
CPU性能指标提取及源码分析原创
陈老师说 当2022级的同学考上研究生,这个暑假在云班课开启了Linux内核学习之旅,很多同学是零基础、本科非计算机专业,通过两个月的学习,他们逐渐踏入Linux内核的大门,开启性能探索之旅 作者介绍 南帅波,师从陈莉君老师,西安邮电大学研一在读,刚刚踏入Linux内核学习的小白一枚。
内容介绍
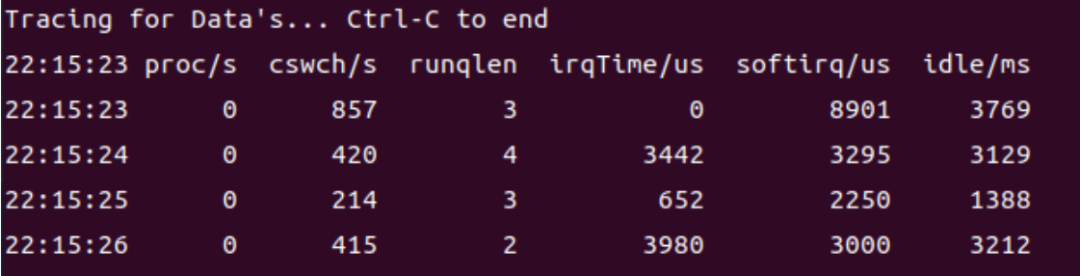
运行队列长度
CPU调度程序运行队列中存放的是那些已经准备好运行、正等待可用CPU的轻量级进程,如果准备运行 的轻量级进程数超过系统所能处理的上限,运行队列就会很长,运行队列长表明系统负载可能已经饱和。
// 获取运行队列长度
// SEC("kprobe/update_rq_clock")
int update_rq_clock(struct pt_regs *ctx) {
u32 key = 0;
u32 rqKey = 0;
struct rq *p_rq = 0;
p_rq = (struct rq *)rq_map.lookup(&rqKey);
if (!p_rq) { // 针对map表项未创建的时候,map表项之后会自动创建并初始化
return 0;
}
bpf_probe_read_kernel(p_rq, sizeof(struct rq), (void *)PT_REGS_PARM1(ctx));
u64 val = p_rq->nr_running;
runqlen.update(&key, &val);
return 0;
}周期性调度器在scheduler_tick中实现. 如果系统正在活动中, 内核会按照频率HZ自动调用该函数. 如果没有进程在等待调度, 那么在计算机电力供应不足的情况下, 内核将关闭该调度器以减少能耗. 这对于我们的 嵌入式设备或者手机终端设备的电源管理是很重要的。
-
更新相关统计量,管理内核中的与整个系统和各个进程的调度相关的统计量. 其间执行的主要操作 是对各种计数器+1。
函数 描述 定义 update_rq_clock 处理就绪队列时钟的更新, 本质上 就是增加struct rq当前实例的时钟时间戳 sched/core.c update_cpu_load_active 负责更新就绪队列的cpu_load数 组, 其本质上相当于将数组中先前 存储的负荷值向后移动一个位置, 将当前就绪队列的符合记入数组的 第一个位置. 另外该函数还引入一 些取平均值的技巧, 以确保符合数 组的内容不会呈现太多的不联系跳读. kernel/sched/fair.c calc_global_load_tick 跟新cpu的活动计数, 主要是更新 全局cpu就绪队列的 calc_load_update kernel/sched/loadavg.c -
激活负责当前进程调度类的周期性调度方法。
由于调度器的模块化结构, 主体工程其实很简单, 在更新统计信息的同时, 内核将真正的调度工作委 托给了特定的调度类方法。
内核先找到了就绪队列上当前运行的进程curr, 然后调用curr所属调度类sched_class的周期性调度 方法task_tick,即:
curr->sched_class->task_tick(rq, curr, 0);task_tick的实现方法取决于底层的调度器类, 例如完全公平调度器会在该方法中检测是否进程已经 运行了太长的时间, 以避免过长的延迟, 注意此处的做法与之前就的基于时间片的调度方法有本质区 别, 旧的方法我们称之为到期的时间片, 而完全公平调度器CFS中则不存在所谓的时间片概念.
rq结构体包含cfs和rt成员,分别表示两个就绪队列:cfs就绪队列用于组织就绪的普通进程(这个队列上 的进程用完全公平调度器进行调度);rt就绪队列用于用于组织就绪的实时进程(该队列上的进程用实时调 度器调度)。在多核系统中,每个CPU对应一个rq结构体。
struct rq {
/* runqueue lock: */
raw_spinlock_t lock;
/*
nr_running and cpu_load should be in the same cacheline because
remote CPUs use both these fields when doing load calculation.
