
Flink Jobmanager Metaspace OOM
环境说明:
系统后台换了一套ETL的框架,把MySQL中的数据用Flink转到ClickHouse,再经过Flink处理后再次写入到ClickHouse(中间用了zookeeper和kafka)。
配置截图如下:
Jobmanager:
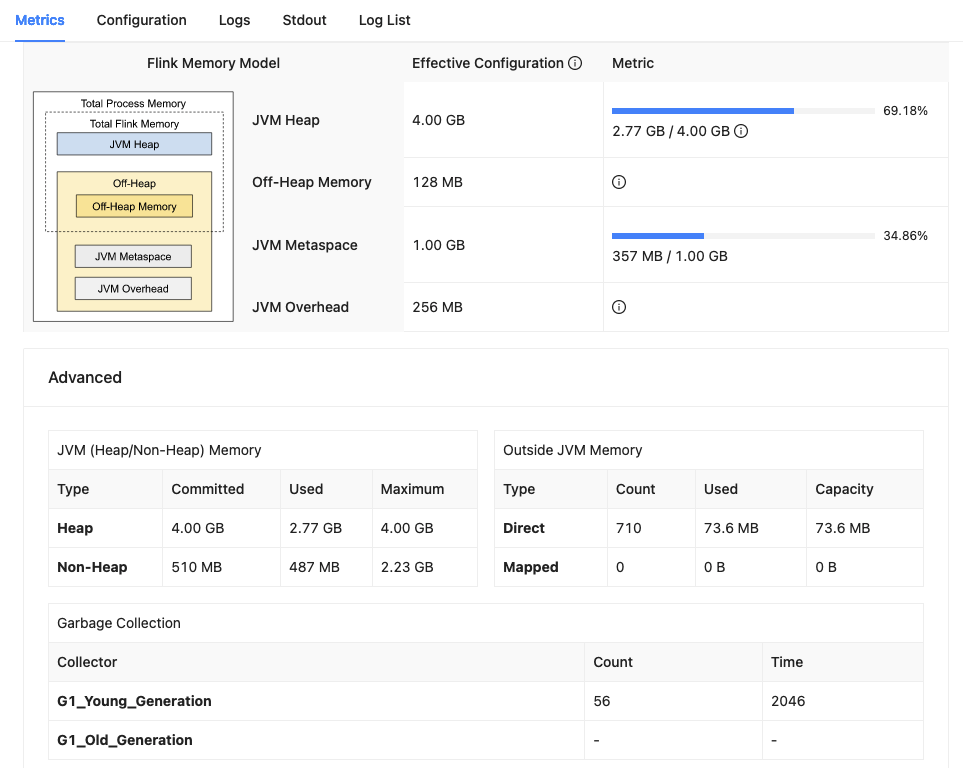
