
io_uring,干翻 nio!原创
原创:小姐姐味道(微信公众号ID:xjjdog),欢迎分享~
大家都知道BIO非常的低效,而网络编程中的IO多路复用普遍比较高效。
现在,io_uring已经能够挑战NIO的,功能非常强大。io_uring在2019加入了Linux内核,目前5.1+的内核,可以采用这个功能。
随着一步步的优化,系统调用这个大家伙,调用次数越来越少了。
一、性能耗费在哪里?
在Linux的性能指标里,有us和sy两个指标,使用top命令可以很方便的看到。
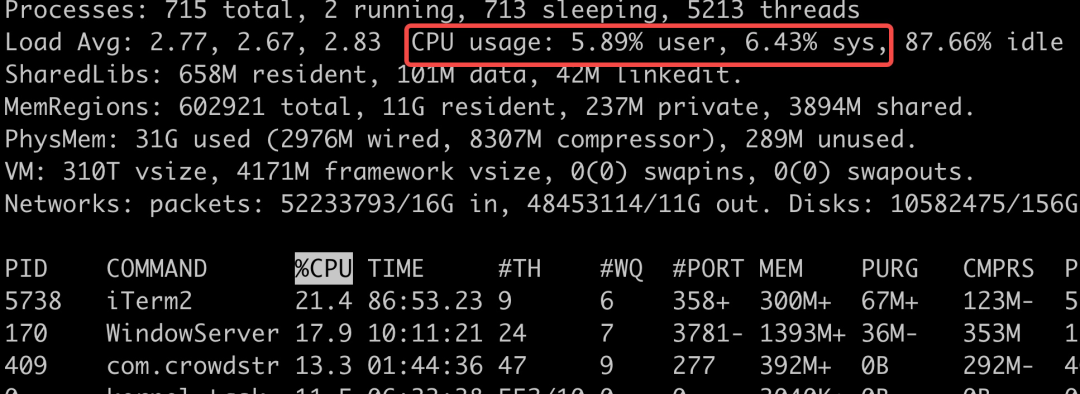
us是用户进程的意思,而sy是在内核中所使用的cpu占比。如果进程在内核态和用户态切换的非常频繁,那么效率大部分就会浪费在切换之上。
一次内核态和用户态切换的时间,普遍在微秒级别以上,可以说非常昂贵了。
cpu的性能是固定的,在无用的东西上浪费越小,在真正业务上的处理就效率越高。影响效率的有两个方面。
-
进程或者线程的数量,引起过多的上下文切换。进程是由内核来管理和调度的,进程的切换只能发生在内核态。所以,如果你的代码切换了线程,它必然伴随着一次用户态和内核态的切换。 -
IO的编程模型,引起过多的系统态和内核态切换。比如同步阻塞等待的模型,需要经过数据接收、软中断的处理(内核态),然后唤醒用户线程(用户态),处理完毕之后再进入等待状态(内核态)。
二、BIO
可以说,BIO这种模式,在线程数量上爆炸,编程模型古老,把性能低的原因全给占了。
通常情况下,BIO一条连接就对应着一个线程。BIO的读写操作是阻塞的,线程的整个生命周期和连接的生命周期是一样的,而且不能够被复用。
如果连接有1000条,那就需要1000个线程。线程资源是非常昂贵的,除了占用大量的内存,还会占用非常多的CPU调度时间,所以BIO在连接非常多的情况下,效率会变得非常低。
BIO的编程模型,也存在诸多缺陷。因为它是阻塞性编程模式,在有数据的时候,需要内核通知它;在没有数据的时候,需要阻塞wait在相应的socket上。这两个操作,都涉及到内核态和用户态的切换。如果数据报文非常频繁,BIO就需要这么一直切换。
三、NIO
提到NIO,Java中使用的是Epoll,Netty使用的是改良后的Epoll,它们都是多路复用,只不过叫惯了,所以称作NIO。
采用Reactor编程模型,可以采用非常少的线程,就能够应对海量的Socket连接。
