
图文详解 Linux 分段机制!原创
上一篇聊到分段机制是为了提供了隔绝代码、数据和堆栈区域的机制,能够使得多个程序运行在同一个内存空间中不会相互干扰,这是对内存平坦模型的一种保护。内存经过分段机制后会变为一个个的段,这称为多段模型。多段模型能够利用分段机制的功能提供由硬件增强代码、数据结构、程序和任务的保护措施。
现在我们知道了分段的目的是为了什么,但是我们好像还不知道什么是段,以及段有哪些特征。
段的定义
保护模式中的 80x86 架构提供了 4GB 的物理地址空间。这是 CPU 在地址总线上可以寻址的地址空间。这段地址空间是一种平坦模型地址空间,地址范围从 0 到 0xFFFFFFFF。
平坦模型:相对于多个段的模型来说,平坦模型指的就是一个段,比如在实模式下,处理器最大可寻址 64 KB(2 ^ 16)的地址空间,在保护模式下,处理器最大可寻址 4GB (2 ^ 32)的地址空间,如果访问超过最大地址空间的数据指令,需要重新指定段。
需要注意下的是,段地址 + 偏移地址确实能寻址 1MB 的地址空间,但这却不是平坦模型的访问方式,而是多段模型。
再来啰嗦一下分段机制的目的:分段机制就是把虚拟地址空间中的虚拟内存组织成一个个长度可变的段,这个段是虚拟地址到线性地址转换的基础,一般来说,段由三部分组成:
-
段基址(Base address):段的初始地址,可以认为是段的开始,段基址的段内偏移为 0 。 -
段限长(limit):该段最大可用的偏移位置,它定义了段的长度,也是段内偏移最大能够寻址到的位置。 -
段属性(Attributes):指的是该段的特性,比如段是否可读、是否可写、是否能够作为程序执行,段的特权级等。
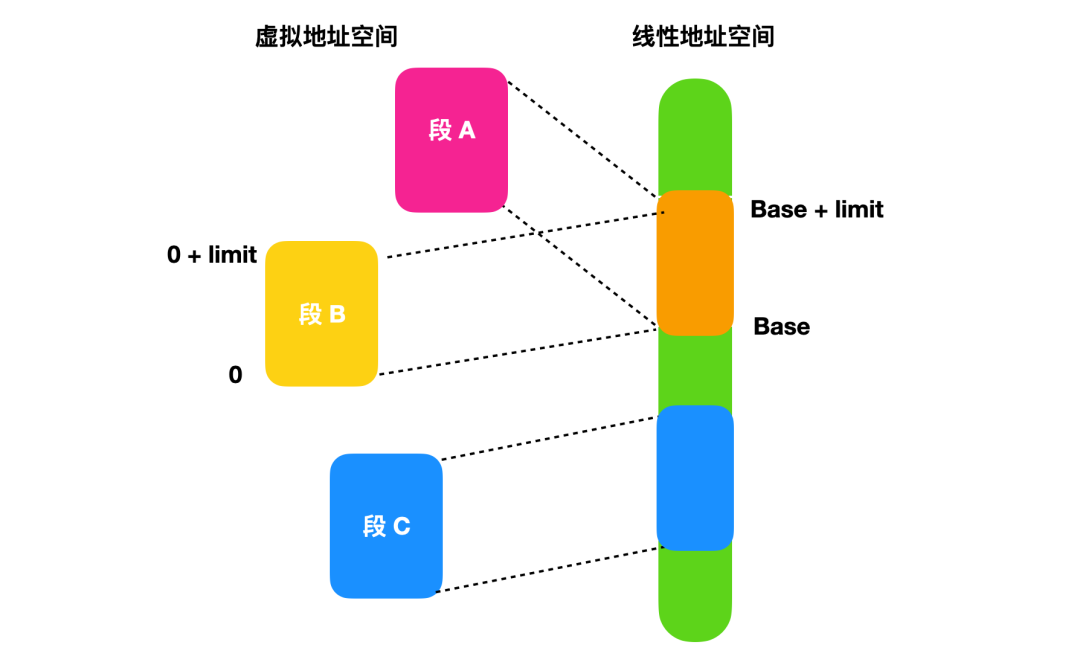
