一文讲透消息队列RocketMQ实现消费幂等原创
这篇文章,我们聊聊消息队列中非常重要的最佳实践之一:消费幂等。

1 基础概念
消费幂等是指:当出现 RocketMQ 消费者对某条消息重复消费的情况时,重复消费的结果与消费一次的结果是相同的,并且多次消费并未对业务系统产生任何负面影响。
例如,在支付场景下,消费者消费扣款消息,对一笔订单执行扣款操作,扣款金额为100元。
如果因网络不稳定等原因导致扣款消息重复投递,消费者重复消费了该扣款消息,但最终的业务结果是只扣款一次,扣费100元,且用户的扣款记录中对应的订单只有一条扣款流水,不会多次扣除费用。那么这次扣款操作是符合要求的,整个消费过程实现了消费幂等。
2 适用场景
RocketMQ 消息重复的场景如下:
-
发送时消息重复
当一条消息已被成功发送到服务端并完成持久化,此时出现了网络闪断或者客户端宕机,导致服务端对客户端应答失败。
如果此时生产者意识到消息发送失败并尝试再次发送消息,消费者后续会收到两条内容相同但 Message ID 不同的消息。
-
投递时消息重复
消息消费的场景下,消息已投递到消费者并完成业务处理,当客户端给服务端反馈应答的时候网络闪断。为了保证消息至少被消费一次,Broker 服务端将在网络恢复后再次尝试投递之前已被处理过的消息,消费者后续会收到两条内容相同并且 Message ID 也相同的消息。
-
负载均衡时消息重复(包括但不限于网络抖动、Broker 重启以及消费者应用重启)
Broker 端或客户端重启、扩容或缩容时,会触发 Rebalance ,此时消费者可能会收到少量重复消息。
3 业务唯一标识
因为不同的 Message ID 对应的消息内容可能相同,有可能出现冲突(重复)的情况,所以真正安全的幂等处理,不建议以 Message ID 作为处理依据。
最好的方式是以业务唯一标识作为幂等处理的关键依据,消息必须携带业务唯一标识。
消息携带业务唯一标识一般来讲有两种方式:
- 消息 Key 存放业务唯一标识
Message msg = new Message(TOPIC /* Topic */,
TAG /* Tag */,
("Hello RocketMQ " + i).getBytes(RemotingHelper.DEFAULT_CHARSET) /* Message body */
);
message.setKey("ORDERID_100"); // 订单编号
SendResult sendResult = producer.send(message);
- 消息 body 存放业务唯一标识
Message msg = new Message(TOPIC /* Topic */,
TAG /* Tag */,
(JSON.toJSONString(orderDTO)).getBytes(RemotingHelper.DEFAULT_CHARSET) /* Message body */
);
message.setKey("ORDERID_100"); // 订单编号
SendResult sendResult = producer.send(message);
消费者收到消息时,从消息中获取订单号来实现消息幂等 :
consumer.registerMessageListener(new MessageListenerConcurrently() {
@Override
public ConsumeConcurrentlyStatus consumeMessage(List<MessageExt> msgs, ConsumeConcurrentlyContext context) {
for (MessageExt message : msgs) {
// 方法1: 根据业务唯一标识的Key做幂等处理
String orderId = message.getKeys();
// 方法2: 从消息body体重解析出订单号
String orderJSON = new String(messageExt.getBody(), "UTF-8");
OrderPO orderPO = JSON.parseObject(orderJSON, OrderPO.class);
String orderId = orderPO.getId();
// TODO 业务处理逻辑
}
return ConsumeConcurrentlyStatus.CONSUME_SUCCESS;
}
});
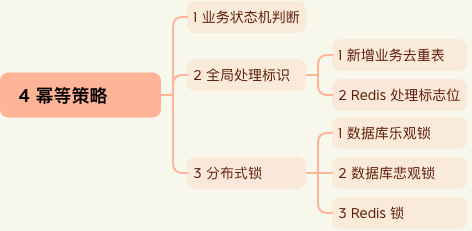
4 幂等策略
1 业务状态机判断
为了保证幂等,一定要做业务逻辑判断,笔者认为这是保证幂等的首要条件。
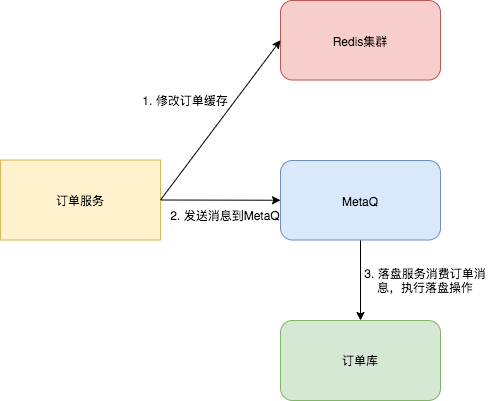
笔者曾经服务于神州专车,乘客在用户端点击立即叫车,订单服务创建订单,首先保存到数据库后,然后将订单信息同步保存到缓存中。
