
高效入门eBPF原创
今天主要进行eBPF的入门介绍,说起eBPF就不得不先了解一下eBPF的前身BPF。eBPF是extended BPF 的简称,而BPF的全称是Berkeley Packet Filter,即伯克利报文过滤器。
BPF
在BPF之前,如果想做数据包过滤,则必须将所有数据包复制到用户空间中,然后在那里过滤它们,这种方式意味着必须将所有数据包复制到用户空间中,复制数据的开销很大。当然可以通过将过滤逻辑转移到内核中解决开销问题,我们来看BPF做了什么工作。
伯克利报文过滤器的设计思想来源于1992年的一篇论文"The BSD packet filter: A New architecture for user-level packet capture"(《BSD数据包过滤器:一种用于用户级数据包捕获的新体系结构》)。最初,BPF是在BSD内核实现的,后来由于其出色的设计思想,其他操作系统也将其引入,其中也包括Linux。

BPF原理
论文中展示的bpf架构原理如下图所示。
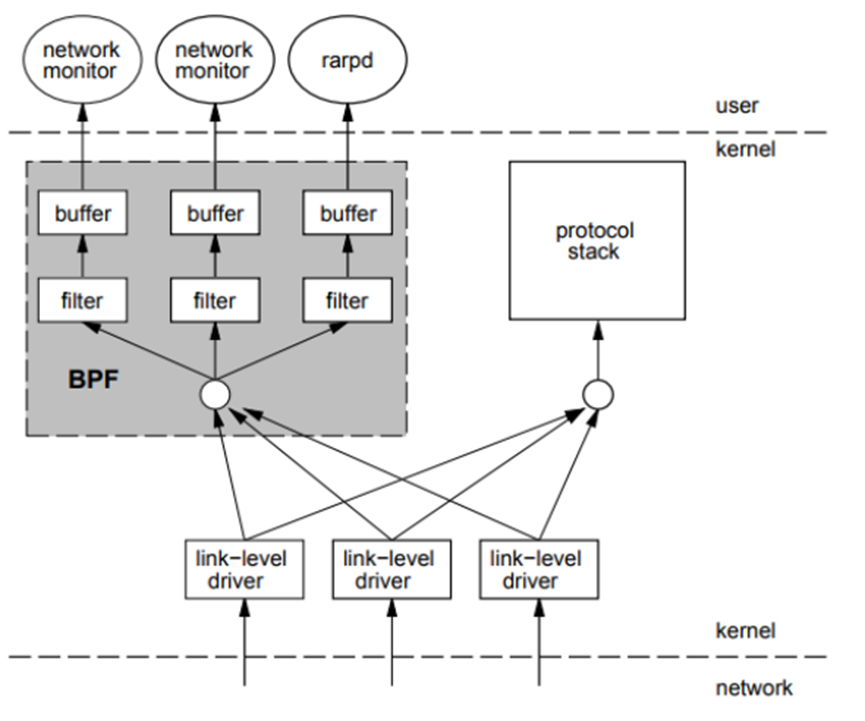
BPF是作为内核报文传输路径的一个旁路存在,当报文到达内核驱动程序后,内核在将报文上送协议栈的同时,会额外将报文的一个副本交给BPF。之后,报文会经过BPF内部逻辑的过滤(这个逻辑可以自己设置) ,然后最终送给用户程序 (比如tcpdump)。
BPF如何运行?
下面我们将带着如下问题通过代码来观察bpf是如何工作的。
-
bpf程序如何编写? -
bpf程序如何载入到内核中? -
载入到内核中的bpf程序何时执行?
BPF用到的系统调用有:
socket(AF_PACKET, SOCK_RAW, ...)
bind(sockfd, iface)
setsockopt(sockfd, SOL_SOCKET, SO_ATTACH_FILTER,&Filter, sizeof(Filter))
recv(sockfd, ...)
通过 setsockopt 系统调用,将用户自定义的bpf过滤程序载入内核空间。
参数&Filter的类型是struct sock_fprog,结构如下:
struct sock_fprog /* Required for SO_ATTACH_FILTER. */
{
unsigned short len; /* Number of filter blocks */
struct sock_filter *filter;
};
其中的filter指针指向结构为struct sock_filter的BPF过滤代码。结构如下:
struct sock_filter /* Filter block */
{
__u16 code; /* Actual filter code */
__u8 jt; /* Jump true */
__u8 jf; /* Jump false */
__u32 k; /* Generic multiuse field */
};
如何编写BPF并加载进内核
如下用户态代码中定义结构体bpfcode,使用bpf指令自定义了过滤程序。
#include <stdio.h>
#include <linux/filter.h>
…
#define OP_LDH (BPF_LD | BPF_H | BPF_ABS)
#define OP_LDB (BPF_LD | BPF_B | BPF_ABS)
#define OP_JEQ (BPF_JMP | BPF_JEQ | BPF_K)
#define OP_RET (BPF_RET | BPF_K)
static struct sock_filter bpfcode[6] = {
{ OP_LDH, 0, 0, 12 }, // ldh [12]
{ OP_JEQ, 0, 2, ETH_P_IP }, // jeq #0x800, L2, L5
{ OP_LDB, 0, 0, 23 }, // ldb [23]
{ OP_JEQ, 0, 1, IPPROTO_TCP }, // jeq #0x6, L4, L5
{ OP_RET, 0, 0, 0 }, // ret #0x0
{ OP_RET, 0, 0, -1, }, // ret #0xffffffff
};
int main(int argc, char **argv)
{
…
struct sock_fprog bpf = { 6, bpfcode };
…
sock = socket(AF_PACKET, SOCK_RAW, htons(ETH_P_ALL));
…
if (setsockopt(sock, SOL_SOCKET, SO_ATTACH_FILTER, &bpf, sizeof(bpf))) {
perror("setsockopt ATTACH_FILTER");
return 1;
}
…
}
setsockopt提供 SO_ATTACH_FILTER 和 SO_DETACH_FILTER 两个操作枚举值,分别表示装载程序和卸载程序。
switch(optname) {
/* some code omitted ... */
case SO_ATTACH_FILTER:
ret = -EINVAL;
if (optlen == sizeof(struct sock_fprog)) {
struct sock_fprog fprog;
ret = -EFAULT;
/* 从用户空间向内核空间拷贝描述bpf程序的结构体*/
if (copy_from_user(&fprog, optval, sizeof(fprog)))
break;
/* 给 sock 挂载bpf程序 */
ret = sk_attach_filter(&fprog, sk);
}
break;
case SO_DETACH_FILTER:
/* 卸载bpf程序 */
ret = sk_detach_filter(sk);
break;
sk_attach_filter 对用户自定义的bpf程序进行安全检测,通过后将程序挂载到钩子sk_filter 上。内核使用struct sk_filter结构体来记录保存用户编写的bpf指令。
struct sk_filter
{
......
