用次数,例如,最后的一次栈追踪导致malloc() 函数被调用了65922次。这全部是在内核上下文中统计的数据,在程序结束时才输出摘要,这样做避免了每次追踪malloc()向用户空间传输数据的开销。我还使用了-U选项,代表仅仅追踪了用户级堆栈,因为我要检测的是用户级函数:libc库中的malloc()。
然后你可以用我写的FlameGraph软件把输出结果(out.stacks)转化成火焰图(out.svg):
$ ./stackcollapse.pl < out.stacks | ./flamegraph.pl --color=mem \
--title="malloc() Flame Graph" --countname="calls" > out.svg现在就可以在一个Web浏览器中打开out.svg了。下图是一个火焰图的例子,将鼠标停留在一个条形块上会自动显示细节,点击就可以放大(如果你的浏览器不支持SVG,请尝试PNG):
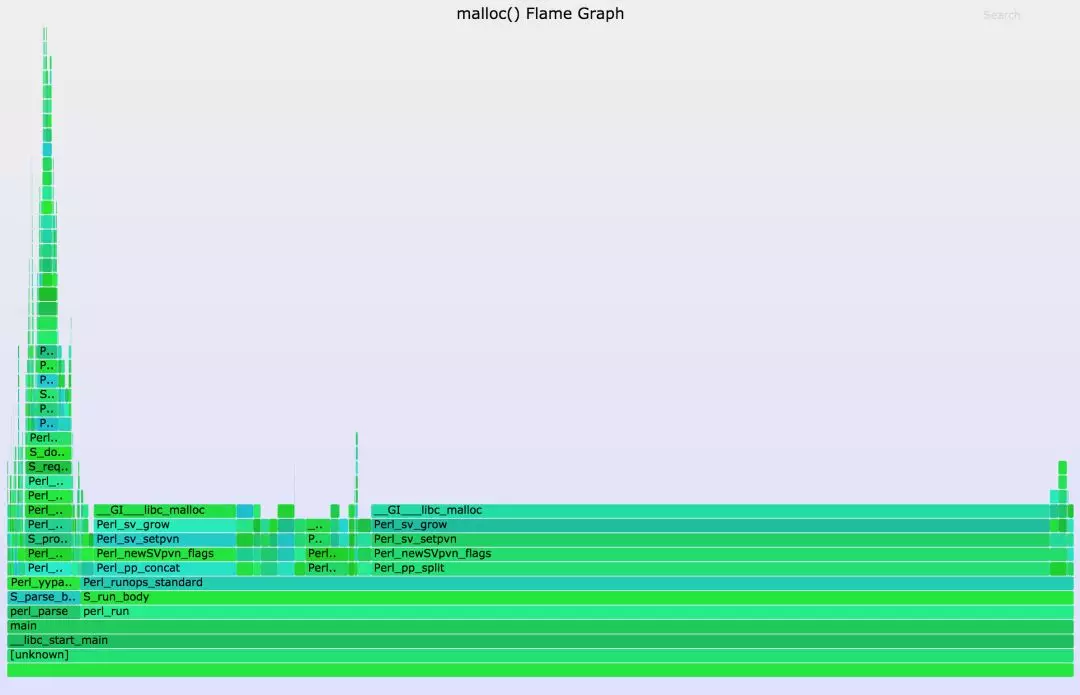
上图表明大多数分配都是通过 Perl_pp_split()路径进行的。(最宽的一个分支)
如果你想自己尝试这种方法,记得最好把所有的分配器函数(malloc()、realloc()、calloc()等)都追踪一遍。不仅如此,你还可以测量每次分配内存的大小,把它加进来取代之前的样本计数,这样火焰图就会显示分配的字节数而不再是函数调用的次数。Sasha Goldshtein已经基于eBPF编写了一个先进的工具,很好地实现了这些功能,其能够以字节数大小的形式追踪那些被分配后长期存留且没有在取样间隔内被释放的内存,用以识别内存泄漏。这个工具是bcc中的memleak:详见示例文件
1.2. MySQL的例子
我将把上面的例子进行一点扩展,这次的场景是一个正在处理某个benchmark负载的MySQL数据库服务器。首先,我们还是使用之前stackcount工具来得到一个malloc()计数火焰图,但这次使用 stackcount-D30,代表持续时间为30秒。得到的火焰图如下:

图示结果告诉我们,malloc()调用次数最多的是在 st_select_lex::optimization() -> JOIN::optimization()这条路径,然而这并不是分配内存最多的地方。
下面这个是malloc()字节火焰图,宽度显示了分配的总字节数:
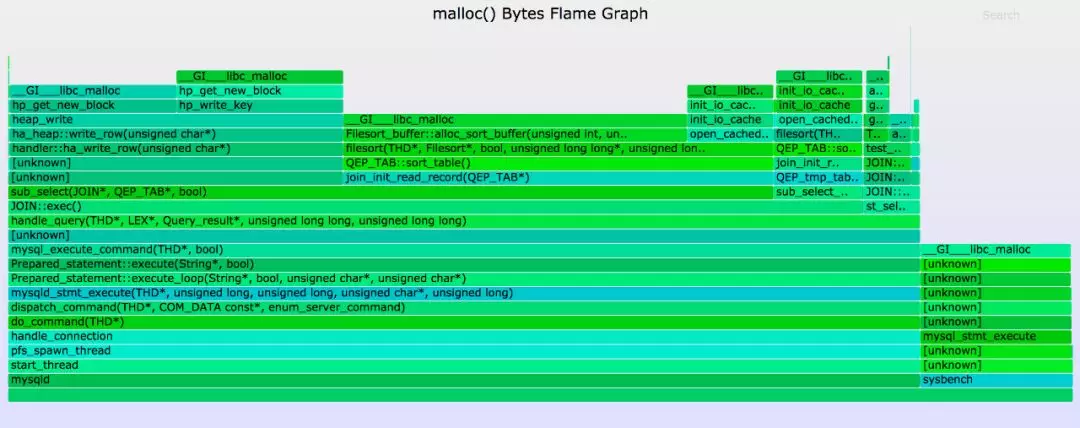
可以看到大部分的字节都是在 JOIN::exec()中分配的,只有少数字节在 JOIN::optimization()中分配。两张火焰图基本上是在同一时间捕获的,保证了两次追踪之间负载不会出现很大的变化,表明这里造成差异的原因是因为一些调用虽然不频繁,但是会比其他调用分配更多内存。
我另行开发了一个mallocstacks工具可以做到这样,它跟stackcount很像,但是不再做堆栈计数,而是以参数 size_t为单位进行统计。下面是在全局追踪malloc()来生成火焰图的步骤:
# ./mallocstacks.py -f 30 > out.stacks
[...copy out.stacks to your local system if desired...]
# git clone https://github.com/brendangregg/FlameGraph
# cd FlameGraph
# ./flamegraph.pl --color=mem --title="malloc() bytes Flame Graph" --countname=bytes < out.stacks > out.svg而这里在生成malloc()字节火焰图以及之前的malloc()计数火焰图时,我多加了一步,目的是让mallocstacks的追踪范围只限定在mysqld和sysbench堆栈(sysbench是MySQL负载生成工具),实际中用命令表示如下:
[...]