在订单的载客生命周期里,订单的修改操作先修改缓存,然后发送消息到<strong style=“font-size: inherit;line-height: inherit;color: rgb(255, 104, 39);”> MetaQ </strong>,订单落盘服务消费消息,并判断订单信息是否正常(比如有无乱序),若订单数据无误,则存储到数据库中。
订单状态机按顺序分别是:创建、已分配司机、司机已出发、司机已到达、司机已接到乘客、已到达。
这种设计是为了快速提升系统性能,由于网络问题有非常小的概率,消费者会收到乱序的消息。
当订单状态是司机已到达时,消费者可能会收到司机已出发的消息,也就是先发的消息因为网络原因被延迟消费了。
此时,消费者需要判断当前的专车订单状态机,保存最合理的订单数据,就可以忽略旧的消息,打印相关日志即可。
2 全局处理标识
1 数据库去重表
数据库去重表有两个要点 :
- 操作之前先从去重表中通过唯一业务标识查询记录是否存在,若不存在,则进行后续消费流程 ;
- 为了避免并发场景,去重表需要包含业务唯一键 uniqueKey , 这样就算并发插入也不可能插入多条,插入失败后,抛异常。
举一个电商场景的例子:用户购物车结算时,系统会创建支付订单。用户支付成功后支付订单的状态会由未支付修改为支付成功,然后系统给用户增加积分。
我们可以使用 RocketMQ 事务消息的方案,该方案能够发挥 MQ 的优势:异步和解耦,以及事务的最终一致性的特性。
在消费监听器逻辑里,幂等非常重要 。积分表 SQL 如下:
CREATE TABLE `t_points` (
`id` bigint(20) NOT NULL COMMENT '主键',
`user_id` bigint(20) NOT NULL COMMENT '用户id',
`order_id` bigint(20) NOT NULL COMMENT '订单编号',
`points` int(4) NOT NULL COMMENT '积分',
`remarks` varchar(128) COLLATE utf8mb4_bin NOT NULL COMMENT '备注',
`create_time` datetime NOT NULL,
PRIMARY KEY (`id`),
UNIQUE KEY `unique_order_Id` (`order_id`) USING BTREE COMMENT '订单唯一'
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin;
当收到订单信息后,首先判断该订单是否有积分记录,若没有记录,才插入积分记录。
就算出现极端并发场景下,订单编号也是唯一键,数据库中也必然不会存在相同订单的多条积分记录。
public ConsumeConcurrentlyStatus consumeMessage(List<MessageExt> msgs, ConsumeConcurrentlyContext context) {
try {
for (MessageExt messageExt : msgs) {
String orderJSON = new String(messageExt.getBody(), "UTF-8");
logger.info("orderJSON:" + orderJSON);
OrderPO orderPO = JSON.parseObject(orderJSON, OrderPO.class);
// 首先查询是否处理完成
PointsPO pointsPO = pointsMapper.getByOrderId(orderPO.getId());
if (pointsPO == null) {
Long id = SnowFlakeIdGenerator.getUniqueId(1023, 0);
pointsPO = new PointsPO();
pointsPO.setId(id);
pointsPO.setOrderId(orderPO.getId());
pointsPO.setUserId(orderPO.getUserId());
// 添加积分数 30
pointsPO.setPoints(30);
pointsPO.setCreateTime(new Date());
pointsPO.setRemarks("添加积分数 30");
pointsMapper.insert(pointsPO);
}
}
return ConsumeConcurrentlyStatus.CONSUME_SUCCESS;
} catch (Exception e) {
logger.error("consumeMessage error: ", e);
return ConsumeConcurrentlyStatus.RECONSUME_LATER;
}
}
2 Redis处理标志位
