
【全网首发】深度剖析 Linux 伙伴系统的设计与实现原创
在上篇文章 《深入理解 Linux 物理内存分配全链路实现》 中,笔者为大家详细介绍了 Linux 内存分配在内核中的整个链路实现:
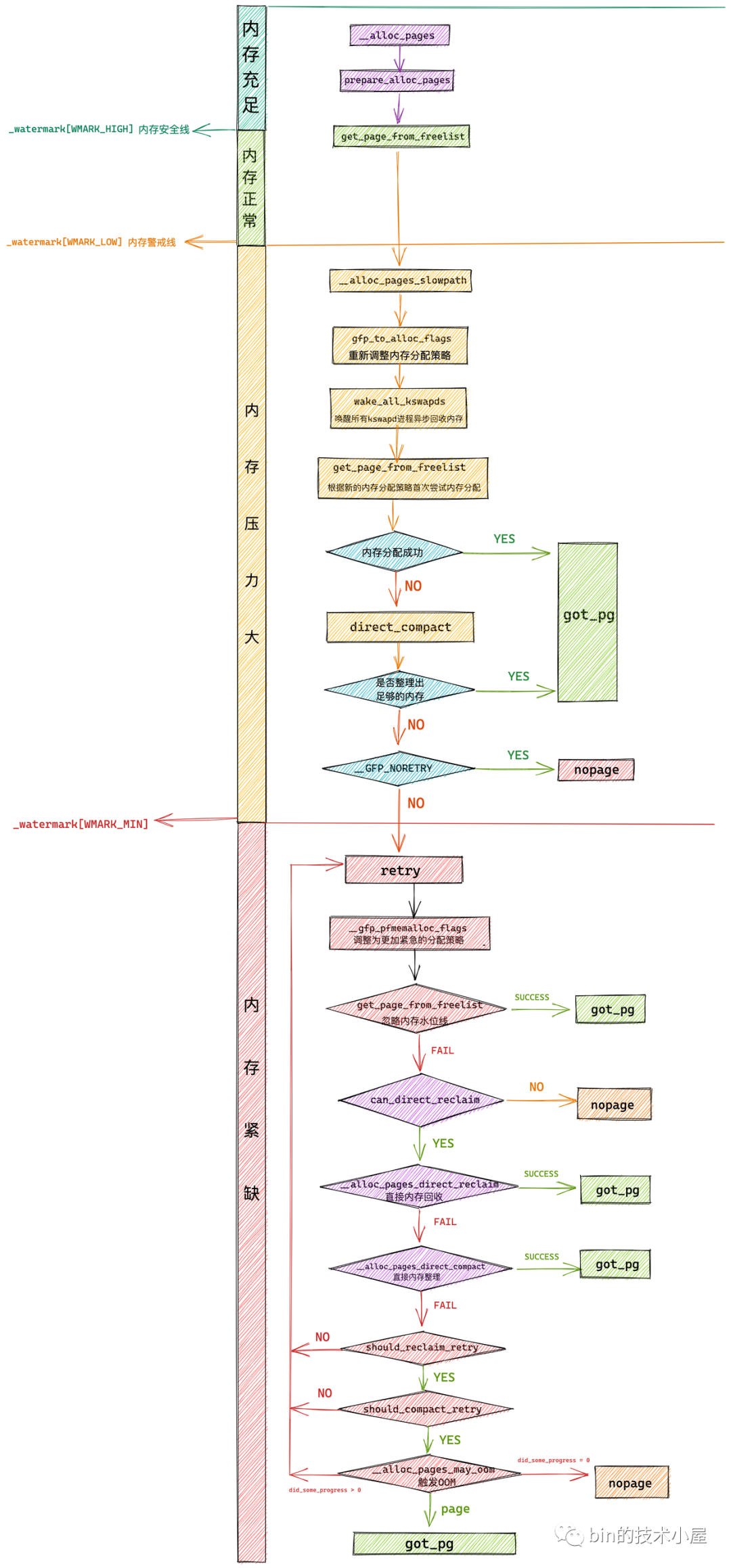
但是当内核执行到 get_page_from_freelist 函数,准备进入伙伴系统执行具体内存分配动作的相关逻辑,笔者考虑到文章篇幅的原因,并没有过多的着墨,算是留下了一个小尾巴。
那么本文笔者就为大家完整地介绍一下伙伴系统这部分的内容,我们将基于内核 5.4 版本的源码来详细的讨论一下伙伴系统在内核中的设计与实现。
1. 伙伴系统的核心数据结构
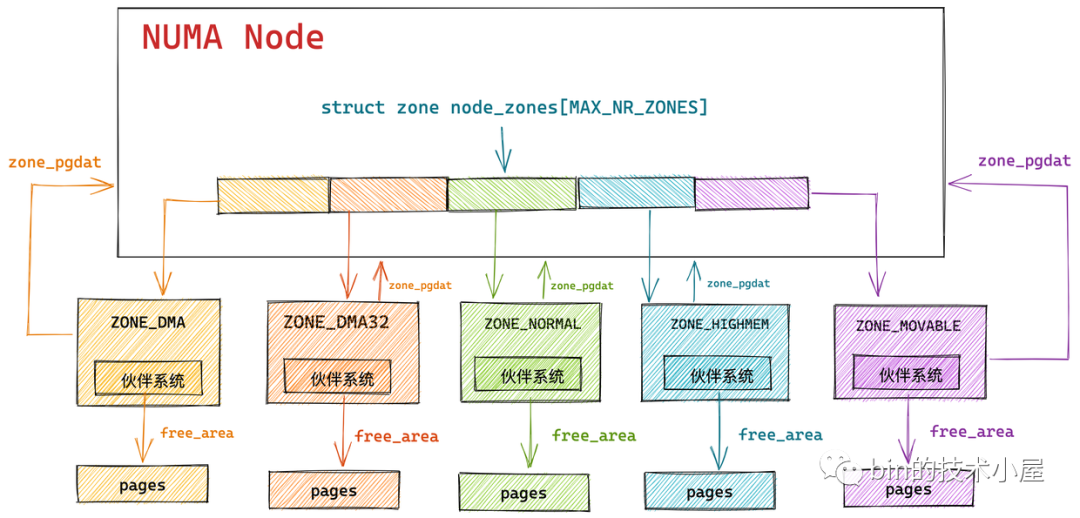
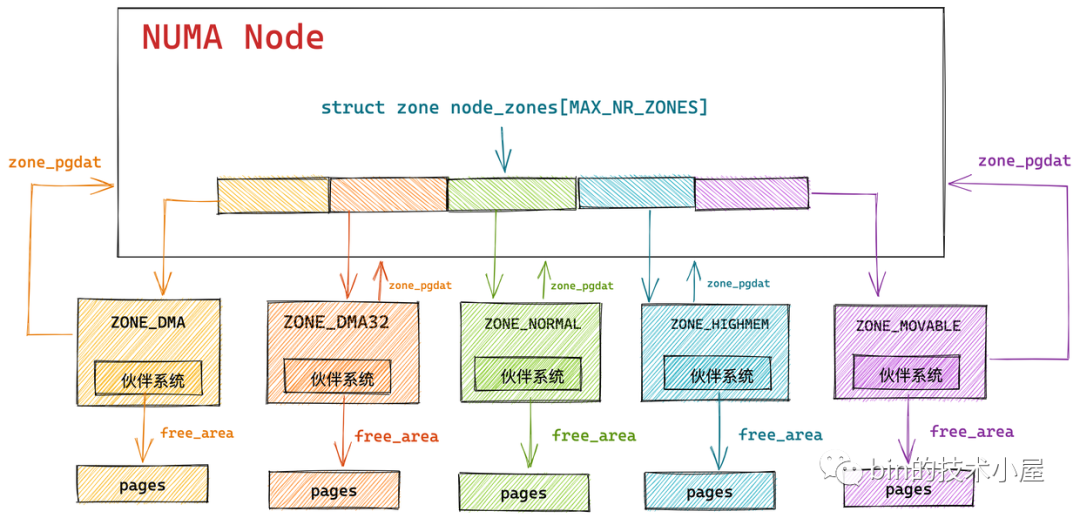
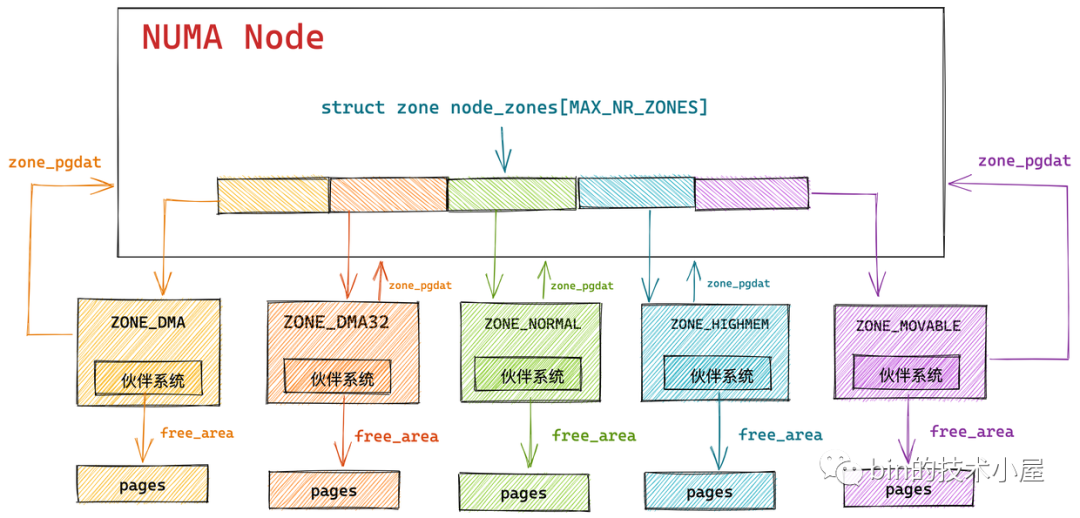
如上图所示,内核会为 NUMA 节点中的每个物理内存区域 zone 分配一个伙伴系统用于管理该物理内存区域 zone 里的空闲内存页。
而伙伴系统的核心数据结构就封装在 struct zone 里,关于 struct zone 结构体的详细介绍感兴趣的朋友可以回看下笔者之前的文章 《深入理解 Linux 物理内存管理》中第五小节 “ 5. 内核如何管理 NUMA 节点中的物理内存区域 ” 的内容。
在本小节中,我们聚焦于伙伴系统相关的数据结构介绍~~
struct zone {
// 被伙伴系统所管理的物理内存页个数
atomic_long_t managed_pages;
// 伙伴系统的核心数据结构
struct free_area free_area[MAX_ORDER];
}
struct zone 结构中的 managed_pages 用于表示该内存区域内被伙伴系统所管理的物理内存页数量。
而 managed_pages 的计算方式之前也介绍过了,它是通过 present_pages (不包含内存空洞)减去内核为应对紧急情况而预留的物理内存页 reserved_pages 得到的。
从这里可以看出伙伴系统所管理的空闲物理内存页并不包含紧急预留内存
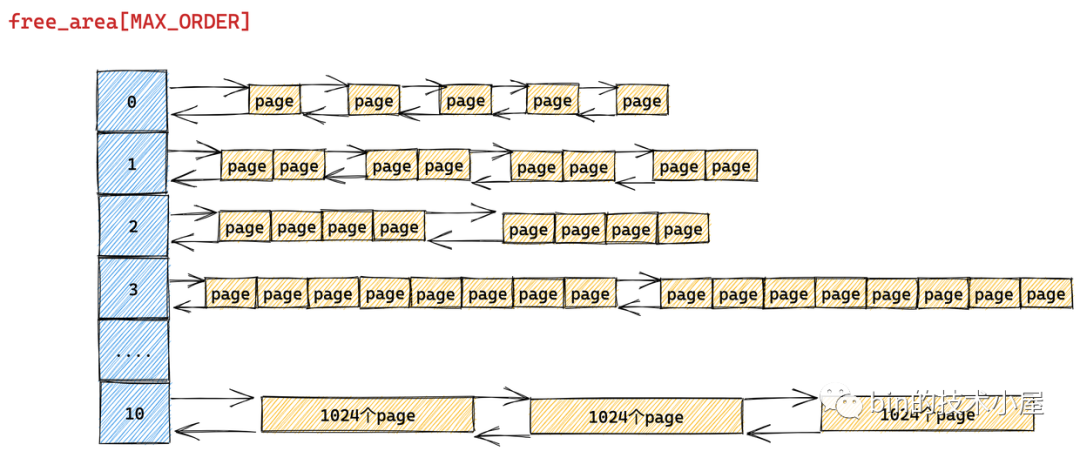
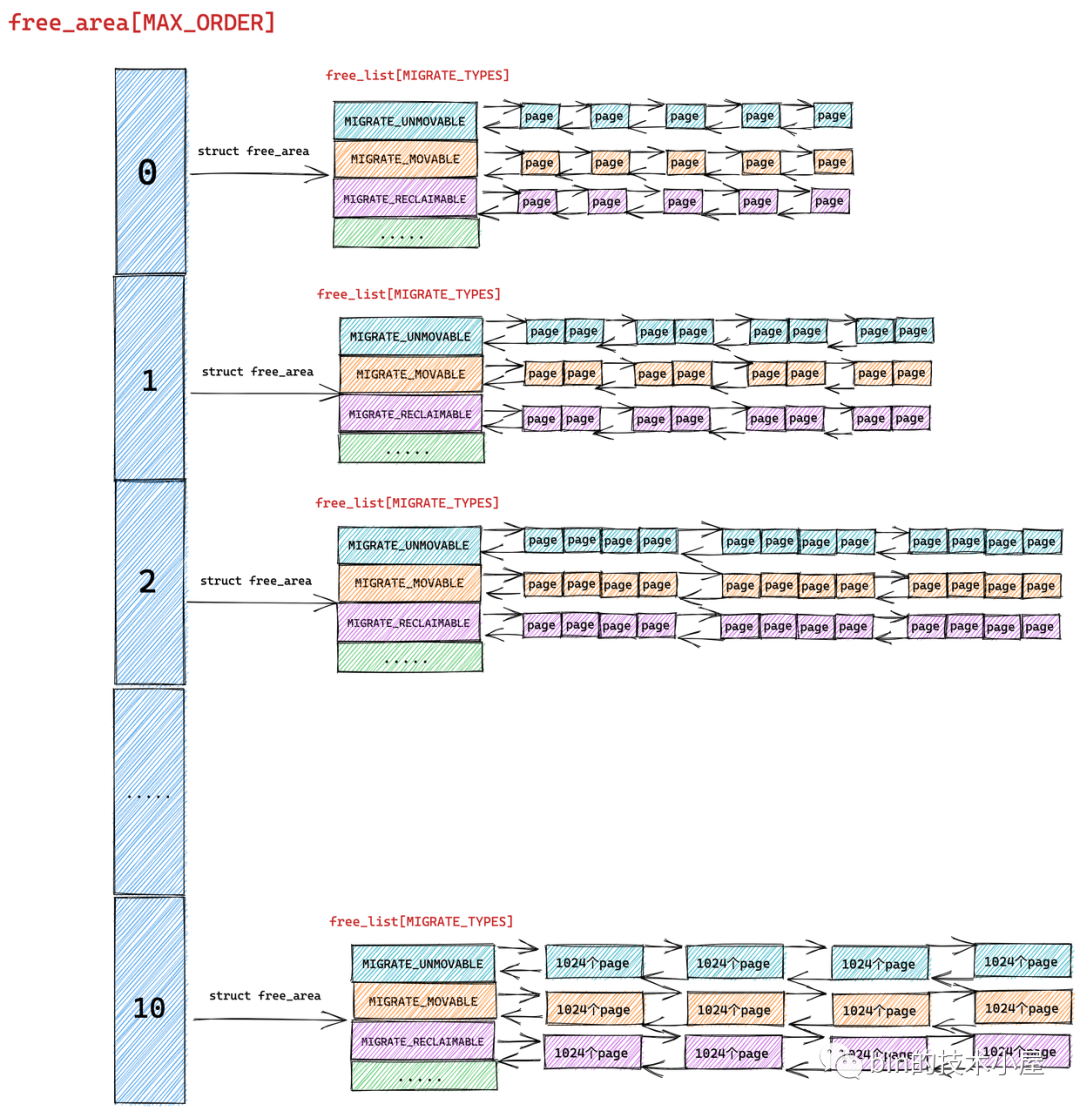
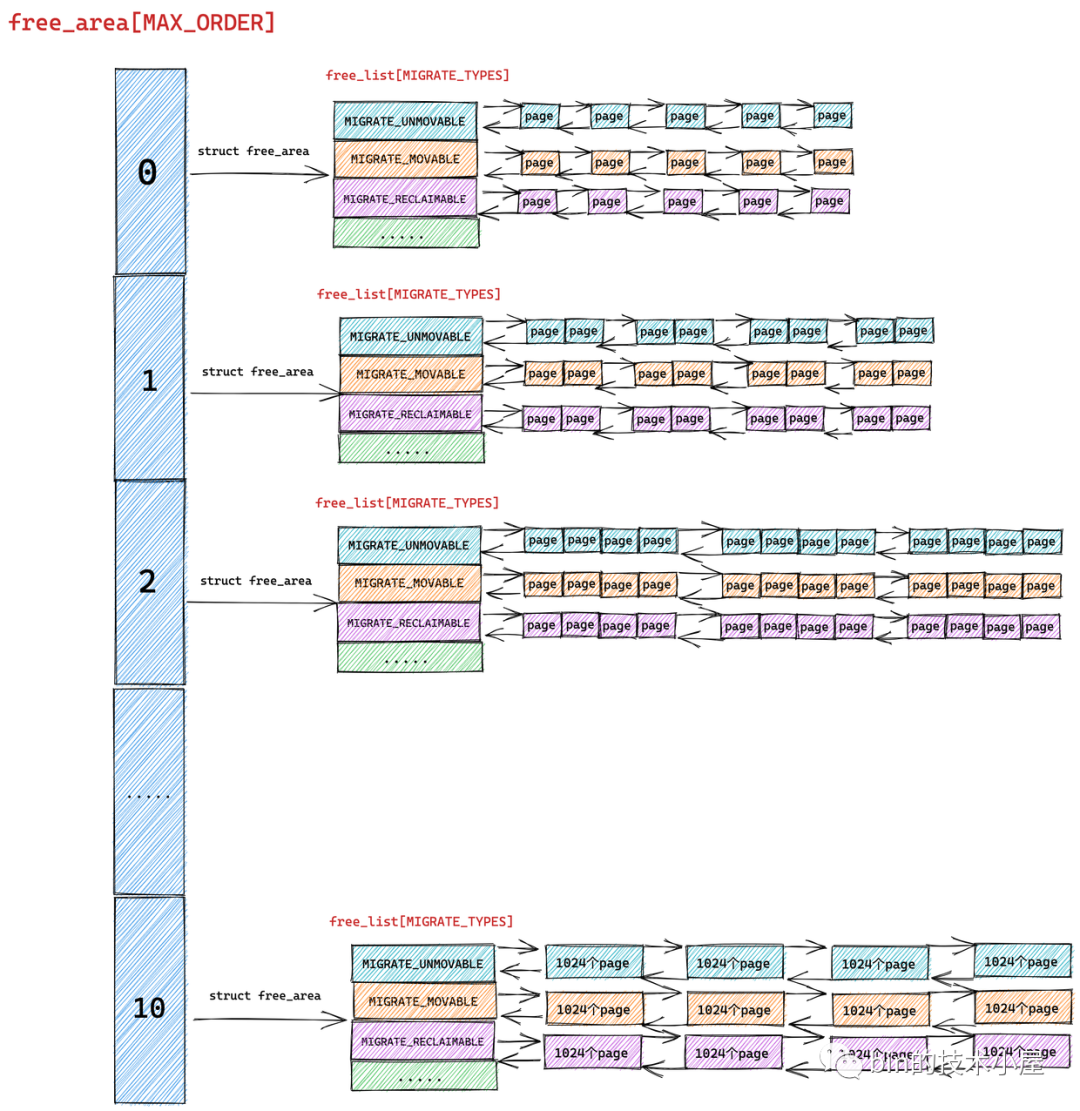
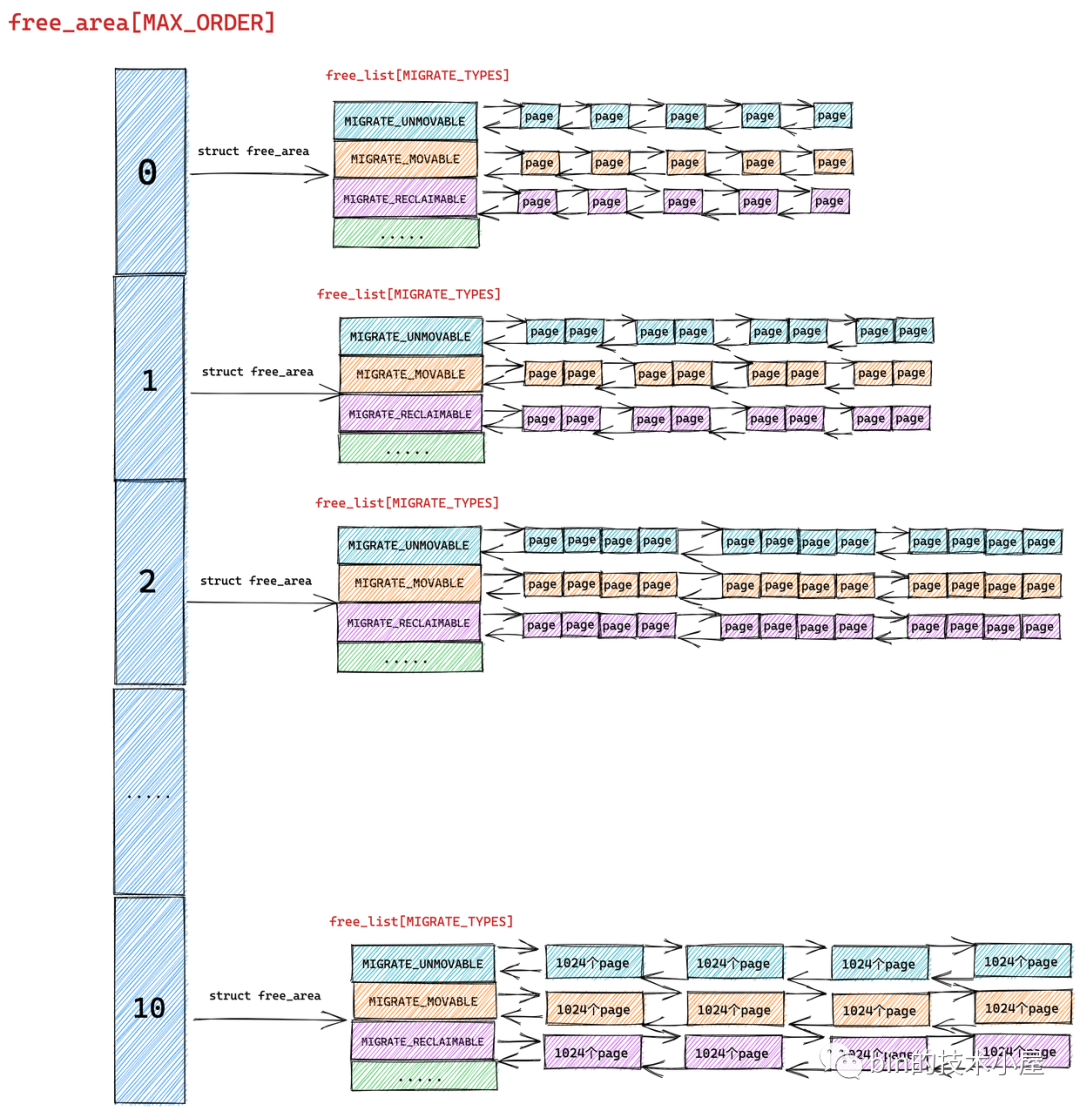
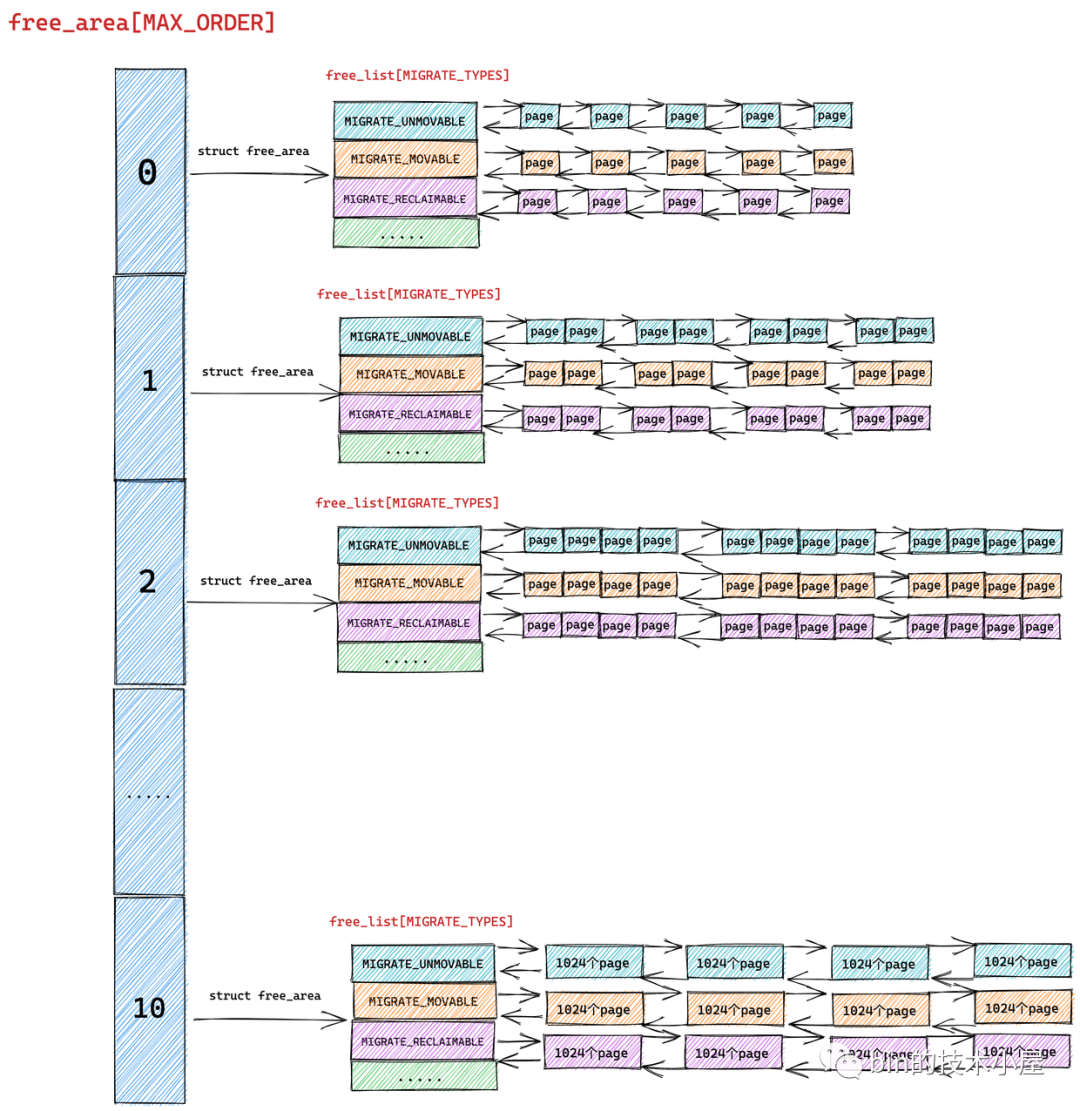
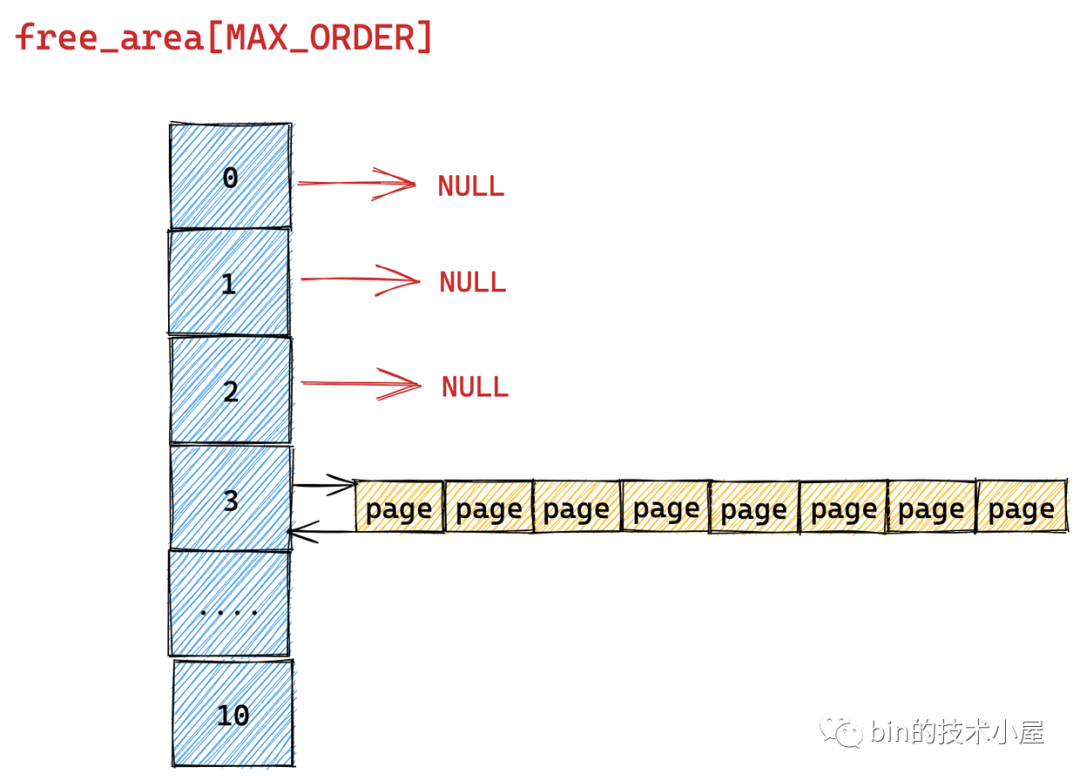
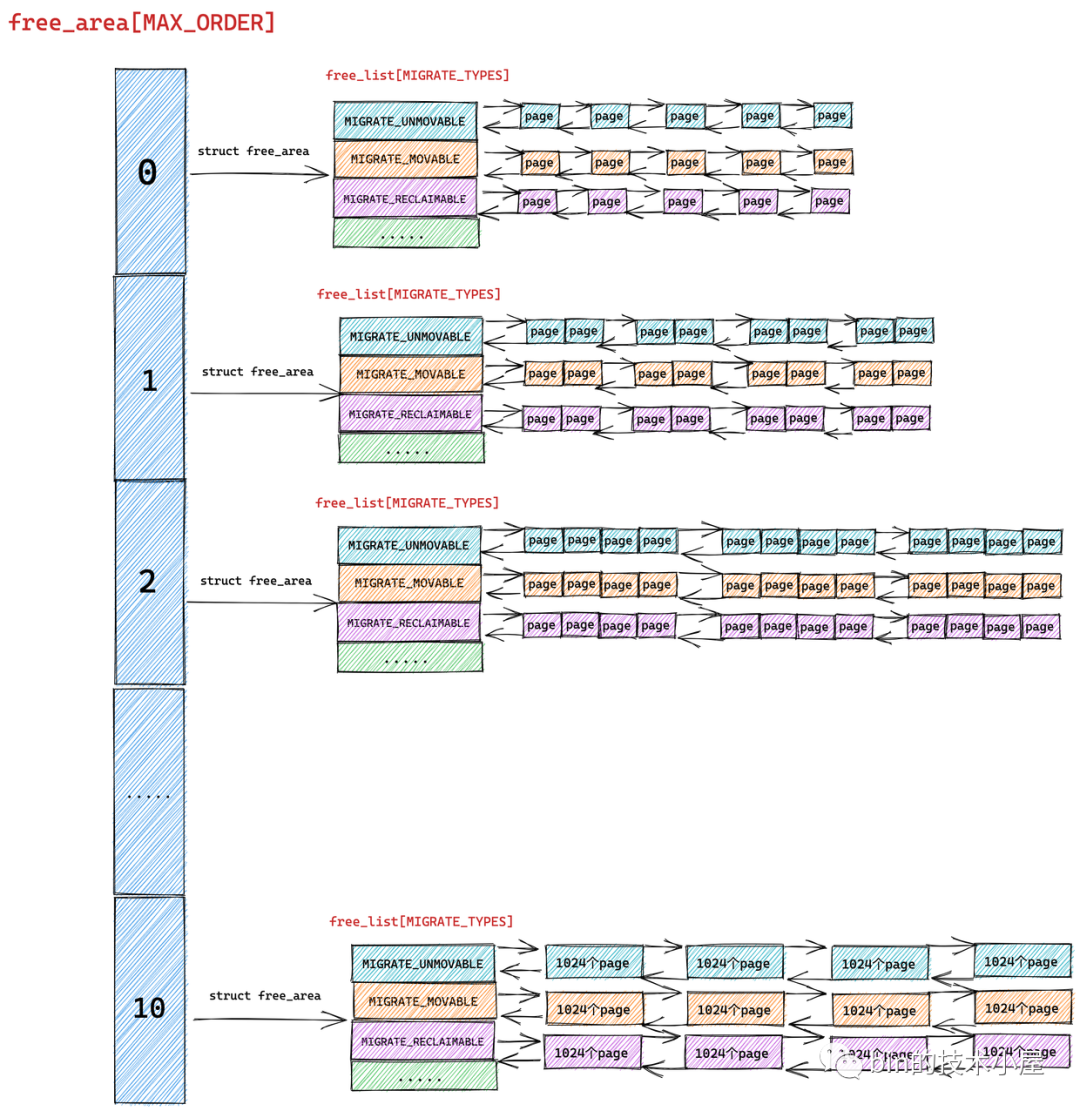
伙伴系统的真正核心数据结构就是这个 struct free_area 类型的数组 free_area[MAX_ORDER] 。MAX_ORDER 就是笔者在《深入理解 Linux 物理内存分配全链路实现》 “ 的第一小节 "1. 内核物理内存分配接口 ” 中介绍的分配阶 order 的最大值减 1。
伙伴系统所分配的物理内存页全部都是物理上连续的,并且只能分配 2 的整数幂个页,这里的整数幂在内核中称之为分配阶 order。
在我们调用物理内存分配接口时,均需要指定这个分配阶 order,意思是从伙伴系统申请多少个物理内存页,假设我们指定分配阶为 order,那么就会从伙伴系统中申请 2 的 order 次幂个物理内存页。
伙伴系统会将物理内存区域中的空闲内存根据分配阶 order 划分出不同尺寸的内存块,并将这些不同尺寸的内存块分别用一个双向链表组织起来。
比如:分配阶 order 为 0 时,对应的内存块就是一个 page。分配阶 order 为 1 时,对应的内存块就是 2 个 pages。依次类推,当分配阶 order 为 n 时,对应的内存块就是 2 的 order 次幂个 pages。
MAX_ORDER - 1 就是内核中规定的分配阶 order 的最大值,定义在 /include/linux/mmzone.h 文件中,最大分配阶 MAX_ORDER - 1 = 10,也就是说一次,最多只能从伙伴系统中申请 1024 个内存页,对应 4M 大小的连续物理内存。
/* Free memory management - zoned buddy allocator. */
#ifndef CONFIG_FORCE_MAX_ZONEORDER
#define MAX_ORDER 11
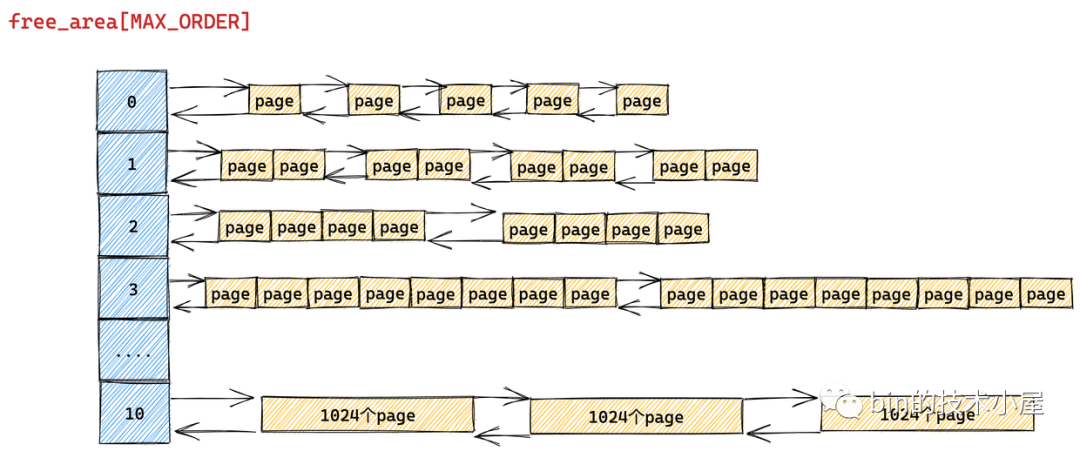
数组 free_area[MAX_ORDER] 中的索引表示的就是分配阶 order,用于指定对应双向链表组织管理的内存块包含多少个 page。
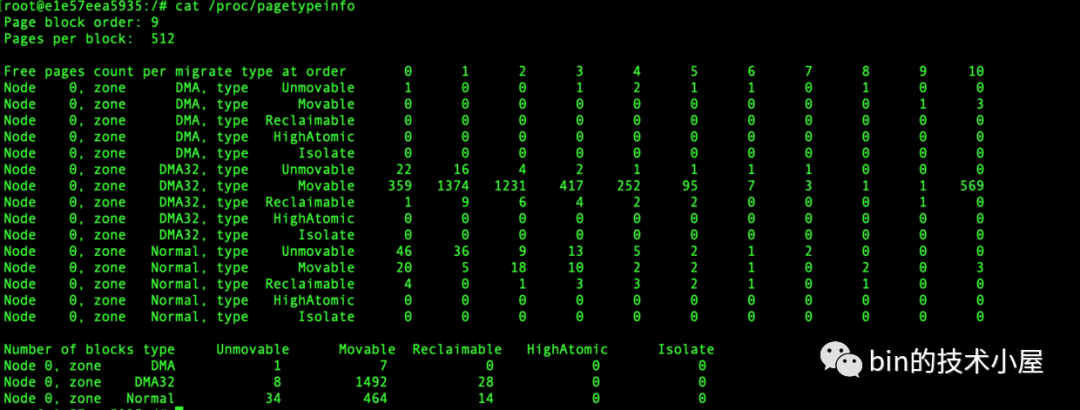
我们可以通过 cat /proc/buddyinfo 命令来查看 NUMA 节点中不同内存区域 zone 的伙伴系统当前状态:

上图展示了不同内存区域伙伴系统的 free_area[MAX_ORDER] 数组中,不同分配阶对应的内存块个数,从左到右依次是 0 阶,1 阶, ........ ,10 阶对应的双向链表中包含的内存块个数。
以上内容展示的只是伙伴系统的一个基本骨架,有了这个基本骨架之后,下面笔者继续按照一步一图的方式,来为大家揭开伙伴系统的完整样貌。
我们先从 free_area[MAX_ORDER] 数组的类型 struct free_area 结构开始谈起~~~
struct free_area {
struct list_head free_list[MIGRATE_TYPES];
unsigned long nr_free;
};
struct list_head {
// 双向链表
struct list_head *next, *prev;
};
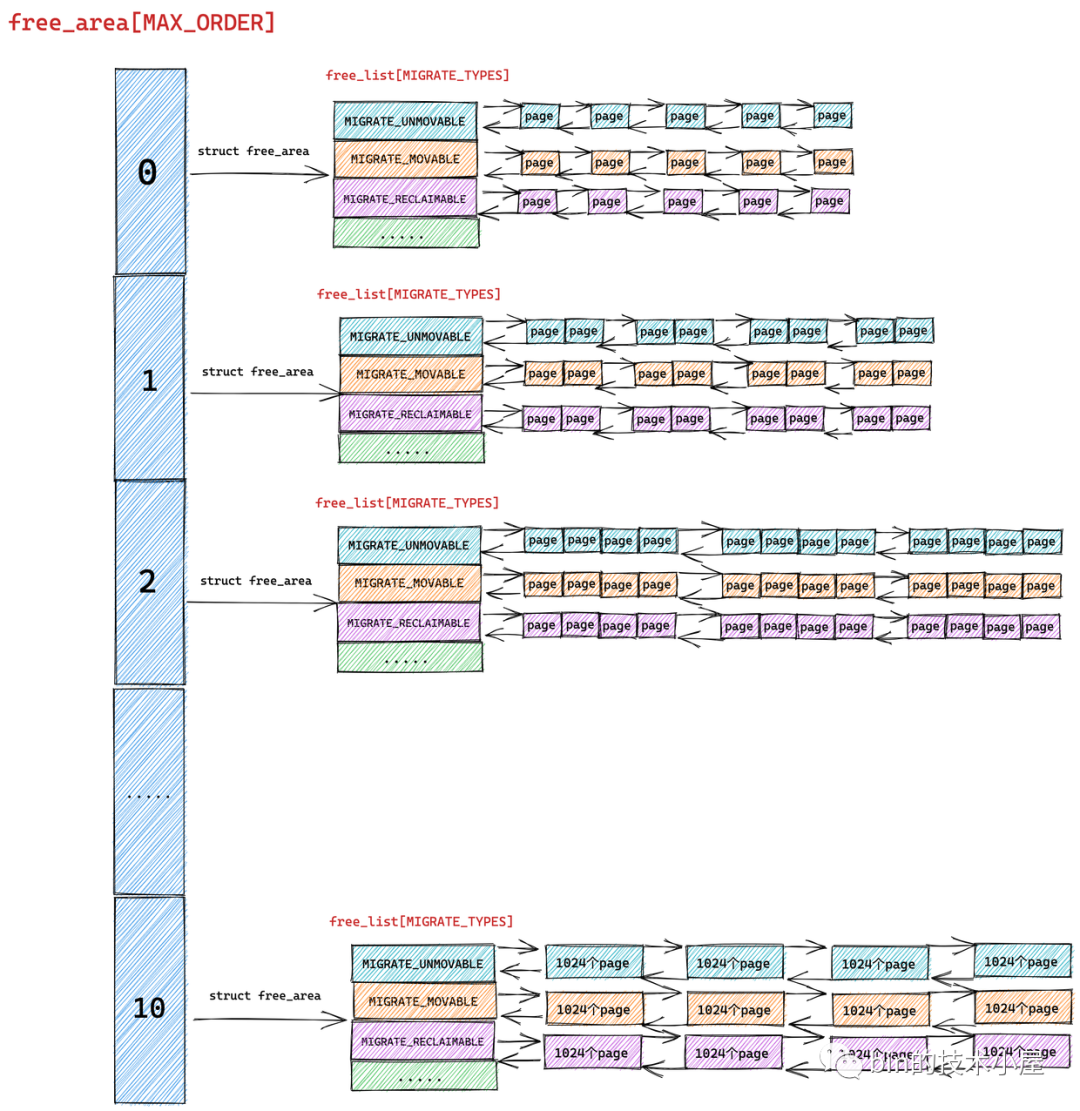