*/
unsigned int nr_running;
....
压力测试工具 stress-ng :
-
-c 2 : 生成2个worker循环调用sqrt()产生cpu压力
-
-i 1 : 生成1个worker循环调用sync()产生io压力
-
-m 1 : 生成1个worker循环调用malloc()/free()产生内存压力

当系统运行队列长度等于虚拟处理器的个数时,用户不会明显感觉到性能下降,当运行队列长度达到虚 拟处理器的4倍或更多时,系统的响应就非常迟缓了。
如果在很长一段时间里,运行队列的长度一直都超过虚拟处理器个数的1倍,就需要关注了,只是暂时不需要立即采取行动。如果在很长一段时间里,运行队列的长度达到虚拟处理器个数的3~4倍或更高,则需要立即采取行动。
-
增加CPU以分担负载或减少处理器的负载量,从根本上减少了每个虚拟处理器上的活动线程数,从而 减少运行队列中的轻量级进程数。
-
分析系统中运行的应用,改进CPU使用率。程序员可以通过更有效的算法和数据结构来实现更好的性 能,性能专家通过减少代码路径长度或完成同样任务更少CPU指令的算法来提高性能。
调度延迟
.......
int trace_wake_up_new_task(struct pt_regs *ctx, struct task_struct *p)
{
return trace_enqueue(p->tgid, p->pid);
}
int trace_ttwu_do_wakeup(struct pt_regs *ctx, struct rq *rq, struct task_struct
*p,
int wake_flags)
{
return trace_enqueue(p->tgid, p->pid);
}
// record enqueue timestamp
static int trace_enqueue(u32 tgid, u32 pid)
{
if (FILTER || pid == 0)
return 0;
u64 ts = bpf_ktime_get_ns();
start.update(&pid, &ts);
return 0;
}
/*trace_enqueue()函数只做了一件事情,就是记录当前这个pid进程进入 runqueue 的时间戳, 现在只
考虑最普通的情况,只记录pid的情况,因此每有一个 task 被加入到 runqueue 的时候,就记录这个
task 的 pid 和当前的纳秒时间戳。*/
int trace_run(struct pt_regs *ctx, struct task_struct *prev)
{
u32 pid, tgid;
// ivcsw: treat like an enqueue event and store timestamp
if (prev->__state == TASK_RUNNING) {
tgid = prev->tgid;
pid = prev->pid;
if (!(FILTER || pid == 0)) {
u64 ts = bpf_ktime_get_ns();
start.update(&pid, &ts);
}
}
tgid = bpf_get_current_pid_tgid() >> 32;
pid = bpf_get_current_pid_tgid();
if (FILTER || pid == 0)
return 0;
u64 *tsp, delta;
// fetch timestamp and calculate delta
tsp = start.lookup(&pid);
if (tsp == 0) {
return 0; // missed enqueue
}
delta = bpf_ktime_get_ns() - *tsp;
FACTOR
// store as histogram
STORE
start.delete(&pid);
return 0;
}
.....
# load BPF program
b = BPF(text=bpf_text)
if not is_support_raw_tp:
b.attach_kprobe(event="ttwu_do_wakeup", fn_name="trace_ttwu_do_wakeup")
b.attach_kprobe(event="wake_up_new_task", fn_name="trace_wake_up_new_task")
b.attach_kprobe(event="finish_task_switch", fn_name="trace_run")
print("Tracing run queue latency... Hit Ctrl-C to end.")