段基址和段限长一起定义了段所映射的线性地址空间的范围。段内从 0 到 limit 地址范围会对应线性地址空间中的 base 到 base + limit ,偏移量是无法大于段限长的,如果偏移地址大于段限长会引发异常,除此之外,如果访问的这个段没有符合段属性,也会引发异常。
不同的段可以映射到相同的线性地址空间,这种映射是操作系统所允许的。也就是说不同的段可以在线性地址空间中覆盖或者完全重叠,如下图所示
段基址、段限长和段属性都存储在段描述符这个结构中,可以说段描述符就是能够查找段重要信息的结构,在虚拟地址到线性地址的转换过程中,就需要用到段描述符。那么段描述符被存储在哪里呢?段描述符被存储在段描述符表中,这个表就是一个数组,这个数组的下标就是段选择子,还记得我们上篇文章聊过段选择子吗?段选择子中的 Index 是这么描述的:

为了把逻辑地址转换成为线性地址,CPU 会执行以下操作:
-
使用段选择子中的 Index 属性通过查询 GDT/LDT 表定位相应的段描述符。 -
利用段描述符检验段的访问权限和范围,用于确保该段是可访问并且偏移量位于段界限内。 -
把段描述符中取得的段基地址加上 Index ,最后形成偏移地址。
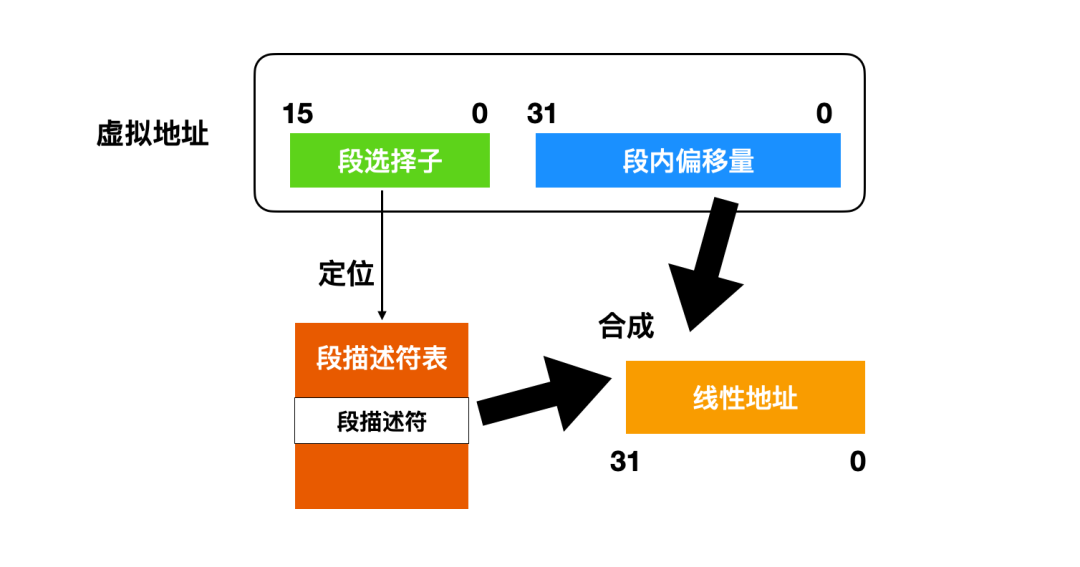
如果没有开启分页机制,那么此时的线性地址就等同于物理地址;如果开启分页机制,那么此时的线性地址会经过分页机制转换后才会把线性地址映射成为物理地址。
段选择子
上篇文章提到了段选择子,大致介绍了一下它的结构,并没有细致说明,这篇文章就来细致说明一下。
段选择子又称段选择符,它是一个 16 位的标识符,如下图所示,段选择子并不指向段,它指向段描述符表中的段描述符。

段选择子总共分为三个部分:
-
RPL(Request Privilege Level):请求特权级,表示进程应该以什么权限来访问段,数值越大权限越小。 -