根据前边的内容我们知道 free_area[MAX_ORDER] 数组描述的只是伙伴系统的一个基本骨架,数组中的每一个元素统一组织存储了相同尺寸的内存块。内存块的尺寸分为 0 阶,1 阶 ,........ ,10 阶,一共 MAX_ORDER 个尺寸。
struct free_area 主要描述的就是相同尺寸的内存块在伙伴系统中的组织结构, nr_free 则表示的是该尺寸的内存块在当前伙伴系统中的个数,这个值会随着内存的分配而减少,随着内存的回收而增加。
注意:nr_free 表示的可不是空闲内存页 page 的个数,而是空闲内存块的个数,对于 0 阶的内存块来说 nr_free 确实表示的是单个内存页 page 的个数,因为 0 阶内存块是由一个 page 组成的,但是对于 1 阶内存块来说,nr_free 则表示的是 2 个 page 集合的个数,以此类推对于 n 阶内存块来说,nr_free 表示的是 2 的 n 次方 page 集合的个数
这些相同尺寸的内存块在 struct free_area 结构中是通过 struct list_head 结构类型的双向链表统一组织起来的。
按理来说,内核只需要将这些相同尺寸的内存块在 struct free_area 中用一个双向链表串联起来就行了。
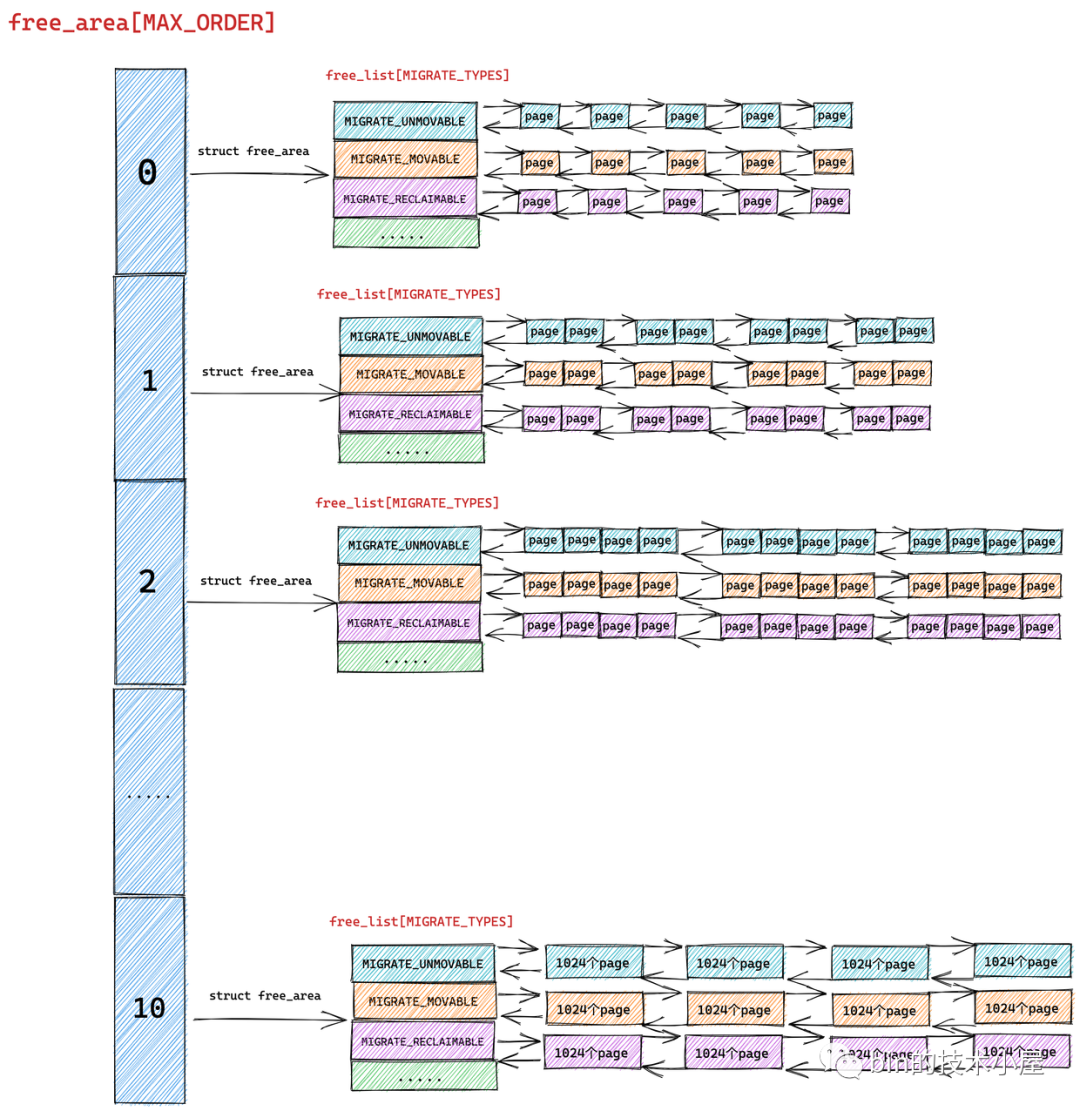
但是我们从源码中却看到内核是用多个双向链表来组织这些相同尺寸的内存块的,这些双向链表组成一个数组 free_list[MIGRATE_TYPES],该数组中双向链表的个数为 MIGRATE_TYPES。
我们从 MIGRATE_TYPES 的字面意思上可以看出,内核会根据物理内存页的迁移类型将这些相同尺寸的内存块近一步通过不同的双向链表重新组织起来。
free_area 是将相同尺寸的内存块组织起来,free_list 是在 free_area 的基础上近一步根据页面的迁移类型将这些相同尺寸的内存块划分到不同的双向链表中管理
而物理内存页面的迁移类型 MIGRATE_TYPES 定义在 /include/linux/mmzone.h 文件中:
enum migratetype {
MIGRATE_UNMOVABLE, // 不可移动
MIGRATE_MOVABLE, // 可移动
MIGRATE_RECLAIMABLE, // 可回收
MIGRATE_PCPTYPES, // 属于 CPU 高速缓存中的类型,PCP 是 per_cpu_pageset 的缩写
MIGRATE_HIGHATOMIC = MIGRATE_PCPTYPES, // 紧急内存
#ifdef CONFIG_CMA
MIGRATE_CMA, // 预留的连续内存 CMA
#endif
#ifdef CONFIG_MEMORY_ISOLATION
MIGRATE_ISOLATE, /* can't allocate from here */
#endif
MIGRATE_TYPES // 不代表任何区域,只是单纯表示一共有多少个迁移类型
};
MIGRATE_UNMOVABLE 表示不可移动的页面类型,这种类型的物理内存页面是固定的不能随意移动,内核所需要的核心内存大多数是从 MIGRATE_UNMOVABLE 类型的页面中进行分配,这部分内存一般位于内核虚拟地址空间中的直接映射区。
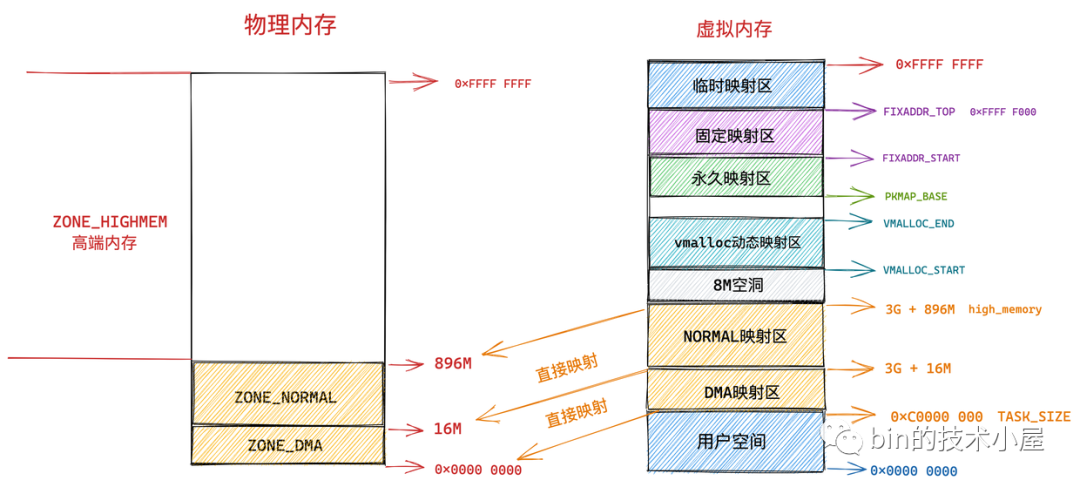
在内核虚拟地址空间的直接映射区中,虚拟内存地址与物理内存地址都是直接映射的,虚拟内存地址通过减去一个固定的偏移量就可以直接得到物理内存地址,由于这种直接映射的关系,所以这部分内存是不能移动的,因为一旦移动虚拟内存地址就会发生变化,这样一来虚拟内存地址减去固定的偏移得到的物理内存地址就不一样了。
MIGRATE_MOVABLE 表示可以移动的内存页类型,这种页面类型一般用于在进程用户空间中分配,因为在用户空间中虚拟内存与物理内存都是通过页表来动态映射的,物理页移动之后,只需要改变页表中的映射关系即可,而虚拟内存地址并不需要改变。一切对进程来说都是透明的。
MIGRATE_RECLAIMABLE 表示不能移动,但是可以直接回收的页面类型,比如前面提到的文件缓存页,它们就可以直接被回收掉,当再次需要的时候可以从磁盘中继续读取生成。或者一些生命周期比较短的内存页,比如 DMA 缓存区中的内存页也是可以被直接回收掉。
MIGRATE_PCPTYPES 则表示 CPU 高速缓存中的页面类型,PCP 是 per_cpu_pageset 的缩写,每个 CPU 对应一个 per_cpu_pageset 结构,里面包含了高速缓存中的冷页和热页。这部分的详细内容感兴趣的可以回看下笔者的这篇文章 《深入理解 Linux 物理内存管理》中的 “ 5.7 物理内存区域中的冷热页 ” 小节。
MIGRATE_CMA 表示属于 CMA 区域中的内存页类型,CMA 的全称是 contiguous memory allocator,顾名思义它是一个分配连续物理内存页面的分配器用于分配连续的物理内存。
大家可能好奇了,我们这节讲到的伙伴系统分配的不也是连续的物理内存吗?为什么又会多出个 CMA 呢?
原因还是前边我们多次提到的内存碎片对内存分配的巨大影响,随着系统的长时间运行,不可避免的会产生内存碎片,这些内存碎片会导致在内存充足的情况下却依然找不到一片足够大的连续物理内存,伙伴系统在这种情况下就会失败,而连续的物理内存分配对于内核来说又是刚需,比如:一些 DMA 设备只能访问连续的物理内存,内核对于大页的支持也需要连续的物理内存。
所以为了解决这个问题,内核会在系统刚刚启动的时候,这时内存还很充足,先预留一部分连续的物理内存,这部分物理内存就是 CMA 区域,这部分内存可以被进程正常的使用,当有连续内存分配需求时,内核会通过页面回收或者迁移的方式将这部分内存腾出来给 CMA 分配。
CMA 的初始化是在伙伴系统初始化之前就已经完成的
MIGRATE_ISOLATE 则是一个虚拟区域,用于跨越 NUMA 节点移动物理内存页,内核可以将物理内存页移动到使用该页最频繁的 CPU 所在的 NUMA 节点中。
在介绍完这些物理页面的迁移类型 MIGRATE_TYPES 之后,大家可能不禁有疑问,内核为啥会设定这么多的页面迁移类型呢 ?