Taskmanager:(6个TM,slots共60个,每个TM分配10个slot)
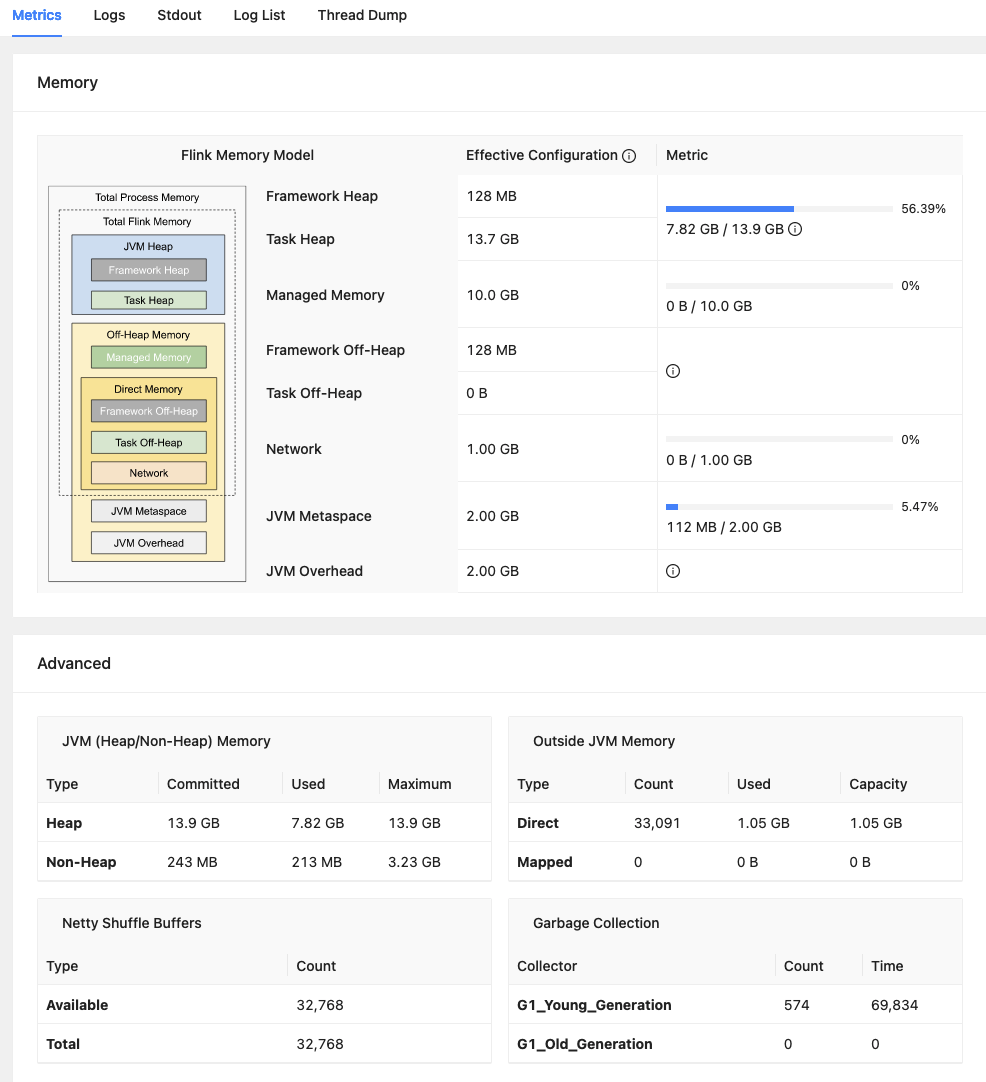
问题描述:
现在遇到个奇怪的问题,Flink的Jobmanager在job指派给taskmanager后执行过程中,Metaspace内存会快速上升直到 OOM。
