
【全网首发】Linux 中的负载高低和 CPU 开销并不完全对应原创
大家好,我是飞哥!
负载是查看 Linux 服务器运行状态时很常用的一个性能指标。在观察线上服务器运行状况的时候,我们也是经常把负载找出来看一看。在线上请求压力过大的时候,经常是也伴随着负载的飙高。
但是负载的原理你真的理解了吗?我来列举几个问题,看看你对负载的理解是否足够的深刻。
-
负载是如何计算出来的? -
负载高低和 CPU 消耗正相关吗? -
内核是如何暴露负载数据给应用层的?
如果你对以上问题的理解还拿捏不是很准,那么飞哥今天就带你来深入地了解一下 Linux 中的负载!
一、理解负载查看过程
我们经常用 top 命令查看 Linux 系统的负载情况。一个典型的 top 命令输出的负载如下所示。
# top
Load Avg: 1.25, 1.30, 1.95 .....
......
输出中的 Load Avg 就是我们常说的负载,也叫系统平均负载。因为单纯某一个瞬时的负载值并没有太大意义。所以 Linux 是计算了过去一段时间内的平均值,这三个数分别代表的是过去 1 分钟、过去 5 分钟和过去 15 分钟的平均负载值。
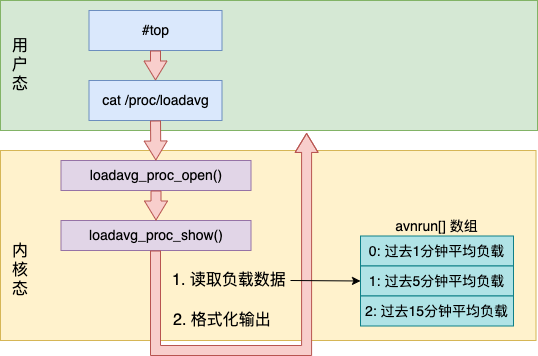
那么 top 命令展示的数据数是如何来的呢?事实上,top 命令里的负载值是从 /proc/loadavg 这个伪文件里来的。通过 strace 命令跟踪 top 命令的系统调用可以看的到这个过程。
# strace top
...
openat(AT_FDCWD, "/proc/loadavg", O_RDONLY) = 7
内核中定义了 loadavg 这个伪文件的 open 函数。当用户态访问 /proc/loadavg 会触发内核定义的函数,在这里会读取内核中的平均负载变量,简单计算后便可展示出来。整体流程如下图所示。
//file: fs/proc/loadavg.c
static int __init proc_loadavg_init(void)
{
proc_create("loadavg", 0, NULL, &loadavg_proc_fops);
return 0;
}
在 loadavg_proc_fops 中包含了打开该文件时对应的操作方法。
//file: fs/proc/loadavg.c
static const struct file_operations loadavg_proc_fops = {
.open = loadavg_proc_open,
......
};
当在用户态打开 /proc/loadavg 文件时,都会调用 loadavg_proc_fops 中的 open 函数指针 - loadavg_proc_open。loadavg_proc_open 接下来会调用 loadavg_proc_show 进行处理,核心的计算是在这里完成的。
//file: fs/proc/loadavg.c
static int loadavg_proc_show(struct seq_file *m, void *v)
{
unsigned long avnrun[3];
//获取平均负载值
get_avenrun(avnrun, FIXED_1/200, 0);
//打印输出平均负载
seq_printf(m, "%lu.%02lu %lu.%02lu %lu.%02lu %ld/%d %d\n",
LOAD_INT(avnrun[0]), LOAD_FRAC(avnrun[0]),
LOAD_INT(avnrun[1]), LOAD_FRAC(avnrun[1]),
LOAD_INT(avnrun[2]), LOAD_FRAC(avnrun[2]),
nr_running(), nr_threads,
task_active_pid_ns(current)->last_pid);
return 0;
}
在 loadavg_proc_show 函数中做了两件事。
-
调用 get_avenrun 读取当前负载值 -
将平均负载值按照一定的格式打印输出
在上面的源码中,大家看到了 FIXED_1/200、LOAD_INT、LOAD_FRAC 等奇奇怪怪的定义,代码写的这么猥琐是因为内核中并没有 float、double 等浮点数类型,而是用整数来模拟的。这些代码都是为了在整数和小数之间转化使的。知道这个背景就行了,不用过度展开剖析。
这样用户通过访问 /proc/loadavg 文件就可以读取到内核计算的负载数据了。其中获取 get_avenrun 只是在访问 avenrun 这个全局数组而已。
//file:kernel/sched/core.c
void get_avenrun(unsigned long *loads, unsigned long offset, int shift)
{
loads[0] = (avenrun[0] + offset) << shift;
loads[1] = (avenrun[1] + offset) << shift;
loads[2] = (avenrun[2] + offset) << shift;
}
现在可以总结一下我们开篇中的一个问题: 内核是如何暴露负载数据给应用层的?