答案还是为了解决前面我们反复提到的内存碎片问题,当系统长时间运行之后,随着不同尺寸内存的分配和释放,就会引起内存碎片,这些碎片会导致内核在明明还有足够内存的前提下,仍然无法找到一块足够大的连续内存分配。如下图所示:
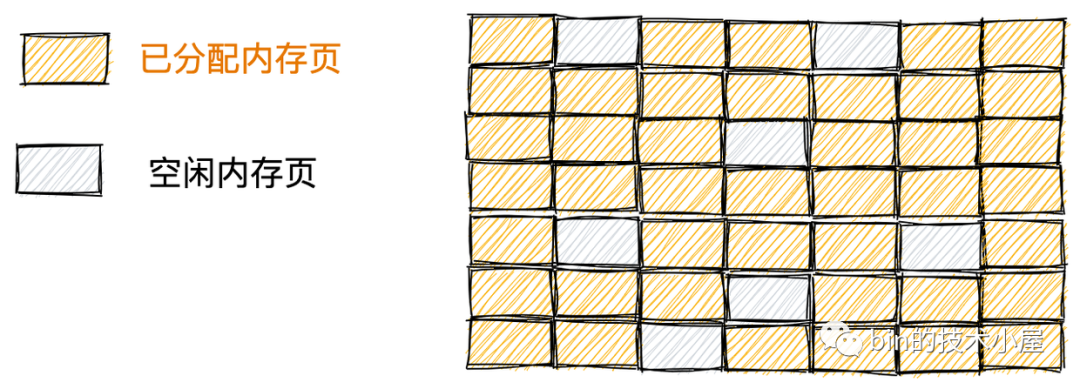
上图中显示的这 7 个空闲的内存页以碎片的形式存在于内存中,这就导致明明还有 7 个空闲的内存页,但是最大的连续内存区域只有 1 个内存页,当内核想要申请 2 个连续的内存页时就会导致失败。
很长时间以来,物理内存碎片一直是 Linux 操作系统的弱点,所以内核在 2.6.24 版本中引入了以下方式来避免内存碎片。
如果这些内存页是可以迁移的,内核就会将空闲的内存页迁移至一起,已分配的内存页迁移至一起,形成了一整块足够大的连续内存区域。

如果这些内存页是可以回收的,内核也可以通过回收页面的方式,整理出一块足够大的空闲连续内存区域。
在我们清楚了以上介绍的基础知识之后,再回过头来看伙伴系统的这些核心数据结构,是不是就变得容易理解了~~
struct zone {
// 被伙伴系统所管理的物理页数
atomic_long_t managed_pages;
// 伙伴系统的核心数据结构
struct free_area free_area[MAX_ORDER];
}
struct free_area {
struct list_head free_list[MIGRATE_TYPES];
unsigned long nr_free;
};
首先伙伴系统会将物理内存区域 zone 中的空闲内存页按照分配阶 order 将相同尺寸的内存块组织在 free_area[MAX_ORDER] 数组中:
随后在 struct free_area 结构中伙伴系统近一步根据这些相同尺寸内存块的页面迁移类型 MIGRATE_TYPES,将相同迁移类型的物理页面组织在 free_list[MIGRATE_TYPES] 数组中,最终形成了完整的伙伴系统结构:
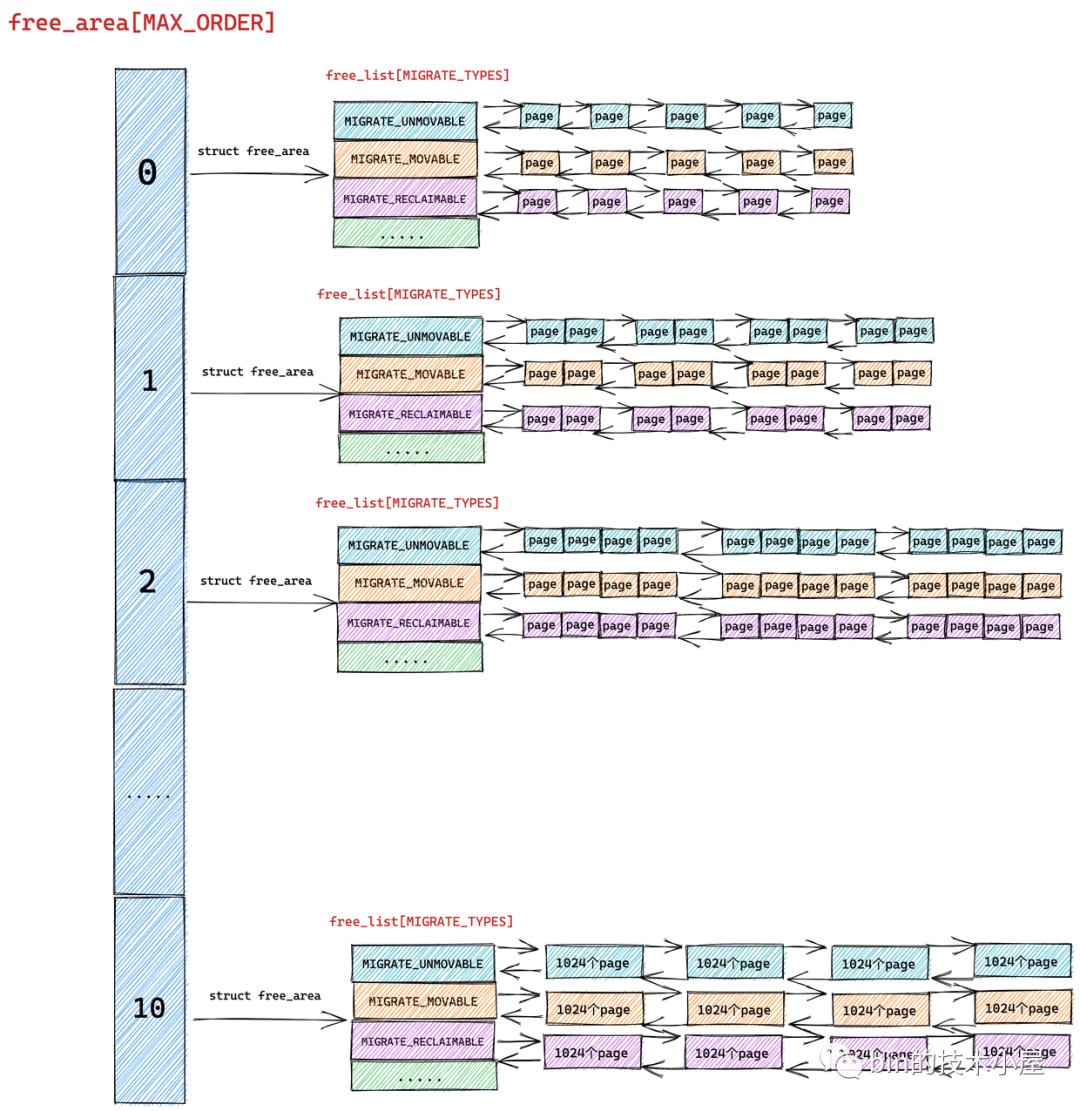
我们可以通过 cat /proc/pagetypeinfo 命令可以查看当前各个内存区域中的伙伴系统中不同页面迁移类型以及不同 order 尺寸的内存块个数。
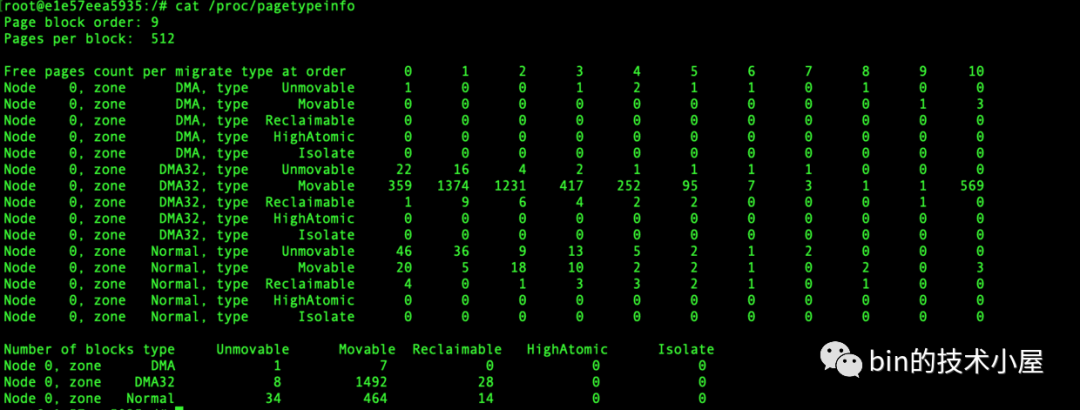
page block order 表示系统中支持的巨型页对应的分配阶,pages per block 表示巨型页中包含的 pages 个数。
好了,现在我们已经清楚了伙伴系统的数据结构全貌,接下来笔者会在这个基础上继续为大家介绍伙伴系统的核心工作原理~~
2. 到底什么是伙伴
我们前面一直在谈伙伴系统,那么伙伴这个概念到底在内核中是什么意思呢?其实下面这张伙伴系统的结构图已经把伙伴的概念很清晰的表达出来了。
伙伴在我们日常生活中含义就是形影不离的好朋友,在内核中也是如此,内核中的伙伴指的是大小相同并且在物理内存上是连续的两个或者多个 page。
比如在上图中,free_area[1] 中组织的是分配阶 order = 1 的内存块,内存块中包含了两个连续的空闲 page。这两个空闲 page 就是伙伴。
free_area[10] 中组织的是分配阶 order = 10 的内存块,内存块中包含了 1024 个连续的空闲 page。这 1024 个空闲 page 就是伙伴。

再比如上图中的 page0 和 page 1 是伙伴,page2 到 page 5 是伙伴,page6 和 page7 又是伙伴。但是 page0 和 page2 就不能成为伙伴,因为它们的物理内存是不连续的。同时 (page0 到 page3) 和 (page4 到 page7) 所组成的两个内存块又能构成一个伙伴。伙伴必须是大小相同并且在物理内存上是连续的两个或者多个 page。
3. 伙伴系统的内存分配原理
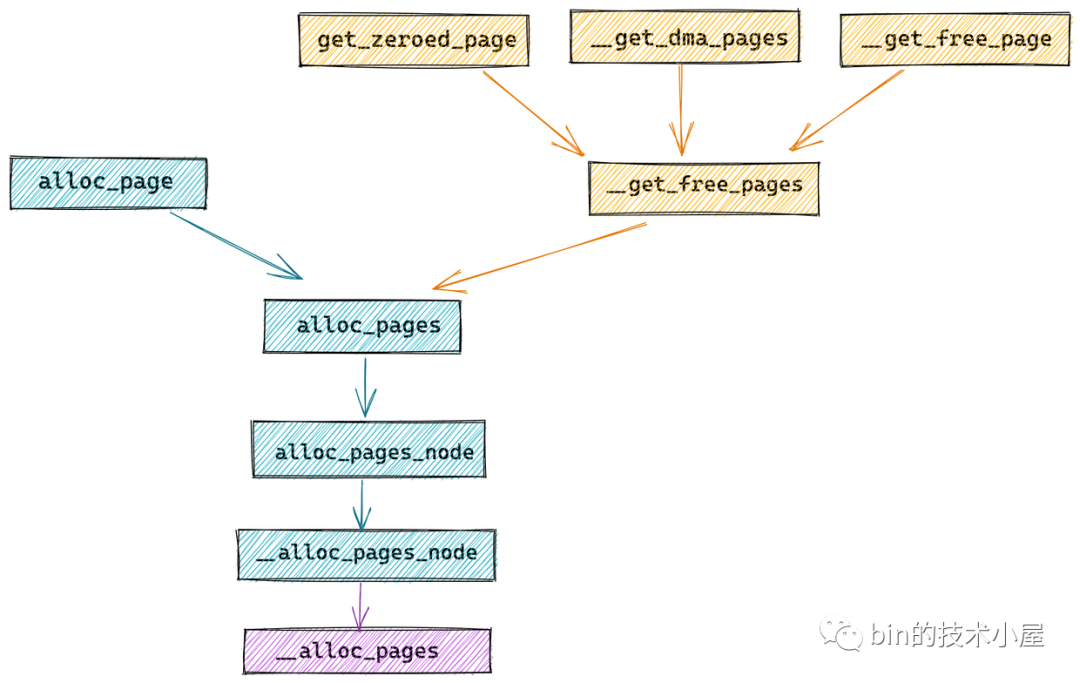
在 《深入理解 Linux 物理内存分配全链路实现》 一文中的第二小节 " 2. 物理内存分配内核源码实现 ",笔者介绍了如下四个内存分配的接口,内核可以通过这些接口向伙伴系统申请内存:
struct page *alloc_pages(gfp_t gfp, unsigned int order)
unsigned long __get_free_pages(gfp_t gfp_mask, unsigned int order)
unsigned long get_zeroed_page(gfp_t gfp_mask)
unsigned long __get_dma_pages(gfp_t gfp_mask, unsigned int order)
首先我们可以根据内存分配接口函数中的 gfp_t gfp_mask ,找到内存分配指定的 NUMA 节点和物理内存区域 zone ,然后找到物理内存区域 zone 对应的伙伴系统。
随后内核通过接口中指定的分配阶 order,可以定位到伙伴系统的 free_area[order] 数组,其中存放的就是分配阶为 order 的全部内存块。
最后内核进一步通过 gfp_t gfp_mask 掩码中指定的页面迁移类型 MIGRATE_TYPE,定位到 free_list[MIGRATE_TYPE],这里存放的就是符合内存分配要求的所有内存块。通过遍历这个双向链表就可以轻松获得要分配的内存。
比如我们向内核申请 ( 2 ^ (order - 1),2 ^ order ] 之间大小的内存,并且这块内存我们指定的迁移类型为 MIGRATE_MOVABLE 时,内核会按照 2 ^ order 个内存页进行申请。
随后内核会根据 order 找到伙伴系统中的 free_area[order] 对应的 free_area 结构,并进一步根据页面迁移类型定位到对应的 free_list[MIGRATE_MOVABLE],如果该迁移类型的 free_list 中没有空闲的内存块时,内核会进一步到上一级链表也就是 free_area[order + 1] 中寻找。
如果 free_area[order + 1] 中对应的 free_list[MIGRATE_MOVABLE] 链表中还是没有,则继续循环到更高一级 free_area[order + 2] 寻找,直到在 free_area[order + n] 中的 free_list[MIGRATE_MOVABLE] 链表中找到空闲的内存块。
但是此时我们在 free_area[order + n] 链表中找到的空闲内存块的尺寸是 2 ^ (order + n) 大小,而我们需要的是 2 ^ order 尺寸的内存块,于是内核会将这 2 ^ (order + n) 大小的内存块逐级减半**,将每一次**后的内存块插入到相应的 free_area 数组里对应的 free_list[MIGRATE_MOVABLE] 链表中,并将最后**出的 2 ^ order 尺寸的内存块分配给进程使用。
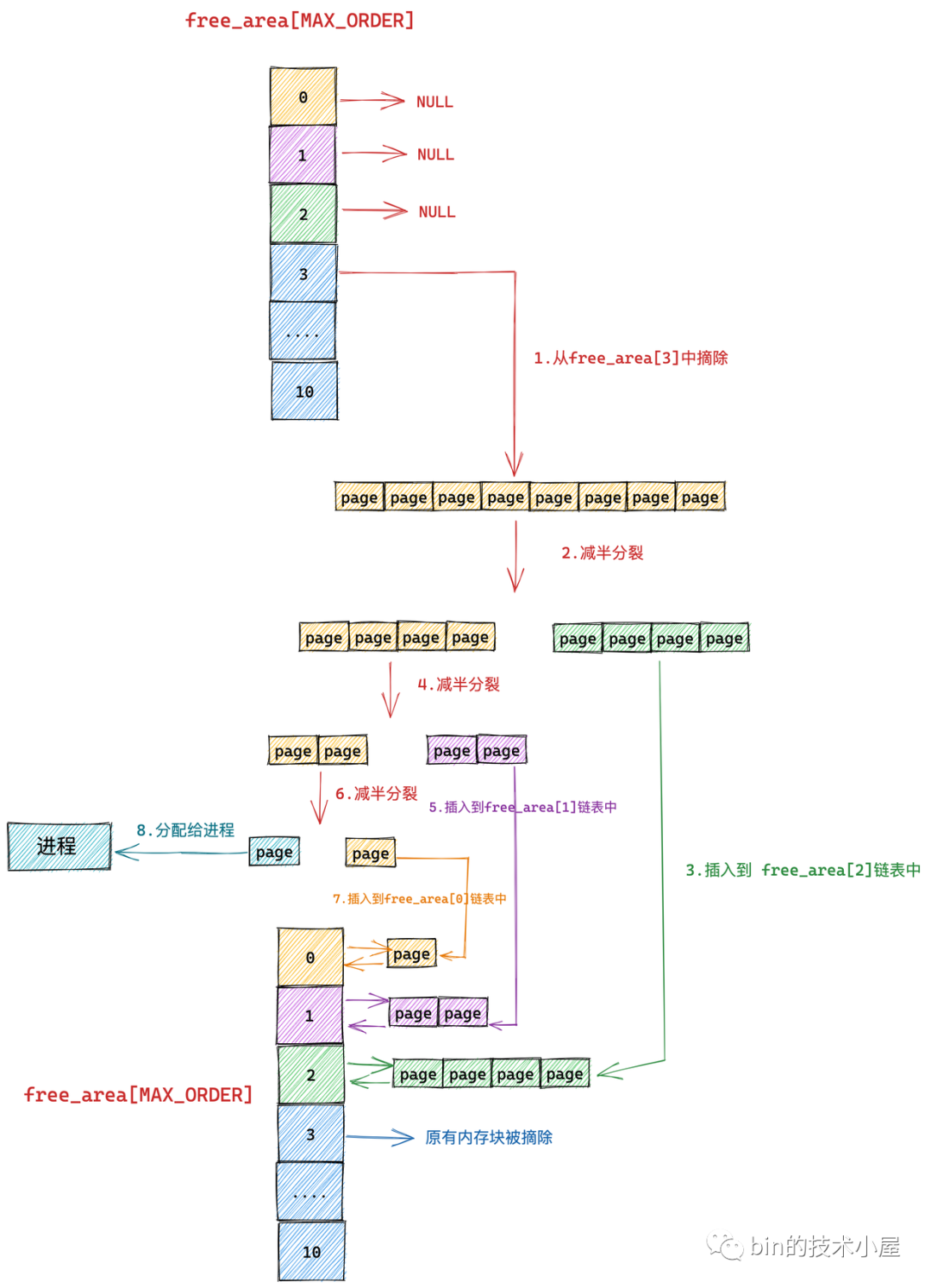
下面笔者举一个具体的例子来为大家说明伙伴系统的整个内存分配过程:
为了清晰地给大家展现伙伴系统的内存分配过程,我们暂时忽略 MIGRATE_TYPES 相关的组织结构
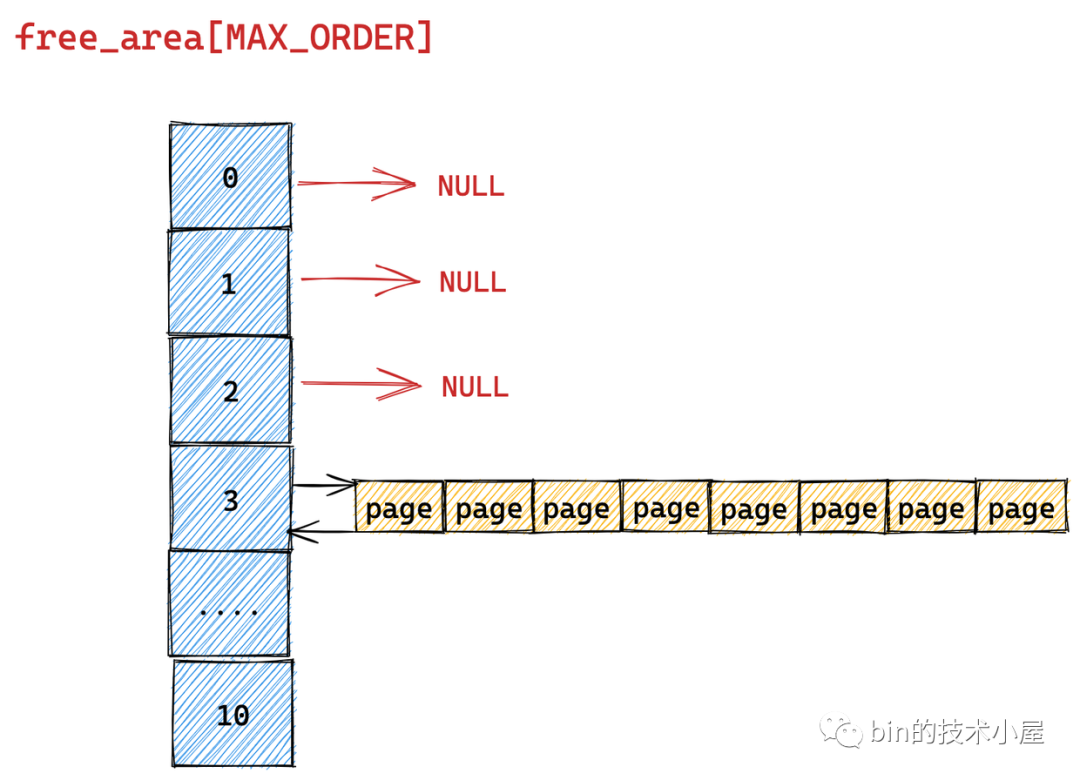
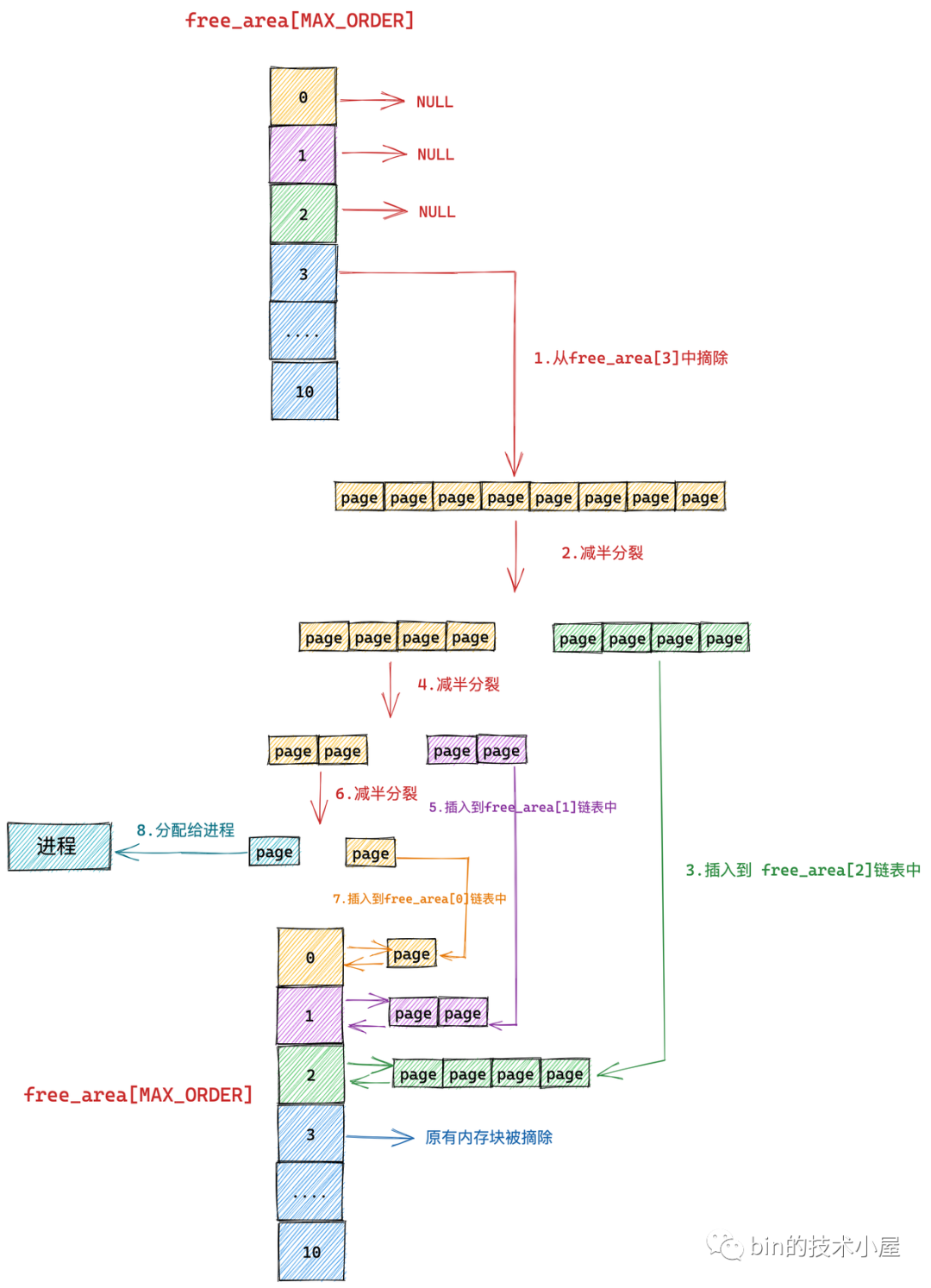
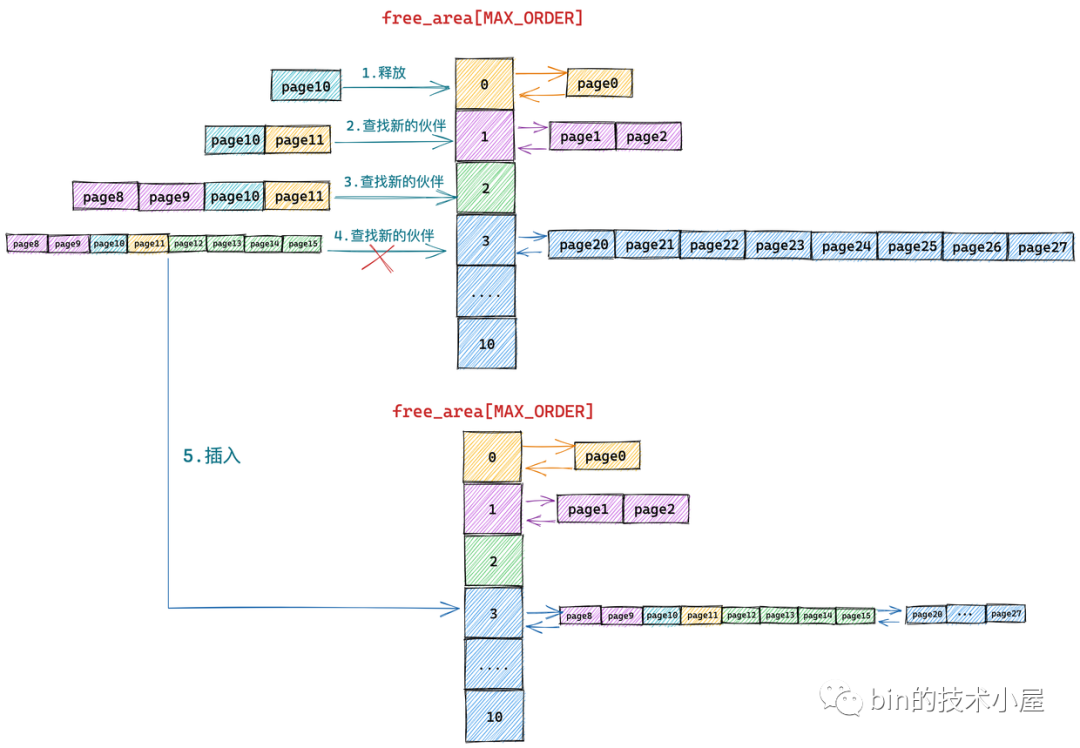
我们假设当前伙伴系统中只有 order = 3 的空闲链表 free_area[3],其余剩下的分配阶 order 对应的空闲链表中均是空的。 free_area[3] 中仅有一个空闲的内存块,其中包含了连续的 8 个 page。
现在我们向伙伴系统申请一个 page 大小的内存(对应的分配阶 order = 0),那么内核会在伙伴系统中首先查看 order = 0 对应的空闲链表 free_area[0] 中是否有空闲内存块可供分配。
随后内核会根据前边介绍的内存分配逻辑,继续升级到 free_area[1] , free_area[2] 链表中寻找空闲内存块,直到查找到 free_area[3] 发现有一个可供分配的内存块。这个内存块中包含了 8 个 连续的空闲 page,但是我们只要一个 page 就够了,那该怎么办呢?
