
【全网首发】如何正确获取容器的CPU利用率?原创
大家好,我是飞哥!
今天我们来深入理解关于容器 cpu 利用率相关的两个问题。
第一个问题:如何正确地获取容器中的 cpu 利用率?
在上一篇《Linux 中的各项 CPU 利用率是这样算出来的!》中我们讨论了 Linux 是如何计算系统的 cpu 利用率。在物理机上,使用这种方法查看 cpu 的使用情况是没有问题的。
但是在容器中,默认情况下 /proc/stat 是使用的宿主机的伪文件,也就是说查看到的是物理机的 cpu 使用情况,而不是容器本身的。那么我们该如何才能正确地获取到容器本身的 cpu 使用率呢?
第二个问题:容器 cpu 使用率的指标项为什么比物理机上少了 nice/irq/softirq?
不少公司基于部署的 kubelet 解决了获取的问题,将容器的总 cpu 用量、user 用户态、system 系统态都正确地上报了。
但如果你仔细观察过就会发现,是在物理机的 top 输出中有 user/nice/system/irq/softirq 等很多指标项,而容器中却只有 user 和 system。其它的指标项去哪儿了?
实际上,容器中统计到 cpu user、system 指标项的含义和物理机中 top 输出的同名指标项的含义是完全不同的。
好,我们现在对以上两个问题进行深入的剖析!
一、获取容器 cpu 利用率的思路
绝大部分同学都习惯了使用 top 来查看 cpu 利用率。到了容器里,大家也都是习惯打开 top 看看。但经常会遇到明明是 2 核的容器,top 显示出来的核却有很多个。
这是因为在默认情况下,容器中的 /proc/stat 并没有单独挂载,而是使用的宿主机的。而 top 命令中对 cpu 核数的判断,以及对 cpu 利用率的显示都是根据 /proc/stat 文件的输出来计算的。所以自然容器下想看 cpu 利用率就不能使用这种方法了。
那么容器下就没有办法正确获取 cpu 的使用情况了吗?肯定不是的,办法总比困难多。
第一个办法是对容器中的 /proc/ 目录下的一些文件进行挂载,包括 /proc/stat。在容器中不再使用和宿主机相同的文件。lxcfs 就是基于这种思想做出来的项目。业界有不少公司都使用它修改了容器里的 stat 伪文件。该项目的 github 地址:https://github.com/lxc/lxcfs
安装了 lxcfs 后,开发们又可以愉快地像在物理上一样地使用 top 来玩耍了。
第二个方法就是直接找到容器所属的 cgroup 目录,在这里也有当前 cgroup 所消耗的 cpu 资源的统计信息。根据这个信息可以计算出容器的 cpu 利用率。
kubelet 中集成的 cadvisor 就是采用上述方案来上报容器 cpu 利用率的打点信息的。每隔一段定长的时间都进行采样,将数据上传给 Prometheus。这样,我们就能在 Prometheus 上看到容器的 cpu 利用信息了。不过 cadvisor 具体访问 cgroup 目录是通过调用 libcontainer 获取的。github 地址:https://github.com/opencontainers/runc/tree/main/libcontainer
如果我们自己在业务中出于某些需求需要获取容器的 cpu 利用率的话,我建议的是采用后面的这个方法。不过要注意的是,cgroup 有 V1 和 V2 两个版本。使用 libcontainer 的话它替我们做了这个处理。如果我们自己计算的话,需要首先判断当前在用的 cgroup 是 V1 还是 V2。
libcontainer 中是通过 cgroup 挂载的文件系统的 magic number 来判断的。
//file:https://github.com/opencontainers/runc/blob/main/libcontainer/cgroups/utils.go
func IsCgroup2UnifiedMode() bool {
isUnifiedOnce.Do(func() {
var st unix.Statfs_t
err := unix.Statfs(unifiedMountpoint, &st)
...
isUnified = st.Type == unix.CGROUP2_SUPER_MAGIC
})
return isUnified
}
其中 cgroup2 的 magic number 是固定的。
const (
...