.....-
标记当前进程需要被调度;
-
将被唤醒的进程添加到优先级队列,以便schedule()在选取下一个进程运行时,有机会选择到。注意 此处:对于实时进程来说,不是添加到优先级队列就一定会被调度选择到,这还与进程的优先级相关,这一 点和cfs调度器有明显区别,cfs策略在一个调度周期内所有进程都有机会被调度到,只是运行时间不同, 与nice值有关。
进程被重新调度时无论是否为刚fork出的进程都会走到finish_task_switch这个函数,主要工作为:检查回收前一个进程资源,为当前进程恢复执行做一些准备工作。
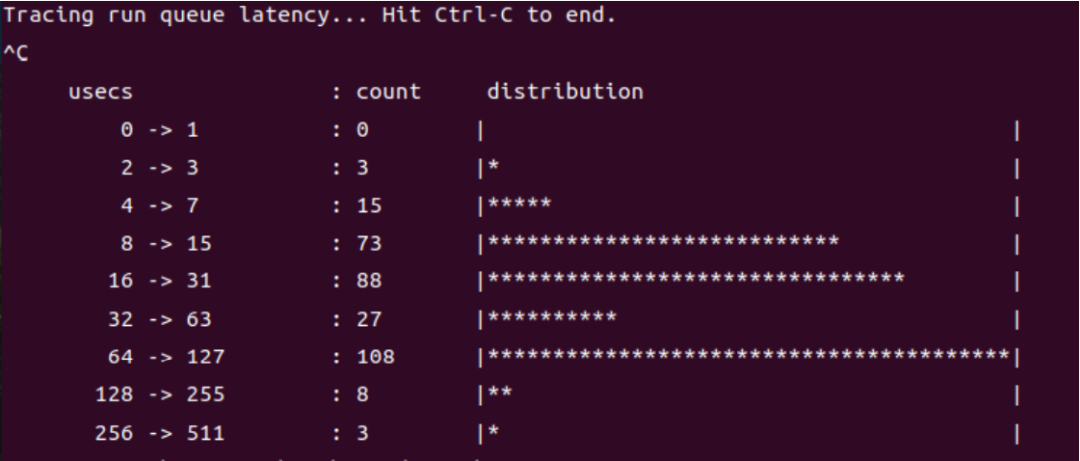

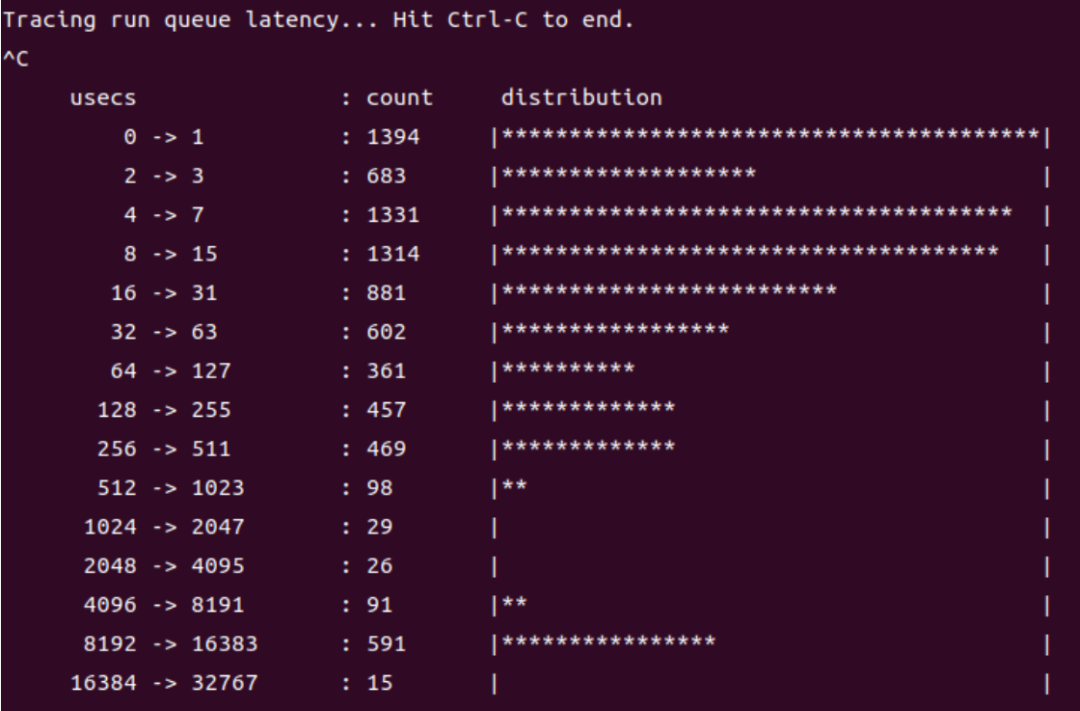
以上的 runqlat脚本只能看出延迟时间的统计结果,如果要探究延迟为什么会增大,得用 perf 这样更精 细的工具。在保持 4 个 worker 线程的情况下,采样 5 秒内和 "sched" 相关的信息:perf sched record -- sleep 5,然后用 perf sched latency 解析,可以看到每个进程的运行时间、最大延迟等 信息。像这里,就是 stress-ng 进程有 4 个线程,总共运行了 20 秒左右,最大延迟为 5.151 毫秒。
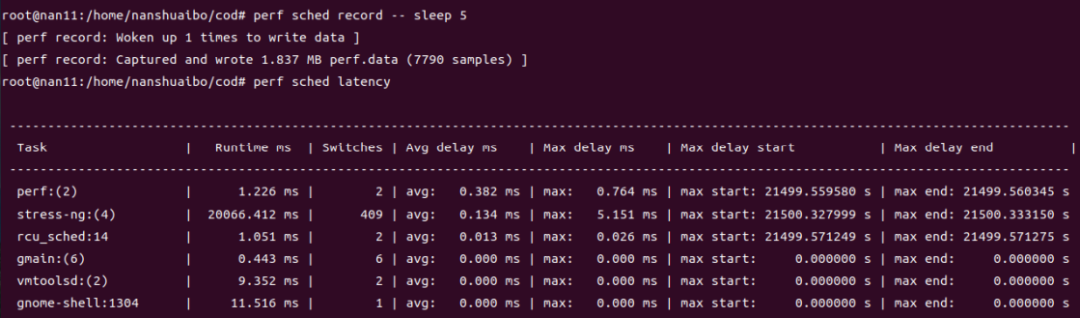
说明:
当CPU 还被其他任务占据,还没有空出来,可能还有其他在 runqueue 中排队的任务。就会产生调度延 迟,排队的任务越多,调度延迟就可能越长,所以这也是间接衡量 CPU 负载的一个指标(CPU 负载通 过计算各个时刻 runqueue 上的任务数量获得)。
