
BCC小白写测试上下文切换延时程序原创
作者介绍:
张子恒,西安邮电大学研一在读,导师陈莉君老师,刚刚踏入Linux内核学习的小白一枚。
下文Linux内核版本5.4
01启发
学习兴趣起源于论文《Linux上下文切换性能测试的一种新方法》的阅读,该论文提出了一种在用户态编写应用程序并且调用schedu_yield()系统调用主动放弃处理器实现任务切换的测试方法,然后与传统的使用管道读写切换、在内核态测试context_switch()函数的开销等方法进行了对比分析(传统方法分析见下图),最后结果表明,使用该方法测试上下文切换的准确性和便捷性均有所提高。
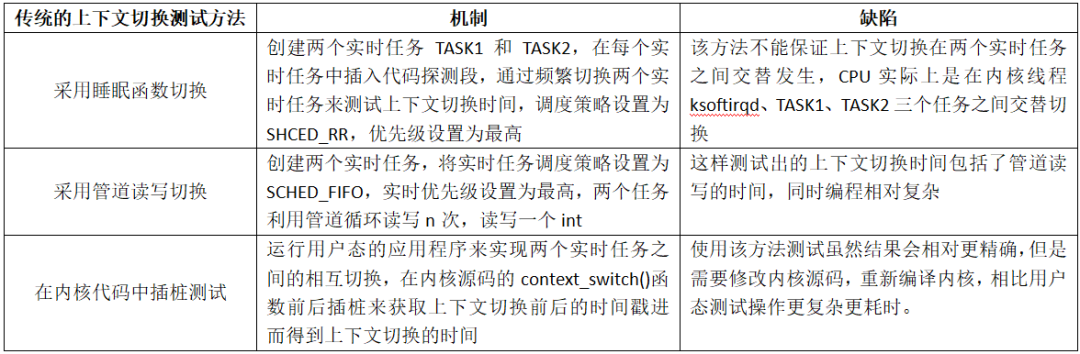
论文中提出的新方法有个明显的缺陷:原理上获得的上下文切换延时还包含了系统调用等其他指令的开销 overhead,但是他这个用户态的程序无法测量也无法避免这个overhead。
结合所学知识,受此启发:直接对内核函数context_switch()进行测试才是最准确最可靠的方法,因此可以写一个ebpf程序直接对context_switch()函数进行测试,这样的ebpf程序不仅测试出来的结果更加准确,而且操作起来也很方便,于是就有了下面的学习历程。
02思路
首先是整理思路,作为eBPF小白的我一开始也是一筹莫展,于是翻看起了《BPF之巅 洞悉Linux系统和应用性能》这本书,书中有这么几个地方很受启发:
-
P57:

由于:

内核中没有context_switch的静态跟踪点,所以这里选择用kprobes动态跟踪。(这里忘记对kprobe进行查询,导致下面绕了一波远路,这也提醒学者在写eBPF程序之前一定要先找探针)
-
P49:
kprobes 可以对任何内核函数进行插桩,它还可以对函数内部的指令进行插桩。它可以实时在生产环境系统中启用,不需要重启系统,也不需要以特殊方式重启内核。这是一项令人惊叹的能力,这意味着我们可以对 Linux 中数以万计的内核函数任意插桩根据需要生成指标。
kprobes 技术还有另外一个接口,即 kretprobes,用来对内核函数返回时进行插桩以获取返回值。当用 kprobes 和 kretprobes 对同一个函数进行插时,可以使用时间戳来记录函数执行的时长。这在性能分析中是一个重要的指标。
-
P52:
BCC:attach_kprobe 和 attach_kretprobe
于是我就准备从kprobes和kretprobes这两种探针入手,对context_switch函数的执行时长进行测量。
03实践
最后就是实践了,我利用不同的映射输出函数写了三个版本,每个版本都是上一个版本的优化。
(一)起初代码
主要涉及函数:
-
bpf_trace_printk()
语法: int bpf_trace_printk(const char *fmt, ...)
