
理解 RocketMQ 消息轨迹,看这一篇就够了原创
这篇文章,我们聊一聊 RocketMQ 的消息轨迹设计思路。
查询消息轨迹可作为生产环境中排查问题强有力的数据支持 ,也是研发同学解决线上问题的重要武器之一。
1 基础概念
消息轨迹是指一条消息从生产者发送到 Broker , 再到消费者消费,整个过程中的各个相关节点的时间、状态等数据汇聚而成的完整链路信息。
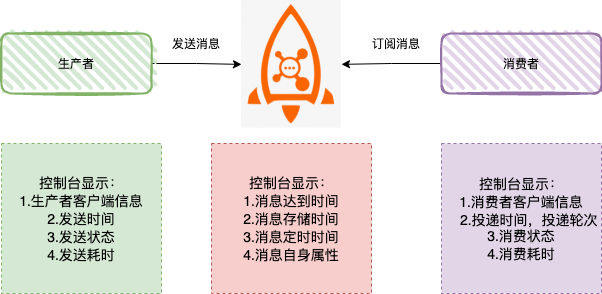
当我们需要查询消息轨迹时,需要明白一点:消息轨迹数据是存储在 Broker 服务端,我们需要定义一个主题,在生产者,消费者端定义轨迹钩子。
2 开启轨迹
2.1 修改 Broker 配置文件
# 开启消息轨迹
traceTopicEnable=true
2.2 生产者配置
public DefaultMQProducer(final String producerGroup, boolean enableMsgTrace)
public DefaultMQProducer(final String producerGroup, boolean enableMsgTrace, final String customizedTraceTopic)
在生产者的构造函数里,有两个核心参数:
- enableMsgTrace:是否开启消息轨迹
- customizedTraceTopic:记录消息轨迹的 Topic , 默认是:
RMQ_SYS_TRACE_TOPIC。
执行如下的生产者代码:
public class Producer {
public static final String PRODUCER_GROUP = "mytestGroup";
public static final String DEFAULT_NAMESRVADDR = "127.0.0.1:9876";
public static final String TOPIC = "example";
public static final String TAG = "TagA";
public static void main(String[] args) throws MQClientException, InterruptedException {
DefaultMQProducer producer = new DefaultMQProducer(PRODUCER_GROUP, true);
producer.setNamesrvAddr(DEFAULT_NAMESRVADDR);
producer.start();
try {
String key = UUID.randomUUID().toString();
System.out.println(key);
Message msg = new Message(
TOPIC,
TAG,
key,
("Hello RocketMQ ").getBytes(RemotingHelper.DEFAULT_CHARSET));
SendResult sendResult = producer.send(msg);
System.out.printf("%s%n", sendResult);
