
数据库系列:使用高区分度索引列提升性能原创
数据库系列:MySQL慢查询分析和性能优化
数据库系列:MySQL索引优化总结(综合版)
数据库系列:高并发下的数据字段变更
1 背景
我们常常在创建组合索引的时候,会纠结一个问题,组合索引包含多个索引字段,它的顺序应该怎么放,怎样能达到更大的性能利用。
正确的索引字段顺序应该取决于使用该索引的查询的最高效率利用,并且同时需要考虑如何更好地满足排序和分组的需要。下面我们详细来说说。
2 索引检索的原理
以innodb为例子, innodb是MySQL默认的存储引擎,使用范围较广,而 innodb的数据组织结构是B+Tree模式。
B+Tree是在B-Tree基础上的一种优化,使其更适合实现外存储索引结构,InnoDB存储引擎就是用B+Tree实现其索引结构。
从上面的B-Tree结构图中可以看到每个节点中不仅包含数据的key值,还有data值。而每一个页的存储空间是有限的,如果data数据较大时将会导致每个节点(即一个页)能存储的key的数量很小,当存储的数据量很大时同样会导致B-Tree的深度较大,增大查询时的磁盘I/O次数,进而影响查询效率。在B+Tree中,所有数据记录节点都是按照键值大小顺序存放在同一层的叶子节点上,而非叶子节点上只存储key值信息,这样可以大大加大每个节点存储的key值数量,降低B+Tree的高度,提高查找效率。
B+Tree相比较于B-Tree的不同点:
1、非叶子节点只存储键值信息。
2、所有叶子节点之间都有一个链指针。
3、数据记录都存放在叶子节点中。
将上面的B-Tree优化,由于B+Tree的非叶子节点只存储键值信息,假设每个磁盘块能存储4个键值及指针信息,则变成B+Tree后其结构如下图所示:
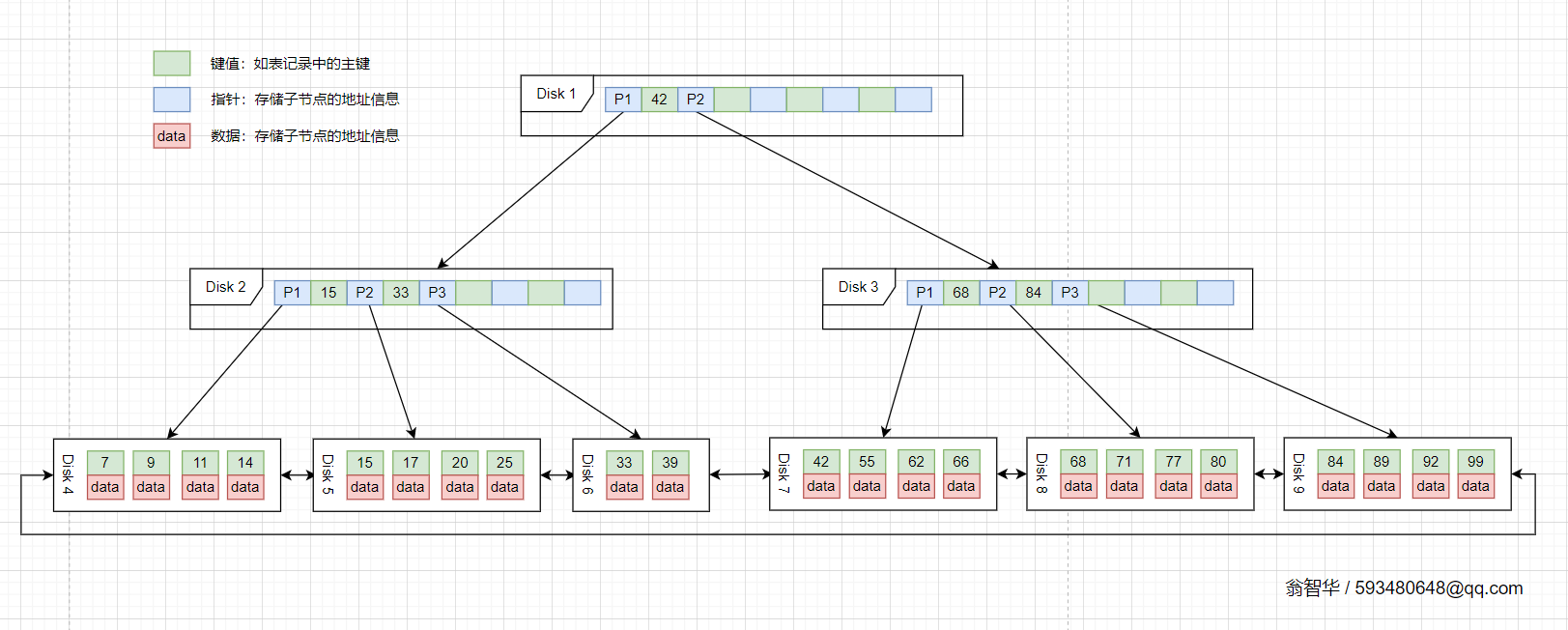
InnoDB存储引擎中页的大小为16KB,一般表的主键类型为INT(占用4个字节)或BIGINT(占用8个字节),指针类型也一般为4或8个字节,也就是说一个页(B+Tree中的一个节点)中大概存储16KB/(8B+8B)=1K个键值(因为是估值,为方便计算,这里的K取值为〖10〗^3 )。也就是说一个深度为3的B+Tree索引可以维护10^3 * 10^3 * 10^3 = 10亿 条记录。
★ 当你查找的数据越大的时候,存储的空间需求就越大,你这棵属树的深度也就越大,越往下搜索,IO次数越多,性能也就越差。
所以说,优质的索引是尽量压缩搜索次数,更快的查到数据结果为最佳。
索引的详细说明可以参考我得这一篇《MySQL全面瓦解23:MySQL索引实现和使用》
3 索引区分度的分析
3.1 索引区分度衡量策略
假设我们有一个500w数据容量的部门表 emp,想在 雇员名称 和 部门编号 这两个字段上做索引,哪个字段的索引区分度更高,执行效率更高呢?