CGROUP2_SUPER_MAGIC = 0x63677270
)
判断出来后,需要针对 cgroup1 和 cgroup2 来区分开始处理。判断完后,下一步是找到容器的 cgroup 的路径。通过检查 /proc/{pid}/cgroup 可以查看到进程所在的 cgroup。
在 cgroup V1 中,是通过 cpuacct 子系统来统计 cpu 利用率的,cpu 相关的内核伪文件有如几个。路径都在 /sys/fs/cgroup/cpuacct 目录下。找到一个并打开后,我们可以看到如下几个 cpu 相关的文件。
# cd /sys/fs/cgroup/cpuacct/.../...
# ls
-r--r--r-- 1 root root 0 Jan 15 02:01 cpuacct.stat
-rw-r--r-- 1 root root 0 Jan 15 02:01 cpuacct.usage
-r--r--r-- 1 root root 0 Jan 15 02:01 cpuacct.usage_sys
-r--r--r-- 1 root root 0 Jan 15 02:01 cpuacct.usage_user
......
其中每个文件的作用是
-
cpuacct.stat:显示当前 cgroup cpu 采样统计信息 -
cpuacct.usage:显示当前 cgroup 中所有进程的总 cpu 时间用量,另外 cpuacct.usage_sys 输出的是用户态时间,cpuacct.usage_user 输出的是系统态时间。
我们找一个 cpuacct.stat 来看
# cat cpuacct.usage
201758848693795
其中输出的数据的单位是纳秒。加入我们再时间 t1 获得该 cgroup 使用的纳秒数位 a1, t2 获得使用的纳秒数位 a2。则该容器使用的 cpu 时间就等于 (a2-a1)/(t2-t1)。
这个输出的是用量,想换算成使用率还需要除以当前的核数。假如用量算出来是 0.5 核,对于 1 核的容器来说,当前容器的 cpu 使用率就是 50%。
在 cgroup V2 中,输出稍有不同。V2 是在 cpu.stat 中输出的,一个示例如下。
# cat cpu.stat
usage_usec 283162364632
user_usec 181662990050
system_usec 101499374581
nr_periods 1908114
nr_throttled 4435
throttled_usec 337853392
其中 usage_usec 代表容器自统计以后所使用的 cpu 时间,user_usec 是使用的用户态时间,system_usec 为内核态时间。它们的单位都为微秒。
计算的方式同样是在 t1 t2 两个点采样,然后用类似的公司计算而得出。
讲到这里,我们已经把容器 cpu 使用率的统计方法介绍清楚了。不过不知道你有没有发现一个问题,我们在物理机的 top 命令中,输出的 cpu 利用率相关的项目有用户态使用率(包括 user、nice)系统态利用率(system、irq、softirq)。
但不管采用上面哪一个办法,我们似乎只能把容器中 user 或者 system 的 cpu 耗时计算出来。而在宿主机中看到的 nice、irq、softirq 却变得无影无踪了。这一点似乎和物理机上是不一致的。
不过别着急,我们马上展开对容器 cpu 利用率内部处理过程的发掘,我们将能找到这个问题的答案。
二、cgroup V2 cpu 利用率统计实现
cgroup 有 V1 和 V2 两个版本。他们都通过伪文件向用户态提供了 cgroup 使用的 cpu 时间的信息。正是有了这个基础,我们才能够在上一节中使用这个数据在两个时间点之间采样后计算 cpu 利用率。
本节我们就来看看,cgroup 提供的 cpu 使用时间信息是怎么来的。为了简便,本文只以 cgroup V2 为例。
2.1 cgroup cpu 时间统计相关定义
cgroup 在内核中的定义就叫 struct cgroup。

cgroup 的 rstat_cpu 是一个 percpu 变量,对每个逻辑核都会分配一个数组元素。cgroup 在每个核上的使用时间信息会先在这里存储。bstat 是整个 cgroup 的全局 cpu 使用统计。
我们来看下具体的定义:
//file:include/linux/cgroup-defs.h
struct cgroup {
...
// cgroup v1 都是存在这里的
struct cgroup_subsys_state __rcu *subsys[CGROUP_SUBSYS_COUNT];
// cgroup v2 的 percpu 统计信息
struct cgroup_rstat_cpu __percpu *rstat_cpu;
// cgroup v2 的汇总 cpu 统计信息
struct cgroup_base_stat bstat;
struct prev_cputime prev_cputime;
...