} catch (Exception e) {
e.printStackTrace();
}
// 这里休眠十秒,是为了异步发送轨迹消息成功。
Thread.sleep(10000);
producer.shutdown();
}
}
在生产者代码中,我们指定了消息的 key 属性, 便于对于消息进行高性能检索。
执行成功之后,我们从控制台查看轨迹信息。
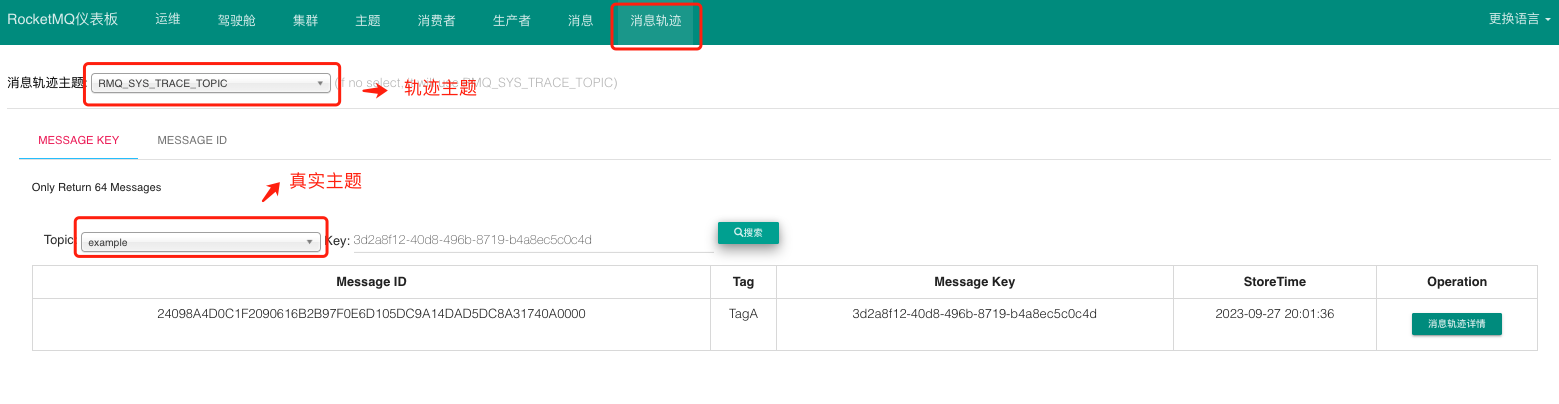
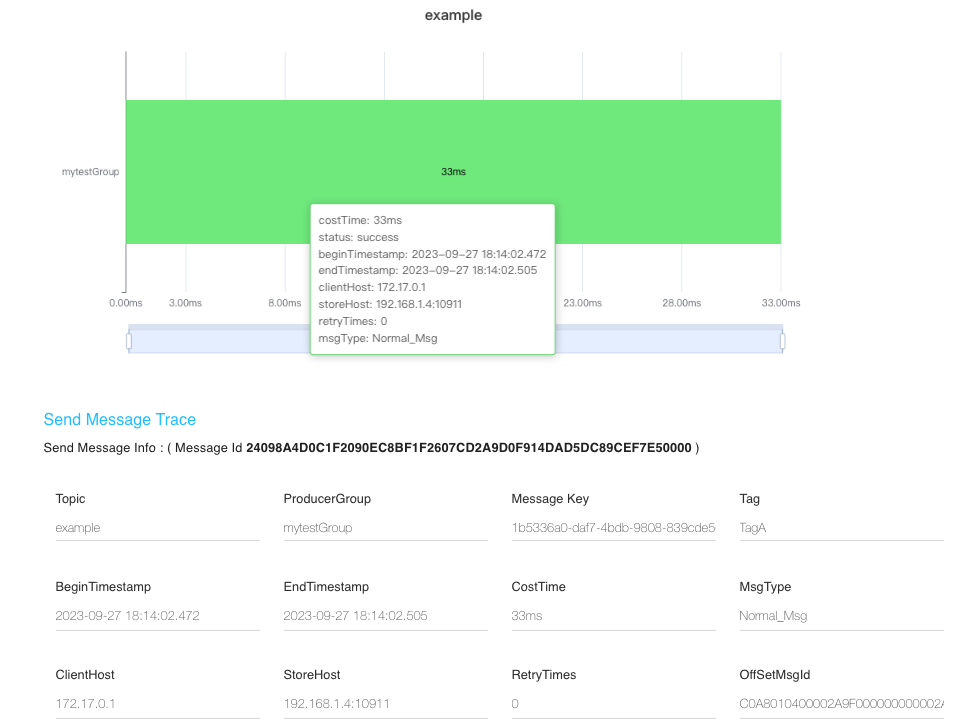
从图中可以看到,消息轨迹中存储了消息的 存储时间 、 存储服务器IP 、发送耗时 。
2.3 消费者配置
和生产者类似,消费者的构造函数可以传递轨迹参数:
public DefaultMQPushConsumer(final String consumerGroup, boolean enableMsgTrace);
public DefaultMQPushConsumer(final String consumerGroup, boolean enableMsgTrace, final String customizedTraceTopic);
执行如下的消费者代码:
public class Consumer {
public static final String CONSUMER_GROUP = "exampleGruop";
public static final String DEFAULT_NAMESRVADDR = "127.0.0.1:9876";
public static final String TOPIC = "example";
public static void main(String[] args) throws InterruptedException, MQClientException {
DefaultMQPushConsumer consumer = new DefaultMQPushConsumer(CONSUMER_GROUP , true);
consumer.setNamesrvAddr(DEFAULT_NAMESRVADDR);
consumer.setConsumeFromWhere(ConsumeFromWhere.CONSUME_FROM_FIRST_OFFSET);
consumer.subscribe(TOPIC, "*");
consumer.registerMessageListener((MessageListenerConcurrently) (msg, context) -> {
System.out.printf("%s Receive New Messages: %s %n", Thread.currentThread().getName(), msg);
return ConsumeConcurrentlyStatus.CONSUME_SUCCESS;
});
consumer.start();
System.out.printf("Consumer Started.%n");
}
}
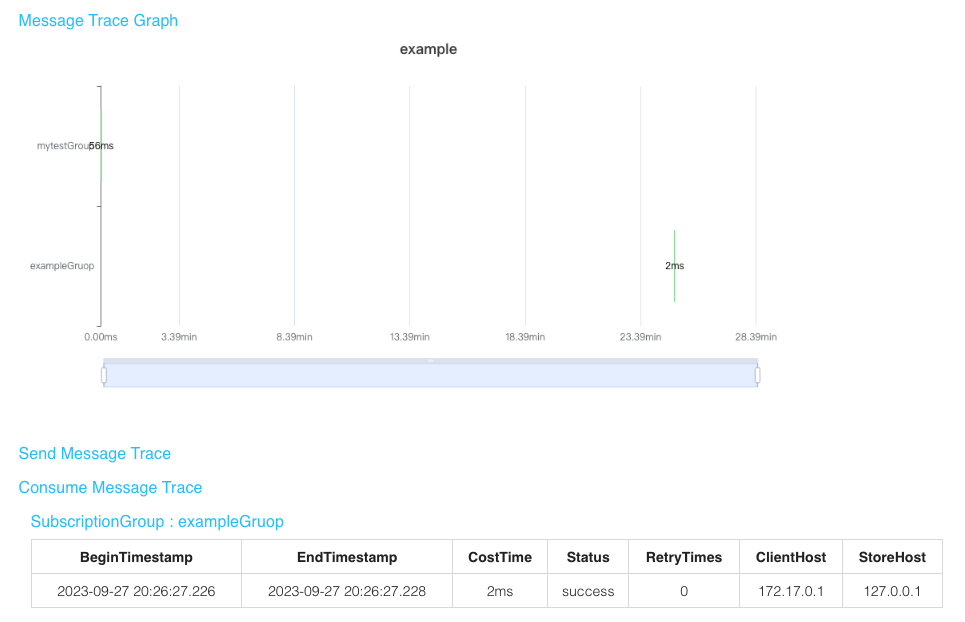
