
6回复
4年前
到达 Safepoint 时间长达 96 秒
虚拟机日志
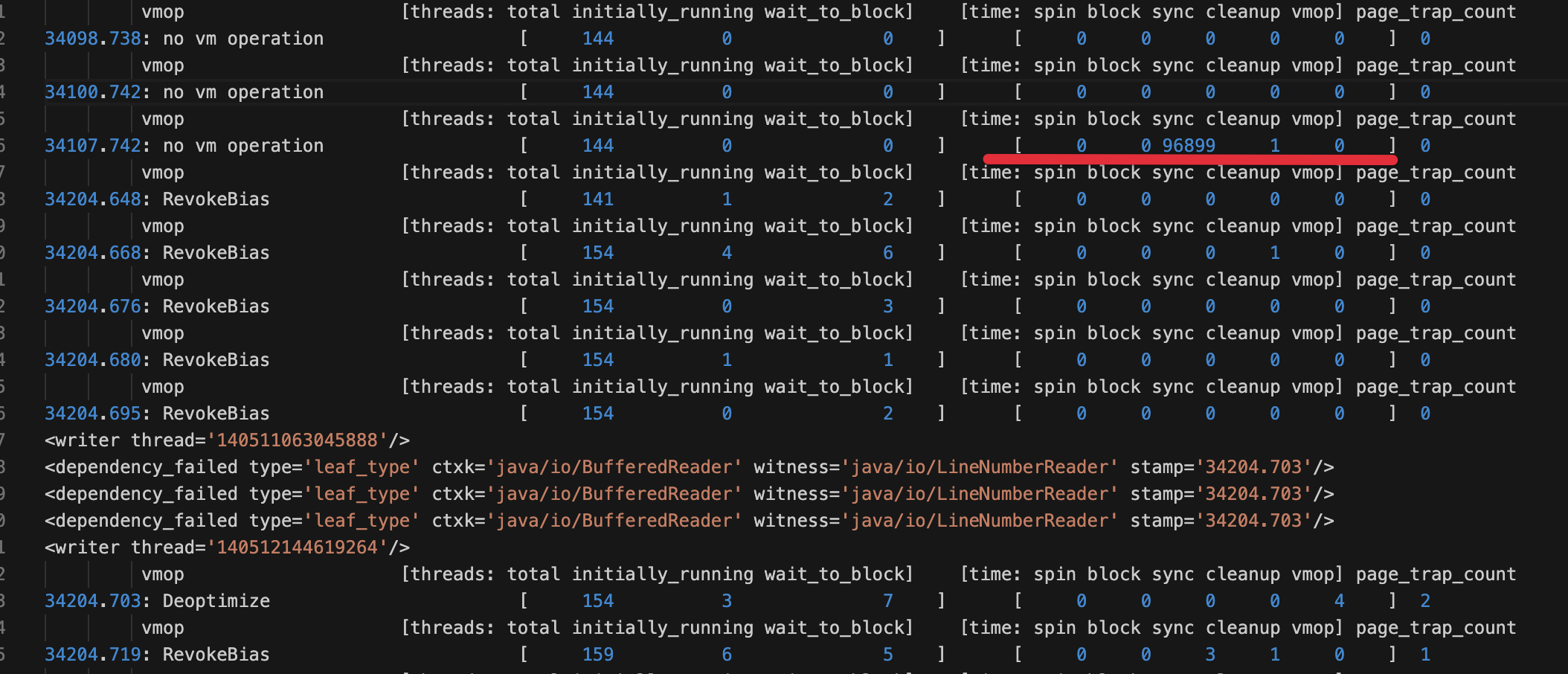
sync = spin + block + 其他
不知道“其他”是哪些因素导致的呢?
已经开启:
-XX:+SafepointTimeout -XX:SafepointTimeoutDelay=2000
但是没有打印出相关信息。
JVM 类型:
Java HotSpot(TM) 64-Bit Server VM (25.121-b13) for linux-amd64 JRE (1.8.0_121-b13)
虚拟机参数:
-Xms5529m -Xmx5529m -XX:MaxDirectMemorySize=2663m -XX:+PrintGCApplicationStoppedTime -XX:+PrintGCApplicationConcurrentTime -XX:+PrintGCDetails -XX:+PrintGCDateStamps -XX:+PrintGCTimeStamps -XX:+PrintPromotionFailure -XX:+PrintGCCause -XX:+PrintSafepointStatistics -XX:PrintSafepointStatisticsCount=1 -XX:+SafepointTimeout -XX:SafepointTimeoutDelay=2000
4642 阅读