unsigned int len; /* BPF 指令的数目, 也就是 insns 的长度 */
unsigned int (*bpf_func)(const struct sk_buff *skb, /* For JIT */
const struct sock_filter *filter);
......
struct sock_filter insns[0]; /* BPF 指令 */
};
sk_attach_filter实现代码如下:
int sk_attach_filter(struct sock_fprog *fprog, struct sock *sk)
{
struct sk_filter *fp, *old_fp;
unsigned int fsize = sizeof(struct sock_filter) * fprog->len;
int err;
fp = sock_kmalloc(sk, fsize+sizeof(*fp), GFP_KERNEL);
/* 从用户空间向内核空间拷贝代理程序 */
if (copy_from_user(fp->insns, fprog->filter, fsize)) {
sock_kfree_s(sk, fp, fsize+sizeof(*fp));
return -EFAULT;
}
/* 在沙箱中对代理程序做安全检测 */
err = sk_chk_filter(fp->insns, fp->len);
if (err) {
sk_filter_uncharge(sk, fp);
return err;
}
rcu_read_lock_bh();
old_fp = rcu_dereference(sk->sk_filter);
/* 在 sk_filter 赋值经过检测的bpf程序 */
rcu_assign_pointer(sk->sk_filter, fp);
rcu_read_unlock_bh();
…
return 0;
}
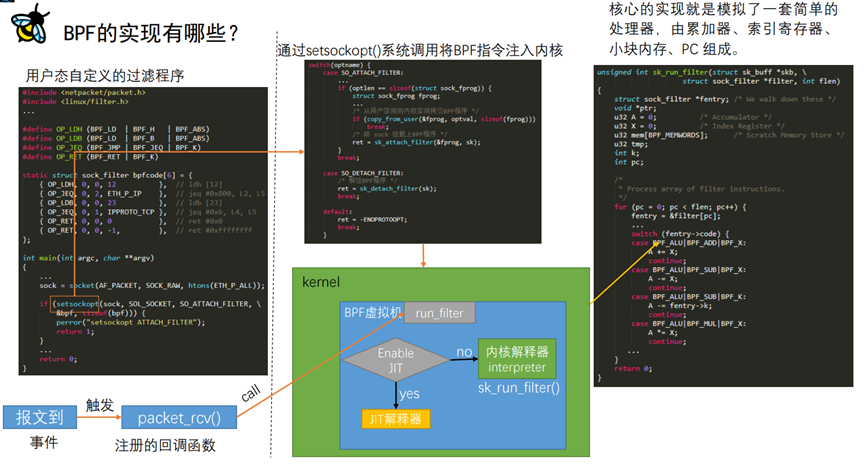
至此,我们已经知道了文章开始提到的前两个疑问,即如何编写bpf指令程序,并加载进内核。最后来看内核中的bpf程序何时会被触发执行。
何时运行BPF程序
网络包(接收/发送)达到数据链路层会调用预置的钩子函数packet_rcv,其中调用的run_filter函数会检测sk_filter中是否挂载了bpf程序,然后调用sk_run_filter函数执行bpf程序。
static int packet_rcv(struct sk_buff *skb, struct net_device *dev, struct packet_type *pt, struct net_device *orig_dev)
{
sk = pt->af_packet_priv;
snaplen = skb->len;
/* 核心代理函数的触发逻辑 */
res = run_filter(skb, sk, snaplen);
if (!res)
goto drop_n_restore;
}
run_filter 的功能就是获取 sk 上设置的 sk_filter 结构, 然后 使用宏定义SK_RUN_FILTER 执行这个结构。SK_RUN_FILTER 根据是否内核使用 JIT 有两种定义,JIT 是一种通过将 BPF 虚拟机指令码映射成主机指令,从而提升 BPF filter 性能的方式。
static unsigned int run_filter(const struct sk_buff *skb,
const struct sock *sk,
unsigned int res)
{
struct sk_filter *filter;
rcu_read_lock();
filter = rcu_dereference(sk->sk_filter);
if (filter != NULL)
res = SK_RUN_FILTER(filter, skb); // For non-JIT: sk_run_filter(SKB, filter->insns) ; For JIT: (*filter->bpf_func)(SKB, filter->insns)
rcu_read_unlock();
return res;
}
sk_run_filter函数模拟了一套简单的处理器,由累加器、索引寄存器、小块内存、PC 组成,其实就是一个虚拟机。
unsigned int sk_run_filter(struct sk_buff *skb, struct sock_filter *filter, int flen)
{
struct sock_filter *fentry; /* We walk down these */
void *ptr;
u32 A = 0; /* Accumulator */
u32 X = 0; /* Index Register */
u32 mem[BPF_MEMWORDS]; /* Scratch Memory Store */
u32 tmp;
int k;
int pc;
/*
* Process array of filter instructions.