3 实现原理
轨迹的实现原理主要是在生产者发送、消费者消费时添加相关的钩子。 因此,我们只需要了解钩子的实现逻辑即可。
下面的代码是 DefaultMQProducer 的构造函数。
public DefaultMQProducer(final String namespace, final String producerGroup, RPCHook rpcHook,
boolean enableMsgTrace, final String customizedTraceTopic) {
this.namespace = namespace;
this.producerGroup = producerGroup;
defaultMQProducerImpl = new DefaultMQProducerImpl(this, rpcHook);
// if client open the message trace feature
if (enableMsgTrace) {
try {
//异步轨迹分发器
AsyncTraceDispatcher dispatcher = new AsyncTraceDispatcher(producerGroup, TraceDispatcher.Type.PRODUCE, customizedTraceTopic, rpcHook);
dispatcher.setHostProducer(this.defaultMQProducerImpl);
traceDispatcher = dispatcher;
// 发送消息时添加执行钩子
this.defaultMQProducerImpl.registerSendMessageHook(
new SendMessageTraceHookImpl(traceDispatcher));
// 结束事务时添加执行钩子
this.defaultMQProducerImpl.registerEndTransactionHook(
new EndTransactionTraceHookImpl(traceDispatcher));
} catch (Throwable e) {
log.error("system mqtrace hook init failed ,maybe can't send msg trace data");
}
}
}
当是否开启轨迹开关打开时,创建异步轨迹分发器 AsyncTraceDispatcher ,然后给默认的生产者实现类在发送消息的钩子 SendMessageTraceHookImpl。
//发送消息时添加执行钩子
this.defaultMQProducerImpl.registerSendMessageHook(new SendMessageTraceHookImpl(traceDispatcher));
我们把生产者发送消息的流程简化如下代码 :
//DefaultMQProducerImpl#sendKernelImpl
this.executeSendMessageHookBefore(context);
// 发生消息
this.mQClientFactory.getMQClientAPIImpl().sendMessage(....)