内核定义了一个伪文件 /proc/loadavg,每当用户打开这个文件的时候,内核中的 loadavg_proc_show 函数就会被调用到,接着访问 avenrun 全局数组变量 并将平均负载从整数转化为小数,并打印出来。
好了,另外一个新问题又来了,avenrun 全局数组变量中存储的数据是何时,又是被如何计算出来的呢?
二、内核中负载的计算过程
接上小节,我们继续查看 avenrun 全局数组变量的数据来源。这个数组的计算过程分为如下两步:
1.PerCPU 定期汇总瞬时负载:定时刷新每个 CPU 当前任务数到 calc_load_tasks,将每个 CPU 的负载数据汇总起来,得到系统当前的瞬时负载。
2.定时计算系统平均负载:定时器根据当前系统整体瞬时负载,使用指数加权移动平均法(一种高效计算平均数的算法)计算过去 1 分钟、过去 5 分钟、过去 15 分钟的平均负载。
接下来我们分成两个小节来分别介绍。
2.1 PerCPU 定期汇总负载
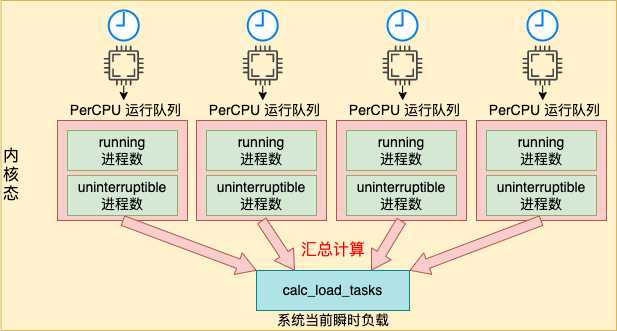
在 Linux 内核中,有一个子系统叫做时间子系统。在时间子系统里,初始化了一个叫高分辨率的定时器。在该定时器中会定时将每个 CPU 上的负载数据(running 进程数 + uninterruptible 进程数)汇总到系统全局的瞬时负载变量 calc_load_tasks 中。整体流程如下图所示。
//file:kernel/time/tick-sched.c
void tick_setup_sched_timer(void)
{
//初始化高分辨率定时器 sched_timer
hrtimer_init(&ts->sched_timer, CLOCK_MONOTONIC, HRTIMER_MODE_ABS);
//将定时器的到期函数设置成 tick_sched_timer
ts->sched_timer.function = tick_sched_timer;
...
}
在高分辨率初始化的时候,将到期函数设置成了 tick_sched_timer。通过这个函数让每个 CPU 都会周期性地执行一些任务。其中刷新当前系统负载就是在这个时机进行的。这里有一点要注意一个前提是每个 CPU 都有自己独立的运行队列,。
我们根据 tick_sched_timer 的源码进行追踪,它依次通过调用 tick_sched_handle => update_process_times => scheduler_tick。最终在 scheduler_tick 中会刷新当前 CPU 上的负载值到 calc_load_tasks 上。因为每个 CPU 都在定时刷,所以 calc_load_tasks 上记录的就是整个系统的瞬时负载值。
我们来看下负责刷新的 scheduler_tick 这个核心函数:
//file:kernel/sched/core.c
void scheduler_tick(void)
{
int cpu = **p_processor_id();
struct rq *rq = cpu_rq(cpu);
update_cpu_load_active(rq);
...