*/
for (pc = 0; pc < flen; pc++) {
fentry = &filter[pc];
switch (fentry->code) {
case BPF_ALU|BPF_ADD|BPF_X:
A += X;
continue;
case BPF_ALU|BPF_ADD|BPF_K:
A += fentry->k;
continue;
case BPF_ALU|BPF_SUB|BPF_X:
A -= X;
continue;
…
}
虚拟机执行虽然保证了内核的安全,但大量的网络包都需要经过这个虚拟机的检测,效率并不高。在 Linux 3.x 版本之后,BPF 开始引入 JIT 技术来提高这部分代码的执行效率。JIT就是将bpf指令翻译为当前系统架构下CPU可以直接执行的机器指令。
最后,bpf整个实现的原理如下图所示。
eBPF
在理解了bpf的工作原理之后,我们进入今天的主题eBPF。随着技术的不断进步,当前的bpf已经不再单纯代表原始的伯克利报文过滤器,也不再仅仅局限于网络包的过滤,bpf这个名词已经代表一项不断进步的技术。因此以下内容中提到的eBPF或者bpf都代表当前的bpf技术,不再进行区分。
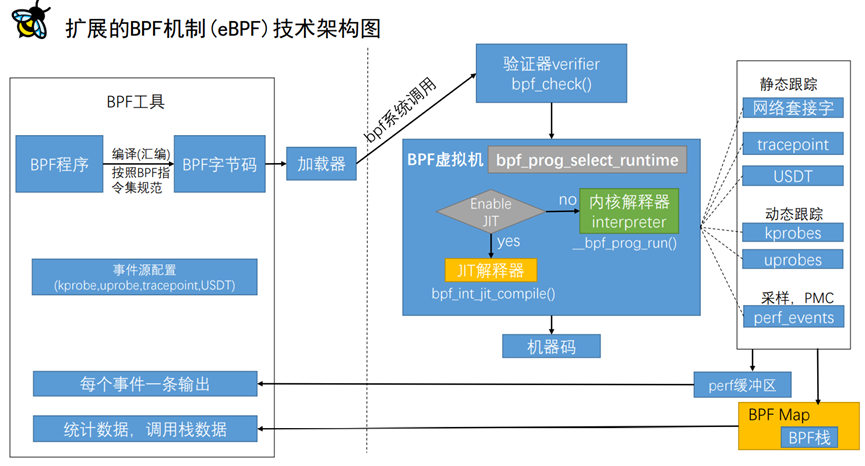
首先通过eBPF架构图来理解eBPF的运行过程,其中有以下几个关键点对于我们理解eBPF的实现原理比较重要。
-
bpf指令集 -
bpf字节码 -
bpf虚拟机
eBPF样例程序
与上文介绍的采用bpf指令编写的bpf程序不同,架构图左上角的bpf程序使用更高级的C语言进行编写。Bpf程序分为两个,通常命名为xxx_kern.c和xxx_user.c,前者加载到内核空间中执行,后者在用户空间执行。在内核源码samples/bpf目录下提供了许多样例程序,可以让我们快速的体验eBPF。例如用于统计每种协议报文数据量的程序sockex1。
//sockex1_kern.c
#include <uapi/linux/bpf.h>
#include <uapi/linux/if_ether.h>
#include <uapi/linux/if_packet.h>
#include <uapi/linux/ip.h>
#include "bpf_helpers.h"
struct bpf_map_def SEC("maps") my_map = {
.type = BPF_MAP_TYPE_ARRAY,
.key_size = sizeof(u32),
.value_size = sizeof(long),
.max_entries = 256,
};
SEC("socket1")
int bpf_prog1(struct __sk_buff *skb)
{
int index = load_byte(skb, ETH_HLEN + offsetof(struct iphdr, protocol));
long *value;
if (skb->pkt_type != PACKET_OUTGOING)
return 0;
value = bpf_map_lookup_elem(&my_map, &index);
if (value)
__sync_fetch_and_add(value, skb->len);
return 0;
}
char _license[] SEC("license") = "GPL";
//sockex1_user.c
int main(int ac, char **argv)
{
char filename[256];
FILE *f;
int i, sock;
snprintf(filename, sizeof(filename), "%s_kern.o", argv[0]);
/* 装载文件 sockex1_kern.o */
if (load_bpf_file(filename)) {
printf("%s", bpf_log_buf);
return 1;
}
/* 创建一个 socket, bind 到回环设备 */
sock = open_raw_sock("lo");
/* 设置 socket 的 SO_ATTACH_BPF 选项,传入 prog_fd */
assert(setsockopt(sock, SOL_SOCKET, SO_ATTACH_BPF, prog_fd,
sizeof(prog_fd[0])) == 0);
/* 启动一个子进程执行 ping 命令 */
f = popen("ping -c5 localhost", "r");
(void) f;
/* 循环读取 map_fd[0] 对应存储区域的各个协议类型对应的统计计数并显示 */
for (i = 0; i < 5; i++) {
long long tcp_cnt, udp_cnt, icmp_cnt;
int key;
key = IPPROTO_TCP;
assert(bpf_map_lookup_elem(map_fd[0], &key, &tcp_cnt) == 0);
key = IPPROTO_UDP;
assert(bpf_map_lookup_elem(map_fd[0], &key, &udp_cnt) == 0);
key = IPPROTO_ICMP;
assert(bpf_map_lookup_elem(map_fd[0], &key, &icmp_cnt) == 0);
printf("TCP %lld UDP %lld ICMP %lld bytes\n",
tcp_cnt, udp_cnt, icmp_cnt);
sleep(1);
}
return 0;
}
BPF程序编写完成后就通过Clang/LLVM进行编译,在此目录下执行make命令就可以全部编译所有样例程序,分别生成字节码文件sockex1_kern.o和可执行文件sockex1。可执行文件执行结果如下:
root@travel:/usr/src/linux-source-4.15.0/samples/bpf # ./sockex1
TCP 0 UDP 0 ICMP 0 bytes
TCP 0 UDP 0 ICMP 184 bytes
TCP 0 UDP 0 ICMP 300 bytes
TCP 0 UDP 0 ICMP 480 bytes
TCP 0 UDP 0 ICMP 984 bytes
编译eBPF字节码
在编译bpf程序的时候遵守了bpf指令集规范,那么如何理解bpf的指令集?
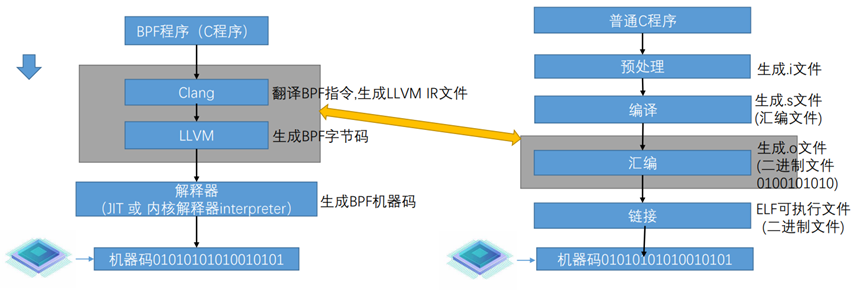
BPF指令集区别于通用的X86和ARM指令集。BPF指令集采用虚拟指令集规范。BPF指令集中的指令类似于汇编,如汇编的无条件跳转指令为jmp, 而BPF指令集中则为BPF_JMP。X86和ARM指令集,每一条指令对应的是一条特定的逻辑门电路。BPF指令集不是直接的机器码而是称为字节码,对比普通C程序如下图所示。经过Clang和LLVM的编译生成BPF字节码,然后交由BPF虚拟机执行,虚拟机通过JIT或者解释器转变成可以本地执行的机器码。
什么是字节码?
