
JDK11现存性能bug(JDK-8221393)深度解析原创
这是一篇鸽了很久的博客,因为博客内容和素材早就准备差不多了,但就是一直懒得整理,今天终于下定决心终于整理出来了,这也是这个bug JDK-8221393唯一一篇中文介绍博客。
先大致介绍下这个bug,准确说这个应该是jdk11新引入的zgc的一个bug,该bug在被触发的情况下会导致进程CPU使用率会逐渐升高,如果不管的话最终CPU会到100% 影响服务可用性,而且这个性能bug在jdk11最新的代码中仍未修复。不过不用担心,这个bug触发的要求比较苛刻,估计这也是jdk开发者不修复该bug的原因之一。另外,我在翻看jdk13源码时发现该bug已被修复,并且有些相关设计上的提升。

该bug的表象如上图,在业务和代码逻辑无变更的情况下,CPU使用率大概每隔10天就会翻倍,重启后恢复正常。上图中我们分别在11月19和11月29日重启过,CPU明显下跌,然后又开启一轮新的轮回…… 这个服务是我们很重要的一个服务,我们有同事很长时间都在找原因,也尝试做过很多优化,一直都没解决,我们的服务只好靠定期重启续命了。 不过这事在我介入后的第二天就立马有了眉目,嘿嘿嘿。。。 (不是我能打,而是他们缺少一把趁手的“兵器”)
排查过程
作为一名工程师,面对上面的现象,你会怎么做? 我想你的第一反应肯定是业务代码有问题?是不是有什么地方导致内存泄露? 是不是业务代码里有什么地方加载的数据太多,越来越慢?…… 同事尝试过dump堆里的内容,dump jstak线程…… 都没看出来什么异常,也优化了业务代码里之前一些不合理的逻辑,始终没有解决问题。 当时的问题是他们都没有往热点代码的方向排查,主要是因为他们不知道有啥好用的工具。
而我恰好当时在关注过阿里的Arthas,知道当时正好Arthas新增了性能排查命令profiler 可以生成CPU火焰图,而我又恰好看过阮一峰老师的如何读懂火焰图?。然后我就给同事推荐了Arthas并建议同事用Arthas生成CPU的火焰图,看下到底是哪个地方耗费CPU,然后就发现了异常。

火焰图该怎么读?
不知道怎么看火焰图不要紧,其实很简单,具体可参考阮一峰老师的如何读懂火焰图?。
y 轴表示调用栈,每一层都是一个函数。调用栈越深,火焰就越高,顶部就是正在执行的函数,下方都是它的父函数。
x 轴表示抽样数,如果一个函数在 x 轴占据的宽度越宽,就表示它被抽到的次数多,即执行的时间长。注意,x 轴不代表时间,而是所有的调用栈合并后,按字母顺序排列的。
火焰图就是看顶层的哪个函数占据的宽度最大。只要有"平顶"(plateaus),就表示该函数可能存在性能问题。
你可以简单认为每一块越宽,它就越耗费CPU,用火焰图做性能分析的关键就是去找那些你觉得本应该很窄但实际却很宽的函数。上图中就是我们有问题服务长期运行后和刚启动时的生成的火焰图(同样的代码和环境),左图明显有异常,它有好几个"平顶",也就是说该函数消耗了过多的CPU,大概率这就是问题的根源了。
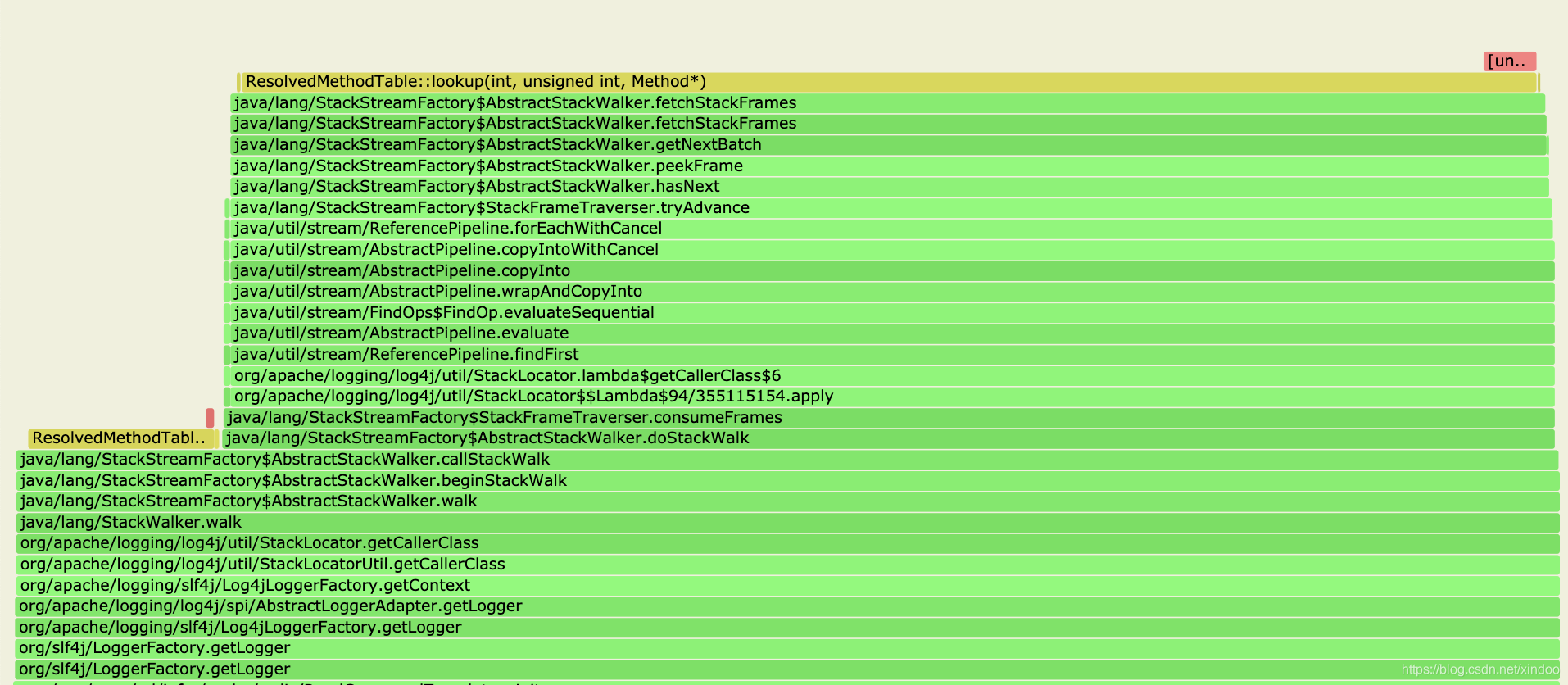
这里我特意找到了该函数调用的堆栈信息,然后就发现了我们代码中不合理的地方。
[0x00007f2091c15000]
java.lang.Thread.State: RUNNABLE
at java.lang.StackStreamFactory$AbstractStackWalker.fetchStackFrames(java.base@11/Native Method)
at java.lang.StackStreamFactory$AbstractStackWalker.fetchStackFrames(java.base@11/StackStreamFactory.java:386)