一旦有新的事件到达,比如有新的连接到来,主线程就能够被调度到,程序就能够向下执行。这时候,就能够根据订阅的事件通知,持续获取订阅的事件。
NIO是基于事件机制的,有一个叫做Selector的选择器,阻塞获取关注的事件列表。获取到事件列表后,可以通过分发器,进行真正的数据操作。
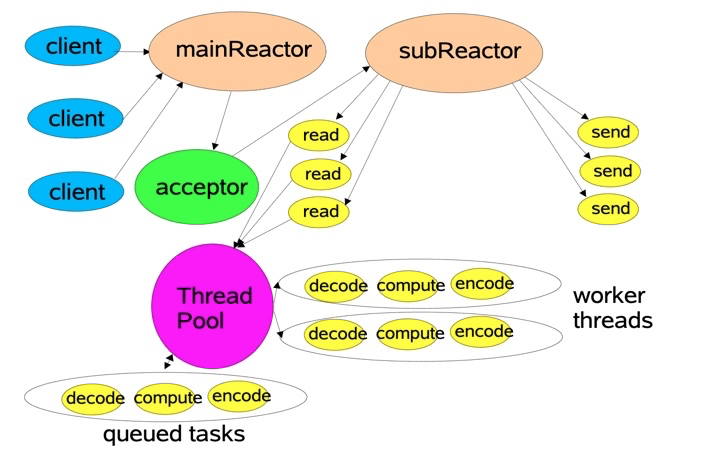
熟悉Netty的同学可以看到,这个模型就是Netty设计的基础。在Netty中,Boss线程对应着对连接的处理和分派,相当于mainReactor;Work线程 对应着subReactor,使用多线程负责读写事件的分发和处理。
通过Selector选择器,NIO将BIO中频繁的wait和notify操作,集中在了一起,大量的减少了内核态和用户态的切换。在网络流量比较高的时候,Selector甚至都不会阻塞,它将一直处于处理数据的过程中。
这种模式将每个组件的职责分的更细,耦合度也更低,能有效的解决C10k问题。
四、io_uring
但是,NIO依然有大量的系统调用,那就是Epoll的epoll_ctl。另外,获取到网络事件之后,还需要把socket的数据进行存取,这也是一次系统调用。虽然相对于BIO来说,上下文切换次数已经减少很多,但它仍然花费了比较多的时间在切换之上。
IO只负责对发生在fd描述符上的事件进行通知。事件的获取和通知部分是非阻塞的,但收到通知之后的操作,却是阻塞的。即使使用多线程去处理这些事件,它依然是阻塞的。
如果能把这些系统调用都放在操作系统里完成,那么就可以节省下这些系统调用的时间,io_uring就是干这个的。
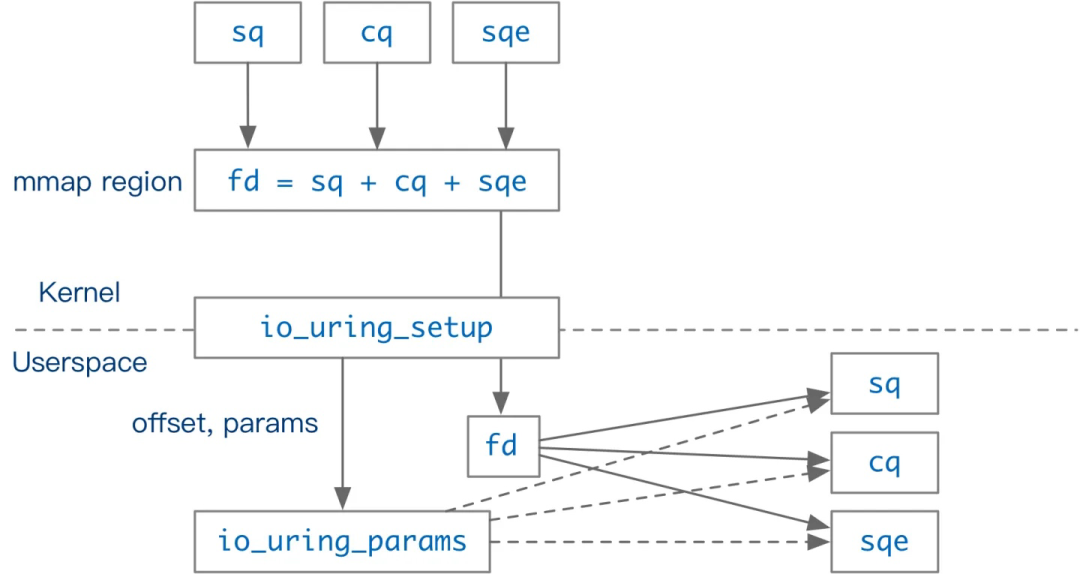
如图,用户态和内核态共享提交队列(submission queue)和完成队列(completion queue),这两条队列通过mmap共享,高效且安全。
(SQ)给内核源源不断的布置任务,然后从另外一条队列(CQ)获取结果;内核则按需进行 epoll(),并在一个线程池中执行就绪的任务。
用户态支持Polling模式,不会发生中断,也就没有系统调用,通过轮询即可消费事件;内核态也支持Polling模式,同样不会发生上下文切换。
可以看出关键的设计在于,内核通过一块和用户共享的内存区域进行消息的传递,可以绕过Linux 的 syscall 机制。
rocksdb、ceph等应用,已经在尝试这些功能,随着内核io_uring的成熟,相信网络编程在效率上会更上一层楼。