字节码也是一种可以被执行的“机器码",只不过被虚拟机执行。之所以称之为字节码,是指这里面的操作码(opcode)是—个字节长。一般机器指令由操作码和操作数组成,字节码(虚拟的机器码)也是由操作码(opcode)和操作数(op)组成。对于字节码,它是按照一套虚机指令集格式来组织。类比java程序的编译过程如下图所示。
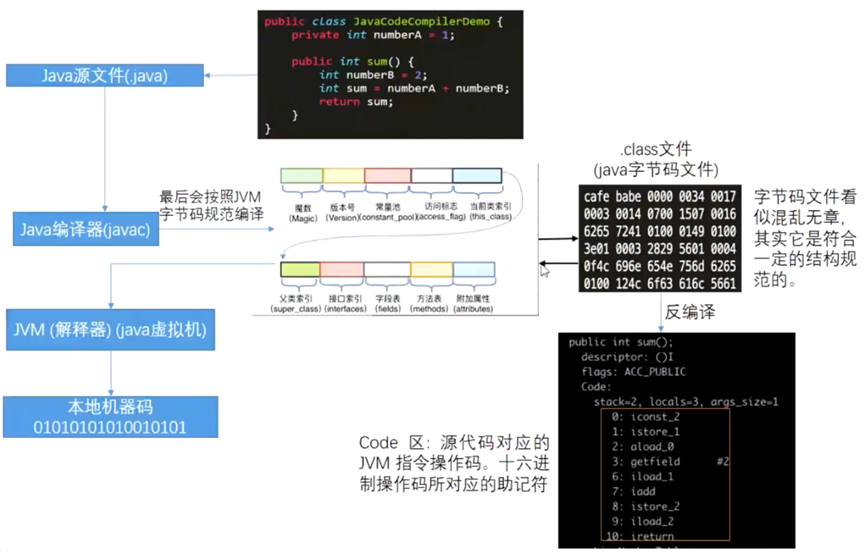
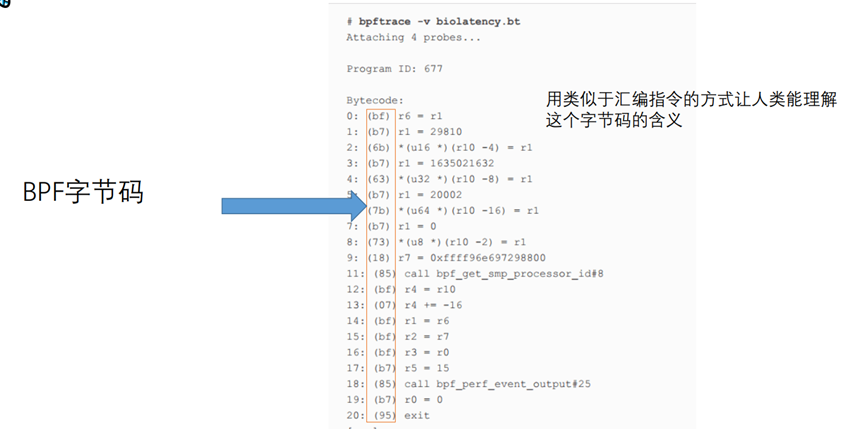
Bpf字节码如下图所示,红框内为16进制的字节码,右面表示对应的伪汇编指令,解释字节码代表的含义。
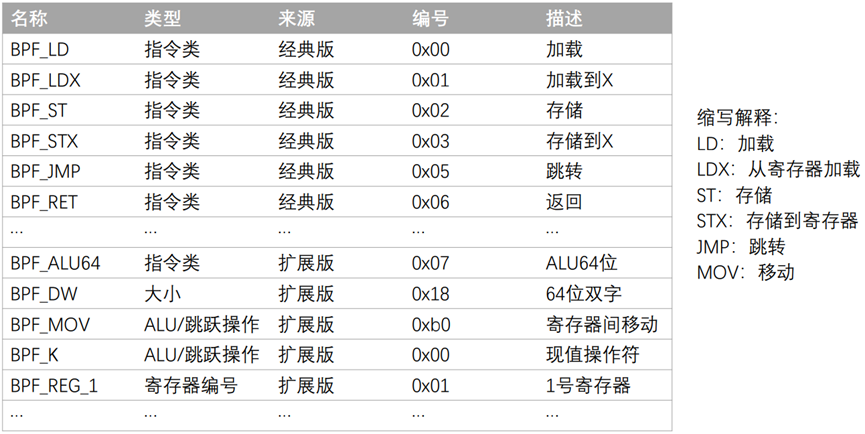
BPF指令集如何变成BPF字节码?
我们首先来看BPF常用的指令,如下图所示,有经典版BPF的指令和扩展版指令。
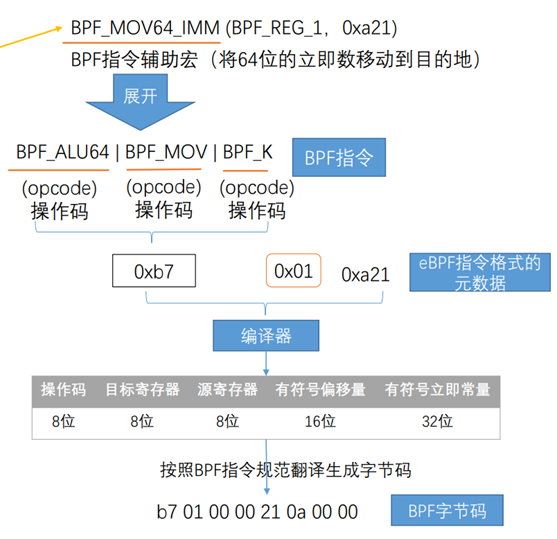
使用BPF指令宏将BPF程序声明为prog数组,那么下面一段BPF指令宏如何转换成字节码呢?
int main(int argc, char *argv[]){
struct bpf_insn prog[]={
BPF_MOV64_IMM(BPF_ REG_1,0xa21),
BPF_STX_MEM(BPF_H,BPF_REG_10,BPF_REG_1,-4),
BPF_MOV64_IMM(BPF__REG_1, 0x646c726f),
...
