
日常Bug排查-偶发性读数据不一致原创
日常Bug排查-偶发性读数据不一致
前言
日常Bug排查系列都是一些简单Bug的排查。笔者将在这里介绍一些排查Bug的简单技巧,同时顺便积累素材。
Bug现场
业务场景
先描述这个问题出现的业务场景。这是一个支付的场景,如果支付成功了,我们就把支付状态置为success(主单据更新)同时写入支付成功时间戳为t1(子单据更新)。支付成功之后,我们还需要做其它的动作,做这个动作的时候我们需要刚才的支付成功时间戳t1。那么,我们正常的请求顺序即为:
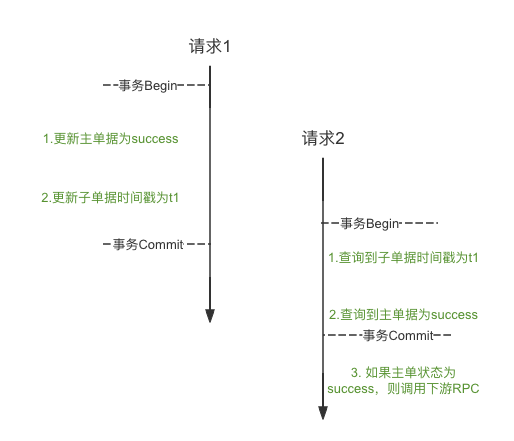
Bug现场
奇怪的是,线上运行时候,会有极小的概率(大概是几亿分之一)获取的这个时间戳为0!也即在读到主单为success的时候,看到的子单时间戳是0!由于时间戳为0,所以调用下游RPC传参错误导致了调用失败。
如下图所示:
![]
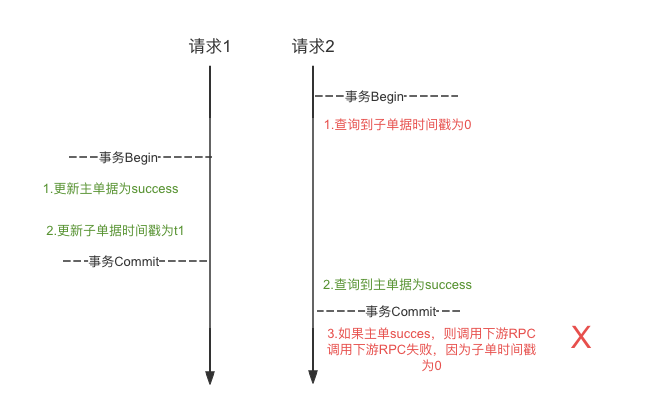
思路
因为在请求1中,我们是在事务内更新的,数据应该始终保持一致才对。那很直观的第一个思考点就是:
思路1: 是不是事务没生效?笔者看了下源代码,使用没有问题,也不存在类内方法互相调用的情况。再者说,如果事务没生效,概率不至于这么低。
思路2:稍加思索一下,好像这个是事务隔离级别的原因。在这个Case里面,看上去数据库采用的RC隔离级别,也就是读已提交。如下图所示:
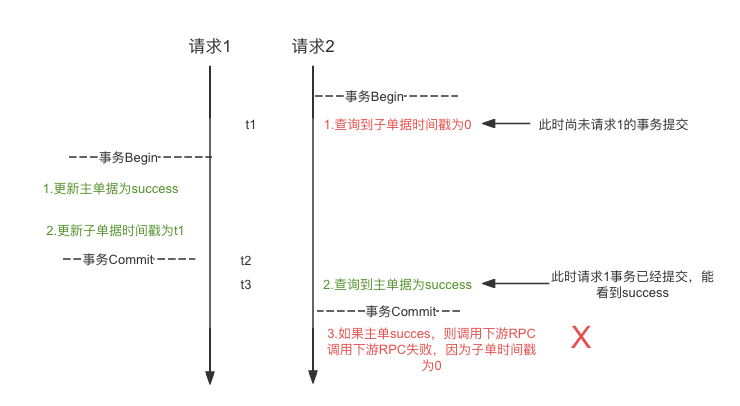
t1时刻,请求2查询到的子单据时间戳为0
t2时刻,请求1提交,这时候将子单据时间戳更新为t1,主单据状态为success
t3时刻,请求2由于RC隔离级别,能看到请求1的提交,主单状态为success,所以判定可以进行下游RPC的调用,但是由于在t1时刻获取到的时间戳为0,导致调用失败
矛盾点
数据库隔离级别是RC应该能非常好的解释出现Bug时的行为。于是笔者查了一下隔离级别,发现是RR,这就陷入了矛盾!但由于RC这个隔离级别解释这个Bug非常的靠谱,所以笔者看了下业务的数据库配置,发现它有100个库。那么就自然有了下一步猜想:这100个库中有的是RR的,有的是RC的。出问题的那个库正好就是RC的。
指定库查询隔离级别
于是笔者就根据业务的shardKey到了指定的库查询隔离级别,发现它果然是RC级别的,真相大白!这100个库中大概有1/3的库是RC隔离级别。
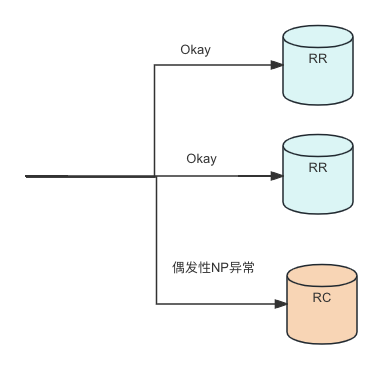
后续修复
这个问题是由于DBA在换库的过程中采用了默认的配置,导致原来设置为RR级别的库在换了大容量机器后被默认改成了RC隔离级别。DBA找了个时间将隔离级别切换回RR后问题就消失了,并编写了相应的巡检脚本防止此类问题再次发生。
总结
隔离级别是比较微妙的,相关问题大多只在高并发大流量下才会有偶发性的显现,分库分表集群中不同DB的隔离级别由于种种原因导致的不一致会加大问题的排查难度。有时候遇到无法解释问题时可以考虑下底层组件的设置问题。



