
频繁操作本地缓存导致YGC耗时过长原创
某天,某位群友在JVM讨论群里发来一张GC log的图片。
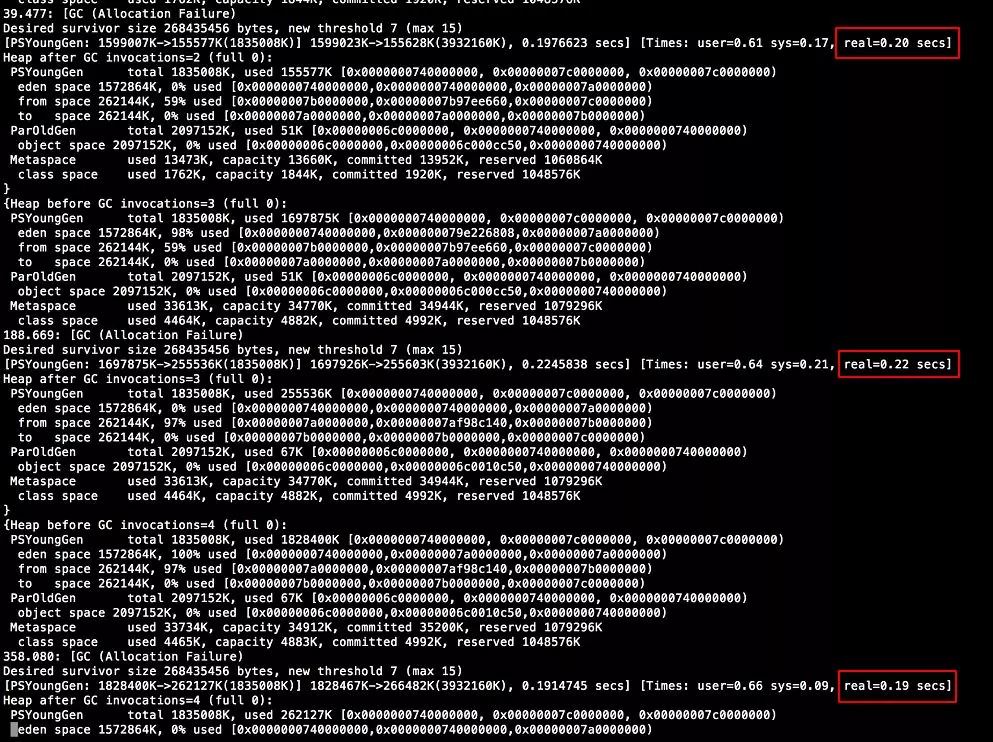
其中主要的问题是YGC过长,每次耗时约为200ms。
使用的JVM参数如下:
-Xmn2048m -Xms4096m -Xmx4096m -XX:+PrintGC -XX:+PrintGCTimeStamps -XX:+PrintGCDetails -XX:+PrintHeapAtGC -XX:+PrintTenuringDistribution -XX:MetaspaceSize=128M -XX:MaxMetaspaceSize=128M
指定年轻代内存为2g,初始JVM内存为4g,最大JVM内存为4g。
这个问题引起了群友们的关注。
从GC log和JVM参数可以看出,GC算法使用默认的Parallel Scanvenge。
可以看到Eden区大小为1536M,两个Survivor区大小为256M。
得出-XX:SurvivorRatio = 6。
此外可以看到在GC时,desired survivor size 268435456 bytes = 256M,得出-XX:TargetSurvivorRatio = 100。
默认情况下,-XX:SurvivorRatio = 8,-XX:SurvivorRatio = 50。
然而并未设置这两个参数,一直怀疑是配置没有生效。
一时没有想到办法,有群友建议试着调整下 MaxGCPauseMills 或者 GCTimeRatio 参数,然后效果都不好。
之后的某天,尝试使用jmap -heap pid打印应用的堆栈信息。
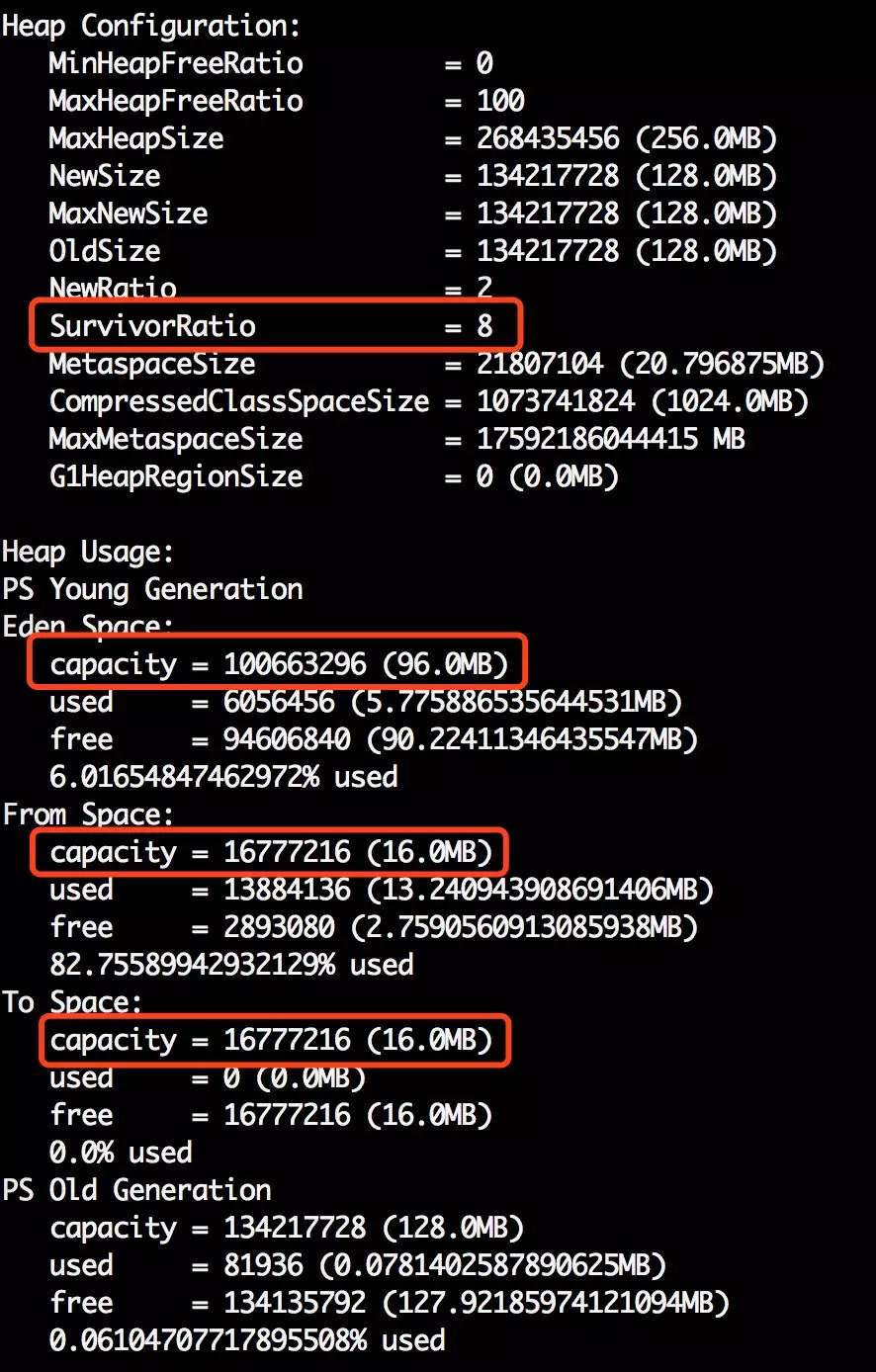
发现虽然写着SurvivorRatio = 8,但是E:S0:S1的比例并非是8:1:1。
于是开始寻找原因。
找到来自R大的回答:
HotSpot VM里,ParallelScavenge系的GC(UseParallelGC / UseParallelOldGC)默认行为是SurvivorRatio如果不显式设置就没啥用。显式设置到跟默认值一样的值则会有效果。
因为ParallelScavenge系的GC最初设计就是默认打开AdaptiveSizePolicy的,它会自动、自适应的调整各种参数。