BPF__EXIT_INSN(),
};
...
return 0;
}
首先BPF_MOV64_IMM指令宏表示将64位的立即数移动到目的地,将其展开可以得到三个操作码,通过上文中的指令集表格可以查找到操作码对应的编号。三个操作码进行“或”操作之后得到0xb7,0x01代表寄存器编号,0xa21代表立即数,这三个数字组成了bpf指令格式的元数据。最后编译器按照指令集规范,生成字节码。
内核中使用struct bpf_insn结构体定义BPF指令规范。
struct bpf_insn {
__u8 code; /* opcode */
__u8 dst_reg:4; /* dest register */
__u8 src_reg:4; /* source register */
__s16 off; /* signed offset */
__s32 imm; /* signed immediate constant */
};
解释执行字节码
生成的BPF字节码需要由BPF虚拟机来解释执行,在不采用JIT编译的情况下,内核中实现的函数为__bpf_prog_run,
/**
* __bpf_prog_run - run eBPF program on a given context
* @ctx: is the data we are operating on
* @insn: is the array of eBPF instructions
*
* Decode and execute eBPF instructions.
*/
static unsigned int __bpf_prog_run(void *ctx, const struct bpf_insn *insn)
{
u64 stack[MAX_BPF_STACK / sizeof(u64)];
u64 regs[MAX_BPF_REG], tmp;
static const void *jumptable[256] = {
[0 ... 255] = &&default_label,
/* Now overwrite non-defaults ... */
…
[BPF_ALU64 | BPF_MOV | BPF_K] = &&ALU64_MOV_K,
[BPF_ALU64 | BPF_ARSH | BPF_X] = &&ALU64_ARSH_X,
…
};
…
ALU64_MOV_X:
DST = SRC;
CONT;
ALU64_MOV_K:
DST = IMM;
CONT;
…
return 0;
}
我们找到操作码[BPF_ALU64 | BPF_MOV | BPF_K]对应的代码标号为ALU64_MOV_K,IMM表示立即数(常量),DST代表目的地(目标寄存器)。
加载eBPF字节码
在生成字节码以后,接下来的问题是字节码如何被加载进内核中的呢?
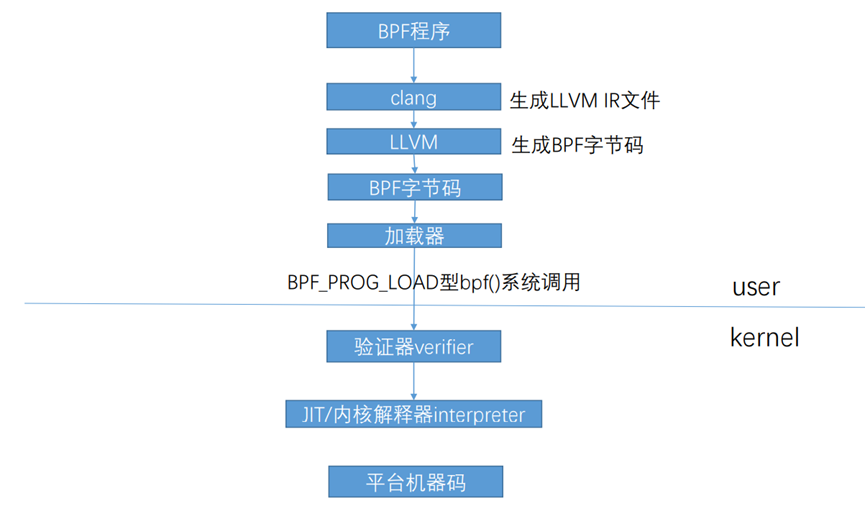
将字节码加载进内核必然涉及用户态到内核态的切换,也就需要介绍BPF相关的系统调用。结合BPF运行时模块图,我们发现BPF可以用系统调用完成对BPF数据存储模块Map的操作,以及加载字节码到内核中。其中Map是BPF内核程序与用户程序进行数据传输的桥梁,用户态程序通过系统调用获取Map中存储的数据。
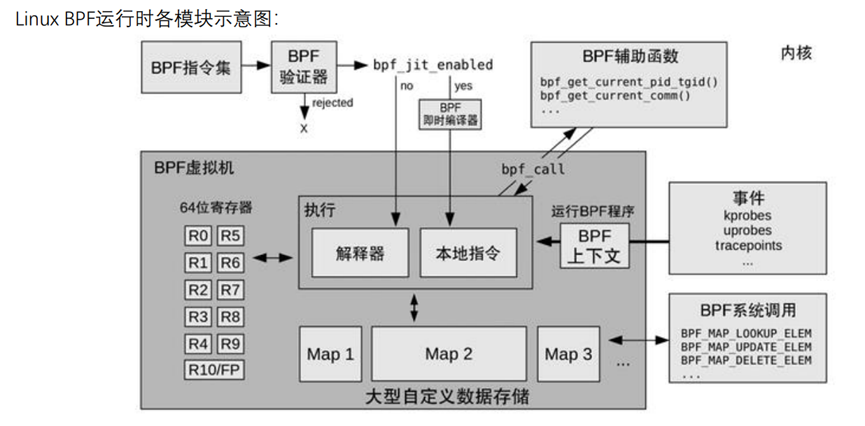
BPF系统调用在内核中定义如下:kernel/bpf/syscall.c
SYSCALL_DEFINE3(bpf, int, cmd, union bpf_attr __user *, uattr, unsigned int, size)
{
...
switch (cmd) {
case BPF_MAP_CREATE:
err = map_create(&attr);
break;
case BPF_MAP_LOOKUP_ELEM:
err = map_lookup_elem(&attr);
break;
case BPF_MAP_UPDATE_ELEM:
err = map_update_elem(&attr);
break;
case BPF_MAP_DELETE_ELEM:
err = map_delete_elem(&attr);
break;
case BPF_MAP_GET_NEXT_KEY:
err = map_get_next_key(&attr);
break;
case BPF_PROG_LOAD:
err = bpf_prog_load(&attr);
break;
...