下面以两个有序的数组为例子,都包含10条记录,分别代表 雇员名称 和 部门编号 的索引。
[<font color=“red”>ali</font> , brand , candy , david , ela , fin , gagn , halande , ivil , jay , kikol]
和
[dep-a , dep-a , dep-a , dep-a , <font color=“red”>dep-a</font>, dep-b , dep-b , dep-b , dep-b , dep-b]
如果要检索值为 empname =‘brand’ 和 depno=‘dep-b’ 的所有记录,哪个效率会高一点?
使用二分法查找执行步骤如下:
- 雇员名称查找
- 使用二分法找到最后一个小于指定值 <font color=“red”>brand</font>(就是上面数组中标红色的 <font color=“red”>ali</font> 的记录)
- 沿着这条记录向后扫描,和指定值 <font color=“red”>brand</font> 对比,直到遇到第一个大于指定值即结束,或者直到扫描完所有数据。
- 部门编号查找
- 使用二分法找到最后一个小于指定值 <font color=“red”>dep-b</font>(就是上面数组中标红色的 <font color=“red”>dep-a</font>的记录)
- 沿着这条记录向后扫描,和指定值 <font color=“red”>dep-b</font> 对比,直到遇到第一个大于指定值即结束,或者直到扫描完所有数据。
采用上面的方法找到需要检索的记录,第一个数组中更快的一些。因为第二个数组中含有dep-b的基数更大,需要访问和比较的次数也更多一点。
所以说区分度越高的。
举个例子就明白了,假如一个班级50名学生(25名男生、25名女生),所用性别作为索引字段,你需要扫描25次才能把数据完全扫出。
使用是学生姓名,就不需要计算那么多次。明显的过滤范围不是一个量级。
这种区分是有一种计算公式来衡量的:
selecttivity = count(distinct c_name)/count(*)
当索引区分度越高,检索速度越快,索引区分度低,则说明重复的数据比较多,检索的时候需要访问更多的记录才能够找到所有目标数据。
当索引区分度小到无限趋近于0的时候,基本等同于全表扫描了,此时检索效率肯定是慢的。
第一个数组没有重复数据,索引区分度为1,第二个区分度为0.2,所以第一个检索效率更高。
我们创建索引的时候,尽量选择区分度高的列作为索引,如果是组合索引,也尽量以区分度更高的排在前面。
3.2 真实数据对比
我们回过头来看看emp 表中的两个字段,empname 和 depno 字段,
empname基本不重复,所以每个empname只有一条数据;而 500W的数据大约分配了10个部门,所以每个的depno下有约50W的数据。
1 mysql> select count(distinct empname)/count(*),count(distinct depno)/count(*) from emp;
2 +----------------------------------+--------------------------------+
3 | count(distinct empname)/count(*) | count(distinct depno)/count(*) |
4 +----------------------------------+--------------------------------+
5 | 0.1713 | 0.0000 |
6 +----------------------------------+--------------------------------+
7 1 row in set
再看看两种不同组合索引查询的效率对比,耗时不是一个级别的
- 按照 empname,depno 组合
mysql> create index idx_emp_empname_depno on emp(empname,depno);
Query OK, 0 rows affected
Records: 0 Duplicates: 0 Warnings: 0
mysql> select * from emp where empname='LsHfFJA' and depno='106';
+---------+---------+---------+---------+-----+---------------------+------+------+-------+
| id | empno | empname | job | mgr | hiredate | sal | comn | depno |
+---------+---------+---------+---------+-----+---------------------+------+------+-------+
| 4582071 | 4582071 | LsHfFJA | SALEMAN | 1 | 2021-01-23 16:46:03 | 2000 | 400 | 106 |
+---------+---------+---------+---------+-----+---------------------+------+------+-------+
1 row in set (0.021 sec)
- 按照 depno,empname 组合
mysql> create index idx_emp_depno_empname on emp(depno,empname);
Query OK, 0 rows affected
Records: 0 Duplicates: 0 Warnings: 0
mysql> select * from emp where depno='106' and empname='LsHfFJA';
+---------+---------+---------+---------+-----+---------------------+------+------+-------+
| id | empno | empname | job | mgr | hiredate | sal | comn | depno |
+---------+---------+---------+---------+-----+---------------------+------+------+-------+
| 4582071 | 4582071 | LsHfFJA | SALEMAN | 1 | 2021-01-23 16:46:03 | 2000 | 400 | 106 |
+---------+---------+---------+---------+-----+---------------------+------+------+-------+
1 row in set (0.393 sec)
4 总结
匹配度分析和基数容量的计算法则是非常值得借鉴的,但在真实的环境下,查询的复杂度要高的多,WHERE子句中的排序、分组和范围条件等其他因素,都可能对查询的性能造成非常大的影响。后面我们结合实际的排序、分组、范围条件变化的情况来做更深入的分析。