at java.lang.StackStreamFactory$AbstractStackWalker.getNextBatch(java.base@11/StackStreamFactory.java:322)
at java.lang.StackStreamFactory$AbstractStackWalker.peekFrame(java.base@11/StackStreamFactory.java:263)
at java.lang.StackStreamFactory$AbstractStackWalker.hasNext(java.base@11/StackStreamFactory.java:351)
at java.lang.StackStreamFactory$StackFrameTraverser.tryAdvance(java.base@11/StackStreamFactory.java:593)
at java.util.stream.ReferencePipeline.forEachWithCancel(java.base@11/ReferencePipeline.java:127)
at java.util.stream.AbstractPipeline.copyIntoWithCancel(java.base@11/AbstractPipeline.java:502)
at java.util.stream.AbstractPipeline.copyInto(java.base@11/AbstractPipeline.java:488)
at java.util.stream.AbstractPipeline.wrapAndCopyInto(java.base@11/AbstractPipeline.java:474)
at java.util.stream.FindOps$FindOp.evaluateSequential(java.base@11/FindOps.java:150)
at java.util.stream.AbstractPipeline.evaluate(java.base@11/AbstractPipeline.java:234)
at java.util.stream.ReferencePipeline.findFirst(java.base@11/ReferencePipeline.java:543)
at org.apache.logging.log4j.util.StackLocator.lambda$getCallerClass$6(StackLocator.java:54)
at org.apache.logging.log4j.util.StackLocator$$Lambda$94/0x00007f238e2cacb0.apply(Unknown Source)
at java.lang.StackStreamFactory$StackFrameTraverser.consumeFrames(java.base@11/StackStreamFactory.java:534)
at java.lang.StackStreamFactory$AbstractStackWalker.doStackWalk(java.base@11/StackStreamFactory.java:306)
at java.lang.StackStreamFactory$AbstractStackWalker.callStackWalk(java.base@11/Native Method)