default:
err = -EINVAL;
break;
}
return err;
}
其中,bpf_prog_load(&attr)函数负责加载bpf字节码到内核中。每一个加载到内核的BPF程序都有一个文件描述符fd返回给用户,它对应一个bpf_prog结构。bpf_prog结构体描述了一个从用户空间加载进来的bpf字节码。
struct bpf_prog {
u16 pages; /* Number of allocated pages */
kmemcheck_bitfield_begin(meta);
u16 jited:1, /* Is our filter JIT'ed? */
gpl_compatible:1, /* Is filter GPL compatible? */
cb_access:1, /* Is control block accessed? */
dst_needed:1; /* Do we need dst entry? */
kmemcheck_bitfield_end(meta);
u32 len; /* Number of filter blocks */
enum bpf_prog_type type; /* Type of BPF program */
struct bpf_prog_aux *aux; /* Auxiliary fields */
struct sock_fprog_kern *orig_prog; /* Original BPF program */
unsigned int (*bpf_func)(const struct sk_buff *skb,
const struct bpf_insn *filter);
/* Instructions for interpreter */
union {
struct sock_filter insns[0];
struct bpf_insn insnsi[0];
};
};
len:程序包含bpf指令的数量;
type:当前bpf程序的类型(kprobe/tracepoint/perf_event/sk_filter/sched_cls/sched_act/xdp/cg_skb);
aux:主要用来辅助verifier校验和转换的数据;
bpf_func:运行时BPF程序的入口。如果JIT转换成功,这里指向的就是BPF程序JIT转换后的映像;否则这里指向内核解析器(interpreter)的通用入口__bpf_prog_run();
insnsi[]:从用户态拷贝过来的,BPF程序原始指令的存放空间;
回到上文的样例eBPF程序sockex1_kern.c和sockex1_user.c,上文通过编译生成了字节码文件sockex1_kern.o和可执行文件sockex1,sockex1就充当了加载器的角色,通过bpf()系统调用把BPF字节码文件送入内核。

Makefile通过调用clang+llvm将sockex1_kern.c编译成了BPF字节码文件,然后sockex1_user.c程序中使用load_bpf_file函数将字节码文件加载到内核中。load_bpf_file函数最终调用了do_load_bpf_file函数。
load_bpf_file
|
|- do_load_bpf_file
int do_load_bpf_file(const char *path, fixup_map_cb fixup_map)
{
fd = open(path, O_RDONLY, 0);
......
/* load programs */
for (i = 1; i < ehdr.e_shnum; i++) {
......
if (memcmp(shname, "kprobe/", 7) == 0 ||
memcmp(shname, "kretprobe/", 10) == 0 ||
memcmp(shname, "tracepoint/", 11) == 0 ||
memcmp(shname, "xdp", 3) == 0 ||
memcmp(shname, "perf_event", 10) == 0 ||
memcmp(shname, "socket", 6) == 0 ||
memcmp(shname, "cgroup/", 7) == 0 ||
memcmp(shname, "sockops", 7) == 0 ||
memcmp(shname, "sk_skb", 6) == 0) {
ret = load_and_attach(shname, data->d_buf,
data->d_size);
if (ret != 0)
goto done;
}
}
}
do_load_bpf_file 会将输入的 .o 文件作为 ELF 格式 文件的逐个 section 进行分析,如 section 的名字是 特殊的(比如“socket”,该名称由SEC宏指定),那么就会将这个section 的内容作为 load_and_attach() 的参数。load_and_attach()会确定程序的类型并保存在prog_type中,继续调用 bpf_load_program, 填入的参数为程序类型 prog_type。
static int load_and_attach(const char *event, struct bpf_insn *prog, int size)
{
bool is_socket = strncmp(event, "socket", 6) == 0;
...
if (is_socket) {
prog_type = BPF_PROG_TYPE_SOCKET_FILTER;
}
...
fd = bpf_load_program(prog_type, prog, insns_cnt, license, kern_version, bpf_log_buf, PF_LOG_BUF_SIZE);
}
bpf_load_program()函数就到达用户空间与内核空间的边界了, 会通过 BPF_PROG_LOAD 系统调用,将需要的信息传递给内核,返回一个文件描述符 fd。
bpf_load_program
|
|-- bpf_load_program_name
int bpf_load_program_name(enum bpf_prog_type type, const char *name,
const struct bpf_insn *insns,
size_t insns_cnt, const char *license,
__u32 kern_version, char *log_buf,
size_t log_buf_sz)
{
int fd;
union bpf_attr attr;
__u32 name_len = name ? strlen(name) : 0;
bzero(&attr, sizeof(attr));
attr.prog_type = type;
attr.insn_cnt = (__u32)insns_cnt;
attr.insns = ptr_to_u64(insns);
attr.license = ptr_to_u64(license);
attr.log_buf = ptr_to_u64(NULL);
attr.log_size = 0;
attr.log_level = 0;
attr.kern_version = kern_version;
memcpy(attr.prog_name, name, min(name_len, BPF_OBJ_NAME_LEN - 1));
fd = sys_bpf(BPF_PROG_LOAD, &attr, sizeof(attr));
if (fd >= 0 || !log_buf || !log_buf_sz)
return fd;
...
}
内核空间加载字节码过程:
SYSCALL_DEFINE3(bpf, int, cmd, union bpf_attr __user *, uattr, unsigned int, size)
{
......
case BPF_PROG_LOAD:
err = bpf_prog_load(&attr);
}
static int bpf_prog_load(union bpf_attr *attr)
{
struct bpf_prog *prog;
......
/* 分配内核 bpf_prog 程序数据结构空间 */
prog = bpf_prog_alloc(bpf_prog_size(attr->insn_cnt), GFP_USER);
.....
/* 将 bpf 字节码从用户空间拷贝到内核空间 */
copy_from_user(prog->insns, u64_to_user_ptr(attr->insns), bpf_prog_insn_size(prog));
...
/*使用verifer 对BPF程序进行合法性扫描*/
err= bpf_check(&prog, attr);
/* 分配一个 fd 与 prog 关联,最终这个 fd 将返回用户空间 */
err = bpf_prog_new_fd(prog);
...
return err;
}
经过上述过程,内核分配了相应的数据结构 struct bpf_prog,BPF字节码已经存储在了内核空间中,那么该字节码何时会执行呢?