Return: 0 on success
printf()到公共trace_pipe (/sys/kernel/debug/tracing/trace_pipe)的一个简单的内核工具。对于一些快速示例,这是可以的,但有限制:最多3个args,只有1% s,并且trace_pipe是全局共享的。
-
trace_print()
语法: BPF.trace_print(fmt="fields")
该方法持续读取全局共享的/sys/kernel/debug/tracing/trace_pipe文件并打印其内容。可以通过BPF和bpf_trace_printk()函数写入该文件。
fmt: 可选,并且可以包含字段格式字符串。默认为None。
cs.c 代码如下:
#include <uapi/linux/ptrace.h>
BPF_HASH(start, u32);
int do_entry(struct pt_regs *ctx) //pt_regs结构定义了在系统调用或其他内核条目期间将寄存器存储在内核堆栈上的方式
{
u32 pid;
u64 ts;
pid = bpf_get_current_pid_tgid();
ts = bpf_ktime_get_ns(); //bpf_ktime_get_ns返回自系统启动以来所经过的时间(以纳秒为单位)。不包括系统挂起的时间。
start.update(&pid,&ts);
return 0;
}
int do_return(struct pt_regs *ctx)
{
u32 pid;
u64 *tsp, delta;
pid = bpf_get_current_pid_tgid();
tsp = start.lookup(&pid);
if (tsp != 0) {
delta = bpf_ktime_get_ns() - *tsp; //获得context_switch函数执行时间
bpf_trace_printk("The time of context_switch is %lu.\n",delta/1000);
start.delete(&pid);
}
return 0;
}
cs.py 代码如下:
from __future__ import print_function
from bcc import BPF
# load BPF program
b = BPF(src_file = "cs.c")
b.attach_kprobe(event="context_switch", fn_name="do_entry")
b.attach_kretprobe(event="context_switch", fn_name="do_return")
b.trace_print()
运行结果,遇到如下问题:

一开始以为是因为context_switch函数没有被导出的原因,经师兄提醒,查看了下探针:
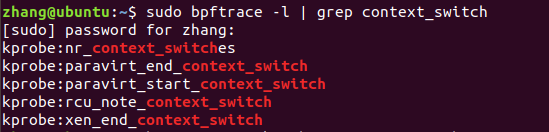
发现没有context_switch的kprobe,相关函数学习:
nr_context_switches //统计目前所有处理器总共的context switch次数
paravirt_end_context_switch //和半虚拟化相关
paravirt_start_context_switch
rcu_note_context_switch //更新全局状态为RCU,标识当前CPU发生上下文的切换
xen_end_context_switch //和虚拟话技术相关
这些函数和上下文切换时间的计算都关联不上。
教训:在编写BCC程序时,一定要先用bpftrace查看一下该插桩点是否存在!
(二)纠正代码
退一步,如果无法对context_switch函数进行跟踪,那么对内核函数schedule进行跟踪就是最好地选择(不存在__schedule函数的探针),虽然存在一定的误差,但是相比于通过用户态程序测量更加准确,相比于在内核里插桩测试更加简便,经查询,schedule函数只存在动态插桩点位:

schedule() 源码:
asmlinkage __visible void __sched schedule(void)
{
struct task_struct *tsk = current;
sched_submit_work(tsk); //sched_submit_work用于检测当前进程是否有plugged io需要处理,由于当前进程执行schedule后,有可能会进入休眠,所以在休眠之前需要把plugged io处理掉,防止死锁。
do {
preempt_disable(); //禁止抢占
__schedule(false); //->context_switch false为禁用抢占标志
sched_preempt_enable_no_resched(); //开启内核抢占
} while (need_resched()); //检查当前进程是否设置了重调度标志
sched_update_worker(tsk); //更新worker的信息,告诉工作队列我又回来了
}
对于数据的输出,由于bpf_trace_printk()是把数据写到公共trace_pipe,可能与其他程序和跟踪器冲突,因此选用BPF_PERF_OUTPUT()进行数据的输出,它的工作原理是创建一个BPF表,用于通过缓冲区向用户空间推出自定义事件数据。这是将每个事件数据推入用户空间的首选方法。
主要涉及函数:
-
BPF_PERF_OUTPUT
语法: BPF_PERF_OUTPUT(name)
创建一个BPF表,用于通过缓冲区向用户空间推出自定义事件数据。这是将每个事件数据推入用户空间的首选方法。
-
perf_submit()
语法: int perf_submit((void *)ctx, (void *)data, u32 data_size)
Return: 0 on success
BPF_PERF_OUTPUT表的方法,用于向用户空间提交自定义事件数据。
ctx参数在kprobes或kretprobes中提供。对于SCHED_CLS或SOCKET_FILTER程序,必须改用struct __sk_buff *skb。
-
open_perf_buffer()
语法: table.open_perf_buffers(callback, page_cnt=N, lost_cb=None)
它对BPF中定义为BPF_PERF_OUTPUT()的表进行操作,并关联回调Python函数callback,以便在性能环缓冲区中有可用数据时调用。这是将每个事件数据从内核传输到用户空间的推荐机制的一部分。缓冲区的大小可以通过page_cnt参数指定,该参数必须是两页数的幂,默认为8。如果回调处理数据的速度不够快,一些提交的数据可能会丢失。lost_cb将被调用来记录/监视丢失的计数。如果lost_cb 是默认的None值,它将只打印一行消息到stderr。
-
perf_buffer_poll()
语法: BPF.perf_buffer_poll(timeout=T)
它从所有打开的性能环缓冲区轮询,调用为每个条目调用open_perf_buffer时提供的回调函数。
timeout参数是可选的,以毫秒为单位。如果没有它,轮询将无限期地继续进行。
cs.c 代码如下:
#include <uapi/linux/ptrace.h>
struct data_t{
u64 t1;
u64 t2;
u64 delay;
};
BPF_PERF_OUTPUT(events);
BPF_HASH(start, u32);
int do_entry(struct pt_regs *ctx) //pt_regs结构定义了在系统调用或其他内核条目期间将寄存器存储在内核堆栈上的方式
{
u32 pid;
u64 ts;
pid = bpf_get_current_pid_tgid();
ts = bpf_ktime_get_ns()/1000; //bpf_ktime_get_ns返回自系统启动以来所经过的时间(以纳秒为单位)。不包括系统挂起的时间。