}
struct cgroup_base_stat {
struct task_cputime cputime;
};
其中 task_cputime 中包含了系统态时间 stime、用户态时间 utime 以及总的时间 sum_exec_runtime。
//file:include/linux/sched/types.h
struct task_cputime {
u64 stime;
u64 utime;
unsigned long long sum_exec_runtime;
};
2.2 查看 cpu.stat 过程
在 cgroup V2 中,是通过 cpu.stat 伪文件来查看到容器内所有进程使用的用户态、系统态以及汇总时间的微秒数的。
其实这个数据是来自于内核中 cgroup 对象的 bstat 成员。在这个成员中存储了当前 cgroup 内进程所使用的用户态时间、系统态时间以及总时间。对 cpu.stat 伪文件的访问就是读取的这个数据并打印输出的。大致流程图如下:
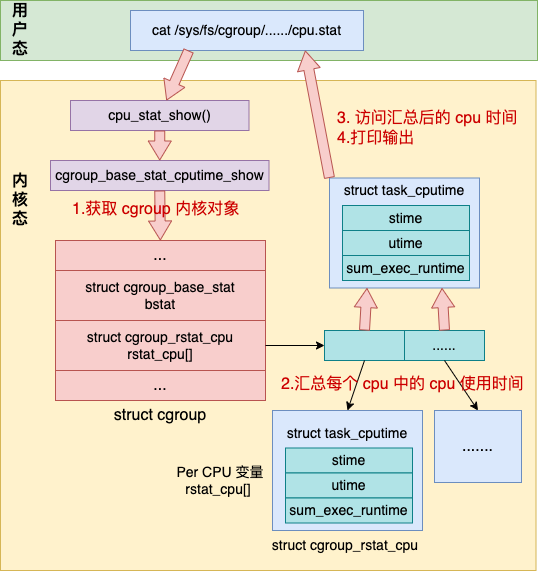
打开 cpu.stat 会触发内核对应的处理函数 cpu_stat_show。在这个函数中会将当前 cgroup 中对每个 cpu 记录使用率信息汇总起来。最后转化成微秒输出。
我们来看下详细工作过程。在 cgroup.c 中定义了对于 cgroup 的各个伪文件的处理函数。
//file:kernel/cgroup/cgroup.c
static struct cftype cgroup_base_files[] = {
...
{
.name = "cpu.stat",
.flags = CFTYPE_NOT_ON_ROOT,
.seq_show = cpu_stat_show,
},
...
}
对于 cpu.stat 来说,它对应的处理函数就是 cpu_stat_show。cpu_stat_show 调用 cgroup_base_stat_cputime_show 访问内核变量并打印输出。
//file:kernel/cgroup/rstat.c
void cgroup_base_stat_cputime_show(struct seq_file *seq)
{
//1.找到当前文件对应的 cgroup 内核对象
struct cgroup *cgrp = seq_css(seq)->cgroup;
u64 usage, utime, stime;
...
//2.汇总 percpu 中存储的时间信息到 cgroup 全局 bstat 中
cgroup_rstat_flush_hold(cgrp);
//3.访问当前 cgroup bstat 中存储的时间信息
usage = cgrp->bstat.cputime.sum_exec_runtime;
cputime_adjust(&cgrp->bstat.cputime, &cgrp->prev_cputime, &utime, &stime);
//4.将纳秒转换为微秒,并打印输出
do_div(usage, NSEC_PER_USEC);
do_div(utime, NSEC_PER_USEC);
do_div(stime, NSEC_PER_USEC);
seq_printf(seq, "usage_usec %llu\n"
"user_usec %llu\n"
"system_usec %llu\n",
usage, utime, stime);
}
在这个函数中做了这么几件事情。
第一件,是先查找到当前伪文件对应的 cgroup 内核对象。
第二件,将 percpu 变量 中保存的 cpu 时间统计汇总到全局 bstat.cputime 中
第三件,访问该对象的 bstat.cputime 中存储的 utime、stime、sum_exec_runtime。
第四件,调用 do_div 将内存中的纳秒值转化成微秒,并打印输出
我们重点来展开看下第二件事,percpu 变量的统计汇总。cgroup_rstat_flush_hold 调用了 cgroup_rstat_flush_locked 来进行 percpu 中 cpu 统计信息进行汇总。
//file:kernel/cgroup/rstat.c
static void cgroup_rstat_flush_locked(struct cgroup *cgrp, ...)