at java.lang.StackStreamFactory$AbstractStackWalker.beginStackWalk(java.base@11/StackStreamFactory.java:370)
at java.lang.StackStreamFactory$AbstractStackWalker.walk(java.base@11/StackStreamFactory.java:243)
at java.lang.StackWalker.walk(java.base@11/StackWalker.java:498)
at org.apache.logging.log4j.util.StackLocator.getCallerClass(StackLocator.java:53)
at org.apache.logging.log4j.util.StackLocatorUtil.getCallerClass(StackLocatorUtil.java:61)
at org.apache.logging.slf4j.Log4jLoggerFactory.getContext(Log4jLoggerFactory.java:43)
at org.apache.logging.log4j.spi.AbstractLoggerAdapter.getLogger(AbstractLoggerAdapter.java:46)
at org.apache.logging.slf4j.Log4jLoggerFactory.getLogger(Log4jLoggerFactory.java:29)
at org.slf4j.LoggerFactory.getLogger(LoggerFactory.java:358)
at org.slf4j.LoggerFactory.getLogger(LoggerFactory.java:383)
at com.xxxxxxx.infra.cache.redis.ReadCommandTemplate.<init>(ReadCommandTemplate.java:21)
at com.xxxxxxx.infra.cache.redis.RedisClient$4.<init>(RedisClient.java:138)
at com.xxxxxxx.infra.cache.redis.RedisClient.hget(RedisClient.java:138)
...
...
ReadCommandTemplate是我们公司封装的一个redis client,每读写一次redis就会实例化一个ReadCommandTemplate,我们的业务逻辑中每个请求都会读一次redis,所以导致ReadCommandTemplate这个类生成很多个实例。本身这个类很轻量,按理来说多次实例话也没关系,但其中用了logger,而且logger没有声明为static,所以没new 一个ReadCommandTemplate,都会同时生成一个logger,从火焰图来看,似乎是生成logger的过程中产生了性能问题。
public abstract class ReadCommandTemplate<T> {
private Logger logger = LoggerFactory.getLogger(ReadCommandTemplate.class);
/**
* 其他代码逻辑省略
*/
}
有经验的java开发者一眼就能看出来上面代码的不合理之处,但应该只是稍微影响性能,不会出现文首那种诡异的现象! 确实,这个redis client在我们部分被广泛使用,其他的应用都没出现问题。。。 会不会是这个应用恰巧凑齐了某个bug触发的所有条件??