start.update(&pid,&ts);
return 0;
}
int do_return(struct pt_regs *ctx)
{
struct data_t data={};
data.t2= bpf_ktime_get_ns()/1000;
u32 pid;
u64 *tsp, delta;
pid = bpf_get_current_pid_tgid();
tsp = start.lookup(&pid);
if (tsp != 0) {
data.t1 = *tsp;
data.delay = data.t2 - data.t1;
start.delete(&pid);
events.perf_submit(ctx,&data,sizeof(data));
}
return 0;
}
cs.py 代码如下:
from __future__ import print_function
from bcc import BPF
import time
# load BPF program
b = BPF(src_file = "cs.c")
b.attach_kprobe(event="schedule", fn_name="do_entry")
b.attach_kretprobe(event="schedule", fn_name="do_return")
print("Tracing for Data's... Ctrl-C to end")
#声明了一个名为print_event()的回调函数,用于处理来自perf缓冲区的一个事件
def print_event(cpu, data, size):
event = b["events"].event(data)
print("t1:%d t2:%d delay:%d" % (event.t1,event.t2,event.delay))
#将回调函数注册到名为events的perf事件缓冲区
b["events"].open_perf_buffer(print_event)
while 1:
try:
b.perf_buffer_poll() #轮询打开perf缓冲区。如果有事件,回调函数会执行
time.sleep(1)
except KeyboardInterrupt: #Python的except用来捕获所有异常, 因为Python里面的每次错误都会抛出 一个异常,所以每个程序的错误都被当作一个运行时错误。捕获指定异常except <异常名>
exit()
cs.py 代码中time.sleep(1)说明:由于上下文切换延时特别小,因此schedule函数的触发非常频繁,每次b.perf_buffer_poll()的输出数据都特别多,会导致ctrl+c很难抢占到CPU对这个程序关闭,所以得加入time.sleep(1)以使得能有时间间隙去关闭该程序
避坑:加载到内核中的代码(这里即cs.c )不要用全局变量,用map相关函数
运行结果:
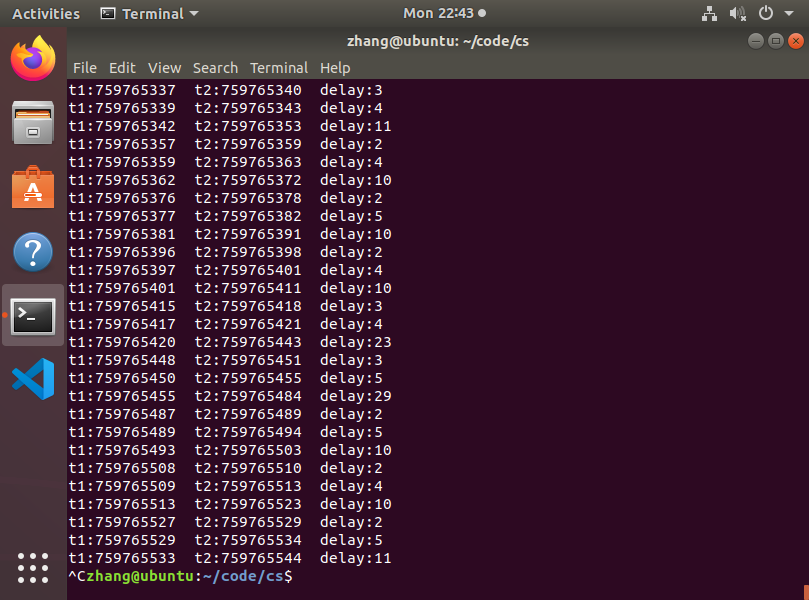
弊端:虽然可以正常运行,但是事件发生地很频繁,导致输出过快、输出量过大,不能直观的了解到数据的情况。
(三)优化代码
可以对事件进行汇总后再输出,打印为以2为幂的直方图。
主要涉及函数:
-
BPF_HISTOGRAM
语法: BPF_HISTOGRAM(name [, key_type [, size ]])
创建一个名为name的直方图映射,带有可选参数。
默认: BPF_HISTOGRAM(name, key_type=int, size=64)
-
map.increment()
语法: map.increment(key[, increment_amount])
按 increment_amount增加键的值,默认为1。用于直方图。
-
bpf_log2l()
语法: unsigned int bpf_log2l(unsigned long v)
返回所提供值的log-2。这通常用于为直方图创建索引,以构造2次方的直方图。
-
print_log2_hist()
语法: table.print_log2_hist(val_type="value", section_header="Bucket ptr", section_print_fn=None)
将表打印为ASCII中的log2直方图。表必须存储为log2,这可以使用BPF函数 bpf_log2l()来实现。
参数:val_type: 可选,列标题;section_header: 如果直方图有一个辅助键,那么将打印多个表,section_header可以用作每个表的头描述;section_print_fn: 如果section_print_fn不是None,它将被传递桶值。
cs.c 代码如下:
#include <uapi/linux/ptrace.h>
BPF_HASH(start, u32);
BPF_HISTOGRAM(dist);
int do_entry(struct pt_regs *ctx) //pt_regs结构定义了在系统调用或其他内核条目期间将寄存器存储在内核堆栈上的方式
{
u64 t1= bpf_ktime_get_ns()/1000; //bpf_ktime_get_ns返回自系统启动以来所经过的时间(以纳秒为单位)。不包括系统挂起的时间。;
u32 pid = bpf_get_current_pid_tgid();
start.update(&pid,&t1);
return 0;
}
int do_return(struct pt_regs *ctx)
{
u64 t2= bpf_ktime_get_ns()/1000;
u32 pid;
u64 *tsp, delay;
pid = bpf_get_current_pid_tgid();
tsp = start.lookup(&pid);
if (tsp != 0)
{
delay = t2 - *tsp;
start.delete(&pid);
dist.increment(bpf_log2l(delay));
}
return 0;
}
cs.py 代码如下:
from __future__ import print_function
from bcc import BPF
from time import sleep
# load BPF program
b = BPF(src_file = "cs.c")
b.attach_kprobe(event="schedule", fn_name="do_entry")
b.attach_kretprobe(event="schedule", fn_name="do_return")
print("Tracing for Data's... Ctrl-C to end")
#trace until Ctrl-C
try:
sleep(99999999)
except KeyboardInterrupt:
print()
#output
b["dist"].print_log2_hist("cs delay")
运行结果:
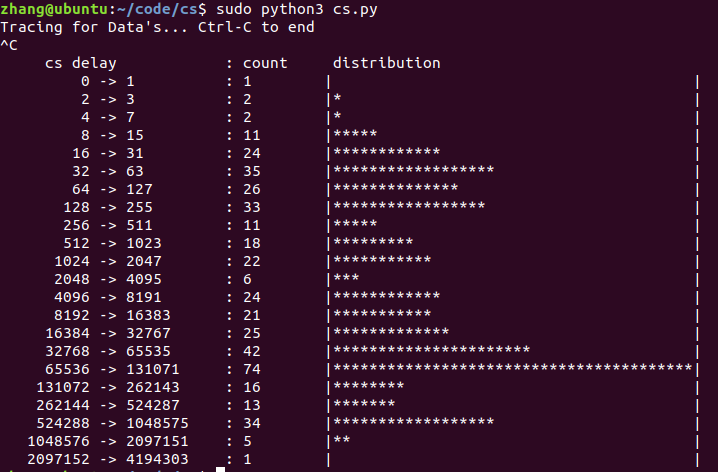
疑惑:这个运行结果和上面的那个运行结果差别比较大,这个运行结果的的值总体上偏大,而上面那个运行结果的值更符合常理,这个运行结果不应该是对上面那个运行结果的统计输出吗?为什么差别这么大呢?
解决:考虑到可能是不同进程环境导致的,于是我同时运行这两个测试程序,以保证进程环境的相同,得到以下运行结果:
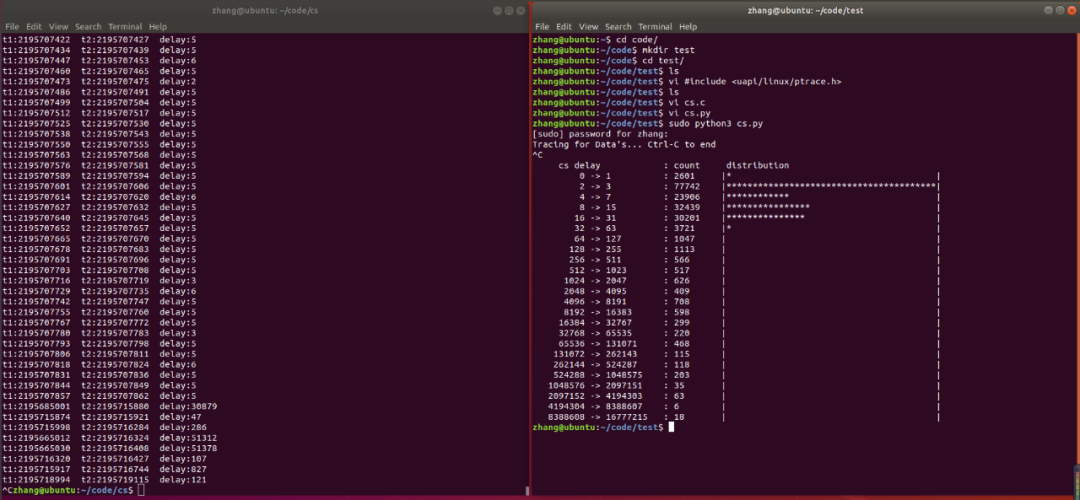
经过数据对比,在数值上,这些数据是对的上的,说明优化后的测试程序就是对优化前的测试程序数据的统计输出,之前单独运行这两个测试程序的运行结果不同就是因为不同进程环境导致的。
参考资料
- bcc Reference Guide https://github.com/iovisor/bcc/blob/master/docs/reference_guide.md
-
《BPF之巅 洞悉Linux系统和应用性能》