在消费者接收到消息后,首先判断 Redis 中是否存在该业务主键的标志位,若存在标志位,则认为消费成功,否则,则执行业务逻辑,执行完成后,在缓存中添加标志位。
public ConsumeConcurrentlyStatus consumeMessage(List<MessageExt> msgs, ConsumeConcurrentlyContext context) {
try {
for (MessageExt messageExt : msgs) {
String bizKey = messageExt.getKeys(); // 唯一业务主键
//1. 判断是否存在标志
if(redisTemplate.hasKey(RedisKeyConstants.WAITING_SEND_LOCK + bizKey)) {
continue;
}
//2. 执行业务逻辑
//TODO do business
//3. 设置标志位
redisTemplate.opsForValue().set(RedisKeyConstants.WAITING_SEND_LOCK + bizKey, "1", 72, TimeUnit.HOURS);
}
return ConsumeConcurrentlyStatus.CONSUME_SUCCESS;
} catch (Exception e) {
logger.error("consumeMessage error: ", e);
return ConsumeConcurrentlyStatus.RECONSUME_LATER;
}
}
3 分布式锁
仅仅有业务逻辑判断是不够的,为了应对并发场景,我们可以使用分布式锁。
分布式锁一般有三种方案:
- 数据库乐观锁
- 数据库悲观锁
- Redis 锁
1 数据库乐观锁
数据乐观锁假设认为数据一般情况下不会造成冲突,所以在数据进行提交更新的时候,才会正式对数据的冲突与否进行检测,如果发现冲突了,则让返回用户错误的信息,让用户决定如何去做。
由于乐观锁没有了锁等待,提高了吞吐量,所以乐观锁适合读多写少的场景。
实现乐观锁:一般是在数据表中加上一个数据版本号 version 字段,表示数据被修改的次数,当数据被修改时,version 值会加一。
当线程 A 要更新数据值时,在读取数据的同时也会读取version值,在提交更新时,若刚才读取到的 version 值为当前数据库中的 version 值相等时才更新,否则重试更新操作,直到更新成功。
步骤 1 : 查询出条目数据
select version from my_table where id = #{id}
步骤 2 :修改条目数据,传递版本参数
update my_table set n = n + 1, version = version + 1 where id=#{id} and version = #{version};
从乐观锁的实现角度来讲,乐观锁非常容易实现,但它有两个缺点:
- 对业务的侵入性,添加版本字段;
- 高并发场景下,只有一个线程可以修改成功,那么就会存在大量的失败 。
消费端演示代码如下:
public ConsumeConcurrentlyStatus consumeMessage(List<MessageExt> msgs, ConsumeConcurrentlyContext context) {
try {
for (MessageExt messageExt : msgs) {
String orderJSON = new String(messageExt.getBody(), "UTF-8");
OrderPO orderPO = JSON.parseObject(orderJSON, OrderPO.class);
Long version = orderMapper.selectVersionByOrderId(orderPO.getId()); //版本
orderPO.setVersion(version);
// 对应 SQL:update t_order t set version = version + 1 , status = #{status} where id = #{id}
// and version = #{version}
int affectedCount = orderMapper.updateOrder(orderPO);
if(affectedCount == 0) {
return ConsumeConcurrentlyStatus.RECONSUME_LATER;
}
}
return ConsumeConcurrentlyStatus.CONSUME_SUCCESS;
} catch (Exception e) {
logger.error("consumeMessage error: ", e);
return ConsumeConcurrentlyStatus.RECONSUME_LATER;
}
}
2 数据库悲观锁
