
从CMS到G1:LinkedIn个人主页调优实战原创
LinkedIn中的个人主页是访问量最多的页面之一,它允许其他人访问你的个人主页,从而了解你的专业技能,经验和兴趣等:
所以,确保用户访问主页时以最快的速度返回是非常重要的。这篇文章,将谈论LinkedIn如何调优,从而确保个人主页达到毫秒级别的响应速度。
背景
在单个数据中心中,个人主页的QPS能轻松的到达几十万以上,然而,当流量发生切换的时候(流量从一个数据中心切换到另一个数据中心),这些额外的负载就会被加到目标数据中心,导致QPS上扬,延迟增大。最终可能导致请求超时。个人主页变慢,就会拖慢其他依赖主页的接口,整个WEB服务性能出现级联反应。
整个切换过程各种问题非常多,这篇文章我们主要介绍在流量高峰期的时候,数据路由层碰到的垃圾收集性能问题,以及我们从CMS切换到G1的动机,我们还将对数据中心切换做进一步的优化。
配置CMS的路由器问题
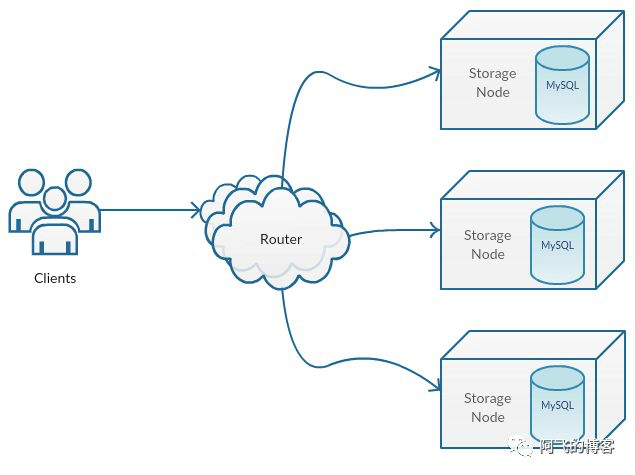
LinkedIn的个人主页数据保存在Espresso中(LinkedIn使用的分布式、面向文档、水平扩容以及高可用的KV存储,你可以把它当作LinkedIn的MongoDB),当用户触发一个到Espresso的读写请求时, 路由器首先把请求定向到包含请求数据的存储节点。许多客户端选择从Master存储节点读取数据,仅是为了保证读取的一致性。然而,客户端也可以选择通过将读请求发送到从节点从而扩展读取能力,当然代价就是可能读取到过时的数据。
想要了解更多关于Espresso,请戳:https://engineering.linkedin.com/espresso/introducing-espresso-linkedins-hot-new-distributed-document-store
Identity服务,即提供主页数据的系统,过去一年该服务的QPS翻了一倍,由于这个服务海量的请求,导致它会对存储节点产生几十万QPS。此外,随着服务存活的时间越长,JVM中CMS的堆碎片化问题就越严重:
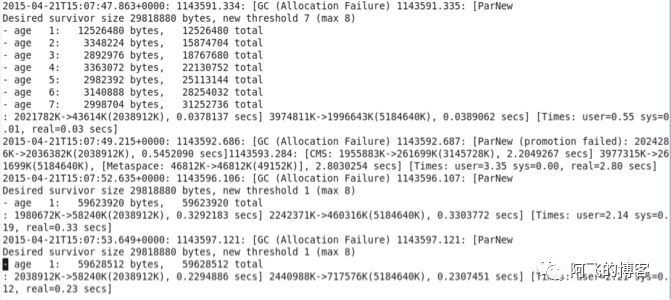
前段时间,我们大概切换了网站某个数据中心75%的流量到另一个数据中心,这个动作导致路由器返回给上游调用大量的503响应码告警。并且JVM出现了大量的晋升失败(promotion failures),导致路由器上很长、而且很多的停顿。很长的停顿就会让许多客户端尝试多次重试,从而使问题越来越恶化。路由器服务中,两个特别突出的JVM参数:-XX:CMSInitiatingOccupancyFraction=75 -XX:+UseCMSInitiatingOccupancyOnly 引起了我们的注意。
这两个参数意味着,老年代(3G)占用75%,即2.25G的时候,就会满足触发CMS的条件。另外,考虑到老年代中巨大的垃圾碎片,老年代可能在占用1.9G的时候,promotion failed就会被触发,导致2.8秒的长时间停顿:
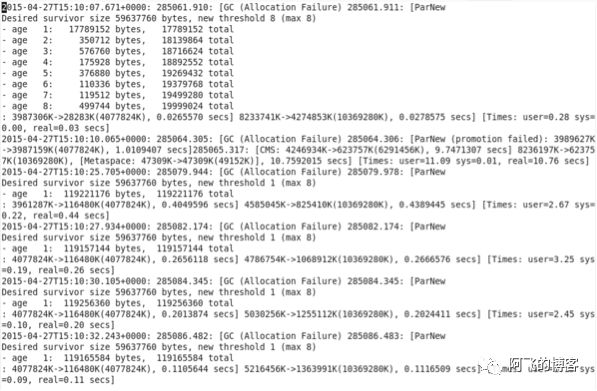
我们最初的想法是将老年代的大小翻倍提升到6G,这样可能帮助我们减少碎片化问题。但是,我们很快意识到,增加老年代容量只能延迟整体的清理时间,但是并不是杜绝碎片化问题和promotion failed,并且这次停顿达到了惊人的10.76秒,如下图所示:
CMS的碎片化
许多垃圾回收器都有一个标记阶段:发现并标记存活的对象,然后清理阶段回收死对象占用的内存空间。CMS不是采用复制算法的垃圾收集器,这就意味着在扫描和清理阶段,只能在它的free-list中更新对象,但是不会压缩存活的对象,这就会在内存中产生一个一个的“洞”,如下图所示,展示了这些“洞”是如何导致堆的碎片化的:
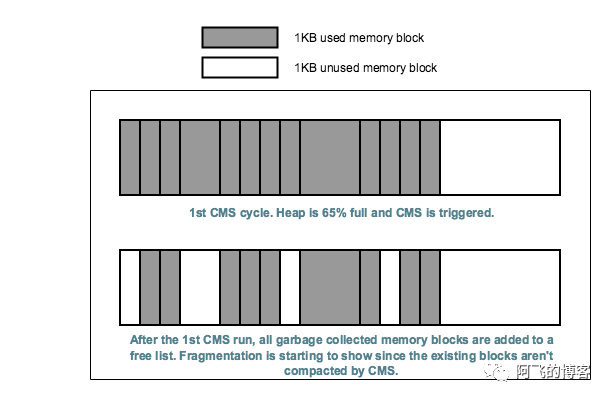
如上图所示,是CMS回收前后的对比图。由上图可知,在老年代使用65%的时候满足了触发CMS GC的条件。下图中空白处就是CMS GC回收掉的垃圾释放的空间,由于这些小空间,慢慢就就出现了碎片化(图中空白处所示),而且随着越来越多次触发CMS,碎片化问题会越来越严重。