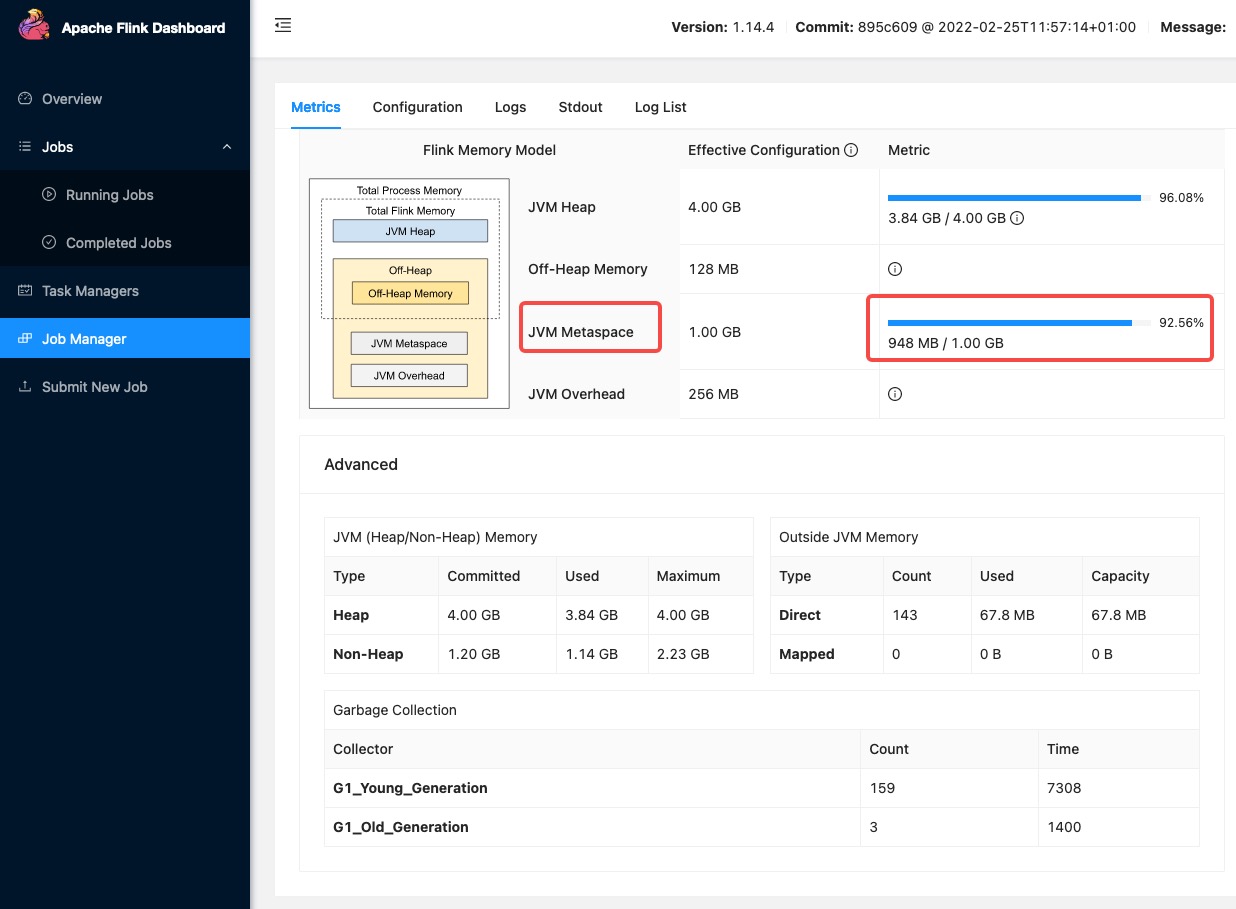
尝试过的解决方法:
先使用 jcmd <pid> VM.metaspace 命令查看了 metaspace 的状态:
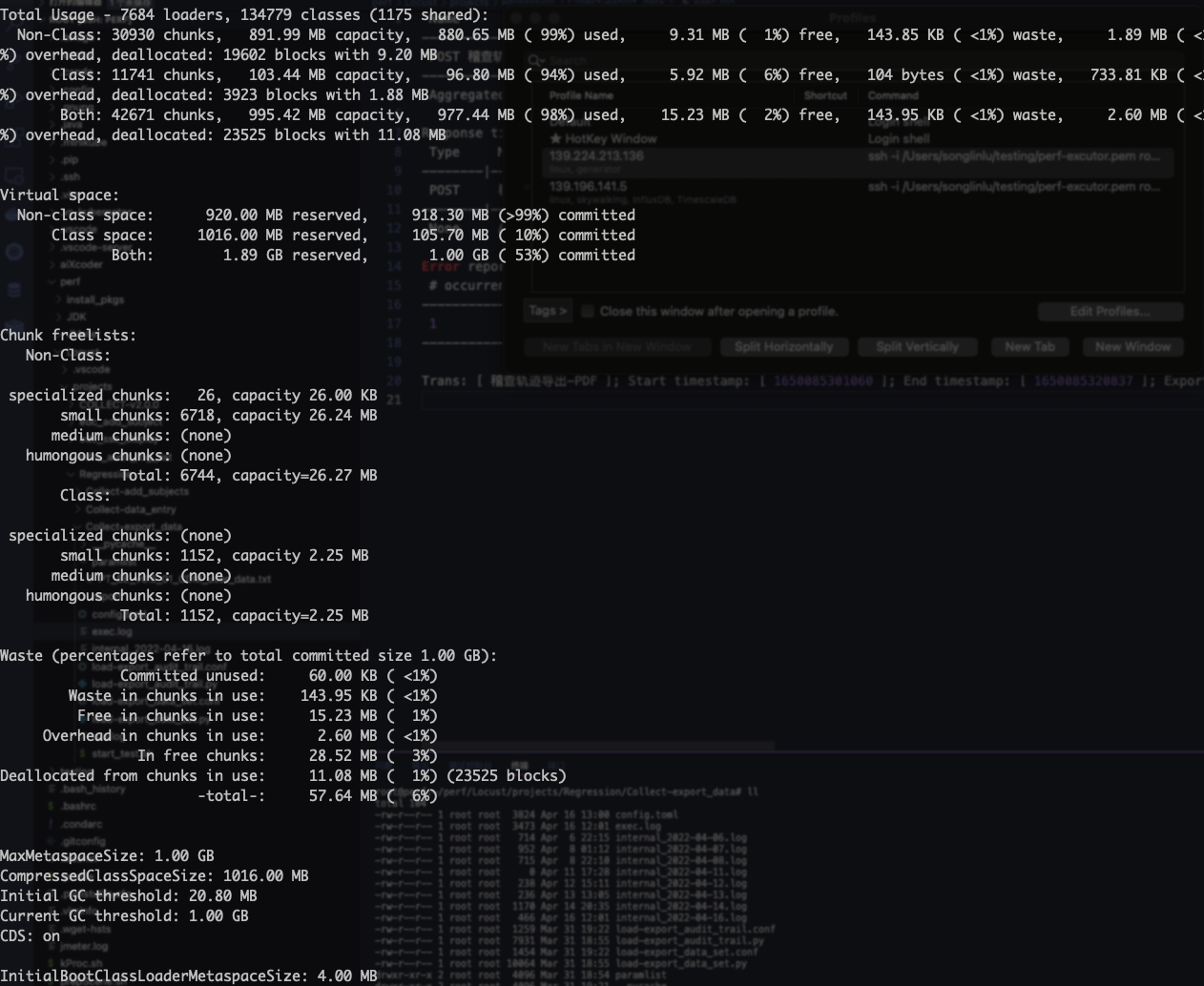
看到了有7674个加载器,134779个类被加载(共享类有1175个),觉得似乎有点太多了?