当我们要对一个数据库中的一条数据进行修改的时候,为了避免同时被其他人修改,最好的办法就是直接对该数据进行加锁以防止并发。
这种借助数据库锁机制在修改数据之前先锁定,再修改的方式被称之为悲观并发控制(又名“悲观锁”,Pessimistic Concurrency Control,缩写“PCC”)。
之所以叫做悲观锁,是因为这是一种对数据的修改抱有悲观态度的并发控制方式。我们一般认为数据被并发修改的概率比较大,所以需要在修改之前先加锁。
悲观并发控制实际上是**“先取锁再访问”的保守策略**,为数据处理的安全提供了保证。
MySQL 悲观锁的使用方法如下:
begin;
-- 读取数据并加锁
select ... for update;
-- 修改数据
update ...;
commit;
例如,以下代码将读取 t_order 表中 id 为 1 的记录,并将该记录的 status 字段修改为 3:
begin;
select * from t_order where id = 1 for update;
update t_order set status = '3' where id = 1;
commit;
如果 t_order 表中 id 为 1 的记录正在被其他事务修改,则上述代码会等待该记录被释放锁后才能继续执行。
消费端演示代码如下:
public ConsumeConcurrentlyStatus consumeMessage(List<MessageExt> msgs, ConsumeConcurrentlyContext context) {
try {
for (MessageExt messageExt : msgs) {
String orderJSON = new String(messageExt.getBody(), "UTF-8");
OrderPO orderPO = JSON.parseObject(orderJSON, OrderPO.class);
Long orderId = orderPo.getId();
//调用service的修改订单信息,该方法事务加锁, 当修改订单记录时,该其他线程会等待该记录被释放才能继续执行
orderService.updateOrderForUpdate(orderId ,orderPO);
}
return ConsumeConcurrentlyStatus.CONSUME_SUCCESS;
} catch (Exception e) {
logger.error("consumeMessage error: ", e);
return ConsumeConcurrentlyStatus.RECONSUME_LATER;
}
}
3 Redis锁
使用数据库锁是非常重的一个操作,我们可以使用更轻量级的 Redis 锁来替换,因为 Redis 性能高,同时有非常丰富的生态(类库)支持不同类型的分布式锁。
我们选择 Redisson 框架提供的分布式锁功能,简化的示例代码如下:
public ConsumeConcurrentlyStatus consumeMessage(List<MessageExt> msgs, ConsumeConcurrentlyContext context) {
try {
for (MessageExt messageExt : msgs) {
String orderJSON = new String(messageExt.getBody(), "UTF-8");
OrderPO orderPO = JSON.parseObject(orderJSON, OrderPO.class);
Long orderId = orderPo.getId();
RLock lock = redissonClient.getLock("order-lock-" + orderId);
rLock.lock(10, TimeUnit.SECONDS);
// TODO 业务逻辑
rLock.unlock();
}
return ConsumeConcurrentlyStatus.CONSUME_SUCCESS;
} catch (Exception e) {
logger.error("consumeMessage error: ", e);
return ConsumeConcurrentlyStatus.RECONSUME_LATER;
}
}
5 总结
这篇文章,我们详细剖析了如何实现 RocketMQ 消费幂等。
1、消费幂等:当出现 RocketMQ 消费者对某条消息重复消费的情况时,重复消费的结果与消费一次的结果是相同的,并且多次消费并未对业务系统产生任何负面影响。
2、适用场景:发送时消息重复、投递时消息重复、负载均衡时消息重复
3、业务唯一标识:以业务唯一标识作为幂等处理的关键依据,消息必须携带业务唯一标识。
4、幂等策略:业务逻辑代码中需要判断业务状态机,同时根据实际条件选择全局处理标识和分布式锁两种方式处理。