}
在这个函数中,获取当前 cpu 以及其对应的运行队列 rq(run queue),调用 update_cpu_load_active 刷新当前 CPU 的负载数据到全局数组中。
//file:kernel/sched/core.c
static void update_cpu_load_active(struct rq *this_rq)
{
...
calc_load_account_active(this_rq);
}
//file:kernel/sched/core.c
static void calc_load_account_active(struct rq *this_rq)
{
//获取当前运行队列的负载相对值
delta = calc_load_fold_active(this_rq);
if (delta)
//添加到全局瞬时负载值
atomic_long_add(delta, &calc_load_tasks);
...
}
在 calc_load_account_active 中看到,通过 calc_load_fold_active 获取当前运行队列的负载相对值,并把它加到全局瞬时负载值 calc_load_tasks 上。至此,calc_load_tasks 上就有了当前系统当前时间下的整体瞬时负载总数了。
我们再展开看看是如何根据运行队列计算负载值的:
//file:kernel/sched/core.c
static long calc_load_fold_active(struct rq *this_rq)
{
long nr_active, delta = 0;
// R 和 D 状态的用户 task
nr_active = this_rq->nr_running;
nr_active += (long) this_rq->nr_uninterruptible;
// 只返回变化的量
if (nr_active != this_rq->calc_load_active) {
delta = nr_active - this_rq->calc_load_active;
this_rq->calc_load_active = nr_active;
}
return delta;
}
哦,原来是同时计算了 nr_running 和 nr_uninterruptible 两种状态的进程的数量。对应于用户空间中的 R 和 D 两种状态的 task 数(进程 OR 线程)。
由于 calc_load_tasks 是一个长期存在的数据。所以在刷新 rq 里的进程数到其上的时候,只需要刷变化的量就行,不用全部重算。因此上述函数返回的是一个 delta。
2.2 定时计算系统平均负载
上一小节中我们找到了系统当前瞬时负载 calc_load_tasks 变量的更新过程。现在我们还缺一个计算过去 1 分钟、过去 5 分钟、过去 15 分钟平均负载的机制。
传统意义上,我们在计算平均数的时候采取的方法都是把过去一段时间的数字都加起来然后平均一下。把过去 N 个时间点的所有瞬时负载都加起来取一个平均数不完事了。这其实是我们传统意义上理解的平均数,假如有 n 个数字,分别是 x1, x2, ..., xn。那么这个数据集合的平均数就是 (x1 + x2 + ... + xn) / N。
但是如果用这种简单的算法来计算平均负载的话,存在以下几个问题:
1.需要存储过去每一个采样周期的数据
假设我们每 10 毫秒都采集一次,那么就需要使用一个比较大的数组将每一次采样的数据全部都存起来,那么统计过去 15 分钟的平均数就得存 1500 个数据(15 分钟 * 每分钟 100 次) 。而且每出现一个新的观察值,就要从移动平均中减去一个最早的观察值,再加上一个最新的观察值,内存数组会频繁地修改和更新。
2.计算过程较为复杂
计算的时候再把整个数组全加起来,再除以样本总数。虽然加法很简单,但是成百上千个数字的累加仍然很是繁琐。
3.不能准确表示当前变化趋势传统的平均数计算过程中,所有数字的权重是一样的。但对于平均负载这种实时应用来说,其实越靠近当前时刻的数值权重应该越要大一些才好。因为这样能更好反应近期变化的趋势。
所以,在 Linux 里使用的并不是我们所以为的传统的平均数的计算方法,而是采用的一种指数加权移动平均(Exponential Weighted Moving Average,EMWA)的平均数计算法。
这种指数加权移动平均数计算法在深度学习中有很广泛的应用。另外股票市场里的 EMA 均线也是使用的是类似的方法求均值的方法。该算法的数学表达式是:a1 = a0 * factor + a * (1 - factor)。这个算法想理解起来有点小复杂,感兴趣的同学可以 Google 自行搜索。
我们只需要知道这种方法在实际计算的时候只需要上一个时间的平均数即可,不需要保存所有瞬时负载值。另外就是越靠近现在的时间点权重越高,能够很好地表示近期变化趋势。
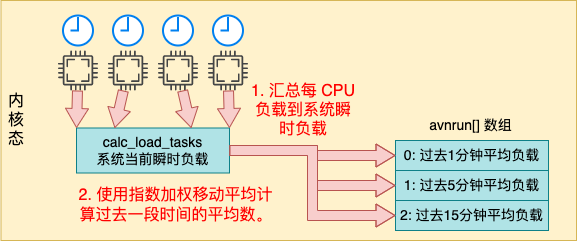
这其实也是在时间子系统中定时完成的,通过一种叫做指数加权移动平均计算的方法,计算这三个平均数。
//file:arch/ia64/kernel/time.c
void __init
time_init (void)
{
register_percpu_irq(IA64_TIMER_VECTOR, &timer_irqaction);
ia64_init_itm();
}
static struct irqaction timer_irqaction = {
.handler = timer_interrupt,
.flags = IRQF_DISABLED | IRQF_IRQPOLL,
.name = "timer"
};
当每次时钟节拍到来时会调用到 timer_interrupt,依次会调用到 do_timer 函数。
//file:kernel/time/timekeeping.c
void do_timer(unsigned long ticks)
{
...
calc_global_load(ticks);
}
其中 calc_global_load 是平均负载计算的核心。它会获取系统当前瞬时负载值 calc_load_tasks,然后来计算过去 1 分钟、过去 5 分钟、过去 15 分钟的平均负载,并保存到 avenrun 中,供用户进程读取。
//file:kernel/sched/core.c
void calc_global_load(unsigned long ticks)
{
...
// 1.获取当前瞬时负载值
active = atomic_long_read(&calc_load_tasks);
// 2.平均负载的计算
avenrun[0] = calc_load(avenrun[0], EXP_1, active);
avenrun[1] = calc_load(avenrun[1], EXP_5, active);
avenrun[2] = calc_load(avenrun[2], EXP_15, active);
...
}
获取瞬时负载比较简单,就是读取一个内存变量而已。在 calc_load 中就是采用了我们前面说的指数加权移动平均法来计算过去 1 分钟、过去 5 分钟、过去 15 分钟的平均负载的。具体实现的代码如下:
//file:kernel/sched/core.c
/*
* a1 = a0 * e + a * (1 - e)
*/
static unsigned long
calc_load(unsigned long load, unsigned long exp, unsigned long active)
{
load *= exp;
load += active * (FIXED_1 - exp);
load += 1UL << (FSHIFT - 1);
return load >> FSHIFT;
}
虽然这个算法理解起来挺复杂,但是代码看起来确实要简单不少,计算量看起来很少。而且看不懂也没有关系,只需要知道内核并不是采用的原始的平均数计算方法,而是采用了一种计算快,且能更好表达变化趋势的算法就行。
至此,我们开篇提到的“负载是如何计算出来的?”这个问题也有结论了。
Linux 定时将每个 CPU 上的运行队列中 running 和 uninterruptible 的状态的进程数量汇总到一个全局系统瞬时负载值中,然后再定时使用指数加权移动平均法来统计过去 1 分钟、过去 5 分钟、过去 15 分钟的平均负载。
三、平均负载和 CPU 消耗的关系
现在很多同学都将平均负载和 CPU 给联系到了一起。认为负载高、CPU 消耗就会高,负载低,CPU 消耗就会低。
在很老的 Linux 的版本里,统计负载的时候确实是只计算了 runnable 的任务数量,这些进程只对 CPU 有需求。在那个年代里,负载和 CPU 消耗量确实是正相关的。负载越高就表示正在 CPU 上运行,或等待 CPU 执行的进程越多,CPU 消耗量也会越高。
但是前面我们看到了,本文使用的 3.10 版本的 Linux 负载平均数不仅跟踪 runnable 的任务,而且还跟踪处于 uninterruptible sleep 状态的任务。而 uninterruptible 状态的进程其实是不占 CPU 的。
为什么要这么修改。我从网上搜到了远在 1993 年的一封邮件里找到了原因,以下是邮件原文。
From: Matthias Urlichs <urlichs@**urf.sub.org>
Subject: Load average broken ?
Date: Fri, 29 Oct 1993 11:37:23 +0200
The kernel only counts "runnable" processes when computing the load average.
I don't like that; the problem is that processes which are swapping or
waiting on "fast", i.e. noninterruptible, I/O, also consume resources.
It seems somewhat nonintuitive that the load average goes down when you
replace your fast swap disk with a slow swap disk...