于是内核先将 free_area[3] 中的这个空闲内存块从链表中摘下,然后减半**成两个内存块,**出来的这两个内存块分别包含 4 个 page(分配阶 order = 2)。
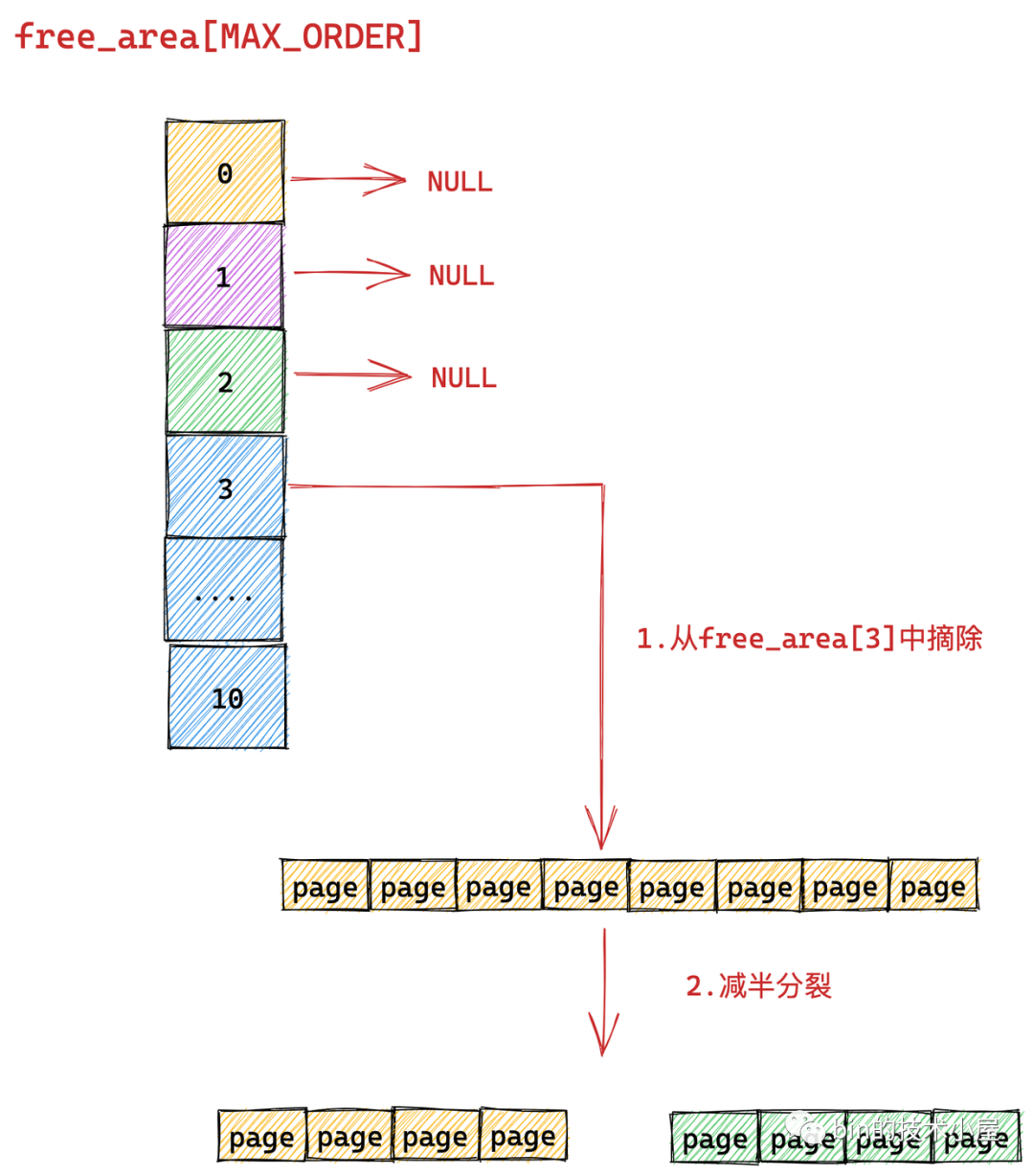
上图**出的两个内存块,**的代表原有内存块的前半部分,绿色代表原有内存块的后半部分。
随后内核会将**出的后半部分(图中绿色部分,order = 2),插入到 free_rea[2] 链表中。
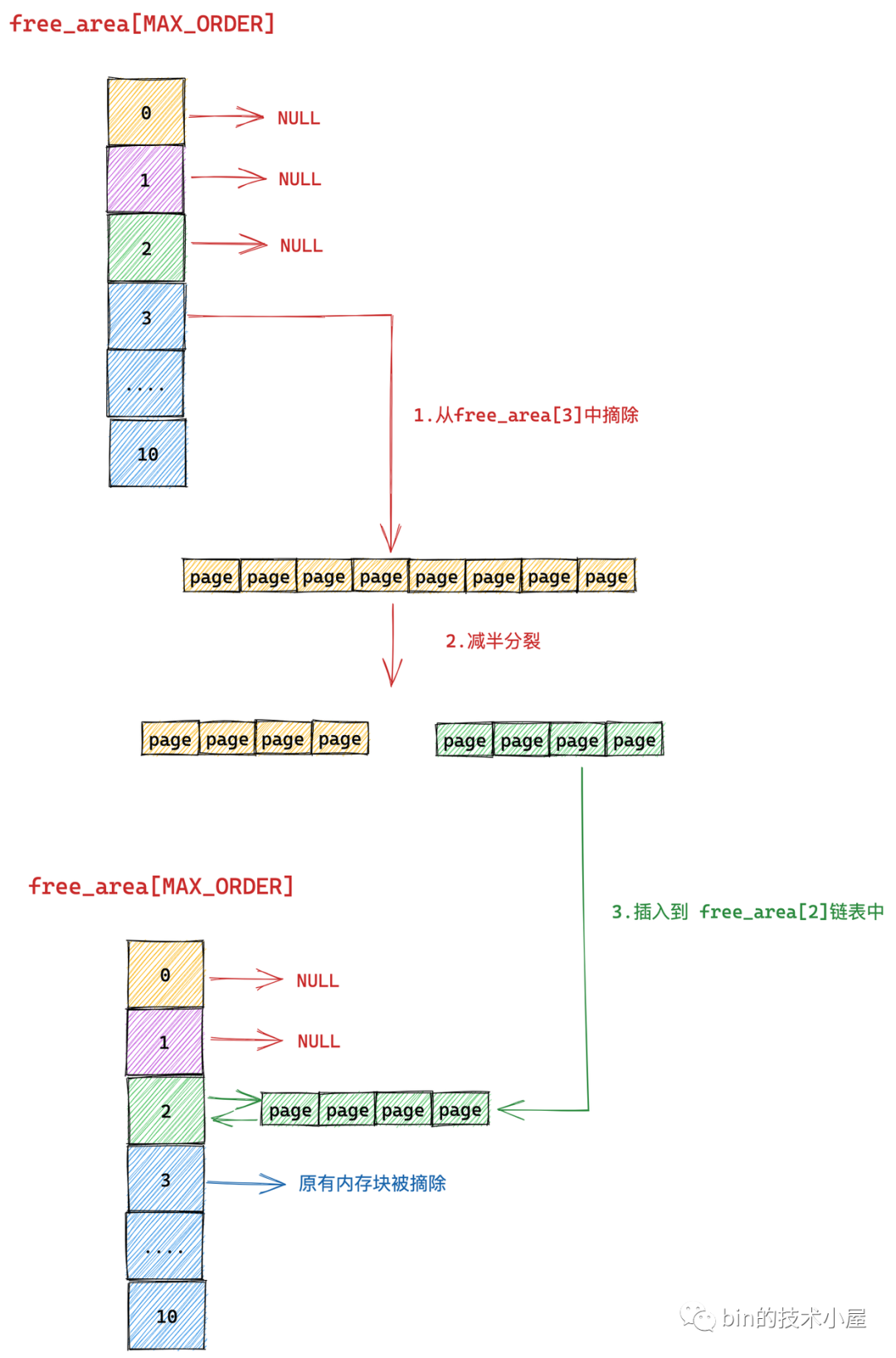
前半部分(图中**部分,order = 2)继续减半**,**出来的这两个内存块分别包含 2 个 page(分配阶 order = 1)。如下图中第 4 步所示,前半部分为**,后半部分为紫色。同理按照前边的**逻辑,内核会将后半部分内存块(紫色部分,分配阶 order = 1)插入到 free_area[1] 链表中。
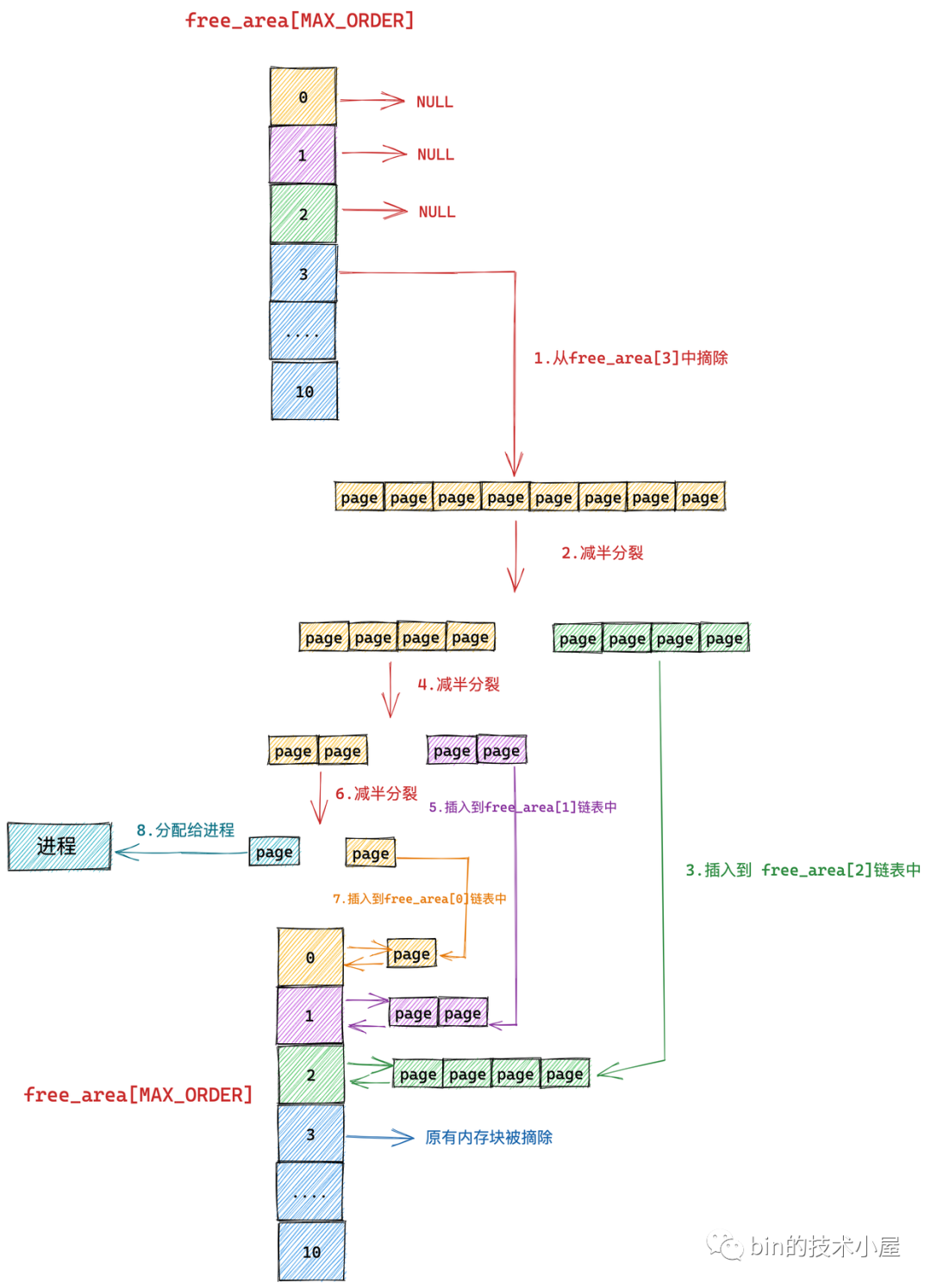
前半部分(图中**部分,order = 1)在上图中的第 6 步继续减半**,**出来的这两个内存块分别包含 1 个 page(分配阶 order = 0),前半部分为青色,后半部分为**。
后半部分插入到 frea_area[0] 链表中,前半部分返回给进程,这时内存分配成功,流程结束。
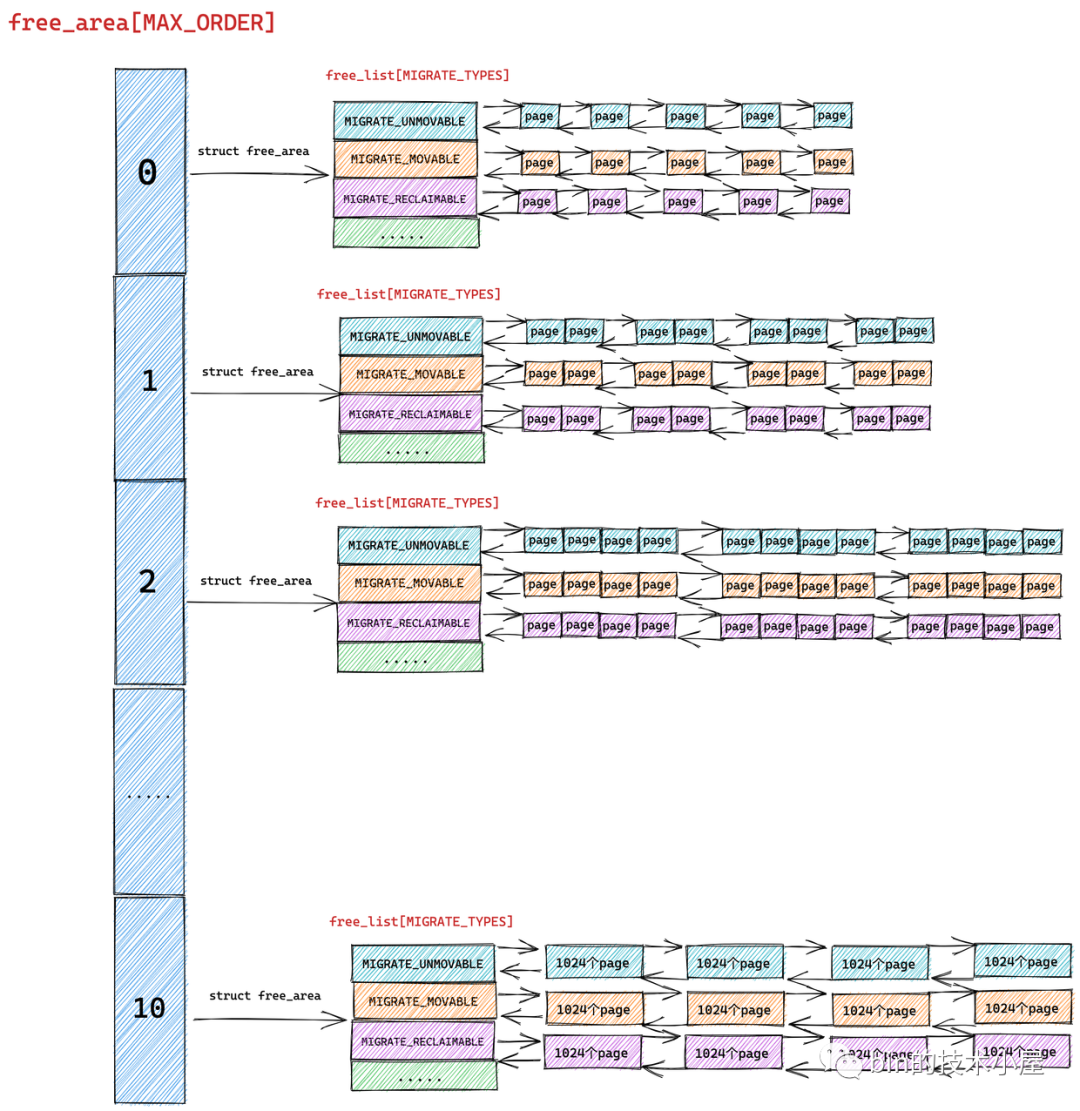
以上流程就是伙伴系统的核心内存分配过程,下面我们再把内存页面的迁移属性 MIGRATE_TYPES 考虑进来,来看一下完整的伙伴系统内存分配流程:
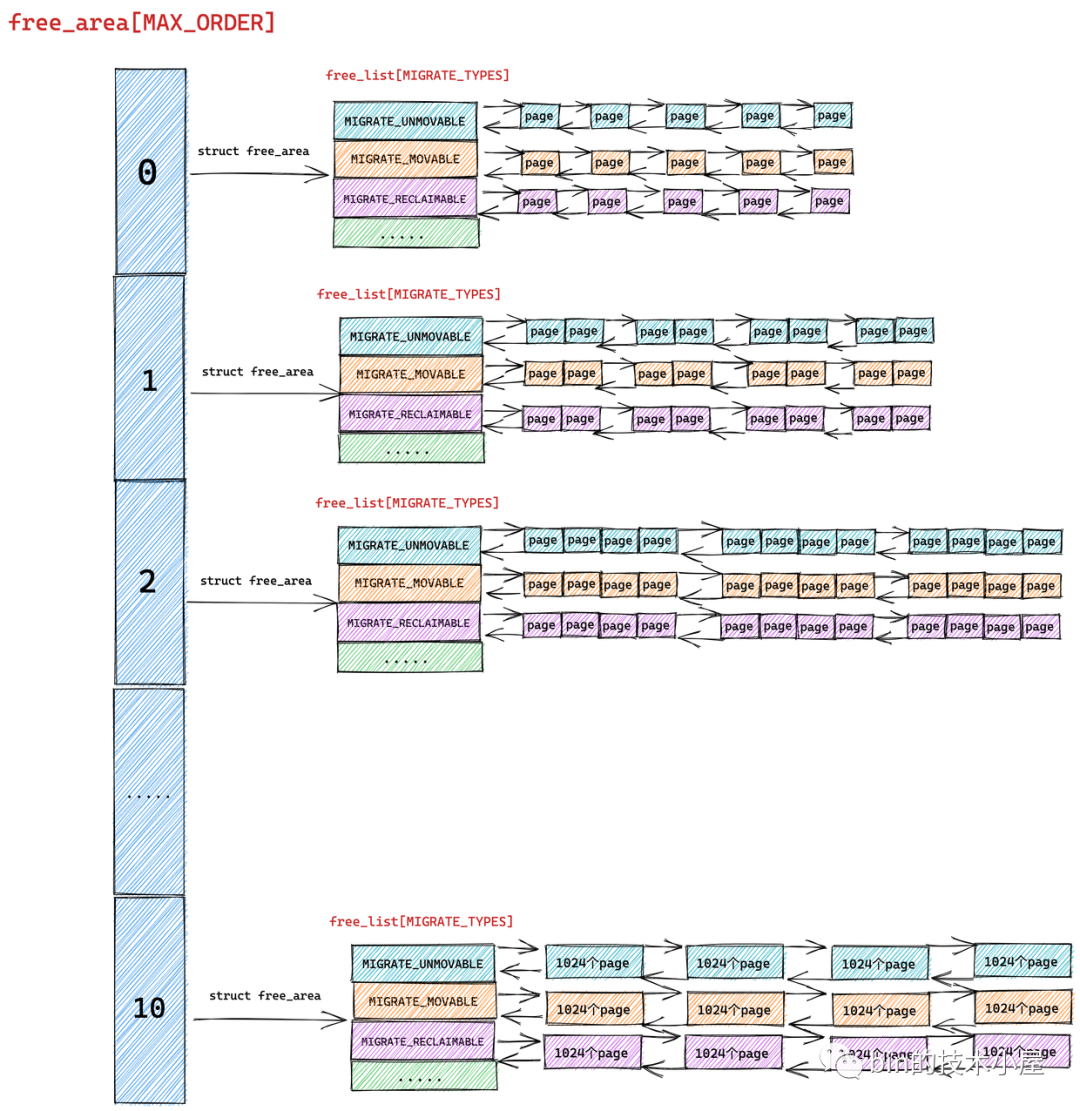
现在我们加上了内存 MIGRATE_TYPES 的组织结构,其实分配流程还是和核心流程一样的,只不过上面提到的那些高阶 order 的减半**情形都发生在各个 free_area[order] 中固定的 free_list[MIGRATE_TYPE] 里罢了。
比如我们要求分配的内存迁移属性要求是 MIGRATE_MOVABLE 类型,那么减半**流程分别发生在 free_area[2] ,free_area[1] ,free_area[0] 对应的 free_list[MIGRATE_MOVABLE] 中,多了一个 free_list 的维度,仅此而已。
不过笔者这里想重点着墨的地方是内存分配的一种异常情形,比如我们想要分配特定迁移类型的内存,但是当前伙伴系统所有 free_area[order] 里对应的 free_list[MIGRATE_TYPE] 均无法满足内存分配的需求(没有足够特定迁移类型的空闲内存块)。那么这种场景下内核会怎么处理呢?
其实同样的问题我们在 《深入理解 Linux 物理内存管理》 一文中也遇到过,当时笔者介绍内存 NUMA 架构的时候提到,如果当前 NUMA 节点无法满足内存分配时,内核会跨越 NUMA 节点从其他节点上分配内存。
typedef struct pglist_data {
// NUMA 节点中的物理内存区域个数
int nr_zones;
// NUMA 节点中的物理内存区域
struct zone node_zones[MAX_NR_ZONES];
// NUMA 节点的备用列表
struct zonelist node_zonelists[MAX_ZONELISTS];
} pg_data_t;
每个 NUMA 节点的 struct pglist_data 结构中都会包含一个 node_zonelists,其中包含了当前NUMA 节点以及备用 NUMA 节点的所有内存区域以及对应的伙伴系统,当前 NUMA 节点内存不足时,内核会从 node_zonelists 中的备用 NUMA 节点中分配内存。
这里也是同样的道理,当伙伴系统中指定的迁移列表 free_list[MIGRATE_TYPE] 无法满足内存分配需求时,内核根据不同迁移类型定义了不同的 fallback 规则:
/*
* This array describes the order lists are fallen back to when
* the free lists for the desirable migrate type are depleted
*
* The other migratetypes do not have fallbacks.