平均负载:
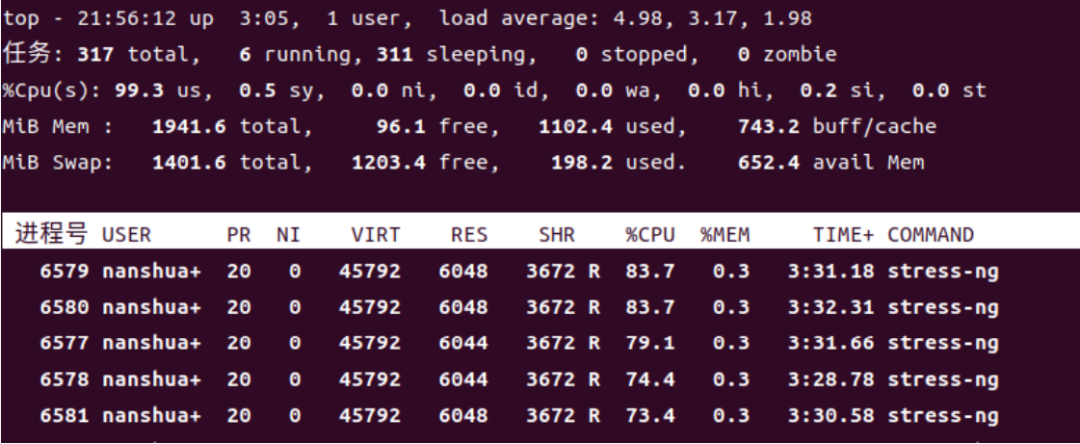
多核和多处理器下的平均负载,单个四核处理器和具有四个处理器(每个处理器一个核)的服务器是否 相同?相对来说,是的。多核和多处理器的主要区别在于,前者是指单个 CPU 具有多个内核,而后者是 指多个 CPU。总结一下:一个四核等于两个双核,也就是四个单核。平均负载与服务器中可用内核的数 量有关,而不是它们在 CPU 上的分布情况。这意味着最大利用率范围是单核 0-1、双核 0-2、四核 0- 4、八核 0-8,依此类推。在单核处理器上,负载为 1.00 意味着容量在单核处理器上恰到好处;而在双 核处理器上,负载为 1.50 意味着负载已满,另一个也要耗尽满。同样,四核处理器上的 5.00 负载是值 得担心的,而在八核处理器上,5.00 意味着正在消耗,并且仍有最佳可用空间。我的虚拟机是四核的, 这里看出,一分钟内的平均负载已经达到4.98,已经是非常高的了。
-
eBPF_Supermarket
https://gitee.com/linuxkerneltravel/lmp/tree/develop/eBPF_Supermarket/CPU_Subsystem/BCC_practice -
Linux 的调度延迟
https://zhuanlan.zhihu.com/p/462728452 -
通过性能指标学习Linux Kernel
赵晨雨,公众号:Linux内核之旅通过性能指标学习Linux Kernel - (上) -
高性能:可用于CPU分析的BPF工具
https://cloud.tencent.com/developer/article/1595327