TI(Table Indicator):表示应该查询哪个表,TI = 0 查 GDT 表;TI = 1 查 LDT 表。 -
Index:CPU 会自动将 Index * 8,在加上 GDT 和 LDT 中的段基址,就是要加载的段描述符。
下面是几幅段选择子的示意图,大家明白图中所示也就明白段选择子是如何表示的了。
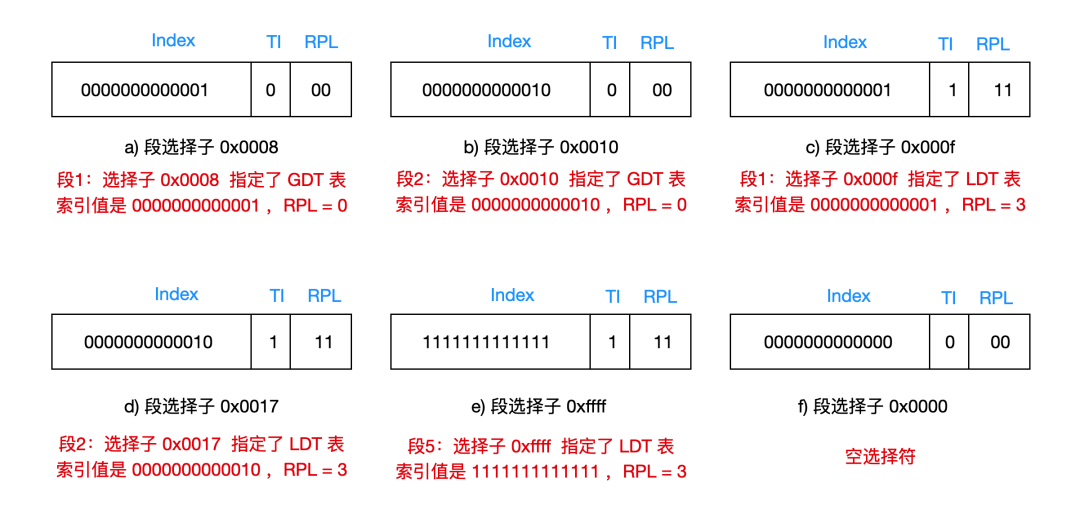
需要注意的是,段选择子 0x0008 和 段选择子 0x000f 指向的是同一个段即段 1;段选择子 0x0010 和 段选择子 0x0017 也指向的是同一个段即段 2。段选择子 0ffff 指向段 8191,而段选择子 0x0000 指向的的是一个空段,因为 CPU 不使用 GDT 表中的第一项,所以指向该段的选择子用作空选择子。当把空选择子加载到段寄存器(CS 和 SS 除外)中时,处理器不产生异常,但是当含有空选择子的段寄存器用于访问内存时,会产生异常。把空选择子加载到 CS 和 SS 中也会产生异常。
段选择子 a b c d 分别指向 linux 0.1x 中的内核代码段、内核数据段、任务代码段和任务数据段。
一般把段选择子放在段寄存器中,每个寄存器支持特定类型的内容引用,这部分引用可以是代码、数据或者堆栈;每个程序都会把有效的段选择子加载到 CS、SS 或者是 DS 中,另外,处理器还提供了另外三个段寄存器即 FS、GS、ES 作为辅助,这三个寄存器提供当前 CPU 访问段寄存器不够时使用。

从上图可以看到,每个段寄存器都由两部分组成,一部分是段选择子,一部分是 "段基址、段限长和段属性信息",段选择子是存在于段寄存器中显示的部分,而段基址、段限长和段属性是隐藏部分。
为什么会有隐藏部分呢?