于是推荐群友尝试使用CMS,让这些配置固定下来,不做自适应调整。但设置之后,发现YGC效果依旧不好。
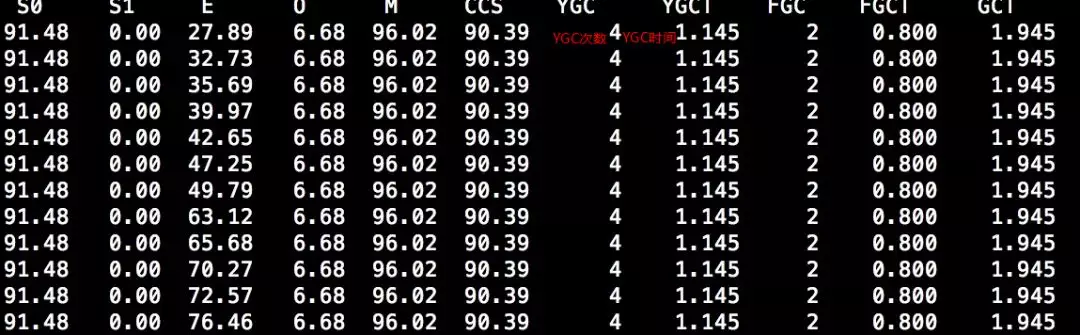
显示发生4次YGC,耗时1.145s,平均耗时约286ms,情况反而更糟,回头再次分析GC log。发现日志中有这么一行:new threshold 7 (max 15)JVM中有个参数为晋升年龄阈值(-XX:MaxTenuringThreshold),默认值为15。意思为在YGC时,超过该年龄的对象会被晋升到老年代。但GC log中显示该阈值被修改成了7。
在年轻代对象晋升时,有一个判断条件如下:
- 动态年龄判断,大于等于某个年龄的对象超过了survivor空间一半,大于等于某个年龄的对象直接进入老年代。
得出,在某次YGC时,Survivor区中,年龄超过7的对象占用了Survivor空间一半以上。而正常情况下,年轻代对象朝生夕死。网络服务处理请求为毫秒级,YGC几秒甚至十几秒才发生一次,多数年轻对象活不过1代。于是,猜测该群友使用了本地缓存。
在得到肯定的回复后,详细询问了群友使用本地缓存的方法。自行实现了一个本地缓存,类似于HashMap。别的服务会每一分钟推送缓存数据用于同步。在同步的时候不做diff操作,直接put。
举例:
缓存中保存Person类。
1@Data
2class Person {
3
4 private String name;
5
6 private Integer age;
7}
缓存内容可能为:
1{
2 "jjs":{
3 "age":27,
4 "name":"jjs"
5 }
6}
缓存同步涉及两种操作:新增和覆盖。
两种操作均直接使用put操作实现,无论当前缓存key是否已经存在。
这样的操作方法在业务上完全没有问题。
但对于GC而言,每次缓存同步需要new很多新的对象,并且这些对象都将一直存活,直到被覆盖,或者晋升到老年代。
这些缓存对象首先会被分配到年轻代,在YGC时候,这些对象都会被标记为存活。
得到YGC耗时过长原因一:
年轻代中有太多存活的对象,增加了标记时间。
此外,HashMap是数组加链表的结构,使用Node结构用于保存key、value。
HashMap的Node结构如下:
1static class Node<K,V> implements Map.Entry<K,V> {