*/
static int fallbacks[MIGRATE_TYPES][3] = {
[MIGRATE_UNMOVABLE] = { MIGRATE_RECLAIMABLE, MIGRATE_MOVABLE, MIGRATE_TYPES },
[MIGRATE_MOVABLE] = { MIGRATE_RECLAIMABLE, MIGRATE_UNMOVABLE, MIGRATE_TYPES },
[MIGRATE_RECLAIMABLE] = { MIGRATE_UNMOVABLE, MIGRATE_MOVABLE, MIGRATE_TYPES },
};
比如:MIGRATE_UNMOVABLE 类型的 free_list 内存不足时,内核会 fallback 到 MIGRATE_RECLAIMABLE 中去获取,如果还是不足,则再次降级到 MIGRATE_MOVABLE 中获取,如果仍然无法满足内存分配,才会失败退出。
正常的分配流程先是从低阶到高阶依次查找空闲内存块,然后将高阶中的内存块依次减半**到低阶 free_list 链表中。
内存分配 fallback 流程则刚好是相反的,它是先从备用 fallback 类型的迁移列表中的最高阶开始查找,找到一块空闲内存块之后,先迁移到最初指定的 free_list[MIGRATE_TYPE] 链表中,然后在指定的 free_list[MIGRATE_TYPE] 链表执行减半**。
内核这里的 fallback 策略是:如果无法避免分配迁移类型不同的内存块,那么就分配一个尽可能大的内存块(从最高阶开始查找),避免向其他链表引入内存碎片。
笔者还是以上边的例子说明,当我们向伙伴系统申请 MIGRATE_UNMOVABLE 迁移类型的内存时,假设内核在伙伴系统中的 free_area[0] 到 free_area[10] 中的所有 free_list[MIGRATE_UNMOVABLE] 链表中均无法找到一个空闲的内存块。
那么就会 fallback 到 MIGRATE_RECLAIMABLE 类型,从最高阶 free_area[10] 中的 free_list[MIGRATE_RECLAIMABLE] 链表开始查找,如果找到一个空闲的内存块,则首先会迁移到对应的 order 的 free_list[MIGRATE_UNMOVABLE] 链表,然后流程继续回到核心流程,在各个 free_area[order] 对应的 free_list[MIGRATE_UNMOVABLE] 链表中执行减半**。
这里大家只需要理解一下 fallback 的大概流程,详细内容笔者会在后面介绍伙伴系统实现的章节详细解析~~~
4. 伙伴系统的内存回收原理
内存有分配就会有释放,本小节我们就来看下如何将内存块释放回伙伴系统中。在上个小节中笔者为大家介绍了伙伴系统内存分配的完整流程,核心就是从高阶 free_list 中寻找空闲内存块,然后依次减半**。
伙伴系统中的内存回收刚好和内存分配的过程相反,核心则是从低阶 free_list 中寻找释放内存块的伙伴,如果没有伙伴则将要释放的内存块插入到对应分配阶 order 的 free_list中。如果存在伙伴,则将释放内存块与它的伙伴合并,作为一个新的内存块继续到更高阶的 free_list 中循环重复上述过程,直到不能合并为止。
伙伴的概念我们已经在本文 《 2. 到底什么是伙伴 》小节中介绍过了,核心就是两个伙伴内存块必须是大小相同并且在物理内存上是连续的。
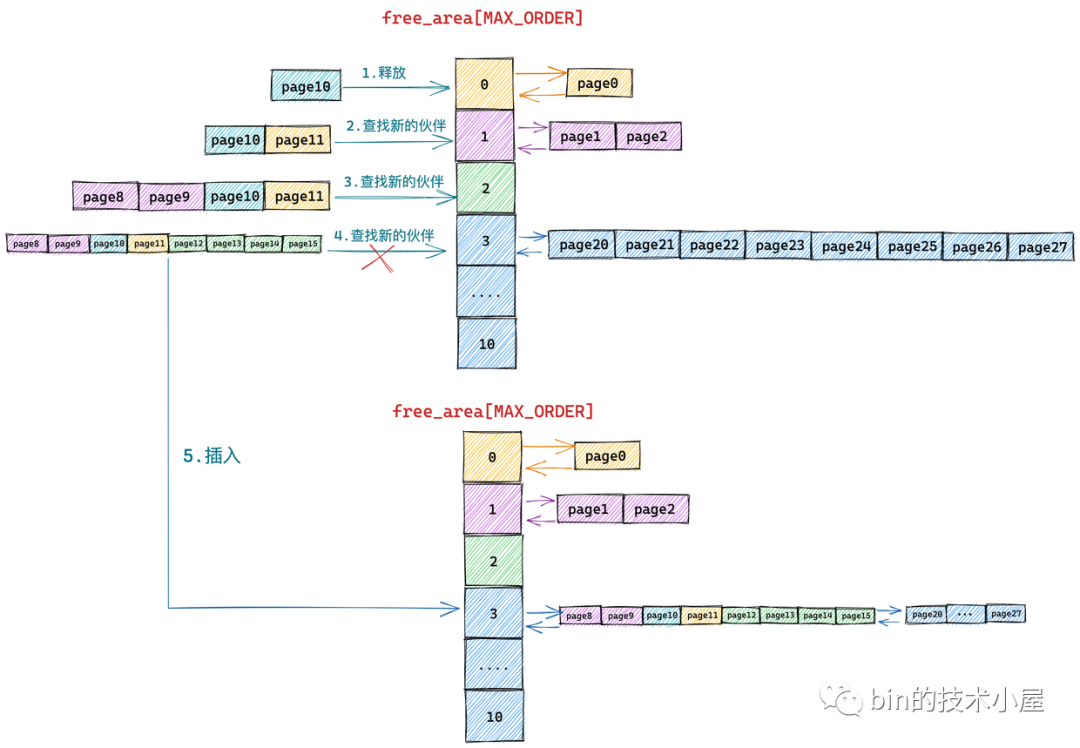
下面笔者还是举一个具体的例子来为大家展现伙伴系统内存回收的过程:
为了清晰地给大家展现伙伴系统的内存回收过程,我们暂时忽略 MIGRATE_TYPES 相关的组织结构
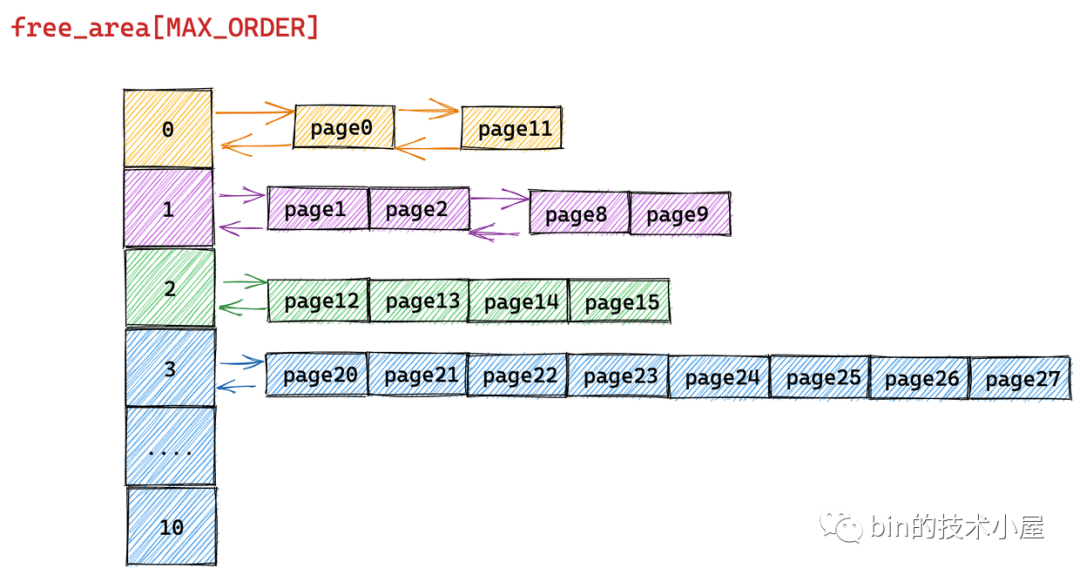
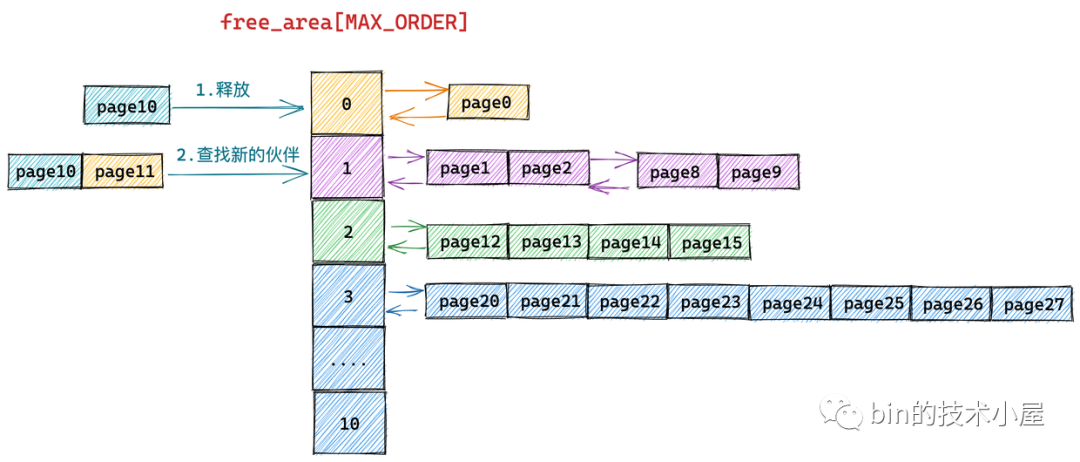
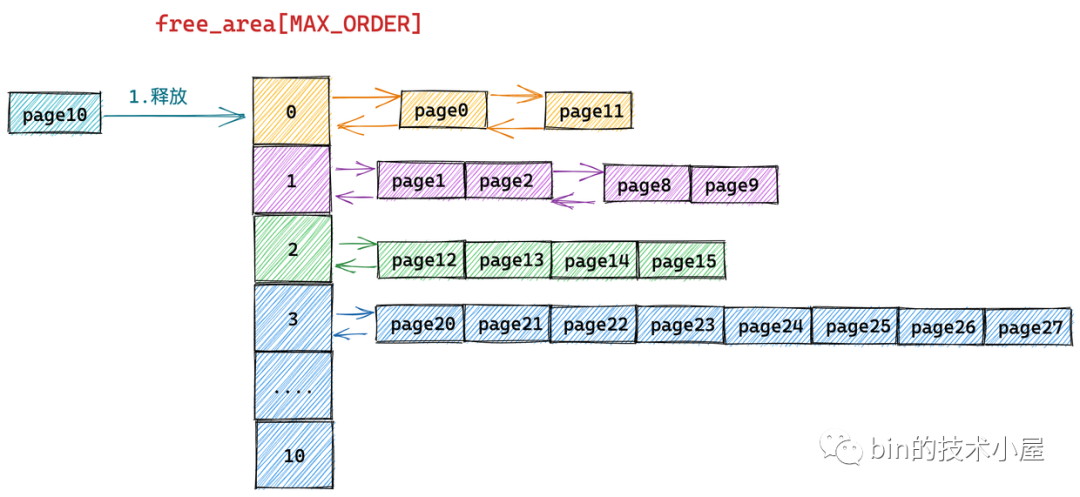
假设当前伙伴系统的状态如上图所示,现在我们需要向伙伴系统释放一个内存页(order = 0),编号为10。
这里笔者先来解释下上图伙伴系统中所管理的物理内存页后边编号的含义:我们知道伙伴系统中所管理的全部是连续的物理内存,既然是连续的,那么每个内存页 page 都会有一个固定的偏移(类似数组中的下标)。
这一点我们在前边的文章 《深入理解 Linux 物理内存管理》的 “ 4.2 NUMA 节点描述符 pglist_data 结构 ” 小节中已经介绍过了,在每个 NUMA 节点中,内核通过一个 node_mem_map 数组来组织节点内的物理内存页 page。
typedef struct pglist_data {
// NUMA 节点id
int node_id;
// 指向 NUMA 节点内管理所有物理页 page 的数组
struct page *node_mem_map;
}
上图伙伴系统中所管理的内存页 page 只是被伙伴系统组织之后的视图,下面是物理内存页在物理内存上的真实视图(包含要被释放的内存页 10):

有了这些基本概念之后,我回过头来在看 page10 释放回伙伴系统的整个过程:
下面的流程需要大家时刻对比内存页在物理内存上的真实视图,不要被伙伴系统的组织视图所干扰。
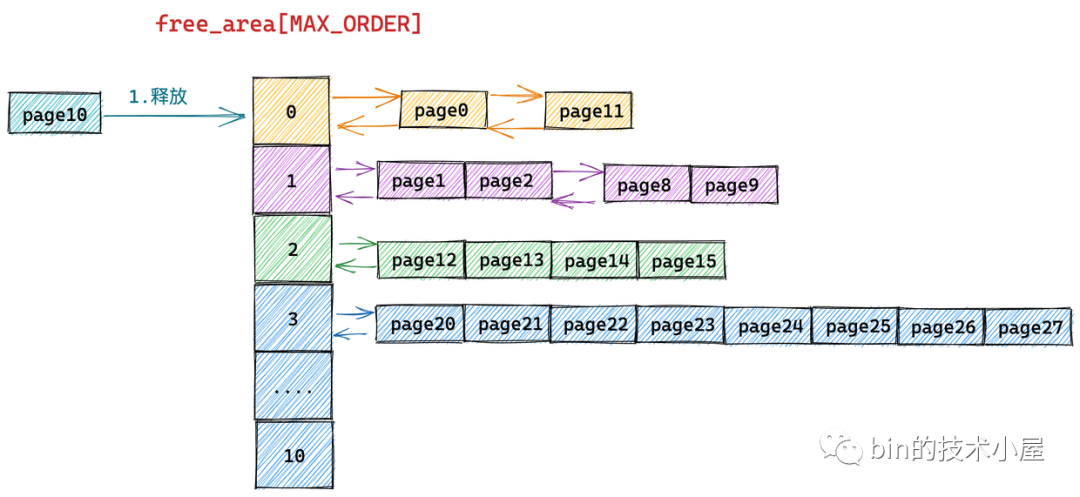
由于我们要释放的内存块只包含了一个物理内存页 page10,所以它的分配阶 order = 0,首先内核需要在伙伴系统 free_area[0] 中查找与 page10 大小相等并且连续的内存块(伙伴)。
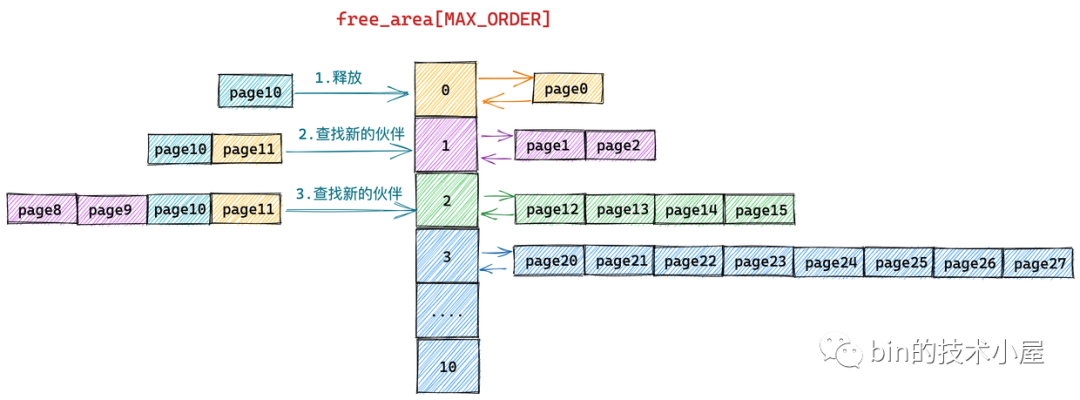
从物理内存的真实视图中我们可以看到 page11 是 page10 的伙伴,于是将 page11 从 free_area[0] 上摘下并与 page10 合并组成一个新的内存块(分配阶 order = 1)。随后内核会在 free_area[1] 中查找新内存块的伙伴:
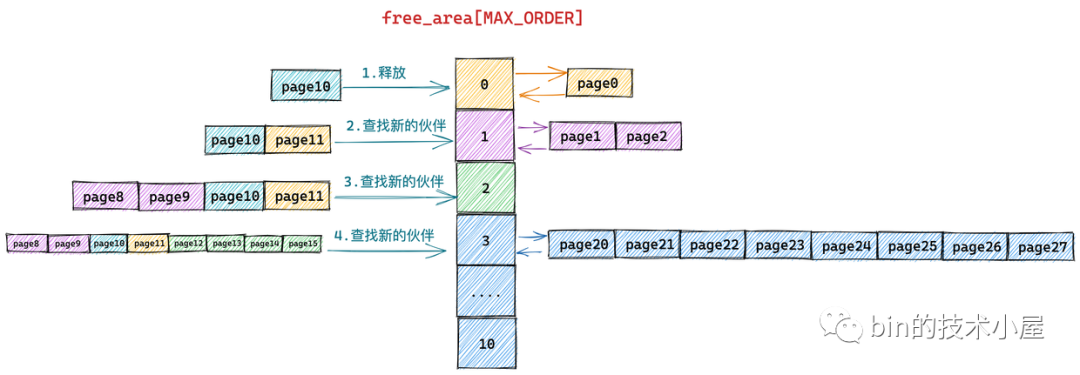
我们继续对比物理内存页的真实视图,发现在 free_area[1] 中 page8 和 page9 组成的内存块与 page10 和 page11 组成的内存块是伙伴,于是继续将这两个内存块(分配阶 order = 1)继续合并成一个新的内存块(分配阶 order = 2)。随后内核会在 free_area[2] 中查找新内存块的伙伴:
继续对比物理内存页的真实视图,发现在 free_area[2] 中 page12,page13,page14,page15 组成的内存块与 page8,page9,page10,page11 组成的新内存块是伙伴,于是将它们从 free_area[2] 上摘下继续合并成一个新的内存块(分配阶 order = 3),随后内核会在 free_area[3] 中查找新内存块的伙伴:
对比物理内存页的真实视图,我们发现在 free_area[3] 中的内存块(page20 到 page 27)与新合并的内存块(page8 到 page15)虽然大小相同但是物理上并不连续,所以它们不是伙伴,不能在继续向上合并了。于是内核将 page8 到 pag15 组成的内存块(分配阶 order = 3)插入到 free_area[3] 中,至此内存释放过程结束。
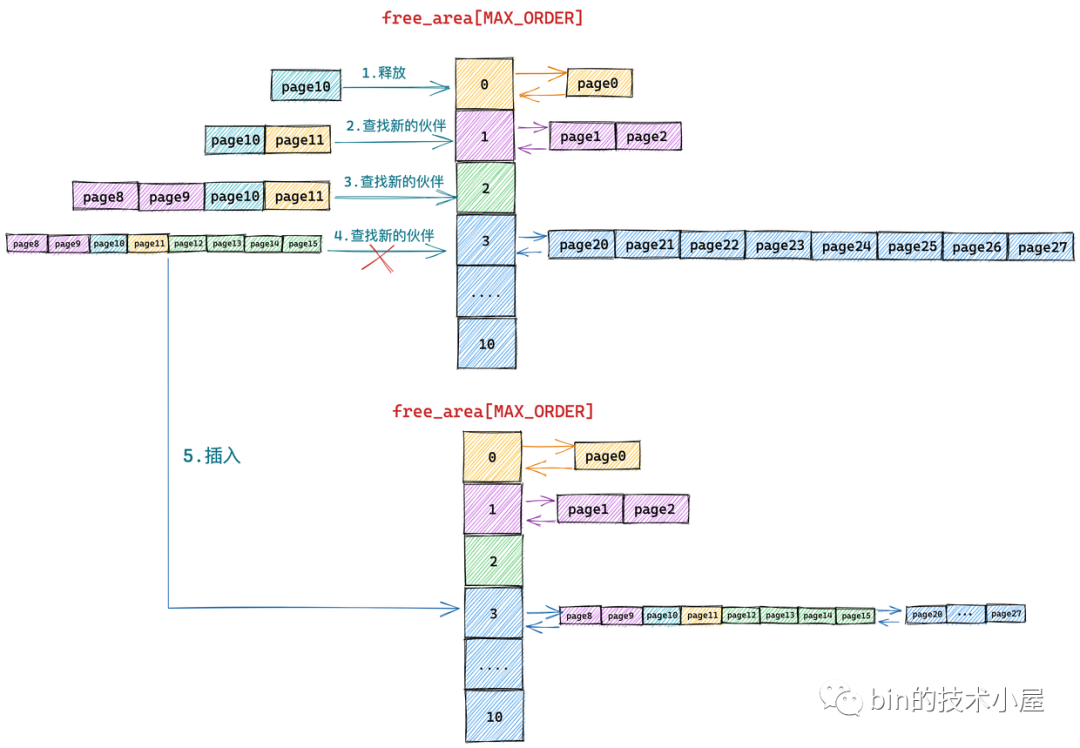
到这里关于伙伴系统内存分配以及回收的核心原理笔者就为大家全部介绍完了,内存分配和释放的过程刚好是相反的过程。
内存分配是从高阶先查找到空闲内存块,然后依次减半**,将**后的内存块插入到低阶的 free_list 中,将最后**出来的内存块分配给进程。
内存释放是先从低阶开始查找释放内存块的伙伴,如果找到,则两两合并成一个新的内存块,随后继续到高阶中去查找新内存块的伙伴,直到没有伙伴可以合并。
一个是高阶到低阶**,一个是低阶到高阶合并。
5. 进入伙伴系统的前奏
现在我们已经清楚了伙伴系统的所有核心原理,但是干讲原理总觉得 talk is cheap,还是需要 show 一下 code,所以接下来笔者会带大家看一下内核中伙伴系统的实现源码,真刀真枪的来一下。
但真正进入伙伴系统之前,内核还是做了很多铺垫工作,为了给大家解释清楚这些内容,我们还是需要重新回到上篇文章 《深入理解 Linux 物理内存分配全链路实现》 “5. __alloc_pages 内存分配流程总览” 小节中留下的尾巴,正式来介绍下 get_page_from_freelist 函数。
在上篇文章 “3. 物理内存分配内核源码实现” 小节中,笔者为大家介绍了 Linux 物理内存分配的完整流程,我们知道物理内存分配总体上分为两个路径,内核首先尝试的是在快速路径下分配内存,如果不行的话,内核会走慢速路径分配内存。
无论是快速路径还是慢速路径下的内存分配都需要最终调用 get_page_from_freelist 函数进行最终的内存分配。只不过,不同路径下 get_page_from_freelist 函数的内存分配策略以及需要考虑的内存水位线会有所不同,其中慢速路径下的内存分配策略会更加激进一些,这一点我们在上篇文章的相关章节内容介绍中体会很深。
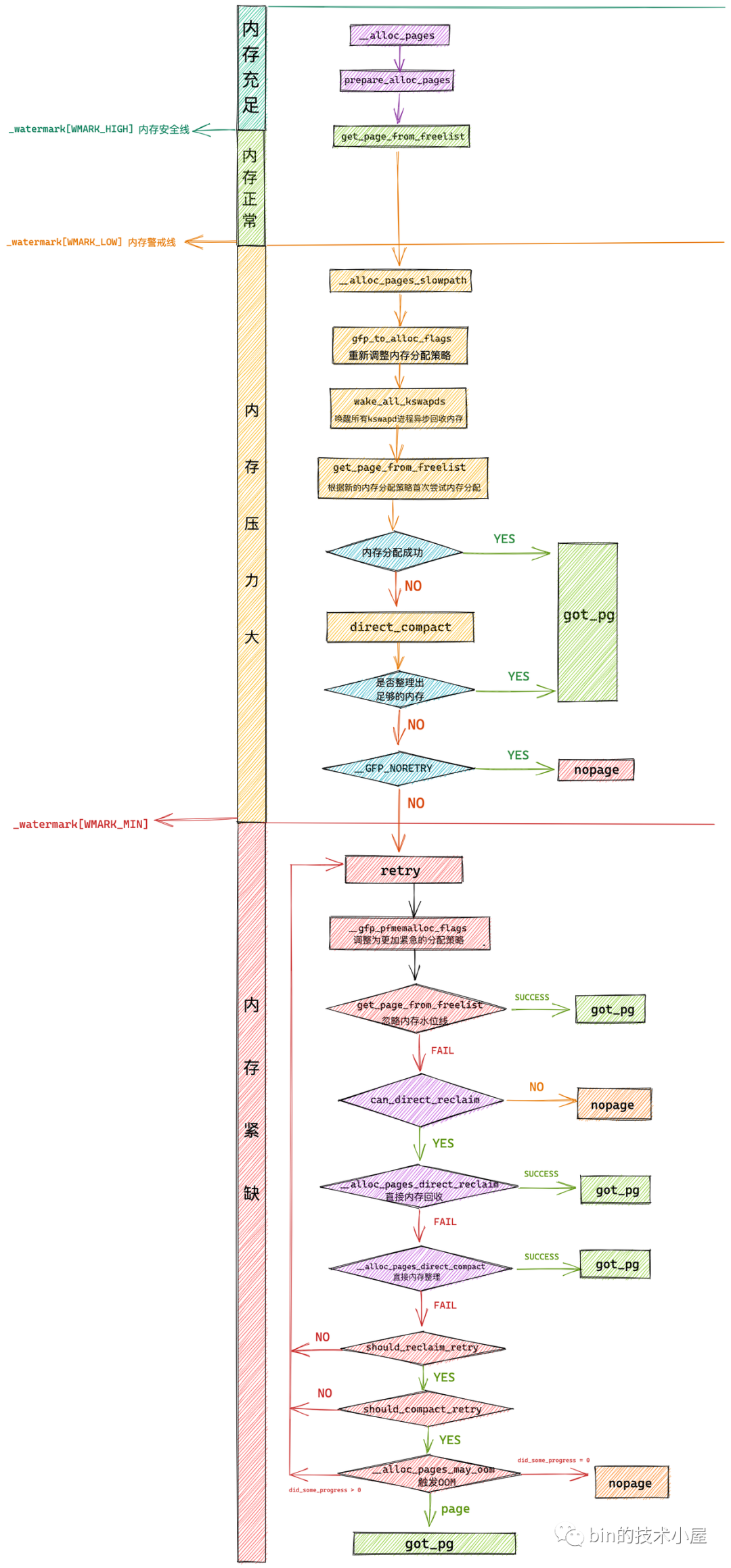
在每次调用 get_page_from_freelist 函数之前,内核都会根据新的内存分配策略来重新初始化 struct alloc_context 结构,alloc_context 结构体中包含了内存分配所需要的所有核心参数。详细初始化过程可以回看上篇文章的 “3.3 prepare_alloc_pages” 小节的内容。
struct alloc_context {
// 运行进程 CPU 所在 NUMA 节点以及其所有备用 NUMA 节点中允许内存分配的内存区域
struct zonelist *zonelist;
// NUMA 节点状态掩码
nodemask_t *nodemask;
// 内存分配优先级最高的内存区域 zone
struct zoneref *preferred_zoneref;
// 物理内存页的迁移类型分为:不可迁移,可回收,可迁移类型,防止内存碎片
int migratetype;
// 内存分配最高优先级的内存区域 zone
enum zone_type highest_zoneidx;
// 是否允许当前 NUMA 节点中的脏页均衡扩散迁移至其他 NUMA 节点
bool spread_dirty_pages;
};
这里最核心的两个参数就是 zonelist 和 preferred_zoneref。preferred_zoneref 表示当前本地 NUMA 节点(优先级最高),其中 zonelist 我们在 《深入理解 Linux 物理内存管理》的 “ 4.3 NUMA 节点物理内存区域的划分 ” 小节中详细介绍过,zonelist 里面包含了当前 NUMA 节点在内的所有备用 NUMA 节点的所有物理内存区域,用于当前 NUMA 节点没有足够空闲内存的情况下进行跨 NUMA 节点分配。
typedef struct pglist_data {
// NUMA 节点中的物理内存区域个数
int nr_zones;
// NUMA 节点中的物理内存区域
struct zone node_zones[MAX_NR_ZONES];
// NUMA 节点的备用列表
struct zonelist node_zonelists[MAX_ZONELISTS];
} pg_data_t;
struct pglist_data 里的 node_zonelists 是一个全集,而 struct alloc_context 里的 zonelist 是在内存分配过程中,根据指定的内存分配策略从全集 node_zonelists 过滤出来的一个子集(允许进行本次内存分配的所有 NUMA 节点及其内存区域)。
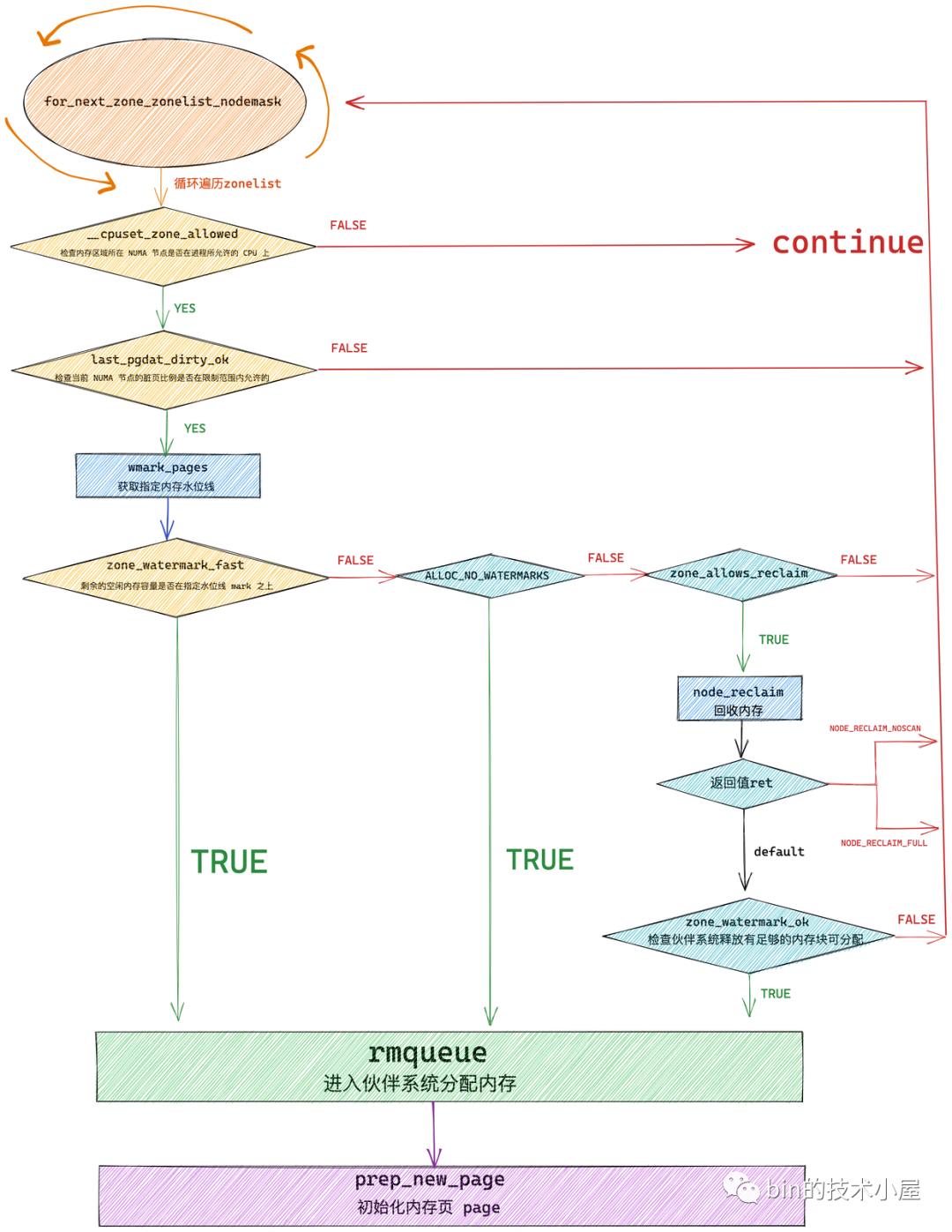
get_page_from_freelist 的核心逻辑其实很简单,就是遍历 struct alloc_context 里的 zonelist,挨个检查各个 NUMA 节点中的物理内存区域是否有足够的空闲内存可以满足本次的内存分配要求,如果可以满足则进入该物理内存区域的伙伴系统中完整真正的内存分配动作。
下面我们先来看一下 get_page_from_freelist 函数的完整逻辑:
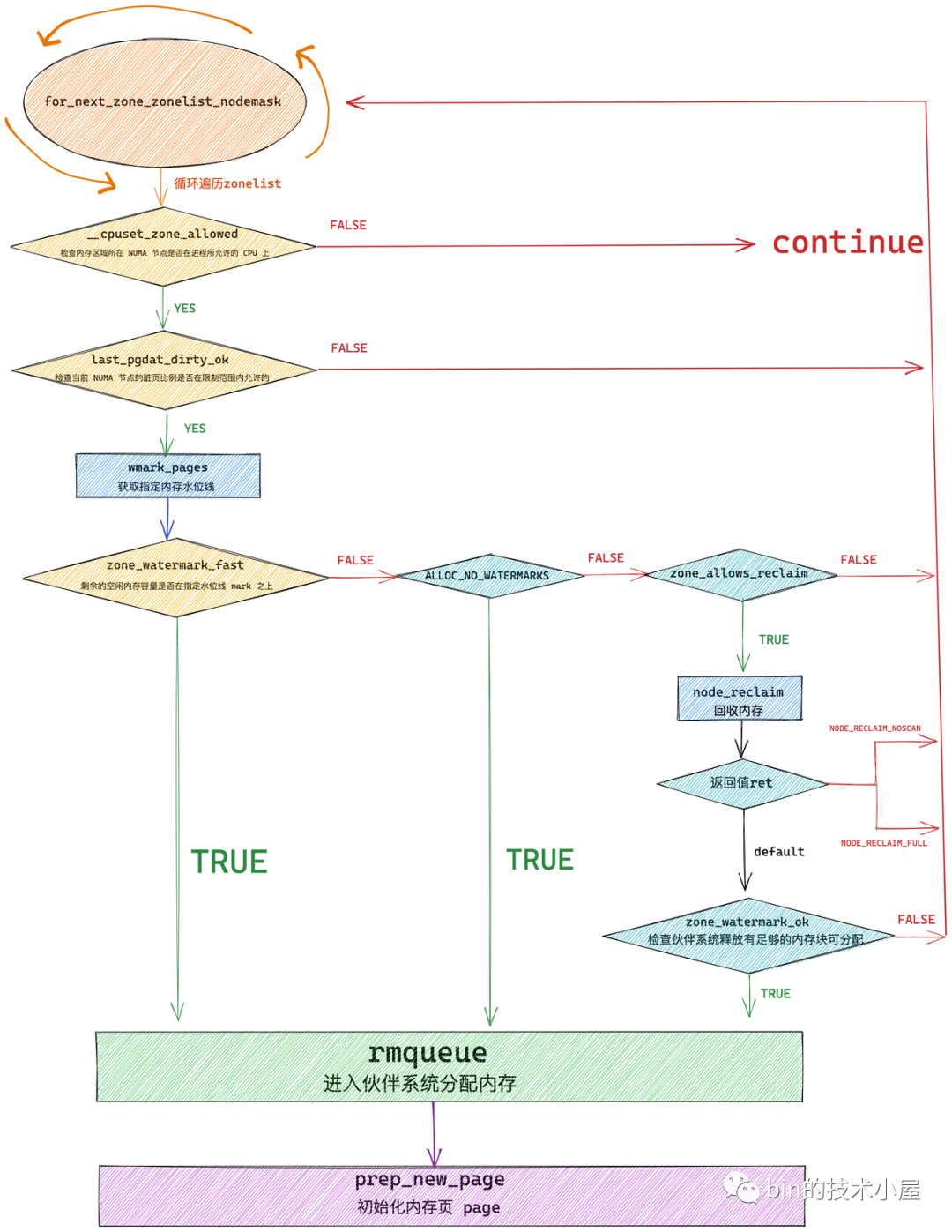
/*
* get_page_from_freelist goes through the zonelist trying to allocate
* a page.
*/
static struct page *
get_page_from_freelist(gfp_t gfp_mask, unsigned int order, int alloc_flags,
const struct alloc_context *ac)
{
struct zoneref *z;
// 当前遍历到的内存区域 zone 引用
struct zone *zone;
// 最近遍历的NUMA节点
struct pglist_data *last_pgdat = NULL;
// 最近遍历的NUMA节点中包含的脏页数量是否在内核限制范围内
bool last_pgdat_dirty_ok = false;
// 如果需要避免内存碎片,则 no_fallback = true
bool no_fallback;
retry:
// 是否需要避免内存碎片
no_fallback = alloc_flags & ALLOC_NOFRAGMENT;
z = ac->preferred_zoneref;
// 开始遍历 zonelist,查找可以满足本次内存分配的物理内存区域 zone
for_next_zone_zonelist_nodemask(zone, z, ac->highest_zoneidx,
ac->nodemask) {
// 指向分配成功之后的内存
struct page *page;
// 内存分配过程中设定的水位线
unsigned long mark;
// 检查内存区域所在 NUMA 节点是否在进程所允许的 CPU 上
if (cpusets_enabled() &&
(alloc_flags & ALLOC_CPUSET) &&
!__cpuset_zone_allowed(zone, gfp_mask))
continue;
// 每个 NUMA 节点中包含的脏页数量都有一定的限制。
// 如果本次内存分配是为 page cache 分配的 page,用于写入数据(不久就会变成脏页)
// 这里需要检查当前 NUMA 节点的脏页比例是否在限制范围内允许的
// 如果没有超过脏页限制则可以进行分配,如果已经超过 last_pgdat_dirty_ok = false
if (ac->spread_dirty_pages) {
if (last_pgdat != zone->zone_pgdat) {
last_pgdat = zone->zone_pgdat;
last_pgdat_dirty_ok = node_dirty_ok(zone->zone_pgdat);
}
if (!last_pgdat_dirty_ok)
continue;
}
// 如果内核设置了避免内存碎片标识,在本地节点无法满足内存分配的情况下(因为需要避免内存碎片)
// 这轮循环会遍历 remote 节点(跨NUMA节点)
if (no_fallback && nr_online_nodes > 1 &&
zone != ac->preferred_zoneref->zone) {
int local_nid;
// 如果本地节点分配内存失败是因为避免内存碎片的原因,那么会继续回到本地节点进行 retry 重试同时取消 ALLOC_NOFRAGMENT(允许引入碎片)
local_nid = zone_to_nid(ac->preferred_zoneref->zone);
if (zone_to_nid(zone) != local_nid) {
// 内核认为保证本地的局部性会比避免内存碎片更加重要
alloc_flags &= ~ALLOC_NOFRAGMENT;
goto retry;
}
}
// 获取本次内存分配需要考虑到的内存水位线,快速路径下是 WMARK_LOW, 慢速路径下是 WMARK_MIN
mark = wmark_pages(zone, alloc_flags & ALLOC_WMARK_MASK);
// 检查当前遍历到的 zone 里剩余的空闲内存容量是否在指定水位线 mark 之上
// 剩余内存容量在水位线之下返回 false
if (!zone_watermark_fast(zone, order, mark,
ac->highest_zoneidx, alloc_flags,
gfp_mask)) {
int ret;
// 如果本次内存分配策略是忽略内存水位线,那么就在本次遍历到的zone里尝试分配内存
if (alloc_flags & ALLOC_NO_WATERMARKS)
goto try_this_zone;
// 如果本次内存分配不能忽略内存水位线的限制,那么就会判断当前 zone 所属 NUMA 节点是否允许进行内存回收
if (!node_reclaim_enabled() ||
!zone_allows_reclaim(ac->preferred_zoneref->zone, zone))
// 不允许进行内存回收则继续遍历下一个 NUMA 节点的内存区域
continue;
// 针对当前 zone 所在 NUMA 节点进行内存回收
ret = node_reclaim(zone->zone_pgdat, gfp_mask, order);
switch (ret) {
case NODE_RECLAIM_NOSCAN:
// 返回该值表示当前 NUMA 节点没有必要进行回收。比如快速分配路径下就不处理页面回收的问题
continue;
case NODE_RECLAIM_FULL:
// 返回该值表示通过扫描之后发现当前 NUMA 节点并没有可以回收的内存页
continue;
default:
// 该分支表示当前 NUMA 节点已经进行了内存回收操作
// zone_watermark_ok 判断内存回收是否回收了足够的内存能否满足内存分配的需要
if (zone_watermark_ok(zone, order, mark,
ac->highest_zoneidx, alloc_flags))
goto try_this_zone;
continue;
}
}
try_this_zone:
// 这里就是伙伴系统的入口,rmqueue 函数中封装的就是伙伴系统的核心逻辑
// 从伙伴系统中获取内存
page = rmqueue(ac->preferred_zoneref->zone, zone, order,
gfp_mask, alloc_flags, ac->migratetype);
if (page) {
// 分配内存成功,初始化内存页 page
prep_new_page(page, order, gfp_mask, alloc_flags);
return page;
} else {
....... 省略 .....
}
}
// 内存分配失败
return NULL;
}
与本文主题无关的非核心步骤大家通过笔者的注释简单了解即可,下面我们只介绍与本文主题相关的核心步骤。
虽然 get_page_from_freelist 函数的代码比较冗长,但是其核心逻辑比较简单,主干框架就是通过 for_next_zone_zonelist_nodemask 来遍历当前 NUMA 节点以及备用节点的所有内存区域(zonelist),然后逐个通过 zone_watermark_fast 检查这些内存区域 zone 中的剩余空闲内存容量是否在指定的水位线 mark 之上。如果满足水位线的要求则直接调用 rmqueue 进入伙伴系统分配内存,分配成功之后通过 prep_new_page 初始化分配好的内存页 page。
如果当前正在遍历的 zone 中剩余空闲内存容量在指定的水位线 mark 之下,就需要通过 node_reclaim 触发内存回收,随后通过 zone_watermark_ok 检查经过内存回收之后,内核是否回收到了足够的内存以满足本次内存分配的需要。如果内存回收到了足够的内存则 zone_watermark_ok = true 随后跳转到 try_this_zone 分支在本内存区域 zone 中分配内存。否则继续遍历下一个 zone。
5.1 获取内存区域 zone 里指定的内存水位线
get_page_from_freelist 函数中的内存分配逻辑是要考虑内存水位线的,满足内存分配要求的物理内存区域 zone 中的剩余空闲内存容量必须在指定内存水位线之上。否则内核则认为内存不足不能进行内存分配。
在上篇文章 《深入理解 Linux 物理内存分配全链路实现》 中的 “3.2 内存分配的心脏 __alloc_pages” 小节的介绍中,我们知道在快速路径下,内存分配策略中的水位线设置为 WMARK_LOW:
// 内存区域中的剩余内存需要在 WMARK_LOW 水位线之上才能进行内存分配,否则失败(初次尝试快速内存分配)
unsigned int alloc_flags = ALLOC_WMARK_LOW;
在上篇文章 “4. 内存慢速分配入口 alloc_pages_slowpath” 小节的介绍中,我们知道在慢速路径下,内存分配策略中的水位线又被调整为了 WMARK_MIN:
// 在慢速内存分配路径中,会进一步放宽对内存分配的限制,将内存分配水位线调低到 WMARK_MIN
// 也就是说内存区域中的剩余内存需要在 WMARK_MIN 水位线之上就可以进行内存分配了
unsigned int alloc_flags = ALLOC_WMARK_MIN | ALLOC_CPUSET;
如果内存分配仍然失败,则内核会将内存分配策略中的水位线调整为 ALLOC_NO_WATERMARKS,表示再内存分配时,可以忽略水位线的限制,再一次进行重试。
不同的内存水位线会影响到内存分配逻辑,所以在通过 for_next_zone_zonelist_nodemask 遍历 NUMA 节点中的物理内存区域的一开始就需要获取该内存区域指定水位线的具体数值,内核通过 wmark_pages 宏来获取:
#define wmark_pages(z, i) (z->_watermark[i] + z->watermark_boost)
struct zone {
// 物理内存区域中的水位线
unsigned long _watermark[NR_WMARK];
// 优化内存碎片对内存分配的影响,可以动态改变内存区域的基准水位线。
unsigned long watermark_boost;
}
关于内存区域 zone 中水位线的相关内容介绍,大家可以回看下笔者之前的文章 《深入理解 Linux 物理内存管理》 中 “ 5.2 物理内存区域中的水位线 ” 小节。
5.2 检查 zone 中剩余内存容量是否满足水位线要求
在我们通过 wmark_pages 获取到当前内存区域 zone 的指定水位线 mark 之后,我们就需要近一步判断当前 zone 中剩余的空闲内存容量是否在水位线 mark 之上,这是保证内存分配顺利进行的必要条件。
内核中判断水位线的逻辑封装在 zone_watermark_fast 和 __zone_watermark_ok 函数中,其中核心逻辑在 __zone_watermark_ok 里,zone_watermark_fast 只是用来快速检测分配阶 order = 0 情况下的相关水位线情况。
下面我们先来看下 zone_watermark_fast 的逻辑:
static inline bool zone_watermark_fast(struct zone *z, unsigned int order,
unsigned long mark, int highest_zoneidx,
unsigned int alloc_flags, gfp_t gfp_mask)
{
long free_pages;
// 获取当前内存区域中所有空闲的物理内存页
free_pages = zone_page_state(z, NR_FREE_PAGES);
// 快速检查分配阶 order = 0 情况下相关水位线,空闲内存需要刨除掉为 highatomic 预留的紧急内存
if (!order) {
long usable_free;
long reserved;
// 可供本次内存分配使用的符合要求的真实可用内存,初始为 free_pages
// free_pages 为空闲内存页的全集其中也包括了不能为本次内存分配提供内存的空闲内存
usable_free = free_pages;
// 获取本次不能使用的空闲内存页数量
reserved = __zone_watermark_unusable_free(z, 0, alloc_flags);
// 计算真正可供内存分配的空闲页数量:空闲内存页全集 - 不能使用的空闲页
usable_free -= min(usable_free, reserved);
// 如果可用的空闲内存页数量大于内存水位线与预留内存之和
// 那么表示物理内存区域中的可用空闲内存能够满足本次内存分配的需要
if (usable_free > mark + z->lowmem_reserve[highest_zoneidx])
return true;
}
// 近一步检查内存区域伙伴系统中是否有足够的 order 阶的内存块可供分配
if (__zone_watermark_ok(z, order, mark, highest_zoneidx, alloc_flags,
free_pages))
return true;
........ 省略无关代码 .......
// 水位线检查失败
return false;
}
首先会通过 zone_page_state 来获取当前 zone 中剩余空闲内存页的总体容量 free_pages。
笔者在 《深入理解 Linux 物理内存管理》的 “ 5. 内核如何管理 NUMA 节点中的物理内存区域 ” 小节中为大家介绍 struct zone 结构体的时候提过,每个内存区域 zone 里有一个 vm_stat 用来存放与 zone 相关的各种统计变量。
struct zone {
// 该内存区域内存使用的统计信息
atomic_long_t vm_stat[NR_VM_ZONE_STAT_ITEMS];
}
内核可以通过 zone_page_state 来访问 vm_stat 从而获取对应的统计量,free_pages 就是其中的一个统计变量。但是这里大家需要注意的是 free_pages 表示的当前 zone 里剩余空闲内存页的一个总量,是一个全集的概念。其中还包括了内存区域的预留内存 lowmem_reserve 以及为 highatomic 预留的紧急内存。这些预留内存都有自己特定的用途,普通内存的申请不会用到预留内存。
流程如果进入到 if (!order) 分支的话表示本次内存分配只是申请一个(order = 0)空闲的内存页,在这里会快速的检测相关水位线情况是否满足,如果满足就会快速返回。
这里涉及到两个重要的局部变量,笔者需要向大家交代一下:
-
usable_free:表示可供本次内存分配使用的空闲内存页总量。前边我们提到 free_pages 表示的是剩余空闲内存页的一个全集,里边还包括很多不能进行普通内存分配的空闲内存页,比如预留内存和紧急内存。
-
reserved:表示本次内存分配不能使用到的空闲内存页数量,这一部分的内存页数量计算是通过 __zone_watermark_unusable_free 函数完成的。最后使用 free_pages 减去 reserved 就可以得到真正的 usable_free 。
static inline long __zone_watermark_unusable_free(struct zone *z,
unsigned int order, unsigned int alloc_flags)
{
// ALLOC_HARDER 的设置表示可以使用 high-atomic 紧急预留内存
const bool alloc_harder = (alloc_flags & (ALLOC_HARDER|ALLOC_OOM));
long unusable_free = (1 << order) - 1;
// 如果没有设置 ALLOC_HARDER 则不能使用 high_atomic 紧急预留内存
if (likely(!alloc_harder))
// 不可用内存的数量需要统计上 high-atomic 这部分内存
unusable_free += z->nr_reserved_highatomic;
#ifdef CONFIG_CMA
// 如果没有设置 ALLOC_CMA 则表示本次内存分配不能从 CMA 区域获取
if (!(alloc_flags & ALLOC_CMA))
// 不可用内存的数量需要统计上 CMA 区域中的空闲内存页
unusable_free += zone_page_state(z, NR_FREE_CMA_PAGES);
#endif
// 返回不可用内存的数量,表示本次内存分配不能使用的内存容量
return unusable_free;
}
如果 usable_free > mark + z->lowmem_reserve[highest_zoneidx] 条件为 true 表示当前可用剩余内存页容量在水位线 mark 之上,可以进行内存分配,返回 true。
我们在 《深入理解 Linux 物理内存管理》的 " 5.2 物理内存区域中的水位线 " 小节中介绍水位线相关的计算逻辑的时候提过,水位线的计算是需要刨去 lowmem_reserve 预留内存的,也就是水位线的值并不包含 lowmem_reserve 内存在内。
所以这里在判断可用内存是否满足水位线的关系时需要加上这部分 lowmem_reserve ,才能得到正确的结果。
如果本次内存分配申请的是高阶内存块( order > 0),则会进入 __zone_watermark_ok 函数中,近一步判断伙伴系统中是否有足够的高阶内存块能够满足 order 阶的内存分配:
bool __zone_watermark_ok(struct zone *z, unsigned int order, unsigned long mark,
int highest_zoneidx, unsigned int alloc_flags,
long free_pages)
{
// 保证内存分配顺利进行的最低水位线
long min = mark;
int o;
const bool alloc_harder = (alloc_flags & (ALLOC_HARDER|ALLOC_OOM));
// 获取真正可用的剩余空闲内存页数量
free_pages -= __zone_watermark_unusable_free(z, order, alloc_flags);
// 如果设置了 ALLOC_HIGH 则水位线降低二分之一,使内存分配更加努力激进一些
if (alloc_flags & ALLOC_HIGH)
min -= min / 2;
if (unlikely(alloc_harder)) {
// 在要进行 OOM 的情况下内存分配会比普通的 ALLOC_HARDER 策略更加努力激进一些,所以这里水位线会降低二分之一
if (alloc_flags & ALLOC_OOM)
min -= min / 2;
else
// ALLOC_HARDER 策略下水位线只会降低四分之一
min -= min / 4;
}
// 检查当前可用剩余内存是否在指定水位线之上。
// 内存的分配必须保证可用剩余内存容量在指定水位线之上,否则不能进行内存分配
if (free_pages <= min + z->lowmem_reserve[highest_zoneidx])
return false;
// 流程走到这里,对应内存分配阶 order = 0 的情况下就已经 OK 了
// 剩余空闲内存在水位线之上,那么肯定能够分配一页出来
if (!order)
return true;
// 但是对于 high-order 的内存分配,这里还需要近一步检查伙伴系统
// 根据伙伴系统内存分配的原理,这里需要检查高阶 free_list 中是否有足够的空闲内存块可供分配
for (o = order; o < MAX_ORDER; o++) {
// 从当前分配阶 order 对应的 free_area 中检查是否有足够的内存块
struct free_area *area = &z->free_area[o];
int mt;
// 如果当前 free_area 中的 nr_free = 0 表示对应 free_list 中没有合适的空闲内存块
// 那么继续到高阶 free_area 中查找
if (!area->nr_free)
continue;
// 检查 free_area 中所有的迁移类型 free_list 是否有足够的内存块
for (mt = 0; mt < MIGRATE_PCPTYPES; mt++) {
if (!free_area_empty(area, mt))
return true;
}
#ifdef CONFIG_CMA
// 如果内存分配指定需要从 CMA 区域中分配连续内存
// 那么就需要检查 MIGRATE_CMA 对应的 free_list 是否是空
if ((alloc_flags & ALLOC_CMA) &&
!free_area_empty(area, MIGRATE_CMA)) {
return true;
}
#endif
// 如果设置了 ALLOC_HARDER,则表示可以从 HIGHATOMIC 区中的紧急预留内存中分配,检查对应 free_list
if (alloc_harder && !free_area_empty(area, MIGRATE_HIGHATOMIC))
return true;
}
// 伙伴系统中的剩余内存块无法满足 order 阶的内存分配
return false;
}
在 __zone_watermark_ok 函数的开始需要计算出真正可用的剩余内存 free_pages 。
// 获取真正可用的剩余空闲内存页数量
free_pages -= __zone_watermark_unusable_free(z, order, alloc_flags);
紧接着内核会根据 ALLOC_HIGH 以及 ALLOC_HARDER 标识来决定是否降低水位线的要求。在 《深入理解 Linux 物理内存分配全链路实现》 一文中的 “3.1 内存分配行为标识掩码 ALLOC_* ” 小节中笔者曾详细的为大家介绍过这些 ALLOC_* 相关的掩码,当时笔者提了一句,当内存分配策略设置为 ALLOC_HIGH 或者 ALLOC_HARDER 时,会使内存分配更加的激进,努力一些。
当时大家可能会比较懵,怎样才算是激进?怎样才算是努力呢?
其实答案就在这里,当内存分配策略 alloc_flags 设置了 ALLOC_HARDER 时,水位线的要求会降低原来的四分之一,相当于放款了内存分配的限制。比原来更加努力使内存分配成功。
当内存分配策略 alloc_flags 设置了 ALLOC_HIGH 时,水位线的要求会降低原来的二分之一,相当于更近一步放款了内存分配的限制。比原来更加激进些。
在调整完水位线之后,还是一样的逻辑,需要判断当前可用剩余内存容量是否在水位线之上,如果是,则水位线检查完毕符合内存分配的要求。如果不是,则返回 false 不能进行内存分配。
// 内存的分配必须保证可用剩余内存容量在指定水位线之上,否则不能进行内存分配
free_pages <= min + z->lowmem_reserve[highest_zoneidx])
在水位线 OK 之后,对于 order = 0 的内存分配情形下,就已经 OK 了,可以放心直接进行内存分配了。
但是对于 high-order 的内存分配情形,这里还需要近一步检查伙伴系统是否有足够的空闲内存块可以满足本次 high-order 的内存分配。
根据本文 《3. 伙伴系统的内存分配原理》小节中,为大家介绍的伙伴系统内存分配原理,内核需要从当前分配阶 order 开始一直向高阶 free_area 中查找对应的 free_list 中是否有足够的内存块满足 order 阶的内存分配要求。
-
如果有,那么水位线相关的校验工作到此结束,内核会直接去伙伴系统中申请 order 阶的内存块。
-
如果没有,则水位线校验失败,伙伴系统无法满足本次的内存分配要求。
5.3 内存分配成功之后初始化 page
经过 zone_watermark_ok 的校验,现在内存水位线符合内存分配的要求,并且伙伴系统中有足够的空闲内存块可供内存分配申请,现在可以放心调用 rmqueue 函数进入伙伴系统进行内存分配了。
rmqueue 函数封装的正是伙伴系统的核心逻辑,这一部分的源码实现笔者放在下一小节中介绍,这里我们先关注内存分配成功之后,对于内存页 page 的初始化逻辑。
当通过 rmqueue 函数从伙伴系统中成功申请到分配阶为 order 大小的内存块时,内核需要调用 prep_new_page 函数初始化这部分内存块,之后才能返回给进程使用。
static void prep_new_page(struct page *page, unsigned int order, gfp_t gfp_flags,
unsigned int alloc_flags)
{
// 初始化 struct page,清除一些页面属性标记
post_alloc_hook(page, order, gfp_flags);
// 设置复合页
if (order && (gfp_flags & __GFP_COMP))
prep_compound_page(page, order);
if (alloc_flags & ALLOC_NO_WATERMARKS)
// 使用 set_page_XXX(page) 方法设置 page 的 PG_XXX 标志位
set_page_pfmemalloc(page);
else
// 使用 clear_page_XXX(page) 方法清除 page 的 PG_XXX 标志位
clear_page_pfmemalloc(page);
}
5.3.1 初始化 struct page
由于现在我们拿到的 struct page 结构是刚刚从伙伴系统中申请出来的,里面可能包含一些无用的标记(上一次被使用过的,还没清理),所以需要将这些无用标记清理掉,并且在此基础上根据 gfp_flags 掩码对 struct page 进行初始化的准备工作。
比如通过 set_page_private 将 struct page 里的 private 指针所指向的内容清空,private 指针在内核中的使用比较复杂,它会在不同场景下指向不同的内容。
set_page_private(page, 0);
将页面的使用计数设置为 1 ,表示当前物理内存页正在被使用。
set_page_refcounted(page);
如果 gfp_flags 掩码中设置了 ___GFP_ZERO,这时就需要将这些 page 初始化为零页。
由于初始化页面的准备工作和本文的主线内容并没有多大的关联,所以笔者这里只做简单介绍,大家大概了解一下初始化做了哪些准备工作即可。
5.3.2 设置复合页 compound_page
复合页 compound_page 本质上就是通过两个或者多个物理上连续的内存页 page 组装成的一个在逻辑上看起来比普通内存页 page 更大的页。它底层的依赖本质还是一个一个的普通内存页 page。
我们都知道 Linux 管理内存的最小单位是 page,每个 page 描述 4K 大小的物理内存,但在一些内核使用场景中,比如 slab 内存池中,往往会向伙伴系统一次性申请多个普通内存页 page,然后将这些内存页 page 划分为多个大小相同的小内存块,这些小内存块被 slab 内存池统一管理。
slab 内存池底层其实依赖的是多个普通内存页,但是内核期望将这多个内存页统一成一个逻辑上的内存页来统一管理,这个逻辑上的内存页就是本小节要介绍的复合页。
而在 Linux 内存管理的架构中都是统一通过 struct page 来管理内存,复合页却是通过两个或者多个物理上连续的内存页 page 组装成的一个逻辑页,那么复合页的管理与普通页的管理如何统一呢?