隐藏部分也被称为描述符缓冲或者是影子寄存器,当一个段选择子被加载到段寄存器中可见部分时,处理器也会同时把段基址等信息加载到段寄存器的隐藏部分,缓存在段寄存器中隐藏部分使得处理器在进行地址转换的时候不用再去段描述符中读取段的相关信息。
段寄存器中的隐藏部分相当于是段描述符的一个镜像,或者说是拷贝。因此操作系统必须要确保对段描述符的改动反映在描述符缓冲中,如果更改了段描述符却没有在描述符缓冲中进行修改,就会造成段不一致的现象。所以最快捷的方法就是在对描述附表做过改动之后就立刻重新加载 6 个段寄存器。这将会把描述附表中的相应段信息加载到描述符缓冲中。
处理器提供了两类加载指令用于加载段的相关信息:
一类是 MOV、POP、LDS、LES、LSS、LGS 以及 LFS 指令,这些指令显示的直接引用段寄存器;
一类是隐式加载指令,例如 CALL、JMP 和 RET 指令、IRET、INTn、INTO 和 INT3 等指令。这些指令在操作过程中会附带改变 CS 寄存器的内容。
段描述符
段描述符是 GDT 和 LDT 表中的一个数据项,用于向处理器提供有关一个段的位置和大小信息以及访问控制的状态信息。每个段描述符长度是 8 字节,含有三个主要字段:段基址、段限长和段属性,其他是一些细节字段。段描述符通常是由编译器、链接器、加载器或者操作系统来创建。
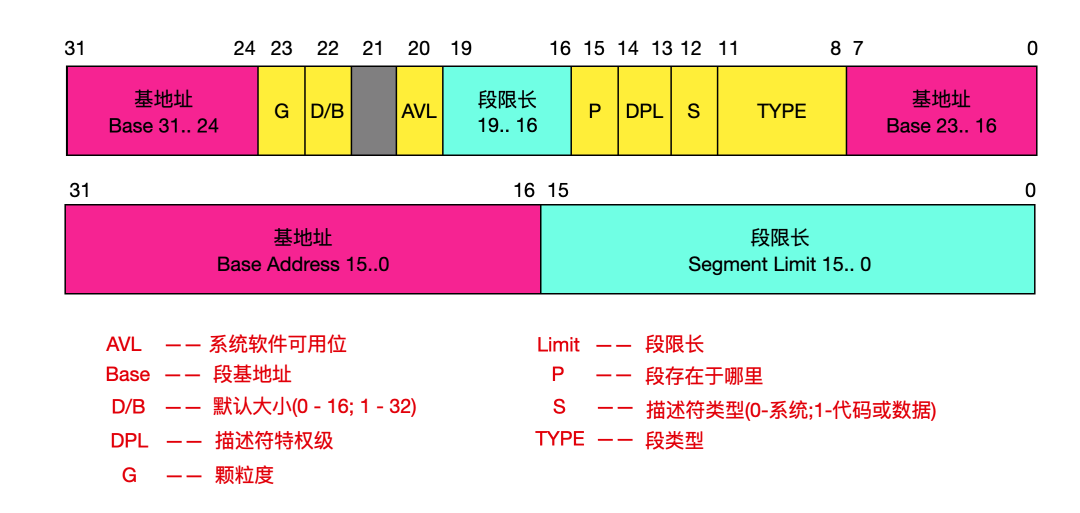
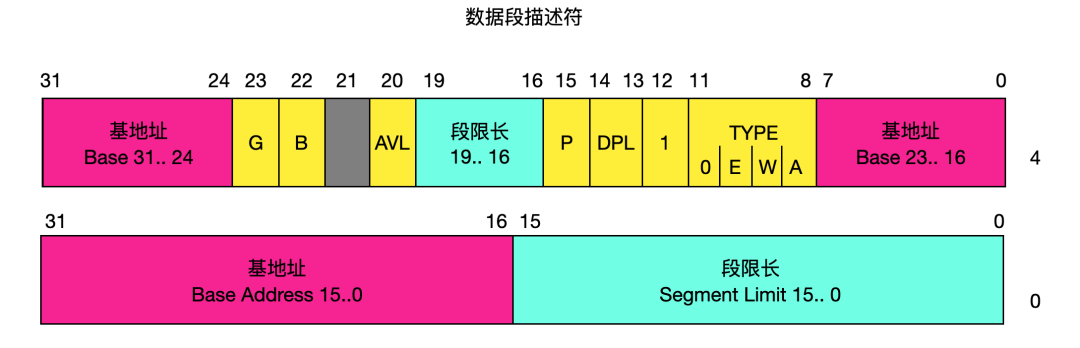
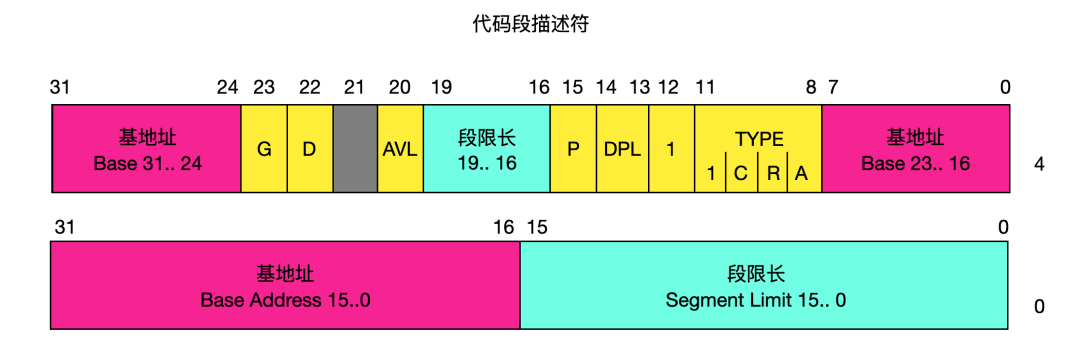