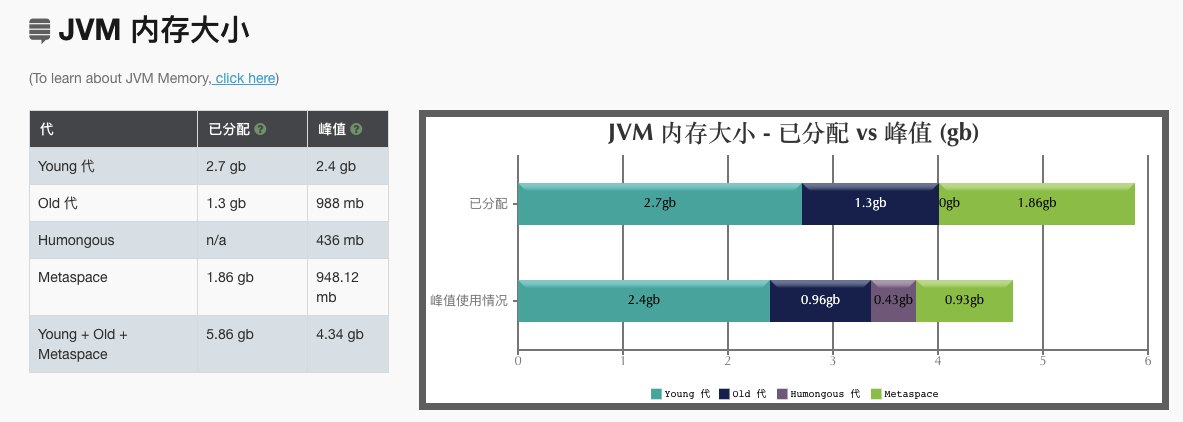
job一共有26个,跑完一轮 jobmanager 中的 metaspace 内存会上升 330M左右(配置了1G,那就是30%左右);
所以跑了3轮就把 1G 的 metaspace 给几乎占满了,继续跑就会 OOM。
然后看了下面的 Waste 的 In free chunks 也并不大,总共3%,顺势看了眼上面的 freelists,感觉也还好。
然后去分析了下GC日志(用的G1收集器),截图如下:
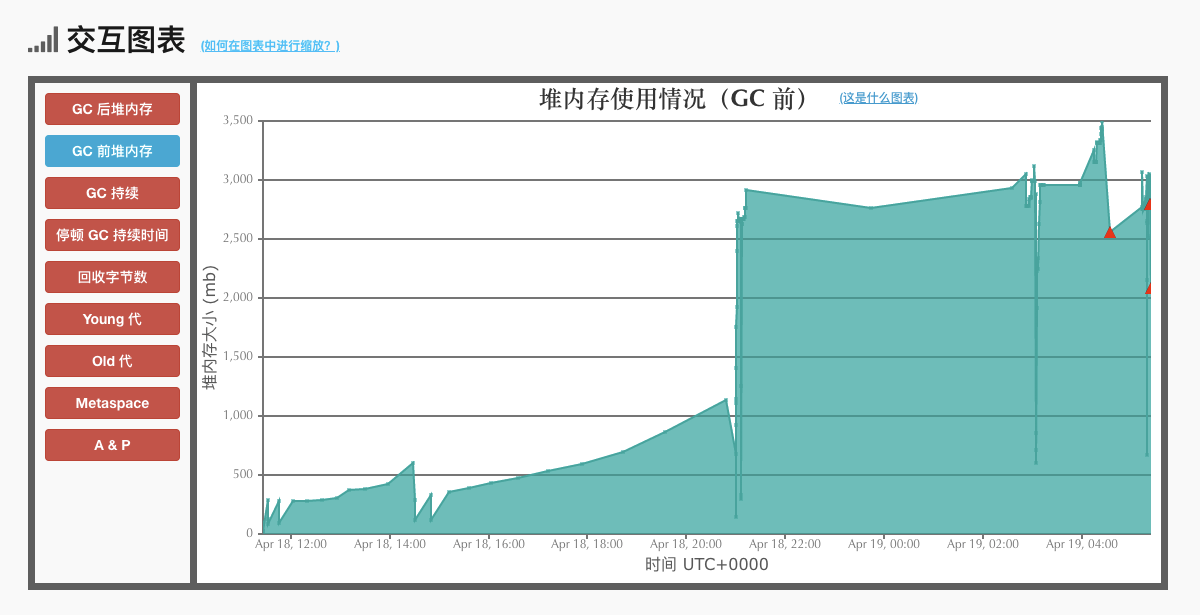
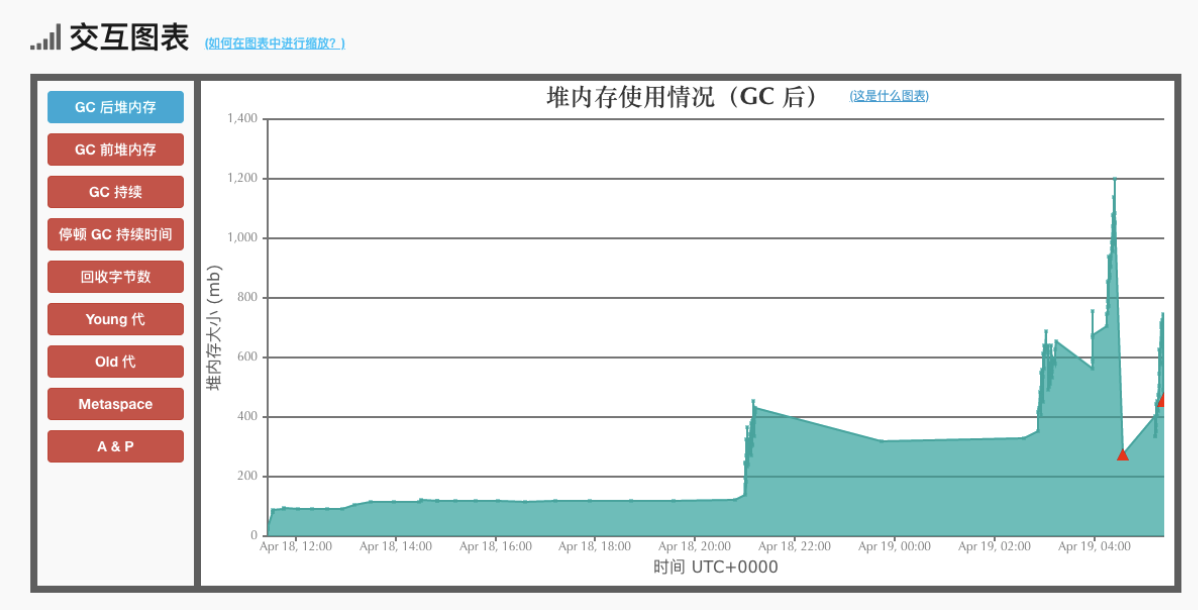
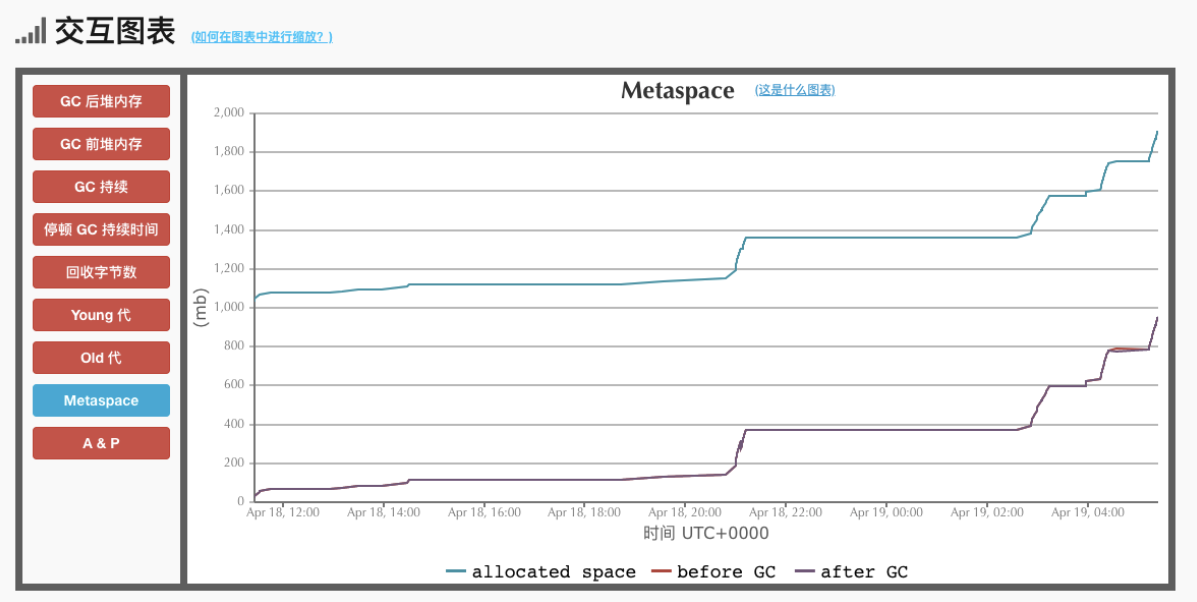
堆内存的GC是正常的,但是看 metaspace 就几乎没有被回收过内存。
个人猜测可能是有很多类加载器没有卸载 堆积在了元空间内存中 GC后那些内存没有返回给操作系统 最终导致的metaspace OOM。(但是我没有证据 T.T)
然后呢,开始用 MAT 分析 heap dump 文件,先看了 histogram,流程如下:
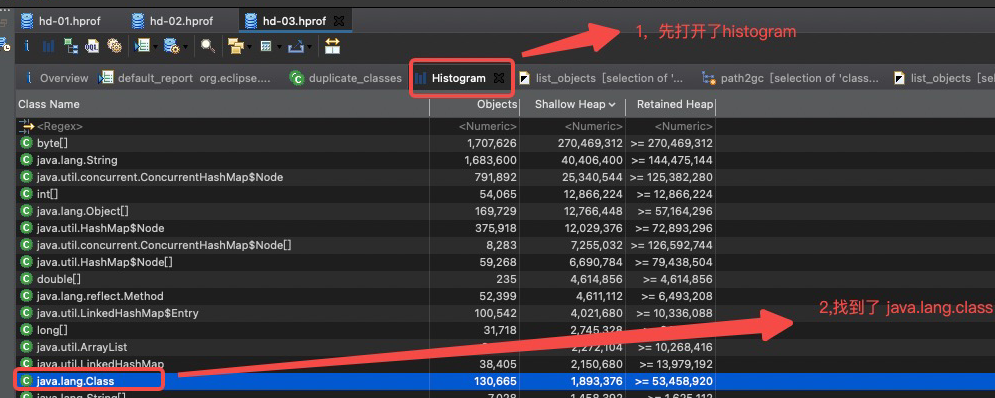
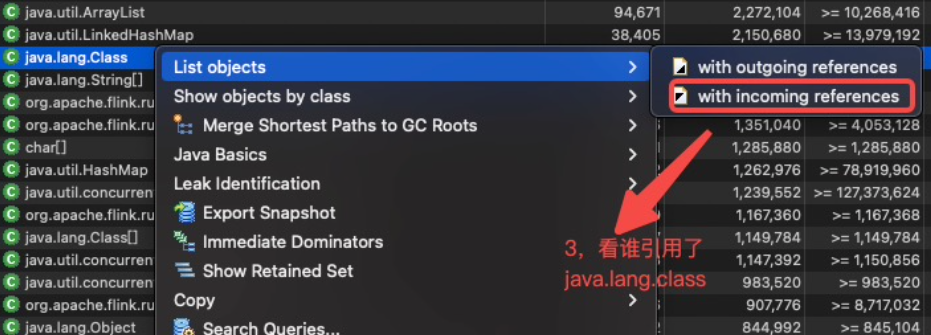
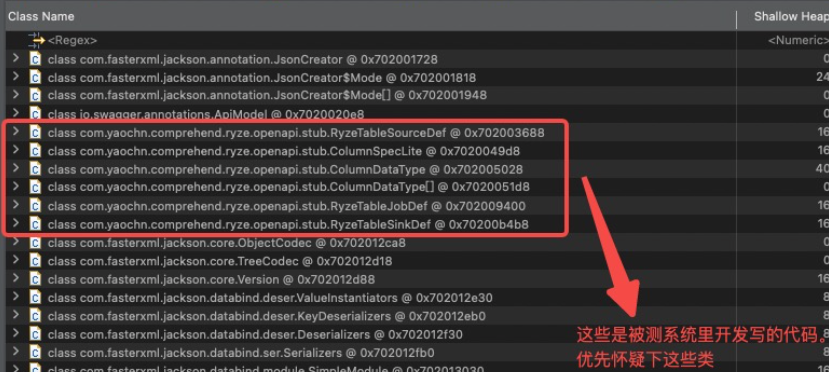
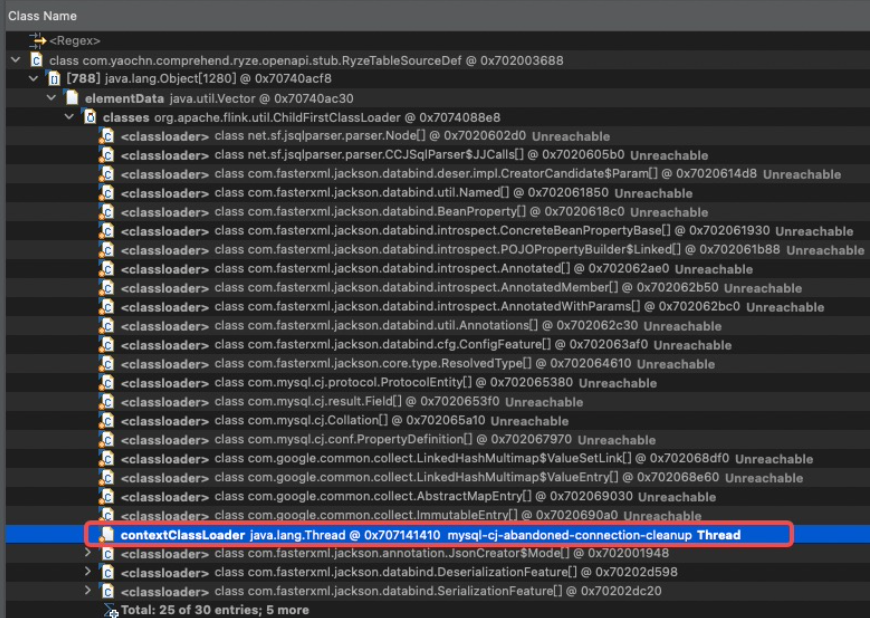
GC root可达的对象中,除了上面划出来的 mysql-cj-abandoned-connection-cleanup 线程