// 生产者发送消息后会执行
this.executeSendMessageHookAfter(context);
进入SendMessageTraceHookImpl 类 ,该类主要有两个方法 sendMessageBefore 和 sendMessageAfter 。
1、sendMessageBefore 方法
public void sendMessageBefore(SendMessageContext context) {
//if it is message trace data,then it doesn't recorded
if (context == null || context.getMessage().getTopic().startsWith(((AsyncTraceDispatcher) localDispatcher).getTraceTopicName())) {
return;
}
//build the context content of TuxeTraceContext
TraceContext tuxeContext = new TraceContext();
tuxeContext.setTraceBeans(new ArrayList<TraceBean>(1));
context.setMqTraceContext(tuxeContext);
tuxeContext.setTraceType(TraceType.Pub);
tuxeContext.setGroupName(NamespaceUtil.withoutNamespace(context.getProducerGroup()));
//build the data bean object of message trace
TraceBean traceBean = new TraceBean();
traceBean.setTopic(NamespaceUtil.withoutNamespace(context.getMessage().getTopic()));
traceBean.setTags(context.getMessage().getTags());
traceBean.setKeys(context.getMessage().getKeys());
traceBean.setStoreHost(context.getBrokerAddr());
traceBean.setBodyLength(context.getMessage().getBody().length);
traceBean.setMsgType(context.getMsgType());
tuxeContext.getTraceBeans().add(traceBean);
}
发送消息之前,先收集消息的 topic 、tag、key 、存储 Broker 的 IP 地址、消息体的长度等基础信息,并将消息轨迹数据存储在调用上下文中。
2、sendMessageAfter 方法
public void sendMessageAfter(SendMessageContext context) {
// ...省略部分代码
TraceContext tuxeContext = (TraceContext) context.getMqTraceContext();
TraceBean traceBean = tuxeContext.getTraceBeans().get(0);
int costTime = (int) ((System.currentTimeMillis() - tuxeContext.getTimeStamp()) / tuxeContext.getTraceBeans().size());
tuxeContext.setCostTime(costTime);
if (context.getSendResult().getSendStatus().equals(SendStatus.SEND_OK)) {
tuxeContext.setSuccess(true);
} else {
tuxeContext.setSuccess(false);
}
tuxeContext.setRegionId(context.getSendResult().getRegionId());
traceBean.setMsgId(context.getSendResult().getMsgId());
traceBean.setOffsetMsgId(context.getSendResult().getOffsetMsgId());
traceBean.setStoreTime(tuxeContext.getTimeStamp() + costTime / 2);
localDispatcher.append(tuxeContext);
}
跟踪对象里会保存 costTime (消息发送时间)、success (是否发送成功)、regionId (发送到 Broker 所在的分区) 、 msgId (消息 ID,全局唯一)、offsetMsgId (消息物理偏移量) ,storeTime (存储时间 ) 。
存储时间并没有取消息的实际存储时间,而是估算出来的:客户端发送时间的一般的耗时表示消息的存储时间。
最后将跟踪上下文添加到本地轨迹分发器:
localDispatcher.append(tuxeContext);
下面我们分析下轨迹分发器的原理:
public AsyncTraceDispatcher(String group, Type type, String traceTopicName, RPCHook rpcHook) {
// 省略代码 ....
this.traceContextQueue = new ArrayBlockingQueue<TraceContext>(1024);
this.appenderQueue = new ArrayBlockingQueue<Runnable>(queueSize);
if (!UtilAll.isBlank(traceTopicName)) {
this.traceTopicName = traceTopicName;
} else {
this.traceTopicName = TopicValidator.RMQ_SYS_TRACE_TOPIC;
}
this.traceExecutor = new ThreadPoolExecutor(//
10,
20,
1000 * 60,
TimeUnit.MILLISECONDS,
this.appenderQueue,
new ThreadFactoryImpl("MQTraceSendThread_"));
traceProducer = getAndCreateTraceProducer(rpcHook);
}
public void start(String nameSrvAddr, AccessChannel accessChannel) throws MQClientException {
if (isStarted.compareAndSet(false, true)) {
traceProducer.setNamesrvAddr(nameSrvAddr);
traceProducer.setInstanceName(TRACE_INSTANCE_NAME + "_" + nameSrvAddr);
traceProducer.start();
}
this.accessChannel = accessChannel;
this.worker = new Thread(new AsyncRunnable(), "MQ-AsyncTraceDispatcher-Thread-" + dispatcherId);
this.worker.setDaemon(true);
this.worker.start();
this.registerShutDownHook();
}
上面的代码展示了分发器的构造函数和启动方法,构造函数创建了一个发送消息的线程池 traceExecutor ,启动 start 后会启动一个 worker线程。
class AsyncRunnable implements Runnable {