这就引出了本小节的主题——复合页 compound_page,下面我们就来看下 Linux 如果通过统一的 struct page 结构来描述这些复合页(compound_page):
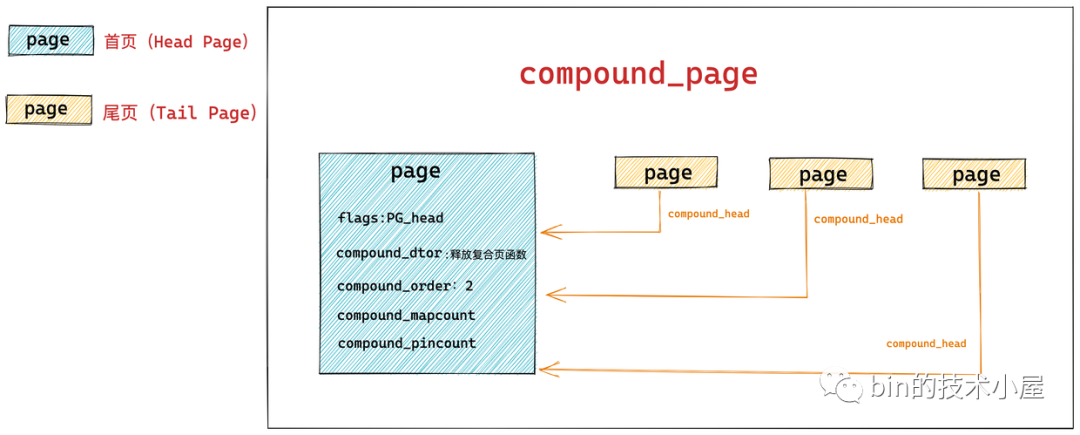
虽然复合页(compound_page)是由多个物理上连续的普通 page 组成的,但是在内核的视角里它还是被当做一个特殊内存页来看待。
下图所示,是由 4 个连续的普通内存页 page 组成的一个 compound_page:
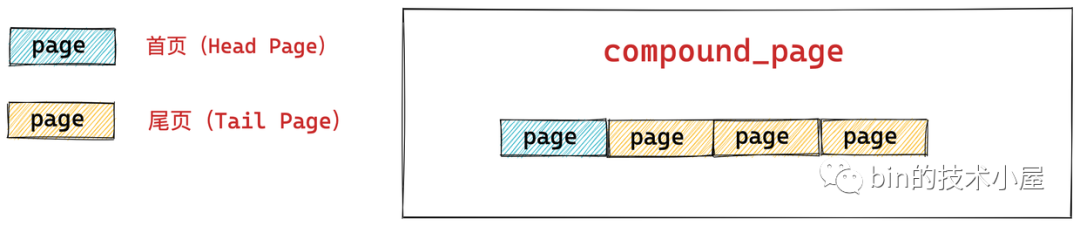
组成复合页的第一个 page 我们称之为首页(Head Page),其余的均称之为尾页(Tail Page)。
我们来看一下 struct page 中关于描述 compound_page 的相关字段:
struct page {
// 首页 page 中的 flags 会被设置为 PG_head 表示复合页的第一页
unsigned long flags;
// 其余尾页会通过该字段指向首页
unsigned long compound_head;
// 用于释放复合页的析构函数,保存在首页中
unsigned char compound_dtor;
// 该复合页有多少个 page 组成,order 还是分配阶的概念,在首页中保存
// 本例中的 order = 2 表示由 4 个普通页组成
unsigned char compound_order;
// 该复合页被多少个进程使用,内存页反向映射的概念,首页中保存
atomic_t compound_mapcount;
// 复合页使用计数,首页中保存
atomic_t compound_pincount;
}
首页对应的 struct page 结构里的 flags 会被设置为 PG_head,表示这是复合页的第一页。
另外首页中还保存关于复合页的一些额外信息,比如:
-
用于释放复合页的析构函数会保存在首页 struct page 结构里的 compound_dtor 字段中 -
复合页的分配阶 order 会保存在首页中的 compound_order 中以及用于指示复合页的引用计数 compound_pincount,以及复合页的反向映射个数(该复合页被多少个进程的页表所映射)compound_mapcount 均在首页中保存。
关于 struct page 的 flags 字段的介绍,以及内存页反向映射原理,大家可以回看下笔者 《深入理解 Linux 物理内存管理》中的 “ 6.4 物理内存页属性和状态的标志位 flag ” 和 “ 6.1 匿名页的反向映射 ” 小节。
复合页中的所有尾页都会通过其对应的 struct page 结构中的 compound_head 指向首页,这样通过首页和尾页就组装成了一个完整的复合页 compound_page 。
在我们理解了 compound_page 的组织结构之后,我们在回过头来看 "6.3 内存分配成功之后初始化 page" 小节中的 prep_new_page 函数:
当内核向伙伴系统申请复合页 compound_page 的时候,会在 gfp_flags 掩码中设置 __GFP_COMP 标识,表次本次内存分配要分配一个复合页,复合页中的 page 个数由分配阶 order 决定。
当内核向伙伴系统申请了 2 ^ order 个内存页 page 时,大家注意在伙伴系统的视角中内存还是一页一页的,伙伴系统并不知道有复合页的存在,当我们申请成功之后,需要在 prep_new_page 函数中将这 2 ^ order 个内存页 page 按照前面介绍的逻辑组装成一个 复合页 compound_page。
void prep_compound_page(struct page *page, unsigned int order)
{
int i;
int nr_pages = 1 << order;
// 设置首页 page 中的 flags 为 PG_head
__SetPageHead(page);
// 首页之后的 page 全部是尾页,循环遍历设置尾页
for (i = 1; i < nr_pages; i++)
prep_compound_tail(page, i);
// 最后设置首页相关属性
prep_compound_head(page, order);
}
static void prep_compound_tail(struct page *head, int tail_idx)
{
// 由于复合页中的 page 全部是连续的,直接使用偏移即可获得对应尾页
struct page *p = head + tail_idx;
// 设置尾页标识
p->mapping = TAIL_MAPPING;
// 尾页 page 结构中的 compound_head 指向首页
set_compound_head(p, head);
}
static __always_inline void set_compound_head(struct page *page, struct page *head)
{
WRITE_ONCE(page->compound_head, (unsigned long)head + 1);
}
static void prep_compound_head(struct page *page, unsigned int order)
{
// 设置首页相关属性
set_compound_page_dtor(page, COMPOUND_PAGE_DTOR);
set_compound_order(page, order);
atomic_set(compound_mapcount_ptr(page), -1);
atomic_set(compound_pincount_ptr(page), 0);
}
6. 伙伴系统的实现
现在内核通过前边介绍的 get_page_from_freelist 函数,循环遍历 zonelist 终于找到了符合内存分配条件的物理内存区域 zone。接下来就会通过 rmqueue 函数进入到该物理内存区域 zone 对应的伙伴系统中实际分配物理内存。
/*
* Allocate a page from the given zone. Use pcplists for order-0 allocations.
*/
static inline
struct page *rmqueue(struct zone *preferred_zone,
struct zone *zone, unsigned int order,
gfp_t gfp_flags, unsigned int alloc_flags,
int migratetype)
{
unsigned long flags;
struct page *page;
if (likely(order == 0)) {
// 当我们申请一个物理页面(order = 0)时,内核首先会从 CPU 高速缓存列表 pcplist 中直接分配,而不会走伙伴系统,提高内存分配速度
page = rmqueue_pcplist(preferred_zone, zone, gfp_flags,
migratetype, alloc_flags);
goto out;
}
// 加锁并关闭中断,防止并发访问
spin_lock_irqsave(&zone->lock, flags);
// 当申请页面超过一个 (order > 0)时,则从伙伴系统中进行分配
do {
page = NULL;
if (alloc_flags & ALLOC_HARDER) {
// 如果设置了 ALLOC_HARDER 分配策略,则从伙伴系统的 HIGHATOMIC 迁移类型的 freelist 中获取
page = __rmqueue_**allest(zone, order, MIGRATE_HIGHATOMIC);
}
if (!page)
// 从伙伴系统中申请分配阶 order 大小的物理内存块
page = __rmqueue(zone, order, migratetype, alloc_flags);
} while (page && check_new_pages(page, order));
// 解锁
spin_unlock(&zone->lock);
if (!page)
goto failed;
// 重新统计内存区域中的相关统计指标
zone_statistics(preferred_zone, zone);
// 打开中断
local_irq_restore(flags);
out:
return page;
failed:
// 分配失败
local_irq_restore(flags);
return NULL;
}
6.1 从 CPU 高速缓存列表中获取内存页
内核对只分配一页物理内存的情况做了特殊处理,当只请求一页内存时,内核会借助 CPU 高速缓存冷热页列表 pcplist 加速内存分配的处理,此时分配的内存页将来自于 pcplist 而不是伙伴系统。
pcp 是 per_cpu_pageset 的缩写,内核会为每个 CPU 分配一个高速缓存列表,关于这部分内容,笔者已经在 《深入理解 Linux 物理内存管理》一文中的 “ 5.7 物理内存区域中的冷热页 ” 小节非常详细的为大家介绍过了,忘记的同学可以在回看下。
在 NUMA 内存架构下,每个物理内存区域都归属于一个特定的 NUMA 节点,NUMA 节点中包含了一个或者多个 CPU,NUMA 节点中的每个内存区域会关联到一个特定的 CPU 上.
而每个 CPU 都有自己独立的高速缓存,所以每个 CPU 对应一个 per_cpu_pageset 结构,用于管理这个 CPU 高速缓存中的冷热页。
所谓的热页就是已经加载进 CPU 高速缓存中的物理内存页,所谓的冷页就是还未加载进 CPU 高速缓存中的物理内存页,冷页是热页的后备选项
每个 CPU 都可以访问系统中的所有物理内存页,尽管访问速度不同,因此特定的物理内存区域 struct zone 不仅要考虑到所属 NUMA 节点中相关的 CPU,还需要照顾到系统中的其他 CPU。
在 Linux 内核中,系统会经常请求和释放单个页面。如果针对每个 CPU,都为其预先分配一个用于缓存单个内存页面的高速缓存页列表,用于满足本地 CPU 发出的单页内存请求,就能提升系统的性能。所以在 struct zone 结构中持有了系统中所有 CPU 的高速缓存页列表 per_cpu_pageset。
struct zone {
struct per_cpu_pages __percpu *per_cpu_pageset;
}
struct per_cpu_pages {
int count; /* pcplist 里的页面总数 */
int high; /* pcplist 里的高水位线,count 超过 high 时,内核会释放 batch 个页面到伙伴系统中*/
int batch; /* pcplist 里的页面来自于伙伴系统,batch 定义了每次从伙伴系统获取或者归还多少个页面*/
// CPU 高速缓存列表 pcplist,每个迁移类型对应一个 pcplist
struct list_head lists[NR_PCP_LISTS];
};
当内核尝试从 pcplist 中获取一个物理内存页时,会首先获取运行当前进程的 CPU 对应的高速缓存列表 pcplist。然后根据指定的具体页面迁移类型 migratetype 获取对应迁移类型的 pcplist。
当获取到符合条件的 pcplist 之后,内核会调用 __rmqueue_pcplist 从 pcplist 中摘下一个物理内存页返回。
/* Lock and remove page from the per-cpu list */
static struct page *rmqueue_pcplist(struct zone *preferred_zone,
struct zone *zone, gfp_t gfp_flags,
int migratetype, unsigned int alloc_flags)
{
struct per_cpu_pages *pcp;
struct list_head *list;
struct page *page;
unsigned long flags;
// 关闭中断
local_irq_save(flags);
// 获取运行当前进程的 CPU 高速缓存列表 pcplist
pcp = &this_cpu_ptr(zone->pageset)->pcp;
// 获取指定页面迁移类型的 pcplist
list = &pcp->lists[migratetype];
// 从指定迁移类型的 pcplist 中移除一个页面,用于内存分配
page = __rmqueue_pcplist(zone, migratetype, alloc_flags, pcp, list);
if (page) {
// 统计内存区域内的相关信息
zone_statistics(preferred_zone, zone);
}
// 开中断
local_irq_restore(flags);
return page;
}
pcplist 中缓存的内存页面其实全部来自于伙伴系统,当 pcplist 中的页面数量 count 为 0 (表示此时 pcplist 里没有缓存的页面)时,内核会调用 rmqueue_bulk 从伙伴系统中获取 batch 个物理页面添加到 pcplist,从伙伴系统中获取页面的过程参照本文 "3. 伙伴系统的内存分配原理" 小节中的内容。
随后内核会将 pcplist 中的第一个物理内存页从链表中摘下返回,count 计数减一。
/* Remove page from the per-cpu list, caller must protect the list */
static struct page *__rmqueue_pcplist(struct zone *zone, int migratetype,
unsigned int alloc_flags,
struct per_cpu_pages *pcp,
struct list_head *list)
{
struct page *page;
do {
// 如果当前 pcplist 中的页面为空,那么则从伙伴系统中获取 batch 个页面放入 pcplist 中
if (list_empty(list)) {
pcp->count += rmqueue_bulk(zone, 0,
pcp->batch, list,
migratetype, alloc_flags);
if (unlikely(list_empty(list)))
return NULL;
}
// 获取 pcplist 上的第一个物理页面
page = list_first_entry(list, struct page, lru);
// 将该物理页面从 pcplist 中摘除
list_del(&page->lru);
// pcplist 中的 count 减一
pcp->count--;
} while (check_new_pcp(page));
return page;
}
6.2 从伙伴系统中获取内存页
在本文 "3. 伙伴系统的内存分配原理" 小节中笔者详细为大家介绍了伙伴系统的整个内存分配原理,那么在本小节中,我们将正式进入伙伴系统中,来看下伙伴系统在内核中是如何实现的。
在前面介绍的 rmqueue 函数中,涉及到伙伴系统入口函数的有两个:
-
__rmqueue_**allest 函数主要是封装了整个伙伴系统关于内存分配的核心流程,该函数中的代码正是 “3. 伙伴系统的内存分配原理” 小节所讲的核心内容。
-
__rmqueue 函数封装的是伙伴系统的整个完整流程,底层调用了 __rmqueue_**allest 函数,它主要实现的是当伙伴系统 free_area 中对应的迁移列表 free_list[MIGRATE_TYPE] 无法满足内存分配需求时, 内存分配在伙伴系统中的 fallback 流程。这一点笔者也在 “3. 伙伴系统的内存分配原理” 小节中详细介绍过了。
当我们向内核申请的内存页超过一页(order > 0)时,内核就会进入伙伴系统中为我们申请内存。
如果内存分配策略 alloc_flags 指定了 ALLOC_HARDER 时,就会调用 __rmqueue_**allest 直接进入伙伴系统,从 free_list[MIGRATE_HIGHATOMIC] 链表中分配 order 大小的物理内存块。
如果分配失败或者 alloc_flags 没有指定 ALLOC_HARDER 则会通过 __rmqueue 进入伙伴系统,这里会处理分配失败之后的 fallback 逻辑。
/*
* This array describes the order lists are fallen back to when
* the free lists for the desirable migrate type are depleted
*
* The other migratetypes do not have fallbacks.
*/
static int fallbacks[MIGRATE_TYPES][3] = {
[MIGRATE_UNMOVABLE] = { MIGRATE_RECLAIMABLE, MIGRATE_MOVABLE, MIGRATE_TYPES },
[MIGRATE_MOVABLE] = { MIGRATE_RECLAIMABLE, MIGRATE_UNMOVABLE, MIGRATE_TYPES },
[MIGRATE_RECLAIMABLE] = { MIGRATE_UNMOVABLE, MIGRATE_MOVABLE, MIGRATE_TYPES },
};
6.2.1 __rmqueue_**allest 伙伴系统的核心实现
我们还是以 “3. 伙伴系统的内存分配原理” 小节中,介绍伙伴系统内存分配核心原理时,所举的示例为大家剖析伙伴系统的核心源码实现。
假设当前伙伴系统中只有 order = 3 的空闲链表 free_area[3] ,其中只有一个空闲的内存块,包含了连续的 8 个 page。其余剩下的分配阶 order 对应的空闲链表中均是空的。
现在我们向伙伴系统申请一个 page 大小的内存(对应的分配阶 order = 0),经过前面的介绍我们知道当申请一个 page 大小的内存时,内核是从 pcplist 中进行分配的,但是这里笔者为了方便给大家介绍伙伴系统,所以我们暂时让它走伙伴系统的流程。
内核会在伙伴系统中从当前分配阶 order 开始,依次遍历 free_area[order] 里对应的指定页面迁移类型 free_list[MIGRATE_TYPE] 链表,直到找到一个合适尺寸的内存块为止。
在本示例中,内核会在伙伴系统中首先查看 order = 0 对应的空闲链表 free_area[0] 中是否有空闲内存块可供分配。如果有,则将该空闲内存块从 free_area[0] 摘下返回,内存分配成功。
如果没有,随后内核会根据前边介绍的内存分配逻辑,继续升级到 free_area[1] , free_area[2] 链表中寻找空闲内存块,直到查找到 free_area[3] 发现有一个可供分配的内存块。这个内存块中包含了 8 个连续的空闲 page,然后将这 8 个 连续的空闲 page 组成的内存块依次进行减半**,将每次**出来的后半部分内存块插入到对应尺寸的 free_area 中,如下图所示:
/*
* Go through the free lists for the given migratetype and remove
* the **allest available page from the freelists
*/
static __always_inline
struct page *__rmqueue_**allest(struct zone *zone, unsigned int order,
int migratetype)
{
unsigned int current_order;
struct free_area *area;
struct page *page;
/* 从当前分配阶 order 开始在伙伴系统对应的 free_area[order] 里查找合适尺寸的内存块*/
for (current_order = order; current_order < MAX_ORDER; ++current_order) {
// 获取当前 order 在伙伴系统中对应的 free_area[order]
// 对应上图 free_area[3]
area = &(zone->free_area[current_order]);
// 从 free_area[order] 中对应的 free_list[MIGRATE_TYPE] 链表中获取空闲内存块
page = get_page_from_free_area(area, migratetype);
if (!page)
// 如果当前 free_area[order] 中没有空闲内存块则继续向上查找
// 对应上图 free_area[0],free_area[1],free_area[2]
continue;
// 如果在当前 free_area[order] 中找到空闲内存块,则从 free_list[MIGRATE_TYPE] 链表中摘除
// 对应上图步骤 1:将内存块从 free_area[3] 中摘除
del_page_from_free_area(page, area);
// 将摘下来的内存块进行减半**并插入对应的尺寸的 free_area 中
// 对应上图步骤 [2,3], [4,5], [6,7]
expand(zone, page, order, current_order, area, migratetype);
// 设置页面的迁移类型
set_pcppage_migratetype(page, migratetype);
// 内存分配成功返回,对应上图步骤 8
return page;
}
// 内存分配失败返回 null
return NULL;
}
下面我们来看下减半**过程的实现,expand 函数中的参数在本节示例中:low = 指定分配阶 order = 0,high = 最后遍历到的分配阶 order = 3。
static inline void expand(struct zone *zone, struct page *page,
int low, int high, struct free_area *area,
int migratetype)
{
// size = 8,表示当前要进行减半**的内存块是由 8 个连续 page 组成的。
// 刚刚从 free_area[3] 上摘下
unsigned long size = 1 << high;
// 依次进行减半**,直到**出指定 order 的内存块出来
// 对应上图中的步骤 2,4,6
// 初始 high = 3 ,low = 0
while (high > low) {
// free_area 要降到下一阶,此时变为 free_area[2]
area--;
// 分配阶要降级 high = 2
high--;
// 内存块尺寸要减半,由 8 变成 4,表示要**出由 4 个连续 page 组成的两个内存块。
// 参考上图中的步骤 2
size >>= 1;
// 标记为保护页,当其伙伴被释放时,允许合并,参见 《4.伙伴系统的内存回收原理》小节
if (set_page_guard(zone, &page[size], high, migratetype))
continue;
// 将本次减半**出来的第二个内存块插入到对应 free_area[high] 中
// 参见上图步骤 3,5,7
add_to_free_area(&page[size], area, migratetype);
// 设置内存块的分配阶 high
set_page_order(&page[size], high);
// 本次**出来的第一个内存块继续循环进行减半**直到 high = low
// 即已经**出来了指定 order 尺寸的内存块无需在进行**了,直接返回
// 参见上图步骤 2,4,6
}
}
6.2.2 __rmqueue 伙伴系统的 fallback 实现
当我们向内核申请的内存页面超过一页(order > 0 ),并且内存分配策略 alloc_flags 中并没有设置 ALLOC_HARDER 的时候,内存分配流程就会进入 __rmqueue 走常规的伙伴系统分配流程。
static __always_inline struct page *
__rmqueue(struct zone *zone, unsigned int order, int migratetype,
unsigned int alloc_flags)
{
struct page *page;
retry:
// 首先进入伙伴系统到指定页面迁移类型的 free_list[migratetype] 获取空闲内存块
// 这里走的就是上小节中介绍的伙伴系统核心流程
page = __rmqueue_**allest(zone, order, migratetype);
if (unlikely(!page)) {
..... 当伙伴系统中没有足够指定迁移类型 migratetype 的空闲内存块时,就会进入这个分支 .....
// 如果迁移类型是 MIGRATE_MOVABLE 则优先 fallback 到 CMA 区中分配内存
if (migratetype == MIGRATE_MOVABLE)
page = __rmqueue_cma_fallback(zone, order);
// 走常规的伙伴系统 fallback 流程,核心原理参见《3.伙伴系统的内存分配原理》小节
if (!page && __rmqueue_fallback(zone, order, migratetype,
alloc_flags))
goto retry;
}
// 内存分配成功
return page;
}
从上述 __rmqueue 函数的源码实现中我们可以看出,该函数处理了伙伴系统内存分配的异常流程,即调用 __rmqueue_**allest 进入伙伴系统分配内存时,发现伙伴系统各个分配阶 free_area[order] 中对应的迁移列表 free_list[MIGRATE_TYPE] 无法满足内存分配需求时,__rmqueue_**allest 函数就会返回 null,伙伴系统内存分配失败。
随后内核就会进入伙伴系统的 fallback 流程,这里对 MIGRATE_MOVABLE 迁移类型做了一下特殊处理,当伙伴系统中 free_list[MIGRATE_MOVABLE] 没有足够空闲内存块时,会优先降级到 CMA 区域内进行分配。
static __always_inline struct page *__rmqueue_cma_fallback(struct zone *zone,
unsigned int order)
{
return __rmqueue_**allest(zone, order, MIGRATE_CMA);
}
如果我们指定的页面迁移类型并非 MIGRATE_MOVABLE 或者降级 CMA 之后仍然分配失败,内核就会进入 __rmqueue_fallback 走常规的 fallback 流程,该函数封装的正是笔者在 “3. 伙伴系统的内存分配原理” 小节的后半部分介绍的 fallback 逻辑:
在 __rmqueue_fallback 函数中,内核会根据预先定义的相关 fallback 规则开启内存分配的 fallback 流程。fallback 规则在内核中用一个 int 类型的二维数组表示,其中第一维表示需要进行 fallback 的页面迁移类型,第二维表示 fallback 的优先级。后续内核会按照这个优先级 fallback 到具体的 free_list[fallback_migratetype] 中去分配内存。
static int fallbacks[MIGRATE_TYPES][3] = {
[MIGRATE_UNMOVABLE] = { MIGRATE_RECLAIMABLE, MIGRATE_MOVABLE, MIGRATE_TYPES },
[MIGRATE_MOVABLE] = { MIGRATE_RECLAIMABLE, MIGRATE_UNMOVABLE, MIGRATE_TYPES },
[MIGRATE_RECLAIMABLE] = { MIGRATE_UNMOVABLE, MIGRATE_MOVABLE, MIGRATE_TYPES },
};
比如:MIGRATE_UNMOVABLE 类型的 free_list 内存不足时,内核会 fallback 到 MIGRATE_RECLAIMABLE 中去获取,如果还是不足,则再次降级到 MIGRATE_MOVABLE 中获取,如果仍然无法满足内存分配,才会失败退出。
static __always_inline bool
__rmqueue_fallback(struct zone *zone, int order, int start_migratetype,
unsigned int alloc_flags)
{
// 最终会 fall back 到伙伴系统的哪个 free_area 中分配内存
struct free_area *area;
// fallback 和正常的分配流程正好相反,是从最高阶的free_area[MAX_ORDER - 1] 开始查找空闲内存块
int current_order;
// 最初指定的内存分配阶
int min_order = order;
struct page *page;
// 最终计算出 fallback 到哪个页面迁移类型 free_list 上
int fallback_mt;
// 是否可以从 free_list[fallback] 中窃取内存块到 free_list[start_migratetype] 中
// start_migratetype 表示我们最初指定的页面迁移类型
bool can_steal;
// 如果设置了 ALLOC_NOFRAGMENT 表示不希望引入内存碎片
// 在这种情况下内核会更加倾向于分配一个尽可能大的内存块,避免向其他链表引入内存碎片
if (alloc_flags & ALLOC_NOFRAGMENT)
// pageblock_order 用于定义系统支持的巨型页对应的分配阶
// 默认为最大分配阶 - 1 = 9
min_order = pageblock_order;
// fallback 内存分配流程从最高阶 free_area 开始查找空闲内存块(页面迁移类型为 fallback 类型)
for (current_order = MAX_ORDER - 1; current_order >= min_order;
--current_order) {
// 获取伙伴系统中最高阶的 free_area
area = &(zone->free_area[current_order]);
// 按照上述的内存分配 fallback 规则查找最合适的 fallback 迁移类型
fallback_mt = find_suitable_fallback(area, current_order,
start_migratetype, false, &can_steal);
// 如果没有合适的 fallback_mt,则继续降级到下一个分配阶 free_area 中查找
if (fallback_mt == -1)
continue;
// can_steal 会在 find_suitable_fallback 的过程中被设置
// 当我们指定的页面迁移类型为 MIGRATE_MOVABLE 并且无法从其他 fallback 迁移类型列表中窃取页面 can_steal = false 时
// 内核会更加倾向于 fallback 分配最小的可用页面,即尺寸和指定order最接近的页面数量而不是尺寸最大的
// 因为这里的条件是分配可移动的页面类型,天然可以避免永久内存碎片,无需按照最大的尺寸分配
if (!can_steal && start_migratetype == MIGRATE_MOVABLE
&& current_order > order)
goto find_**allest;
// can_steal = true,则开始从 free_list[fallback] 列表中窃取页面
goto do_steal;
}
return false;
find_**allest:
// 该分支目的在于寻找尺寸最贴近指定 order 大小的最小可用页面
// 从指定 order 开始 fallback
for (current_order = order; current_order < MAX_ORDER;
current_order++) {
area = &(zone->free_area[current_order]);
fallback_mt = find_suitable_fallback(area, current_order,
start_migratetype, false, &can_steal);
if (fallback_mt != -1)
break;
}
do_steal:
// 从上述流程获取到的伙伴系统 free_area 中获取 free_list[fallback_mt]
page = get_page_from_free_area(area, fallback_mt);
// 从 free_list[fallback_mt] 中窃取页面到 free_list[start_migratetype] 中
steal_suitable_fallback(zone, page, alloc_flags, start_migratetype,
can_steal);
// 返回到 __rmqueue 函数中进行 retry 重试流程,此时 free_list[start_migratetype] 中已经有足够的内存页面可供分配了
return true;
}
从上述内存分配 fallback 源码实现中,我们可以看出内存分配 fallback 流程正好和正常的分配流程相反:
-
伙伴系统正常内存分配流程先是从低阶到高阶依次查找空闲内存块,然后将高阶中的内存块依次减半**到低阶 free_list 链表中。
-
伙伴系统 fallback 内存分配流程则是先从最高阶开始查找,找到一块空闲内存块之后,先迁移到最初指定的 free_list[start_migratetype] 链表中,然后在指定的 free_list[start_migratetype] 链表中执行减半**。
6.2.3 fallback 核心逻辑实现
本小节我们来看下内核定义的 fallback 规则具体的流程实现,fallback 规则定义如下,笔者在之前的章节中已经多次提到过了,这里不在重复解释,我们重点关注它的 fallback 流程实现。
static int fallbacks[MIGRATE_TYPES][3] = {
[MIGRATE_UNMOVABLE] = { MIGRATE_RECLAIMABLE, MIGRATE_MOVABLE, MIGRATE_TYPES },
[MIGRATE_MOVABLE] = { MIGRATE_RECLAIMABLE, MIGRATE_UNMOVABLE, MIGRATE_TYPES },
[MIGRATE_RECLAIMABLE] = { MIGRATE_UNMOVABLE, MIGRATE_MOVABLE, MIGRATE_TYPES },
};
find_suitable_fallback 函数中封装了页面迁移类型整个的 fallback 过程:
-
fallback 规则定义在 fallbacks[MIGRATE_TYPES][3] 二维数组中,第一维表示要进行 fallback 的页面迁移类型 migratetype。第二维 migratetype 迁移类型可以 fallback 到哪些迁移类型中,这些可以 fallback 的页面迁移类型按照优先级排列。
-
该函数的核心逻辑是在
for (i = 0;; i++)循环中按照 fallbacks[migratetype][i] 数组定义的 fallback 优先级,依次在 free_area[order] 中对应的 free_list[fallback] 列表中查找是否有空闲的内存块。
-
如果当前 free_list[fallback] 列表中没有空闲内存块,则继续在 for 循环中降级到下一个 fallback 页面迁移类型中去查找,也就是 for 循环中的 fallbacks[migratetype][i] 。直到找到空闲内存块为止,否则返回 -1。
int find_suitable_fallback(struct free_area *area, unsigned int order,
int migratetype, bool only_stealable, bool *can_steal)
{
int i;
// 最终选取的 fallback 页面迁移类型
int fallback_mt;
// 当前 free_area[order] 中以无空闲页面,则返回失败
if (area->nr_free == 0)
return -1;
*can_steal = false;
// 按照 fallback 优先级,循环在 free_list[fallback] 中查询是否有空闲内存块
for (i = 0;; i++) {
// 按照优先级获取 fallback 页面迁移类型
fallback_mt = fallbacks[migratetype][i];
if (fallback_mt == MIGRATE_TYPES)
break;
// 如果当前 free_list[fallback] 为空则继续循环降级查找
if (free_area_empty(area, fallback_mt))
continue;
// 判断是否可以从 free_list[fallback] 窃取页面到指定 free_list[migratetype] 中
if (can_steal_fallback(order, migratetype))
*can_steal = true;
if (!only_stealable)
return fallback_mt;
if (*can_steal)
return fallback_mt;
}
return -1;
}
// 这里窃取页面的目的是从 fallback 类型的 freelist 中拿到一个高阶的大内存块
// 之所以要窃取尽可能大的内存块是为了避免引入内存碎片
// 但 MIGRATE_MOVABLE 类型的页面本身就可以避免永久内存碎片
// 所以 fallback MIGRATE_MOVABLE 类型的页面时,会跳转到 find_**allest 分支只需要选择一个合适的 fallback 内存块即可
static bool can_steal_fallback(unsigned int order, int start_mt)
{
if (order >= pageblock_order)
return true;
if (order >= pageblock_order / 2 ||
start_mt == MIGRATE_RECLAIMABLE ||
start_mt == MIGRATE_UNMOVABLE ||
page_group_by_mobility_disabled)
return true;
// 跳转到 find_**allest 分支选择一个合适的 fallback 内存块
return false;
}
can_steal_fallback 函数中定义了是否可以从 free_list[fallback] 窃取页面到指定 free_list[migratetype] 中,逻辑如下:
-
如果我们指定的内存分配阶 order 大于等于 pageblock_order,则返回 true。pageblock_order 表示系统中支持的巨型页对应的分配阶,默认为伙伴系统中的最大分配阶减一,我们可以通过 cat /proc/pagetypeinfo命令查看。
-
如果我们指定的页面迁移类型为 MIGRATE_RECLAIMABLE 或者 MIGRATE_UNMOVABLE,则不管我们要申请的页面尺寸有多大,内核都会允许窃取页面 can_steal = true ,因为它们最终会 fallback 到 MIGRATE_MOVABLE 可移动页面类型中,这样造成内存碎片的情况会少一些。
-
当内核全局变量 page_group_by_mobility_disabled 设置为 1 时,则所有物理内存页面都是不可移动的,这时内核也允许窃取页面。
在系统初始化期间,所有页都被标记为 MIGRATE_MOVABLE 可移动的页面类型,其他的页面迁移类型都是后来通过 __rmqueue_fallback 窃取产生的。而是否能够窃取 fallback 迁移类型列表中的页面,就是本小节介绍的内容。
7. 内存释放源码实现
在 《深入理解 Linux 物理内存分配全链路实现》 中的 “1. 内核物理内存分配接口” 小节中我们介绍了内核分配物理内存的相关接口:
struct page *alloc_pages(gfp_t gfp, unsigned int order)
unsigned long __get_free_pages(gfp_t gfp_mask, unsigned int order)
unsigned long get_zeroed_page(gfp_t gfp_mask)
unsigned long __get_dma_pages(gfp_t gfp_mask, unsigned int order)
内核释放物理内存的相关接口,这也是本小节的重点:
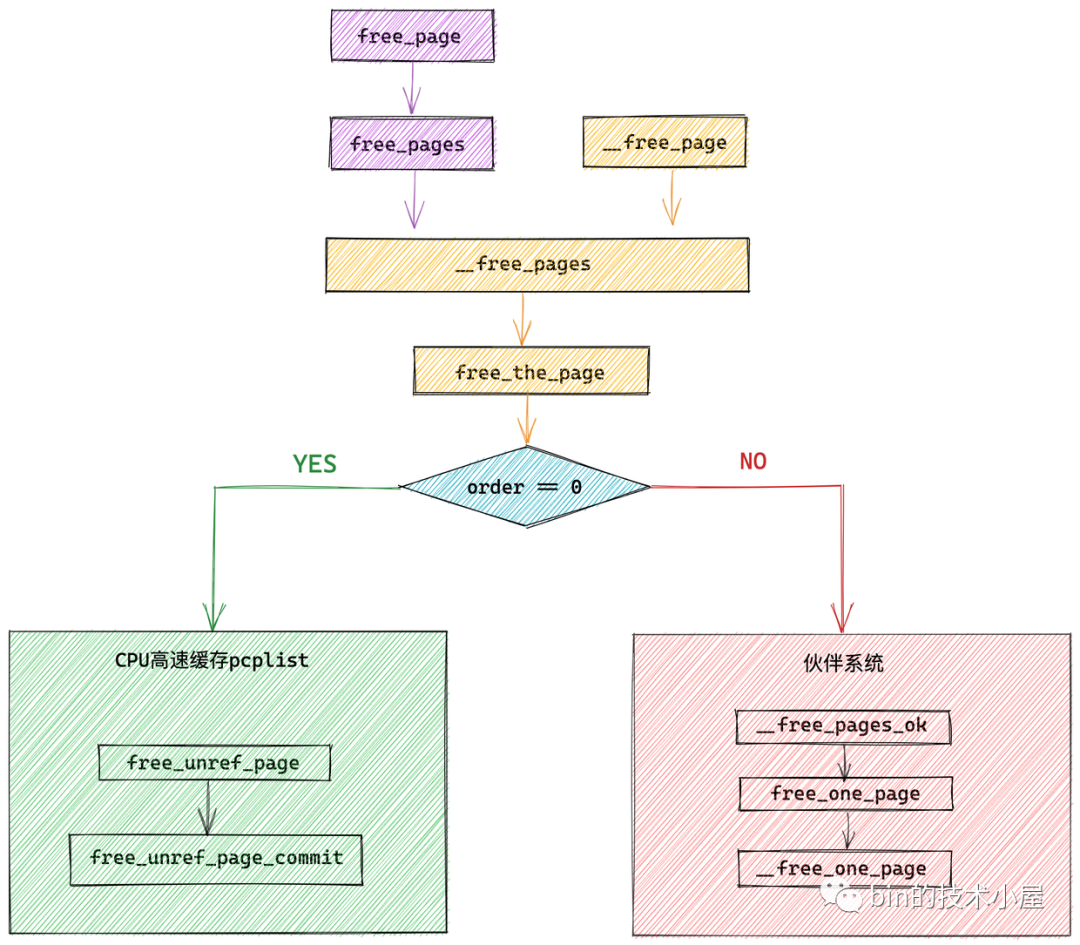
void __free_pages(struct page *page, unsigned int order);
void free_pages(unsigned long addr, unsigned int order);
-
__free_pages : 同 alloc_pages 函数对应,用于释放 2 的 order 次幂个内存页,释放的物理内存区域起始地址由该区域中的第一个 page 实例指针表示,也就是参数里的 struct page *page 指针。
void __free_pages(struct page *page, unsigned int order)
{
if (put_page_testzero(page))
free_the_page(page, order);
}
-
free_pages:同 __get_free_pages 函数对应,与 __free_pages 函数的区别是在释放物理内存时,使用了虚拟内存地址而不是 page 指针。
void free_pages(unsigned long addr, unsigned int order)
{
if (addr != 0) {
// 校验虚拟内存地址 addr 的有效性
VM_BUG_ON(!virt_addr_valid((void *)addr));
// 将虚拟内存地址 addr 转换为 page,最终还是调用 __free_pages
__free_pages(virt_to_page((void *)addr), order);
}
}
在我们释放内存时需要非常谨慎小心,只能释放属于你自己的页,传递了错误的 struct page 指针或者错误的虚拟内存地址,或者传递错了 order 值都可能会导致系统的崩溃。在内核空间中,内核是完全信赖自己的,这点和用户空间不同。
另外内核也提供了 __free_page 和 free_page 两个宏,专门用于释放单个物理内存页。
#define __free_page(page) __free_pages((page), 0)
#define free_page(addr) free_pages((addr), 0)
我们可以看出无论是内核定义的这些用于释放内存的宏或是辅助函数,它们最终会调用 __free_pages,这里正是释放内存的核心所在。
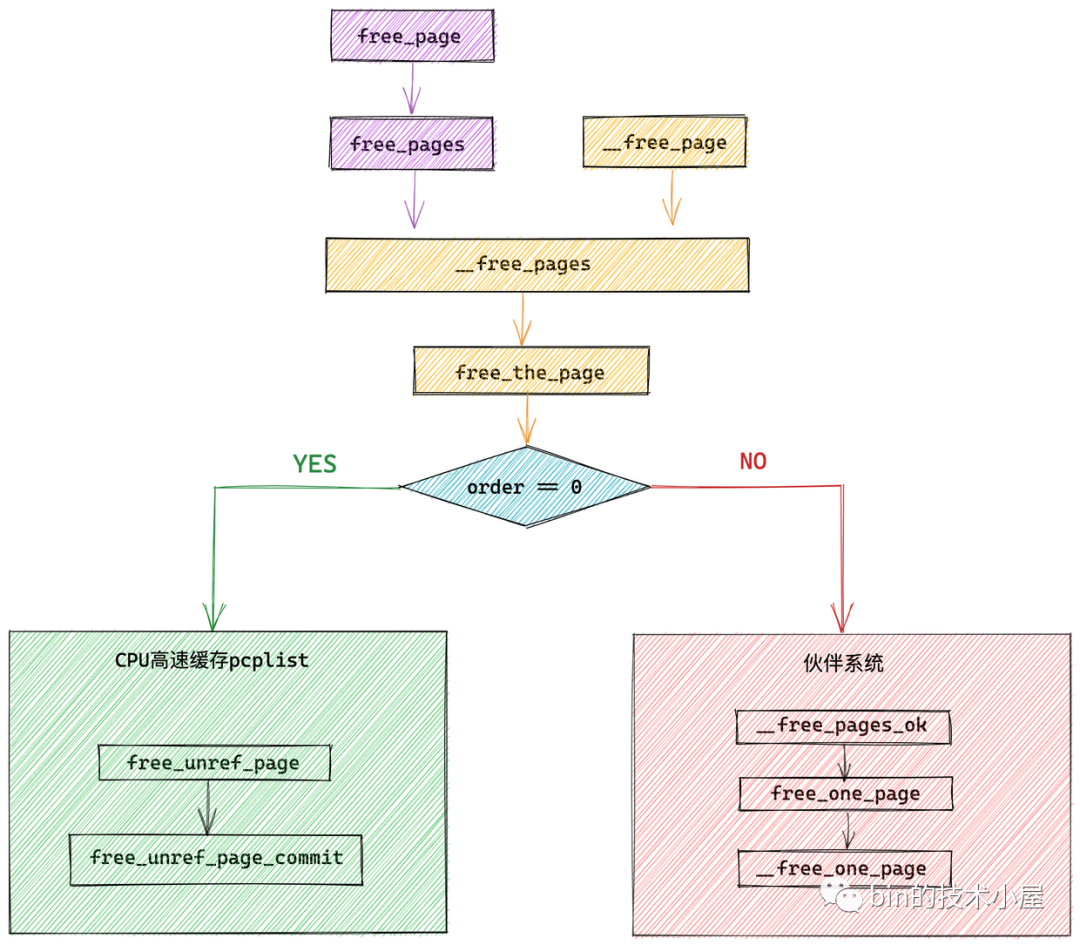
static inline void free_the_page(struct page *page, unsigned int order)
{
if (order == 0)
// 如果释放一页的话,则直接释放到 CPU 高速缓存列表 pcplist 中
free_unref_page(page);
else
// 如果释放多页的话,则进入伙伴系统回收这部分内存
__free_pages_ok(page, order);
}
从这里我们看到伙伴系统回收内存的流程和伙伴系统分配内存的流程是一样的,在最开始首先都会检查本次释放或者分配的是否只是一个物理内存页(order = 0),如果是则直接释放到 CPU 高速缓存列表 pcplist 中。如果不是则将内存释放回伙伴系统中。
struct zone {
struct per_cpu_pages __percpu *per_cpu_pageset;
}
struct per_cpu_pages {
int count; /* pcplist 里的页面总数 */
int high; /* pcplist 里的高水位线,count 超过 high 时,内核会释放 batch 个页面到伙伴系统中*/
int batch; /* pcplist 里的页面来自于伙伴系统,batch 定义了每次从伙伴系统获取或者归还多少个页面*/
// CPU 高速缓存列表 pcplist,每个迁移类型对应一个 pcplist
struct list_head lists[NR_PCP_LISTS];
};
7.1 释放内存至 CPU 高速缓存列表 pcplist 中
/*
* Free a 0-order page
*/
void free_unref_page(struct page *page)
{
unsigned long flags;
// 获取要释放的物理内存页对应的物理页号 pfn
unsigned long pfn = page_to_pfn(page);
// 关闭中断
local_irq_save(flags);
// 释放物理内存页至 pcplist 中
free_unref_page_commit(page, pfn);
// 开启中断
local_irq_restore(flags);
}
首先内核会通过 page_to_pfn 函数获取要释放内存页对应的物理页号,而物理页号 pfn 的计算逻辑会根据内存模型的不同而不同,关于 page_to_pfn 在不同内存模型下的计算逻辑,大家可以回看下笔者之前文章 《深入理解 Linux 物理内存管理》中的 “ 2. 从 CPU 角度看物理内存模型 ” 小节。
最后通过 free_unref_page_commit 函数将内存页释放至 CPU 高速缓存列表 pcplist 中,这里大家需要注意的是在释放的过程中是不会响应中断的。
static void free_unref_page_commit(struct page *page, unsigned long pfn)
{
// 获取内存页所在物理内存区域 zone
struct zone *zone = page_zone(page);
// 运行当前进程的 CPU 高速缓存列表 pcplist
struct per_cpu_pages *pcp;
// 页面的迁移类型
int migratetype;
migratetype = get_pcppage_migratetype(page);
// 内核这里只会将 UNMOVABLE,MOVABLE,RECLAIMABLE 这三种页面迁移类型放入 pcplist 中,其余的迁移类型均释放回伙伴系统
if (migratetype >= MIGRATE_PCPTYPES) {
if (unlikely(is_migrate_isolate(migratetype))) {
// 释放回伙伴系统
free_one_page(zone, page, pfn, 0, migratetype);
return;
}
// 内核这里会将 HIGHATOMIC 类型页面当做 MIGRATE_MOVABLE 类型处理
migratetype = MIGRATE_MOVABLE;
}
// 获取运行当前进程的 CPU 高速缓存列表 pcplist
pcp = &this_cpu_ptr(zone->pageset)->pcp;
// 将要释放的物理内存页添加到 pcplist 中
list_add(&page->lru, &pcp->lists[migratetype]);
// pcplist 页面计数加一
pcp->count++;
// 如果 pcp 中的页面总数超过了 high 水位线,则将 pcp 中的 batch 个页面释放回伙伴系统中
if (pcp->count >= pcp->high) {
unsigned long batch = READ_ONCE(pcp->batch);
// 释放 batch 个页面回伙伴系统中
free_pcppages_bulk(zone, batch, pcp);
}
}
这里笔者需要强调的是,内核只会将 UNMOVABLE,MOVABLE,RECLAIMABLE 这三种页面迁移类型放入 CPU 高速缓存列表 pcplist 中,其余的迁移类型均需释放回伙伴系统。
enum migratetype {
MIGRATE_UNMOVABLE, // 不可移动
MIGRATE_MOVABLE, // 可移动
MIGRATE_RECLAIMABLE, // 可回收
MIGRATE_PCPTYPES, // 属于 CPU 高速缓存中的类型,PCP 是 per_cpu_pageset 的缩写
MIGRATE_HIGHATOMIC = MIGRATE_PCPTYPES, // 紧急内存
#ifdef CONFIG_CMA
MIGRATE_CMA, // 预留的连续内存 CMA
#endif
#ifdef CONFIG_MEMORY_ISOLATION
MIGRATE_ISOLATE, /* can't allocate from here */
#endif
MIGRATE_TYPES // 不代表任何区域,只是单纯的标识迁移类型这个枚举
};
关于页面迁移类型的介绍,可回看本文 "1. 伙伴系统的核心数据结构" 小节的内容。
通过 this_cpu_ptr 获取运行当前进程的 CPU 高速缓存列表 pcplist,然后将要释放的物理内存页添加到对应迁移类型的 pcp->lists[migratetype]。
在 CPU 高速缓存列表 per_cpu_pages 中,每个迁移类型对应一个 pcplist 。
如果当前 pcplist 中的页面数量 count 超过了规定的水位线 high 的值,说明现在 pcplist 中的页面太多了,需要从 pcplist 中释放 batch 个物理页面到伙伴系统中。这个过程称之为惰性合并。
根据本文 "4. 伙伴系统的内存回收原理" 小节介绍的内容,我们知道,单内存页直接释放回伙伴系统会发生很多合并的动作,这里的惰性合并策略阻止了大量的无效合并操作。
7.2 伙伴系统回收内存源码实现
当我们要释放的内存页超过一页(order > 0 )时,内核会将这些内存页回收至伙伴系统中,释放内存时伙伴系统的入口函数为 __free_pages_ok:
static void __free_pages_ok(struct page *page, unsigned int order)
{
unsigned long flags;
int migratetype;
// 获取释放内存页对应的物理页号 pfn
unsigned long pfn = page_to_pfn(page);
// 在将内存页回收至伙伴系统之前,需要将内存页 page 相关的无用属性清理一下
if (!free_pages_prepare(page, order, true))
return;
// 获取页面迁移类型,后续会将内存页释放至伙伴系统中的 free_list[migratetype] 中
migratetype = get_pfnblock_migratetype(page, pfn);
// 关中断
local_irq_save(flags);
// 进入伙伴系统,释放内存
free_one_page(page_zone(page), page, pfn, order, migratetype);
// 开中断
local_irq_restore(flags);
}
__free_pages_ok 函数的逻辑比较容易理解,核心就是在将内存页回收至伙伴系统之前,需要将这些内存页的 page 结构清理一下,将无用的属性至空,将清理之后干净的 page 结构回收至伙伴系统中。这里大家需要注意的是在伙伴系统回收内存的时候也是不响应中断的。
static void free_one_page(struct zone *zone,
struct page *page, unsigned long pfn,
unsigned int order,
int migratetype)
{
// 加锁
spin_lock(&zone->lock);
// 正式进入伙伴系统回收内存,《4.伙伴系统的内存回收原理》小节介绍的逻辑全部封装在这里
__free_one_page(page, pfn, zone, order, migratetype);
// 释放锁
spin_unlock(&zone->lock);
}
之前我们在 "4. 伙伴系统的内存回收原理" 小节中介绍的伙伴系统内存回收的全部逻辑就封装在 __free_one_page 函数中,笔者这里建议大家在看下面相关源码实现的内容之前再去回顾下 5.3 小节的内容。
下面我们还是以 5.3 小节中所举的具体例子来剖析内核如何将内存释放回伙伴系统中的完整实现过程。
在开始之前,笔者还是先把当前伙伴系统中空闲内存页的真实物理视图给大家贴出来方便大家对比,后面在查找需要合并的伙伴的时候需要拿这张图来做对比才能清晰的理解:

以下是系统中空闲内存页在当前伙伴系统中的组织视图,现在我们需要将 page10 释放回伙伴系统中:
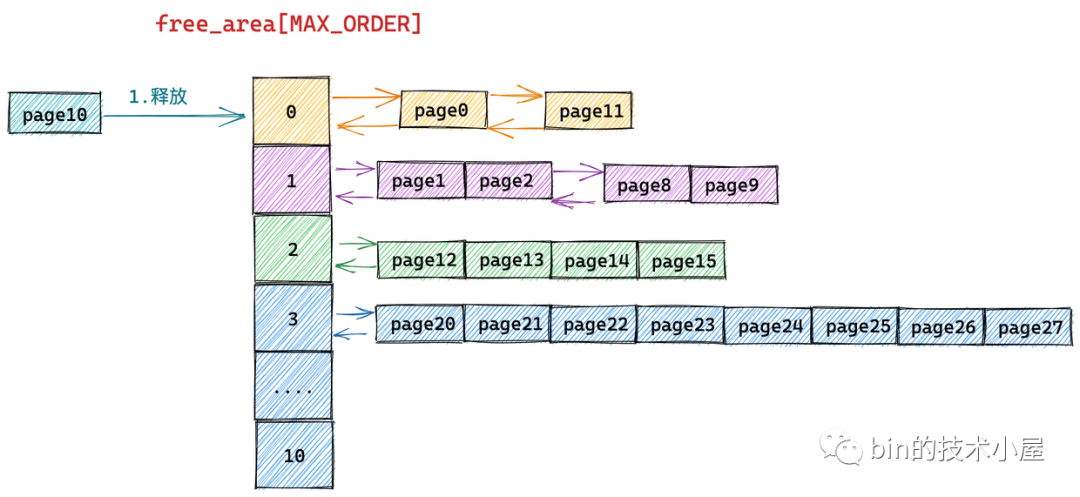
经过 “4. 伙伴系统的内存回收原理” 小节的内容介绍我们知道,在将内存块释放回伙伴系统时,内核需要从内存块的当前阶(本例中 order = 0)开始在伙伴系统 free_area[order] 中查找能够合并的伙伴。
伙伴的定义笔者已经在 “2. 到底什么是伙伴” 小节中详细为大家介绍过了,伙伴的核心就是两个尺寸大小相同并且在物理上连续的两个空闲内存块,内存块可以由一个物理内存页组成的也可以是由多个物理内存页组成的。
如果在当前阶 free_area[order] 中找到了伙伴,则将释放的内存块和它的伙伴内存块两两合并成一个新的内存块,随后继续到高阶中去查找新内存块的伙伴,直到没有伙伴可以合并为止。
/*
* Freeing function for a buddy system allocator.
*/
static inline void __free_one_page(struct page *page,
unsigned long pfn,
struct zone *zone, unsigned int order,
int migratetype)
{
// 释放内存块与其伙伴内存块合并之后新内存块的 pfn
unsigned long combined_pfn;
// 伙伴内存块的 pfn
unsigned long uninitialized_var(buddy_pfn);
// 伙伴内存块的首页 page 指针
struct page *buddy;
// 伙伴系统中的最大分配阶
unsigned int max_order;
continue_merging:
// 从释放内存块的当前分配阶开始一直向高阶合并内存块,直到不能合并为止
// 在本例中当前分配阶 order = 0,我们要释放 page10
while (order < max_order - 1) {
// 在 free_area[order] 中查找伙伴内存块的 pfn
// 上图步骤一中伙伴的 pfn 为 11
// 上图步骤二中伙伴的 pfn 为 8
// 上图步骤三中伙伴的 pfn 为 12
buddy_pfn = __find_buddy_pfn(pfn, order);
// 根据偏移 buddy_pfn - pfn 计算伙伴内存块中的首页 page 地址
// 步骤一伙伴首页为 page11,步骤二伙伴首页为 page8,步骤三伙伴首页为 page12
buddy = page + (buddy_pfn - pfn);
// 检查伙伴 pfn 的有效性
if (!pfn_valid_within(buddy_pfn))
// 无效停止合并
goto done_merging;
// 按照前面介绍的伙伴定义检查是否为伙伴
if (!page_is_buddy(page, buddy, order))
// 不是伙伴停止合并
goto done_merging;
// 将伙伴内存块从当前 free_area[order] 列表中摘下,对比步骤一到步骤四
del_page_from_free_area(buddy, &zone->free_area[order]);
// 合并后新内存块首页 page 的 pfn
combined_pfn = buddy_pfn & pfn;
// 合并后新内存块首页 page 指针
page = page + (combined_pfn - pfn);
// 以合并后的新内存块为基础继续向高阶 free_area 合并
pfn = combined_pfn;
// 继续向高阶 free_area 合并,直到不能合并为止
order++;
}
done_merging:
// 表示在当前伙伴系统 free_area[order] 中没有找到伙伴内存块,停止合并
// 设置内存块的分配阶 order,存储在第一个 page 结构中的 private 属性中
set_page_order(page, order);
// 将最终合并的内存块插入到伙伴系统对应的 free_are[order] 中,上图中步骤五
add_to_free_area(page, &zone->free_area[order], migratetype);
}
根据上图展示的在内存释放过程中被释放内存块从当前阶 free_area[order] 开始查找其伙伴并依次向高阶 free_area 合并的过程以及结合笔者源码中提供的详细注释,整个内存释放的过程还是不难理解的。
这里笔者想重点来讲的是,内核如何在 free_area 链表中查找伙伴内存块,以及如何判断两个内存块是否为伙伴关系。下面我们来一起看下这部分内容:
7.3 如何查找伙伴
static inline unsigned long
__find_buddy_pfn(unsigned long page_pfn, unsigned int order)
{
return page_pfn ^ (1 << order);
}
内核会通过 __find_buddy_pfn 函数根据当前释放内存块的 pfn,以及当前释放内存块的分配阶 order 来确定其伙伴内存块的 pfn。
首先通过 1 << order 左移操作确定要查找伙伴内存块的分配阶,因为伙伴关系最重要的一点就是它们必须是大小相等的两个内存块。然后巧妙地通过与要释放内存块的 pfn 进行异或操作就得到了伙伴内存块的 pfn 。
7.4 如何判断两个内存块是否是伙伴
另外一个重要的辅助函数就是 page_is_buddy,内核通过该函数来判断给定两个内存块是否为伙伴关系。笔者在 "2. 到底什么是伙伴" 小节中明确的给出了伙伴的定义,page_is_buddy 就是相关的内核实现:
-
伙伴系统所管理的内存页必须是可用的,不能处于内存空洞中,通过 page_is_guard 函数判断。
-
伙伴必须是空闲的内存块,这些内存块必须存在于伙伴系统中,组成内存块的内存页 page 结构中的 flag 标志设置了 PG_buddy 标记。通过 PageBuddy 判断这些内存页是否在伙伴系统中。
-
两个互为伙伴的内存块必须拥有相同的分配阶 order,也就是它们之间的大小尺寸必须一致。通过
page_order(buddy) == order判断 -
互为伙伴关系的内存块必须处于相同的物理内存区域 zone 中。通过
page_zone_id(page) == page_zone_id(buddy)判断。
同时满足上述四点的两个内存块即为伙伴关系,下面是内核中关于判断是否为伙伴关系的源码实现:
static inline int page_is_buddy(struct page *page, struct page *buddy,
unsigned int order)
{
if (page_is_guard(buddy) && page_order(buddy) == order) {
if (page_zone_id(page) != page_zone_id(buddy))
return 0;
return 1;
}
if (PageBuddy(buddy) && page_order(buddy) == order) {
if (page_zone_id(page) != page_zone_id(buddy))
return 0;
return 1;
}
return 0;
}
总结
在本文的开头,笔者首先为大家介绍了伙伴系统的核心数据结构,目的是在介绍核心原理之前,先为大家构建起伙伴系统的整个骨架。从整体上先认识一下伙伴系统的全局样貌。
然后又为大家阐述了伙伴系统中的这个伙伴到底是什么概念 ,以及如何通过 __find_buddy_pfn 来查找内存块的伙伴。如果通过 page_is_buddy 来判断两个内存块是否为伙伴关系。
在我们明白了伙伴系统的这些基本概念以及全局框架结构之后,笔者详细剖析了伙伴系统的内存分配原理及其实现,其中重点着墨了从高阶 freelist 链表到低阶 freelist 链表的减半**过程实现,以及内存分配失败之后,伙伴系统的 fallback 过程实现。
最后又详细剖析了伙伴系统内存回收的原理以及实现,其中重点着墨了从低阶 freelist 到高阶 freelist 的合并过程。
好了,到这里关于伙伴系统的全部内容就结束了,感谢大家的收看,我们下篇文章见~~~