Bug的确认
要想确认bug是否是这个非static的logger导致的,有两个方案:1. 修复logger的问题,看CPU是否会上涨。 2. 真正搞清楚这个bug的原理。因为方案1需要至少等待一周才能实锤,所以我们选择了二者并行。同事修复了logger,而我开启了问题探索和jvm源码阅读之旅。后来方案1确实也正式了是logger导致的,而我也找到了19年有人给jvm团队反馈bug后jvm团队讨论的邮件列表。

jdk的开发者Stefan Karlsson确认并大致给出了这个bug出现的原因,如上图。这里我大致解释下,JVM在查找方法的时候会调用"ResolvedMethodTable::lookup",其实这里是查找一个只有1007个bucket的hash表,因为jdk11的zgc没有定期对ResolvedMethodTable做清理,所以里面的数据会越来越多,查询会越来越慢。
问题是用jdk11+zgc+log4j组合的人也非常多,为什么偏偏就我们的代码触发了bug??
深度剖析
为了深入理解这个bug,我们首先来看下我们调LoggerFactory.getLogger()的时候发生了什么!!
在jdk9及以后的版本中,log4j使用了新的StackWalker来获取线程的堆栈信息,然后遍历每个栈帧,所以StackWalker就调用native方法fetchStackFrames从JVM里获取这个栈帧。
我翻阅了JVM代码,找到了ResolvedMethodTable::lockup()在做啥! 不过首先我们得知道ResolvedMethodTable是啥? ResolvedMethodTable可以简单认为是JVM中存储所有已经解析到的方法信息的一个hashtable,它只有1007的bucket(为什么设计这么小?),这么小的bucket必然很容易产生hash冲突,处理hash冲突的方式就是开链,而lockup()在查找过程中,需要遍历单链表,所以如果单链表过长,lookup的查询性能就下来了,lookup()的源码如下。
oop ResolvedMethodTable::lookup(Method* method) {
unsigned int hash = compute_hash(method);
int index = hash_to_index(hash);
return lookup(index, hash, method);
}
oop ResolvedMethodTable::lookup(int index, unsigned int hash, Method* method) {
for (ResolvedMethodEntry* p = bucket(index); p != NULL; p = p->next()) {
if (p->hash() == hash) {
oop target = p->object_no_keepalive();
if (target != NULL && java_lang_invoke_ResolvedMethodName::vmtarget(target) == method) {
ResourceMark rm;
log_debug(membername, table) ("ResolvedMethod entry found for %s index %d",
method->name_and_sig_as_C_string(), index);
return p->object();
}
}
}
return NULL;
}
现在的问题是究竟是什么导致ResolvedMethodTable数据太多,从而使得其中单个bucket的链表过长? 我们还是从该bug的邮件讨论列表里找到答案http://mail.openjdk.java.net/pipermail/zgc-dev/2019-March/000612.html,这里我大概翻译如下:
GC除了卸载不用的类时,也会做好多其他的清理工作,比如清理ResolvedMethodTable和StringTable中不用的信息。ResolvedMethodTable保存着java中ResolvedMethodName类实例的弱指针,如果ResolvedMethodName不可达,正常情况下gc就会清理掉这个不可达对象。而ResolvedMethodName是MemberName中的一部分。StackWalker遍历栈帧的时候,就会创建MemberName java对象并放到StackFrameInfo.memberName中,jvm中的代码实现如下:
void java_lang_StackFrameInfo::set_method_and_bci(Handle stackFrame,
const methodHandle& method, int bci, TRAPS) {
...