{
for_each_possible_cpu(cpu) {
while ((pos = cgroup_rstat_cpu_pop_updated(pos, cgrp, cpu))) {
cgroup_base_stat_flush(pos, cpu);
...
}
}
...
}
在上述函数中遍历每个 cpu,然后调用 cgroup_base_stat_flush 来将该 cpu 上的记录的 cpu 统计信息汇总到 cgroup 的全局统计 bstat 中。
//file:kernel/cgroup/rstat.c
static void cgroup_base_stat_flush(struct cgroup *cgrp, int cpu)
{
//获取当前 percpu 值
struct cgroup_rstat_cpu *rstatc = cgroup_rstat_cpu(cgrp, cpu);
cputime = rstatc->bstat.cputime;
//计算从上一次到现在的 cpu 使用增量值
delta.cputime.utime = cputime.utime - last_cputime->utime;
delta.cputime.stime = cputime.stime - last_cputime->stime;
delta.cputime.sum_exec_runtime = cputime.sum_exec_runtime -
last_cputime->sum_exec_runtime;
*last_cputime = cputime;
//将增量都加到 cgroup 全局统计 bstat 中
cgroup_base_stat_accumulate(&cgrp->bstat, &delta);
...
}
具体的统计思路是记录一个上一次统计信息,本次将当前时间和上一次相减得出最近使用的 cpu 增量,然后把这些增量都调用 cgroup_base_stat_accumulate 累加到 cgroup 的 bstat 中。
接下来就是访问全局 bstat.cputime 中 utime、stime,并可能会进行一些调整,然后打印输出。
在接下来的一个小节中我们再看下,percpu 变量 rstat 中的数据是怎么加进来的。
2.3 累加到 percpu 统计信息中
在《Linux 中的各项 CPU 利用率是这样算出来的!》 中我们介绍到了,系统会定期在每个 cpu 核上发起 timer interrupt。每次当时间中断到来的时候,采样 cpu 使用情况并汇总起来,提供给 /proc/stat 访问用。对于系统中每一个 cgroup 来说,也是在这个时机里统计并汇总起来的。
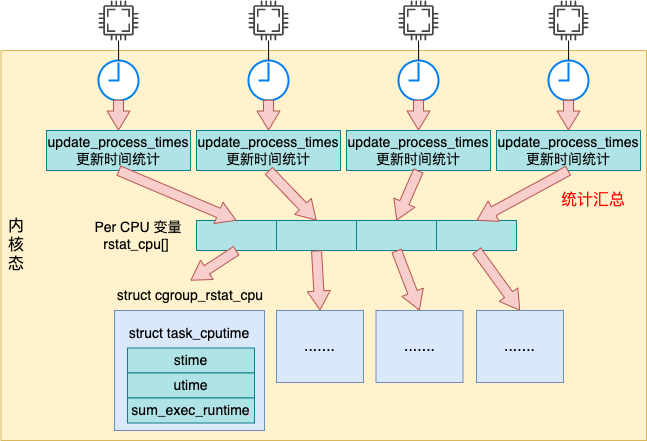
定时器定时将 cgroup 在每个 cpu 上的使用信息都记录到 percpu 变量 rstat_cpu。我们来看看详细的统计过程。
每次执行时钟中断处理程序 都会调用 都会调用 update_process_times 来进行时钟中断的处理。在时钟中断中处理的事情包括 cpu 利用率的统计,以及周期性的进程调度等。其中和容器 cpu 利用率相关的调用栈比较深,如下图所示。
update_process_times
->account_process_tick
->account_user_time //累计用户态时间
->task_group_account_field
->cgroup_account_cputime_field
->cpuacct_account_field
-> __cgroup_account_cputime_field
->account_system_time //累计系统态时间
->account_system_index_time
->task_group_account_field
->cgroup_account_cputime_field
->cpuacct_account_field
->__cgroup_account_cputime_field
update_process_times 调用 account_process_tick 来处理 cpu 处理时间的累积。在 account_process_tick 中根据当前的状态判断是该累计用户态时间,还是内核态时间。
//file:kernel/sched/cputime.c
void account_process_tick(struct task_struct *p, int user_tick)
{
u64 cputime, steal;
struct rq *rq = this_rq();
cputime = TICK_NSEC;
...
if (user_tick)
//累计用户态时间
account_user_time(p, cputime);
else if ((p != rq->idle) || (irq_count() != HARDIRQ_OFFSET))
//累计内核态时间
account_system_time(p, HARDIRQ_OFFSET, cputime);
else
account_idle_time(cputime);
}
无论是累计用户态时间处理函数 account_user_time 还是累积内核态时间 account_system_time,最后都用调用到 __cgroup_account_cputime_field 将当前节拍的时间添加到 cgroup 内核对象的 。
//file:kernel/cgroup/rstat.c
void __cgroup_account_cputime_field(struct cgroup *cgrp,
enum cpu_usage_stat index, u64 delta_exec)
{
struct cgroup_rstat_cpu *rstatc;
rstatc = cgroup_base_stat_cputime_account_begin(cgrp);
switch (index) {
case CPUTIME_USER:
case CPUTIME_NICE:
rstatc->bstat.cputime.utime += delta_exec;
break;
case CPUTIME_SYSTEM:
case CPUTIME_IRQ:
case CPUTIME_SOFTIRQ:
rstatc->bstat.cputime.stime += delta_exec;
break;
default:
break;
}
cgroup_base_stat_cputime_account_end(cgrp, rstatc);
}
在这个函数中,将本次节拍的时间 delta_exec 添加到了 cgroup 中为统计 cpu 使用率的 percpu 变量 rstat_cpu 中了(cgroup_base_stat_cputime_account_begin 函数访问的是 cgroup 下的 rstat_cpu)。
这里我们还看到了,对于 user 和 nice,cgroup 都统一添加到了 utime(用户态时间)下,对于 system、irq 和 softirq 都统计到了 stime (系统态时间)下。
这就是前面我们提到的问题的答案,为什么容器 cpu 利用率只能体现 user 和 system,而在宿主机中可以看到的 nice、irq、softirq 却看不到了。
这是因为容器将所有用户态时间都记录到了一起,系统态时间都记录到了一起。而不像在宿主机中分的那么细。在容器中的 cpu 的 user 指标和宿主机中 top 命令输出的 user 指标含义是完全不一样的,system 也是。这个点值得大家注意。在容器中:
-
用户态时间:和宿主机中的 user + nice 相对应 -
系统态时间:和宿主机中的 system + irq + softirq 相对应。
三、总结
这篇文章中,我们讨论两个核容器 cpu 使用率相关的问题。
第一个问题:如何正确地获取容器中的 cpu 利用率?
这个问题有两个解决思路。
思路之一是使用 lxcfs,将容器中的 /proc/stat 替换掉。这样 top 等命令就不再显示的是宿主机的 cpu 利用率了,而是容器的。思路之二是直接使用 cgroup 提供的伪文件来进行统计,这些伪文件一般位于 /sys/fs/cgroup/... 路径。kubelet 中集成的 cadvisor 就是采用上述方案来上报容器 cpu 利用率的打点信息的。
第二个问题:容器 cpu 使用率的指标项为什么比物理机上少了 nice/irq/softirq?
这个问题的根本原因是容器 cpu 利用率的指标项 user、system 和宿主机的同名指标项根本就不是一个东西。
容器将所有用户态时间都记录到了 user 指标项,系统态时间都记录到了 system。
容器中的 user 指标:在指标含义上等同于宿主机的 user + nice容器中的 system 指标:在指标含义上等同于宿主机的 system + irq + softirq
以上就是这两个问题的深度的答案。好了,今天的分享就到这里,欢迎转发!