private boolean stopped;
@Override
public void run() {
while (!stopped) {
synchronized (traceContextQueue) {
long endTime = System.currentTimeMillis() + pollingTimeMil;
while (System.currentTimeMillis() < endTime) {
try {
TraceContext traceContext = traceContextQueue.poll(
endTime - System.currentTimeMillis(), TimeUnit.MILLISECONDS
);
if (traceContext != null && !traceContext.getTraceBeans().isEmpty()) {
// get the topic which the trace message will send to
String traceTopicName = this.getTraceTopicName(traceContext.getRegionId());
// get the traceDataSegment which will save this trace message, create if null
TraceDataSegment traceDataSegment = taskQueueByTopic.get(traceTopicName);
if (traceDataSegment == null) {
traceDataSegment = new TraceDataSegment(traceTopicName, traceContext.getRegionId());
taskQueueByTopic.put(traceTopicName, traceDataSegment);
}
// encode traceContext and save it into traceDataSegment
// NOTE if data size in traceDataSegment more than maxMsgSize,
// a AsyncDataSendTask will be created and submitted
TraceTransferBean traceTransferBean = TraceDataEncoder.encoderFromContextBean(traceContext);
traceDataSegment.addTraceTransferBean(traceTransferBean);
}
} catch (InterruptedException ignore) {
log.debug("traceContextQueue#poll exception");
}
}
// NOTE send the data in traceDataSegment which the first TraceTransferBean
// is longer than waitTimeThreshold
sendDataByTimeThreshold();
if (AsyncTraceDispatcher.this.stopped) {
this.stopped = true;
}
}
}
}
worker 启动后,会从轨迹上下文队列 traceContextQueue 中不断的取出轨迹上下文,并将上下文转换成轨迹数据片段 TraceDataSegment 。
为了提升系统的性能,并不是每一次从队列中获取到数据就直接发送到 MQ ,而是积累到一定程度的临界点才触发这个操作,我们可以简单的理解为批量操作。
这里面有两个维度 :
-
轨迹数据片段的数据大小大于某个数据大小阈值。笔者认为这段 RocketMQ 4.9.4 版本代码存疑,因为最新的 5.0 版本做了优化。
if (currentMsgSize >= traceProducer.getMaxMessageSize()) { List<TraceTransferBean> dataToSend = new ArrayList(traceTransferBeanList); AsyncDataSendTask asyncDataSendTask = new AsyncDataSendTask(traceTopicName, regionId, dataToSend); traceExecutor.submit(asyncDataSendTask); this.clear(); } -
当前时间 - 轨迹数据片段的首次存储时间 是否大于刷新时间 ,也就是每500毫秒刷新一次。
private void sendDataByTimeThreshold() { long now = System.currentTimeMillis(); for (TraceDataSegment taskInfo : taskQueueByTopic.values()) { if (now - taskInfo.firstBeanAddTime >= waitTimeThresholdMil) { taskInfo.sendAllData(); } } }
轨迹数据存储的格式如下:
TraceBean bean = ctx.getTraceBeans().get(0);
//append the content of context and traceBean to transferBean's TransData
case Pub: {
**.append(ctx.getTraceType()).append(TraceConstants.CONTENT_SPLITOR)
.append(ctx.getTimeStamp()).append(TraceConstants.CONTENT_SPLITOR)
.append(ctx.getRegionId()).append(TraceConstants.CONTENT_SPLITOR)
.append(ctx.getGroupName()).append(TraceConstants.CONTENT_SPLITOR)
.append(bean.getTopic()).append(TraceConstants.CONTENT_SPLITOR)
.append(bean.getMsgId()).append(TraceConstants.CONTENT_SPLITOR)
.append(bean.getTags()).append(TraceConstants.CONTENT_SPLITOR)
.append(bean.getKeys()).append(TraceConstants.CONTENT_SPLITOR)
.append(bean.getStoreHost()).append(TraceConstants.CONTENT_SPLITOR)
.append(bean.getBodyLength()).append(TraceConstants.CONTENT_SPLITOR)
.append(ctx.getCostTime()).append(TraceConstants.CONTENT_SPLITOR)
.append(bean.getMsgType().ordinal()).append(TraceConstants.CONTENT_SPLITOR)
.append(bean.getOffsetMsgId()).append(TraceConstants.CONTENT_SPLITOR)
.append(ctx.isSuccess()).append(TraceConstants.FIELD_SPLITOR);
}
break;
下图展示了事务轨迹消息数据,每个数据字段是按照 CONTENT_SPLITOR 分隔。

注意:
分隔符 CONTENT_SPLITOR = (char) 1 它在内存中的值是:00000001 , 但是 char i = ‘1’ 它在内存中的值是 49 ,即 00110001。
参考资料:
阿里云文档:
石臻臻:


