
RocketMQ生产环境出现故障,一起探究问题根因!原创
大家好,我是威哥,《RocketMQ技术内幕》、《RocketMQ实战》作者、RocketMQ社区首席布道师、极客时间《中间件核心技术与实战》专栏作者、中通快递基础架构资深架构师,越努力越幸运,唯有坚持不懈,与大家共勉。
1、故障现象
我遇到一个RocketMQ集群出现了一个十分诡异的现象,现象如下图所示:
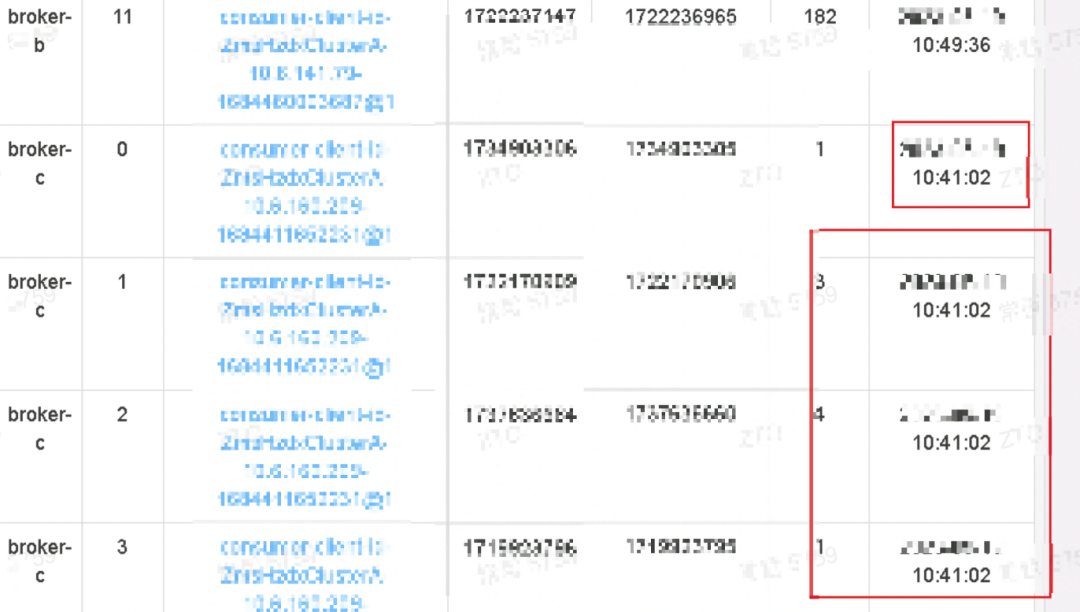
上述图中的关键信息归纳如下:
-
当前的系统时间为202x-xx-xx 10:49:50 -
broker-b上相关队列当前的消费积压数量为182,上一次消费的时间为202x-xx-xx 10:49:36,积压量比较少,对业务无影响,正常现象。 -
broker-c上的队列积压量在个位数, 但上一次消费的时间为202x-xx-xx 10:41:02,落后当前时间8分多钟,并且业务方明确表示在10:41到10:49会有大量消息发送。
我们结合业务方使用消息中间件,一般的使用场景如下图所示:
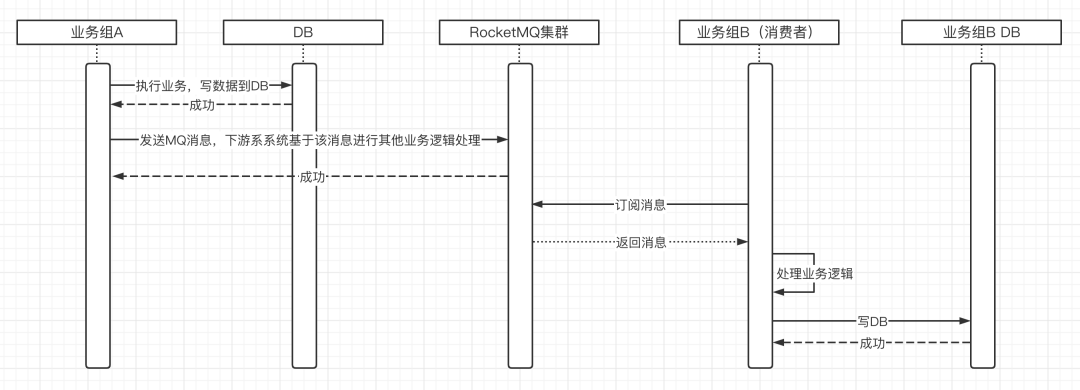
当业务组A处理完业务逻辑后将数据存储到业务A所对应的DB库,然后发送一条消息到MQ,下游系统会根据这些数据,进行额外的业务加工,并将数据写入到业务组B的数据库,目前业务方反馈的是业务组B中的数据要比业务组A中的数据落后将近8分钟。
2、一个小小的请求
结合故障现象与服务端日志,并仔细阅读相关源码,关于上述现象能给出一个相对有说服力的故障原因,但具体的根因还缺乏足够的证据支撑,如果大家对问题排查有任何的想法和思路,欢迎大家反馈给我(个人微信:dingwpmz),我去尝试排查,也希望大家转发给更多人,一起寻找问题的根因,以此来不断提升我们的技术能力。
3、问题排查
3.1 问题结论
对上述现象的综合分析与经过一段时间的尝试摸索后,觉得出现这种问题最有可能的原因是RocketMQ内部将消息从Commitlog转发到ConsumeQueue文件时出现积压,导致消息消费端无法感知消息。
我们简单看一下RocketMQ内部消息写入机制:
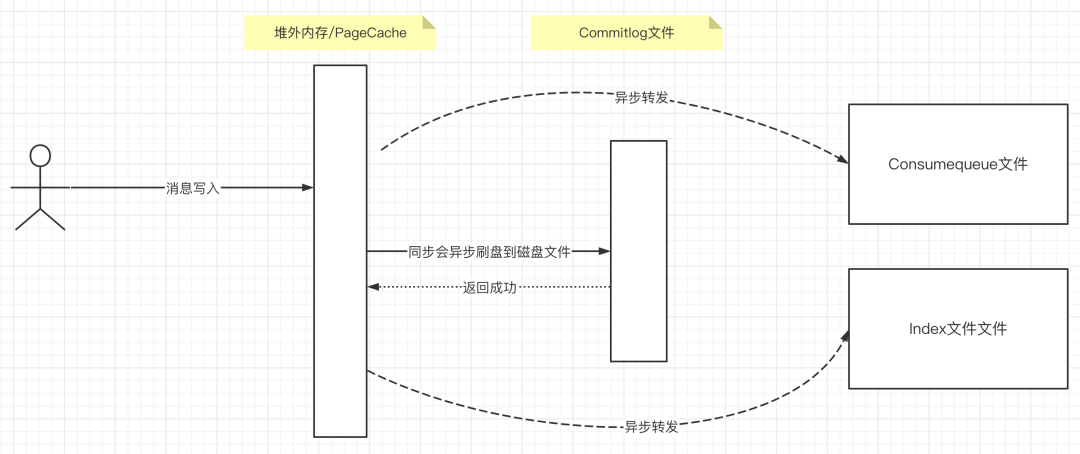
RocketMQ Broker收到客户端消息写入请求后,所有消息首先要存储到Commitlog文件,但直接写磁盘效率太低,故会将Commitlog文件以内存映射或文件通道方式写消息。