// 创建ResolvedMethodName对象并插入到ResolvedMethodTable中
CallInfo info(method(), ik, CHECK);
// 把ResolveMethodName对象放到MemberName中
MethodHandles::init_method_MemberName(mname, info);
堆栈调用信息如下:
java_lang_StackFrameInfo::set_method_and_bci(Handle, methodHandle
const&, int, Thread*)
JavaFrameStream::fill_frame(int, objArrayHandle, methodHandle const&,
Thread*)
StackWalk::fill_in_frames(long, BaseFrameStream&, int, int,
objArrayHandle, int&, Thread*)
StackWalk::fetchNextBatch(Handle, long, long, int, int,
objArrayHandle, Thread*)
JVM_MoreStackWalk
java.lang.StackStreamFactory$AbstractStackWalker.fetchStackFrames
后续,如果StackFrameInfos不用之后,这些对象会被从类的引用关系中移除,并被gc回收掉,然后gc会移除ResolvedMethodTable中相应的ResolvedMethodName。但问题是jdk11中,zgc并没有真正移除这些ResolvedMethodName,从而导致ResolvedMethodTable中的数据量越来越大,单链越来越长,查找效率越来越低。
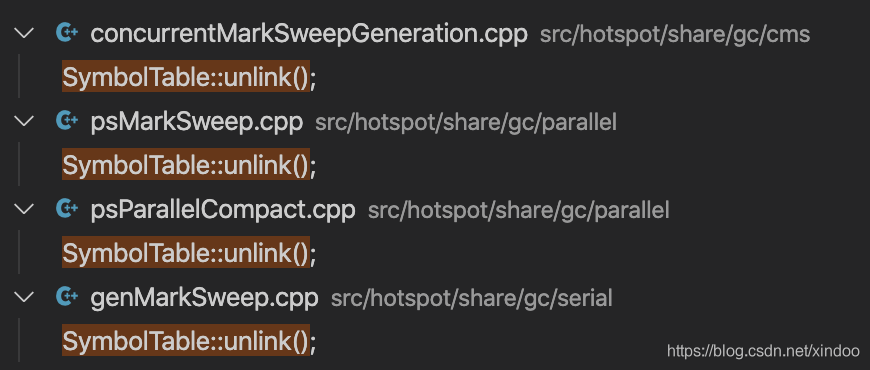
在JDK11的源码中SymbolTable::unlink()中实现了ResolvedMethodTable中无用信息的卸载,其他几个老gc都调用了,而zgc中确实没有调用,不知道这是忘记了还是特意为之……
简单梳理下就是:每次调用StackWalker遍历栈帧的时候,每个栈帧都会生成一个ResolvedMethodName对象放到jvm中的ResolvedMethodTable中,但jdk11的zgc不能有效清理其中不用的对象。因为ResolvedMethodTable是个定容的hashtable,随着其中的数据越来越多,每个bucket的单链表越来越长,查询效率会越来越慢。 所以最终导致CPU的使用率越来越高。
避坑指南
如果你看懂了上文的bug原理,相信你已经知道了如何闭坑,如果没看懂也没关系, 一句话 不要使用jdk11+zgc的同时频繁使用StackWalker(比如错误使用log4j)。当然也不是完全不能使用log4j了,只要不是频繁调用StackWalker就没问题,像我们代码中的logger只需要声明成static,这样StackWalker只会在类初始化的时候调用,就不会有问题了。知道了原理,也就能解释清楚为什么我们很多其他应用用了jdk11也用了有问题的RedisClient没有出现cpu异常的现象,就是因为其他应用没有启用zgc。
当然这个bug的本质就是jdk11+zgc+StackWalker的bug,三者都是bug触发的必要条件,如果你能避免其中一条就可以完美避开这个bug了,比如升级到jdk12+,比如不用zgc……
Bugfix
对于我们应用来说,只需按照上面的避坑指南操作即可,但对于jdk团队来说,这个bug他们肯定是要修复的。