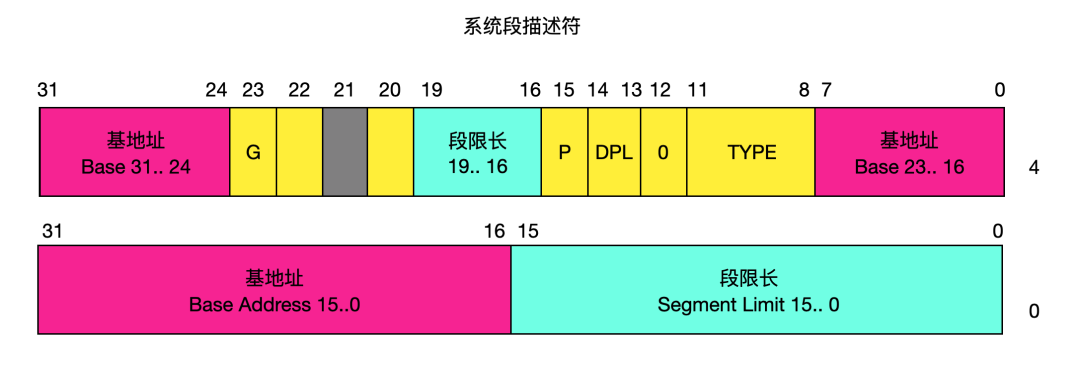
这是一个比较详细的段描述符的结构,下面来具体介绍一下这些字段的含义:
-
段限长字段 LIMIT --- Segment limit field
段限长用于指定段的长度,处理器会把段描述符中两个段限长字段组合成一个 20 位的值,并且根据颗粒度标志 G 来指定段限长 Limit 值的实际含义。如果 G = 0,则段长度 Limit 范围可以从 1 到 1MB 字节。如果 G = 1,则段长度 Limit 的范围可以是从 4KB 到 4GB ,单位是 4KB。
-
基地址字段 BASE --- Base address field
这个字段定义在 4GB 线性地址空间中一个段字节 0 所处的位置。处理器会把 3 个分立的基地址字段组合成为一个 32 位的值,段基址应该对其 16 字节边界,这样做性能比较高。
-
段类型字段 TYPE --- Type field
类型字段指定段或门(Gate)的类型、说明段的访问种类以及段的扩展方向。这个字段依赖与描述符类型标志 S 指明的是一个应用描述符还是系统描述。TYPE 字段的编码对代码、数据或系统描述符都不同。
-
描述符类型标志 S --- Descriptor type flag
表明描述符的类型,0 - 表示系统描述符,1 - 代码或数据段描述符。
-
描述符特权级 --- DPL Descriptor priviledge level
DPL 表示描述符的特权级,特权级范围从 0 - 3 ,3 最低,0 最高,DPL 用于控制对段的访问;
我在内核访问相关的描述中也提到了一个特权级,大家还记得是啥吗?