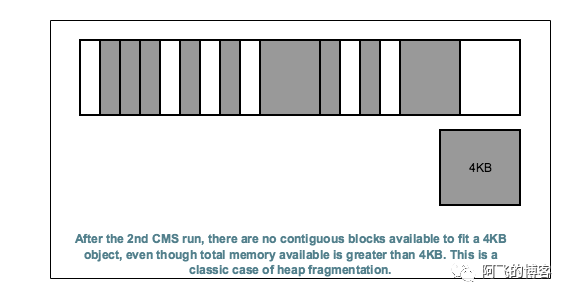
再看下面这幅图,请求需要4KB的空间,即使堆中总有效内存是足够的(所有空白处相加),但是这个请求还是无法成功分配到内存,因为没有连续至少4KB的空间,最终导致promotion failure:
调优
现在的情况,个人主页请求的响应报文大小在2MB以内。一开始,晋升到Old区的对象都是分配的连续的内存块。 随着时间的推移,许多大大小小不同尺寸的对象被分配,碎片化开始形成并越来越严重。接下来的某个时间点,如果晋升一个2MB甚至更大的对象,老年代可能就没有这么多连续的内存空间。那么一个FullGC就会被触发,FullGC意味着完全的STW,应用线程彻底停止,直到完成对堆的清理。而且FullGC的时间一般都是持续超过1秒,甚至几秒,上10秒。堆越大FullGC停顿的时间就越长。所以,增大内存(当前的Xmx为4GB,我们尝试将其调大到5GB,甚至10GB)并不能解决办法,它只是拖延了长时间停顿的问题,并且我们看到了更长的GC停顿。
切换到G1的动机
总之,CMS垃圾回收器不能满足我们对性能的需求,而G1相比CMS有更清晰的优势:
- CMS没有采用复制算法,所以它不能压缩,最终导致内存碎片化问题。而G1采用了复制算法,它通过把对象从若干个Region拷贝到新的Region过程中,执行了压缩处理。
- 在G1中,堆是由Region组成的,因此碎片化问题比CMS肯定要少的多。而且,当碎片化出现的时候,它只影响特定的Region,而不是影响整个堆中的老年代。
- 而且CMS必须扫描整个堆来确认存活对象,所以,长时间停顿是非常常见的。而G1的停顿时间取决于收集的Region集合数量,而不是整个堆的大小,所以相比起CMS,长时间停顿要少很多,可控很多。
G1调优
