
InnoDB 全表扫描和全主键扫描一样吗?原创
《explain 显示 count(*) 使用了索引,实际却是全表扫描》提到了全表扫描和对主键索引进行全索引扫描,我把这两者等价对待了。
对主键索引进行全索引扫描对应的就是本文标题中的全主键扫描。
因为有两位读者就全表扫描、全主键扫描这两种读取数据的方式和我进行了交流,为了弄清楚两者到底是不是一样的,我对它们的执行流程进行了调试,写下来分享给大家。
本文基于 MySQL 8.0.32 源码,存储引擎为 InnoDB。
目录
-
1. 准备工作
-
2. 执行计划对比
-
3. 执行流程对比
-
4. 总结
正文
1. 准备工作
创建测试表:
CREATE TABLE `t2` (
`id` int unsigned NOT NULL AUTO_INCREMENT,
`i1` int DEFAULT '0',
PRIMARY KEY (`id`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb3
插入测试数据:
INSERT INTO `t2` (`id`, `i1`) VALUES
(1, 20), (2, 21),
(3, 22), (4, 23),
(5, 23), (6, 33);
示例 SQL 1:
SELECT `i1` FROM `t2`
示例 SQL 2:
SELECT `id` FROM `t2`
2. 执行计划对比
我们从执行计划入手,先来看看分别代表全表扫描、全主键扫描的示例 SQL 1、2 的执行计划。
示例 SQL 1:

type = ALL,说明示例 SQL 1 读取数据的方式为全表扫描,这个我们应该都很熟悉了。
示例 SQL 2:

type = index、key = PRIMARY,表示示例 SQL 2 使用了覆盖索引,并且使用的是主键索引,这说明示例 SQL 2 读取数据的方式是全主键扫描。
InnoDB 表属于索引组织表,主键索引包含表中所有数据,也就是所谓的索引即数据,数据即索引。不管是全表扫描,还是全主键扫描,都需要从主键索引中读取数据。
既然都是从主键索引中读取数据,那怎么会得到两种不同的执行计划呢?
执行计划是代码给出的,我们去代码里找答案。
确定执行计划时,全表扫描和全主键扫描的分叉口位于 JOIN::adjust_access_methods() 方法中。
示例 SQL 1:

程序停留在 JOIN::adjust_access_methods() 方法的 2949 行,说明 2938 行的 if (tab->type() == JT_ALL) 条件成立,也就是说,示例 SQL 1 最初确定的读取数据方式是全表扫描。
接下来,我们通过调试控制台打印出 !tab->table()->covering_keys.is_clear_all() 表达式的值:
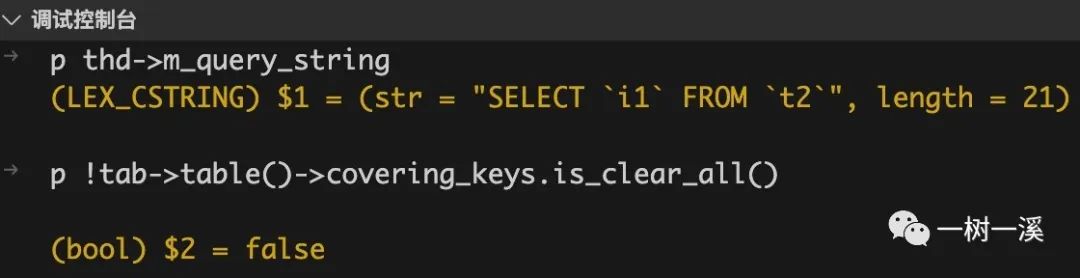
表达值的为 false,说明没有覆盖索引可用,不会进入对应的 if 分支,也就不会调用 tab->set_type(JT_INDEX_SCAN) 把全表扫描修改为覆盖索引扫描。
最终,示例 SQL 1 读取数据的方式就是全表扫描。
示例 SQL 2:

程序停留在 JOIN::adjust_access_methods() 方法的 2966 行:
-
说明 1 号红框处的 if 条件成立,示例 SQL 2 最初确定的读取数据方式也是全表扫描。 -
说明 2 号红框处的表达式值为 true,示例 SQL 2 可以使用覆盖索引扫描。
3 号红框处,find_shortest_key() 函数从可用的覆盖索引中找到占用空间最小的索引。
然后,tab->set_type(JT_INDEX_SCAN) 把全表扫描修改为覆盖索引扫描。
t2 表只有主键索引,没有二级索引,可以使用的覆盖索引(tab->table()->covering_keys)也就只有主键索引了,我们可以打印 covering_keys 来验证:

covering_keys 属性的类型是 Key_map,每个覆盖索引使用 1 bit 作为标志位。
map = 1,说明只设置了一个标志位,这意味着可供示例 SQL 2 使用的覆盖索引只有一个。

主键索引的 ID(primary_key)为 0,covering_keys.is_set(0) 的输出结果为 true,说明 covering_keys 中设置的标志位对应的就是主键索引。
最终,示例 SQL 2 读取数据的方式由全表扫描修改为全主键扫描。
既然 InnoDB 主键索引中包含了全表数据,那代码中到底是怎么表示主键索引的?