# egrep 'mysqld|sysbench' out.stacks | ./flamegraph.pl ... > out.svg由于mallocstack.py(以前使用stackcollapse.pl)的输出格式是一栈一行,这样在生成火焰图之前,可以更方便地添加grep/sed/awk来对数据进行操作。
我的mallocstacks只是一个概念验证(proof-of-concept)工具,只用于追踪malloc()。我还会持续开发这些工具,但比起这个我更关心的是开销问题。
1.3. 警告
警告:从Linux 4.15开始,通过Linux uprobes进行分配器函数追踪的开销增高(在以后的内核中可能会有所改进),即便栈追踪工具使用内核级(即在内核上下文中)计数,但这个Perl程序的运行速度还是慢了4倍(耗时从0.53秒增长到2.14秒),但这至少比libtcmalloc的堆分析要快,后者在运行相同程序时速度慢了6倍。这算是一种最糟糕的情况,原因是Perl程序在初始化期间,malloc()函数频繁运行。在跟踪malloc()时,MySQL服务器的吞吐量下降了33% (CPU已经饱和,没有空闲的余量给tracers)。无论追踪什么,如果样本数量超过一个极小的量(持续几秒),那么在工业级环境中这些开销仍然是无法接受的。
由于开销问题,我会尝试使用其他内存分析方法,后续章节(brk(), mmap(), 缺页中断)会详细描述。
1.4. 其他例子
章亦春(agentzh)基于SystemTap开发了leaks.stp,为了追求效率,leaks.stp仍然在内核上下文中进行摘要。他还生成了一份看起来很不错火焰图,请看这里http://agentzh.org/misc/flamegraph/nginx-memleak-2013-08-05.svg。至此以后,我决定为火焰图新添加一种配色(–color=mem),这样我们就可以区分CPU火焰图(暖色)和内存火焰图(冷色)。
对于内存泄漏检测来说,直接追踪分配器函数或许更有帮助,但是追踪malloc()的开销实在太大,我倾向于一些间接的方法,后续章节我会讲到brk(), mmap(), 缺页中断这些方法,它们是折中的选择,但是开销要小很多。
2. brk()系统调用
很多应用使用brk()来获取内存,brk()系统调用在堆段的尾部(也即进程的数据段)设置断点。brk()不是由应用程序直接调用的,而是提供接口给malloc()/free()这些用户级分配器函数,这些分配器函数通常不会把内存直接返还给系统,而是把释放的内存作为cache以供将来继续分配。因此,brk()通常只等价于增长(而不是收缩),我们即将设想的情景就是这样,这简化了追踪难度。
通常brk()调用频率不高(每秒不多于1000次),这意味着即使我们用perf对每个brk()都进行追踪,也不会明显地降低效率。使用perf测量brk()调用频率的命令如下(这里还是在内核上下文中计数):
# perf stat -e syscalls:sys_enter_brk -I 1000 -a
# time counts unit events
1.000283341 0 syscalls:sys_enter_brk
2.000616435 0 syscalls:sys_enter_brk
3.000923926 0 syscalls:sys_enter_brk
4.001251251 0 syscalls:sys_enter_brk
5.001593364 3 syscalls:sys_enter_brk
6.001923318 0 syscalls:sys_enter_brk
7.002222241 0 syscalls:sys_enter_brk
8.002540272 0 syscalls:sys_enter_brk
[...]由于这是一个服务器,我们看到大部分时间brk()都没有运行,这表明如果你想要得到火焰图,你需要长时间(几分钟)的测量来捕获足够多的样本。
如果你仍然觉得brk()运行频率过低,你可以使用perf的 sampling模式,该模式下将对每个事件都进行dump。下面是用perf采样brk()之后再用FlameGraph生成火焰图的步骤:
# perf record -e syscalls:sys_enter_brk -a -g -- sleep 120
# perf script > out.stacks
[...copy out.stacks to a local system if desired...]
# ./stackcollapse-perf.pl < out.stacks | ./flamegraph.pl --color=mem \
--title="Heap Expansion Flame Graph" --countname="calls" > out.svg我使用了一个“ sleep120”哑命令。由于brk的频率较低,可以将采样时间维持120秒(你也可以增加)来捕获足够多的样本用于分析。
除了perf,在较新的Linux系统上(4.8以上)你还可以使用Linux eBPF。可以通过内核函数Sysbrk()或sysbrk()来追踪brk();4.14以上的内核还可以通过 syscall:sys_enter_brk这个tracepoint实现追踪。这里我将通过内核函数Sys_brk,使用BCC工具stackcount来演示eBPF的追踪步骤:
# /usr/share/bcc/tools/stackcount SyS_brk > out.stacks
[...copy out.stacks to a local system if desired...]
# ./stackcollapse.pl < out.stacks | ./flamegraph.pl --color=mem \
--title="Heap Expansion Flame Graph" --countname="calls" > out.svg下面是部分stackcount输出的结果:
$ cat out.stacks
[...]
sys_brk
entry_SYSCALL_64_fastpath
brk
Perl_do_readline
Perl_pp_readline
Perl_runops_standard
S_run_body
perl_run
main
__libc_start_main
[unknown]
3
sys_brk
entry_SYSCALL_64_fastpath
brk
19输出包括许多追踪到的栈以及相应的brk()调用次数,尽管完整的输出不是特别长,但我还是截取了最后两次的结果。因为brk()不会被频繁调用,并且也没有很多有明显差异的栈(仅当分配时会使当前堆溢出时才会调用brk)。这意味着它的开销非常低,与追踪malloc()/free()导致速度变慢四倍以上相比,追踪brk()的开销可以忽略。
现在给出一个brk火焰图的例子:

通过追踪brk(),我们能够得到导致堆空间扩展的代码路径,可能属于以下其中一种:
-
一条导致内存增长的代码路径
-
一条导致内存泄漏的代码路径
-
一条无辜的代码路径,恰好引发了当前堆空间不足的问题
-
异步分配器函数的代码路径,在可用空间减少时调用
通常需要一番侦察才能明确分辨它们,但有时会很幸运。比如你在特意检查泄漏问题时,很容易发现有一条异常代码路径已经现身在BUG数据库中,它会指向一个已知的泄漏问题。
brk()追踪可以告诉我们是什么导致内存扩展,而后面讲到的缺页中断追踪,则会告诉我们是什么消耗了内存。
3. mmap() syscall
一个应用程序,特别是在其启动和初始化期间,可以显式地使用mmap() 系统调用来加载数据文件或创建各种段,在这个上下文中,我们聚焦于那些比较缓慢的应用增长,这种情况可能是由于分配器函数调用了mmap()而不是brk()造成的。而libc通常用mmap()分配较大的内存,可以使用munmap()将分配的内存返还给系统。
mmap()的调用频率不高,所以用perf追踪每个事件应该是高效的。如果你不确定,可以用之前检查brk()的方法检查一下mmap(),只需把事件替换为 syscall:sys_enter_mmap。使用perf和FlameGraph的步骤:
# perf record -e syscalls:sys_enter_mmap -a -g -- sleep 60
# perf script > out.stacks
[...copy out.stacks to a local system if desired...]
# ./stackcollapse-perf.pl < out.stacks | ./flamegraph.pl --color=mem \
--title="mmap() Flame Graph" --countname="calls" > out.svg当然,在较新的Linux系统上(4.8以上)你还可以使用Linux eBPF。可以通过内核函数Sysmmap()或sysmmap()来追踪mmap();4.14以上的内核还可以通过 syscall:sys_enter_mmap这个tracepoint实现追踪。这里我还是通过内核函数(SyS_mmap),再次使用BCC工具stackcount来演示eBPF的追踪步骤:
# /usr/share/bcc/tools/stackcount SyS_mmap > out.stacks
[...copy out.stacks to a local system if desired...]
# ./stackcollapse.pl < out.stacks | ./flamegraph.pl --color=mem \
--title="mmap() Flame Graph" --countname="calls" > out.svg与brk()不同,调用mmap()并不意味着一定增长,因为它可能马上就被munmap()释放掉了。所以在追踪mmap()时会显示很多新的映射,它们中的大部分(也可能是全部)既不是增长也不是泄漏。如果你的系统经常存在一些短期进程(比如编译一个软件),那么大量的mmap()s就会在这些程序初始化时如洪水般涌来,毁掉你的追踪过程。
与追踪malloc()/ free()一样,你可以观察和联想地址映射的情况,于是就能找到那些没有被free的内存。我将其留给读者作为练习。:-)
与brk()的追踪一样,一旦你找出那些增长的映射(还没有被munmap()释放),它们就可能是如下几种情况之一:
-
一条导致内存增长的代码路径
-
一条映射内存泄漏的代码路径
-
异步分配器函数的代码路径,在可用空间减少时调用
由于mmap()和munmap()调用频率不高,所以这同样是一种低开销的、用于分析增长问题的方法。如果它们调用频率很高(超过每秒1000次),那么开销就会变得非常大,这也表明分配器和应用的设计出了问题。
4. 缺页中断
brk()和mmap()追踪显示的是虚拟内存扩展,随后的写入操作会逐渐消耗物理内存,引起缺页中断并初始化虚拟到物理的映射。这些过程可能在不同的代码路径上发生,一条路径有时可能足以说明问题,有时却可能不太典型,可以通过追踪缺页中断来进一步分析。
对比分配器函数malloc(),缺页中断是一个低频率行为。这意味着开销可以忽略不计,并且你可以用perf对每一个事件进行dump,可以先用perf在一个工业环境系统上检查一下缺页中断的频率:
# perf stat -e page-faults -I 1000 -a
# time counts unit events
1.000257907 534 page-faults
2.000581953 440 page-faults
3.000886622 457 page-faults
4.001184123 701 page-faults
5.001474912 690 page-faults
6.001793133 630 page-faults
7.002094796 636 page-faults
8.002401844 998 page-faults
[...]可以看到每秒钟会有几百次的缺页中断。当前系统有16颗CPU,如果维持这种频率,用perf追踪每个事件造成的开销可以忽略不计。但如果系统只有一颗CPU,或者是缺页中断频率高达每秒几千次,那么我就会考虑使用eBPF内核概括的方法来降低开销。
使用perf以及Flamegraph的步骤:
# perf record -e page-fault -a -g -- sleep 30
# perf script > out.stacks
[...copy out.stacks to a local system if desired...]