-
段存在标志 --- P Segment present
P 标志位表示一个段是在内存中 p = 1 还是不在内存中 p = 0。当段描述符的 P 标志为 0 时,那么把指向这个段描述符的选择符加载进段寄存器将导致产生一个段不存在异常。
-
D/B --- 默认操作大小/默认栈指针大小和/或上界限 Default operation size/default stack pointer size and/or upper bound
根据段描述符表示的是可执行代码段、下扩数据段还是堆栈段,这个标志具有不同的功能(如果是 32 位,这个标志应该设置为 1,16 位应该设置为 0 )。如果是可执行代码段时,这个标志是 D 标志;如果是栈段和下扩数据段,这个标志是 B 标志;
-
颗粒度标志 --- G Granularity
这个字段用于确定段限长字段 Limit 值的单位,如果颗粒度标志为 0 ,则段限长值的单位是字节;如果设置了颗粒度标志,则段限长使用 4KB 单位。
-
可用和保留比特位 --- Available and reserved bits
段描述符的第 2 个双字的位 20 供系统软件使用,位 21 是保留位并且设置为 0 。
段描述符表
段描述符表是存储段描述符的一个数组,索引是由段选择子提供。段描述符表的长度可变,最多可以包含 8192 个 8 字节的描述符,段描述符有两种:即全局描述符表(Global descriptor table) 和 局部描述符表(Local descriptor table)。
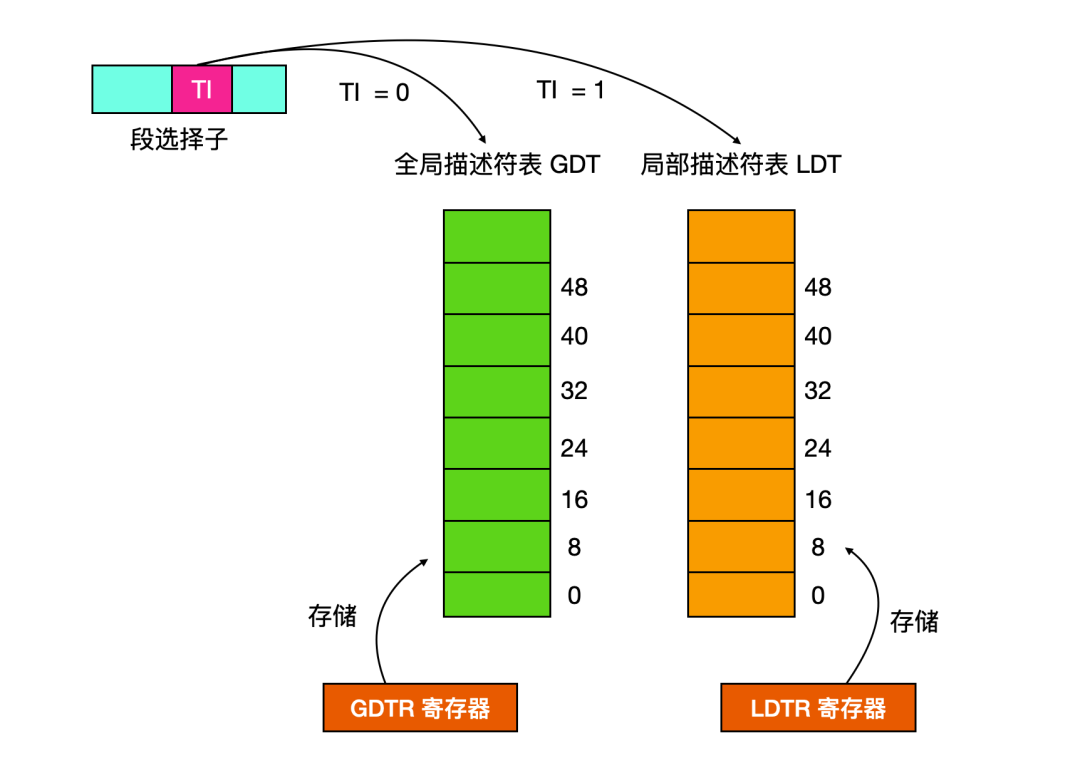
描述符表由操作系统中的特殊数据结构来维护着,并且由内存管理硬件来引用。虚拟内存空间被分割成大小相等的两半,一半由 GDT 来映射变换成为线性地址,一半由 LDT 来映射,由于段描述符表最大可以包含 8192 个 8 字节的描述符,也就是 2 ^ 13 = 8192 ,所以整个虚拟地址空间是 2 ^ 14 = 16384 个段了,通过指定 TI = 1 or 0 就可以查找到指令的段描述符。