t2 表的主键索引(name 为 PRIMARY)有 1 个字段(user_defined_key_parts 为 1),字段名是 id,和表结构中 PRIMARY KEY 定义的主键字段一致。
也就是说,虽然主键索引包含了表中全部数据,但是内存中的索引对象还是只包含表结构中定义的主键字段。
通过前面的介绍,我们可以对全表扫描和全主键扫描做个简单的总结了:
-
如果 server 层只需要从 InnoDB 读取主键字段,主键索引可以充当覆盖索引的角色,读取数据的方式为
全主键扫描。 -
如果 server 层需要从 InnoDB 读取主键之外的字段,主键索引就不能充当覆盖索引的角色了,读取数据的方式为
全表扫描。
主键字段指的是表结构中 PRIMARY KEY 定义的字段。
3. 执行流程对比
前面对全表扫描和全主键扫描两种执行计划做了简单的对比,接下来我们再从三个方面对两者的执行流程做个对比,看看它们有什么异同。
首先,我们来看一下两者的主要堆栈:
-
全表扫描
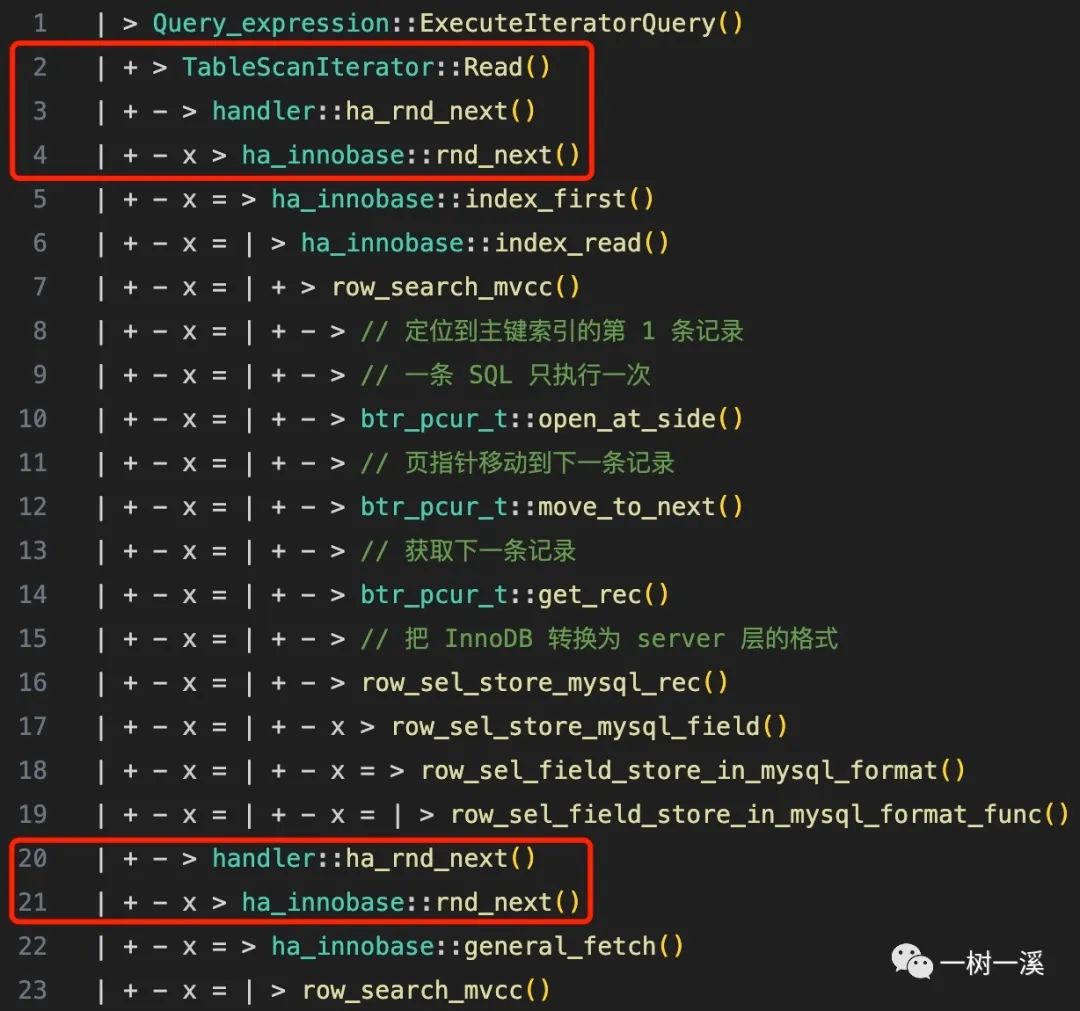