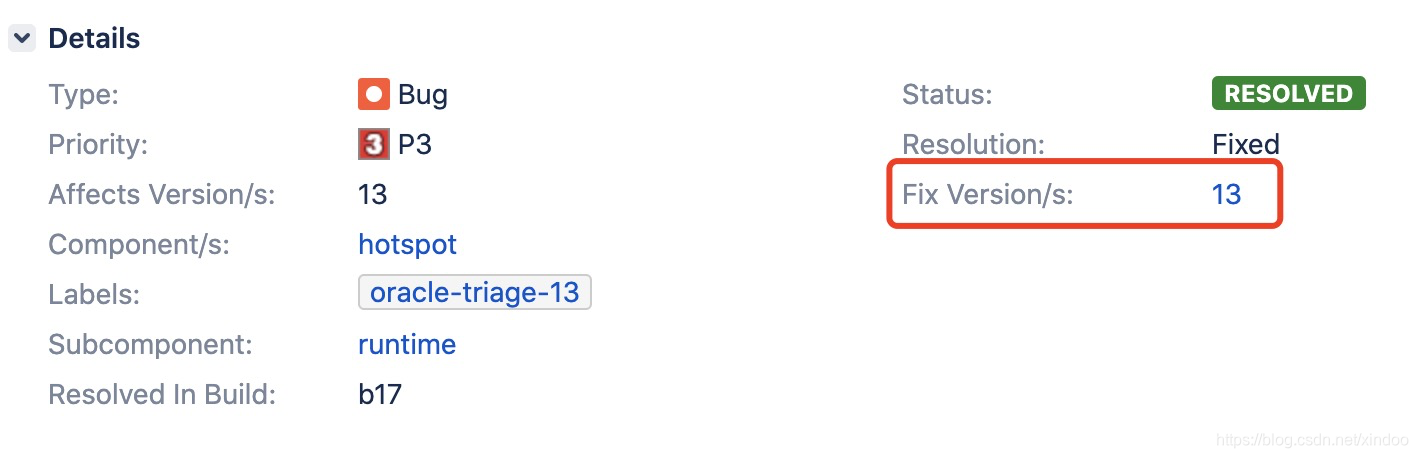
从官网bug页面可以看到这个bug在jdk13中已经修复了,我们来看看他们是如何修复的。是不是只需要在zgc合适的地方调一下SymbolTable::unlink()就行了?是的,但jdk团队做的远不止于此,除了unlink之外,他们还优化了ResolvedMethodTable的实现,支持了动态扩缩容,可以避免单链表过长的问题,具体可以看下jdk源码中src/hotspot/share/prims/resolvedMethodTable.cpp的文件。
void ResolvedMethodTable::do_concurrent_work(JavaThread* jt) {
_has_work = false;
double load_factor = get_load_factor();
log_debug(membername, table)("Concurrent work, live factor: %g", load_factor);
// 人工load_factor大于2,并且没有达到最大限制,就执行bucket扩容,并且移除无用的entry
if (load_factor > PREF_AVG_LIST_LEN && !_local_table->is_max_size_reached()) {
grow(jt);
} else {
clean_dead_entries(jt);
}
}
void ResolvedMethodTable::grow(JavaThread* jt) {
ResolvedMethodTableHash::GrowTask gt(_local_table);
if (!gt.prepare(jt)) {
return;
}
log_trace(membername, table)("Started to grow");
{
TraceTime timer("Grow", TRACETIME_LOG(Debug, membername, table, perf));
while (gt.do_task(jt)) {
gt.pause(jt);
{
ThreadBlockInVM tbivm(jt);
}
gt.cont(jt);
}
}
gt.done(jt);
_current_size = table_size();
log_info(membername, table)("Grown to size:" SIZE_FORMAT, _current_size);
}
总结
这个bug触发的主要原因其实还是我们自己的代码写的不够规范(logger未声明为static),而这个不规范其实也对其他没有触发这个bug的应用也产生了影响,毕竟生成logger也是会消耗性能的,我们代码fix后其他应用升级,有些服务CPU占用率降低5%+。这也充分说明代码质量的重要性,尤其是那种被广泛采用的基础代码。
另外是不是有些人还有个疑问,这个bug为什么不在jdk11后续版本中修掉,而是选择在jdk13中彻底修掉,不怕影响到使用jdk11的用户吗?对这个问题我有个想法,其实这个bug并不是很容易触发的严重bug(jdk11+zgc+log4j的频繁调用),而且即便是触发了,jdk的使用者也很容易通过修改自己的代码来规避这个bug,所以对jdk的开发者而言这不是一个重要且紧急的bug,后续修复掉就行了。
参考资料
- 阿里巴巴开源java问题排查工具 Arthas.
- 阮一峰 如何读懂火焰图?
- jdk开发者关于bug讨论的邮件列表