执行eBPF程序的时机
eBPF 程序指令都是在内核的特定 Hook 点执行,不同类型的程序有不同的钩子,有不同的上下文(ctx)。将指令 load 到内核时,内核会创建 bpf_prog 存储指令,但只是第一步,成功运行这些指令还需要完成以下两个步骤:
-
将 bpf_prog 与内核中的特定 Hook 点关联起来,也就是将BPF程序挂到钩子上。 -
在 Hook 点被访问到时,取出 bpf_prog,执行这些指令。
以kprobe原理为例,若某个kprobe探测点的内核地址attach了一段BPF程序后,当内核执行到这个地址时发生陷入(trap,x86上的int3断点指令),断点处理程序do_int3()通过中断门调用,因此当控制到达那里时中断被禁用。
该处理程序通知 kprobe 发生了断点;kprobe 检查断点是否是由 kprobe 的注册函数设置。每个探针由struct kprobe 结构描述,并存储在一个哈希表中,该哈希表由探针所在的地址进行哈希处理。如果在探针被命中的地址上没有注册kprobe,它只返回 0。否则调用注册的kprobe函数。唤醒kprobe的回调函数(pre_handler函数将在被探测指令被执行前回调,post_handler会在被探测指令执行完毕后回调),后者又会触发attach的BPF程序执行。
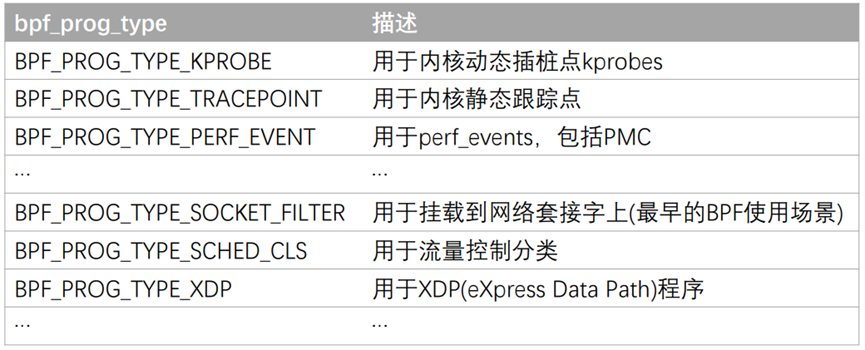
内核中的Hook点也即bpf的程序类型有哪些呢?
在内核文件/include/uapi/linux/bpf.h中给出了定义。
enum bpf_prog_type {
BPF_PROG_TYPE_UNSPEC,
BPF_PROG_TYPE_SOCKET_FILTER,
BPF_PROG_TYPE_KPROBE,
BPF_PROG_TYPE_SCHED_CLS,
BPF_PROG_TYPE_SCHED_ACT,
BPF_PROG_TYPE_TRACEPOINT,
BPF_PROG_TYPE_XDP,
BPF_PROG_TYPE_PERF_EVENT,
BPF_PROG_TYPE_CGROUP_SKB,
BPF_PROG_TYPE_CGROUP_SOCK,
BPF_PROG_TYPE_LWT_IN,
BPF_PROG_TYPE_LWT_OUT,
BPF_PROG_TYPE_LWT_XMIT,
...
BPF_PROG_TYPE_SYSCALL, /* a program that can execute syscalls */
};
BPF常见类型介绍如下:
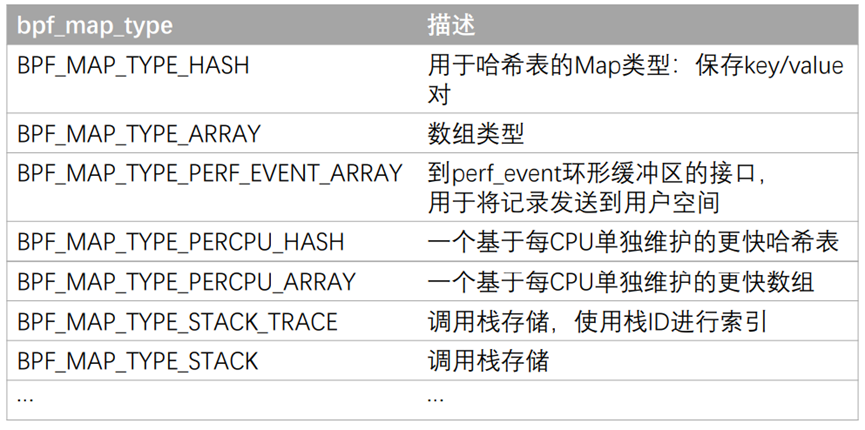
BPF同样为Map存储定义了多种类型:
enum bpf_map_type {
BPF_MAP_TYPE_UNSPEC,
BPF_MAP_TYPE_HASH,
BPF_MAP_TYPE_ARRAY,
BPF_MAP_TYPE_PROG_ARRAY,
BPF_MAP_TYPE_PERF_EVENT_ARRAY,
BPF_MAP_TYPE_PERCPU_HASH,
BPF_MAP_TYPE_PERCPU_ARRAY,
BPF_MAP_TYPE_STACK_TRACE,
BPF_MAP_TYPE_CGROUP_ARRAY,
BPF_MAP_TYPE_LRU_HASH,
BPF_MAP_TYPE_LRU_PERCPU_HASH,
...