消息首先写入到文件通道(FileChannel)或PageCache中后,写入成功后如果刷盘策略为异步刷盘,就直接向客户端返回消息发送成功;如果是同步刷盘,需要等到消息持久存储到文件后再返回客户端。
但消息一旦进入到FileChannel或者PageCache后,转发线程(ReputMessage线程)就会感知到数据,并尝试将数据转发到ConsumeQueue文件。
也就是说Commitlog文件转发到ConsumeQueue文件与客户端消息发送这两个步骤是异步的。即就算消息未及时转发,也不会影响消息发送的成功执行。
在了解了上述相关机制后,我们假设如果是Commitlog文件未及时转发到Consumequeue文件,看能否解释上述现象:
1、如果是Commitlog文件中的消息未及时转发到Consumequeue文件,但上游系统发送消息成功,并且业务数据正常存储到数据库,但由于Consumequeue中没有对应的消息,消息消费者无法感知到这些消息,从而不会触发消费,自然不会进下游系统的数据库,在数据库层面是会出现延迟的,并且在消费端消费队列维度看不出消息积压,从而diff(消费队列最大消息偏移量 - 已消费消息偏移量)是个位数。
2、再来看那些有消费延迟的Broker中相关队列,显示最后的消费时间与当前时间相隔8分钟左右,这个是因为这个时间显示的是消费者最后一次成功消费的消息的位点处的消息的存储时间戳,由于当前消费队列中少了将近8分钟的消息,故显示的是8分钟之前的消息,也是可以解释的通的。
故从RocketMQ运作原理来看,Commitlog文件未及时转发到ConsumeQueue很可能导致本次故障的“元凶”,也许有些朋友会问,这个转发存在延迟你有没有更直接的证据。
当然是有的,我们从Broker的日志中,能看到如下关键信息:

这段日志就是输出Commitlog中还有多少字节数未转发到Consumequeue和index文件,其计算逻辑如下图所示:

但现在的关键是,RocketMQ为什么会出现Commitlog转发到ConsumeQueue的转发异常呢?我暂未找到太多相关的证据,接下来我先将我的分析结果整理一下,希望后续各位能为我提供一些思路。
3.2 问题分析
目前从相关系统监控(IO、IoWait、GC、内存)等监控维度并未察觉出问题,故我的思路是首先深入源码,仔细分析一下RocketMQ Commitlog文件转发机制。
在RocketMQ中专门有一个线程(ReputMessageService)进行异步转发,在这里我不再详细展开这块的源码逐行分析,我试着用一张图展示其核心原理:
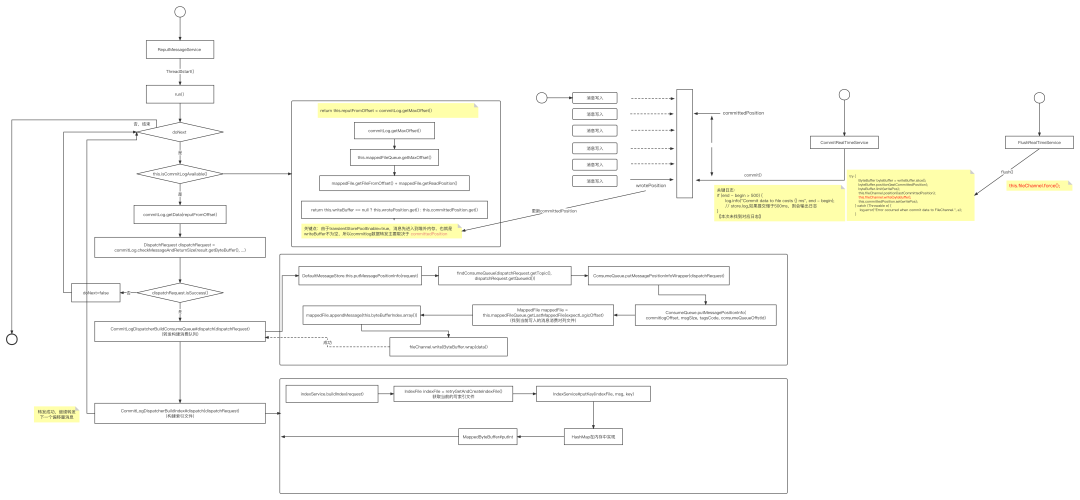
总结实现要点:
-
RocketMQ内核中只使用一个线程进行转发。 -
整个转发过程是一条消息一条消息进行转发,并且构建ConsumeQueue文件与索引文件是串行执行的。 -
ConsumeQueue文件在转发过程中,使用FileChannel的write方法进行数据的写入,将其数据写入到FileChannel中就认为转发成功,可以被消费者感知。每一条消息转发,调用FileChannel的write方法一次性写入的字节数非常少,只需要写入20个字节。 -
IndexFile文件的转发过程中,使用的是MappedByteBuffer(PageCache),需要操作的空间也不多,但 IndexFile的刷盘策略是一个文件写满后创建完另外一个新文件时同步对上一个文件进行刷盘。但刷盘动作是异步的(直接开一个线程进行刷盘),IndexFile文件的刷盘时间可以在store.log中使用关键字(flush index file elapsed time)。
Commitlog转发到ConsumeQueue、IndexFile整个过程并未有任何异常情况发生,当然整个链路过程中输出日志也比较少,主要包括如下日志:
-
如果处理异常,会抛出带有关键字 BUG 的日志。 -
commit操作,将堆外内存数据批量提交到FileChannel(调用FileChannel#write)方法,如果该过程超过500ms,会输出 Commit data to file costs -
相关线程如果因为异常退出日志
RocketMQ转发相关的原理是摸清楚了,但目前没有发现任何异常日志,但确确实实是出现了Commitlog文件与ConsumeQueue之间转发延迟,并且从某一个时间点开始,这个延迟持续越来越大,那这个问题的根本原因是什么?
该如何从操作系统,文件存储等其他方面去寻找日志去找出慢的根本原因?这就是我现在最大的困惑,也期待各位给我微信(dingwpmz)留言,一起交流探讨。
4、后续应对策略思考
虽然还没有找到根本原因,但总归要采取一些措施避免下一次发生或者在下一次刚发生时就能立马感知,方便我们采取诸如扩容等方式立马将其扼杀在摇篮里。
一个基本要做的点:就是采集RocketMQ服务端的日志,将 dispatch behind commit log 100 bytes 这类日志进行采集,然后设置一些告警规则,例如连续5个采集值都是单调递增,则需要提前进行告警。
另外一个,我在尝试思考,是不是我们可以优化代码,将整个转发流程异步化。

如果这篇文章对您有所帮助,求一键三连:点赞、转发、评论。关注公众号:「中间件兴趣圈」