Anyway, the following patch seems to make the load average much more
consistent WRT the subjective speed of the system. And, most important, the
load is still zero when nobody is doing anything. ;-)
--- kernel/sched.c.orig Fri Oct 29 10:31:11 1993
+++ kernel/sched.c Fri Oct 29 10:32:51 1993
@@ -414,7 +414,9 @@
unsigned long nr = 0;
for(p = &LAST_TASK; p > &FIRST_TASK; --p)
- if (*p && (*p)->state == TASK_RUNNING)
+ if (*p && ((*p)->state == TASK_RUNNING) ||
+ (*p)->state == TASK_UNINTERRUPTIBLE) ||
+ (*p)->state == TASK_SWAPPING))
nr += FIXED_1;
return nr;
}
可见这个修改是在 1993 年就引入了。在这封邮件所示的 Linux 源码变化中可以看到,负载正式把 TASK_UNINTERRUPTIBLE 和 TASK_SWAPPING 状态(交换状态后来从 Linux 中删除)的进程也给添加了进来。在这封邮件中的正文中,作者也清楚地表达了为什么要把 TASK_UNINTERRUPTIBLE 状态的进程添加进来的原因。我把他的说明翻译一下,如下:
“内核在计算平均负载时只计算“可运行”进程。我不喜欢那样;问题是正在“快速”交换或等待的进程,即不可中断的 I/O,也会消耗资源。当您用慢速交换磁盘替换快速交换磁盘时,平均负载下降似乎有点不直观...... 无论如何,下面的补丁似乎使负载平均值更加一致 WRT 系统的主观速度。而且,最重要的是,当没有人做任何事情时,负载仍然为零。;-)”
这一补丁提交者的主要思想是平均负载应该表现对系统所有资源的需求情况,而不应该只表现对 CPU 资源的需求。
假设某个 TASK_UNINTERRUPTIBLE 状态的进程因为等待磁盘 IO 而排队的话,此时它并不消耗 CPU,但是正在等磁盘等硬件资源。那么它是应该体现在平均负载的计算里的。所以作者把 TASK_UNINTERRUPTIBLE 状态的进程都表现到平均负载里了。
所以,负载高低表明的是当前系统上对系统资源整体需求更情况。如果负载变高,可能是 CPU 资源不够了,也可能是磁盘 IO 资源不够了,所以还需要配合其它观测命令具体分情况分析。
四、总结
今天我带大家深入地学习了一下 Linux 中的负载。我们根据一幅图来总结一下今天学到的内容。
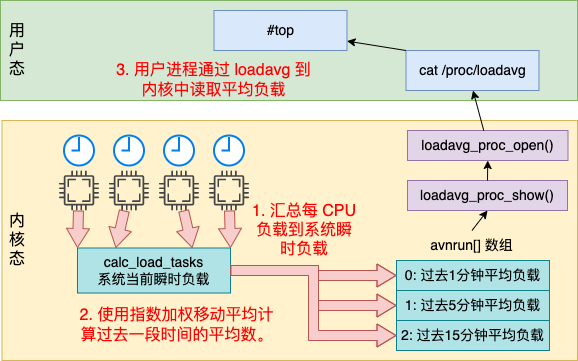
我把负载工作原理分成了如下三步。
-
1.内核定时汇总每 CPU 负载到系统瞬时负载 -
2.内核使用指数加权移动平均快速计算过去1、5、15分钟的平均数 -
3.用户进程通过打开 loadavg 读取内核中的平均负载
我们再回头来总结一下开篇提到的几个问题。
1.负载是如何计算出来的?
是定时将每个 CPU 上的运行队列中 running 和 uninterruptible 的状态的进程数量汇总到一个全局系统瞬时负载值中,然后再定时使用指数加权移动平均法来统计过去 1 分钟、过去 5 分钟、过去 15 分钟的平均负载。
2.负载高低和 CPU 消耗正相关吗?
负载高低表明的是当前系统上对系统资源整体需求更情况。如果负载变高,可能是 CPU 资源不够了,也可能是磁盘 IO 资源不够了。所以不能说看着负载变高,就觉得是 CPU 资源不够用了。
3.内核是如何暴露负载数据给应用层的?
内核定义了一个伪文件 /proc/loadavg,每当用户打开这个文件的时候,内核中的 loadavg_proc_show 函数就会被调用到,该函数中访问 avenrun 全局数组变量,并将平均负载从整数转化为小数,然后打印出来。
好了,今天的分享就到这里了。欢迎分享给你的同事或好友,相信他一定会对你很感激的!