G1被配置在一部分服务器上,且堆大小为5G,测试其与CMS的对比效果。并且路由器节点运行在JDK8上:Intel Xeon E5-2640芯片,24核心,2.5GHz,64G内存。
Reference处理问题
G1偶然性出现奇怪的soft/weak引用清理,从下面的日志可以看出,在YGC阶段清理时,Ref Proc居然耗时达到101.3毫秒,从而导致Eden区减少,这就会导致部分对象提早晋升到Old区,从而导致并发GC周期变短:
2015-06-10T12:00:01.854+0000: 711685.290: [GC pause (G1 Evacuation Pause) (young) [Ref Proc: 4.0 ms] [Eden: 2904.0M(2904.0M)->0.0B(2872.0M)
2015-06-10T12:00:05.899+0000: 711689.335: [GC pause (G1 Evacuation Pause) (young) [Ref Proc: 101.3 ms] [Eden: 2872.0M(2872.0M)->0.0B(216.0M) Survivors: 32.0M->40.0M Heap: 4570.1M(5120.0M)->1706.8M(5120.0M)]
我们通过设置-XX:G1NewSizePercent=40,即设置年轻代占用堆最小百分比为40%来解决这个问题。因为有了这个设置,即使引用处理耗时变长,Eden区大小也不可能比这个阈值更低,从而避免对象提早晋升。同时,我们还添加了参数-XX:+ParallelRefProcEnabled,从而在Remark阶段多线程并发处理引用对象。
G1的Region大小
G1使用默认的Region大小,但是运行没多久后,我们就看到了巨大(humongous)对象!对于G1来说,只有那些超过Region大小50%的对象,才会被当作巨大对象。巨大对象分配时需要连续的Region集合,并且直接被分配在H区(特殊的Old区)。在JDK8U40之前,巨大对象只能在并发收集阶段或者FullGC时才能回收清理,JDK8U40之后,有一定的优化。因此,我们将JDK升级到8U40以后的版本,清理就可以在更早的GC阶段进行了。