# ./stackcollapse-perf.pl < out.stacks | ./flamegraph.pl --color=mem \
--title="Page Fault Flame Graph" --countname="pages" > out.svg同样,在较新的Linux系统上你可以用eBPF。可以通过内核函数,比如 handle_mm_fault()来动态追踪缺页中断,也可以在4.14以上的内核中通过tracepoint来追踪,比如 t:exceptions:page_fault_user 和 t:exceptions:page_fault_kerne。这里我通过tracepoint,使用BCC工具stackcount来演示eBPF的追踪步骤:
# /usr/share/bcc/tools/stackcount 't:exceptions:page_fault_*' > out.stacks
[...copy out.stacks to a local system if desired...]
# ./stackcollapse.pl < out.stacks | ./flamegraph.pl --color=mem \
--title="Page Fault Flame Graph" --countname="pages" > out.svg下面是一个火焰图的例子,这次是从一个java应用中生成的:
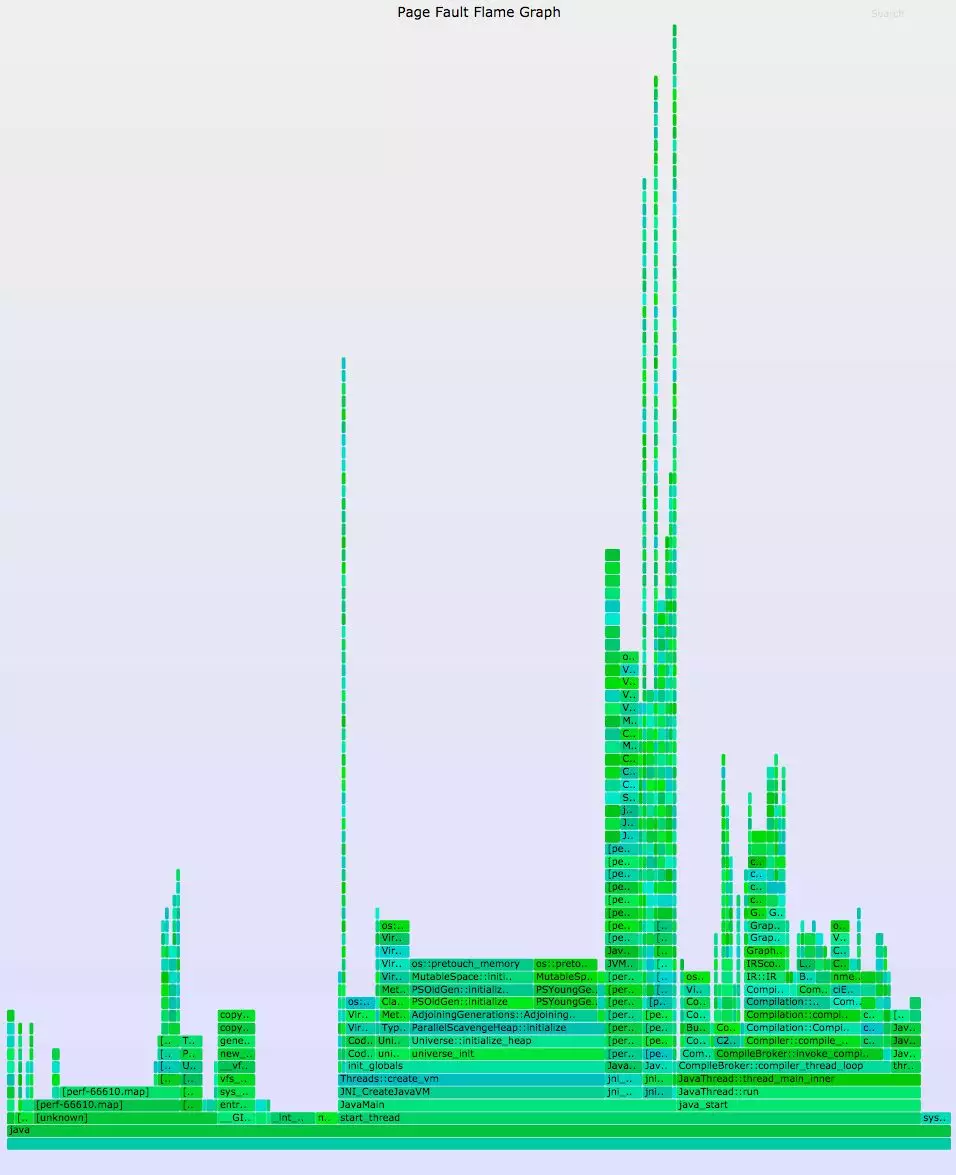
一些路径很正常,比如中间 Universe::initialize_heap到 os::pretouch_memory这条,但其实我对右边表示编译过程的那条分支更感兴趣,因为它能显示出有多少内存增长是由于java的编译造成的,而不是数据本身造成的。
之前几种方法显示的都是初始分配的代码路径,而缺页中断追踪有所不同:它显示那些占据物理内存的代码路径。他们可能是:
-
一条导致内存增长的代码路径
-
一条导致内存泄漏的代码路径