2 final int hash;
3 final K key;
4 V value;
5 Node<K,V> next;
6}
每次put生成的node节点,很可能(hash冲突)被挂在已有node节点的next域上。已有node为缓存,长期存活,很有可能位于老年代。
那么,就形成了老年代对象对年轻代对象的引用。
在YGC中,需要扫描Card Table中的dirty区域来识别被老年代对象引用的年轻代对象。正常情况下,这种情形并不多。但在本文例子中,会大量存在。
得到YGC耗时过长原因二:
- YGC又需要花费大量的时间在扫描Card Table上,总结原因是操作本地缓存太频繁导致了YGC耗时过长。
回顾YGC的大致过程:
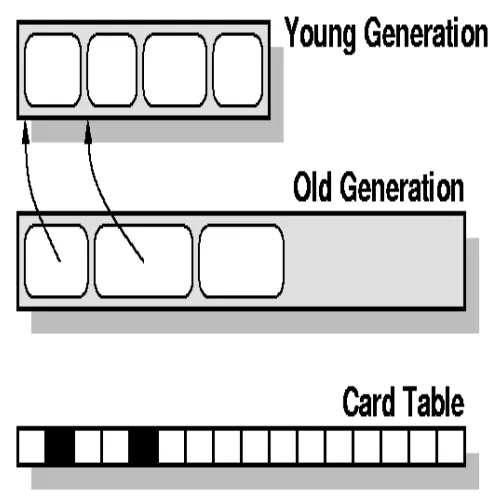
从根节点开始扫描年轻代对象,直到扫描到下个引用为非年轻代对象。(可以避免YGC扫描整个堆。)
扫描老年代dirty区域,即可扫描到被老年代对象引用的年轻代对象。(老年代被分为不同的块,Card Table字节数组中每个字节表示老年代中的一块。新分配对象时,触发写屏障,存在有老年代对象引用年轻代对象时,将对应的卡表设置为dirty。)
将Eden和From区中的对象复制到To区。如果To区已满,则直接复制到老年代。
YGC耗时过长问题的排查还是应该从两个点出发:
-
YGC时存活的年轻代对象太多。
-
老年代对象引用年轻代对象的情况太多。
解决方案
修改代码需要一定的时间,群友采用了一种短期的办法。修改了推送的周期。原来每一分钟推送一次。YGC下降到18-25ms,但在缓存推送时,YGC时间仍然达到200ms。两次缓存推送之间的对象都符合朝生夕死的弱分代假设,YGC时间正常。
后续修改思考/建议:
-
分批推送缓存,并且在接到推送的缓存时做diff操作,尽量修改已有对象而非新建对象。此举可减少长寿对象生成。
-
即使使用分批推送,在应用启动时,还是需要全量加载缓存。仍旧会面临应用刚启动时,YGC耗时过长的问题。
-
重新规划应用。因为经常变化的数据并不适合放在缓存中。
-
使用Redis缓存。Redis的响应时间为毫秒级,甚至只需几毫秒,并且无需考虑分布式下缓存同步问题。
-
使用CMS垃圾回收算法。因为默认和Parallel Scanvenge算法配合的老年代回收算法是Serial Old。该算法需要标记清理压缩,STW时间较长。