BPF_MAP_TYPE_BLOOM_FILTER,
};
常用的map类型解释如下:
eBPF辅助函数
BPF辅助函数属于BPF的基础设施之一,因为BPF程序中不允许随意调用内核函数,内核专门提供了BPF可以调用的函数。
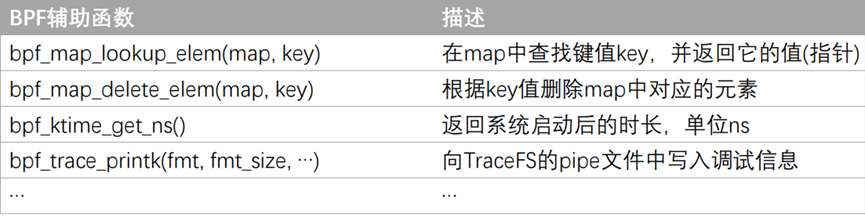
eBPF程序编程方式
前面我们通过一个简单的eBPF程序,并且介绍了其如何编译成字节码、加载到内核空间、解码执行的过程以及执行的时机,接下来我们看看BPF为我们提供了哪些可编程的方式。
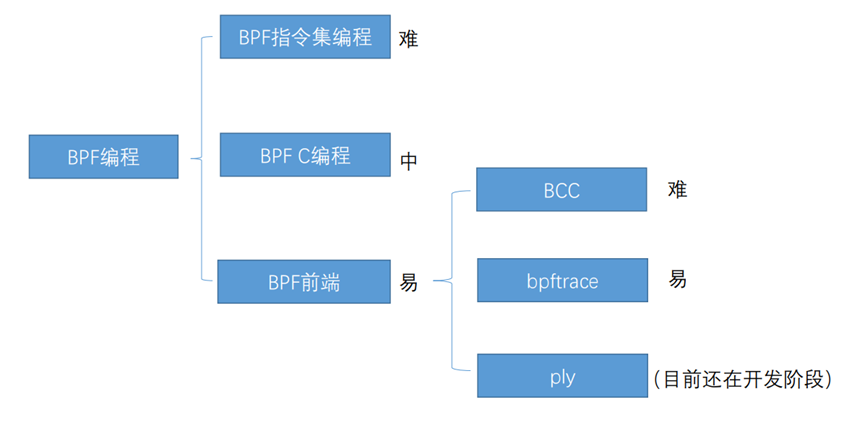
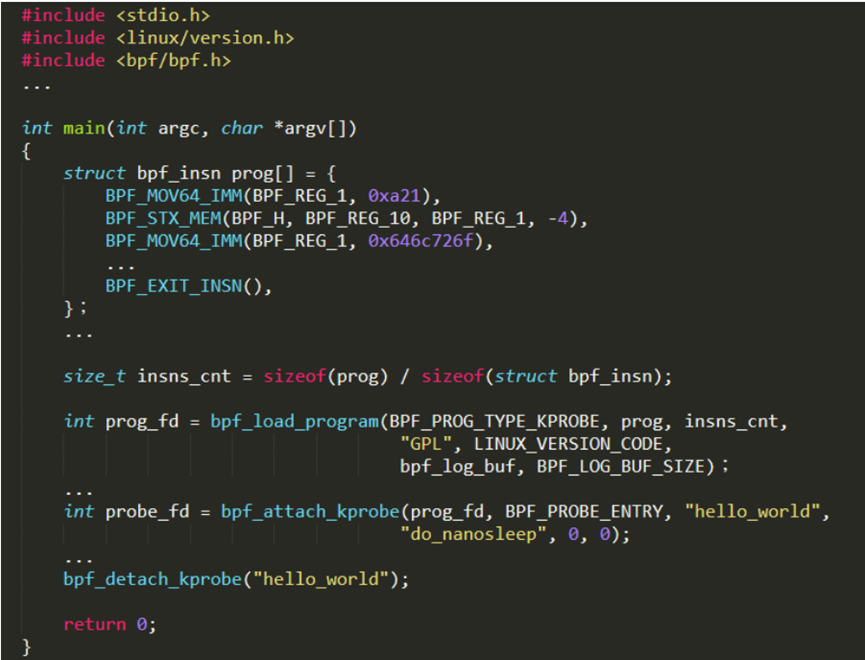
首先是BPF指令集编程,难度最大,如下图所示。
BPF C编程就是上文介绍的样例程序,如下图所示,通过定义SEC宏指定节的名称,定义map结构体在用户空间与内核空间之间传递数据,通过内核提供的bpf帮助函数来操作map。

通过BPF前端进行编程是目前最简单也是最推荐的方式,BPF目前的前端主要有BCC,bpftrace和ply。BCC提供了其他高级语言(python、Lua、C++)环境来实现用户端接口,可以实现一些功能比较复杂的,BPF程序,bpftrace通常是一个单行程序,编写非常方便,但是不易实现复杂的功能。我们可以根据需求在bcc和bpftrace之间进行灵活选择。
BCC和bpftrace都是BPF的两个前端,源代码不在内核代码仓库中,托管在github上的一个名为IO Visor的Linux基金会项目。BCC其实提供了一种使用BPF编程的框架,这套框架提供给我们一些用户接口,并且屏蔽掉了一些加载,编译的复杂环节,只需要运行写好的BCC脚本,BPF程序就可以工作。
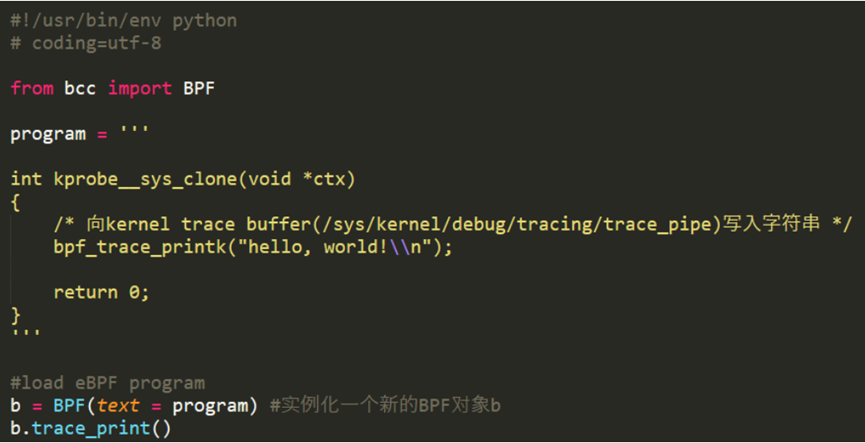
BCC程序由C和python两部分组成,C程序编写需要加载到内核空间运行的函数,python则提供了一系列封装的函数来加载bpf程序,处理Map,完成用户态的一系列操作。
BPF学习资料
书籍
-
《Linux内核观测技术BPF》 -
《BPF之巅:洞悉Linux系统和应用性能》 -
《Systems Performance》 -
《BPF Performance Tools》
Brendan Gregg大神的个人网站
https://www.brendangregg.com/index.html
Github
Linux基金会的IO Visor项目:https://github.com/iovisor https://github.com/zoidbergwill/awesome-ebpf
网站
Cilium eBPF:https://ebpf.io
BPF原始论文
https://www.tcpdump.org/papers/bpf-usenix93.pdf
本文原直播视频
https://www.bilibili.com/video/BV1LX4y157Gp?share_source=copy_web