(查了下是用来关闭mysql conntction的 不关闭线程会一直被强引用占着 就没办法释放),
其他都是unreachable对象。
问了开发 开发说不合理。。。因为代码里 mysql的connection 是用try 括起来的,按理来说try结束了就退出了
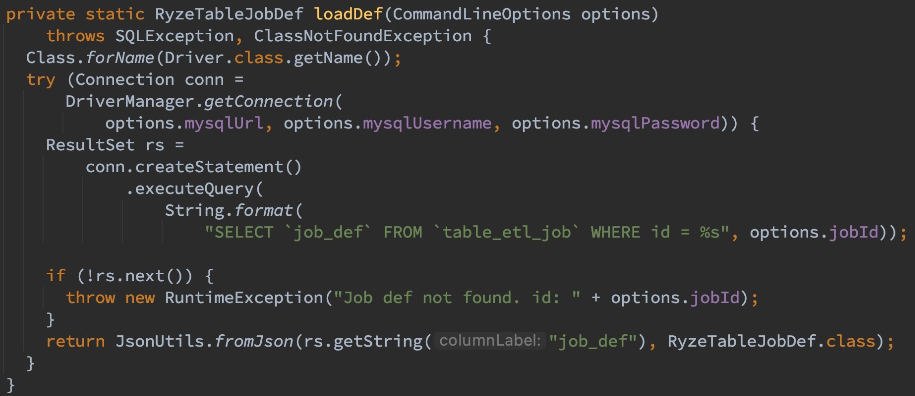
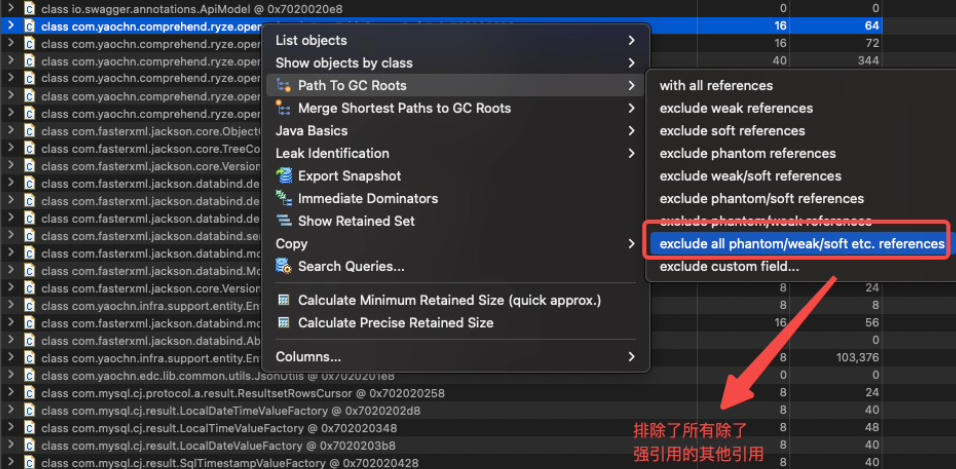
然后也获取了GC root 可达的最短路径:


然后再排序了下 retained heap 再查了一遍:
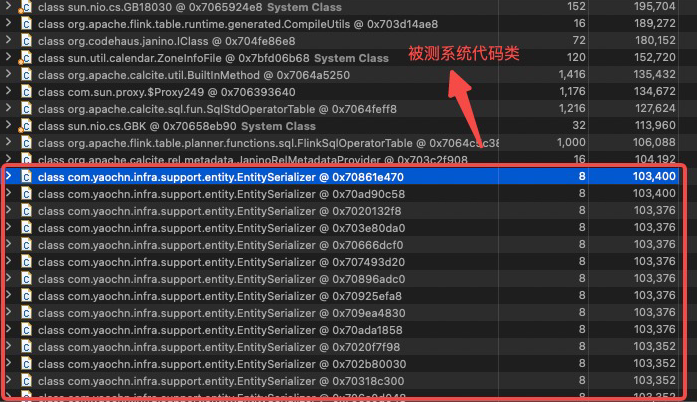
Path to GC root:
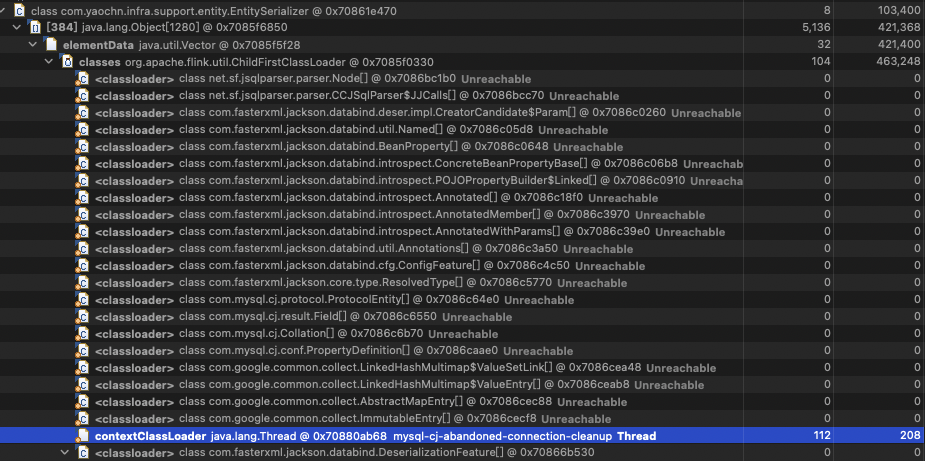
shortest Path to GC root:

heap dump文件及 gc日志链接:(其中有3份dump文件 是在metaspace 内存逐步上升的过程中分别dump的)
链接: https://pan.baidu.com/s/1RcTGhuCOxINqAnn6B_bkOQ 提取码: 8t8d
请求大佬的协助,分析的我人快麻了 T.T...