CMS vs. G1
接下来,从堆的使用情况、CPU使用时间和GC暂停时间等几个方面对比CMS和G1。
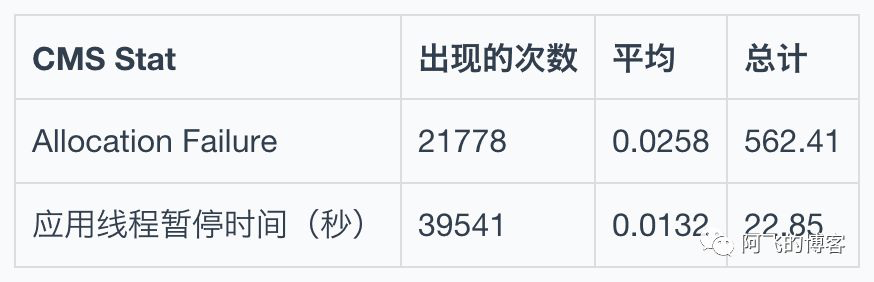
先看CMS的一些统计信息–说明,CMS+ParNew的组合,GC日志中出现Allocation Failure就表示发生了YGC:
再看G1的一些统计信息–说明,G1的话,GC日志中出现Evacuation Pause就表示发生了YGC:

堆使用情况
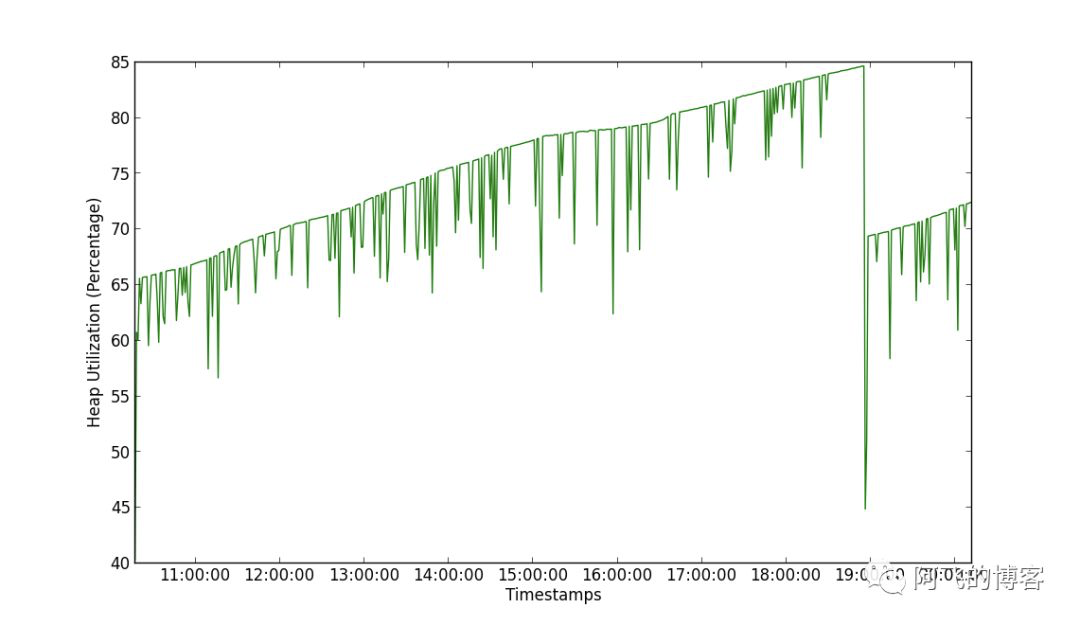
如下两张图所示,第一张图是CMS堆的使用情况,我们可以发现,有3次明显的波动,即发生了3次CMS GC:
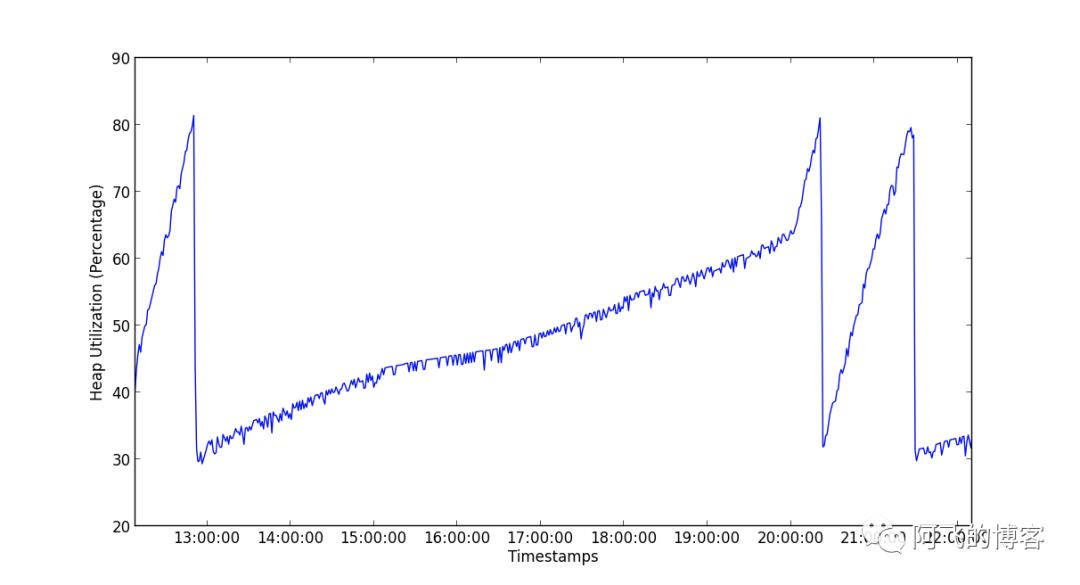
第二张图是G1堆的使用情况。我们可以看到,只有1次明显的波动,所以G1相比CMS优势明显:
CPU使用时间
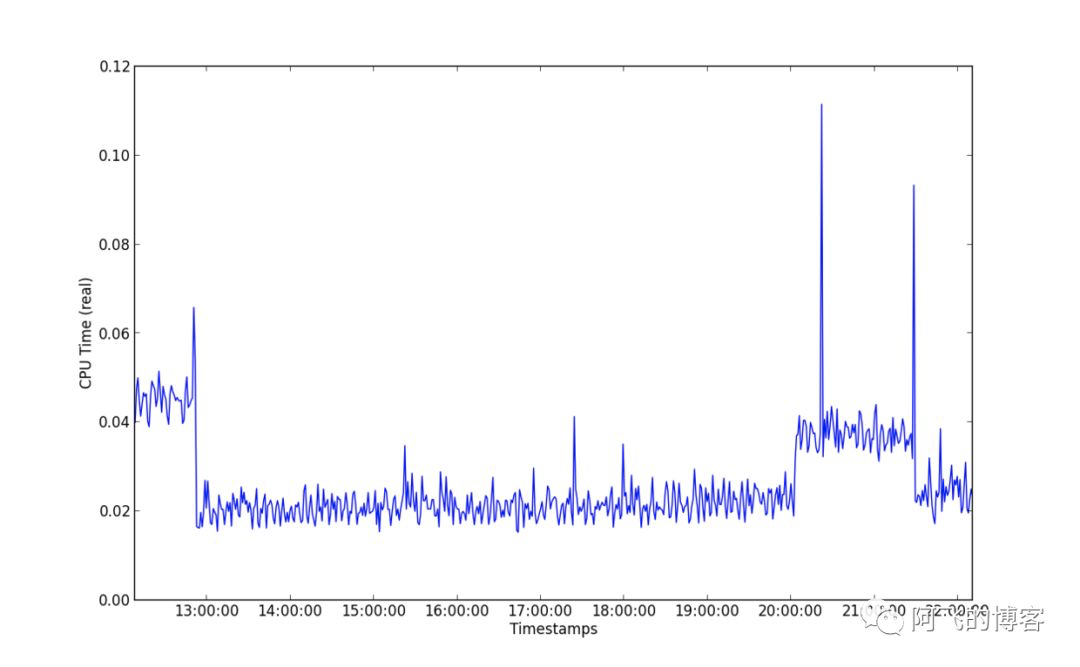
我们再看CPU使用时间,如第一张图所示,是CMS的CPU使用时间,有3次的毛刺,这3次毛刺的时间点刚好是发生CMS GC的时候,事实上就是CMS的Remark非常耗时,且峰值达到了惊人的115ms。
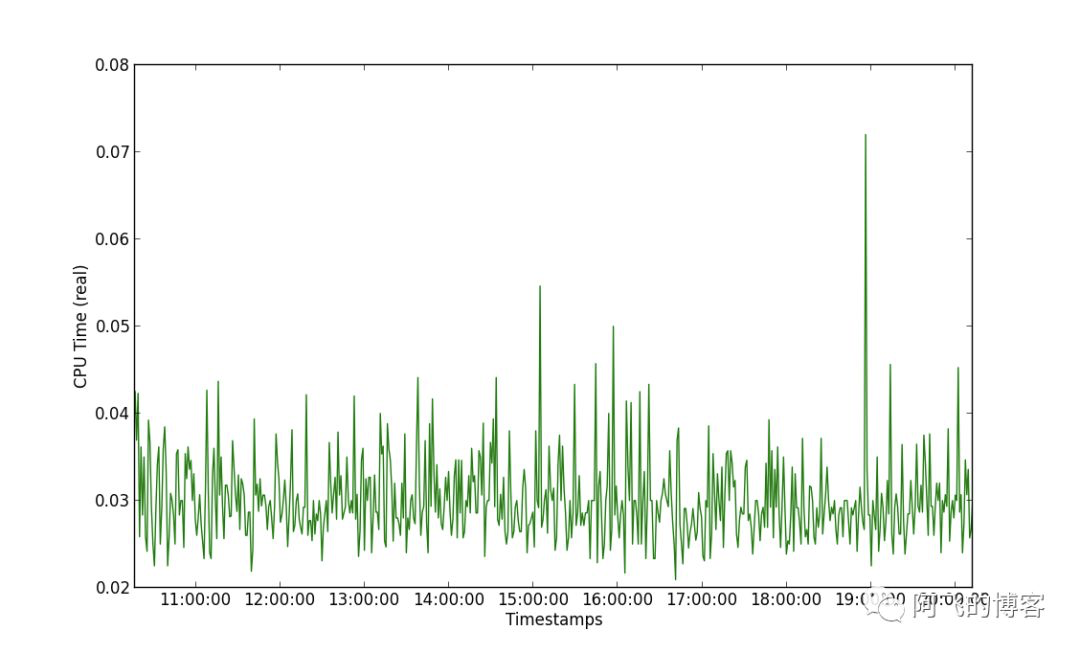
第二张图是G1的CPU使用时间,我们可以看到,只有1次明显的波动,且峰值只有75ms左右:
YGC停顿时间
CMS+ParNew前提下,YGC的平均停顿时间是20~25ms。而G1前提下,YGC的停顿时间是27~30ms,尽管G1相比CMS的YGC平均停顿时间高20%左右,但是G1大概是3秒1次YGC,而CMS的化,大概1秒1次YGC。所以,以3秒为单位的话,CMS的停顿时间要放到3倍,即60~75ms,远远大于G1的27~30ms。因此,G1相比CMS的吞吐能力更强。
