
xplain 显示 count(*) 使用了索引,实际却是全表扫描原创
这篇文章依然源于一位读者的提问:explain 显示 count(*) 使用了索引,optimizer trace 却显示为全表扫描,这是为什么?
去年,我写过一篇关于 count(distinct) 实现原理的文章《count(distinct) 玩出了新花样》。
还记得当时调试源码的过程中,如果 explain 显示会使用二级索引进行全索引扫描,执行时也确实只会从二级索引中读取记录,不会进行全表扫描。
不过,那会没有关注过 optimizer trace 是怎么显示的。
既然不能从记忆里找到答案,那就只能从源码里找答案了。
撸完源码发现:和 5.7.35 版本相比,8.0.32 的 count(*) 实现逻辑,确实有了一些变化。
接下来,我们一起来看看。
本文基于 MySQL 8.0.32 源码,存储引擎为 InnoDB。
如需转载,请联系『一树一溪』公众号作者。
目录
-
1. 准备工作
-
2. 问题重现及分析
-
3. 总结
正文
1. 准备工作
创建测试表:
CREATE TABLE `t1` (
`id` int unsigned NOT NULL AUTO_INCREMENT,
`i1` int DEFAULT '0',
PRIMARY KEY (`id`) USING BTREE,
KEY `idx_i1` (`i1`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb3
插入数据:
INSERT INTO `t1`(`id`, `i1`)
VALUES (10, 101), (20, 201), (30, 301);
2. 问题重现及分析
explain 查看执行计划:
EXPLAIN SELECT COUNT(*) FROM `t1`;
结果如下(只截取了部分字段):

再来看看 optimizer trace 描述的执行计划,依次执行以下 3 条 SQL:
-- 开启 optimizer trace
SET optimizer_trace = "enabled=on";
-- 执行 SELECT 语句
SELECT COUNT(*) FROM `t1`;
-- 获取 optimizer trace
SELECT * FROM information_schema.optimizer_trace;
结果如下(只截取了部分内容):
{
"considered_execution_plans": [
{
"plan_prefix": [
],
"table": "`t1`",
"best_access_path": {
"considered_access_paths": [
{
"rows_to_scan": 3,
"access_type": "scan",
"resulting_rows": 3,
"cost": 0.55,
"chosen": true
}
]
},
"condition_filtering_pct": 100,
"rows_for_plan": 3,
"cost_for_plan": 0.55,
"chosen": true
}
]
}
我们来对比下 explain 和 optimizer trace 的结果:
-
explain 输出结果中,type 字段值为
index、key 字段值为idx_i1,表示会使用 idx_i1 作为覆盖索引执行 select 语句。
由于没有 where 条件,select 语句会对二级索引idx_i1进行全索引扫描,以获取t1表的记录数量。 -
optimizer trace 输出结果中,没有显示会使用索引
idx_i1,而且,access_type 为scan,看起来像是会进行全表扫描。
我在 5.7.35 中调试了这条 SQL:
SELECT COUNT(*) FROM `t1`
可以证实,select 语句执行过程中,确实对 idx_i1 进行了全索引扫描,和 explain 输出的执行计划一致。
同时也确认了:不管是对主键索引进行全索引扫描(也就是全表扫描),还是对二级索引进行全索引扫描,optimizer trace 的输出结果中,access_type 字段值都是 scan。
我又在 8.0.32 中调试了上面的 SQL,发现了新情况:InnoDB 对不包含 where 条件的 select count(*) from table 语句进行了特殊处理。
跟随调试过程,我们一起来看看 InnoDB 做了什么特殊处理。
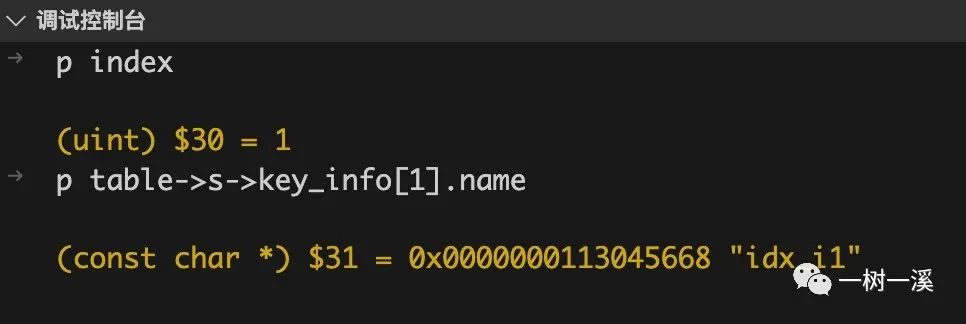
程序执行到 ha_records() 方法时,我们可以看到,index 参数的值是 1,这就是执行计划确定要使用的索引 ID。

我们在调试控制台打印索引名字,可以看到 ID = 1 的索引就 idx_i1:
ha_records() 会调用 records_from_index(),代码如下:
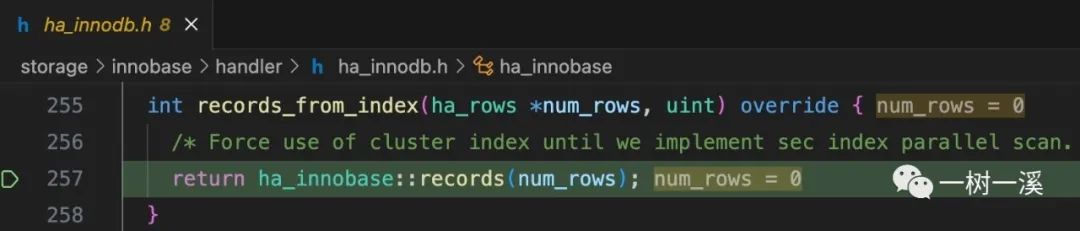
从以上代码可以看到,ha_records() 把索引 idx_i1 的 ID 传给了 records_from_index() 的第 2 个参数,但是,该方法的第 2 个参数,只有类型(uint),没有名字,这说明第 2 个参数不能被使用。
也就是说,虽然执行计划确定了要使用索引 idx_i1 来统计 t1 表的记录数量,records_from_index() 却没有真正使用 idx_i1。
从代码注释也可以看到:在实现二级索引的并行扫描之前,records_from_index() 会强制使用主键索引来统计表中的记录数量。
在 github 中追溯代码提交历史,发现 records_from_index() 是 8.0.17 版本新加的。
从这个版本开始,到最新的 8.0.33,对于不包含 where 条件的 select count(*) from table 语句,都会强制使用主键索引(也就是会进行全表扫描)。
之所以这么做,是为了使用多个线程对主键索引进行并行扫描,以提升执行速度。
3. 总结
虽然本文内容比较短,但是本着完整的原则,还是进行个简单的总结:
-
8.0.16(含)版本之前,对于
select count(*) from table语句,如果表中有二级索引,InnoDB 会选择对某个二级索引进行全索引扫描,以获取表中的记录数量。 -
从 8.0.17(含)版本开始,直到目前的最新版本(8.0.33),如果表中有二级索引,explain 输出的执行计划也表示会使用二级索引,然而,实际执行过程中,InnoDB 却会强制进行全表扫描,以使用主键索引的并行扫描能力。
-
optimizer trace 的结果中,对于
select count(*) from table语句,二级索引的全索引扫描和全表扫描同等对待,执行计划的access_type字段值都是scan。有想了解的 MySQL 知识点或想交流的问题可以关注我公众号:一树一溪