-
全主键扫描
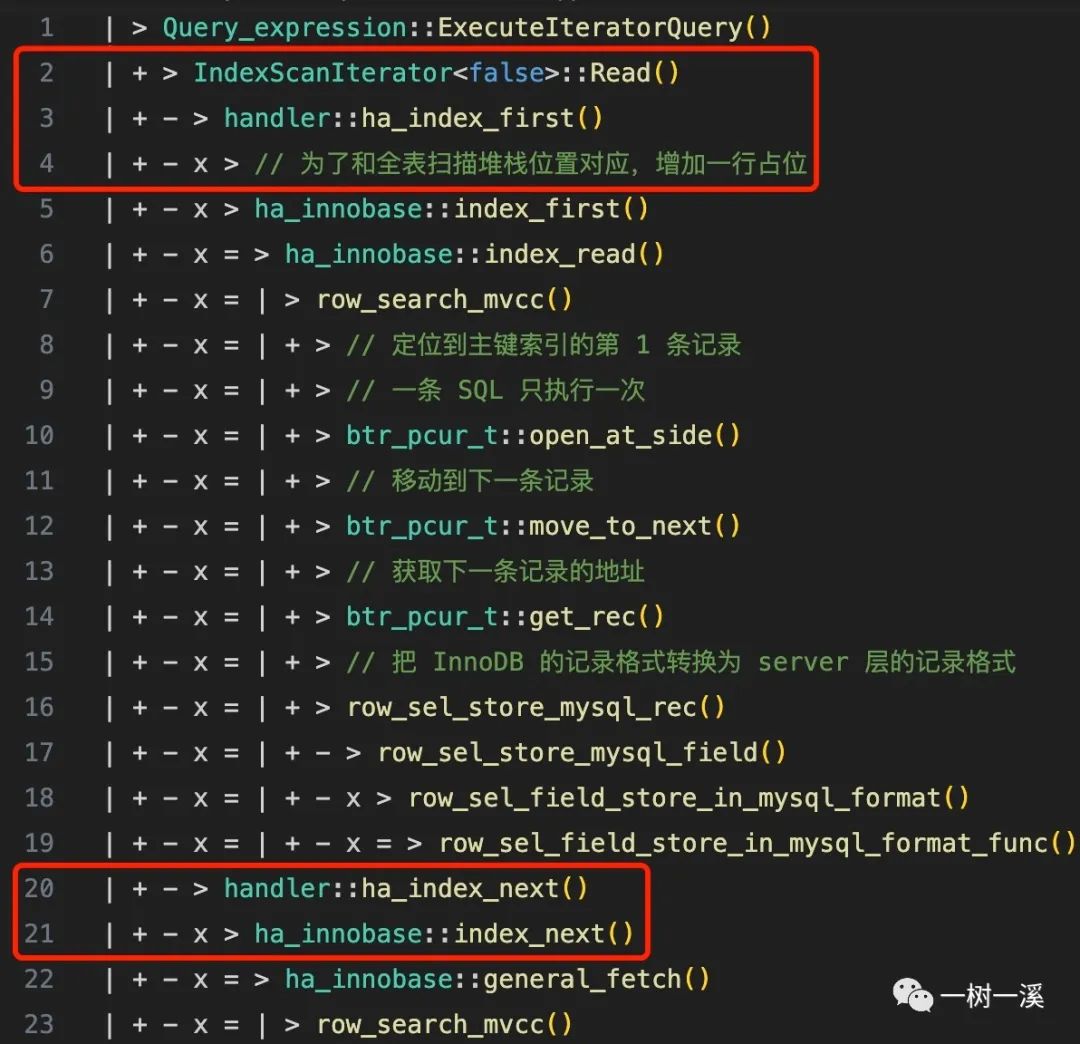
2 ~ 4 行是读取第一条记录的入口,20 ~ 21 行是读取第二条及以后记录的入口。
入口之下,两者都会依次调用 ha_innbase::index_first() -> ha_innobase::index_read() -> row_search_mvcc() 读取第一条记录。
依次调用 ha_innobase::general_fetch() -> row_search_mvcc() 读取第二条及以后的记录。
row_search_mvcc() 读取记录最关键的步骤是:定位到要读取的第一条记录。
因为读取第一条记录之后,只需要沿着记录之间的指针、数据页之间的指针就能依次读取到所有记录了。
row_search_mvcc() 调用 btr_pcur_t::open_at_side() 打开索引并定位到索引中的第一条记录。
程序执行到 row_search_mvcc() 的 pcur->open_at_side() 处,我们在调试控制台打印出两者使用的索引:
-
全表扫描
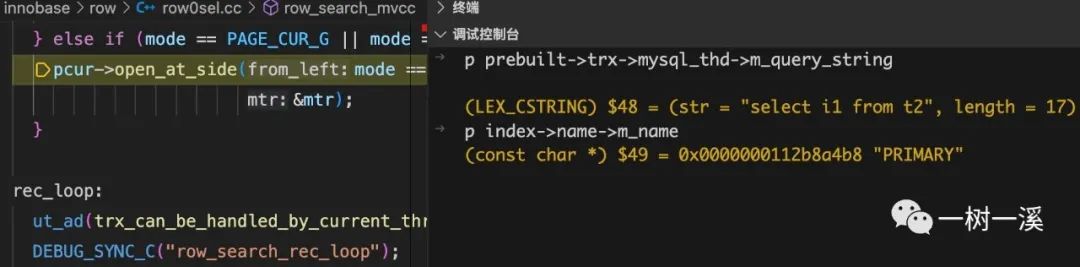
-
全主键扫描

通过上面两张图中打印出的 SQL 和索引名,我们可以看到:全表扫描和全主键扫描都打开了主键索引,意味着都会从主键索引中读取数据。
pcur->open_at_side() 打开并定位到索引的第一条记录(infimum)之后,btr_pcur_t::move_to_next() 把数据页的记录指针移动到下一条记录(第一条用户记录),btr_pcur_t::get_rec() 获取第一条用户记录的地址。
然后,row_sel_store_mysql_rec() 把第一条用户记录从 InnoDB 格式转换为 server 层的格式。
我们通过第一条用户记录来看看全表扫描和全主键扫描读取了主键索引的哪些字段。
-
全表扫描
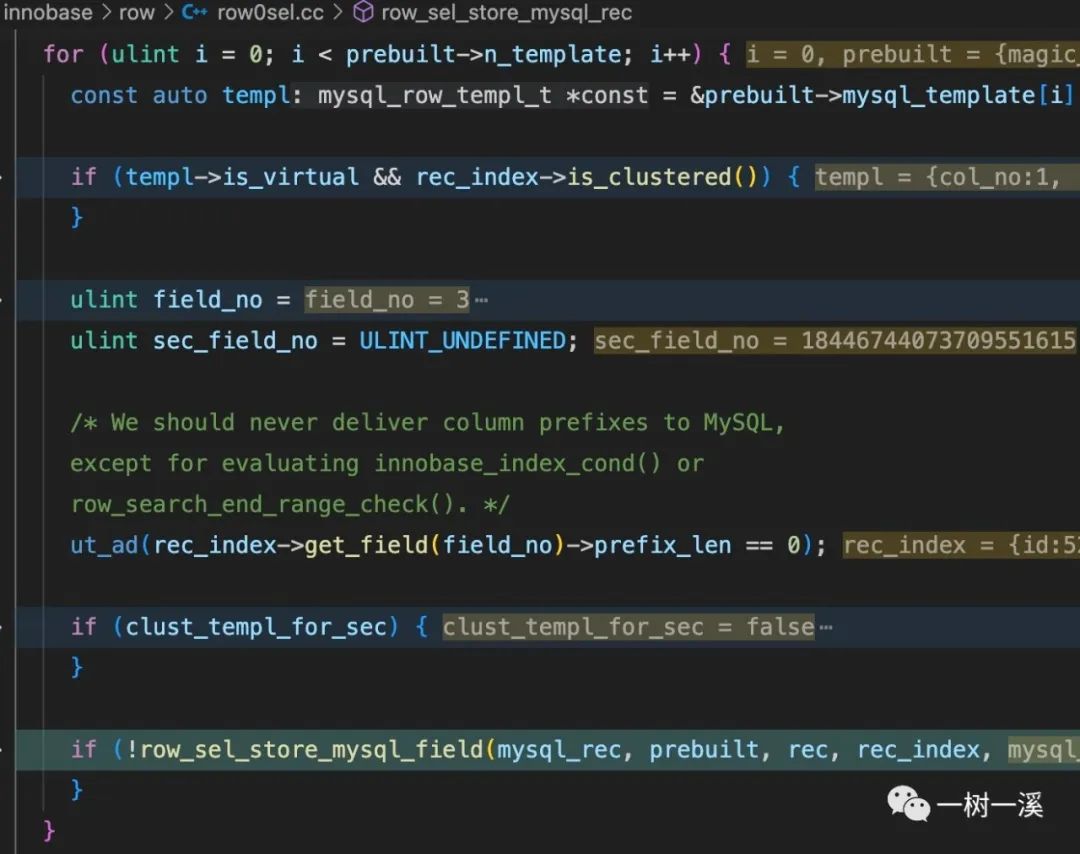
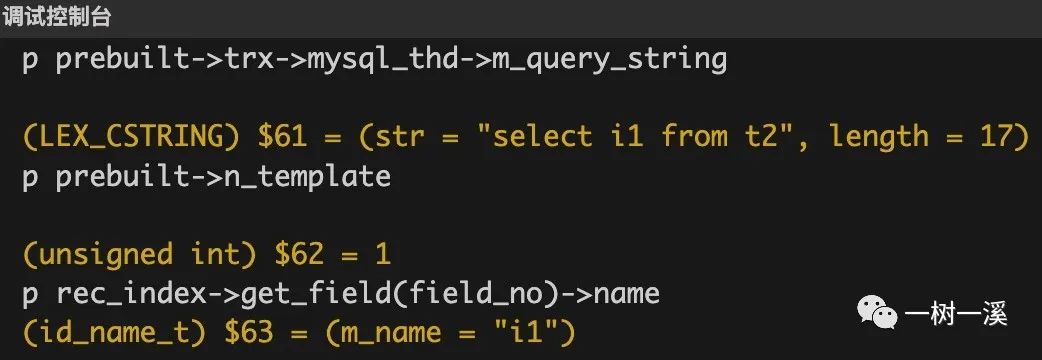