同样,需要进行侦察才能区分二者。如果你在排查某个应用的漏洞,并且有一个相似的正常(没有增长的)应用,那么为每个应用都生成一个火焰图,然后对比寻找多出来的代码路径,可能能够很快地找出不同;如果你正在开发应用,那么每天都收集一些基线数据,这不仅可以使你找到一个增长或泄漏的代码路径,还能确定它们发生的日期,有助你跟踪变化。
追踪缺页中断的开销可能比brk()或mmap()大一点,但也不会太大。缺页中断仍然属于低频率事件,这使得追踪它的开销接近于“可忽略”。在实践中,我发现用追踪缺页中断来诊断内存增长和泄漏是简单、快速而且往往有效的。尽管它不是万能的,但值得一试。
其它操作系统
-
Solaris: 可以使用DTrace进行内存追踪,这是我的原创文章: Solaris 内存泄漏(增长)火焰图
-
FreeBSD: 可以像Solaris一样使用DTrace,我有机会可以分享一些例子。
总结
我已经详细论述了4种动态追踪的方法来分析内存增长:
-
分配器函数追踪
-
brk()系统调用追踪
-
mmap()系统调用追踪
-
缺页中断追踪
运用这些方法可以识别虚拟或物理内存的增长,定位造成增长包括泄漏的原因。brk(),mmap()以及缺页中断不能直接分析泄漏问题,仍需要进一步分析。然而它们也具有优势,一个是超低的开销使得它们可以广泛适用于工业级应用分析,另一个是在于它们可以使追踪工具灵活部署,不需要重启应用程序。
链接
我在USENIX LISA 2013 的关于Blazing Performance with Flame Graphs 的报告演讲中介绍了这四种分析内存的方法,在 幻灯片102 和 视频 56:22处。
我的原创网页内容Solaris Memory Flame Graphs 提供了更多的例子(基于其他系统)
在我的 2016 ACMQ文章 The Flame Graph中我总结了这四种内存分析的方法, 文章以Communications of the ACM, Vol. 59 No. 6出版。
在火焰图主页 Flame Graphs中有其他形式的火焰图、链接,还有火焰图软件。
本文来自公众号:Linux阅码场,由西邮陈莉君教授研一学生戴君毅、梁金荣、马明慧等翻译,宋宝华老师指导和审核。译者戴君毅、梁金荣、马明慧等同学热爱开源,践行开放、自由和分享。
相关阅读