当发生任务切换时,LDT 会更换成新任务的 LDT,但是 GDT 内容却不会变。因此可以看出,GDT 相当于是全局共有的,系统中所有任务共享的段用 GDT 来映射,而 LDT 是当前任务特有的,可以把 LDT 看成是操作系统的数据。
下面是一副关于 GDT、LDT 的映射图。
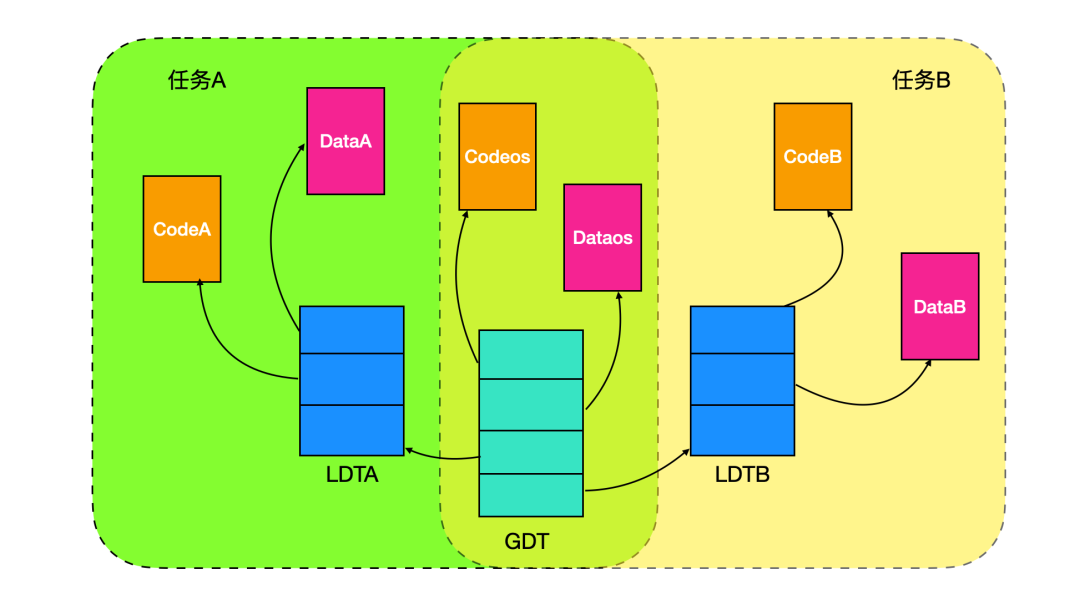
上图中共有六个段,分别是用于任务 A 的 CodeA 、DataA,任务 B 的 CodeB、DataB,用于操作系统的 Codeos 和 Dataos,系统中的任务 A 和 任务B 分别是两个不同的应用程序,并且每个任务都有自己的 Code 和 Data,在各自的 LDT 表中保存着 Code 和 Data。包含操作系统内核的两个段 Codeos 和 Dataos 在 GDT 中映射,并且 GDT 表示任务 A 和任务 B 共同享有的全局映射,GDT 表还保存着 LDTA 和 LDTB。
当任务 A 在运行时,可访问的段包括 LDTA 的 CodeA 和 DataA,加上 GDT 映射的 Codeos 和 Dataos,任务 B 运行时,可访问的段包括 LDTB 的 CodeB 和 DataB,加上 GDT 映射的 Codeos 和 Dataos 。任务 A 在运行时,是无法访问任务 B 的两个段的;同样的任务 B 在运行时,也是无法访问任务 A 的,这正是虚拟地址提供的保护机制,还记得上篇文章写到的吗?

GDT 本身并不是一个段,它只是线性地址空间中的一个数据结构。GDT 的基地址 (Base Address)+ 段长度(Limit)会被直接加载进 GDTR 寄存器中。GDT 的基地址应该进行内存 8 字节对齐,用已得到最佳的处理性能。GDT 的限长以字节为单位。
处理器并不会使用 GDT 表中的第 1 个描述符,第 1 个描述符也是空描述符,把这个描述符加载进数据段寄存器 DS、FS、GS 和 ES 后不会产生异常,但是使用空描述符的段选择符访问内存时就肯定会产生一般保护性异常。
访问 LDT 表需要使用其段选择符,为了在访问 LDT 时减少地址转换次数,LDT 的段选择符、基地址、段限长和访问权限需要存储在 LDTR 寄存器中。