row_sel_store_mysql_rec() 只读取 1 个字段(p prebuilt->n_template 输出 1)。
字段名为 i1(p rec_index->get_field(field_no)->name 输出 i1)。
-
全主键扫描

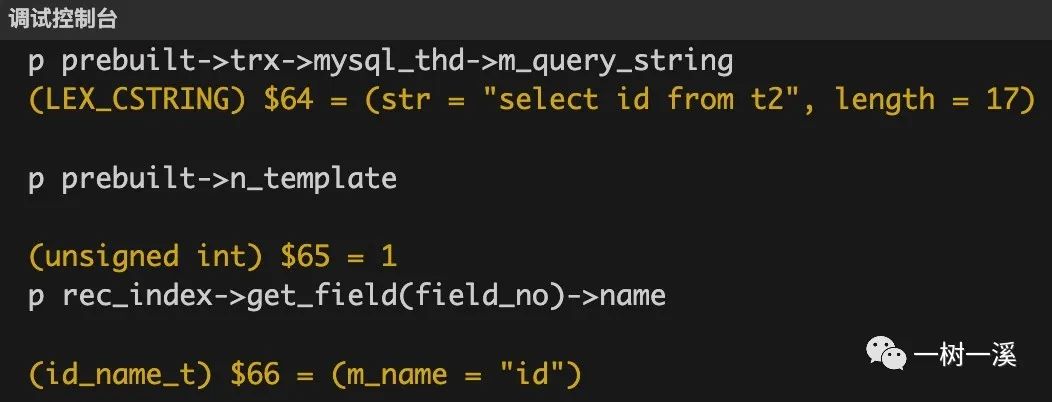
row_sel_store_mysql_rec() 也只读取 1 个字段(p prebuilt->n_template 输出 1)。
字段名为 id(p rec_index->get_field(field_no)->name 输出 id)。
通过前面三项对比,我们可以确定:
全表扫描和全主键扫描都使用了主键索引,并且都是先定位到主键索引的第一条记录,然后沿着第一条记录一直读取到最后一条记录。
4. 总结
从执行流程来看,全表扫描和全主键扫描都需要从主键索引中读取数据。
InnoDB 每读取一条记录,都需要把该记录所属的数据页从磁盘上的表空间文件读取到 Buffer Pool 中(如果数据页已在 Buffer Pool 中,不需要重复读取)。
全表扫描需要读取表中所有记录,全主键扫描需要读取主键索引的所有记录,由于 InnoDB 表的数据和主键索引合二为一了,两者都会把主键索引中所有叶子结点数据页全部读取到 Buffer Pool 中。
从这点可见,InnoDB 全主键扫描的执行效率并不会比全表扫描高。
全表扫描和和全主键扫描读取时,都需要先定位到主键索引第 1 个叶子结点数据页中的第 1 条用户记录,然后沿着第 1 条用户记录依次读取,直到读完主键索引中的所有记录(或者说表中的所有记录)。
所以,我们可以认为全表扫描和全主键扫描本质上是一样的。
既然如此,执行计划中为什么要区分全表扫描和全主键扫描呢?
这是因为 MySQL 支持多种存储引擎,对于使用堆表的存储引擎(例如 MyISAM),因为表中数据和索引是分开存储的,全表扫描和全主键扫描确实不同。
server 层确定执行计划时,对于所有存储引擎一视同仁,InnoDB 自然也就区分全表扫描和全主键扫描了。
有想了解的 MySQL 知识点或想交流的问题可以关注我公众号:一树一溪