如下面两张图所示,前面一张图是CMS的YGC停顿时间,后面一张图是G1的YGC停顿时间:


并发GC频率
并发收集就是当老年代达到一定比例的时候,比如CMS通过参数-XX:CMSInitiatingOccupancyFraction=75配置老年代占用75%的时候满足并发GC的条件。
对于Identity服务而言,平均6~8小时发生一次CMS GC。而对于G1,周期差不多,大概在6~7小时。如下面两张图所示,前面一张图是CMS并发收集周期,后面一张图是G1并发收集周期:


Remark停顿时间
并发标记阶段就是GC从Root集合遍历并标记存活对象,这个是一个并发阶段,即应用线程和GC线程一起运行。然而,Remark阶段是STW的,意味着应用线程必须停顿,直到GC从并发标记开始到找出所有更新的引用。
因为并发收集应用停顿时间主要来自于Remark阶段(相比起Remark阶段,初始化标记阶段时间短很多),因此,调优让Remark停顿时间尽可能的低,就变得非常非常重要。对于Identity服务,CMS的Remark阶段平均停顿时间是150ms,而G1只有50ms。可见,相比CMS,G1并发标记阶段的停顿时间控制好很多。
调优效果
通过从CMS切换到G1,我们将平均停顿时间从150ms降低到50ms,并且大大减少了JVM碎片化问题(G1也不能完全避免),并且几乎没有观察到延迟毛刺。而且,将一个数据中心的流量全部切换到另一个数据中心的流量,也完全可以Hold住了。
这次调优已经证明,G1很大的缓解了性能问题,最大化吞吐量的同时,也最小化了延迟,现在服务的平均RT只有30ms。除了Identity服务之外,我们还在测量其他集群的性能指标,以了解它们将从G1中受益多少。
备注:本篇文章翻译自Tuning Espresso’s JVM Performance:https://engineering.linkedin.com/blog/2016/01/tuning_espresso_jvm


